
목차
57. 지역변수의 범위를 최소화하라.
클린코드의 첫 걸음 최소화
아이템 15에서 소개했던 내용 클래스와 멤버의 접근 권한을 최소화하라를 다시 연상시킬 수 있는 내용이다. 아이템 57에서 소개하고자 하는 내용은 지역 변수의 유효범위도 최소화하여 코드의 가독성과 유지보수성을 올려서 오류 가능성을 낮추자는 것이다.
사실, 대부분 더 좋은 코드를 짜기 위해 공유되는 학습 자료나 책들, 강의들을 보면 공통적으로 나오는 얘기들도 결국 최소화하는 것이다. 접근범위를 최소화하고, 기능을 최소화하고, 책임도 최소화하면서 각각의 클래스, 메서드, 필드까지 각각이 최소한의 책임과 최소한의 접근 범위를 가지고 맡은 일만 다하도록함으로써 변경이나 추가, 삭제시 그 영향을 최소화하는데 있다.
지역변수는 언제 선언할까?
책에서는 다음과 같이 지역 변수의 범위를 줄이는 방법을 소개한다.

가장 처음 쓰일 때 선언한다.
우리가 흔히 사용하던 메서드의 최상단에 변수 선언을 하고 사용하는게 아닌 해당 변수를 사용하기 직전에 선언하라는 말인데, 조금 의아한 생각이 들 수 있다. 왜냐하면 책 클린코드의 챕터5 형식 맞추기에서는 유사성을 가진 군집으로 모아놓기를 바란다. 즉, 개념적 유사성을 가진 군집으로 묶기를 바란다고 생각할 수 있는데, 다시 생각해보면 여기서 말하는 개념적 유사성은 변수나 로직이라는 그룹이 아닌 행위에 집중해야 하지 않나 싶다. 다음 코드를 보자. 전형적으로 변수 선언은 최상단에 작성하고 로직을 작성하는 방식의 요금 계산 메서드다.
public void appendTax(List<Fee> fees, List<Integer> tax) {
Iterator<Fee> it = fees.iterator();
Iterator<Integer> taxIt = tax.iterator();
List<Integer> taxPercents = null;
List<Integer> resultFees = null;
while(it.hasNext()){
//logic...
}
//lgoic...
while(taxIt.hasNext()){
taxPercents.add(calculateTax(taxIt.next()));
}
return resultFees;
}
Java
복사
변수선언을 최상단에 모아놓는 방식의 메서드 작성방식
이 코드를 책에서 말하는 가장 처음 쓰일 때 선언하도록 리팩토링을 수행하면 어떻게 될까?
Refactoring 1. 변수 선언 위치 변경
public void appendTax(List<Fee> fees, List<Integer> tax) {
Iterator<Fee> it = fees.iterator();
while(it.hasNext()){
//logic...
}
//lgoic...
Iterator<Integer> taxIt = tax.iterator();
List<Integer> taxPercents = new ArrayList();
while(taxIt.hasNext()){
taxPercents.add(calculateTax(taxIt.next()));
}
List<Integer> resultFees = new ArrayList();
//logic..
return fees.stream()
.reduce(Fee::sum)
.orElseThrow(RuntimeException::new);;
}
Java
복사
변수의 선언 위치를 최상단이 아닌 실제로 사용되는 위치 직전으로 변경해줬다. 이 리팩터링은 어떤 이점을 가질 수 있을까?
실제로 사용하는 위치에 가깝게 위치하기에 타입과 초기값에 대해 혼동하지 않을 수 있다. 그렇기에 메서드의 로직에서 사용되는 변수들이 어떤 값이였고 어떤 타입이였는지를 알기 위해 코드를 위 아래로 계속 스크롤을 움직일 필요가 없어졌다. 또한 지역변수를 선언과 동시에 초기화해준것도 알 수 있다. 초기화에 필요한 정보가 충분치 않다면 충분해질 때까지 선언을 미뤄야 한다.
주의: try-catch 는 즉시 초기화 규칙에서 예외다.try-catch문은 변수를 초기화는 표현식에서 예외가 발생할 수 있다면, try 블록 안에서 초기화를 해줘야 하는데, 이 변수가 try블록 밖에서도 사용해야 한다면, 변수 선언의 위치와 초기화의 시점이 다를 수 있다.
Example
Refactoring 2. while보단 for문(or for-each)
변수의 위치를 사용하기 전으로 옮겼지만, 이 지역변수의 생존범위는 아직 선언된 위치로부터 블럭이 끝날때까지 전부이다. 현재는 while문을 사용하고, 반복 조건을 지역변수를 이용하고 있는데, for문 혹은 for-each문을 사용하면, 이러한 지역변수의 범위를 for 키워드와 몸체 사이의 괄호 안으로 더 좁힐 수 있다. 그렇기에 이 지역변수가 반복문이 종료되고도 계속 사용되야하는게 아니라면 while문 보다는 for문을 사용하는게 낫다.
public Fee appendTax(List<Fee> fees, List<Integer> taxs) {
for(Fee fee : fees){
//logic...
