
목차
이번 챕터의 목적
•
클래스와 인터페이스를 쓰기 편하고, 견고하며 유연하게 만드는 방법을 알아본다.
15. 클래스와 멤버의 접근 권한을 최소화하라
좋은 설계란?
잘 설계된 컴포넌트와 그렇지 못한 컴포넌트의 가장 큰 차이점은 클래스 내부 데이터와 구현 정보를 외부로부터 얼마나 잘 숨겼고 꼭 필요한 정보들만 공개를 했는가다. 잘 설계된 컴포넌트일수록 내부 구현을 완벽히 숨겨서 구현과 API를 분리한다. 이처럼 구현과 API가 분리되어있다면 사용자 입장에서는 API만 신경쓰면되고 그 결과에만 집중하면된다. 이런개념을 정보 은닉, 혹은 캡슐화라고 한다.
정보 은닉(캡슐화)의 장점
장점은 대부분 컴포넌트를 서로 독립시켜 개발,테스트, 최적화, 적용, 분석, 수정을 개별적으로 할 수 있게 하는것과 연관되있다.
•
시스템 개발 속도를 높힌다.
⇒ 여러 컴포넌트(개발, 테스트, 최적화...)가 개별적으로(병렬로) 개발 가능하기 때문이다.
•
시스템 관리 비용을 낮춘다.
⇒ 각 컴포넌트를 더 빨리 파악하여 디버깅이 가능하고 컴포넌트 교체도 부담이 적기 때문이다.
•
성능 최적화에 도움을 준다.
⇒ 정보 은닉 자체가 성능을 높혀주는 것은아니지만, 완성된 시스템에서 최적화 할 컴포넌트를 정하고 다른 컴포넌트에 영향을 주지 않고 해당 컴포넌트만 최적화 할 수 있기 때문이다.
•
소프트웨어 재사용성을 높힌다.
⇒ 외부에 거의 의존하지 않고 독자적으로 동작이 가능한 컴포넌트는 다른 시스템에서도 바로 적용이 가능하기 때문이다.
•
큰 시스템을 제작하는 난이도를 낮춰준다.
⇒ 시스템이 완성되지 않은 상태에서도 개별 컴포넌트의 동작을 검증할 수 있기 때문이다.
자바의 정보 은닉을 위한 장치
접근 제어 메커니즘을 이용해 클래스, 인터페이스, 멤버의 접근성(접근 허용 범위)를 명시한다.
각 요소의 접근성은 그 요소가 선언된 위치와 접근 제한자(ex: private, protected, public)로 정해진다. 그리고 이런 접근 제한자를 활용하여 정보 은닉을 할 수 있다.
모든 클래스와 멤버의 접근성을 최대한 좁혀라
모든 클래스, 인터페이스, 멤버에 접근성을 최대한 좁히면 해당 데이터를 수정할 수 있는 대상이 줄어든다.
그 말은, 접근성이 낮을수록 자원은 독립적이고, 위/변조의 위험에서 안전해진다는 의미가 된다.
톱레벨 클래스와 인터페이스는 package-private(default), public 을 부여할 수 있다. public으로 할 경우 공개 API가 되며, package-private가 되면 해당 패키지 내에서만 쓸 수 있다.
그러니, 패키지 외부에서 쓸 일이 없다면(공개 API가 아니라면) package-private로 선언하자.
그럼, API가 아닌 내부 구현이기에 수정에서 자유로워진다. 만일 public으로 선언할 경우 공개 API가 되어 영원히 하위 호환을 위해 관리해줘야 하며 수정 변경이 힘들어진다.
public 클래스에서는 멤버의 접근성을 package-private → protected 로 바꾸는 순간 접근 범위가 엄청 넓어진다. public 클래스의 protected 멤버는 공개 API이기에 영원히 지원되야하며 내부 동작 방식을 API 문서에 적어 사용자에게 제공해야 할 수도 있다.
private static 중첩을 이용해보자.
•
package-private 톱레벨 클래스나 인터페이스가 한 클래스에서만 사용된다면 분리 해서 접근성을 높게 해 둘 필요가 없다.
•
private static으로 중첩시키면 바깥 클래스 하나에서만 접근할 수 있다.
•
대표적으로 Map의 Entry가 이에 해당한다.
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
...
static class Node<K,V> implements Map.Entry<K,V> { ... }
}
Java
복사
⇒ Entry 의 구현체는 Map의 구현체 내에서만 사용되기에 innerClass로 구현되있다.
 참고: 접근제어자의 접근 범위
참고: 접근제어자의 접근 범위접근성: public > protected > package-private(default) > private
•
private: 멤버를 선언한 톱레벨 클래스에서만 접근이 가능하다.
•
package-private(default): 멤버가 소속된 패키지 안의 모든 클래스에서 접근할 수 있다. 접근 제한자를 따로 작성해주지 않으면 기본적으로 package-private이다. (단, 인터페이스는 public이 기본이다.)
•
protected: package-private의 접근 범위를 포함하며, 이 멤버를 선언한 클래스의 하위 클래스에서도 접근할 수 있다.
•
public: 모든 곳에서 접근할 수 있다.
멤버 접근성을 좁히지 못하는 제약
상위 클래스의 메서드를 하위 클래스에서 재정의하는 경우 이 메서드의 접근 수준을 상위 클래스보다 좁게 설정할 수 없다. 즉 상위 클래스에서 package-private로 선언된 메서드는 하위 클래스에서는 package-private보다 높은 접근성인 protected, public을 붙힐 수 있고 더 좁은 범위인 private는 사용할 수 없다는 말이다.
이유는, 리스코프 치환 원칙(LSP)(상위 클래스의 인스턴스는 하위 클래스의 인스턴스로 대체해 사용 가능해야 한다.)때문이다. 이 원칙을 어길 경우 컴파일 오류가 발생한다.
만약, 테스트 목적으로 접근성을 높히고 싶다면, package-private까지는 허용 가능하다 패키지 내부에 테스트 클래스 내부에 작성해서 접근할 수 있기 때문이다. 하지만 그 이상으로 높혀서 공개 API가 되서는 안된다.
public 클래스의 인스턴스 필드는 되도록 public이 아니어야 한다.
사실, 모든 인스턴스 필드는 다음과 같은 이유로 되도록 낮은 접근성을 유지하는게 좋다.
•
필드가 가변 객체를 참조하거나, final이 아니면 필드 값을 제한할 수가 없어지며 해당 필드에 대한 모든 것은 불변식을 보장할 수 없게 된다.
•
필드가 수정될 때 막을 수 없기에 public 가변 필드를 갖는 클래스는 일반적으로 스레드 안전하지 않다.
•
final이면서 불변 객체를 참조하더라도 내부 구현을 바꾸지 못하는 문제가 남는다.
여기엔 예외가 하나 있다. 해당 클래스의 추상 개념을 완성하는데 필요한 구성요소로써의 상수라면 public static final필드로 공개해도 좋다. (관례적으로 대문자 알파벳으로 작성하며 구분은 밑줄(_)으로 한다. )
이런 필드는 반드시 기본 타입 값이나 불변 객체를 참조해야 한다.
public class FixDiscountPolicy1000 implements DiscountPolicy{
public static final int DISCOUNT_AMOUNT = 1000;
...
}
Java
복사
⇒ 고정적인 1000원 할인을 하는 할인정책 구현체에서 1000원이라는 금액은 필수적인 구성요소이자 변경의 가능성이 없기 때문에 public static final 필드로 공개한다.
이런 필드(public static final)가 기본 타입이나 불변 객체가 아닌 가변 필드나 가변 객체를 참조할 경우 final이 아닌 필드에 적용되는 단점이 모조리 적용된다. 참조된 객체 자체가 수정될 수 있기에 문제가 크다.
그리고, 길이가 0이 아닌 배열이나 콜렉션들도 모두 변경 가능하니 주의하자. 다음 코드를 보자.
public static final Thing[] VALUES = { ... };
이 배열 필드에는 큰 보안 허점이 존재한다. final이여도 배열 내부의 값들은 얼마든지 수정이 가능하다.
해결책
•
접근제어자를 private로 만들고 public 불변 리스트를 추가하기
private static final Thing[] PRIVATE_VALUES = { ... };
public static final List<Thing> VALUES =
Collections.unmodifiableList(Arrays.asList(PRIVATE_VALUES));
Java
복사
•
배열을 private로 만들고 복사본을 반환하는 public 메서드를 추가하는 방법(방어적 복사)
private static final Thing[] PRIVATE_VALUES = { ... };
public static final Thing[] values() {
return PRIVATE_VALUES.clone();
}
Java
복사
자바 9의 모듈 시스템
자바 9에서는 모듈 시스템이라는 개념이 도입되면서 두 가지 암묵적 접근 수준이 추가되었다.
