
목차
69. 예외는 진짜 예외 상황에만 사용하라.
반례
예외를 진짜 예외상황이 아닌 상황에 사용한다는게 무엇일까? 다음 코드를 보자.
try {
int i = 0;
while(true) {
range[i++].climb();
}
} catch(ArrayIndexOutOfBoundsException e) { }
JavaScript
복사
이 코드는 무한 루프를 돌다가 배열의 끝에 도달해 ArrayIndexOutOfBoundsException 예외가 발생하면 catch문에서 아무 동작도 하지 않고 끝내는 로직으로, 예외를 일종의 제어 흐름용으로 사용한 것이다. 그냥 for-each문을 사용하면 되는데, 어째서 위와 같이 작성한 것일까?
for (Mountain m : range){
m.climb();
}
JavaScript
복사
그 이유는 잘못된 추론에 연원한 최적화시도이다.
JVM은 배열에 접근할 때마다 경계를 넘지 않는지 검사하는데, 일반적인 반복문도 배열 경계에 도달하면 종료한다. 그래서 위와 같은 코드로 배열 경계에서 검사되는 로직을 하나 제거한 것이다.
하지만, 이런 최적화는 세 가지 부분에서 잘못된 추론이다.
1.
예외의 용도 자체가 예외 상황을 고려해서 만든 것이기에 JVM 구현자는 명확한 검사만큼 빠르게 만들 이유가 별로 없기에 최적화가 안되있을 확률이 높다.
2.
코드를 try-catch 블럭에 넣으면 JVM이 적용할 수 있는 최적화가 제한된다.
3.
배열을 순회하는 표준 관용구는 앞서 고민했던 중복 검사를 수행하지 않고 JVM이 알아서 최적화 해준다.
즉, 위와 같이 예외를 사용한 최적화를 할 필요가 없으며 오히려 더 느리게 동작한다.
문제는 이 뿐만이 아니다. 위와같이 예외를 예외상황이 아니게 사용하는 경우 문제는 또 있다.
또 다른 문제
예외를 예외상황이 아닌 제어 흐름과 같이 다른 상황에서 사용한다면, 속도 뿐 아니라 프로그램의 유지 보수 측면에서도 문제가 있다. 위 코드의 try 블럭 안에 로직을 작성하는데 여기서 관련 없는 배열에서 ArrayIndexOutOfBoundsException이 발생해도, 이 버그를 정상적인 반복문 종료 상황으로 보고 넘어간다. 이렇게 되면, 실제로 예외가 던져져야 하는 상황에서도 그러지 못하기에 예기치 못한곳에서 예외가 발생해 디버깅의 어려움을 겪을 수 있다.
그렇기에 예외는 오직 예외상황에서만 사용하도록 해야 한다.
참고: 상태 검사 메서드, 옵셔널, 특정 값
예외를 통해 제어흐름을 하지 않으면서 할 수 있는 방법은 뭐가 있을까?
상태 검사 메서드를 사용해 진행 여부(반복 여부)를 선택할 수도 있고, 비어있는 옵셔널 혹은 null과 같은 특정 값을 반환할수도 있다. 이런 여러 방식을 선택하는 지침을 소개한다.
1.
외부 동기화 없이 여러 스레드가 동시 접근이 가능하거나 외부 요인에 의해 상태가 변할 수 있다면 옵셔널이나 특정 값을 사용한다.
상태 검사 메서드와 상태 의존적 메서드 호출 사이에 객체의 상태가 변할 수 있기 때문이다.
2.
성능이 중요한 상황에서 상태 검사 메서드가 상태 의존적 메서드의 작업 일부를 중복 수행한다면 옵셔널이나 특정 값을 선택한다.
3.
그 외의 경우에는 상태 검사 메서드가 더 낫다. 가독성도 좋고, 문제가 발생할 경우 발견하기도쉽다.
70. 복구할 수 있는 상황에는 검사 예외를, 프로그래밍 오류에는 런타임 예외를 사용하라.
Previous
예외에 대해 자세히 모르겠다면 다음 포스팅을 참고하자.
개요
자바에서 프로그램 실행시 문제가 발생하는 것을 오류라고 하는데, 이런 오류를 알리는 타입을 throwable이라 하고 자세히 살펴보면 오류의 경우에 따라 검사 예외(checked exception), 런타임 예외(unchecked exception), 에러(error)라고 분류할 수 있다. 그런데 언제 무엇을 사용할지에 대해 고민이 될 수 있고, 이번 아이템에서는 이런 상황에서 참고하면 좋은 지침을들 안내한다.
1. 호출하는 쪽에서 복구하리라 여겨지는 상황이라면 검사 예외를 사용하라.