}
//lgoic...
List<Integer> taxPercents = new ArrayList();
for(Inteer tp : taxs){
taxPercents.add(calculateTax(tp));
}
List<Integer> resultFees = new ArrayList();
//logic..
return fees.stream()
.reduce(Fee::sum)
.orElseThrow(RuntimeException::new); return fees.stream()
.reduce(Fee::sum)
.orElseThrow(RuntimeException::new);
}
Java
복사
Refactoring 3. 기능 분리
몇 가지 지역변수를 for문 안으로 넣어서 유효범위를 더 줄였지만, 아직도 taxPercent나 resultFees등은 넓은 범위를 가지고 있다. 이만해도 충분할 것 같지만, 여기서 의미있는 행위들은 모두 메서드로 분리해서 범위를 더 좁힐 수 있다.
public Fee appendTax(List<Fee> fees, List<Integer> taxs) {
handleFees(fees);
for(Integer taxPercent : calculateTaxs(taxs)){
applyTax(fees, taxPercent);
}
//logic..
return fees.stream()
.reduce(Fee::sum)
.orElseThrow(RuntimeException::new);
}
Java
복사
정리
•
지역 변수의 유효범위를 최소화 하자.
•
지역 변수의 선언 및 초기화 시점은 사용하기 직전이 좋다.
◦
거리가 멀수록 코드트레이싱에 드는 비용이 커진다.
•
while문 보다는 지역 변수의 범위를 for 키워드와 블럭 안으로 제한하는 for문이 좋다.
•
메서드를 작게 유지하고 한 가지 기능에 집중하도록 만드는게 좋다.
58. 전통적인 for문보다 for-each문을 사용하라.
다음은 for문을 이용하여 List를 순회하는 방법이다.
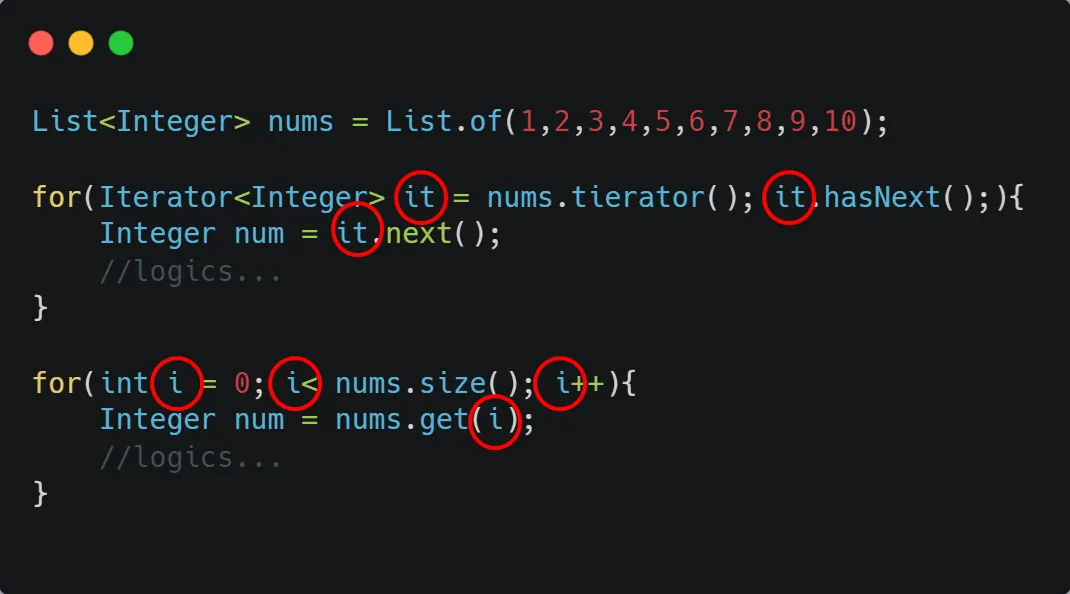
등장하는 반복자, 인덱스가 상당하다.
두 for문 다 전통적인 for문 사용법으로 while문보다는 지역변수의 유효범위를 제한하기에 좋다.
하지만, 가장 좋은 방법은 아니다. 반복자(it.next())나 인덱스(i)는 모두 내가 작업하길 원하는 자원을 사용하기 위한 도구인데, 핵심적인 내용도 아니지만 등장횟수는 잦아서 오류를 일으킬 확률이 높다.
그럼 이런 반복자나 인덱스를 줄이기 위해서는 무슨 방법이 있을까?
재귀를 사용한다는 선택지도 있을 수 있지만, 좀 더 간단하게 for-each(enhanced for statement) 를 떠올려 볼 수 있을 것 같다.
List<Integer> nums = List.of(1,2,3,4,5,6,7,8,9,10);
for(Integer num : nums) {
//logics...
}
Java
복사
for-each 사용 코드
이제 반복자나 인덱스 그 어느것도 노출되지 않고 있고 있다. 개발자가 잘못 기입하는 문제는 걱정하지 않아도 되고 nums안의 원소num 만 신경쓰면 된다.
