

목차
개요
서비스 디스커버리(Service Discovery)의 등장배경
클라우드 서비스 환경에서 수평 확장( auto-scaling)같은 이유로 서비스 인스턴스의 수가 동적으로 가감하는 상황에서 가감되는 서비스의 주소(IP…)를 감지하고 서비스의 헬스체크를 하여 이용이 불가능한 서비스를 삭제하는 등 이름 그대로 서비스 인스턴스를 발견하고 관리하는 역할이 필요해졌고, 이 때 Netflix에서 지난 7년간 Cloud System으로 서비스 이전을 하면서 쌓은 MSA기술이 오픈 소스로 풀린 것이 스프링 클라우드 넷플릭스이다. 이 Netflix OSS에는 다음과 같은 서비스가 있다.
•
Eureka: Discovery Service
•
Ribbon: Client Side Load Balancer
•
Zuul: API Gateway
•
Hystrix: Circuit Breaker
•
EvCache
•
Spectator
•
Archaius
이 중에서 Eureka 서비스는 MSA의 핵심 요소인 Service Discovery를 지원하는 서비스로,
서비스 디스커버리가 가져야 할 장점들을 모두 가져갈 수 있게 해준다.
 참고: 서비스 디스커버리가 제공해야 할 기능
참고: 서비스 디스커버리가 제공해야 할 기능
•
고가용성
: 서비스 검색 정보를 서비스 디스커버리 클러스터의 여러 노드가 공유하는 핫 클러스터링 환경을 지원하여 한 노드가 사용할 수 없게 되면 클러스터의 다른 노드가 인계를 받을 수 있어야 한다.
•
P2P(Peer-to-Peer)
: 서비스 디스커버리 클러스터의 각 노드는 서비스 인스턴스 상태를 공유한다.
•
부하 분산
: 요청을 동적으로 부하 분산하여 서비스 디스커버리가 관리하는 모든 서비스 인스턴스에 분배해야 한다.
•
회복성
: 서비스 디스커버리 클라이언트는 서비스 정보를 로컬에 캐시(cache)해야 한다. 로컬 캐싱은 서비스 디스커버리의 성능을 점진적 저하시킬 수 있는데 서비스 디스커버리 서비스가 가용하지 않을 때 애플리케이션이 로컬 캐시에 저장된 정보를 바탕으로 서비스를 찾을 수 있고 동작하게 한다.
•
장애 내성
: 서비스 인스턴스의 비정상을 탐지하고 가용 서비스 목록에서 인스턴스를 제거해야 한다.
참고: 서비스 디스커버리 아키텍처
서비스 디스커버리 아키텍처는 위에서 소개한 기능을 어떻게 구현하는가에서 시작한다.
•
서비스를 어떻게 서버에 등록하는가?
•
서비스 클라이언트가 어떻게 서비스 정보를 검색하는가?
•
서비스 정보를 노드간에 어떻게 공유하는가?
•
서비스가 자신의 상태 정보를 서버에 어떻게 전달하는가?
Service Discovery Patterns
1. Client-Side Discovery Pattern
클라이언트에서 서버(Service Registry)에서 서비스의 위치를 찾아 호출하는 방식으로, 비교적 사용이 간단하고 클라이언트는 사용 가능한 서비스의 주소를 알고 있기에 서비스에 맞게 로드 밸런싱 방법을 선택할 수 있다는 장점이 있지만, 클라이언트와 서버간에 종속성이 생기고, 서버의 프레임워크에 맞는 서비스 검색 로직을 구현해야 한다는 단점이 있다.
개요에서 소개한 Netflix OSS가 대표적인 Client-Side Discovery Pattern을 제공하며 Netflix Eureka가 서버(Service Registry)역할을 하는 OSS다.