이는 checked와 unchecked exception 을 구분하는 기본 규칙으로, 검사 예외의 경우 호출자가 그 예외를 잡아 처리하거나 바깥으로 전파하도록 강제하게 된다.
 참고: 검사 예외란?
참고: 검사 예외란?•
컴파일 타임에 검사되는 예외
•
(스프링은) 예외가 발생해도 트랜잭션에 의해 롤백되지 않는다.
•
반드시 예외 처리를 해야하는 코드
◦
try-catch or throws로 처리한다.
public static void main(String[] args) throws IOException {
byte[] inSrc = Arrays.asList(args);//{0, 1, 2, 3, 4, 5};
byte[] outSrc = null;
byte[] temp = new byte[4];
ByteArrayInputStream input = new ByteArrayInputStream(inSrc);
ByteArrayOutputStream output = new ByteArrayOutputStream();
try {
while (input.available() > 0) {
int len = input.read(temp);
output.write(temp, 0, len);
}
} catch (IOException ie) {
}
outSrc = output.toByteArray();
System.out.println("Input Source: " + Arrays.toString(inSrc));
System.out.println("temp: " + Arrays.toString(temp));
System.out.println("Output Source: " + Arrays.toString(outSrc));
}
Java
복사
CheckedException이 발생하는 코드 args로 입력한 배열을 읽은 뒤 output에 저장하는 코드
2. 프로그래밍 오류를 나타낼 때는 런타임 예외를 사용하자.
그리고 비검사 throwable은 Runtime Exception과 Error 두 가지가 있다.
둘 다 프로그램에서 잡을 필요도 없고 잡지 않아야 하는 상황으로 이 경우 적절한 오류 메세지와 함께 중단된다. 대부분 런타임 예외는 전제조건을 만족하지 못했을 경우를 의미하는데, 정리하자면 클라이언트에서 API명세의 규약을 지키지 못하는 경우를 말한다.
public class Car {
private String name;
public Car(String name) {
if(name.length() > 5){
throw new IllegalArgumentException("이름은 5자를 넘을 수 없습니다.");
}
this.name = name;
}
}
Java
복사
Car 도메인은 이름이 5글자를 넘지 말아야한다는 규약이 있다.
그리고 에러(Error)는 JVM의 자원부족, 불변식 깨짐 등 더 이상 수행이 불가한 상황을 나타낼 때 사용하는데, 이 Error 클래스를 상속해 하위 클래스를 만드는 일은 자제해야 한다.
3. Throwable은 사용하지 말자.
Exception, RuntimeException, Error같은 상위 예외를 상속하지 않는 throwable을 만들 수 도 있지만, 결코 좋을게 없으니 사용하지 않도록 하자. 딱히 더 좋지도 않으면서 개발자를 헷갈리게 할 뿐이다.
4. 검사 예외는 복구에 필요한 정보를 제공하자.
검사 예외는 일반적으로 복구할 수 있는 조건에서 발생한다.
따라서 호출자가 예외 상황에서 벗어나기 위해 필요한 정보를 알려주는 메서드를 함께 제공하는것이 중요하다.
정리
•
복구할 수 있는 상황에는 검사 예외를 사용하자.
•
프로그래밍 오류라면 비검사 예외를 던지자.
•
확실하지 않다면 비검사 예외를 던지자.
•
두 경우에 포함되지 않는 throwable은 정의조차 하지 말자.
•
검사 예외라면 복구에 필요한 정보를 알려주는 메서드도 제공하자.
71. 필요 없는 검사 예외 사용은 피하라.
개요
검사 예외(Checked Exception)은 예외가 발생하면 이 문제를 개발자가 처리해 안전성을 높이게 해준다. 그렇기에 잘만 사용한다면 코드의 품질은 올라갈 수 있다.
하지만, 좋다는 말에 과도하게 검사 예외를 남용하다보면 API 설계 자체가 복잡해지고 사용하기 힘든 API가 될 수 있다.
public static void main(String[] args) {
occurrenceCheckedException(Boolean.parseBoolean(args[0]));
}
private static void occurrenceCheckedException(boolean flag) throws IOException {
if (flag) {
throw new IOException("임의의 예외 발생");
}
}
Java
복사
이를 해결하기 위해서는 try-catch 혹은 throw로 상위 호출자로 던져야 한다.
어떤 방법이든 API 사용자에게는 부담이 될 수 있다. 게다가 예외를 던지는 메서드는 스트림 내부에서는 직접적으로 사용할 수도 없다.
그래서 개발자에게 하고 싶은 말은 이거다.
