
목차
개요

살아 있지만 틀린 게 나은가, 올바르지만 죽은 게 나은가?
- 제이 크렙스, 카프카와 젭슨에 대한 몇 가지 기록(2013)
이전 장(08. 분산 시스템의 골칫거리)에서 말했듯이 분산 시스템에서는 많은 부분에서 결함이 생길 수 있는데, 이러한 결함은 발생 시점에서 전체 서비스가 실패하고 사용자에게 오류 메세지를 보여주는게 가장 간단한 해결책이다.
하지만, 이 방법이 힘들다면 결함을 견뎌낼(tolerating), 방법을 찾아야 한다.
(결함이 생겨도 서비스가 올바르게 동작할 수 있도록 할 방법)
이번 장에서는 이전 장에서 언급했던
•
네트워크 패킷 손실
•
순서 변경
•
중복
•
시간 지연
과 같은 결함들에 대해 내결함성을 가지는 분산 시스템을 구축하는데 사용되는 몇 가지 알고리즘이나 프로토콜에 대해 알아보자.
일관성 보장
복제 DB는 대부분 최종적 일관성을 제공한다.
DB들간의 정보가 일시적으로는 다를 수 있어도 결국 최종적으로는 동일해져 읽기 요청에 같은 값을 반환한다는 의미이다. 결국 스스로 해결한다는 의미이기도 한데, 모든 복제본이 결국 같은 값으로 수렴되기를 기대하기에 최종적 일관성보단 수렴이 더 적절할지도 모른다.
하지만, 이건 매우 약한 보장으로 언제 복제본이 수렴될지에 대해선 모른다.
수렴되기 전에는 읽기 요청에 대해 값을 반환할지도 보장할 수 없고, 동일한 값을 반환하는 것에 대해서도 보장할 수 없다.
약한 보장만 제공하는 DB를 다룰 때는 그 제한을 알아야 하고 너무 많은 가정을 해서도 안된다.
대부분의 시간 동안 애플리케이션은 잘 동작할 수도 있기에 버그는 종종 미묘하며 테스트로 발견하기 어렵다. 최종적 일관성의 에지 케이스는 시스템에 결함이 있거나 동시성이 높을 때만 드러난다.
일관성이 강해질수록 시스템의 성능 혹은 내결함성에서 취약한 모습을 보일 수 있다.
하지만, 강한 보장은 올바르게 사용하기가 쉽기에 매력적이다. 중요한건 강한 보장이나 약한 보장이 아니라 여러 일관성 모델 중 필요에 맞는 적절한 일관성 모델을 찾는 것이다.
선형성
최종적 일관성을 지닌 DB에서 두 개의 다른 복제본에 같은 질문을 동시에 하면, 각기 다른 응답을 받을수도 있다. 여기서 DB의 복제본이 하나만 있다는 환상을 주고 클라이언트가 복제 지연에 대한 고민을 하지 않도록 하는게 선형성의 기반 아이디어다.
이런 선형성의 기반 하에 시스템에 (실제로는 여러개가 있더라도) 데이터 복사본은 하나만 있고, 그 데이터를 대상으로 수행하는 모든 연산이 원자적인 것처럼 보이게 만든다.
선형성 시스템에선 클라이언트가 쓰기를 성공및 완료하자마자 DB를 읽는 클라이언트는 방금 쓰여진 값을 볼 수 있어야 한다. DB의 복사본이 하나만 있다는 환상을 유지하는 것은 읽힌 값이 최근에 갱신된 값이며 뒤처진 캐시나 복제본에서 나온 값이 아니라고 보장해준다는 뜻이다.
즉, 다시 말해 선형성은 최신성 보장(recency guarantee)이다.
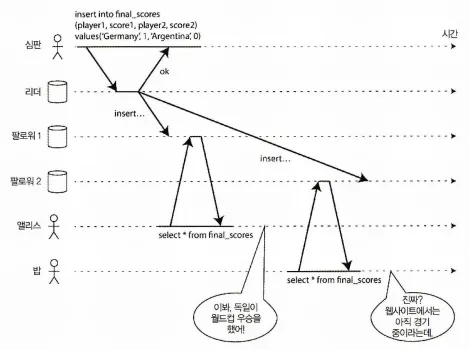
비선형 구조는 클라이언트를 혼란스럽게 한다.
위 그림은 비선형성 시스템의 문제를 보여준다.
경기 결과에 대해서 두 클라이언트가 읽기 요청을 하지만, 밥은 복제가 지연된 DB에서 읽기 요청을 해서 앨리스와 다른 결과를 보게 된다. 심지어, 밥은 앨리스의 조회 결과를 확인한 뒤 읽기요청을 한 것이기에 더 문제가 되며, 이러한 사실은 선형성 위반이다.
시스템에 선형성을 부여하는 것은 무엇인가?
그럼 어떻게 시스템이 데이터 복사본이 하나가 아니더라도 하나뿐인 것처럼 보이게 할 수 있을까?
그 전에 데이터 복사본이 하나가 아니더라도 하나뿐인 것처럼 보이게 이 말이 정확히 무슨 뜻인지 알 필요가 있다. 선형성을 잘 이해하기 위해 몇 가지 예를 더 살펴보자.
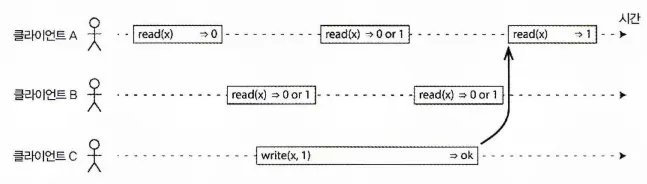
읽기 요청이 쓰기 요청과 동시에 실행되면 과거의 값, 새로운 값 무엇을 반환할지 알 수 없다.
위 그림은 선형성 DB에서 동시에 같은 키X를 읽고 쓰는 세 클라이언트를 보여준다.
분산 시스템 본야에서 X는 레지스터(register)라 부른다.
(키-값 저장소의 키 하나, DB의 Row하나, NoSQL의 document 하나가 될 수 있다.)
그림의 막대들은 클라이언트 관점에서 보낸 요청(막대의 시작)과 응답(막대의 끝)이다.
네트워크 지연의 불확실성으로 인해 클라이언트는 DB가 언제 자신의 요청을 처리했는지 알 수 없다.
이 예제에서 레지스터는
•
read(x) ⇒ v
◦
클라이언트가 레지스터X 의 값을 읽기를 요청했고 DB는 값 v를 반환했다는 것을 의미한다.
•
write(x, v)⇒ r
◦
클라이언트가 레지스터X의 값을 V로 설정하라 요청했고 DB가 응답 r(ok or error)을 반환했다는 것을 의미한다.
클라이언트 A와 C는 계속해서 DB Polling을 하며 최신 값을 읽으려 시도하고 클라이언트 C는 쓰기 요청을 통해 X의 값을 1로 설정하라고 했는데,
•
클라이언트 A는
◦
마지막 읽기 요청이 쓰기가 완료된 후 시작하기에 DB가 선형적이라면 1을 반환해야 한다.
•
클라이언트 B는
◦
쓰기 연산과 시간이 겹치기에 0 혹은 1을 반환할 수 있다. 읽기 연산의 처리 시점이 쓰기의 영향이 발생했는지 알 수 없다. 이러한 연산은 쓰기와 동시에 실행된다.
클라이언트 B의 읽기 요청과 같이 쓰기 연산과 동시에 실행되는 상황에서 발생하는 오래된 값과 새로운 값 사이의 잦은 이동은 데이터의 단일 복사본을 모방하는 시스템에서 적절하지 않다.
그렇기에 시스템을 선형적으로 만들기 위해 다음과 같이 제약 조건을 추가해야 한다.
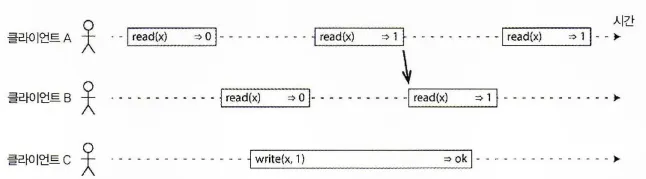
읽기가 새로운 값을 반환한 적이 있은 후엔 모든 후속 읽기(어떤 클라이언트에서 실행되든)도 반드시 새로운 값을 반환해야 한다.
선형적 시스템에서 우린 X의 값이 원자적으로 0에서 1로 바뀌는(쓰기 연산의 시작과 끝 사이의) 어떤 시점이 있어야 한다고 상상한다. 따라서 한 클라이언트의 읽기가 새로운 값 1을 반환하면 이후의 모든 읽기 또한 새로운 값을 반환해야 한다. 아직 쓰기 연산이 완료되지 않았더라도말이다.
타이밍 의존 관계가 위 그림에 화살표로 설명되어 있다.
클라이언트 A의 읽기가 반환된 후 클라이언트 B가 새로운 읽기를 시작한다. B는 A보다 이후의 시점에서 실행되기에 C가 실행한 쓰기가 아직 진행중이라도 1을 반환해야 한다.
이 타이밍 다이어그램을 더 개선해 어떤 시점에 원자적으로 영향을 주는 개별 연산을 시각화할 수 있다. 다음 그림을 보자.
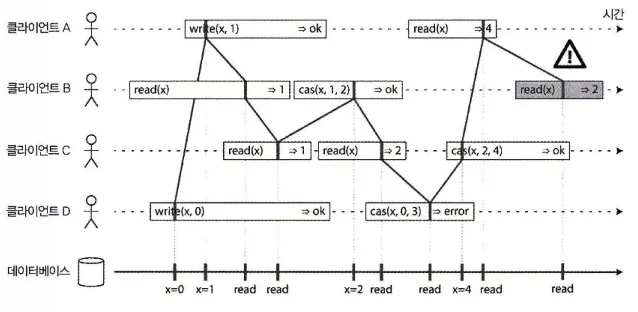
읽기/쓰기의 영향이 나타내는 것으로 보이는 시점을 시각화하기, B의 마지막 읽기는 선형적이지 않다.
위 그림에서는 기존 읽기와 쓰기 연산 외에 하나의 연산이 추가되었다.
•
◦
클라이언트가 compar-and-set 연산을 요청했다는 의미
▪
레지스터 x의 현재 값이 와 같으면 원자적으로 로 설정돼야 한다.
▪
X ≠ 라면 이 연산은 레지스터를 그대로 두고 오류를 반환해야 한다.
그림에는 연산이 실행됐다고 생각하는 시점이 각 막대에 수직선으로 표시돼 있다. 이 표시들이 모여 순차열을 이루고 이 결과가 레지스터에 실행된 읽기와 쓰기의 유효한 순차열이 돼야 한다.
Q. 위 그림에서 클라이언트 B의 마지막 읽기 요청은 어째서 2를 반환하는가? 4를 반환해야 하는 것 아닌가?
선형성 VS 직렬성
데이터의 일관성을 보장하기 위해 고려된 여러 방법 중 대표적인 두 가지인 선형성과 직렬성은 순차적인 순서로 배열될 수 있는 뭔가를 의미한다는 점에서 같다고 혼동하기 쉽다. 하지만 이 두 개념은 매우 다른 보장으로 구별을 할 필요가 있다.
•
직렬성은
◦
모든 트랜잭션이 여러 객체를 읽고 쓸 수 있는 상황에서의 트랜잭션들의 격리 속성으로 여러 대의 컴퓨터에서 일어나는 작업들을 순서에 맞게 일어나도록 보장하는 것을 의미한다. 그 순서가 트랜잭션들이 실제로 실행되는 순서와 달라도 상관은 없다.
◦
연산들의 순서를 엄격하게 보장한다.
•
선형성은
◦
레지스터(개별 객체)에 실행되는 읽기와 쓰기에 대한 최신성 보장이다.
◦
연산을 트랜잭션으로 묶지 않아서 충돌 구체화 같은 부가적인 수단을 사용하지 않으면 쓰기 스큐 같은 문제를 막지 못한다.
◦
여러 서버에서 동시에 일어나는 작업들을 순차적으로 정렬해 각 연산이 순차적으로 일어난 것과 같은 효과를 내는 것으로 분산 시스템에서 데이터의 일관성을 보장하게 해준다.
◦
연산의 순서를 덜 엄격하게 보장한다.
DB는 직렬성과 선형성을 모두 제공할 수도 있는데 이런 조합을 엄격한 직렬성(strict serializability)이나 강한 단일 복사본 직렬성(strong one-copy serializability, strong-1SR)이라고 한다.
그럼 선형성과 직렬성은 무슨 차이가 있을까?
선형성을 보장하는 분산 시스템에선 여러 작업들이 서로 다른 순서로 수행할 수 있지만, 직렬성을 보장하는 시스템에서는 모든 클라이언트가 동일한 순서로 작업을 수행해야 한다.
선형성과 직렬성중 어떤게 더 적합할까?
상황에 따라 다르다.
선형성은 연산의 순서를 덜 엄격하게 보장하기에 대규모의 분산 시스템에선 성능에 더 유리하다. 하지만, 이 경우 일부 클라이언트에서 작업 시점의 문제로 데이터의 일관성이 깨질 수 있다.
반면, 직렬성은 연산의 순서를 엄격하게 보장하기에 데이터의 일관성은 더 강하게 보장할 수 있다. 하지만, 이 경우에는 모든 클라이언트가 동일한 순서로 작업을 수행해야 하기 때문에, 대규모 분산 시스템에서는 성능에 제한이 있을 수 있다.
결론적으로, 상황에 맞춰 여러 방법을 조합해 최적의 시스템을 구축하는게 중요하며 선형성은 순서를 보장하고 직렬성은 복사본을 보장한다.
선형성에 기대기
선형성은 순서를 보장하기에 순서가 중요한 환경에서 유용하게 사용할 수 있을 것이다.
다음은 이러한 선형성이 중요하게 적용되는 몇 가지 영역에 대해 알아보자.