Structure
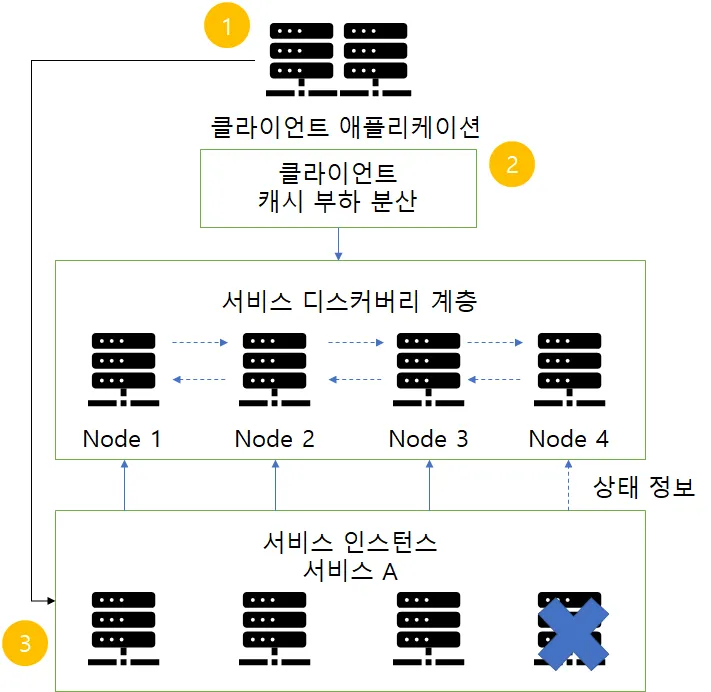
1.
클라이언트에서 서비스 호출시 로컬 캐시에 캐싱된 서비스 인스턴스 IP를 확인한다.
2.
클라이언트 측 캐시는 서비스 디스커버리 계층을 통해 주기적 업데이트를 한다.
3.
클라이언트가 캐시에서 찾은 IP를 사용하고 찾지 못하면 서비스 디스커버리에서 검색한다.
참고: Netflix Ribbon
Ribbon은 클라이언트 레벨에서 Load Balancing을 수행해주는 Netflix OSS중 하나.
Zuul을 통해 API Gateway를 구현할 수 있지만 Ribbon을 사용해 API Gateway없이도 애플리케이션을 직접 로드 밸런싱 할 수도 있다고 한다. Server-Side Load Balancer에 비교해서 H/W 부담을 줄일 수 있고 서버 목록 변경의 용이성 등의 장점을 가진다.
2. Server-Side Discovery Pattern
호출되는 서비스 앞에 로드 밸런서를 넣는 방식으로 클라이언트가 아닌 로드 밸런서가 서버(Service Registry)로부터 등록된 서비스의 위치를 전달하는 방식이다. 이 방식은 Client-Side와는 다르게 클라이언트와 서버간에 종속성은 없기에 의존성은 낮고, 클라이언트는 로드밸런서에 요청만 하면 되기에 서버에 맞는 검색 로직을 구현할 필욘 없다. 하지만 로드밸런서가 배포환경에서 제공되야하며 그게 안된다면 관리해야 할 구성 요소가 추가되는 것이다.
ELB(AWS Elastic Load Balancer)나 Kubernetes등이 있다.