의미 있는 처리를 할 수 없다면 비검사 예외를 사용해라.
사용이 번거로울 수 있고 불편할지라도, API를 제대로 사용해도 발생할 수 있는 예외이거나, 개발자가 의미있는 조치를 할 수 있는 경우 검사예외를 사용해도 문제 없다. 아니 오히려 더 안정적이다.
하지만, 이런 경우에 해당하지 않는다면 비검사 예외(Unchecked Exception)을 사용하는게 좋다.
하나의 검사 예외만 던질 경우 고민해보자.
메서드에서 두 개의 검사 예외를 던진다고 가정해보자.
public static void main(String[] args) {
try {
occurrenceCheckedException(args);
} catch (IOException | ClassNotFoundException e) {
//logic...
}
}
private static void occurrenceCheckedException(String[] args) throws IOException, ClassNotFoundException {
if (args[0].equals("on")) {
throw new IOException("임의의 예외 발생");
}
if (args[1].equals("on")) {
throw new ClassNotFoundException("클래스 로드 불가 예외");
}
}
Java
복사
여기서 새로운 예외가 추가된다고 생각하면 그냥 catch문을 추가하거나 처리로직도 동일하다면 | 로 추가 될 예외만 추가해주면 된다.
catch (IOException | ClassNotFoundException | ${추가 될 예외} e)
Java
복사
하지만, 그게 아니라 예외가 단 하나라면 try-catch 블럭을 추가해야하고 스트림에서 직접 사용하지 못하게 되기에 검사 예외를 사용하기가 까다로워진다.
이런 경우 책에서는 검사 예외를 회피하기 위해 적절한 결과 타입을 담은 옵셔널을 반환하는 방안을 제시한다. 물론, 이 방법은 예외의 발생 원인과 같은 정보를 제공하기 힘들다는 점이 있다.
또 다른 방법으로는 검사 예외를 던지는 메서드를 2개로 쪼개 비검사 예외로 바꾸는 방식이다.
//before
try {
obj.action(args);
} catch (CheckedException e) {
//logics...
}
//after
if(obj.actionPermitted(args)) {
obj.action(args);
} else {
//logics...
}
Java
복사
다만, 이 방법은 몇 가지 단점이 존재하는데 첫 째로, 모든 상황에서 적용은 불가능 하다는 점과, 외부 동기화 없는 멀티 쓰레드 환경에서 actionPermitted(args) 메서드 호출과 action(args) 호출 시간 사이에 외부 요인에 의해 상태가 변하면서 문제가 발생할 수 있다. 즉 Thread-Safe 하지 않다.
그리고, 두 메서드간에 동작이 중복되는게 있다면 성능적으로도 손해이기에 잘 고려해서 적용하도록 해야 한다.
정리
•
필요한 곳에서 검사 예외는 프로그램의 안전성을 높혀준다.
•
API 호출자가 예외 복구를 할 수 없다면 비검사 예외를 던지자.
•
API 호출자가 예외 복구를 할 수 있고, 해주길 바란다면 옵셔널을 반환할 수 있을지 고민하자.
◦
옵셔널로 해결이 안되는 경우에는 검사 예외를 던지자.
72. 표준 예외를 사용하라.
재사용성
클래스, 메서드, 필드를 설계하고 코드를 작성하면서 우리가 좀 더 좋은 코드를 작성하기 위해 노력을 하는데, 그 중에서는 재사용성도 있다. 숙련된 개발자일수록 코드의 중복을 줄일 뿐더러 많은 코드를 재사용한다. 그리고 이런 재사용의 대상에는 예외 역시 포함된다.
물론, 자바 라이브러리는 대부분의 API 에서 쓰기에 적절한 예외를 모두 제공한다.
표준 예외 사용의 장점
그럼 내가 별도로 명시적인 예외를 만드는 것과 비교해서 표준 예외 사용이 어떠한 이점을 가져올까?
•
다른 개발자가 익히고 사용하기 쉬워진다.
◦
개발자 입장에선 낯선 프로그램이라고 하더라도 익숙한 표준 예외가 던져진다면, 읽기 쉬울 것이다. 어디서 갑자기 개발자가 임의로 만든 InvalidMoneyAmountByChildException보다는 IllegalArgumentException이 익숙할 것이다.
◦
이미 익숙한 규약들을 그대로 따르기에 핸들링하기도 쉬워진다.
•
예외 클래스 수가 적을수록 메모리 사용량도 줄고 클래스를 적재하는 시간도 적어진다.
Exception, RuntimeException, Throwable, Error는 직접 사용하지 말자.