잠금과 리더 선출
단일 리더 복제를 사용하는 시스템은 리더가 하나만 존재하도록 보장해야 한다.
리더를 선출하는 한 가지 방법은 잠금을 사용하는 것이다.
모든 노드는 시작할 때 잠금 획득을 시도하고 성공한 노드가 리더가 된다.
이 잠금을 어떻게 구현하든지 선형적이어야 한다. 모든 노드는 어느 노드가 잠금을 소유하는지에 동의해야 한다.
분산 잠금과 리더 선출을 구현하기 위해
•
Apache ZooKeeper
•
etcd
와 같은 코디네이션 서비스가 종종 사용된다.
이들은 합의 알고리즘을 사용해 선형성 연산을 내결함성이 있는 방식으로 구현한다.
잠금과 리더 선출을 올바르게 구현하는 데는 미묘한 세부 사항이 여전히 많고(Ex: 펜싱 문제) Apache Curator같은 라이브러리는 주키퍼 위에 고수준 레시피를 제공해서 도움을 준다. 그러나 이런 코디네이션 작업에는 선형성 저장소 서비스가 기초적인 기반이 된다.
분산 잠금은 오라클 리얼 애플리케이션 클러스터(Oracle Real Application Cluster, RAC) 같은 분산 데이터베이스에서 훨씬 세분화된 수준으로 사용되기도 한다. RAC는 여러 노드가 동일한 디스크 저장 시스템을 공유해서 접근하며 디스크 페이지마다 잠금을 사용한다.
이런 선형성 잠금은 트랜잭션 실행의 중요 경로(critical path)에 있으므로 RAC를 배치할 때는 보통 DB 노드들 사이의 통신용으로 전용 클러스터 연결 네트워크를 사용한다.
합의 알고리즘
분산 시스템에서 노드 간 일관성을 유지하는 알고리즘으로 여러 노드에서 동시에 쓰기 요청을 할 때 어떤 노드의 데이터로 쓰기를 할지 결정하기 위해 사용된다. 많은 방법으로 구현될 수 있지만 일반적으로 노드 간 정족수로 판단하며 Paxos, Raft 등의 알고리즘이 있다.
Paxos
: Leslie Lamport가 개발한 합의 알고리즘으로, 단일 리더 모델을 사용하며 노드 간의 메시지 교환을 통해 합의를 이루는데 이해하기 어려운 알고리즘이라는 단점이 있다.
Raft
: Diego Ongaro와 John Ousterhout이 개발한 합의 알고리즘으로 리더와 팔로워, 후보자로 구성된 리더 기반 모델을 사용하는데, Paxos에 비해 더 이해하기 쉽고 많은 기능을 제공한다.
중요 경로(critical path)
어떤 작업을 처리하는 데 있어서, 해당 작업이 빠르게 수행되지 않으면 전체 작업이 느려지는 경로로써, 시스템의 성능을 결정하는 핵심적인 역할을 하기 때문에, 성능 개선을 위해 반드시 최적화가 필요하다.
제약 조건과 유일성 보장
유일성 제약 조건은 DB에서 흔하다. (Ex: 주민등록번호, 사용자명, 이메일 주소, …)
데이터가 기록될 때 이 제약 조건을 강제하고 싶을 경우 선형성이 필요하다.
이 상황은 잠금과 비슷한데, 사용자가 서비스에 가입할 때 사용자가 선택한 사용자명에 잠금을 획득하는 것으로 생각할 수 있고, 원자적 compare-and-set과도 비슷하다.
상황에 따라서 이런 제약 조건을 느슨하게 다뤄도 되고, 이런 경우 선형성이 필요 없을 수도 있지만 RDB에서 전형적으로 볼 수 있는 엄격한 유일성 제약 조건은 선형성이 필요하다.
채널 간 타이밍 의존성
앨리스가 점수를 외치지 않앗다면 밥은 자신의 질의 결과가 뒤처졌다는 것을 알지 못했을 것이다.
선형성 위반은 시스템에(앨리스의 목소리에서 밥의 귀로 이어지는) 부가적인 통신 채널이 있었기 때문에 발견됐다.
컴퓨터 시스템에서도 비슷한 상황이 발생할 수 있다.
이미지 업로드 API를 예로 들어보자. 사용자들은 이미지를 올릴 수 있고, 백그라운드에서는 사진 다운로드를 빠르게 할 수 있도록 저해상도(썸네일)로 바꾸는 로직이 다음 그림과 같이 동작한다.
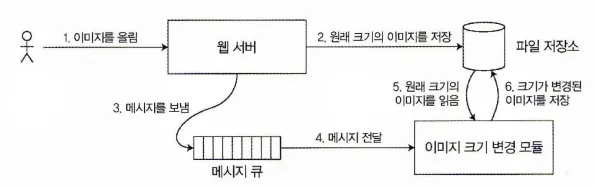
이 파일 저장 서비스가 선형적이라면 이 시스템은 잘 동작한다.
하지만, 선형적이지 않다면 경쟁 조건의 위험이 있다.
메세지 큐(3, 4단계)가 저장 서비스 내부의 복제(2 단계)보다 빠를 경우, 5~6단계를 수행하려고 할 때, 그 이미지의 과거 버전 혹은 아무것도 없을 수도 있다. 이 경우, 만약 과거 버전의 이미지를 처리한다면 이미지 불일치 문제가 발생할 것이다. 이 문제는 웹 서버와 크기 변경 모듈 사이에 두 가지 다른 통신 채널, 파일 저장소와 메시지 큐가 있기에 발생한다. 선형성의 최신성 보장이 없을 경우 이 두 채널 사이에 경쟁 조건이 발생할 수 있다.
선형성은 경쟁 조건을 회피하는 유일한 방법은 아니다.
선형성 시스템 구현하기
선형성 시맨틱을 제공하는 시스템을 어떻게 구현해야 할까?
선형성은 근본적으로
•
데이터 복사본이 하나만 있는 것처럼 동작하고 그 데이터에 실행되는 모든 연산은 원자적
이라는 것을 의미하기에 가장 간단한 해답은 데이터 복사본을 정말 하나만 사용하는 것이다.
하지만, 이 방법으로는 결함을 견뎌낼 수가 없다. (하나뿐인 복사본 저장 노드에 문제가 생길 경우 대응이 힘들다. )
5장 복제 챕터에서 다뤘던 복제 방법들을 다시 살펴보며 선형적으로 만들 수 있을지 비교해보자.
•
단일 리더 복제(선형적이 될 가능성 있음)
◦
선형적이 될 수 있는 이유
▪
리더는 쓰기에 사용되는 주 복사본을 가지고 있고 팔로워는 다른 노드에 데이터의 복사본을 보관한다.
▪
리더나 동기식으로 갱신된 팔로워에서 실행한 읽기는 선형적이 될 가능성이 있다.
◦
선형적이 안 될 수 있는 이유
▪
리더가 아닌 노드가 자신을 리더라고 생각하는 경우 해당 노드의 요청으로 인해 선형성을 위반하기 쉽다.
▪
비동기 복제를 사용하면 장애 복구를 할 때 커밋된 쓰기가 손실될 수도 있는데 지속성과 선형성을 모두 위반하는 것이다.
•
합의 알고리즘(선형적)
◦
합의 프로토콜에는 스플릿 브레인과 복제본이 뒤처지는 문제를 막을 수단이 포함되기 때문에 선형성 저장소를 안전하게 구현할 수 있다.
•
다중 리더 복제(비선형적)
◦
여러 노드에서 동시에 쓰기를 처리하고 그렇게 쓰여진 내용을 비동기로 다른 노드에 복제하기 때문에 일반적으로 선형적이지 않다.
•
리더 없는 복제(아마도 비선형적)
◦
리더 없는 복제를 하는 시스템에 대해 사람들은 때때로 정족수 읽기와 쓰기를 요구해 엄격한 일관성을 달성할 수 있다고 주장하지만, 엄격한 일관성을 어떻게 정의하냐에 따라 이 주장은 거짓이 될 수도 있다.
◦
일 기준 시계를 기반으로 한 최종 쓰기 승리(LWW) 충돌 해소 방법은 비선형적이다.
▪
시계 타임스탬프는 시계 스큐(clock skew)때문에 이벤트의 실제 순서와 일치하리라고 보장할 수 없기 때문이다.
▪
느슨한 정족수도 선형성의 가능성을 망친다.
선형성과 정족수
직관적으로 다이나모 스타일 모델에서 엄격한 정족수를 사용한 읽기 쓰기는 선형적인 것처럼 보인다. 하지만 다음 그림과 같이 네트워크 지연의 변동이 심하면 경쟁 조건이 생길 수 있다.
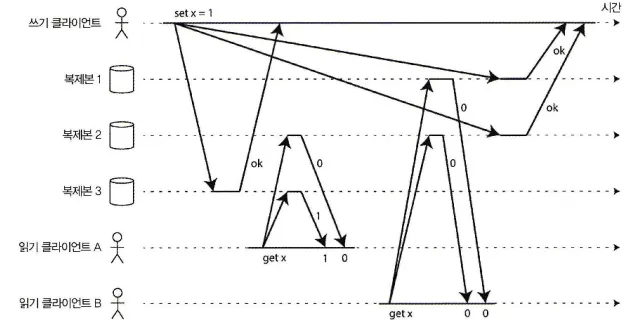
엄격한 정족수를 사용하지만 비선형적인 실행
•
x의 초기값은 0이고,
•
쓰기 클라이언트가 세 복제본에 모드 쓰기요청을 보내 x를 1로 갱신한다(n = 3, w = 3)
•
동시에 클라이언트 A는 두 노드로 구성된 정족수로부터 읽어서(r = 2)
◦
새로운 값 1을 본다.
•
동시에 클라이언트 B는 두 노드로 구성된 정족수로부터 읽어서(r = 2)
◦
두 노두 모두에서 예전 값 0을 본다.
정족수 조건이 만족(w + r > n)됨에도 이 실행은 선형적이지 않다.
성능이 떨어지는 비용을 감수하고 다이나모 스타일 정족수를 선형적으로 만드는 게 가능하다.
•
읽기 실행 클라이언트는 결과를 애플리케이션에 반환하기 전 읽기 복구를 동기식으로 수행해야 하고
•
쓰기 실행 클라이언트는 쓰기 요청을 보내기 전 노드들의 정족수로부터 최신 상태를 읽어야 한다.
하지만,
•
리악은 성능상 불이익 때문에 동기식 읽기 복구를 수행하지 않는다.
•
카산드라는 정족수 읽기를 할 때 읽기 복구가 완료되기를 기다리지만 최종 쓰기 충돌 해소 방법을 쓰기 때문에 같은 키에 여러 쓰기를 동시에 실행하면 선형성을 잃게 된다.
게다가 이 방법으론 선형성 읽기와 쓰기 연산만 구현할 수 있다.
선형성 compare-and-set 연산은 합의 알고리즘이 필요하기에 구현할 수 없다.
요약하면 다이나모 스타일 복제를 하는 리더 없는 시스템은 선형성을 제공하지 않는다고 보는게 가장 안전하다.
선형성의 비용
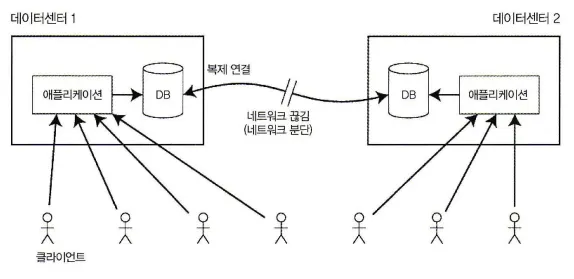
네트워크가 끊기면 선형성과 가용성 사이에서 선택해야만 한다.
복제 방법마다 선형성의 제공 여부는 다르다. 위 그림은 다중 리더 복제환경에서 네트워크가 끊긴 상황이다. 두 데이터센터 사이에 네트워크가 끊기면 무슨 일이 생길지 생각해 보자.
각 데이터센터 내부 네트워크는 동작하고 클라이언트들은 데이터센터에 접근할 수 있지만 데이터센터끼리는 서로 연결할 수 없다고 가정한다.
다중 리더 DB를 사용하면 각 데이터센터는 계속 정상 동작할 수 있다.
한 데이터센터에 쓰여진 내용이 비동기로 다른 데이터센터로 복제되므로 쓰기는 큐에 쌓였다가 네트워크 연결 복구 시점에 전달된다.
반면, 단일 리더 복제를 사용하면 리더가 데이터센터 중 하나에 있어야만 한다.
모든 쓰기와 선형성 읽기는 리더로 보내져야 한다. 따라서 팔로워 데이터센터로 접속한 클라이언트에서 보낸 읽기와 쓰기 요청은 네트워크를 통해 동기식으로 리더 데이터센터로 전송돼야 한다.
단일 리더 설정에서 데이터센터 사이의 네트워크가 끊기면 팔로워 데이터센터로 접속한 클라이언트들은 리더로 연결할 수 없으므로 데이터베이스에 아무것도 쓸 수 없고 선형성 일관성도 전혀 할 수 없다.
팔로워로부터 읽을 수는 있지만 데이터가 뒤처져서 비선형성이 발생할 수도 있다.
애플리케이션에서 선형성 읽기와 쓰기를 요구한다면 네트워크가 끊길 때 리더와 연결할 수 없는 데이터센터에서는 그 애플리케이션을 사용할 수 없다.
클라이언트가 리더 데이터센터로 직접 접속할 수 있다면 애플리케이션이 계속 정상 동작할 수 있기에 문제가 안된다. 하지만 팔로워 데이터센터로만 접속할 수 있는 클라이언트는 네트워크 링크가 복구될 때까지 중단을 경험한다.
CAP 정리
이런 문제는 단일 리더 복제, 다중 리더 복제의 결과만은 아니다.