언제나 for-each를 쓸 수 있는건 아니다.
하지만, 이런 for-each문도 늘 좋기만 한 것은 아니다. 분명 for-each문을 사용할 수 없는 상황도 3가지나 존재한다.
1. 파괴적인 필터링(destructive filtering)
List<Integer> nums = new ArrayList<>(List.of(1,2,3,4,5,6,7,8,9,10));
for(Integer num : nums) {
nums.remove(num);
}
Java
복사
위 코드를 동작시켜본다면 ConcurrentModificationException 예외가 발생할 것이다.
컬렉션을 순회하면서 동시에 제거하려고 하기에 생기는 문제다.
참고: Collection.removeIfJava 8 부터는 Collection에는 removeIf라는 메서드를 제공하는데, 이를 이용하면 명시적으로 순회하지 않고도 원소들을 제거할 수 있다.
//홀수는 삭제한다.
nums.removeIf(n -> n % 2 == 1);
Java
복사
2. 변형(transforming)
리스트나 배열을 순회할 때 특정 위치의 원소가 변경되야 하는 경우가 있다. 이럴 경우 인덱스를 사용해야 한다.
3. 병렬 반복(parallel iteration)
: 여러 컬렉션을 병렬로 순회해야 하는 경우 각각의 반복자와 인덱스를 사용해 엄격하고 명시적으로 제어해야 한다.
for-each를 사용하고싶다면 Iterable을 구현하자.
Collection 프레임워크에서 제공하는 List, Set, Map이 아니더라도 Iterable인터페이스를 구현한다면 무엇이든 for-each문을 사용해 순회할 수 있다.
public interface Iterable<T> {
Iterator<T> iterator();
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
Iterator var2 = this.iterator();
while(var2.hasNext()) {
T t = var2.next();
action.accept(t);
}
}
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(this.iterator(), 0);
}
}
Java
복사
forEach, spliterator는 default method이니 상관없지만, 적절하게 Iterator()메서드만 재정의를 해준다면, 내가 만든 객체에서도 for-each를 사용할 수 있다.
59. 라이브러리를 익히고 사용하라
책임을 분리하여 각각의 결합도를 낮추고 응집도를 높혀야 한다는 것은, 프로그램 소스 뿐 아니라 그 외에 일상생활에도 적용할 수 있다.
갈수록 기술의 고도화가 이루어지고 있는 상황에서 한 명의 개발자가 여러 분야에 대해 모두 통달하기란 쉽지 않다.
솔루션을 개발할 때 솔루션에 필요한 모든 기능에 대해 뼈대부터 직접 개발하려면 드는 비용도 엄청나지만, 하나하나의 기능에 대한 신뢰성과 안전성까지 보증하기 위해서는 각각의 기능마저도 솔루션화 되고 관리가 되어야 한다.
이런 경우, 이미 기존에 전문가가 만든 표준라이브러리를 사용하도록 하자.
표준 라이브러리를 사용하면 그 코드를 작성한 전문가의 지식과 이 라이브러리를 사용해본 여러 개발자들의 경험을 활용할 수 있다.
그리고 이렇게 라이브러리를 사용할 경우 내가 따로 신경을 쓰지 않아도 성능이 개선될 수 있다는 이점이 있다. 해당 라이브러리를 제공하는 제작자들은 계속해서 라이브러리의 성능을 개선 할 것이고, 이런 라이브러리를 사용하는 우리의 솔루션은 가만히 둬도 성능이 향상될 것이다.
라이브러리를 사용하면 성능만 개선되는것이 아니라 기능이 추가되고 호환성이 커질수도 있다..
라이브러리의 부족한 기능이 이슈가 된다면 이는 논의 후 다음 릴리즈에서도 추가될 수 있다.
60. 정확한 답이 필요하다면 float와 double은 피하라
근사치
float와 double 타입은 이진 부동소수점 연산에 사용되며 넓은 범위의 수를 빠르게 정밀한 근사치로 계산하도록 설게되었다. 즉, 정확한 결과가 필요할 때는 사용하지 안 된다.
이 두 타입은 0.1 혹은 10의 음의 거듭 제곱 수를 표현할 수 없다.
System.out.println(1.03 - 0.42); // 0.61000000000000001
Java
복사
우리가 예상한 0.61이 아닌 0.61000000000000001이 출력된다.
반올림도 해결책이 되지 않는다.
그럼 반올림으로 소숫점을 제한하면 되지 않을까? 생각하지만, 이래도 틀릴 수 있다.
public static void main(String[] args) {
double funds = 1.00;
int itemBought = 0;
for(double price = 0.10; funds >= price; price += 0.10) {
funds -= price;
itemBought++;
}
System.out.println(itemBought + "개 구입");
System.out.println("잔돈(달러):" + funds);
}
Java
복사
•
실행 결과
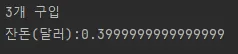
생각해보면 1달러로 10센트, 20센트, 30센트, 40센트 이렇게 4개의 사탕을 구입할 수 있어야 한다고 생각하지만, 결과는 3개만 구입 가능하고 잔돈으로 0.3999999999999999 달러가 남은 상황이다.