패키지가 클래스의 묶음이듯, 모듈은 패키지들의 묶음이다.
모듈은 자신에 속하는 패키지 중 공개(export)할 것들을 선언한다. protected나 public 멤버라도 해당 패키지를 공개하지 않았다면 외부에서 접근 할 수 없다. (내부에서는 상관없다.)
하지만, 모듈에 적용되눈 접근 수준은 모듈의 JAR 파일을 자신의 모듈 경로가 아니라 애플리케이션 클래스패스(classpath)에 두면 그 모듈 안의 모든 패키지는 모듈이 없는것처럼 행동하기에 모듈 공개여부와 상관없이 public 클래스가 선언한 모든 public(or protected)멤버를 모듈 밖에서 접근할 수 있게 된다.
이 부분 말고도 모듈을 제대로 사용하려면 할 일이 많다.
•
패키지를 모듈 단위로 묶고, 모듈 선언에 패키지들의 모든 의존성 명시
•
소스 트리 재배치 뒤, 모듈 안으로부터(모듈 시스템을 적용하지 않는) 일반 패키지로의 모든 접근에 조치를 취해야 한다.
그렇기에 아직은 사용하지 않는게 맘 편한다.(2021/05/27 기준)
16. public 클래스에서는 public 필드가 아닌 접근자 메서드를 사용하라.
public 클래스의 필드의 접근성이 public이면 어떨까? 다음 코드를 보자.
class Point {
public double x;
public double y;
}
Java
복사
위치 정보를 가지는 Point 클래스이며, 각 좌표 필드의 접근성은 public으로 어디서든 접근이 가능하다. 어디서든 접근이 가능하다는 말은 정보 은닉이 안된다는 의미가되어 정보 은닉(캡슐화)의 장점을 가지지 못한다.
그렇기에 필드의 접근제어자를 public → private로 바꾸고 메서드를 통해 접근하도록 구현한다.
public class Point {
private double x;
private double y;
public Point(double x, double y) {
this.x = x;
this.y = y;
}
public double getX() { return x; }
public void setX(double x) { this.x = x; }
public double getY() { return y; }
public void setY(double y) { this.y = y; }
}
Java
복사
접근자(getter)와 변경자(setter)메서드를 활용해 데이터 캡슐화
이처럼 public 클래스에서는 getter/setter 메서드를 활용해 캡슐화의 장점을 가질 수 있다.
하지만, package-private 클래스나 private 중첩 클래스에서는 데이터 필드의 노출은 큰 문제가 되지 않는다.
해당 클래스가 표현하고자 하는 추상 개념만 제대로 표현해주면 되는데, 클라이언트 코드가 이 클래스 내부 표현에 묶이게 되지만, 클라이언트가 이 클래스를 포함하는 패키지 안에서만 동작하기에 문제가되지 않는다.
정리
•
public 클래스는 가변 필드를 노출해서는 안된다.
•
불변 필드라도 완전히 안심할 수 없다.
•
package-private 클래스나 private 중첩 클래스에서는 필드를 노출하는게 좋을 때도 있다.
17. 변경 가능성을 최소화하라.
객체의 접근성이 낮을수록 해당 객체를 사용하는 서비스단에서는 해당 객체의 위/변조를 항상 걱정해야 한다. 그렇기에 객체의 접근성은 높을수록 좋고, 그 중에서도 불변 클래스일수록 좋다.
여기서 불변클래스란 인스턴스 내부의 값을 변경할 수 없는 클래스를 불변 클래스라 부르는데, 이러한 불변클래스에 저장된 정보는 객체가 파괴될 때까지 변경되지 않는다.
다음 코드는 외부에서 변경 가능한 접근성이 낮은 ChangeablePoint에 대한 코드다.
public class ChangeablePointApplication {
public static void main(String[] args)
throws ExecutionException, InterruptedException {
ChangeablePoint point = new ChangeablePoint(1, 2);
CompletableFuture<Void> future1 = CompletableFuture.runAsync(() -> {
System.out.println("Thread: "+Thread.currentThread().getName());
System.out.println("future1 point = " + point);
});
CompletableFuture<Void> future2 = CompletableFuture.runAsync(() -> {
System.out.println("Thread: "+Thread.currentThread().getName());
point.x += 5;
System.out.println("future2 point = " + point);
});
CompletableFuture<Void> allOf = CompletableFuture.allOf(future1, future2);
allOf.get();
}
@Data
@AllArgsConstructor
private static class ChangeablePoint {
public double x;
public double y;
@Override
public String toString() {
return "[" + x + ", " + y + "]";
}
}
}
Java
복사
•
[실행 결과]
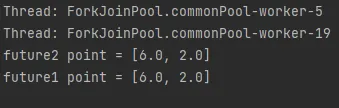
•
각각 다른 쓰레드에서 병렬적으로 처리가되는데 2번 쓰레드에서 x의 값을 변경하니 해당 영향은 다른 쓰레드에도 영향을 줬다. 즉, 스레드 안정적이지 못한다.
간단하게는 이런 이유로 불변 클래스를 사용하는게 좋은데, 클래스를 불변으로 만들기 위해선 몇가지 규칙을 따르면 된다.
불변 클래스를 만들기위한 규칙
•
객체의 상태를 변경하는 메서드(변경자)를 제공하지 않는다. (ex: setter)
•
클래스를 확장할 수 없도록 한다.
⇒ (ex: final Class 선언, 정적 팩토리 메소드)
•
모든 필드를 final로 선언한다.
•
모든 필드를 private로 선언한다.
⇒ public final도 불변이 되지만, 다음 릴리즈에서 내부 표현을 바꾸지 못하기에 비추천
•
자신 외에는 내부의 가변 컴포넌트에 접근할 수 없도록 한다.
⇒ 클래스에 가변객체가 하나라도 있다면 클라이언트에서 객체의 참조를 얻을 수 없도록 해야한다. 접근자 메서드가 해당 필드를 그대로 반환해도 안되며, 생성자, 접근자, readObject 메서드 모두에서 방어적 복사를 수행하라.
이러한 규칙들을 적용해 불변 클래스 포인트 객체를 만들어 보자.
public class ImmutablePointApplication {
private static ImmutablePoint point = new ImmutablePoint(1, 2);
public static void main(String[] args) throws ExecutionException, InterruptedException {
CompletableFuture<Void> future1 = CompletableFuture.runAsync(() -> {
System.out.println("Thread: "+Thread.currentThread().getName());
System.out.println("future1 point = " + point);
});
CompletableFuture<Void> future2 = CompletableFuture.runAsync(() -> {
System.out.println("Thread: "+Thread.currentThread().getName());
point = point.move(3, 4);
System.out.println("future2 point = " + point);
});
CompletableFuture<Void> allOf = CompletableFuture.allOf(future1, future2);
allOf.get();
}
@Data
@AllArgsConstructor
private static class ImmutablePoint {
private final double x;
private final double y;
public ImmutablePoint move(double x, double y) {
return new ImmutablePoint(this.x + x, this.y + y);
}
@Override
public String toString() {
return "[" + x + ", " + y + "]";
}
}
}
Java
복사
•
[실행 결과]
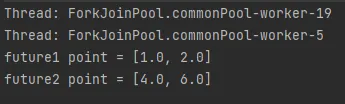
•
future2에서 point의 move라는 메서드로 포인트를 이동시킨다. 하지만 불변성을 지키기위해 내부의 값을 바꾸는것이 아닌 방어적 복사로 새로운 Point 객체를 만들어 반환한다.
•
move는 새로운 객체를 만들어서 반환하는데, 람다식 내부에서 외부의 변수를 사용할때는 effective final이라 하여 기본적으로 final 키워드가 없더라도 final로 간주한다. 그렇기에 point 객체를 정적 변수로 선언을 해주었다.
불변 클래스의 장점
클래스의 낮은 접근성은 얼핏보면 불변 클래스에 비교해서 로직을 짤 때 데이터 접근이 편하기에 불변 클래스로 만들경우 생기는 추가적인 고려사항들이 까다롭게 느껴질 수 있다. 그렇기 때문에 다음과 같은 장점들을 명확히 알 필요가 있다.
•
불변 객체는 단순하다.
⇒ 생성된 시점의 상태를 파괴될 때까지 그대로 가지고 있기에 불변식이 보장된다면 해당 클래스를 사용하는 곳에서도 불변을 유지하기 쉽다.
•
스레드 안전하며 따로 동기화할 필요가 없다.
⇒ 여러 스레드가 동시에 사용해도 절대 훼손되지 않는다. 스레드를 안전하게 만드는 가장 쉬운방법이 불변 클래스다. 이처럼 스레드가 안전하게되니 불변객체는 공유하는데 문제도 없다.
•
복사 생성자가 필요없다.