어떤 선형성 데이터베이스라도 구현이 어떻게 됐는지에 상관없이 이 문제가 있다.
이 문제는 다중 데이터센터 배치에 특정된 것도아니고, 신뢰성이 없는 어떤 네트워크, 심지어 한 데이터센터 내에서도 발생할 수 있다. 트레이드 오프는 다음과 같다.
•
애플리케이션에서 선형성을 요구하고 네트워크 문제 때문에 일부 복제 서버가 다른 복제 서버와 연결이 끊기면 일부 복제 서버는 연결이 끊긴 동안은 요청을 처리할 수 없다. 네트워크 문제가 고쳐질 때까지 기다리거나 오류를 반환해야하는데 어떤 방법도 가용성이 없다.
•
애플리케이션에서 선형성을 요구하지 않는다면 각 복제 서버가 다른 복제서버(Ex: 다중 리더)와 연결이 끊기더라도 독립적으로 요청을 처리하는 방식으로 쓰기를 처리할 수 있다.
이 경우 애플리케이션은 네트워크 문제에 직면해도 가용한 상태를 유지하지만, 선형적이지 않다.
따라서 선형성이 필요 없는 애플리케이션은 네트워크 문제에 더 강인하다. 이런 통찰력은 CAP정리로 널리 알려졌다.
CAP는 원래 DB에서 트레이드오프에 대한 논의를 시작하려는 목적으로 정확한 정의 없이 경험 법칙으로서 제안됐다.
도움이 안 되는 CAP 정리
CAP는 때때로 일관성(Consistency), 가용성(Availability), 분단 내성(Partition tolerance) 이라는 세 개 중 두 개를 고르라는 것으로 표현된다.
하지만 이렇게 생각하는건 오해의 소지가 있으며, 네트워크 분단은 일종의 결함이기에 선택할 수 있는 무엇인가가 아니다.
네트워크가 잘 동작할 땐 시스템이 일관성(선형성)과 완전한 가용성 모두를 제공할 수 있다. 네트워크 결함이 생기면 선형성과 완전한 가용성 사이에서 선택해야 한다.
따라서 CAP는 네트워크 분단시 일관성과 가용성 중 하나를 선택하라는 의미로 보는게 좋다.
공식적으로 정의된 CAP는 매우 범위가 좁아 오직 하나의 일관성 모델(즉 선형성)과 한 종류의 결함(네트워크 분단)만 고려한다. 그래서 역사적인 가치를 떠나 실용적인 가치가 거의 없다.
선형성과 네트워크 지연
현실에서 실제로 선형적인 시스템은 드물다.
최신 다중코어 CPU의 램(RAM)조차 선형적이지 않는다.
이유는 모든 CPU 코어가 저마다 메모리 캐시와 저장 버퍼를 갖기 때문이다. 메모리 접근은 기본적으로 캐시로 먼저 가고 변경은 메인 메모리에 비동기로 기록된다. 캐시에 있는 데이터를 접근하는 게 메인 메모리로 가는 것보다 훨씬 더 빠르기에 이런 특성은 최신 CPU에서 좋은 성능을 내는 데 필수적이다.
하지만, 이제 데이터 복사본이 몇 개 생기고 이런 복사본은 비동기로 갱신되기에 선형성이 손실된다.
왜 이런 트레이드오프를 만들까? 선형성을 제거한 이유는 내결함성이 아닌 성능이다.
즉, 선형성을 희생하는 대신 시스템의 가용성과 내결함성을 높히기 위함이다.
선형성 보장을 제공하지 않기를 택한 여러 분산 데이터베이스에서도 마찬가지다. 내결함성이 아닌 성능을 향상시키기 위해서 그렇게 한다.
대부분의 컴퓨터 네트워크처럼 지연의 변동이 심한 환경에서 선형성 읽기와 쓰기의 응답 시간은 필연적으로 높아진다.
순서화 보장
선형성 레지스터는 데이터 복사본이 하나만 있는 것처럼 동작하고 모든 연산이 어느 시점에 원자적으로 효과가 나타나는 것처럼 보인다고 했다.
이 정의는 연산들이 순서대로 실행된다는 것을 암시한다.
순서화, 선형성, 합의 사이에는 깊은 연결 관계가 있다.
•
5장 복제 챕터에선 단일 리더 복제에서 리더의 주 목적이 복제 로그에서 쓰기의 순서, 즉 팔로워가 쓰기를 적용하는 순서를 결정하는 것이라 배웠고,
•
7장에서 직렬성은 트랜잭션들이 마치 어떤 일련 순서에 따라 실행되는 것처럼 동작하도록 보장하는 것과 관련돼 있다.
•
8장에서 설명한 분산 시스템에서 타임스탬프와 시계 사용은 무질서한 세상에 질서를 부여하려는 또 다른 시도로 두 개의 쓰기 중 어느 것이 나중에 일어났는지 결정하는 것을 하나의 예로 들 수 있다.
순서화와 인과성
순서화가 계속해서 나오고 있는데, 그 이유는 순서화가 인과성을 보존하는 데 도움을 주기 때문이다.
위에서 살펴본 인과성이 중요한 예 몇 가지를 다시 살펴보면
•
일관된 순서로 읽기에서 대화의 관찰자가 질문에 대한 응답을 먼저 보고 나서 응답된 질문을 보게했는데, 질문이 답변됐다면 반드시 그 질문이 먼저 있었어야 한다. 이를 가리켜 질문과 답변 사이에 인과적 의존성(causal dependency)이 있다고 말한다.
•
네트워크 지연 문제로 어떤 쓰기가 다른 쓰기를 추월할 수 있다.
•
동시 쓰기 감지에서 두 개의 연산(A, B)이 있으면 세 가지 가능성이 있음을 봤다. A와 B사이의 이전 발생(happened before) 관계가 인과성을 표현하는 다른 방법이다.
인과성은
•
이벤트에 순서를 부과한다.
•
결과가 나타나기전에 원인이 발생한다.
•
메세지를 받기 전에 메세지를 보낸다.
•
답변하기 전에 질문을 한다.
시스템이 인과성에 의해 부과된 순서를 지키면 그 시스템은 인과적으로 일관된(causally consistent)이라고 한다. 스냅숏 격리는 인과적 일관성을 제공한다.
인과적 순서가 전체 순서는 아니다
전체 순서(total order)는 어떤 두 요소를 비교할 수 있게 하므로 두 요소가 있으면 항상 어떤 것이 더 크고 작은지 말할 수 있다. 예를 들어 자연수는 전체 순서를 정할 수 있다.
하지만, 수학적 집합은 항상 순서를 정할 수 있는 것은 아니다. 집합 관계같은 경우 어느 것도 다른 것의 부분 집합이 아닐 경우 비교할 수 없다. 이런 것은 비교불가(incomparable)하고 따라서 수학적 집합은 부분적으로 순서가 정해진다(partially ordered).
전체 순서와 부분 순서의 차이점은 다른 DB 일관성 모델에 반영된다.
•
선형성
◦
선형성 시스템에선 연산의 전체 순서를 정할 수 있다.
•
인과성
◦
두 연산 중 어떤 것도 다른 것보다 먼저 실행되지 않았다면 두 연산이 동시적이라고 말했다.
◦
달리 말해 두 이벤트에 인과적인 관계가 있으면 이들은 순서가 있지만 이들이 동시에 실행되면 비교할 수 없다. 인과성이 전체 순서가 아닌 부분 순서를 정의한다는 뜻이다.
어떤 연산들은 서로에 대해 순서를 정할 수 있지만 어떤 연산들은 비교할 수 없다.
이 정의에 따르면 선형성 데이터스토어엔 동시적 연산이 없다.
하나의 타임라인이 있고 모든 연산은 그 타임라인을 따라 전체 순서가 정해져야 한다.
동시성은 타임라인이 갈라졌다 다시 합쳐지는 것을 의미하며, 이 경우 다른 가지에 있는 연산은 비교 불가(즉 동시적) 하다.
선형성은 인과적 일관성보다 강하다
Q. 인과적 순서와 선형성 사이에는 어떠한 관계가 있을까?
A. 선형성은 인과성을 내포한다.
어떤 시스템이든지 선형적이라면 인과성도 올바르게 유지한다.
하지만, 선형적인 시스템은 네트워크 지연이 클수록 성능과 가용성에 해가 될 수 있다. 이런 이유로 어떤 분산 데이터 시스템은 선형성을 포기하고 성능을 취하기도 하지만 사용하긴 더 어렵다.
그래서 절충하는 방안이 있다.
선형성은 인과성을 보존하는 유일한 방법은 아니다. 시스템은 선형적으로 만드는 성능 손해를 유발하지 않고도 인과적 일관성을 만족시킬 수 있다. 사실 인과적 일관성은 네트워크 지연 때문에 느려지지 않고 네트워크 장애가 발생하도 가용한 일관성 모델 중 가장 강한 것이다.
사실 많은 선형성을 요구하는 시스템에서 실제로 진짜 필요한 것은 인과적 일관성이다.
그리고 이는 더 효율적으로 구현될 수 있다.
인과적 의존성 담기
비선형성 시스템이 어떻게 인과적 일관성을 유지할 수 있는지 핵심 아이디어 중 일부만 간단히 살펴보자.
•
인과성을 유지하기 위해 어떤 연산이 다른 연산보다 먼저 실행됐는지 알아야 한다.
◦
이것은 부분 순서다.
•
복제 서버는 연산을 처리할 때 인과적으로 앞서는 모든 연산(먼저 실행된 모든 연산)이 이미 처리됐다고 보장할 수 있어야 한다.
•
선행 연산 중 빠진 게 있으면 후속 연산은 그 선행 연산이 처리될 때까지 기다려야 한다.
⇒ 리더 없는 데이터스토어의 인과성을 설명했다.
리더 없는 데이터 저장소는 갱신 손실 방지를 위해 같은 키에 대한 동시 쓰기를 검출해야 한다.
인과적 의존성은 여기서 더 나아가 단일 키 뿐 아니라 전체 DB에 걸친 인과적 의존성을 추적해야 한다. 이를 위해 버전 벡터(version vector)를 일반화할 수 있다.
인과적 순서를 결정하기 위해 DB는 애플리케이션이 데이터의 어떤 버전을 읽었는지 알아야 한다. 직렬성 스냅숏 격리(SSI)에서 설명한 SSI의 충돌 검출에서도 비슷한 아이디어가 나타난다.
트랜잭션이 커밋을 원할 때 DB는 읽은 데이터의 버전이 여전히 최신인지 확인한다.
이런 목적으로 DB는 어떤 데이터를 어떤 트랜잭션이 읽었는지 추적한다.
참고: 인과적 일관성을 보장하는 몇 가지 패턴들
선형성을 보장하는건 비용이 많이든다. 그렇기에 선형성을 보장하는 것 대신 인과적 일관성을 효율적으로 구현하는 방법이 필요한데, 몇 가지 패턴들에 대해 알아보자.
•
이벤트 소싱 패턴
◦
DB에 저장된 모든 상태 변경 사항을 이벤트 로그로 기록한다.
◦
이벤트 로그는 모든 작업이 순서대로 기록되는 것을 보장하며 이를 통해 인과적 일관성을 유지한다.
◦
추가적으로 해당 패턴을 사용해 이벤트 데이터를 다양한 방법으로 검색할 수도 있다.
•
비동기 메시지 패턴
◦
각 서비스가 메시지를 비동기적으로 처리하도록 해 성능을 향상시킨다.
◦
전송자는 중간 매개체(ex: broker)에 메세지를 보내고 매개체에선 메시지를 처리한 뒤 수신자에게 전달하는데, 이 중간 매개체를 이용해 메시지 전송과 수신의 시점을 분리할 수 있어서 전송과 수신 사이의 인과적 순서를 보장할 수 있다.
•
분산 트랜잭션 패턴
◦
서비스 간의 트랜잭션을 관리하기 위한 방법
◦
2PC (Two-Phase Commit) 프로토콜을 이용해 인과적 일관성을 보장한다.
1.
준비: 각 클라이언트는 트랜잭션 수행 가능 상태를 확인하고 트랜잭션 수행에 필요한 리소스 확보 및 로컬 트랜잭션을 수행한다.
2.
투표: 각 클라이언트는 트랜잭션 수행 여부에 대한 투표를 하고, 모든 참여자에게 자기가 준비가 끝났다는 것을 알리고 트랜잭션을 커밋할 수 있는지 투표한다.
3.
커밋: 트랜잭션을 수행할 수 있는 모든 클라이언트들이 투표를 마치면 커밋이 시작된다. 모든 클라이언트들은 커밋 메세지를 보내고 로컬 트랜잭션을 커밋한다.
▪
클라이언트 중 하나라도 실패하면 모든 트랜잭션은 롤백한다.
▪
But, 높은 레이턴시와 복잡성을 가지기에 성능 이슈가 있을 수 있다.
일련번호 순서화
모든 인과적 의존성을 실제로 추적하는 것은 실용적이지 않다.
그래서 일련번호나 타임스탬프를 써서 이벤트의 순서를 정할 수 있다. 타임스탬프는 일 기준 시계에서 얻을 필요도 없고 논리적 시계에서 얻어도 된다.
이런 일련번호나 타임스탬프는 크기가 작고 전체 순서를 제공한다.
즉 모든 연산은 고유 일련번호를 갖고 항상 두 개의 일련번호를 비교해서 어떤 거싱 큰지(어떤 연산이 나중에 실행됐는지) 결정할 수 있다.
특히 인과성에 일관적인 전체 순서대로 일련번호를 생성할 수 있다.
연산 A가 연산B보다 인과적으로 먼저 실행됐다면 A는 전체 순서에서도 B보다 먼저다.