정확한 계산이 필요하다면, BigDecimal, int, long
public static void main(String[] args) {
final BigDecimal TEN_CENTS = new BigDecimal(".10");
BigDecimal funds = new BigDecimal("1.00");
int itemBought = 0;
for (BigDecimal price = TEN_CENTS;
funds.compareTo(price) >= 0;
price = price.add(TEN_CENTS)) {
funds = funds.subtract(price);
itemBought++;
}
System.out.println(itemBought + "개 구입");
System.out.println("잔돈(달러):" + funds);
}
Java
복사
•
실행 결과
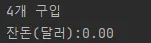
이제 정상적인 결과가 나온다. 하지만, BigDecimal을 사용하는 방식은 불편하고 느리다.
이런 경우에는 primitive type인 int나 long을 쓰는 것도 방법이 될 수 있다.
다만, 이 경우 값의 크기가 제한되고 소수점을 직접 관리해야 한다.
public static void main(String[] args) {
int itemBought = 0;
int funds = 100;
for (int price = 0; funds >= price; price += 10) {
funds -= price;
itemBought++;
}
System.out.println(itemBought + "개 구입");
System.out.println("잔돈(달러):" + funds);
}
Java
복사
정리
1.
정확한 결과가 필요한 경우 float이나 double 타입을 피하라.
2.
사용의 불편함과 성능을 고려하지 않아도 된다면 BigDecimal을 사용하자.
3.
성능이 중요하고 소수점 관리를 직접 할 수 있다면 int나 long을 사용하라.
a.
숫자를 9자리 십진수로 표현이 가능하다면 int
b.
숫자를 18자리 십진수로 표현이 가능하다면 long
c.
그 외에는 BigDecimal
61. 박싱된 기본 타입보다는 기본 타입을 사용하라
auto라는 이름의 성능 저하 원인
int, double, boolean과 같은 타입은 자바에서 사용하는 대표적인 기본타입이다.
그리고 제네릭등의 이유로 이에 대응하는 박싱 타입인 Integer, Double, Boolean 타입이 지원된다.
자바에서는 자동으로 이 기본 타입과 박싱된 기본타입 두 타입을 자동으로 박싱과 언박싱을 제공해준다. 그래서 그냥 똑같이 취급하고 사용을 하더라도 크게 문제 없이 프로그램을 구현할 수 있다.
하지만, 둘은 분명히 차이점이 있고, 어떤 타입을 사용하는지 고려하는게 중요하다.
그렇기에 무분별한 박싱/언박싱은 프로그램 성능 저하의 원인이 된다.
차이점
•
기본 타입은 값만 가지고 있지만, 박싱된 기본 타입은 식별성(itentity)이란 속성을 추가로 갖는다.
int a = 1;
int b = 1;
a == b; // always true
Java
복사
Integer a = new Integer(1);
Integer b = new Integer(1);
System.out.println(a == b); // false
System.out.println(a.equals(b)); // true
Java
복사
그렇기에, 같은 값을 가지고 있음에도 동등성 비교에서 다르다고 평가될 수 있다.
•
기본 타입은 언제나 유효한 값을 가지지만, 박싱된 기본 타입은 유효하지 않은 값(null) 을 가질 수 있다.
public class Main {
static Integer i;
public static void main(String[] args) {
if (i == 42) { // NPE 발생
System.out.println("beIncredible");
}
System.out.println("etc");
}
}
Java
복사
Integer 타입인 i가 null이기에 NPE가 발생하는 코드
•
기본 타입이 박싱된 기본 타입보다 시간과 메모리 사용면에서 더 효율적이다.
public class Main {
public static void main(String[] args) {
LocalDateTime time = LocalDateTime.now();
System.out.println("start: "+ time);
Long sum = 0L;
for (long i = 0; i < Integer.MAX_VALUE; i++) {
sum += i;
}
System.out.println(sum);
System.out.println("end: "+ time);
System.out.println("duration: "+ Duration.between(time, LocalDateTime.now()));
}
}
Java
복사
CPU i7-9700k 기준으로 약 5초 이상이 소요된다.
◦
참고로 sum의 타입을 long으로만 바꿔줘도 1초 이하로 소요시간이 감소한다.
그럼 박싱된 기본타입의 사용처는?
컬렉션이나 제네릭에서 사용하는 타입 매개변수는 기본형이 사용될 수 없다. 이 경우 박싱된 기본타입을 써야만 한다.
ThreadLocal<int> threadMap; // 사용할 수 없다.
ThreadLocal<Integer> threadMap; // 사용할 수 있다.
Java
복사
62. 다른 타입이 적절하다면 문자열 사용을 피하라.