⇒ 불변 객체는 공유에서 자유롭기 때문에 방어적 복사도 필요가 없다. 그냥 공유하면 되기 때문이다. 그렇기에 불변 클래스는 clone 메서드나 복사 생성자를 제공하지 않는게 좋다.
•
⇒ 상태가 변하지 않기에 잠깐이라도 불일치 상태에 빠지지 않는다.
•
객체 생성시 불변 객체를 사용할 경우 이점이 많다.
⇒ 생성될 객체가 복잡한 구조라도 구성요소로 불변 객체가 사용된다면 불변식을 유지하기 훨씬 수월하기 때문이다. 가령 맵의 키와 집합(Set)의 원소로 쓰기 좋다.
이러한 장점들 때문에 불변 클래스라면 한 번 만든 객체를 최대한 재활용하는게 좋다.
예를들어 Point 클래스라면 다음과 같은 상수들을 제공할 수 있다.
public static final ImmutablePoint ZERO = new ImmutablePoint(0, 0);
public static final ImmutablePoint ONE = new ImmutablePoint(1, 0);
public static final ImmutablePoint I = new ImmutablePoint(0, 1);
Java
복사
또한, 이런 불변 클래스에서 자주 사용되는 인스턴스를 캐싱해서 중복된 인스턴스를 생성하지 않도록 할 수도 있다. (정적 팩토리)
불변 클래스의 단점
•
값이 다를경우 반드시 독립된 객체로 만들어야 한다.
⇒ ImmutablePoint처럼 필드가 적은 가벼운 객체에서는 문제가 되지 않지만, 백만 비트가 넘는 BigInteger에서 비트 하나를 바꿔야 한다면? 새로운 객체를 비트하나 때문에 복사하는 데 드는 비용이 몹시 크다.
대안책
•
다단계 연산(multistep operation)들을 예측해 기본 기능으로 제공하기
⇒ Ex: BigInteger는 모듈러 지수같은 다단계 연산 속도를 높혀주는 가변 동반 클래스(companion class)를 package-private로 두고 있다.
⇒ 다른 예로는 String과 String의 가변 동반 클래스인 StringBuilder가 있다.
불변 클래스를 만드는 설계 방법
클래스가 불변임을 보장하려면 자신을 상속하지 못하게 해야하는데 그 방법은 다음과 같다.
•
클래스를 final로 선언하는 것.
•
모든 생성자를 private(or package-private)로 만들고 public 정적 팩토리를 제공하는 방법
@Data
public class ImmutablePointV2 {
private final double x;
private final double y;
private ImmutablePointV2(double x, double y) {
this.x = x;
this.y = y;
}
public static ImmutablePointV2 valueOf(double x, double y) {
return new ImmutablePointV2(x, y);
}
...
}
Java
복사
⇒ 패키지 바깥의 클라이언트에서 본 이 객체는 사실상 final이다. public이나 protected생성자도 없기에 다른 패키지에서는 이 클래스를 확장하는게 불가능하다.
⇒ 정적 팩토리 방식은 다수의 구현 클래스를 활용한 유연성을 제공한다.
⇒ 다음 릴리즈에서 객체 캐싱 기능을 추가해 성능을 끌어올릴 수도 있다.
정리
•
최대한 불변 클래스로 만들자.
•
불변으로 만들 수 없는 클래스도 변경할 수 있는 부분을 최소한으로 줄이자.
•
다른 합당한 이유가 없다면 모든 필드는 private final이어야 한다.
•
생성자는 불변식 설정이 모두 완료된, 초기화가 끝난 상태의 객체를 생성해야 한다.
(1): 예외가 발생한 후에도 그 객체는 예외 발생전과 동일하게 유효한 상태여야 한다.
18. 상속보다는 컴포지션을 사용하라.
객체를 재사용하면서 확장까지 고려하는데 있어서 상속은 상당히 강력한 기능이다.
하지만, 상속은 상위 클래스의 장점뿐 아니라 단점까지 가져온다는 문제가 있다. 그렇기에 특정상황을 제하면 대부분 상속보다는 컴포지션(위임)을 사용하는게 유리한데, 이에 대해 알아보자.
(참고로, 여기서 말하는 상속은 인터페이스를 구현하거나 인터페이스가 다른 인터페이스를 확장하는 인터페이스 상속과는 상관이 없다. )
상속을 써도 문제가 없는 경우
•
상위 클래스와 하위 클래스가 모두 통제되는 패키지 안에 있을 경우
•
확장할 목적으로 설계되었고 문서화도 잘 된 클래스
이 외에는 상속은 모두 문제라고 볼 수 있다.
우선, 상속은 캡슐화를 깨트린다. 이 말은 상위 클래스의 구현에 따라 하위 클래스에서 문제가 생길 수 있다는 의미이다. 상위 클래스가 릴리즈가 되면서 내부 구현이 달라지면 하위 클래스는 어느것도 수정한게 없지만 릴리즈에 따라 문제가 발생할 수 있다는 의미가 된다.
문제 발생 사례
HashSet을 사용하는 프로그램을 만들어 문제점을 파악해보자.
•
상위 클래스: HashSet
•
하위 클래스: InstrumentedHashSet
•
확장 될 기능: 생성 이후 원소가 몇 개 더해졌는지를 알 수 있는 기능
public class InstrumentedHashSet<E> extends HashSet<E> {
private int addCount = 0;
public InstrumentedHashSet() { }
public InstrumentedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
}
@Override
public boolean add(E e) {
addCount++;
return super.add(e);
}
@Override
public boolean addAll(Collection<? extends E> c) {
addCount += c.size();
return super.addAll(c);
}
}
public class SetApplication {
public static void main(String[] args) {
InstrumentedHashSet<String> set = new InstrumentedHashSet<>();
set.addAll(Arrays.asList("java", "test", "code"));
System.out.println("set.getAddCount() = " + set.getAddCount());
}
}
Java
복사
⇒ main로직을 실행하면 어떤 값이 예측되는가? 코드만 봐서는 java, test, code 세 가지 문자만 addAll로 추가하기 때문에 addCount는 3이 될 것으로 보인다.
⇒ 실제 실행 결과
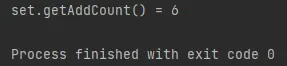
예상과 다르게 6이 반환된다. 어째서 3개를 추가했는데 6이 출력된 것일까? 그 원인은 HashSet 클래스의 addAll메서드가 내부적으로는 add를 사용해 구현하는데 있다. 즉, addAll에 3개가 원자가 추가되면서 로직내에서 최초 3을 addCount에 더해주고 그다음 3회 add()메서드를 내부적으로 호출하면서 add()메서드에서 다시 한 번 addCount에 +1씩 증가되면서 결국 인자 하나당 2회씩 addCount가 증가된 것이다.
이런 내부 구현 방식은 HashSet 문서에는 당연히도 쓰여있지 않기 때문이며, 위와같은 문제는
addAll을 재정의 하지 않으면 고칠 수 있는 문제다. 하지만, 내가 add메서드만 재정의하여 addCount를 증가시키는것도 다음 릴리즈에서 HashSet의 내부 구현이 어떻게 변경되냐에따라 깨지기 쉽다.
게다가 하위 클래스에서 상위 클래스의 private 필드를 써야 하는 경우 구현조차 불가능하다.
그렇다고, addAll이나 add가 아니라 addAndPlusCount, addAllAndPlusCount 이런식으로 새로운 메서드를 추가해 기능을 넣는다면, 문제가 없어보이고 실제로도 위 재정의 방법보다는 안전하지만, 만약 새로운 릴리즈에서 추가된 메서드가 시그니처는 같고 반환타입은 다른 경우에는 또 문제가 발생한다.
컴포지션(Composition)을 사용하자.
위와같은 많은 문제들은 새로운 클래스에서 본디 상위 클래스로 사용할 클래스를 private 필드로 작성해 참조하도록 하자. 이를 기존 클래스가 새로운 클래스의 구성요소로 쓰인다는 의미로 컴포지션(Composition)이라 한다.
새로운 클래스에서 기존 클래스에 대응하는 메서드를 호출하면 새로운 클래스는 기존 클래스의 메서드를 호출해서 결과를 반환하는데 이를 전달(forwarding)이라 하며, 이런 새로운 클래스의 메서드를 전달 메서드(forwarding method)라 부른다.