단일 리더 복제를 쓰는 DB에선 복제 로그가 인과성에 일관적인 쓰기 연산의 전체 순서를 정의한다. 리더는 연산마다 카운터를 증가시키고 복제 로그의 각 연산에 단조 증가하는 일련번호를 할당하기만 하면 된다. 팔로워가 복제 로그에 나오는 순서대로 쓰기를 적용하면 팔로워의 상태는 언제나 인과성에 일관적이다.
비인과적 일련번호 생성기
단일 리더가 없다면(다중 리더이거나 리더 없는 DB를 사용하거나 DB가 파티셔닝돼서) 연산에 사용할 일련번호를 생성하는 방법이 명확해 보이지 않는다.
이 경우,
•
각 노드가 자신만의 독립적인 일련번호 집합을 생성할 수 있다.
◦
노드가 두 대 인경우 하나는 홀수만 하나는 짝수만 생성한다.
◦
일련번호의 이진 표현에서 몇 비트를 예약해서 공유 노드 식별자를 포함할 수 있다.
•
각 연산에 일 기준 시계(물리적 시계)에서 얻은 타임 스탬프를 붙일 수 있다.
◦
순차적이지는 않지만 해상도가 충분하다면 연산의 전체 순서를 정하는 데 충분할 수도 있다.
◦
LWW에서 사용된다.
•
일련번호 블록을 미리 할당할 수 있다.
◦
Node A 는 1~1,000까지의 블록을
◦
Node B 는 1,001 ~ 2,000까지의 블록을 차지할 수 있다.
이 세 가지 방법 모두 잘 동작하고, 카운터를 증가시키는 단일 리더에 모든 연산을 밀어넣는 것 보다 확장성이 좋다. 각각이 고유한 근사 증가(approximately increasing) 일련번호를 생성하는데, 문제는 인과성에 일관적이지 않다.
인과성 문제는 일련번호 생성기들이 여러 노드에 걸친 연산들의 순서를 올바르게 담지 못하게 때문에 발생한다.
•
각 노드는 초당 연산수가 다를 수 있다.
◦
짝수용 카운터가 홀수용 카운터보다 뒤처지거나 반대 상황이 발생할 수 있다.
•
물리적 시계에서 얻은 타임스탬프는 시계 스큐에 종속적이어서 인과성에 일관적이지 않게 될 수 있다.
•
블록 할당자의 경우 한 연산이 1,001과 2,000 사이의 구간에서 일련번호를 받고 인과적으로 나중에 실행되는 연산이 1 ~ 1,000 사이의 구간에서 일련번호를 받을 수도 있다.
램포트 타임스탬프
인과성에 일관적인 일련번호를 생성하는 간단한 방법으로 램포트 타임스탬프(Lamport timestamp)가 있다.
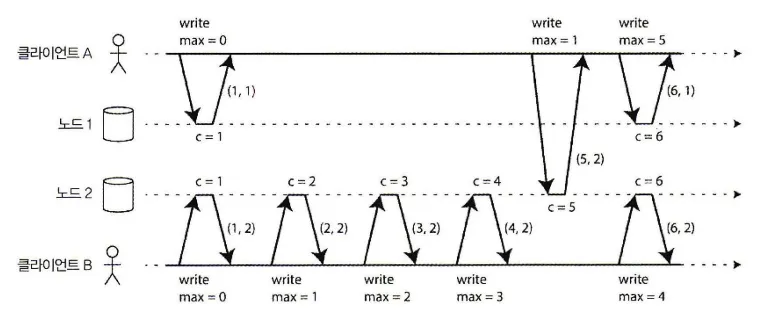
램포트 타임스탬프는 인과성에 일관적인 전체 순서화를 제공한다.
•
각 노드는 고유 식별자를 갖고 각 노드는 처리한 연산 개수를 카운터로 유지한다.
•
램포트 타임스탬프는 그냥(카운터, 노드ID)의 쌍이다.
•
두 노드는 때때로 카운터 값이 같을 수 있지만 타임스탬프에 노드ID를 포함시켜 중복되지 않게 한다.
•
램포트 타임스탬프는 물리적 일 기준 시계와 관련 없지만 전체 순서화를 제공한다.
•
모든 노드와 모든 클라이언트가 카운터 값 중 최댓값을 추적하고 모든 요청에 그 최댓값을 포함시킨다.
◦
노드가 자신의 카운터 값보다 큰 최대 카운터를 가진 요청이나 응답을 받으면 바로 자신의 카운터를 그 최댓값으로 증가시킨다.
위 그림을 보면 클라이언트 A는 노드 2로부터 카운터 값 5를 받고 노드 1에게 최댓값 5를 보낸다. 그때 노드 1의 카운터는 1이었지만 바로 5로 바뀌고 따라서 다음 연산은 증가된 카운터 값 6을 갖는다.
모든 연산에 최대 카운터 값이 따라다니는 한 이 방법은 램포트 타임스탬프로부터 얻은 순서가 인과성에 일관적이도록 보장해준다. 모든 인과적 의존성이 타임스탬프를 증가시키기 때문이다.
이 램포트 타임스탬프는 동시 쓰기 감지의 버전 벡터와 비슷하지만 목적이 다르다.
버전 벡터는 두 연산이 동시적인지 또는 어떤 연산이 다른 연산에 인과적으로 의존하는지 구별할 수 있지만 램포트 타임스탬프는 항상 전체 순서화를 강제한다.
램포트 타임스탬프는 전체 순서화로부터 두 연산이 동시적인지 혹은 인과적으로 의존성이 있는지를 알 수는 없다. 버전 벡터보다 램포트 타임스탬프가 좋은 점은 크기가 더 작다는 것이다.
타임스탬프 순서화로는 충분하지 않다.
램포트 타임스탬프로는 분산 시스템의 여러 공통 문제를 해결하기에는 부족함이 있다.
예를 들어, 사용자명으로 사용자 계정을 유일하게 식별할 수 있도록 보장해야 하는 시스템을 고려해보자. 두 사용자가 동시에 동일한 사용자명으로 계정을 생성하려고 하면 둘 중 한 명은 성공하고 다른 사람은 실패해야 한다 .
이 역시 램포트 타임스탬프로 충분히 해결할 수 있을 것으로 보인다.
타임스탬프가 더 낮은것을 성공한것으로 판단하는 식으로 시스템에서 사용자명 생성 연산을 모두 모아 타임스탬프를 비교해서 결정할 수 있다.
하지만, 노드가 사용자로부터 사용자명 생성 요청을 막 받고 그 요청의 성공 혹은 실패 여부를 당장 결정해야 할 때는 램포트 타임스탬프로는 부족하다.
(다른 노드가 동시에 동일한 사용자명으로 계정 생성을 처리하고 있는지와 다른 노드가 그 연산에 어떤 타임스탬프를 배정할지 알지 못한다.)
결국 문제는 연산의 전체 순서가 연산을 모두 모은 뒤에 드러난다는 점이다.
다른 노드가 어떤 연산을 생성했지만 그것이 무엇인지 아직 알 수 없다면 연산의 최종 순서를 만들어낼 수 없다. 이 문제를 해결하기 위해서는 연산의 전체 순서 뿐 아니라 그 순서가 언제 확정되는지도 알아야 한다.
언제 전체 순서가 확정되는지 알아야 한다는 아이디어는 전체 순서 브로드캐스트에서 알아보자.
전체 순서 브로드캐스트
분산 시스템에서 모든 노드의 연산의 전체 순서가 동일하도록 합의하기는 까다롭다.
타임스탬프, 일련번호를 사용해도 단일 리더 복제만큼 강력하지는 않다.
단일 리더 복제는 한 노드를 리더로 선택해 리더의 단일 CPU 코어에서 모든 연산을 차례대로 배열하고 연산의 전체 순서를 정한다. 이 경우 다음 사항을 고민해볼 수 있다.
1.
처리량이 단일 리더 처리량을 넘어설 때 어떻게 시스템 확장을 할 것인가
2.
리더에 장애가 발생했을 때 어떻게 장애 복구를 처리할 것인가
분산 시스템 분야에서 이 문제는 전체 순서 브로드캐스트(total order broadcats)나 원자적 브로드캐스트(atomic broadcast)로 알려져 있다.
참고: 순서화 보장의 범위
파티션마다 단일 리더를 갖도록 파티셔닝된 DB는 종종 각 파티션에서만 순서를 유지하는데 이는 여러 파티션에 걸친 일관성 보장(Ex: 일관된 스냅숏, 외래 키 참고)을 제공할 수 없다는 뜻이다. 모든 파티션에 걸친 전체 순서화도 가능하긴 하지만 추가적인 코디네이션이 필요하다.
전체 순서 브로드캐스트는 보통 노드 사이에 메시지를 교환하는 프토토콜로 기술된다.
비공식적으로는 두 가지 안전성 속성을 항상 만족해야 한다.
신뢰성 있는 전달(reliable delivery)
어떤 메시지도 손실되지 않는다. 메시지가 한 노드에 전달되면 모든 노드에도 전달된다.
전체 순서가 정해진 전달(totally ordered delivery)
메시지는 모든 노드에 같은 순서로 전달된다.
전체 순서 브로드캐스트를 구현하는 올바른 알고리즘은
•
노드나 네트워크에 결함이 있더라도
◦
신뢰성과 순서화 속성이 항상 만족되도록 보장되야 한다.
•
네트워크가 끊긴 동안 메시지는 전달될 수 없지만
◦
알고리즘이 계속 재시도를 해서 네트워크가 복구되면 메시지가 전달되게 할 수 있다.
◦
이때도 메시지는 올바른 순서로 전달돼야 한다.
전체 순서 브로드캐스트 사용하기
주키퍼, etcd같은 합의 서비스는 전체 순서 브로드캐스트를 실제로 구현한다.
(합의와 전체 순서 브로드캐스트에는 강한 연관이 있다는 의미이기도 하다.)
전체 순서 브로드캐스트는 DB 복제에 딱 필요한 것이다.
모든 메시지가 DB에 쓰기를 나타내고 모든 복제 서버가 같은 쓰기 연산을 같은 순서로 처리하면 복제 서버들은 서로 일관성 있는 상태를 유지한다.
이 원리를 상태 기계 복제(state machine replication)라고 한다.
타임스태프에 비해 전체 순서 브로드캐스트가 강력한 이유는 순서의 고정에 있다.
전체 순서 브로드캐스트는 후속 메시지가 전달됐다면, 메시지를 중간에 끼워넣을 수 없다.
그리고 전체 순서 브로드캐스트는 로그 모니터링에서도 유용하다.
모든 노드가 같은 메시지를 같은 순서로 전달해야 하는데, 순서가 고정된 전체 순서 브로드캐스트에서는 동일한 순서의 동일한 메세지를 볼 수 있다.
또한, 전체 순서 브로드캐스트는 펜싱 토큰을 제공하는 잠금 서비스 구현에도 유용하다. 잠금을 획득하는 모든 요청은 메시지로 로그에 추가되고 모든 메시지들은 로그에 나타난 순서대로 일련번호가 붙는다. 이 일련번호는 단조 증가하기에 펜싱 토큰의역할을 할 수 있다.
etcd
가용성을 보장하며 분산된 key-value 저장소로서, 분산 시스템의 구성요소들 간의 정보 전달을 위해 사용되는 합의 알고리즘인 Raft를 사용하여 데이터 일관성을 유지한다.
대규모 분산 시스템에서 사용될 수 있는 다양한 기능을 제공하며, Kubernetes 같은 컨테이너 오케스트레이션 시스템에서도 사용된다.
또한 HTTP/2 API를 제공하여 간편하게 데이터를 읽고 쓸 수 있으며 etcd의 데이터는 안전성을 보장하기 위해 디스크에 지속적으로 저장되며, 이를 통해 장애 발생 시 데이터 손실을 방지할 수 있다. Go 언어로 작성되었다.
전체 순서 브로드캐스트를 사용해 선형성 저장소 구현하기
전체 순서 브로드캐스트와 선형성 시스템은 모두 전체 순서가 있다.
그렇기에 이 둘 사이에는 밀접한 관계가 있다.
전체 순서 브로드캐스트는 비동기식이다. 메시지는 고정된 순서로 신뢰성 있게 전달되도록 보장되지만 언제 전달될지는 보장되지 않는다. 그에 반해 선형성은 최신성 보장이다. 읽다가 최근에 쓰여진 값을 보는 게 보장된다.
그러나 전체 순서 브로드캐스트 구현이 있다면 이를 기반으로 선형성 저장소를 만들 수 있다.
예를 들어 사용자명으로 사용자 계정을 유일하게 식별하도록 보장할 수 있다.
사용 가능한 모든 사용자명마다 원자적(compare-and-set)연산이 구현된 선형성 저장소를 가질 수 있다고 하자. 모든 레지스터는 초기에 null 값을 가지며 사용자가 사용자명을 생성하기를 원할 때 해당 사용자명에 해당하는 레지스터에 compare-and-set연산을 실행해 레지스터의 이전 값이 null이라는 조건하에 그 값을 사용자 계정 ID로 설정한다.
전체 순서 브로드캐스트를 추가 전용 로그로 사용해 선형성 compare-and-set연산을 다음과 같이 구현할 수 있다.
1.
메시지를 로그에 추가해 점유하기 원하는 사용자명을 시험적으로 가리킨다.
2.
로그를 읽고, 추가한 메시지가 되돌아오기를 기다린다.
3.
원하는 사용자명을 점유하려고 하는 메시지가 있는지 확인한다.
a.
원하는 사용자명에 해당하는 첫 번째 메시지가 자신의 것이라면 성공
b.
다른 사용자가 보낸 것이라면 연산을 어보트시킨다.
이러한 방식은 선형성 쓰기는 보장하지만 선형성 읽기는 보장하지 않는다. 그래서 읽기도 선형적으로 만들려면 몇 가지 선택지가 있다.
•
로그를 통해 순차 읽기를 할 수 있다.
◦
로그에 메시지를 추가하고 로그를 읽어 메시지가 되돌아왔을 때 실제 읽기를 수행한다.