표준예외를 사용하라고 했다고, 또 무슨 예외를 던져야 할 지 잘 모르겠다고, 무작정 RuntimeException을 던지는 개발자가 많다. 하지만, 이는 지양해야 할 방법으로 IDE에서 SonarLint같은 정적 코드 분석 플러그인을 사용하면 바로 경고문구를 던지곤 한다.
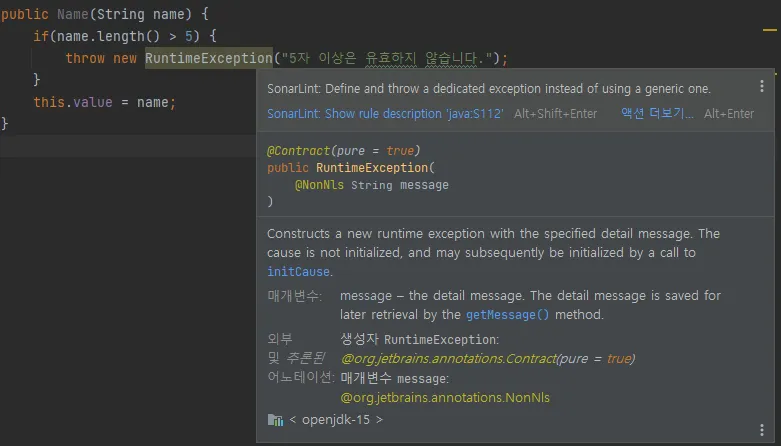
SonarLint에서 일단 예외(Generic Exception)는 그냥 던져서는 안된다고 경고한다.
이처럼 이런 클래스들은 추상 클래스라 생각하는게 좋다. 이 클래스들은 다른 예외들의 상위 클래스로 여러 성격을 포함하는 포괄적인 클래스이기에 적절한 예외를 알리기 힘들다.
자주 사용되는 표준 예외의 쓰임새
예외 | 주요 쓰임 |
IllegalArgumentException | 허용하지 않는 값이 인수로 전달되었을 때(Null은 NPE로 처리) |
IllegalStateException | 객체가 메서드를 수행하기 적절치 않은 상태일 때 |
NullPointerException | null을 허용하지 않는 메서드에 null을 전달했을 때 |
IndexOutOfBoundsException | 인덱스가 범위를 넘어섰을 때 |
ConcurrentModificationException | 허용하지 않는 동시 수정이 발견되었을 때 |
UnsupportedOperationException | 호출한 메서드를 지원하지 않을 때 |
상호 배타적이지 않은 예외의 쓰임새
그런데, 예외객체간의 쓰임새가 모두 고유하지는 않기에 겹치는 부분들이 있고 이런 경우 고민이 될 수 있다. 예를 들어 카드 덱을 표현하는 객체가 있고, 인수로 전달한 수 만큼 카드를 뽑아 나눠주는 메서드를 제공한다고 하자.
이 때, 덱에 남아 있는 카드 수보다 큰 값을 인수로 전달하면 어떤 예외를 던져야 할까?
public class Cards {
private final List<Card> deck = new ArrayList<>();
public static Cards from(int count) {
List<Card> deck = new ArrayList<>();
for (int i = 0; i < count; i++) {
deck.add(new Card(i));
}
return new Cards(deck);
}
public Cards(List<Card> deck) {
this.deck.addAll(deck);
}
public List<Card> poll(int pickCount) {
if (pickCount > deck.size()) {
throw new ???; //무슨 예외를 던져야 할까?
}
Collections.shuffle(deck);
return deck.subList(0, pickCount);
}
private static class Card {
int number;
public Card(int number) {
this.number = number;
}
}
}
Java
복사
여기서 인수의 값이 너무 크다고 생각하면 IllegalArgumentException을 던질 것이고 덱의 카드 수가 너무 적다고 보면 IllegalStateException을 던질 것이다.
이런 경우 다음과 같은 규칙을 가이드 한다.
인수 값과 무관하게 실패했을 것이라면 IllegalStateException을 던진다.
인수 값에 따라 성공할 수 있었다면 IllegalArgumentException을 던진다.
Question
이 글을 보는 사람들에게 다음과 같은 질문을 해보자.
다음 코드는 적절한가? 적절하지 않다면 무슨 표준 예외가 적절한가?
public class Name {
private final String value;
public Name(String name) {
if(name.length() > 5) {
throw new InvalidNameLengthException(5);
}
this.value = name;
}
}
public class InvalidNameLengthException extends RuntimeException {
public static final String DEFAULT_MESSAGE = "%d자 이상은 유효하지 않습니다.";
public InvalidNameLengthException(int limit) {
super(DEFAULT_MESSAGE.formatted(limit));
}
}
Java
복사
그래서 제 생각은요...