이번에는 컴포지션과 전달방식으로 다시 InstrumentedSet을 구현한 코드를 작성해보자.
public class CompositionInstrumentedSet<E> extends ForwardingSet<E>{
private int addCount = 0;
public CompositionInstrumentedSet(Set<E> s) {
super(s);
}
@Override
public boolean add(E e) {
addCount ++;
return super.add(e);
}
@Override
public boolean addAll(Collection<? extends E> collection) {
addCount += collection.size();
return super.addAll(collection);
}
public int getAddCount() {
return addCount;
}
}
public class ForwardingSet<E> implements Set<E> {
private final Set<E> s;
public ForwardingSet(Set<E> s) {
this.s = s;
}
@Override
public int size() { return s.size(); }
@Override
public boolean isEmpty() { return s.isEmpty(); }
@Override
public boolean contains(Object o) { return s.contains(o); }
@Override
public Iterator<E> iterator() { return s.iterator(); }
@Override
public Object[] toArray() { return s.toArray(); }
@Override
public <T> T[] toArray(T[] ts) { return s.toArray(ts); }
@Override
public boolean add(E e) { return s.add(e); }
@Override
public boolean remove(Object o) { return s.remove(o); }
@Override
public boolean containsAll(Collection<?> collection) { return s.containsAll(collection); }
@Override
public boolean addAll(Collection<? extends E> collection) { return s.addAll(collection); }
@Override
public boolean retainAll(Collection<?> collection) { return s.retainAll(collection); }
@Override
public boolean removeAll(Collection<?> collection) { return s.removeAll(collection); }
@Override
public void clear() { s.clear(); }
}
public class CompositionApplication {
public static void main(String[] args) {
CompositionInstrumentedSet<String> set = new CompositionInstrumentedSet<String>(new HashSet<>());
set.addAll(Arrays.asList("hello", "java", "world"));
System.out.println("set.getAddCount() = " + set.getAddCount());
}
}
Java
복사
⇒ 추가횟수를 저장하는 클래스인 InstrumentedSet과 이를 컴포지션으로 가지고있는 Set 필드에 전달해주는 전달 메서드를 구현하는 ForwardingSet을 이용해 보았다. 여기서 ForwardingSet은 HashSet에 있는 모든 공개 API가 존재하는 상위 인터페이스 Set을 구현했기에 견고하고 유연하다.
(내부적으로 hashSet뿐아니라 TresSet, LinkedHashSet등도 구성요소로 넣어서 사용이 가능하다.)
잘 보면 InstrumentedSet은 Set 인스턴스를 감싸고 있다. 이런 클래스를 래퍼 클래스라 하며 기존 Set 에 기능을 덧씌운다는 의미에서 데코레이터 패턴(Decorator pattern)을 적용했다고 할 수 있다.
래퍼 클래스는 콜백 프레임워크와 어울리지 않는다는 점만 주의하면 된다.
콜백 프레임워크에서는 자기 자신의 참조를 다른 객체에 넘겨 다음 호출(콜백) 때 사용하도록 한다.
내부 객체는 자신을 감싸고 있는 래퍼의 존재를 모르니 대신 자신(this)의 참조를 넘기고, 콜백 때는 래퍼가 아닌 내부 객체를 호출하게 되는데 이를 SELF문제라 한다.
전달 메서드, 래퍼 객체가 메모리 사용량에 비용 낭비가 생기지 않나 걱정할 수 있지만, 실제로는 둘 다 별다른 영향을 끼치지 않는다.
상속은 하위클래스가 상위 클래스의 '진짜" 하위 타입인 경우에만 사용되야 한다.
정리
•
상속은 캡슐화를 깨트린다.
•
상속은 상위 클래스와 하위 클래스의 관계가 온전한 is-a 관계일 때만 써야한다.
•
is-a 관계일때도 하위 클래스의 패키지가 상위 클래스와 다르고, 상위 클래스가 확장을 고려하지 않은경우 문제가 발생할 수 있다.
•
대부분의 경우 컴포지션과 전달을 사용하자.
⇒ 래퍼클래스로 구현할 인터페이스(ex: Set, List, Map)이 있다면 더욱 그렇다.
19. 상속을 고려해 설계하고 문서화하라. 그러지 않았다면 상속을 금지하라
상속을 염두해두지 않은 외부 클래스(주: 프로그래머의 통제권 밖에 있어 변경시점을 알 수 없는 클래스)를 상속할 경우 여러 문제가 발생할 수 있다. 그렇기에 상속용 클래스를 설계 할 때는 문서화가 필요하다.
상속을 고려한 설계와 문서란 무엇인가?
처음부터 기능확장및 재정의를 염두해두고 만드는 상속용 클래스를 설계해야 한다면 해당 상속용 클래스는 재정의할 수 있는 메서드들을 내부적으로 어떻게 이용하는지(자기사용) 문서로 남겨야 한다.
문서에는 무엇을 작성해야 하는가?
•
재정의할 수 있는 메서드들이 내부적으로 어떻게 이용하는지(자기사용) 적어야 한다.
•
API로 공개된 메서드로부터 호출되는 재정의 메서드
⇒ 호출된다는 사실과, 어떤 순서로 호출되는지와 호출결과에 이어지는 처리에 어떤 영향을 주는지 적어야 한다.
참고: 재정의 가능 메서드란 public(or protected)메서드 중 final이 아닌 모든 메서드를 말한다.Implementation Requirements
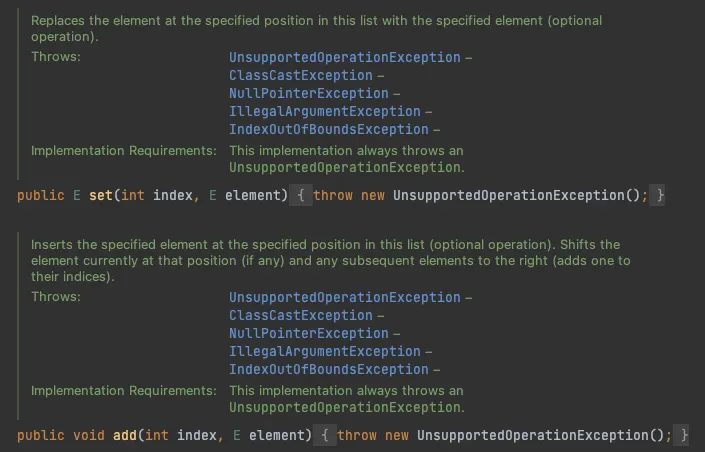
AbstractList의 set, add메서드
API 문서의 끝부분을 보면 implementation Requirements라는 항목이 존재하는데, 이 메서드의 내부 동작 방식을 설명하는 절이다. 메서드 주석에 @impleSpec 태그를 붙혀주면 자바독 도구가 생성해준다.
위 set과 add 메서드의 문서를 살펴보면 이 구현체는 항상 UnsupportedOperationException 예외가 발생할 수 있다는 점을 알려준다. 그럼 구현하는 입장에서는 항상 이런 부분을 염두해두고 개발을 해야 한다는 것을 알 수 있다.
좋은 API문서란 어떻게 가 아니라 무엇을 하는지를 설명해야 한다.
이 주제는 지금 위에 작성된 API문서의 내용하고는 상충된다. 어째서일까?
상충되는 이유는 상속이 캡슐화를 깨트리기 때문인데, 클래스를 안전하게 상속할 수 있도록 하기 위해서는 내부 구현 방식을 설명해야만 하기 때문이다.
@implSpec 태그 활성화 방법
-tag "implSpec:a:Implementation Requirements:"
자바 9부터 본격적으로 사용된 해당 태그는 자바 11의 자바독에서도 필수및 기본값이 아닌 선택사항으로 남겨져 있는데, 이를 활성화 하기위해서는 명령줄 매개변수로 위에 작성한 명령어를 지정해주면 된다.
Hook
클래스 내부 동작 과정 중간에 끼어들 수 있는 훅(hook)을 잘 선별해서 protected 메서드 형태로 공개해야 할 수도 있다. 다음 코드는 java.util.AbstractList에 있는 removeRange 메서드다.
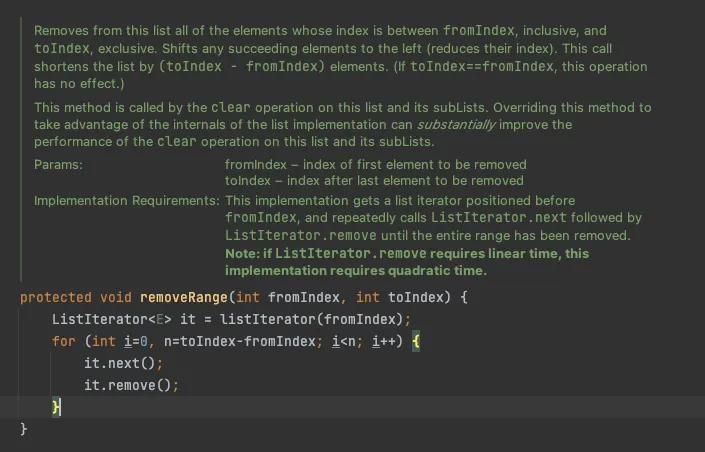
List 구현체를 사용하는 개발자 입장에서 removeRange를 직접 사용할일도 없고 관심도 없다.
그런데 어째서 이 메서드도 문서가 제공되는 것일까?