◦
로그 상의 메시지 위치는 읽기가 실행된 시점을 나타낸다.
•
로그에서 최신 로그 메시지의 위치를 선형적 방법으로 얻을 수 있다면 그 위치를 질의하고 그 위치까지의 모든 항목이 전달되기를 기다린 후 읽기를 수행할 수 있다.
•
쓰기를 실행할 때 동기식으로 갱신돼서 최신이 보장되는 복제 서버에서 읽을 수 있다.
선형성 저장소를 사용해 전체 순서 브로드캐스트 구현하기
위에서 본 것과 반대로 선형성 저장소가 있을 때 이를 기반으로 전체 순서 브로드캐스트를 구현하는 것도 가능하다.
가장 쉬운 방법은 정수를 저장하고 원자적 increment-and-get 연산이 지원되는 선형성 레지스터가 있다고 가정하는 것이다.
알고리즘은
•
보내고 싶은 모든 메시지에 대해 선형성 정수로 increment-and-get연산을 수행하고
•
레지스터에서 얻은 값을 일련번호로 메시지에 붙힌다.
•
이후 메시지를 모든 노드에 보낼 수 있고(메시지 손실시 재전송), 수신자들은 일련번호 순서대로 메시지를 전달한다.
램포트 타임스탬프완 다르게 선형성 레지스터를 증가시켜 얻은 숫자들은 틈이 없는 순열을 형성한다. 따라서 어떤 메시지 4를 전달하고 일련번호가 6인 메시지를 받았다면 메시지 6을 전달하기 전 메시지5를 기다려야 한다는 것임을 알 수 있다.
램포트 타임스탬프에선 그렇지 않고, 이 부분이 전체 순서 브로드캐스트와의 핵심 차이다.
원자적 연산 increment-and-get이 지원되는 선형성 정수를 만드는건 얼마나 힘들까?
실패가 없다면 오히려 쉽다. 노드하나에 변수 하나만 저장하면 된다. 문제는 그 노드와 네트워크 연결이 끊긴 상황을 처리하고 노드에 장애가 발생할 때 그 값을 복구하는데 있다.
일반적으로 선형성 일련번호 생성기에 대해 고민하다보면 필연적으로 합의 알고리즘에 도달하게 되는데 이는 우연이 아니고 선형성 compare-and-set(or increment-and-get)레지스터와 전체 순서 브로드캐스트는 둘 다 합의와 동등하다고(equivalent to consensus)증명할 수 있다.
분산 트랜잭션과 합의
분산 컴퓨팅에서 합의란 매우 중요한 개념이고, 근본적인 문제 중 하나이기도 하다.
합의는 여러 노드들이 무엇인가에 동의하게 만드는 것에 그 목적이 있다. 그저 동의만 얻으면 된다고 생각해서 어렵지 않다고 생각할 수 있지만, 현재 고장나고 있는 많은 시스템들이 이런 이유로 문제가 생겼다.
그럼 언제 노드들이 동의하는것이 중요해질까?

끄덕
•
리더 선출
◦
단일 리더 복제를 사용하는 경우 DB에서 모든 노드는 어떤 노드가 리더인지 동의해야 한다.
◦
기존의 리더 노드가 네트워크 문제로 통신이 불가해지면 새로운 리더 선출을 위해 노드간에 경쟁할 수 있다.
◦
하나 이상의 노드가 자신이 리더라고 생각하는 스플릿 브레인을 유발할 수 있는 잘못된 장애 복구를 필요하는데 합의가 중요하다.
•
원자적 커밋
◦
여러 노드나 파티션에 걸친 트랜잭션을 지원하는 데이터베이스는 트랜잭션이 어떤 노드에서 성공하고 어떤 노드에선 실패할 수 있다.
◦
트랜잭션 원자성(ACID의 Atomic)을 유지하고 싶다면 모든 노드가 트랜잭션의 결과에 동의하게 만들어야 한다.
◦
문제가 생길 경우 모두 어보트/롤백되거나 모두 커밋된다. 이러한 합의 문제를 원자적 커밋 문제라 한다.
합의 불가능성
노드가 죽을 가능성이 있다면 항상 합의에 이를 수 있는 알고리즘은 없다.
이를 증명하는 알고리즘으로 FLP 결과라는 논문이 있다. 분산 시스템에서는 노드가 죽을 가능성을 항상 가정해야 하고, 따라서 신뢰성 있는 합의는 불가능해진다.
Q. 그럼 합의 알고리즘을 살펴볼 필요가 없을까?
A. 그렇지 않다.
FLP결과는 어떤 시계나 타임아웃도 사용할 수 없는 결정적인 알고리즘을 가정하는 매우 제한된 모델인 비동기 시스템 모델에서 증명된다.
즉, 알고리즘에서 타임아웃을 쓰는 게 허용되거나 죽은 것으로 의심되는 노드를 식별하는 다른 방법이 있다면 합의는 해결 가능해진다.
FLP 결과
: Fischer, Lynch 및 Paterson의 이니셜을 따서 불완전한 비동기 시스템에서 합의 알고리즘이 불가능하다는 것을 증명한 논문.
이 FLP 결과는 비동기 시스템에서는 합의 알고리즘이 항상 실패할 가능성이 있다는 것을 의미합니다. 따라서 동기 시스템에서만 합의 알고리즘이 가능하다고 주장한다.
원자적 커밋과 2단계 커밋(2PC)
트랜잭션 원자성의 목적은 여러 쓰기를 실행하는 도중 문제 발생시 간단한 시맨틱을 제공하기 위함이다. 트랜잭션의 결과는 커밋 성공이 아니라면 어보트다.
커밋이
•
성공할 경우 내용은 모두 지속성을 지니게 되고,
•
실패할 경우 모든 내용은 롤백된다.(취소되거나 폐기된다.)
이런 동작이 원자성을 보장하며, 다중 객체 트랜잭션과 보조 색인을 유지하는 DB에서 매우 중요한 개념이다. 개별 보조 색인은 주 데이터와 분리된 자료구조로 데이터 변경시 그에 해당하는 변경은 보조 색인에도 반영돼야 한다. 원자성은 보조 색인이 주 데이터와 일관성을 유지하도록 보장한다.
단일 노드에서 분산 원자적 커밋으로
•
단일 (DB)노드에선
◦
트랜잭션의 원자성은 저장소 엔진에서 구현된다.
◦
트랜잭션 커밋 요청시
▪
DB는 트랜잭션의 쓰기가 지속성 있게 하고
▪
디스크에 있는 로그에 커밋 레코드를 추가한다.
◦
커밋 레코드를 기준으로
▪
디스크에 쓰여지는데 성공했다면 커밋된 것으로 간주되고,
▪
디스크에 쓰여지는데 성공했다면 롤백된다.
◦
즉, 커밋을 원자적으로 만들어 주는 건 단일 장치이다.
•
분산 노드에선
◦
어떤 노드들은 제약 조건 위반이나 충돌을 감지해 어보트가 필요하게 하지만 다른 노드들은 성공적으로 커밋될 수 있다.
◦
어떤 커밋 요청은 네트워크에서 손실되어 타임아웃 때문에 어보트되지만 다른 커밋 요청은 전달될 수 있다.
◦
어떤 노드는 커밋 레코드가 완전히 쓰여지기 전에 죽어서 복구할 때 롤백되지만 다른 노드는 성공적으로 커밋될 수 있다.
트랜잭션 커밋은 되돌릴 수 없고, 여러 노드 중 어떤 노드는 어보트 어떤 노드는 커밋할 경우 일관성은 없어지게 된다. 따라서 모든 노드가 커밋된다고 확신할 때만 커밋이 돼야 한다.
보상 트랜잭션(compensating transaction)
: 커밋된 트랜잭션의 효과를 다른 보상 트랜잭션이 취소하는 것은 가능하다.
하지만 DB관점에서 이건 분리된 트랜잭션이고 트랜잭션 사이의 정확성 요구사항은 애플리케이션의 문제다.
2단계 커밋 소개
2단계 커밋은 모든 노드가 커밋되거나 어보트되도록 보장하는 알고리즘이다.
일부 DB에선 2PC가 내부적으로 사용되고 XA 트랜잭션의 형태나 SOAP 웹 서비스용 WS-AtomicTransaction을 통해 애플리케이션에서도 사용할 수 있다.
2PC의 기본 흐름은 다음과 같다.
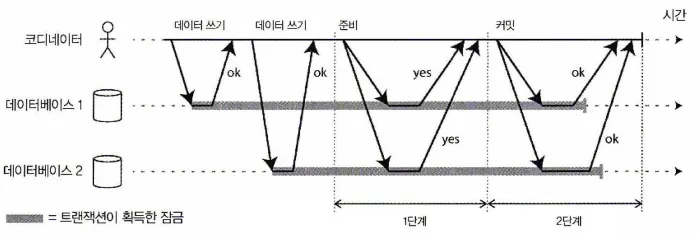
2단계 커밋(2PC)의 성공적인 실행
2PC는 단일 노드 트랜잭션에선 보통 존재하지 않는 새로운 컴포넌트인 코디네이터(coordinator, 트랜잭션 관리자라고도 한다) 를 사용한다.
이 코디네이터는 종종 트랜잭션을 요청하는 애플리케이션 프로세스 내에서 라이브러리 형태로 구현되지만(Ex: 자바 EE컨테이너 내장) 분리된 프로세스나 서비스가 될 수도 있다.
예를 들어 나라야나(Narayana), JOTM, BTM, MSDTC같은 코디네이터가 있다.
2PC 트랜잭션은
•
애플리케이션이 여러 DB 노드에서 데이터를 읽고 쓰면서 시작된다.
•
이 때 DB노드를 트랜잭션의 참여자(participant)라고 부른다.
•
애플리케이션이 커밋할 준비가 되면 코디네이터가 1단계를 시작한다.
1.
각 노드에 준비 요청을 보내 커밋할 수 있는지 물어본다.
2.
코디네이터는 참여자들의 응답을 추적한 뒤
a.
모두 준비가 됐다면 2단계에서 커밋요청을 보내고 커밋이 이뤄진다.
b.
준비가 안 된 노드가 있다면 2단계에서 모든 노드에 어보트 요청을 보낸다.
약속에 관한 시스템
위의 설명으로는 아직 1단계 커밋과 다르게 2단계 커밋이 원자성을 보장하는지에 대한 설명이 명확하지 않다. 오히려 단계가 많아지고 2단계(커밋 수행 or 어보트 요청)에서 손실될 수 있을 것 같다.
그럼 무엇이 2PC를 다르게 만들어줄까?
1.
애플리케이션은 분산 트랜잭션 시작을 원할 때 코디네이터에게 트랜잭션ID(이하 txid)를 요청한다.
•
이 txid는 전역적으로 유일하다.
2.
애플리케이션은 각 참여자에게 단일 노드 트랜잭션을 시작하고 단일 노드 트랜잭션에 전역적으로 유일한 txid를 붙인다. 모든 읽기와 쓰기는 단일 노드 트랜잭션 중 하나에서 실행된다. 이 단계에서 문제가 생기면(ex: 노드가 죽거나 타임아웃) 코디네이터나 참여자 중 누군가가 어보트할 수 있다.
3.
애플리케이션이 커밋할 준비가 되면 코디네이터는 모든 참여자에게 전역 txid로 태깅된 준비 요청을 보낸다. 이 과정에서도 문제가 생기면 코디네이터는 모든 참여자에게 해당 txid로 어보트 요청을 보낸다.
4.
참여자가 준비 요청을 받으면 모든 상황에서 분명히 트랜잭션을 커밋할 수 있는지 확인한다. 여기에는 모든 트랜잭션 데이터를 디스크에 쓰는 것(죽거나 전원 장애나 디스크 공간이 부족한건 커밋을 거부하는데 용인되는 변명이 아니다)과 충돌이나 제약 조건 위반을 확인하는 게 포함된다. 코디네이터에게 네 라고 응답함으로써 노드는 요청이 있으면 트랜잭션을 문제 없이 커밋할 것이라 약속한다.
5.
코디네이터가 모든 준비 요청에 대해 응답을 받았을 때 트랜잭션의 커밋/어보트 여부를 최종 결정한다. 코디네이터는 추후 죽는 경우에 어떻게 결정했는지 알 수 있도록 그 결정을 디스크에 있는 트랜잭션 로그에 기록해야하며 이를 커밋 포인트라 한다.
6.
코디네이터의 결정이 디스크에 쓰여지면 모든 참여자에게 커밋이나 어보트 요청이 전송된다. 이 요청에 문제가 생기면 성공할 때까지 영원히 재시도해야 한다. 커밋하기로 결정이 되었다면 재시도 횟수와 상관없이 무조건 커밋을 해야 한다. 한 참여자가 죽으면 그 참여자가 복구될 때 커밋된다.
이 프로토콜은 두 개의 중대한 돌아갈 수 없는 지점이 있다.
1.
커밋 포인트: 코디네이터가 모든 준비 요청에 대해 응답을 받고, 트랜잭션의 커밋/어보트 여부를 최종 결정하고 이를 디스크에 쓰는 지점. 이 지점 이후로는 결정을 바꿀 수 없다.
2.
커밋 요청: 코디네이터의 결정이 디스크에 쓰여지고, 모든 참여자에게 커밋이나 어보트 요청이 전송된 이후에는 커밋이나 어보트 요청을 바꿀 수 없다.
이러한 약속이 2PC의 원자성을 보장한다.
코디네이터 장애
2PC 도중 코디네이터가 죽을 경우 어떻게 될까?
•
코디네이터가 준비 요청을 보내기 전에 장애가 나면 안전하게 트랜잭션 어보트가 가능하다.
•
코디네이터가 준비 요청을 보낸 후에 참여자가 요청을 받고 네라고 투표했다면 일방적으로 어보트할 수 없다.