73. 추상화 수준에 맞는 예외를 던져라.
예외 번역(Exception translation)
현재 로직과 전혀 상관없고 유추할 수 없는 예외가 나올 경우 당황스러울 것이다.
이는 메서드를 호출했을 때 메서드가 저수준 예외를 처리하지 않고 바깥으로 전파해버릴 때 종종 일어나는 상황이다.
이러한 방식은, 단순히 당황시키는 것으로 끝나는게 아니라 내부 구현 방식을 드러내 윗 레벨 API를 오염시킬 수 있다. 구현 방식이 바뀌게 되면 다른 예외가 전파되어 프로그램을 깨지게 할 수도 있다.
이런 문제를 피하기 위해서 전파된 저수준 예외를 잡아 자신의 추상화 수준에 맞는 예외로 바꾼뒤 던져야하는데 이를 예외 번역(exception translation)이라 한다.
try {
... // 저수준 추상화 이용
} catch(LowLevelException e) {
//추상화 수준에 맞게 번역한다.
throw new HigherLevelException(...);
}
Java
복사
예외 번역의 예시
예외 연쇄(exception chaining)
예외를 번역해서 상위로 전파할 때 번역할 저수준 예외가 디버깅에 도움이 된다면 예외 연쇄를 사용할 수 있다. 이 예외 연쇄란 문제의 원인(cause)를 고수준 예외에 실어 보내는 방식으로, 상위 계층에서는 필요하면 저수준 예외를 꺼내어 확인할 수 있다.
try {
... // 저수준 추상화 이용
} catch(LowLevelException e) {
// 저수준 예외(e)를 고수준 예외에 실어 보낸다.
throw new HigherLevelException(e);
}
Java
복사
예외 번역도 남용해선 안된다.
저수준의 예외를 무작정 바깥으로 전파해서 생기는 문제는 해결할 수 있지만, 그렇다고 이를 남용해서는 안된다. 전파 혹은 번역을 하기전에 적절한 수준에서 메서드가 성공하도록하여 하위 계층에서 예외가 발생하지 않도록 만드는게 최선이다. 그러기 위해서는 몇 가지를 유념해두자.
•
상위 계층에서 인수를 전달하기 전에 미리 검사한다.
•
java.util.logging의 로깅 기능등을 이용해 기록해두어 클라이언트에게 전파하지 않고 프로그래머가 로그 분석 및 조치를 취할 수 있게 한다.
74. 메서드가 던지는 모든 예외를 문서화하라.
개요
아이템 56 의 주제인 모든 public 메서드에 주석을 달라는 내용과 연결된다.
즉, 모든 public 메서드에는 주석을 다는데 그 주석 내용에는 예외 내용을 포함하라는 말이다. 주석은 개발자가 메서드를 올바르게 사용하기 위한 정보를 제공하는데, 여기서 예외에 대한 문서는 메서드를 올바르게 쓰기 위해 중요한 정보이다.
그렇기에, 검사 예외는 항상 따로 선언하고, 각 예외가 발생하는 상황을 javadoc의 @throws 태그를 사용해 문서화하자.
너무 포괄적인 예외로 합쳐 선언하는 일은 삼가자.
public class Foo {
public void xxx1() throws Exception {
//...logic
throw new Exception("err1");
}
public void xxx2() throws Exception {
//...logic
throw new Exception("err2");
}
public void xxx3() throws Exception {
//...logic
throw new Exception("err3");
}
}
Java
복사
모든 예외를 RuntimeException으로 퉁쳐버린 코드
위처럼 각각의 예외를 RuntimeException이라는 큰 추상 예외 클래스로 선언할 경우 어떤 문제가 있을까? 사용자는 해당 클래스 Foo에서 각각의 메서드 마다 발생하는 예외가 모두 뭉뚱그려 선언되어 던져진다면 해당 예외가 어째서 발생하는지 구분하기 힘들 것이다. 직접 디버깅을 통해 알아봐야하는데, 이는 너무 큰 비용소모이다.
또한, 이러한 예외가 한 depth에서 발생한 것이 아닌 여러 depth에서 전파된 것일 경우 모든 예외를 뭉쳐버리게 만들어서 API의 사용성이 필연적으로 떨어지게 된다.
(main 메서드는 JVM에서 호출되기에 Exception을 던지도록 해도 상관없다. )
그리고 이런 문서화는 비검사 예외도 검사 예외처럼 문서화해두면 좋다.
비검사 예외는 자바 언어에서 요구하진 않지만, 문서화를 잘 해 둘 경우 개발자는 해당 문서를 참조해 제약을 지켜 문제가 발생하지 않도록 코딩할 수 있다.