이는, List구현체 최종사용자가 아니라 AbstractList의 하위 클래스를 만들 사람이 이 메서드를 사용하는 clear 메서드를 고성능으로 만들기 쉽게 하기 위해서인데, clear 메서드를 보면 내부적으로 removeRange()를 호출한다.
public void clear() {
removeRange(0, size());
}
Java
복사
만약 removeRange() 메서드가 없는 상태에서 clear 메서드를 구현해야 한다면 부분 리스트의 메커니즘을 다시 구현해야 하는데 쉬운일이 아니다.
그럼 어떤 메서드를 protected로 노출해야 하는가?
책에서도 나와있지만, 명확한 기준을 제공해주지는 못한다. 그렇기에 실제로 하위 클래스를 만들어보면서 테스트를 해봐야하는데, protected 메서드는 내부 구현에 해당하기 때문에 수가 가능한 적어야 한다.
(그렇다고 너무 적게 노출하면 상속의 이점마저 잃을 수 있다.)
주의점
1.
상속용 클래스의 생성자가 재정의 가능 메서드를 호출해서는 안된다. 다음 코드를 보자.
public class Super {
public Super() {
overrideMe();
}
public void overrideMe() {
System.out.println("Super override method!");
}
}
Java
복사
public class Sub extends Super{
private final Instant instant;
public Sub() {
instant = Instant.now();
}
@Override
public void overrideMe() {
System.out.println("Sub overrideMe Method!! " + instant);
}
}
Java
복사
public class App {
public static void main(String[] args) {
Sub sub = new Sub();
sub.overrideMe();
}
}
Java
복사

[실행 결과]
•
메인 로직에서 sub.overrideMe() 메서드를 한 번 호출했고 Sub 클래스의 생성자에서는 instant 필드를 초기화만 해줬는데, 어째서 Sub override Method!! 라는 출력이 두 번되었고, 그 중 첫 번째는 null 이 나온 것일까?
⇒ 우리는 상위 클래스의 생성자가 하위 클래스의 생성자보다 항상 먼저 호출된다는 점을 기억해야 한다.
Sub 생성자에서 명시적으로 super() 를 호출하지 않더라도, 상위 클래스의 생성자에 필요 매개변수가 없는 기본 생성자가 있을 경우 묵시적으로 최우선적으로 super()가 호출된다.
그렇기 때문에 부모 클래스인 Super의 생성자가 실행되는데 여기서 overrideMe()메서드를 호출한다.
그럼 실제 구현체는 Sub 클래스이기 때문에 재정의된 overrideMe() 메서드가 실행되는데 이 시점에는 아직 instant가 초기화되지 않은상태이기 때문에 null이 출력되는 것이다. 만약 로직이 단순 출력이 아닌 instant를 가지고 핸들리을 하거나 그래프 탐색을 시도했다면 NullPointException이 발생했을 것이다.
참고: private, final, static 메서드는 재정의가 불가능하기에 생성자에서 호출해도 문제가 없다.2.
Cloneable, Serializable 인터페이스 구현을 주의하라
상속용 클래스 설계의 어려움을 더해주는게 바로 Cloneable, Serializable 인터페이스다.
그래서 이 두 인터페이스 중 하나라도 구현한 클래스를 상속용 클래스로 설계하는것은 별로 좋은생각은 아니다. 구현을 위해서는 clone, readObject를 재정의해야 하는데, 이 메서드의 로직도 결국 생성자와 비슷하기 때문에 이 역시 마찮가지로 로직에 재정의 가능한 메서드를 호출해서는 안된다.
3.
상속용이 아닌 일반 구체 클래스는 상속을 해서는 안된다.
final도 아니고 상속용으로 설계되거나 문서도 없는 일반 클래스를 상속하게되면 클래스가 변경될 때마다 확장클래스들에서 문제가 생길확률이 몹시 높다.
그렇기에 클래스를 final로 선언하거나 모든 생성자를 private (or package-private)로 선언해서 정적 팩터리를 만들어주는게 좋다.
(만약) 표준 인터페이스를 구현하지 않고 상속을 허용해야 한다면....
클래스 내부에서는 재정의 가능 메서드를 사용하지 않게 하면서, 이 사실을 문서로 남기도록 하자.
그렇게 한다면, 메서드를 재정의해도 다른 메서드의 동작에 영향을 주지 않기 때문에 상속해도 위험하지 않은 클래스를 만들 수 있다.
제안
책에서는 클래스의 동작을 유지하면서 재정의 가능 메서드를 사용하는 코드를 제거하는 방법을 소개한다.
각각의 재정의 가능 메서드는 자신의 본문 코드를 private 도우미 메서드로 옮긴 뒤 이 도우미 메서드를 호출하도록 수정한다. 그런 다음 재정의 가능 메서드를 호출하는 다른 코드들도 모두 이 도우미 메서드를 직접 호출하도록 수정하면 된다.
결론
•
상속용 클래스를 시험하는 방법은 직접 하위 클래스를 만들어 보는것이 유일하다.
•
하위 클래스를 여러개 만드는동안 쓰이지 않는 메서드는 private로 선언해주는게 좋다.
•
공개 될 상속용 클래스는 문서화된 내부 사용방식과, protected 메서드와 필드가 정해지며 영원히 책임져야 한다.
•
상속용으로 설계한 클래스는 배포 전 반드시 하위 클래스를 만들어 검증해봐야 한다.
20. 추상 클래스보다는 인터페이스를 우선하라
JDK1.8부터는 인터페이스에도 default method를 제공할 수 있게 되었다.
그렇기에 많은 개발자들이 이런 질문을 한다.
추상클래스랑 인터페이스랑 뭔차이야?
표면적으로 나온 내용들만 생각해보면 인터페이스에서도 정적 메서드(private 정적 메서드는 제외), 기본 메서드를 제공하게 되면서 다중 상속을 제외하면 추상 클래스와 차이를 느끼기 힘들다. 하지만, 이 다중 상속이 큰 차이점이자 인터페이스를 우선해야 할 이유가 된다. 다중상속이 안되는 추상 클래스는 해당 클래스를 구현하는 구현 클래스가 반드시 이 추상 클래스의 하위 클래스가 되어야 한다는 점이다.
즉, 하위 클래스가 추상클래스에 종속된다는 의미인데 종속성이 생기면서 해당 하위 클래스는 새로운 타입 및 기능을 정의하는데 있어 제약이 많다. 그리고 이런 문제점은 반대로 인터페이스의 장점이 된다.
인터페이스의 장점
1. 기존 클래스에도 손쉽게 새로운 인터페이스를 구현해 넣을 수 있다.
public interface Food {
String getName();
}
public class Apple implements Food, Comparable<Apple>{
private final String name;
private final long price;
public Apple(String name, long price) {
this.name = name;
this.price = price;
}
@Override
public String getName() {
return name;
}
@Override
public int compareTo(Apple o) {
return Long.compare(price, o.price);
}
}
Java
복사
⇒ Food 인터페이스를 구현하는 Apple 하위 클래스가 있다. 음식에 관련된 클래스인 Apple은 객체간 비교를 통해 정렬을 할 수 있도록 Comparable을 구현하고싶다면, 클래스 선언에 implements 구문만 추가해준 뒤 필요 메서드만 재정의해주면 된다. 만약 try-with-resources에서 사용하고 싶다면 AutoCloseable을 순회를 할 요소가 있다면 Iterable을 구현하면 된다.
⇒ 만약 Food가 추상 클래스였다면 새로운 추상 클래스를 끼워넣기는 어렵다.
2. 인터페이스는 믹스인(mixin)정의에 안성맞춤이다.
믹스인(mixin) 타입정의는 믹스인을 구현한 클래스에 주된 타입외에 특정 행위를 제공한다고 선언하는 효과를 주는데, 위에 작성한 Apple 하위 클래스의 Comparable이 믹스인 인터페이스다.
그래서, Apple 클래스는 Food 타입이라는 주된 타입 외에 비교하여 정렬을 할 수 있다고 선언할 수 있다. 하지만, 추상 클래스로는 기존 클래스에 덧씌울 수 없기 때문에 믹스인을 정의할 수 없다.
3. 인터페이스로는 계층구조가 없는 타입 프레임워크를 만들 수 있다.
•
현실에서 계층으로 구분하기 힘든 개념들을 묶어 제 3의 인터페이스로 정의할 수 있다.
public interface Singer {
AudioClip sing(Song s);
}
public interface Songwriter {
Song compose(int chartPosition);
}
public interface SingerSongwriter extends Singer, Songwriter{
AudioClip strum();
void actSensitive();
}
Java
복사
⇒ 가수라는 인터페이스와 작곡가라는 인터페이스가 각각 존재한다. 하지만 현실을 보면 작곡도 같이 하는 가수 역시 많이 있다. 그런 경우 위처럼 SingerSongwriter라는 제 3의 인터페이스를 정의하면 해당 인터페이스의 구현 클래스는 Singer, Songwriter의 정의 메서드를 둘 다 구현해야 한다. 이러한 높은 유연성은 개발자의 개발을 더 즐겁게 해준다.