전자라면 문제가 안되지만 후자인 경우 투표를 한 참여자는 코디네이터로부터 커밋/어보트 여부에 대한 회신을 받을 때까지 기다려야 한다.
그리고 이런 상태에 있는 참여자의 트랜잭션을 의심스럽다(in doubt) or 불확실하다(uncertain)고 한다.
이런 상황에 대해 설명하는 다음 그림을 보자
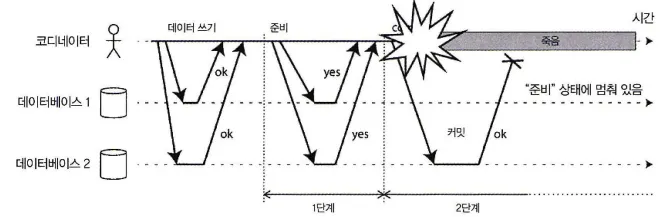
참여자들이 “네”라고 투표한 뒤 코디네이터가 죽으면 DB1은 커밋할지 어보트할지 알지 못한다.
그림을 보면 코디네이터는 1단계 이후 참여자들의 투표 결과까지 듣고난 뒤 2단계 시작하고 DB1에게 커밋 or 어보트결과에 대해 전달하는 시점에 장애가 발생했다. 그래서 DB1은 어떻게 동작할지에 대해 결정할 수가 없다.
타임아웃도 여기서는 해결책이 될 수 없다. DB2는 커밋이 되었기 때문에 일방적으로 타임아웃으로 어보트해버리면 일관성이 깨지게 된다.
즉, 코디네이터를 통하지 않고는 참여자는 어떻게 행동할지 결정할 수 없다.
2PC가 완료할 수 있는 방법은 코디네이터의 복구를 기다리는 것 뿐이다.
그리고 이러한 이유가 코디네이터가 참여자들에게 커밋 or 어보트 요청을 보내기 전 디스크에 있는 트랜잭션 로그에 자신의 결정을 써야 하는 이유다.
이 트랜잭션 로그를 이용해서 코디네이터 복구 시점에 의심스러운 트랜잭션들의 상태를 결정한다.
•
커밋 레코드가 없는 트랜잭션은 어보트하고,
•
커밋 레코드가 있는 트랜잭션은 커밋한다.
따라서 2PC의 커밋 포인트는 코디네이터에서 보통의 단일 노드 원자적 커밋으로 내려온다.
3단계 커밋
2단계 커밋은 2PC가 코디네이터가 복구하기를 기다리느라 멈출 수 있다는 사실 때문에 블로킹 원자적 커밋 프로토콜이라 불린다.
이론상으로는 노드에 장애가 나도 멈추지 않도록 원자적 커밋 프로토콜을 논블로킹하게 만들 수 있다. (현실에서 구현하긴 어렵지만…)
2PC의 대안으로 3단계 커밋(3PC)이라는 알고리즘이 제안됐다. 하지만 3PC는 지연에 제한이 있는 네트워크와 응답 시간에 제한이 있는 노드를 가정한다. 기약 없는 네트워크 지연과 프로세스 중단이 있는 대부분의 실용적 시스템에서 3PC는 원자성을 보장하지 못한다.
일반적으로 논블로킹 원자적 커밋은 완벽한 장애 감지기(perfect failure detector), 즉 노드의 활성화 여부를 구별할 수 있는 신뢰성 있는 메커니즘이 필요하다. 하지만 기약 없는 네트워크 지연이 있는 네트워크에서 타임아웃은 신뢰성 있는 장애 감지기가 아니다.
이러한 이유로 2PC가 계속 사용되고 있다.
현실의 분산 트랜잭션
분산 트랜잭션, 그 중에서 특히 2PC로 구현된 분산 트랜잭션은 평판이 엇갈린다.
•
호: 다른 방법으로 달성하기 어려운 중요한 안전성 보장을 제공한다
•
불호: 운영상의 문제를 일으키고 성능 저하와 과장해서 약속한다.
이러한 이유로 여러 클라우드 서비스들은 분산 트랜잭션을 구현하지 않는다는 선택을 한다.
몇몇 분산 트랜잭션 구현의 성능 저하는 생각보다 많이 심각하다.
예를 들어 MySQL의 분산 트랜잭션은 단일 노드 트랜잭션보다 10배 이상 느리다고 보고된다.
어째서 이렇게 2PC는 성능이 안좋은 걸까?
A. 장애 복구를 위한 부가적인 비용 소비가 원인이 된다.
- 장애 복구를 위해 필요한 디스크 강제쓰기(fsync)
- 부가적인 네트워크 왕복 시간
하지만, 분산 트랜잭션을 이런 이유로 지양하기보단 좀 더 자세히 살펴볼 필요가 있다.
우선, 분산 트랜잭션은 정확히 무얼 의미하는지 구분할 필요가 있다. 두 가지 매우 다른 종류의 분산 트랜잭션이 흔히 혼용되고 있다.
•
데이터베이스 내부 분산 트랜잭션
◦
트랜잭션에 참여하는 모든 노드는 동일한 DB를 사용한다.
◦
Ex: VoltDB, MySQL, 클러스터의 NDB 저장소 엔진
•
이종 분산 트랜잭션
◦
이종(heterogeneous) 트랜잭션에서 참여자들은 둘 혹은 그 이상의 다른 기술이다.
◦
두 가지 서로 다른 벤더의 DB일 수도 있고,
◦
메세지 브로커처럼 비데이터베이스 시스템일 수도 있다.
데이터베이스 내부 분산 트랜잭션은 호환성 고려를 할 필요가 없어 아무 프로토콜이나 쓸 수 있고 특정 기술에 특화된 최적화 사용이 가능하다. 그래서 동작도 매우 잘 된다.
하지만, 이종 분산 트랜잭션은 반대되는 이유로 사용이 어렵다.
정확히 한 번 메시지 처리
이종 분산 트랜잭션은 다양한 시스템들이 강력한 방법으로 통합될 수 있도록 한다.
예를 들어 메시지 큐에서 나온 메시지는 그 메시지를 처리하는 DB 트랜잭션이 커밋에 성공했을 때만 처리된 것으로 확인받을 수 있다.
메시지 확인과 DB 쓰기를 단일 트랜잭션에서 원자적으로 커밋함으로써 이를 구현할 수 있다. 분산 트랜잭션이 지원되면 메시지 브로커와 DB가 서로 다른 장비에서 실행되는 두 가지 무관한 기술이라도 가능하다.
메시지 전달이나 DB 트랜잭션 중 하나가 실패하면 둘 다 어보트되고 메시지 브로커는 나중에 메시지를 안전하게 다시 전달할 수 있다. 그러므로 메시지와 그 처리 과정의 부수 효과를 원자적으로 커밋함으로써 메시지가 결과적으로(effectively) 정확히 한 번(exactly once) 처리되도록 보장할 수 있다.
하지만, 이런 분산 트랜잭션은 트랜잭션의 영향을 받는 모든 시스템이 동일한 원자적 커밋 프로토콜을 사용할 수 있을 때만 가능하다.
예를 들어 메시지를 처리하는 부수 효과가 이메일을 전송하는 것이고 이메일 서버는 2PC를 지원하지 않는다면, 메시지 처리 실패 후 재시도시 이메일이 두 번 이상 전송될 수 있다. 그러나 트랜잭션이 어보트 될 때 메시지를 처리하는 모든 부수효과가 롤백된다면 처리 단계는 마치 아무 일도 없었던 것처럼 안전하게 재시도될 수 있다.
이종 분산 트랜잭션에서 사용되는 확인 응답 메커니즘
: 정확히 한 번 메시지 처리를 보장하기 위해선 확인 응답 메커니즘이 필요한데, 이 메커니즘은 다음과 같은 방식으로 동작한다.
1.
보내는 쪽 시스템은 메시지를 수신한 즉시 수신 확인 응답을 보낸다.
2.
수신 확인 응답을 받은 쪽 시스템은 메시지를 처리하고 처리 결과를 보낸다.
3.
보내는 쪽 시스템은 처리 결과를 수신한 즉시 처리 완료 응답을 보낸다.
이렇게 함으로써, 메시지 처리가 정확히 한 번만 일어나도록 보장할 수 있다.
이러한 방법을 사용하면 메시지 처리의 정확성을 보장할 수 있지만, 네트워크 지연이나 장애에 의해 처리 결과가 수신되지 않는 경우가 있다. 이 경우에는 타임아웃 기능을 사용하여 처리 결과를 재시도하거나, 예외 처리를 수행할 수 있다.
하지만, 이러한 방법은 추가적인 오버헤드와 지연을 유발할 수 있다는 점을 염두에 두어야 한다. 따라서 이러한 방법을 사용하기 전에는 장단점을 신중히 고려해야 한다.
XA 트랜잭션
X/Open XA(eXtended Architecture)는 이종 기술에 걸친 2PC를 구현하는 표준이다.
다음과 같은 여러 RDB와 Message Broker에서 지원된다.
•
RDB: PostgreSQL, MySQL, DB2, SQLServer, Oracle
•
Message Broker: ActiveMQ, HonetQ, MSMQ, IBM MQ
XA는 네트워크 프로토콜이 아니고, 트랜잭션 코디네이터와 연결되는 인터페이스를 제공하는 API로 여러 언어에서 지원한다.
•
JAVA: javax.transaction 패키지에 XA API가 포함되어 있으며, JTA(Java Transaction API)를 사용하여 XA 트랜잭션을 관리할 수 있다.
◦
JTA는 다시 JDBC를 사용하는 DB용 드라이버 다수와 JMS(Java Message Service) API를 사용하는 메시지 브로커용 드라이버에서 지원된다.
•
C or C++: X/Open XA API가 제공된다.
그 밖에 다른 언어도 해당 언어의 고유 API 바인딩을 사용해 구현할 수 있다.
XA는 애플리케이션이 네트워크 드라이버나 클라이언트 라이브러리를 사용해 참여자 DB나 메시징 서비스와 통신한다고 가정한다. 그래서 드라이버가 XA를 지원한다는 것은 연산이 분산 트랜잭션의 일부가 돼야 하는지 알아내기 위해 XA API를 호출한다는 것을 뜻한다.
그 다음 드라이버는
•
DB 서버로 필요한 정보를 보낸다.
•
코디네이터가 참여자에게 준비, 커밋, 어보트를 요청할 수 있는 콜백도 제공한다.
트랜잭션 코디네이터는
•
XA API를 구현하며, 표준에서 어떻게 구현해야 하는지에 대한 명세는 없다.
•
현실에선 독립된 서비스가 아닌 트랜잭션을 시작하는 애플리케이션과 같은 프로세스에 로딩되는 단순한 라이브러리
•
트랜잭션의 참여자를
◦
추적하고
◦
준비 요청을 보내고
◦
응답을 수집하고
◦
트랜잭션에 대한 커밋/어보트 결정을 추적하기 위해 로컬디스크에 있는 로그를 사용한다.
애플리케이션 프로세스가 죽거나 실행중인 장비가 죽으면 코디네이터도 함께 사라진다.
⇒ 준비는 됐지만 커밋되지 않은 트랜잭션들을 가진 참여자들은 의심스러운 상태에 빠지게 된다.
코디네이터의 로그는 프로세스가 복구되며 코디네이터가 복구되었을 때 트랜잭션의 커밋/어보트 결과를 복구하는데 사용한다.
그 후에 XA 콜백을 사용해 참여자들에게 요청을 전달할 수 있다. 모든 통신은 클라이언트 라이브러리를 거쳐야 하기 때문에 DB 서버는 코디네이터에 직접 연결할 수 없다.
의심스러운 상태에 있는 동안 잠금을 유지하는 문제
트랜잭션이 의심스러운 상태에 빠지고 그 상태가 유지된다면, 해당 트랜잭션에서 사용하는 데이터에 대한 잠금이 계속 유지된다. 그리고 이러한 상태를 트랜잭션 블록(blocked)상태라고도 부른다.
DB 트랜잭션은 더티 쓰기(dirty write)를 막기 위해 로우 수준의 독점적인 잠금을 획득하는데, 추가적으로 직렬성 격리를 원한다면 2PL을 사용하는 데이터베이스는 트랜잭션에서 읽은 로우에 공유 잠금도 획득해야 한다.
DB는 트랜잭션이 커밋되거나 어보트할 때까지 잠금을 유지하고 있는데, 만약 코디네이터가 죽어서 재시작까지 20분이 걸린다면 잠금 역시 20분간 유지된다. 심지어 코디네이터가 복구되지 못한다면 잠금은 영원히 유지될 수도 있고, 관리자가 수동으로 해결해야 한다.
언제 트랜잭션이 의심스러운 상태에 빠지는걸까?
1.
다른 트랜잭션에서 해당 데이터에 대한 작업을 수행 중인 경우
2.
트랜잭션에서 사용한 리소스(데이터베이스 연결 등)의 문제로 인한 중단
3.
다른 트랜잭션에서 해당 데이터를 변경하거나 삭제한 경우
코디네이터 장애에서 복구하기
이론상으로는 코디네이터가 재시작하면 디스크에 있는 로그를 사용해 상태를 복구하고 의심스러운 트랜잭션을 해소해야 한다.
하지만, 현실에선 트랜잭션 로그가 손실되어 고아가 된(orphanded) 의심스러운 트랜잭션, 즉 코디네이터가 결과를 결정할 수 없는 트랜잭션이 생길 수 있다.
이런 트랜잭션은 자동으로 해소될 수 없기에 잠금을 유지하고 다른 트랜잭션을 차단하며 DB에서도영원히 남게 된다.
유일한 해결책은 관리자가 수동으로 트랜잭션의 커밋 혹은 롤백 여부를 결정하는 것이다.
하지만, 이러한 이 방식은 잠재적으로 많은 수작업과, 심각한 서비스 중단이 있는 도중이기에 시간적 압박이 있는 상태에서 처리해야 할 가능성이 높다.