문자열(String)은 텍스트를 표현하도록 설계되었다. 그리고 이 문자열을 다루는 기능들도 자바에서 충분하게 제공해주기 때문에, 문자열을 사용하지 말아야 하는 경우에도 문자열을 사용하는 경우가 많다. 다음 코드를 보자.
public void printFruit(String fruitName) {
if(fruitName.equals("apple")) {
System.out.println("사과");
} else if(fruitName.equals("grape")) {
System.out.println("포도");
}
}
Java
복사
매개변수로 받은 문자열을 검사해서 과일 이름을 한글로 출력하는 메서드다.
이전 아이템에서도 얘기했지만, 이런 경우 오타로 인한 문제가 발생하기 쉽고, 해당 타입을 비교하는 곳이 많아질수록 변경에 취약해진다. 그래서 이런 경우 열거타입을 쓰는게 훨씬 낫다.
이 뿐만이 아니라, 수치형 데이터, 논리 데이터 역시 문자열보다는 적절한 해당 타입으로 사용하는게 낫다.
그리고 문자열은 혼합타입을 대신하기에도 적절치 않다.
String compoundKey = className + "#" + i.next();
Java
복사
이렇게 구분자(#)를 가지고 타입을 혼합하는 경우, 이 구분자가 유의미해야 하는데, 혼합되는 개별 요소에 구분자가 포함될 가능성도 있기 때문에 까다롭다. 그리고 매번 문자열을 파싱하는 것도 번거롭고 에러가 생기기 쉽다. 이런 경우 전용 클래스를 새로 만드는 편이 낫다.
public class ClientInfo {
...
private IpPort ipPort;
private static class IpPort {
private final int ip;
private final int port;
}
}
Java
복사
혼합 정보를 다루는 전용 클래스(IpPort)를 내부 클래스로 만들어서 관리한다.
정리
문자열은 얼핏 간결하고 쉽기에 선택하고 싶을 수 있지만, 잘 못 사용할 경우 성능적으로나 비용적으로나 문제가 발생하기 쉽다.
기본 타입(Primitive Type), 열거 타입(Enum Type), 혼합 타입(Compound Type) 의 경우 문자열로 해결하려는 경우가 있는데, 최대한 그에 맞는 적절한 타입으로 사용하도록 하자.
63. 문자열 연결은 느리니 주의하라.
문자열은 불변이다.
문자열(String) 타입은 불변이다. 그렇기에 문자열 연결은 단순히 문자열이 합쳐지는게 아닌 합칠 문자열의 내용을 모두 복사해서 새로운 문자열 객체를 만드는 것이다.
즉, 문자열 연결 연산자(+)를 사용하면 문자열 n개를 잇기 위한 시간은 에 비례한다.
public static void main(String[] args) {
LocalDateTime time = LocalDateTime.now();
System.out.println("start: "+ time);
String str = "";
for (int i = 0; i < 100000; i++) {
str += i;
}
System.out.println("end: "+ time);
System.out.println("duration: "+ Duration.between(time, LocalDateTime.now()));
}
Java
복사
0부터 10만개의 숫자를 문자열 연결하는 코드
•
실행 결과
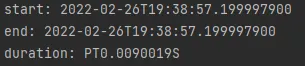
StringBuilder를 쓰자
성능을 포기하고싶지 않다면, StringBuilder를 이용해 문자열 연결을 하면 성능 개선을 할 수 있다.
public static void main(String[] args) {
StringBuilder sb = new StringBuilder("");
LocalDateTime time = LocalDateTime.now();
System.out.println("start: "+ time);
for (int i = 0; i < 100000; i++) {
sb.append(i);
}
System.out.println("end: "+ time);
System.out.println("duration: "+ Duration.between(time, LocalDateTime.now()));
}
Java
복사
•
실행 결과
64. 객체는 인터페이스를 사용해 참조하라.
유연성
아직 언어에 익숙하지 않은 개발자들에게서 다음과 같은 코드를 많이 볼 수 있다.
ArrayList<Integer> list = new ArrayList<>();
HashSet<Integer> sets = new HashSet<>();
Java
복사
잘 동작하고 에러가 나는 코드도 아니다. 하지만, 위와 같은 코드는 유연성을 잃어버린 코드라고 할 수 있다.
좀 더 쉽게 예를 들어보자. 스코빌 지수를 차례대로 저장한 큐를 사용한 자료구조가 있다고 하자.
LinkedList<Integer> scovilleQueue = new LinkedList<>();
Java
복사
위와 같이 scovilleQueue 이라는 컬렉션을 이용해 스코빌 지수를 저장을 해서 사용을 했는데, 어느 순간 기획이 변경되어 이 scovilleQueue 의 값이 정렬되서 보관되야한다고 하면 어떻게 해야할까?
Collections.sort(scovilleQueue) 와 같은 유틸리티 클래스를 활용할 수도 있다. 하지만, 자료구조중에서는 넣는 순간 정렬되서 들어가게끔 하는 PriorityQueue 라는 자료구조가 있다. 그래서 이 자료구조를 사용하는게 더 나은데, 그러기 위해서는 생성하는 곳 뿐 아니라 타입 선언하는 곳까지 모두 변경해야하고 이로 인해 신경써야 하는 곳도 많아질 것이다.