⇒ 인터페이스를 사용하지않고 위와같은 구조를 만들기 위해서는 가능한 조합의 경우의 수를 모두 각각 구현하는 상황이 생긴다. 이는 중복된 코드가 늘어나고 유지 보수가 더 어려워지는 결과를 초래할 수 있다.속성이 n개라면 조합의 수는 개가 되는데 이는 조합 폭발(combinatorial exposion)이라는 현상이다.
4. 래퍼 클래스와 같이 쓰면 기능 향상이 안전하고 강력하다.
래퍼 클래스를 이용해 Composition으로 사용을 하면 기능 보완 및 확장이 편리하면서 위험성도 없다. 하지만, 추상 클래스로 정의할 경우 기능을 추가하려면 상속밖에 답이 없다.
인터페이스의 디폴트 메서드
인터페이스에 정의되는 메서드 중 구현 방법이 명확하고 공통적이라면 디폴트 메서드로 만들면
하위 클래스에서 각각 재정의 할 필요가 없어진다.
디폴트 메서드를 작성해서 제공할 때 해당 인터페이스를 구현하려는 사람들을 위해 문서화를 해야 한다.
제약 사항
•
Object의 메서드(ex: equals, hashCode...)같은 메서드들은 디폴트 메서드로 제공해서는 안된다.
•
인터페이스는 인스턴스 필드를 가질 수 없다.
•
public이 아닌 정적 멤버도 가질 수 없다. (private 정적 메서드는 예외)
•
우리가 구현하지 않은 인터페이스에는 디폴트 메서드를 추가할 수 없다.
제안 사항 - 추상 골격 구현
•
인터페이스와 추상 골격 구현을 동시에 작성해서 인터페이스와 추상 클래스의 장점을 모두 취할 수 있다.
•
인터페이스로는 타입을 정의하고, 필요에따라 디폴트 메서드를 정의한다.
•
골격 구현 클래스는 나머지 메서드들까지 구현한다.
•

skeletal implementation
•
자바 라이브러리에선 콜렉션 프레임워크의 AbstractCollection, AbstractSet, AbstractList, AbstractMap이 골격 구현 클래스다.
•
골격 구현 예제 코드
:List 구현체를 반환하는 정적 팩토리 메서드로 AbstractList 골격 구현으로 활용한다.
public interface Warrior {
void attack();
void guard();
void applyItem(Item item);
default void taunt() {
System.out.println("wraaaaaaaaa!!!");
}
}
public abstract class AbstractWarrior implements Warrior {
private String name;
private int hp;
private int mp;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getHp() {
return hp;
}
public void setHp(int hp) {
this.hp = hp;
}
public int getMp() {
return mp;
}
public void setMp(int mp) {
this.mp = mp;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Warrior)) return false;
Warrior that = (Warrior) o;
return Objects.equals(getHp(), that.getHp())
&& Objects.equals(getMp(), that.getMp())
&& Objects.equals(getName(), that.getName());
}
@Override
public int hashCode() {
return Objects.hash(getName(), getHp(), getMp());
}
@Override
public String toString() {
return "Warrior '" + getName() + "'s Info[HP: " + getHp() + ", MP:" + getMp() + "]";
}
}
Java
복사
⇒ Warrior 인터페이스로 타입이 정의되었고, AbstractWarrior 추상클래스를 만들어 equals, hashCode, toString, getter, setter등의 골격을 구현했다.
⇒ attack, guard, applyItem등의 메서드는 사용자가 직접 하위 클래스에 구현을 해야 한다.
참고: 추상 골격 클래스는..인터페이스에서 구현에 사용될 기반 메소드를 선정해 골격 구현 클래스 내의 추상 메소드가 된다.
그리고 기반 메서드를 통해 직접 구현이 가능한 메서드는 모두 인터페이스의 default method가 되고, 기반 메서드/ 디폴트 메서드가 되지 못한 메서드들(ex: equals, hashCode...)등을 골격 구현 클래스에서 구현하면 된다.
정리
•
다중 구현용 타입으로는 인터페이스가 가장 적합하다.
•
인터페이스가 복잡할 경우 골격 구현을 같이 제공하는 방법을 고려해보자.
•
골격 구현은 가능한 인터페이스의 디폴트 메서드로 제공해서 인터페이스 구현체가 활용하도록 하는게 좋다.
•
하지만 인터페이스의 제약문제로 모든 메서드가 디폴트 메서드로 작성될 수는 없고 이 경우 골격 구현을 한 추상클래스로 해결하자.
21. 인터페이스는 구현하는 쪽을 생각해 설계하라
디폴트 메서드의 등장
아이템 20에서 언급했지만, JDK 1.8 이후 인터페이스에도 정적 메서드와 디폴트 메서드가 추가되면서 인터페이스 내에도 로직을 직접 추가할 수 있게 되었다.
이전에는, 이미 구현한 인터페이스에 메서드를 추가하는것은 쉬운일이 아니였다.
다음 코드를 보자. 간단한 인터페이스와 구현체다.
public interface Phone {
void call(String number);
void hangup();
//메서드 추가를 위해선 모든 하위클래스에서 구현을 해줘야 한다.
//void videoCall(String number);
default void videoCall(String number){
System.out.println(number +"로 화상 전화를 겁니다. 따르릉");
}
}
public class Iphone implements Phone{
@Override
public void call(String number) {
System.out.println(number +"로 전화를 겁니다. 따르릉");
}
@Override
public void hangup() {
System.out.println("전화를 종료합니다.");
}
}
Java
복사
전화(Phone) 인터페이스와 이를 구현하는 아이폰 하위 클래스가 있다.
그런데 추가개발 요구로 단순히 call 이 아닌 영상통화가 필요해지면서 videoCall 이라는 메서드가 추가되야 하는 상황이 되었다. 그래서 이 메서드를 그냥 인터페이스에 추가하면 해당 인터페이스를 구현하는 모든 하위 클래스에서 메서드를 구현해주지 않으면 컴파일 에러가 발생한다.
하지만, 디폴트 메서드가 등장하면서 A라는 인터페이스를 구현하는 구현 클래스가 5개가 있다고 할 때 모두 공통으로 들어가는 로직이 있다면, 정적 혹은 디폴트 메소드를 추가해서 공통 기능을 손쉽게 추가할 수 있게 되었다.
정리하면, 기존 인터페이스에 새로운 메서드를 추가하는 방법이 생겼다.
디폴트 메서드 사용은 쉽지 않다.
사용법만 보면 default 키워드 하나로 로직 구현이 가능하다. 하지만, 좀 더 생각해보면 디폴트 메서드를 추가하는건 쉬운일만은 아니다.
디폴트 메서드는 구현 클래스에 대해서는 알지 못한채로 무작정 구현될 뿐이다.
하지만 이렇게 추가되는 디폴트 메서드가 모든 상황에서 불변식을 해치지 않도록 하는건 쉽지 않다.
•
문제 발생 예
⇒ Collection 인터페이스에 추가된 removeIf가 최근까지 org.apache.commons.collections4.collection.SynchronizedCollection에서 최근까지 동시성 문제에 대한 대응이 되지 않아 멀티 스레드 환경에서 특정 스레드가 removeIf 메서드를 호출하면 ConcurrentModificationException 예외가 발생하거나 문제가 생길 수 있다.
즉, 디폴트 메서드는 기존 인터페이스에 추가하는건 되도록 피하자.
정리
•
디폴트 메서드는 인터페이스의 메서드 제거 및 기존 메서드의 시그니처 수정용이 아니다.
•
디폴트 메서드는 구현 클래스에 공통으로 기능을 제공하는 만큼 문제가 발생한다면 문제 역시 모든 구현 클래스에서 발생할 수 있다.
•
새로운 인터페이스에서 작성하는 디폴트 메서드는 표준 메서드 제공의 유용한 수단이 된다.
•
새로운 인터페이스는 릴리즈 전 최소 3가지의 다른 방식으로 구현하여 테스트할 것을 권장한다.
•
릴리즈 후에도 인터페이스 수정이 가능할 수도 있지만, 이미 늦다.
22. 인터페이스는 타입을 정의하는 용도로만 사용하라
인터페이스를 이용해 공개 API를 정의해서 사용하기도하고, 인터페이스의 구현체 인스턴스를 참조할 수 있는 타입 역할도 수행할 수 있다.
즉, 인터페이스로는 외부에 공개해도 되는 API를 정의한 뒤 사용자가 해당 API만 사용할 수 있게 하는 것으로 인터페이스의 구현체의 내부 구조까지 다 파악할 필요가 없게끔 해주고, 이 용도로만 사용을 해야 한다.