여러 XA 구현에는 참여자가 코디네이터로부터 확정적 결정을 얻지 않고 의심스러운 트랜잭션의 커밋, 어보트 여부를 일방적으로 결정할 수 있도록 하는 경험적 결정(heuristic decision)이라고 부르는 비상 탈출구가 있다.
사실 여기서 말하는 경험적은 2PC의 약속 체계를 위반하기에 원자성을 깰 수도 있다.
따라서 경험적 결정은 평소가 아닌 큰 장애 상황을 벗어나고자 할 때만 쓰도록 의도된 것이다.
분산 트랜잭션의 제약
XA 트랜잭션은 여러 참여 데이터 시스템이 서로 일관성을 유지하게 하는 실제적이고 중요한 문제를 해결해준다.
하지만, 위에서 지금까지 작성한 것처럼 여러 중요한 운영상 문제를 가져온다.
특히 핵심 구현은 트랜잭션 코디네이터 자체가 트랜잭션 결과를 저장할 수 있는 일종의 DB여야 하고 따라서 다른 중요한 DB와 동일하게 신경써서 접근해야 한다.
•
코디네이터가 복제되지 않고 단일 장비에서만 실행되면 전체 시스템의 단일 장애점(single point of failure)이 된다. 놀랍게도 여러 코디네이터 구현은 기본적으로 고가용성을 제공하지 않거나 가장 기초적인 복제만 지원한다.
•
여러 서버 사이드 애플리케이션은 모든 영속적인 상태를 DB에 저장하고 상태 비저장 모드로 개발된다.
◦
애플리케이션 서버를 마음대로 추가 및 제거할 수 있다는 이점이 있지만,
◦
코디네이터가 애플리케이션 서버의 일부가 되면 배포특성이 변하게 된다.
▪
코디네이터의 로그가 지속적인 시스템 상태의 중요한 부분이 된다.
▪
코디네이터 로그가 계속해서 관리되야 하기에 애플리케이션 서버가 더 이상 상태 비저장(stateless)이 아닌 상태 저장(stateful)하게 된다.
•
XA는 광범위한 데이터 시스템과 호환돼야 하기에 일정량의 범용성을 제공해야 한다.
: 각 시스템간에 정보 교환을 위해 표준화된 프로토콜이나 식별 프로토콜이 필요해진다.
◦
여러 시스템에 걸친 데드락을 감지할 수 없다.
◦
직렬성 스냅숏 격리(SSI)와 함께 동작하지 않는다.
•
XA가 아닌 DB 내부 분산 트랜잭션은 제한이 크지 않다.
◦
분산 버전 SSI를 쓸 수 있다.
◦
하지만, 트랜잭션 커밋을 위해 모든 참여자가 응답해야 한다는 문제가 남는다.
◦
분산 트랜잭션은 부분적인 문제도 전체로 커지기 때문에 장애를 증폭시키는 경향이 있고, 이는 내결함성을 지니는 시스템을 구축하려는 목적에 어긋난다.
여러 코디네이터 구현이 고가용성 미제공 및 기초적인 복제만 지원하는 이유
1. 복제 비용 문제: 분산 트랜잭션에서 코디네이터 복제를 하려면 여러 개의 서버에 대한 복제를 수행해야 하는데, 이는 서버 자원 소모 및 복제된 데이터의 일관성을 유지하는데 필요한 비용도 크다.
2. 동기화의 어려움: 분산 환경에서 코디네이터의 동기화는 어려운 문제다. 여러 서버에서 실행되는 트랜잭션을 관리하면서 코디네이터 간에 동기화도 유지해야하는 부분은 상당히 복잡하다.
3. 성능 저하: 분산 환경에서 코디네이터를 복제하면서 고가용성을 제공하려면 네트워크 대역폭이 많이 필요하고, 서버 자원도 많이 필요한데, 이 때문에 전체적인 분산 트랜잭션 처리 성능을 저하시킬 수 있다.
내결함성을 지닌 합의
합의 문제는 다음과 깉이 형식화 된다.
•
하나(혹은 그 이상)의 노드가 값을 제안할 수 있고,
•
합의 알고리즘이 그 값 중 하나를 결정한다.
이러한 형식에서 합의 알고리즘은 다음 속성을 만족해야 하며, 이러한 합의를 균일한 합의라 하고, 신뢰성 없는 장애 감지기를 지닌 비동기 시스템의 일반적인 합의와 같다.
•
균일한 동의
◦
어떤 두 노드도 다르게 결정하지 않는다.
•
무결성
◦
어떤 노드도 두 번 결정하지 않는다.
•
유효성
◦
한 노드가 값 v를 결정한다면 v는 어떤 노드에서 제안된 것이다.
•
종료
◦
죽지 않은 모든 노드는 결국 어떤 값을 결정한다.
균일한 동의와 무결성 속성은 합의의 핵심 아이디어를 정의한다.
유효성 속성은 주로 뻔한 해결책을 배제하기 위해 존재한다. 만약 제안과 무관하게 항상 Null로 결정하는 알고리즘이 있다면, 이 알고리즘은 균일한 동의와 무결성 속성은 만족하지만 유효성 속성은 만족하지 않는다.
내결함성이 상관없다면 처음 세 개의 속성을 만족시키기는 쉽다.
그냥 하나의 노드를 독재자로 하드코딩해 이 노드가 모든 결정을 내리도록 하면 된다. 하지만 이 노드에 문제가 발생하면 아무런 결정을 할 수 없는 시스템이 되버린다. 코디네이터에서 장애가 나면 의심스러운 참여자들은 커밋할지 어보트할지 결정할 수 없다.
종료 속성은 내결함성의 아이디어를 형식화한다.
이 속성은 그대로 가만히 아무것도 안하는 참여자가 없게끔 하며 진행을 해야 한다고 규정하는 속성으로 여러 참여자들 사이에 몇 참여자가 문제가 발생하더라도 나머지는 결정을 내려야 한다고 한다.
즉, 종료는 활동성 속성이고 다른 세 개는 안전성 속성이다.
합의 시스템 모델에서는 노드가 죽으면 복구되지 않는다는걸 가정하며, 이러한 모델에서 노드가 복구되길 기다린다면 종료 속성을 만족할 수 없다. 특히 2PC는 종료에 대한 요구사항을 만족하지 않는다.
알고리즘이 견딜 수 있는 장애의 수
알고리즘이 견딜 수 있는 장애의 수에는 제한이 있다.
어떤 합의 알고리즘이라도 종료를 보장하기 위해서는 최소한 과반수의 노드가 올바르게 동작해야 한다는 점이 증명될 수 있다. 과반수는 안전하게 정족수를 형성할 수 있다.
따라서 종료 속성은 죽거나 연결할 수 없는 노드 대수가 절반 미만이라는 가정하에 성립된다.
그 외의 안전성 속성들은 이런 문제(과반수 노드의 장애, 네트워크 문제)에도 안전성을 항상 만족한다. 이 때문에 대규모 중단이 발생해도 시스템이 요청을 처리할 순 없게 되지만 유효하지 않은 결정을 내려 합의 시스템을 오염시키지는 않는다.
대부분의 합의 알고리즘은 비잔틴 결함이 없다고 가정한다.
즉, 노드가 프로토콜을 올바르게 따르지 않으면 안전성 속성이 깨질수도 있고 1/3 미만의 노드만 비잔틴 결함이 있다면 비잔틴 결함에도 견고하도록 합의를 만들 수 있지만, 이런 알고리즘을 모두 다루기엔 너무 양이 많기에 생략한다.
PBFT(Practical Byzantine Fault Tolerance) 알고리즘
: 4개의 단계로 이뤄져 있으며 1/3미만의 노드가 비잔틴 결함을 가지더라도 합의를 도출할 수 있도록 설계된 알고리즘으로 다음 과 같은 단계로 이뤄져 있다.
1. Request phase: 클라이언트의 요청을 처리하는 단계로 요청을 받은 노드(primary)가 요청을 처리하고 결과를 다른 노드들에게 전달한다.
2. pre-prepare: 사전 준비 단계로 primary가 전달한 결과를 검증하고, 그 결과를 받아들이면 사전 준비 메시지를 다른 노드들에 전달한다.
3. prepare: 사전 준비(pre-prepare)메시지를 받은 노드들은 해당 메시지를 검증하고 준비(prepare) 메시지를 다른 노드들에게 전달한다.
4. commit: 준비(prepare) 메시지를 받은 노드들은 해당 메시지를 겸증하고, 커밋 메시지를 다른 노드들에게 전달한다. 커밋 메시지를 받은 노드들도 마찬가지로 메시지를 검증하고 클라이언트에게 결과를 전달한다.
그 밖의 알고리즘
- SBFT(simplified Byzantine Fault Tolerance) : PBFT 알고리즘을 단순화하여 개발된 알고리즘으로, PBFT보다 더 적은 메시지 통신을 통해 더 빠른 합의 속도를 보장한다.
- dBFT(Delegated Byzantine Fault Tolerance): dBFT는 NEO 블록체인에서 사용되는 알고리즘으로, 승인 노드(validator)를 선정하여 해당 노드들만이 블록을 생성하고 검증하는 방식으로 합의를 도출한다.
- HBBFT(Honey Badger Byzantine Fault Tolerance): HBBFT는 비잔틴 결함을 가진 노드들의 수와 관계없이 안정적인 합의를 보장한다. 하지만, PBFT나 dBFT와 달리 메시지 통신 비용이 많이 들어 성능상의 이슈가 있을 수 있다.
- Zyzzyva: Zyzzyva는 PBFT와 유사하게 3분의 1 미만의 노드가 비잔틴 결함을 가지더라도 합의를 도출할 수 있지만 PBFT와 달리, Zyzzyva는 비동기적(asynchronous) 환경에서도 동작할 수 있도록 설계되었다.
합의 알고리즘과 전체 순서 브로드캐스트
내결함성을 지닌 합의 알고리즘 중 가장 널리 알려진 것은 다음과 같다.
•
뷰스탬프 복제(viewstamped Replication, VSR)
•
팍소스(Paxos)
•
라프트(Raft)
•
잽(Zab)
직접 합의 시스템을 구현할게 아니라면, 이러한 알고리즘에 공통으로 있는 고수준의 아이디어를 아는 것으로 충분하다.
이 알고리즘 중 대다수는 실제로는 여기서 설명한 형식적 모델(동의, 무결성, 유효성, 종료 속성을 만족하며 하나의 값을 제안하고 결정)을 직접 사용하지 않는다.
대신 값의 순차열(sequence)에 대해 결정해 전체 순서 브로드캐스트 알고리즘을 만든다.
전체 순서 브로드캐스트는 모든 노드에게 정확히 한번, 같은 순서로 전달돼야 한다.
이 특징은 합의를 몇 회 하는 것과 동일하다
•
합의의 동의 속성 때문에 모든 노드는 같은 메시지를 같은 순서로 전달하도록 결정한다.
•
무결성 속성 때문에 메시지는 중복되지 않는다.
•
유효성 속성 때문에 메시지는 오염되지 않고 난데없이 조작되지 않는다.
•
종료 속성 때문에 메시지는 손실되지 않는다.
뷰스탬프 복제, 라프트, 잽은 전체 순서 브로드캐스트를 직접 구현한다. 그 이유는 한 번에 하나의 값을 처리하는 합의를 여러 번 하는 것보다 효율적이기 때문이다.
팍소스의 최적화 구현은 다중 팍소스(Multi-Paxos)라고 한다.
단일 리더 복제와 합의
단일 리더 복제는 모든 쓰기를 리더에게 전달하고 쓰기도 같은 순서로 팔로워에 적용하기 때문에 전체 순서 브로드캐스트와 유사하다. 그래서 합의에 대해 고민할 필요가 없을 것 같다.
하지만, 이는 리더를 어떻게 선택하느냐에 따라 달라진다.
리더를 운영팀의 있는 사람이 수동으로 선택해 설정하는 독재자 방식의 합의 알고리즘을 사용하게 되면, 진행을 위해 사람의 개입이 필요하기 때문에 합의의 종료 속성을 만족하지 않는다.
어떤 DB에선 기존 리더에 문제가 생기면 팔로워 하나를 새 리더로 승격시켜 자동 리더 선출 및 장애 복구를 수행해서 내결함성을 지닌 전체 순서 브로드캐스트와 가까워지지만, 이 역시 장애가 났던 (전) 리더 노드가 복구되거나 그 밖에 하나 이상의 노드가 자신이 리더라고 생각하는 스플릿 브레인 문제가 있다. 이 스플릿 브레인 문제가 생기면 각기 다른 노드가 자신이 리더라고 생각하기에 DB의 일관성이 깨진다. 따라서 리더를 선출하기 위한 합의가 필요하다.
하지만 전체 순서 브로드캐스트 알고리즘은 단일 리더 복제와 같기 때문에 합의를 위해선 리더가 필요하다.
즉, 리더를 선출하기 위해선 리더가 필요한 상황인 것이다.
어떻게 이 상황을 해결할 수 있을까?
1.에포크 번호 붙이기와 정족수
위에서 설명한 합의 프로토콜은 모두 리더를 사용하지만 리더가 유일하다고 보장하진 않는다.
대신 더 약한 보장을 할 수 있다. 이 프로토콜들은
•
에포크 번호(epoch number)를 정의한다.
◦
Paxos에선 투표 번호(ballot number)
◦
viewstamped replication에선 뷰 번호(view number)
◦
Raft에선 텀 번호(term number)라고 한다.
각 에포크 내에선 리더가 유일하다고 보장한다.
에포크 번호는 전체 순서가 있고 단조 증가한다. 그래서 두 리더 사이에 충돌이 있다면 에포크 번호가 높은 리더가 이긴다.
리더는 뭔가 결정하도록 허용하기 전 충돌되는 결정을 할지도 모르는 에포크 번호가 더 높은 다른 리더가 없는지 먼저 확인해야 한다.