반면, 타입선언을 인터페이스를 사용해 참조하면 다음과 같이 작성할 수 있다.
Queue<Integer> scovilleQueue = new PriorityQueue<>();
Java
복사
Queue라는 상위 인터페이스가 제공하는 API는 이를 구현하는 하위 구현체들은 모두 재정의해서 제공하기 때문에 구현체를 PriorityQueue 가 아니라 다른 자료구조로 바꾸더라도 문제없이 동작할 것이다. 즉, 참조 타입이 추상적일수록 유연한 프로그램을 작성할 수 있는 것이다.
예외 상황
물론, 적절한 인터페이스가 없는 상황도 있다. 이런 경우 클래스를 참조해야 한다.
1. 값 클래스
String, BigInteger같은 값 클래스는 여러가지로 확장될 일이 없기에 인터페이스가 따로 없고, 이런 값 클래스의 경우 인터페이스가 아니더라도 그대로 사용해도 상관 없다.
2. 클래스 기반의 프레임워크로 제공되는 객체
java.io 패키지에서 제공되는 여러 클래스(ex: InputStream, OutputStream)는 클래스 기반이기에 인터페이스가 따로 없다. 하지만, 이 경우에도 최대한 구현체보다는 추상 클래스(abstract)를 사용해 참조하도록 하자.
3. 특별한 메서드를 제공하는 클래스
위에서 언급한 PriorityQueue도 Queue를 구현하는 구현체지만 Queue 인터페이스에는 없는 comparator라는 메서드를 제공한다. 이렇게 상위 인터페이스에서 제공하지 않는 API를 사용해야 하는 경우에는 클래스 타입을 사용해야 한다. 하지만, 이렇게 명확하게 특정 메서드를 써야 하는 경우가 아니라면 이런 개별 메서드가 있는 구현체라도 인터페이스를 참조하도록 해야 한다.
정리
최대한 인터페이스로 참조해서 프로그램의 유연성을 높히도록 하자.
적절한 인터페이스가 없다면, 클래스의 계층구조에서 가장 추상적인 클래스를 타입으로 사용하자.
65. 리플렉션보다는 인터페이스를 사용하라.
Previous
리플렉션에 대해 잘 모른다면 위 포스팅을 참고하도록 하자.
리플렉션의 단점
•
컴파일 타입 검사가 주는 이점을 누릴 수 없다.
: 리플렉션은 임의의 클래스에 접근해서 이용할 수 있게 해주는데, 존재하지 않거나 접근할 수 없는 메서드를 호출하려하면 런타임 오류가 발생한다. 이는 예외도 마찮가지다.
•
코드가 장황해지고 주절거린다.
public class ContainerService {
public static <T> T getObject(Class<T> classType){
T instance = createInstance(classType);
Arrays.stream(classType.getDeclaredFields()).forEach(f->{
if(f.getAnnotation(Inject.class) != null){
Object fieldInstance = createInstance(f.getType());
f.setAccessible(true);
try {
f.set(instance, fieldInstance);
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
}
}
});
return instance;
}
private static <T> T createInstance(Class<T> classType){
try {
return classType.getConstructor(null).newInstance();
} catch (InstantiationException | IllegalAccessException | InvocationTargetException | NoSuchMethodException e) {
throw new RuntimeException(e);
}
}
}
Java
복사
리플렉션을 사용하는 ContainerService 클래스. 몹시 장황하고 indent도 높다.
•
성능이 떨어진다.
: 일반적인 메서드 호출보다 훨씬 속도가 느리다.
public class Main {
static class Fruit {
String name;
Fruit(String name) {
this.name = name;
}
@Override
public String toString() {
return name;
}
}
public static void main(String[] args) {
directUseClass();
reflectionUseClass();
}
private static void directUseClass() {
LocalDateTime time = LocalDateTime.now();
System.out.println("start: "+ time);
for (int i = 0; i < 1000000; i++) {
Fruit apple = new Fruit("apple" + i);
apple.toString();
}
System.out.println("end: "+ time);
System.out.println("duration: "+ Duration.between(time, LocalDateTime.now()));
}
private static void reflectionUseClass(){
try{
LocalDateTime time = LocalDateTime.now();
System.out.println("Reflection logic start: "+ time);
for (int i = 0; i < 1000000; i++) {
Class<?> fruitClass = Fruit.class;
Constructor<?> constructor = fruitClass.getDeclaredConstructor(String.class);
Object apple = constructor.newInstance("appleReflection" + i);
Method method = fruitClass.getDeclaredMethod("toString");
method.invoke(apple);
}
System.out.println("Reflection logic end: "+ time);
System.out.println("duration: "+ Duration.between(time, LocalDateTime.now()));
}catch(Exception e){
e.printStackTrace();
}
}
}
Java
복사
◦
실행결과
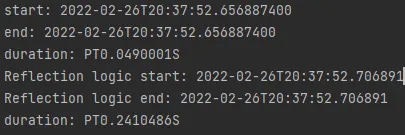
리플렉션이 5배가량 더 느린걸 확인할 수 있다.