비검사 예외는 throws 목록에 넣지 말자.
public void method() throws Exception, RuntimeException {
//...logic
}
Java
복사
위와 같이 작성한 메서드는 문제가 있다.
예외가 검사냐 비검사냐에 따라 API 사용자가 해야 할 일이 달라지기에 이 둘은 구분해주는게 좋다.
/**
* Main Description ... bla bla
*
* @throws RuntimeException ...bla bla
*/
public void method() throws Exception {
//...logic
}
Java
복사
이처럼 검사예외와 비검사 예외를 선언부 throws절과 주석의 @throws 태그로만 구분해도 자바독 문서에서도 이런 예외들을 시각적으로 구분해준다. 그래서 개발자는 예외가 비검사인지 검사인지 알 수 있다.
비검사 예외 문서화가 불가능한 경우
그런데, 이런 비검사 예외의 문서화가 항상 가능한것은 안디ㅏ.
클래스 수정으로 새로운 비검사 예외를 던지게 되어도 소스 호환성, 바이너리 호환성이 그대로 유지된다는게 큰 이유다. 예를 들어, 다른 사람이 작성한 클래스를 사용한 메서드가 있다고 할 때 이 외부 클래스가 나중에 새로운 비검사 예외를 던지게 수정된다면, 아무 수정도 하지 않은 우리 메서드에서는 문서에 정의되지 않은 새 로운 비검사 예외를 전파하게 될 것이다.
예외 합치기
바로 위에서 예외를 하나로 뭉뚱그리지 말라고 했지만, 여기선 예외 합치기에 대해 말해보려 한다.
public class Foo {
/**
* Method Description ... bla bla
*
* @throws NullPointerException
*/
public void method1(Bar bar){
if(bar == null) { throw new NullPointerException(); }
}
/**
* Method Description ... bla bla
*
* @throws NullPointerException
*/
public void method2(Bar bar){
if(bar == null) { throw new NullPointerException(); }
}
/**
* Method Description ... bla bla
*
* @throws NullPointerException
*/
public void method3(Bar bar){
if(bar == null) { throw new NullPointerException(); }
}
/**
* Method Description ... bla bla
*
* @throws NullPointerException
*/
public void method4(Bar bar){
if(bar == null) { throw new NullPointerException(); }
}
}
Java
복사
위 코드를 보면 4개의 메서드에서 모두 동일한 이유로 NPE(NullPointerException)을 던지고 있고, 이에 대한 주석을 각각 작성하고 있다. 이런 경우 메서드 주석을 메서드 레벨이 아닌 클래스 문서화 주석에 추가할 수 있다.
/**
* Class Description ...
*
* 이 클래스의 모든 메서드는 인수로 null이 넘어오면 NullPointerException을 던진다.
*/
public class Foo {
public void method1(Bar bar){
if(bar == null) { throw new NullPointerException(); }
}
public void method2(Bar bar){
if(bar == null) { throw new NullPointerException(); }
}
public void method3(Bar bar){
if(bar == null) { throw new NullPointerException(); }
}
public void method4(Bar bar){
if(bar == null) { throw new NullPointerException(); }
}
}
Java
복사
정리
•
메서드가 던질 가능성이 있는 모든 예외를 문서화 하라.
•
검사 예외는 선언부의 throws 문에 선언하고, 비검사 예외는 메서드 선언에 기입하지 말자.
•
예외에 대한 문서화가 잘 되있고, 뭉뚱그리지 않을수록 사용하기 편해진다.
75. 예외의 상세 메시지에 실패 관련 정보를 담으라.
개요
예외는 프로그램에서 예기치 못한 오류가 발생했을 때 어떤 오류인지, 어디서 발생했는지 등의 예외 정보를 담아서 개발자에게 전달해주기 위해 존재한다. 그렇기에 자바 시스템에서는 예외의 stack trace 정보를 자동으로 출력한다.
그 말인즉슨, 실패 원인에 대해 예외 상세 메세지로 제대로 전달할수록 개발자는 예외 분석을 쉽고 빠르게 할 수 있고 고칠 수 있게 된다.
예외 상세 메세지에는 뭘 담아야 할까?
실패 순간을 포착하기 위해서는 예외에 관여된 모든 매개변수와 필드의 값을 실패 메세지에 담아야 한다.
예를 들면, IndexOutOfBoundsException 예외가 있다. 해당 예외의 메세지는 범위의 최솟값과 최댓값, 그리고 그 범위를 벗어났다는 인덱스의 값을 담아야 한다.