리더는 자신의 결정에 대해 제안된 값을 다른 팔로워들에게 보내서 노드의 정족수가 그 제안을 찬성한다고 응답하기를 기다려야 하며, 노드는 에포크 번호가 더 높은 다른 리더를 알지 못할 때만 제안에 찬성하는 투표를 한다.
따라서 투표는 두 번이 있다.
•
한 번은 리더를 선출하기 위해
•
두 번째는 리더의 제안에 투표하기 위해
중요한건 두 번의 투표 모두 정족수가 겹쳐야 한다. 제안에 대한 투표가 성공했다면 투표한 노드 중 최소 하나는 가장 최근의 리더 선출에도 참여했어야 한다. 따라서 제안에 대한 투표를 할 때 에포크 번호가 더 큰 것이 있다고 밝혀지지 않았다면 현재 리더는 에포크 번호가 더 높은 리더 선출이 발생하지 않았다는 결론을 내릴 수 있고, 그 결과 자신이 리더라고 확신할 수 있다.
이 투표 과정은 2PC와 비슷해보이지만, 다음과 같은 차이점이 있다.
•
2PC의 코디네이터는 선출되지 않는다.
•
2PC는 모든 참여자로부터 네 투표가 필요하다.
◦
합의 알고리즘은 새로운 리더가 선출된 후 노드를 일관적인 상태로 만들어주는 복구 과정을 정의해 안전성 속성이 항상 만족되도록 보장한다.
합의의 제약
분산 시스템은 많은 것들이 불확실하고 불안정하다.
그렇기에 구체적인 안전성 속성(동의, 무결성, 유효성)을 가져오고 내결함성을 유지하게 해주는 합의 알고리즘은 매우 중요하다.
그렇다고, 합의 알고리즘이 트레이드 오프는 있기 때문에 모든 곳에서 사용되지는 않는다.
•
비동기성과 동기성간의 트레이드 오프
합의 알고리즘은 동기식이 있고, 비동기식이 있다. 동기식 합의 알고리즘은 모든 노드가 동시에 참여해 결과를 기다리고 다음 단계로 진행하기 때문에 안정성과 정확성은 가질 수 있지만 노드가 많아질수록 통신이 많아지며 지연시간이 증가할 수 있기에 네트워크에 의존성을 가진다.
반면에, 비동기식 합의 알고리즘은 모든 노드가 독립적으로 작업을 수행하고 결과를 기다리지 않고 다음 작업을 진행한다. 이 방식은 지연 시간을 적기에 빠른 응답을 보장할 수 있고 일부 노드에서 문제가 생겨도 나머지 노드는 계속해서 작업을 수행할 수 있다.
하지만 노드 간의 데이터 불일치가 발생할 수 있고 보안성에 취약할 수 있다.
•
노드 수와 확장성 간의 트레이드 오프
: 합의 시스템은 항상 엄격한 과반수가 동작하기를 요구한다.
그렇기 때문에 하나의 장애를 견디기 위해선 3대의 노드가, 두 대의 장애에 대응하기 위해선 최소 다섯 대의 노드가 필요하다.
대부분의 합의 알고리즘은 투표에 참여하는 노드 집합이 고정돼 있다고 가정하며 이는 클러스터에 노드를 임의로 추가및 제거를 할 수 없다는 의미이기도 한다.
합의 알고리즘의 동적 멤버십(dynamic membership)확장은 클러스터에 있는 노드 집합이 시간이 지남에 따라 바뀌는 것을 허용하지만 이들은 정적 멤버십 알고리즘보다 이해하기 어렵다.
•
신뢰성 없는 네트워크에 견고한 알고리즘을 설계하는 것의 어려움
: 합의 알고리즘은 종종 네트워크 문제에 민감하다. Raft는 전체 네트워크 중 특정 링크 하나가 지속적으로 불안정하다면 리더 노드가 두 노드 사이에서 지속적으로 왔다 갔다 하거나 현재 리더가 꾸준히 리더에서 강제로 내려오는 상황이 발생해 시스템이 진행되지 못할 수 있다.
그 밖에 다른 합의 알고리즘에서도 신뢰성 없는 네트워크에서 견고함을 갖추기는 여전히 해결되지 않은 문제이다.
멤버십과 코디네이션 서비스
종종 분산 키-값 저장소, 코디네이션과 설정 서비스라 불리는 주키퍼와 etcd는 완전히 메모리 안에 들어올 수 있는 작은 양의 데이터를 보관하도록 설계됐다.
따라서 애플리케이션의 모든 데이터를 여기에 저장하기엔 적절하지 않다.
이 소량의 데이터는 내결함성을 지닌 전체 순서 브로드캐스트 알고리즘을 사용해 모든 노드에 걸쳐 복제되는데, 개별 메시지가 DB에 쓰기를 나타낸다면 같은 쓰기를 같은 순서로 적용해 복제본들이 서로 일관성을 유지할 수 있다.
주키퍼는 구글의 Chubby 잠금 서비스를 모델로 삼아 전체 순서 브로드캐스트(따라서 합의도)뿐 아니라 분산 시스템을 구축할 때 특히 유용한 것으로 알려진 다른 흥미로운 기능 집합도 구현한다.
•
선형성 원자적 연산
: 원자적 compare-and-set 연산을 사용해 잠금을 구현할 수 있다.
여러 노드가 동시에 같은 연산을 수행하려 하면 그 중 하나만 성공한다. 합의 프로토콜은 노드에 장애가 나거나 네트워크 중단 문제가 생겨도 연산이 원자적이고 선형적일 것을 보장한다.
분산 잠금은 보통 클라이언트에서 장애가 난 경우 결국엔 해제될 수 있도록 임차권(lease)으로 구현된다.
•
연산의 전체 순서화
: 어떤 자원이 잠금이나 임차권으로 보호될 때 프로세스가 중단되는 경우 클라이언트끼리 충돌하는 것을 막기 위해 펜싱 토큰이 필요하다. 주키퍼는 모든 연산에 전체 순서를 정하고 각 연산에 단조 증가하는 펜싱 토큰(트랜잭션 ID(zxid), 버전 번호(cversion))을 할당해서 이를 제공한다.
•
장애 감지
: 클라이언트는 주키퍼 서버에 수명이 긴 세션을 유지하고 서버와 주기적으로 하트비트(heartbeat)를 교환해 헬스체크를 한다. 연결이 일시적으로 끊기거나 주키퍼 노드에 장애가 나도 세션은 살아있는데, 세션 타임아웃보다 긴 기간 동안 하트비트가 멈출 경우 주키퍼는 세션이 죽었다고 선언한다.
세션에서 획득한 잠금은 세션이 타임아웃 됐을 때 자동으로 해제되도록 설정할 수 있으며 주키퍼에선 이를 단명 노드(ephemeral node)라 한다.
•
변경 알림
: 클라이언트는 다른 클라이언트가 생성한 잠금과 값을 읽을 수 있으며 변경도 감시할 수 있다. 따라서 클라이언트는 다른 클라이언트가 언제 클러스터에 합류했는지 혹은 또 다른 클라이언트에 장애가 났는지 알아챌 수 있다. 알림을 구독함으로써 클라이언트는 변경을 발견하기 위해 주기적으로 폴링해야 하는 필요를 피할 수 있다.
이러한 기능 중에서 선형성 원자적 연산만 실제로 합의가 필요하다.
그러나 주키퍼 같은 시스템을 분산 코디네이션에서 유용하게 만들어주는 것은 이 기능들의 조합이다.
작업을 노드에 할당하기
주키퍼/처비 모델이 잘 동작하는 몇 가지 예는
•
여러 개의 프로세스나 서비스가 있고 그 중 하나가 리더나 주 구성요로 선택돼야 할 때다. 리더에 장애가 생기면 다른 노드 중 하나가 리더로 승격이 되야한다.
•
파티셔닝된 자원(DB, 메시지 스트림, 파일 저장소, 분산 액터(actor)시스템 등..)이 있고 어떤 파티션을 어떤 노드에 할당해야 결정하는 경우다.
새 노드들이 클러스터에 합류하면서 부하의 재균형화를 위해 어떤 파티션들은 기존 노드에서 새로운 노드로 이동되야 한다. 노드가 제거되거나 장애가 나면 다른 노드들이 이 노드의 작업을 넘겨받아야 한다.
이런 작업들은 주키퍼에서 원자적 연산, 단명 노드, 알림을 사용해서 해결할 수 있다.
심지어 사람의 개입 없이도 자동 복구될 수 있게 할 수도 있지만, 쉽지는 않다.
그래도, 어려운것과 불가능한것과는 간극이 크며 아예 처음부터 구현하는 것보다는 낫다.
애플리케이션이 시작은 단일 노드로 할지라도 차후에 수천 대의 노드로 늘어날 수 있다.
이 때 과반수 투표를 진행하는것은 매우 비효율적이다. 대신 주키퍼는 보통 3~5대의 고정된 수의 노드에서 실행되고, 이 노드들 사이에서 과반수 투표를 수행하며 많아질 수 있는 클라이언트를 지원한다.
따라서 주키퍼는 노드들을 코디네이트 하는 작업(합의, 연산 순서화, 장애 감지)의 일부를 외부서비스에 위탁하는 방법을 제공한다.
보통 주키퍼로 관리되는 데이터는 변경 주기가 긴 데이터 위주로 몇 분이나 몇 시간 단위로 변경되는 정보를 표현한다. 애플리케이션의 상태 저장용으로 의도되지 않았으며 이런 애플리케이션 상태를 노드 복제해야 할 경우 다른 도구(아파치 북키퍼(Apache BookKeeper)같은) 를 사용할 수 있다.
서비스 찾기(Service Discovery)
참고 링크: link
주키퍼, etcd, 콘술(Consul)은 특정 서비스에 연결하기 위해 어떤 IP주소로 접속해야 하는지 알아내기 위한 용도로 자주 사용된다.
이러한 서비스 찾기가 실제로 합의가 필요한지에 대해서는 분명하지 않다.
DNS는 서비스 이름으로 IP 주소를 찾는 전통적인 방법이고 고성능, 고가용성을 위해 다층 캐시를 사용한다. DNS에서 읽는 것은 틀림없이 선형적이지 않고 DNS 질의의 결과가 조금 뒤처지더라도 보통 문제로 생각되지는 않는다. DNS는 속도보단 신뢰성과 견고함이 더 중요하다.
서비스 찾기는 합의가 필요 없지만 리더 선출은 합의가 필요하다.
리더 선출 없이 서비스 찾기에 대한 정보를 동시 업데이트하게 될 경우, 여러 노드가 서로 다른 정보를 가질 수 있고, 이는 일관성을 보장할 수 없게 된다.
따라서 서비스 찾기에서는 하나의 노드가 리더로 선출되어 일관성 있는 정보를 유지하고 분산 시스템에서 일관성을 보정해줘야 하며 이를 주키퍼나 Consul등이 지원한다
따라서 합의 시스템이 누가 리더인지 이미 안다면 다른 서비스들이 리더가 누군지 찾는 데 그 정보를 사용하는 것도 타당하다.
이런 목적으로 어떤 합의 시스템은 읽기 전용 캐시 복제서버를 지원한다. 이 복제 서버는 합의 알고리즘의 모든 결정에 관한 로그를 비동기로 받지만 능동적으로 투표에 참여하진 않는다. 그렇기에 선형적일 필요가 없는 읽기 요청을 서비스할 수 있다.
좀 더 자세히 살펴보는 읽기 전용 캐시 서버가 필요한 이유
많은 클라이언트가 분산 시스템에서 사용 가능한 서비스의 위치 및 상태 정보를 주기적으로 조회하는데 이 요청은 많은 트래픽을 발생시키고, 이를 해결하기 위해 읽기 전용 캐시 복제 서버가 도입된다.
캐시 서버는 분산 시스템에서 사용 가능한 서비스의 위치 및 상태 정보를 읽기 전용으로 캐싱하며, 클라이언트는 이러한 캐시 서버에서 서비스 정보를 조회한다.
이를 통해 트래픽을 줄이고, 분산 시스템의 부하를 감소시킨다.
또한 캐시 서버는 주기적으로 멤버십 서비스와 연동해 캐시를 업데이트하며 캐시 서버에 장애가 발생하면 다른 캐시 서버나 멤버십 서비스로부터 새로운 정보를 가져와 캐시를 갱신할 수 있다. 그 결과 서비스 찾기 시스템의 성능을 향상시켜줄 수 있다.
멤버십 서비스
분산 시스템의 노드 정보를 관리하고 동적 멤버십 확장을 지원하는 기능
주키퍼와 유사 프로젝트들은 오랜 멤버십 서비스(membership service)연구 역사의 일부로 볼 수 있다. 과거에 항공 교통 관제 같은 고신뢰성 시스템을 구축하는데 중요한 역할을 했다.
멤버십 서비스는 클러스터에서 어떤 노드가 현재 활성화된 살아 있는 멤버인지 결정한다.
기약 없는 네트워크 지연 때문에 다른 노드에 장애가 생겼는지 신뢰성 있게 감지하는 것은 불가능하지만 장애 감지를 합의와 연결해 노드들은 어떤 노드가 살아 있는 것으로 여겨져야 하는지 혹은 죽은 것으로 여겨져야 하는지 동의할 수 있다.
물론, 여전히 노드가 실제 상태(살았는지 죽었는지)와 다르게 잘못 선언될 가능성은 있다.
그럼에도 불구하고 합의는 시스템에서 어떤 노드가 현재 멤버십을 구성하는지 동의하는데 유용하다.
예를 들어 리더 선택을 현재 멤버들 중 번호가 가장 낮은 것을 선택하는 식으로 간단히 구현할 수 있다. (다만, 다른 노드와 현재 멤버가 누군지에 대해 의견이 갈린다면 이 방법은 동작하지 않는다.)