66. 네이티브 메서드는 신중히 사용하라.
자바 네이티브 메서드(Java Native Interface, JNI)
: 자바 프로그램에서 네이티브 메서드를 호출하는 기술로 네이티브 메서드는 C나 C++과 같은 네이티브 프로그래밍 언어로 작성한 메서드를 말한다.
어디에 사용할까?
1.
레지스트리같은 플랫폼 특화 기능 사용
2.
네이티브 코드로 작성된 기존 라이브러리 사용
3.
성능 개선을 목적으로 성능에 결정적인 영향을 주는 영역만 따로 네이티브 언어로 작성.
줄어드는 사용처
위와같은 이유들로 네이티브 메서드를 사용하고는 했지만, 자바의 버전이 올라갈수록 자바에서도 API를 제공해서 네이티브 메서드를 사용할 일이 줄어들고는 있다.
또한, 성능 개선을 목적으로 네이티브 메서드를 사용하는것은 대체로 권장되지 않는다.
대체로 자바 자체가 성능개선이 되면서 네이티브 메서드까지 사용하지 않아도 되었기 때문이다.
네이티브 메서드의 단점
1.
네이티브 메서드가 안전하지 않기에 네이티브 메서드를 사용하는 애플리케이션도 메모리 훼손 오류로부터 안전하지 않다.
2.
이식성도 낮다.
3.
속도가 더 느려질 가능성도 있다.
4.
가비지 컬렉터에서 네이티브 메모리는 자동 회수하지 못하고 추적할 수도 없다.
5.
자바 코드와 네이티브 코드의 경계를 이동할 때마다 비용이 추가된다.
6.
자바 코드와 네이티브 코드를 연결하는 접착 코드(glue code)를 작성하는데 비용이 들고 가독성도 떨어진다.
개인적인 사용처
•
자바가 아닌 파이썬에서 빅데이터를 다루기위한 DB 접속 라이브러리를 C++로 작성된 네이티브 코드로 작성된 라이브러리로 튜닝
읽어보면 좋은 글
네이티브 코드는 또 다른 말로는 Unmanaged Language라고도 하는데, 이에 대해 알아보면 좋다.

67. 최적화는 신중히 하라.
(맹목적인 어리석음을 포함해) 그 어떤 핑계보다 효율성이라는 이름 아래 행해진 컴퓨팅 죄악이 더 많다.(심지어 더 효율적이지도 않다.)
- 윌리엄 울프(Wulf72)
(전체의 97% 정도인) 자그마한 효율성은 모두 잊자. 섣부른 최적화가 만악의 근원.
- 도널드 크루스(Knuth74)
최적화를 할 때 두 가지 규칙을 따르라.
첫 번째, 하지 마라.
두 번째, (전문가 한정) 아직 하지 마라. 완전히 명백하고 최적화되지 않은 해법을 찾을 때까진 하지 마라.
- M. A. 잭슨(Jacson75)
빠른 프로그램이 아닌 좋은 프로그램을 작성하라.
위 격언들은 자바가 탄생하기 20년도 전에 나온 것이다. 즉, 이전부터 최적화라는 단어는 유혹적이지만, 대체로 배드엔딩뿐인 단어다. 얼마 하지 않는 성능을 올리기 위해 구조를 희생해버리면 안된다.
좋은 프로그램은 정보 은닉 원칙(캡슐화)을 따르기에 각각의 모듈이 독립적으로 설계되며, 시스템의 나머지 부분에 영향을 주지 않고도 각 요소를 다시 설계할 수 있다.
무엇보다, 구현의 문제는 고칠 수 있지만, 설계에 결함이 생기면 시스템 전체를 수정해야 하기에 비용이 크다. 그렇기에 설계 단계에서 성능을 고려해야 한다. 그렇기에 다음 내용을 고려해야 한다.
1. 성능을 제한하는 설계를 피하라.
완성한 뒤 가장 변경하기 어려운 부분이 컴포넌트끼리, 혹은 외부 시스템과의 소통 방식이다.
예로 API, 네트워크 프로토콜, 영구 저장용 데이터 포맷 등이 대표적이다.
이런 요소들은 일단 완성이 된 후에는 시간이 흐를수록 변경하기 어려워지고, 시스템의 성능을 제한하게 된다.
2. API를 설계할 때 성능에 주는 영향을 고려하라.
이전 아이템들에서도 소개한 여러 방식들을 고려해서 성능을 고민해볼 필요가 있다.
•
•
•
3. 최적화 시도 전후로 성능을 측정하라.
그럼에도 불구하고 최적화를 진행해봤다면, 시도 전 후로 성능을 측정할 필요가 있다.
대부분 시도한 최적화 기법이 성능을 눈에 띄게 높이지 못하는 경우가 많다. 그 이유는 개발자가 프로그램에서 어디에 시간이 최대 소요되는지 추측하기 어렵기 때문이다.