이 세 가지 정보중에서 하나 혹은 셋 모두가 잘못되었을 수 있는데, 문제의 원인이 정보가 많은만큼 다양할 수 있기에 이런 자세한 정보가 분석에 도움을 줄 수 있다.
그렇다고, 예외의 상세 메세지를 자세히 작성하라는것과 구구절절하게 작성하라는 것을 혼동해서는 안된다. 예외 발생시 stack trace에서는 예외가 발생한 소스명과 줄 번호까지 모두 기록되어 있다.
그렇기에 문서나 소스코드에서 얻을 수 있는 정보를 길게 늘어트릴 필요가 없다.
예외의 상세 메세지와 최종 사용자에게 보여줄 오류 메세지를 혼동하지 말자.

숫자형 Input에 문자를 담아 전송한 경우 볼 수 있는 에러 내용
웹페이지 사용자에게 위와같이 예외 메세지를 노출하면 바로 이슈 등록 사항이다.
최종 사용자에게 예외의 상세 메세지를 보여줄 필요는 없다. 사용자는 어짜피 이런 서버의 문제를 해결 할 책임도 없다. 충분히 이해할 수 있는 친절한 안내 메세지를 보여줘야 한다.
그럼 위와같은 메세지는 누구에게 보여줘야 할까? 최종 사용자에게 노출하는 안내 메세지가 아닌 예외 메세지는 가독성보다는 내용이 중요하다. 노출 목적이 개발자에게 예외 원인을 알려주기 위해서이기 때문이다.
예외는 실패 관련 정보를 접근자 메서드를 적절히 제공하는게 좋다.
예외의 목적을 다시 말하자면 개발자에게 포착한 실패 정보를 잘 전달해 예외 상황을 복구하는데 있다. 그렇기에 적절한 접근자 메서드를 이용해 예외 내용을 전달할 수 있다면 더욱 좋다.
그리고 이런 실패 정보는 비검사 예외(Unchecked Exception)보다는 검사 예외(Checked Exception)에서 더욱이 유용하게 사용될 것이다. 왜냐? 바로 상황을 복구할 수 있는 정보를 받아 복구할 수 있기에!
76. 가능한 한 실패 원자적으로 만들라
실패 원자적?
실패 원자적이 무슨 얘기일까?
책에서는 다음과 같이 설명을 하고 있다.
호출된 메서드가 실패하더라도 해당 객체는 메서드 호출 전 상태를 유지하도록 하는 특성을 실패 원자적(failure-atomic)이라 한다.
즉, 메서드의 실패가 전체 로직에 영향을 주지 않도록 하는 것인데, 어떻게 메서드를 실패 원자적으로 만들 수 있을까?
1. 불변 객체

가장 간단한 방법은 불변 객체로 설계하는 것인데, 불변 객체는 태생적으로 실패 원자적이다.
메서드가 실패하면 새로운 객체가 만들어지지는 않을 수 있지만, 기존 객체가 불안정한 상태가 되는 경우는 없다. 말 그대로 불변이기 때문이다. 그럼 가변 객체의 메서드는 어떻게 실패 원자적으로 만들까?
2. 로직 수행 전 매개변수의 유효성 검사
7. 메서드
목차

https://catsbi.oopy.io/1b439cd5-58aa-4cb1-a715-2bfa66afc72a#751b185f-4978-4581-85c9-5bf10d5780c8

아이템 49. 매개변수가 유효한지 확인하라.
객체의 내부 상태를 변경하기 전매개변수의 유효성을 검사한다면, 잠재적 예외의 가능성 대부분을 걸러낼 수 있다. 다음 Stack 객체의 pop 메서드를 보자.
public Object pop() {
if(size == 0) throw new EmptyStackException();
Object result = elements[--size];
elements[size] = null; //다 쓴 참조 해제
return result;
}
Java
복사
Stack.pop 메서드
이 pop 메서드는 메서드 호출 전 size의 값을 확인해서 0인 경우 예외를 던진다.
이 예외가 없더라도 스택이 비어있다면 예외를 던진다. 그럼 결국 둘 다 예외를 던지는 것 같지만, 이 후자의 경우에는 size의 값이 음수가 되어 다음 호출도 실패하게 만들뿐 아니라 이 경우 던지는 예외도 EmptyStackException이 아닌 ArrayIndexOutOfBoundsException으로 추상화 수준에 맞지 않는 예외를 던지게 되는 문제가 있다.
3. 실패할 수 있는 코드를 객체의 상태를 바꾸기전에 수행하자.