만약 다른 용도로 사용을 한다면 어떻게 될까?
인터페이스에는 메서드 뿐아니라 상수도 작성할 수 있다는 것 때문에, 메서드 없이 상수만 기록하는 상수 인터페이스를 만들 수 있다.
public interface PhysicalConstants {
static final double AVOGADROS_NUMBER = 6.022_140_857e23;
static final double BOLTZMAN_CONSTANT = 1.380_648_52e-23;
static final double ELECTRON_MASS = 9.109_383_56e-31;
}
Java
복사
상수 인터페이스 안티 패턴
이러한 상수 인터페이스 안티패턴은 인터페이스를 잘못 사용한 예다.
WHY?
•
클래스 내부에서 사용하는 상수는 내부 구현에 해당한다.
•
상수 인터페이스를 구현하는 것은 내부 구현을 외부로 노출하는 행위이다.
•
클래스가 어떤 상수 인터페이스를 사용하든 사용자에게는 의미가 없다.
⇒ 오히려 혼란을 주거나 클라이언트 코드가 내부 구현에 해당하는 이 상수들에 종속될 수 있다.
•
버전이 바뀌며 상수들을 사용하지 않게되더라도 바이너리 호환성을 위해 여전히 상수 인터페이스를 구현하고 있어야 한다.
바이너리 호환성이란?
: 프로젝트내의 무엇을 바꾼 이후에도 기존 바이너리가 문제없이 실행될 수 있는 상황
(ex: 인터페이스에 메서드가 추가되어도 추가된 메서드를 호출하기전에는 문제가 발생하지 않는 것) 바이너리 호환성 더 보기
그 밖에 코드를 고쳐도 기존 프로그램이 Recompile이 될 수 있는 것을 뜻하는 소스 호환성과 코드를 바꾼 뒤에도 동일한 입력에 동일한 동작을 하는 동작 호환성이 있다.
제안
상수를 공개할 목적이라면 상수 인터페이스보다 나은 선택지가 있다.
•
특정 클래스나 인터페이스와 강결합된 상수라면 클래스나 인터페이스 자체에 추가를 해보자.
⇒ EX: Integer, Double의 MIN_VALUE, MAX_VALUE
•
열거 타입으로 나타내기 적합하다면 열거 타입으로 만들어 공개하자.
•
인스턴스화 할 수 없는 유틸리티 클래스에 담아 공개하자.
public class PhysicalConstants {
private PhysicalConstants() { } //인스턴스화 방지
public static final double AVOGADROS_NUMBER = 6.022_140_857e23;
public static final double BOLTZMAN_CONSTANT = 1.380_648_52e-23;
public static final double ELECTRON_MASS = 9.109_383_56e-31;
}
Java
복사
23. 태그 달린 클래스보다는 클래스 계층구조를 활용하라
태그 달린 클래스
•
두 가지 이상의 의미를 표현할 수 있으며 현재 표현하는 의미를 태그 값으로 알려주는 클래스
public class Figure {
enum Shape {
RECTANGLE, CIRCLE
};
//공통 필드
private final Shape shape;
private double length;
private double width;
private double radius;
public Figure(double radius) {
this.radius = radius;
shape = Shape.CIRCLE;
}
public Figure(double length, double width) {
this.length = length;
this.width = width;
shape = Shape.RECTANGLE;
}
public double area() {
switch (shape) {
case RECTANGLE:
return length * width;
case CIRCLE:
return Math.PI * (radius * radius);
default:
throw new AssertionError(shape);
}
}
}
Java
복사
⇒ 원(circle)과 사각형(rectangle)을 나타내는 클래스이고, 하나의 클래스에서 두 타입에 대응이 가능하다.
⇒ 얼핏보면 area() 메서드 하나로 타입별로 맞는 크기를 계산해 반환하기에 편해보인다.
하지만 이런 태그달린 클래스는 단점이 많다.
1.
열거 타입, 태그 필드, switch 문 부가적인 코드가 너무 많다.
2.
하나의 메서드에 여러 구현이 들어가있기에 가독성도 떨어지고 SRP 지침도 어긋난다.
3.
하나의 타입으로 정해지면 그외의 타입을 위한 코드는 모두 불필요한 코드가 되지만 항상 함께 있기에 메모리 낭비가 된다.
4.
필드가 final일 경우 필드 초기화시 매번 불필요한 필드도 초기화 해줘야 한다.
5.
새로운 타입이 추가될 때마다 분기가 필요한 모든 메서드에 새로운 타입에 대응하는 코드를 작성해야 한다.
6.
인스턴스의 타 입만으로 의미를 알기 쉽지 않다.
제안
•
클래스 계층구조를 활용하는 서브타이핑(subtyping)을 해보자.
1.
계층구조의 루트 추상 클래스를 정의한 뒤, 태그에 따라 동작이 달라지는 메서드들을 추상 메서드 선언.
2.
태그 값에 상관없이 동일한 동작을 하는 메서드를 루트클래스에 일반 메서드로 추가한다.
3.
루트 클래스를 확장한 구체 클래스를 의미별로 정의한다.
4.
루트 클래스의 추상 메서드를 구체 클래스에선느 각각 의미에 맞게 구현한다.
•
다음 코드는 계층 구조화가 된 Figure클래스다
public abstract class Figure{
abstract double area();
}
public class Circle extends Figure{
final double radius;
public Circle(double radius) {
this.radius = radius;
}
@Override
double area() {
return Math.PI * (radius * radius);
}
}
public class Rectangle extends Figure{
private final double length;
private final double width;
public Rectangle(double length, double width) {
this.length = length;
this.width = width;
}
@Override
double area() {
return length * width;
}
}
Java
복사
⇒ 기존 구조의 단점을 모두 없앴다.
⇒ switch 구문, 열거타입, 불필요한 필드정보들이 모두 분리되서 사라졌다.
⇒ switch 문에서 default로 AssetionError가 발생할 일도 사라졌다.
⇒ 타입 사이의 자연스러운 계층 관계를 반영할 수 있어 유연성 및 컴파일 타임 검사 능력도 높혀준다.
정리
태그 달린 클래스가 사용되야하는 상황은 거의 없고, 대부분 계층 구조로 해결이 된다.
기존 클래스가 태그 필드를 사용해 구분하고 있다면 리팩터링을 고려할 필요가 있다.
24. 멤버 클래스는 되도록 static으로 만들어라
중첩 클래스(nested class)
클래스 안에 정의된 클래스
ex: Map의 Entry, Calculator의 Operation ...
사용 목적
•
중첩 클래스를 감싼 바깥 클래스에서 사용하기 위해 존재한다.
•
그 외의 경우에는 톱 레벨 클래스로 만들어야 한다.
종류
•
정적 멤버 클래스
•
(비정적) 멤버 클래스
•
익명 클래스
•
지역 클래스
다음으로 이런 중첩 클래스를 하나하나 살펴보며 각각의 중첩 클래스의 사용시점과 사용목적을 알아보고 되도록 static으로 만들어 정적 멤버 클래스로 만들어야 할 이유에 대해 살펴보자.
정적 멤버 클래스
1.
특징
•
다른 클래스 안에 선언되는 클래스
•
바깥 클래스의 private 멤버에도 접근할 수 있다.
•
다른 정적 멤버(필드)와 동일한 접근 규칙을 적용받는다.
⇒ ex: 접근 제어자가 private이면 바깥 클래스에서만 접근할 수 있다.
2.
사용처
•
바깥 클래스와 함께 사용될 때 유용한 public 도우미 클래스로 사용된다.
⇒ ex: Calculator의 Operation 열거 타입(Calculator.Operation.PLUS)
3.
비정적 멤버 클래스와의 차이점
•
정적 멤버 클래스는 바깥 클래스의 인스턴스와의 암묵적 연결이 되어있지 않다. 그래서 클래스 내부에서 바깥 클래스의 멤버필드에 접근할수가 없다. 하지만 비정적 멤버 클래스같은 경우 다음과 같이 정규화된 this( 클래스명.this) 형태로 바깥 인스턴스의 메서드를 호출하거나 참조를 가져올 수 있다.
public class Item {
private String name;
private NestedClass nestedClass;
public Item(String name) {
this.name = name;
this.nestedClass = new NestedClass("nestecClassName-" + name);
}
public void printNames() {
nestedClass.printNames();
}
private class NestedClass {
private String name;
public NestedClass(String name) {
this.name = name;
}
public void printNames() {
System.out.println("this.name = " + this.name);
//정규화된 this를 이용해 바깥 클래스의 멤버를 가져온다.