이런 경우 프로파일링 도구(profiling tool) 를 이용할 수 있다. 이런 도구는 개별 메서드의 소비 시간과 호출 횟수 같은 런타임 정보를 제공한다. 일종의 금속탐지기 역할을 한다고 할 수 있다.
정리
좋은 프로그램을 작성하면 성능은 따라오기 마련이다.
설계 시점에서 API, 네트워크 프로토콜, 영구 저장용 데이터 포맷을 설계할 때 성능을 고민하자.
구현이 완료된 다음에는 ‘느린 경우에만’ 프로파일러를 사용해 문제를 찾아 최적화를 수행하자.
그리고 최적화 뒤에는 꼭 성능을 측정해서 올바른 최적화인지 판단할 필요가 있다.
68. 일반적으로 통용되는 명명 규칙을 따르라.
관례적인 자바의 명명규칙
•
자바 플랫폼은 명명규칙이 대부분 자바 언어 명세에 기술되어 있다.
◦
이 규칙을 어기면 API는 사용이 어렵고 유지보수가 힘들다.
패키지
•
패키지와 모듈 이름은 각 요소를 점(.)으로 구분해 계층적으로 짓는다.
•
요소들은 모두 소문자 알파벳과 (드물게) 숫자로 이뤄진다.
•
외부에서 사용 될 패키지는 조직의 인터넷 도메인 이름을 역순으로 사용한다.
◦
Ex: edu.cmu, com.google, org.eff
•
각 요소는 일반적으로 8자 이하의 짧은 단어로 한다.
◦
utilities 보다는 util
◦
awt처럼 약어를 사용해도 좋다.
•
도메인이 하나의 요소일지라도 기능을 많이 제공하는 경우 계층을 더 나눠도 좋다.
이런 하부의 패키지를 하위 패키지(subpackage)라 부른다.
◦
Ex: java.util.concurrent.atomic
클래스와 인터페이스(열거타입과 애너테이션 포함)
•
이름은 하나 이상의 단어로 이뤄지며, 대문자로 시작한다.
•
여러 단어의 첫 글자를 딴 약자나 널리 통용되는 줄입말(ex: max, min)등을 제외하고는 단어를 줄여 쓰지 않도록 한다.
메서드
•
첫 글자를 소문자로 작성한다.
•
그 외에는 클래스 명명 규칙과 동일하다.
상수 필드 (static final)
•
모두 대문자로 작성하며 단어 사이는 밑줄(_)로 구분한다.
지역 변수
•
지역 변수가 사용되는 범위가 좁기에 유추하기가 쉽기에 약어를 사용해도 좋다.
•
입력 매개변수는 주석에도 작성되는만큼 좀 더 신경써야 한다.
•
타입 매개변수의 이름은 보통 한 문자로 표현한다.
◦
임의의 타입엔 T
◦
컬렉션 원소의 타입은 E
◦
맵의 키와 값에는 K, V
◦
예외에는 X
◦
메서드의 반환 타입에는 R
◦
그외의 임의 타입 시퀀스엔 T, U, V, or T1, T2, T3
작명법
•
패키지에 대한 규칙은 따로 없다.
•
객체를 생성할 수 있는 클래스(열거 타입 포함)의 이름은 단수 명사나 명사구를 사용한다.
◦
Ex: Thread, PriorityQueue, ChessPiece, ...
•
객체 생성이 불가한 클래스의 이름은 보통 복수형 명사로 짓는다.
◦
Ex: Collectors, Collections, Arrays, ...
•
인터페이스는 클래스와 똑같이 짓거나 able, ible로 끝나는 형용사로 짓는다.
◦
Ex: Runnable, Iterable, Accessible, ...
•
애너테이션은 지배적인 규칙없이 모두 두루 사용된다.
◦
Ex: BindingAnnotation, Inject, ImplementedBy, Singleton, ...
•
메서드는 동작을 수행하는 동사나 (목적어를 포함한) 동사구로 짓는다.
◦
Ex: append, drawImage, ...
•
반환타입이 논리 값(bool)인 메서드라면 보통 is나 has를 접두사로 붙히고 명사나 명사구, 혹은 형용사로 기능하는 아무 단어나 구로 끝나도록 짓는다.
◦
Ex: isDigit, isProbablePrime, isEmpty, isEnabled, hasSiblings, ...
•
반환 타입이 논리값이 아니거나 해당 인스턴스의 속성을 반환하는 메서드는 보통 명사, 명사구, 혹은 get으로 시작하는 동사구로 짓는다.
◦
Ex: size, hashCode, getTime, ...
•
객체의 타입을 바꿔 다른 타입의 객체를 반환하는 메서드의 이름은 보통 toType 형태로 짓는다.
◦
Ex: toArray, toString, ...
•
객체의 내용을 다른 뷰로 보여주는 메서드는 asType 형태로 짓는다.
◦
Ex: asList
•
객체의 값을 기본 타입 값으로 반환하는 메서드의 이름은 보통 typeValue 형태로 짓는다.
◦
Ex: intValue