객체의 상태가 변한 다음 로직이 실패하면 이미 늦기에 상태를 변경하기 전에 실패할 수 있는 코드들을 배치하는 방법으로, 계산 전에는 인수의 유효성을 검사할 수 없는 경우 2번 방식과 같이 사용할 수 있는 기법이다.
예를 들어, TreeMap의 경우 원소들을 어떤 기준(Ex: Comparable)으로 정렬을 하는데 예를 들어, 다른 타입의 값을 인수로 전달했을 때 저장부터 한 뒤 정렬을 해버리면 정렬을 실패했더라도 상태는 이미 저장되어 있기에 실패 원자성을 획득할 수 없다. 그렇기에 원소를 추가하기 전 TreeMap의 기준에 맞게 비교할 수 있는 타입으로 변경하는 로직을 우선하면, TreeMap의 내부 값이 변경되기 전에 ClassCastException 예외가 발생해서 실패 원자성을 가질 수 있을 것이다.
4. 객체의 임시 복사본에서 작업을 수행하고 원 객체와 교체하는 방식
말 그대로 객체의 상태를 바꾸는 작업을 임시 자료구조에 저장해 수행하고, 수행이 완료되면 결과를 원래 객체와 교체하도록 하는 것으로, 만약 수행이 실패할지라도 원래 객체의 자료구조는 변하지 않았기에 실패 원자성을 가질 수 있다.
4. 실패를 가로채는 복구 코드
작업 도중 발생하는 실패를 가로채 복구 코드를 작성하여 작업 전 상태로 되돌리는 방법으로, 자주 사용되는 방법은 아니다. 주로 디스크 기반의 내구성(durability)을 보장해야 하는 자료구조에서 쓰인다.
항상 실패 원자성을 달성할수는 없다.
멀티 스레드 환경에서 객체를 동시에 수정하려 하면 객체의 일관성이 깨질 수 있는데(ConcurrentModificationException) 이런 예외를 잡아냈다고 해서 쓸 수 있는 상태라 하긴 힘들다.
또한, Error는 복구할 수조차 없기에 AssertionError에 대해서는 실패 원자적으로 만들 필요가 없다.
그리고, 실패 원자적으로 만들기 위한 비용 및 복잡도가 아주 큰 경우 트레이드 오프를 계산해 결정할 필요가 있다. 다만, 이런 경우 실패할 경우 객체의 상태를 API 설명에 명시해야 한다.
77. 예외를 무시하지 말라
개요
API 설계자가 메서드 선언에 예외를 명시했지만, 우리는 생각보다 많은 예외를 무시하고는 한다.
try {
...
} catch (SomeException e) {}
Java
복사
예외를 무시하는 코드
위와같이 catch 블록으로 예외를 잡아서 아무 동작도 안하고 넘겨버려서 예외를 넘겨버리면, 굳이 비용낭비되게 예외를 발생시킬 이유가 없어진다. 책에서는 불난집의 화재 경보를 조치없이 그냥 꺼버려서 아무도 화재가 발생한 것을 모르게 하는것에 비유한다. 즉 운이 좋아 아무 일도 없이 끝난다면 다행이지만, 이러한 상황이 번지면 꺼져버린 화재 경보기로 인해 뒤늦게 알게 된 나머지에게는 참사가 생길 수 있다. 그렇기에 예외를 무시하지 말고 제대로 처리할 필요가 있다.
그럼에도 무시해야 할 예외도 있다.
FileInputStream 같은 경우 입력 전용 스트림으로 파일의 상태를 변경하지 않기에 복구 할 것도 없고, 스트림을 닫는다는 의미는 필요한 정보를 다 읽었다는 의미이기에 남은 작업을 중단하지 않아도 된다. 이런 경우에는 예외를 무시해도 된다. 하지만, 동일한 예외가 반복된다면 조사가 필요할 수 있기에 catch 블록에 해당 사항에 대해 주석을 남기고 예외 변수의 이름도 ignored로 바꿔놓자.
Future<Integer> f = exec.submit(planarMap::chromaticNumber);
int numColors = 4; // 기본값. 어떤 지도라도 이 값이면 충분하다.
try {
numColors = f.get(1L, TimeUnit.SECONDS);
} catch (TimeoutException | ExecutionException ignored ) {
//기본 값을 사용한다. (색상 수를 최소화하면 좋지만, 필수는 아니다.)
}
Java
복사
정리
•
비검사, 검사 예외 모두 동일하다. 예외를 무시하지 말자.
•
예외는 발생지점에서 가까운 곳에서 잡아서 처리할수록 원인 파악이 쉬워진다.
•
하물며, 바깥으로 전파되도록만 해도 디버깅 정보를 남기고 프로그램이 중단되어, 해결할 수 있다.