System.out.println("Item.this.name = " + Item.this.name);
}
}
}
...
public class ItemApp {
public static void main(String[] args) {
Item test = new Item("test");
test.printNames();
}
}
Java
복사
⇒ [실행 결과]

•
정적 멤버 클래스는 바깥 클래스의 인스턴스와의 암묵적 연결이 되어있지 않다. 그래서 클래스 내부에서 바깥 클래스의 멤버필드에 접근할수가 없다. 하지만 비정적 멤버 클래스같은 경우 다음과 같이 정규화된 this( 클래스명.this) 형태로 바깥 인스턴스의 메서드를 호출하거나 참조를 가져올 수 있다.
public class Item {
private String name;
private NestedClass nestedClass;
public Item(String name) {
this.name = name;
this.nestedClass = new NestedClass("nestecClassName-" + name);
}
public void printNames() {
nestedClass.printNames();
}
private class NestedClass {
private String name;
public NestedClass(String name) {
this.name = name;
}
public void printNames() {
System.out.println("this.name = " + this.name);
//정규화된 this를 이용해 바깥 클래스의 멤버를 가져온다.
System.out.println("Item.this.name = " + Item.this.name);
}
}
}
...
public class ItemApp {
public static void main(String[] args) {
Item test = new Item("test");
test.printNames();
}
}
Java
복사
⇒ [실행 결과]

•
정적 멤버 클래스는 바깥 클래스의 인스턴스 없이 생성이가능하지만, 비정적 멤버 클래스는 바깥 인스턴스 없이는 생성할 수 없다.
비정적 멤버 클래스
1.
특징
•
바깥 클래스의 인스턴스 없이는 생성할 수 없다.
•
멤버 클래스가 인스턴스화 될 때 비정적 멤버 클래스와 바깥 클래스의 인스턴스 사이의 관계가 확립되며 변경할 수 없다.
•
정규화된 this를 이용해 바깥 클래스의 인스턴스 참조를 가져올 수 있다.
2.
사용처
•
어댑터를 정의할 때 자주 사용된다.
⇒ 어떠한 클래스의 인스턴스를 감싸 다른 클래스의 인스턴스처럼 보이게 하는 뷰로 사용하는 것
⇒ ex: Map 인터페이스 구현체들의 컬렉션 뷰를 구현할 때 비정적 멤버 클래스를 사용한다.
public class MySet<E> extends AbstractSet<E> {
@Override
public Iterator<E> iterator(){
return new MyIterator();
}
private class MyIterator implements Iterator<E>{ ... }
}
Java
복사
3.
비정적 멤버 클래스의 문제점
•
바깥 인스턴스로의 숨은 외부 참조를 가지게 된다.
•
이 참조를 저장하기위해 시간과 공간이 소비된다.
•
가비지 컬렉션이 바깥 클래스의 인스턴스를 수거하지 못하는 메모리 누수가 발생할 수 있다.
•
참조가 눈에 보이지 않아 문제 의 원인을 찾기 힘들다.
•
즉, 멤버 클래스에서 바깥 인스턴스를 접근해야 하는 경우가 명확히 없다면 static을 붙혀 정적 멤버 클래스로 만들어라.
익명 클래스
1.
특징
•
이름이 없다. (익명이니까)
•
바깥 클래스의 멤버도 아니다.
•
쓰이는 시점에서 선언과 동시에 인스턴스가 만들어진다.
•
비정적인 문맥에서 사용될 때만 바깥 클래스의 인스턴스를 참조할 수 있다.
•
상수 표현을 위해 초기화된 final 기본 타입과 문자열 필드만 가질 수 있다.
2.
제약
•
선언한 지점에서만 인스턴스 생성이 가능하다.
•
instanceof 검사나 클래스의 이름이 필요한 작업은 수행 불가능하다.
•
여러 인터페이스 구현이나 인터페이스를 구현하는 동시에 다른 클래스 상속도 불가능하다.
•
익명 클래스를 사용하는 클라이언트는 익명클래스가 상위 타입에서 상속한 멤버외에는 호출할 수 없다.
•
표현식 중간에 등장하기에 코드가 길수록 가독성이 급격히 떨어진다.
3.
사용처
•
람다(Lambda) 지원 전에는 즉석에서 작은 함수 객체나 처리 객체를 만드는데 사용했다.
⇒ 이제는 람다로 해결한다.
•
정적 팩토리 메서드를 구현할 때 사용한다.
지역 클래스
1.
특징
•
가장 드물게 사용되는 중첩 클래스다.
•
지역변수를 선언할 수 있는 곳이면 실질적으로 어디서든 선언이 가능하다.
•
유효범위도 지역변수와 동일하다.
•
이름이 있고 반복해서 사용할 수 있다.
•
비정적 문맥에서 사용될 때만 바깥 인스턴스를 사용할 수 있다.
•
정적 멤버는 가질 수 없고 가독성을 위해 짧게 작성해야 한다.
그래서 왜 정적 멤버 클래스를 권장하는걸까?
각각의 중첩 클래스(Nested class)에 대한 설명에 권장될 이유들이 이미 작성되어있다. 하지만 다시 한 번 정리하면 지역 클래스나 익명 클래스는 그 사용처와 제약사항이 명확하다. 중첩 클래스가 한 메서드안에서만 사용되면서 인스턴스의 생성지점이 단 한 곳이고 해당 타입으로 쓰기 적당한 클래스나 인터페이스가 있다면 익명클래스를 만들고 그렇지 않으면 지역 클래스를 만들면 된다.
그럼 그외의 경우 비정적 멤버 클래스보다 정적 멤버 클래스가 권장 될 이유는 위에서 이미 밝혔듯이 비정적 멤버 클래스는 독립적일 수 없고 바깥 클래스와의 관계에 묶여버린다. 그 덕에 정규화된 this로 바깥 클래스의 인스턴스를 참조 할 수도 있지만, 굳이 사용 해야 하는 명확한 경우를 제외하고는 이런 참조는 불필요한 메모리 낭비만 가져온다. 더군다나 이런 참조는 암묵적이기 때문에 추적이 어렵고 가비지 컬렉터에서도 바깥 클래스의 인스턴스를 수거하지 못하게 할 수 있다.
그러니 명확하게 바깥 클래스의 인스턴스에 접근하여 멤버들을 참조해야할 이유가 있는게 아니라면 static을 붙혀 정적 멤버 클래스를 사용하도록 하자.
25. 톱레벨 클래스는 한 파일에 하나만 담으라
하나의 소스파일에 여러 클래스를 선언해도 에러가 발생하지는 않는다.
다음 코드는 하나의 소스파일에 여러 클래스를 담은 코드다.
class Apple {
public static final String name = "사과";
}
class Grape {
public static final String name = "포도";
}
Java
복사
Apple.java
public class AppleApp {
public static void main(String[] args) {
System.out.println(Apple.name +", "+ Grape.name);
}
}
Java
복사
Apple.java라는 소스파일에 Apple과 Grape 클래스를 둘 다 정의한 상태다. 일단 이 코드를 실행시켜보면
[사과, 포도] 라고 출력이 될 것이다.
근데 개발자가 실수로 동일한 클래스를 담은 Grape.java라는 소스파일을 만들수 있다.
class Grape {
public static final String name = "거봉";
}
class Apple {
public static final String name = "애플";
}
Java
복사
Grape.java
이렇게 Grape.java 라는 소스파일이 새로 생성되었지만 클래스 자체는 이전에 만든 Apple.java와 같으며 필드값만 다른 상태다. 다음 커맨드를 차례대로 작성하며 출력물을 확인해보자.
javac -d . AppleApp.java Apple.java
java [package path](ex: me.catsbi.effectivejavastudy.chapter3.item25).AppleApp
//실행 결과 -> 사과, 포도
javac -d . AppleApp.java Grape.java
java [package path](ex: me.catsbi.effectivejavastudy.chapter3.item25).AppleApp
//실행 결과 -> 애플, 거봉
Shell
복사
참고: 책과 다른점
책에서는 javac Main.java(==AppleApp.java) Desert.java(==Grape.java) 명령으로 컴파일 시 컴파일 오류가 발생한다고 하는데 JDK11 기준 에러는 발생하지 않는다.
문제점
하나의 소스파일에 여러 클래스를 작성할 경우 최상단에 노출되며 소스파일명과 동일한 클래스를 제외한 나머지 클래스들의 존재가 감춰진다. 톱레벨 클래스로 하나의 소스파일에 하나의 클래스만 존재할 경우 실수로라도 동일한 클래스를 다시 정의하는 문제는 발생하지 않을 것이다.
위에 작성한 커맨드를 실제로 수행하면 AppleApp의 수행결과가 달라진다. 컴파일 시점에 어느 소스파일을 컴파일 하느냐에 따라 결과가 달라지는데 클래스내에 숨겨있는 다른 클래스가 있다면 언제든 재정의될 위험이 있다.
제안
•
하나의 소스 파일에는 하나의 클래스만 작성하자. (톱 레벨 클래스는 다른 소스 파일로 분리하라.)