structure
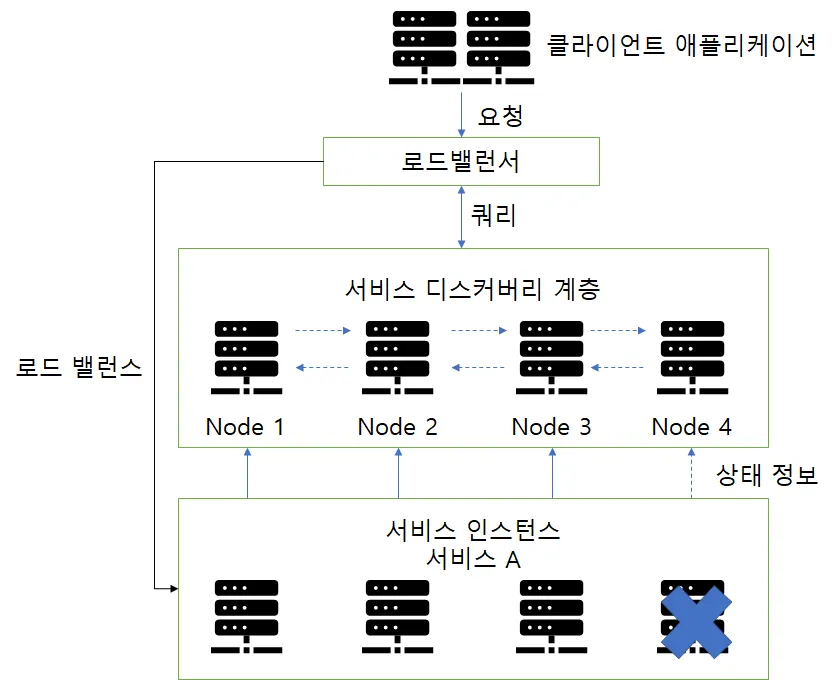
기본 구현
서버
1. 프로젝트 생성 및 yml추가
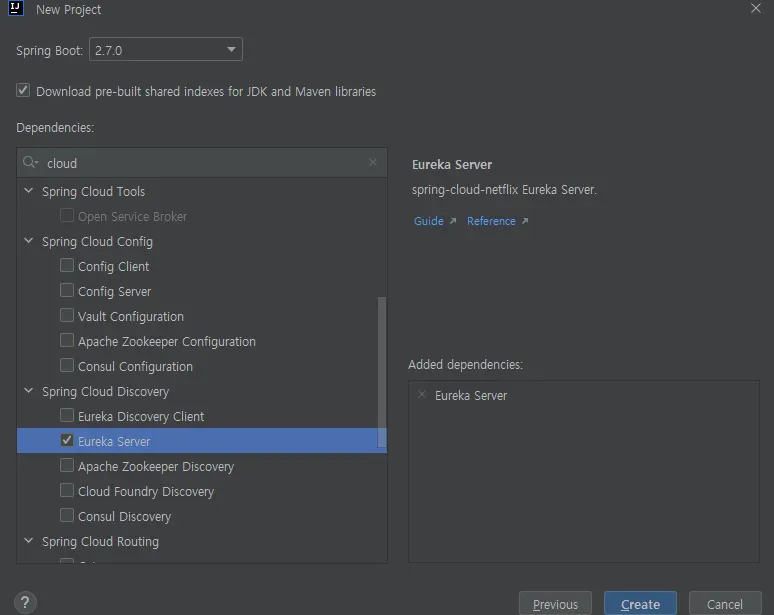
server:
port: 8761 #유레카 서버가 동작되는 포트
eureka:
client:
register-with-eureka: false #해당 서버를 클라이언트로 하겠느냐 여부
fetch-registry: false #디스커버리 등록기에 자기자신(서비스) 등록 여부
server:
wait-time-in-ms-when-sync-empty: 5 #서버가 요청 받기 전 대기할 초기 시간
YAML
복사
2. Root Class에 애노테이션 등록
@SpringBootApplication
@EnableEurekaServer //유레카 서버 등록 애노테이션
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}
Java
복사
3. 서버 동작 확인
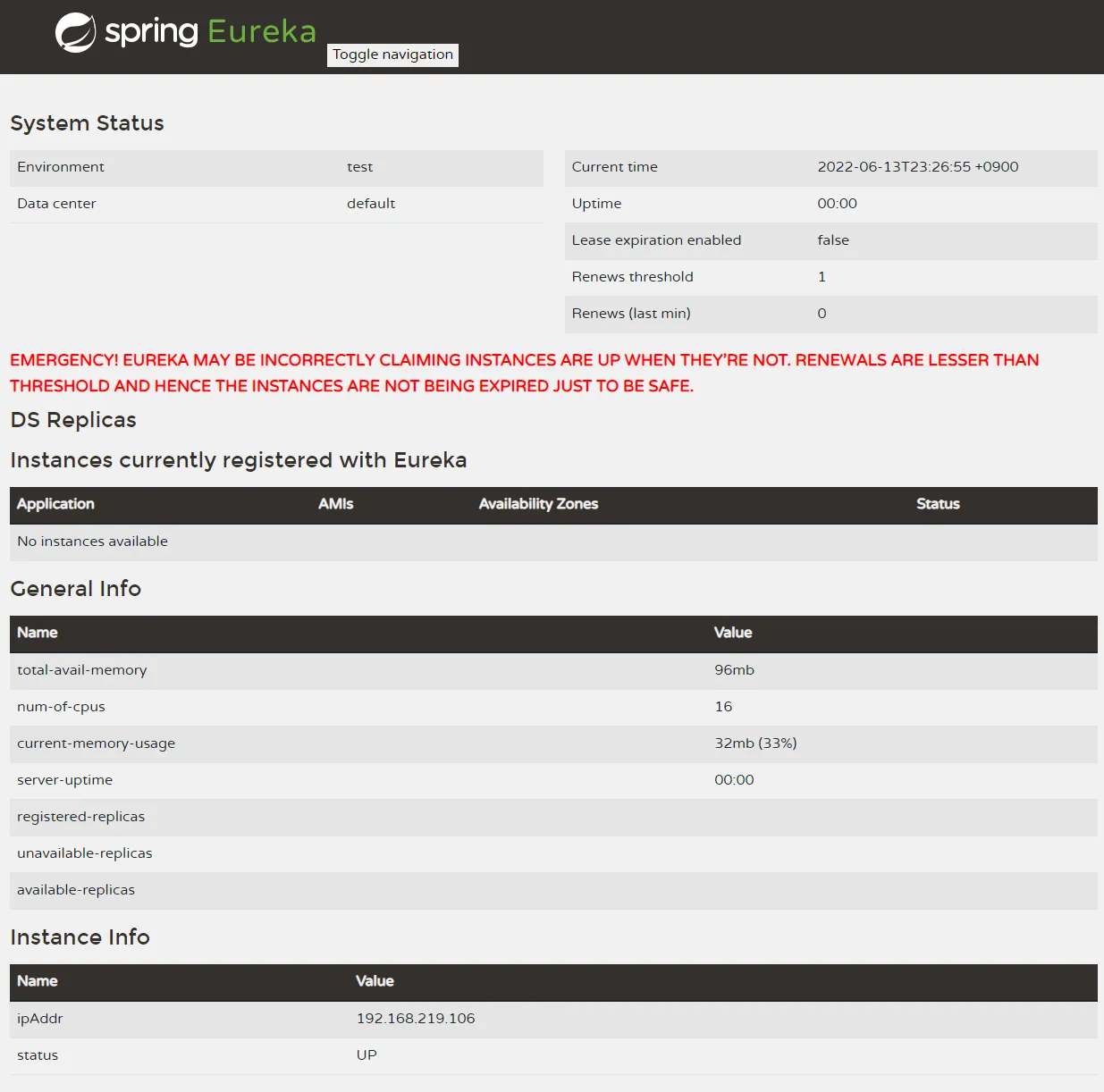
아직 등록된 서비스 애플리케이션이 없어서 인스턴스가 보이지 않는다.
클라이언트
1. 프로젝트 생성 및 yml작성

Spring Web을 필수로 등록안해주면 에러가 생긴다고 한다.
spring:
application:
name: midaseurekaservice #유레카에 등록할 서비스의 논리 이름
profiles:
active: default
eureka:
instance:
prefer-ip-address: true # 서비스 IP 주소 등록 여부
client:
register-with-eureka: true #서비스 등록 여부
fetch-registry: true # 서비스 위치
serviceUrl:
defaultZone: http://localhost:8761/eureka/ #레지스트리 사본을 로컬로 가져온다,.
YAML
복사
2. Root Class에 애노테이션 추가
@SpringBootApplication
@EnableDiscoveryClient
public class EurekaClientApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaClientApplication.class, args);
}
}
Java
복사
3. 서버/클라이언트 모두 구동 후 대시보드 확인
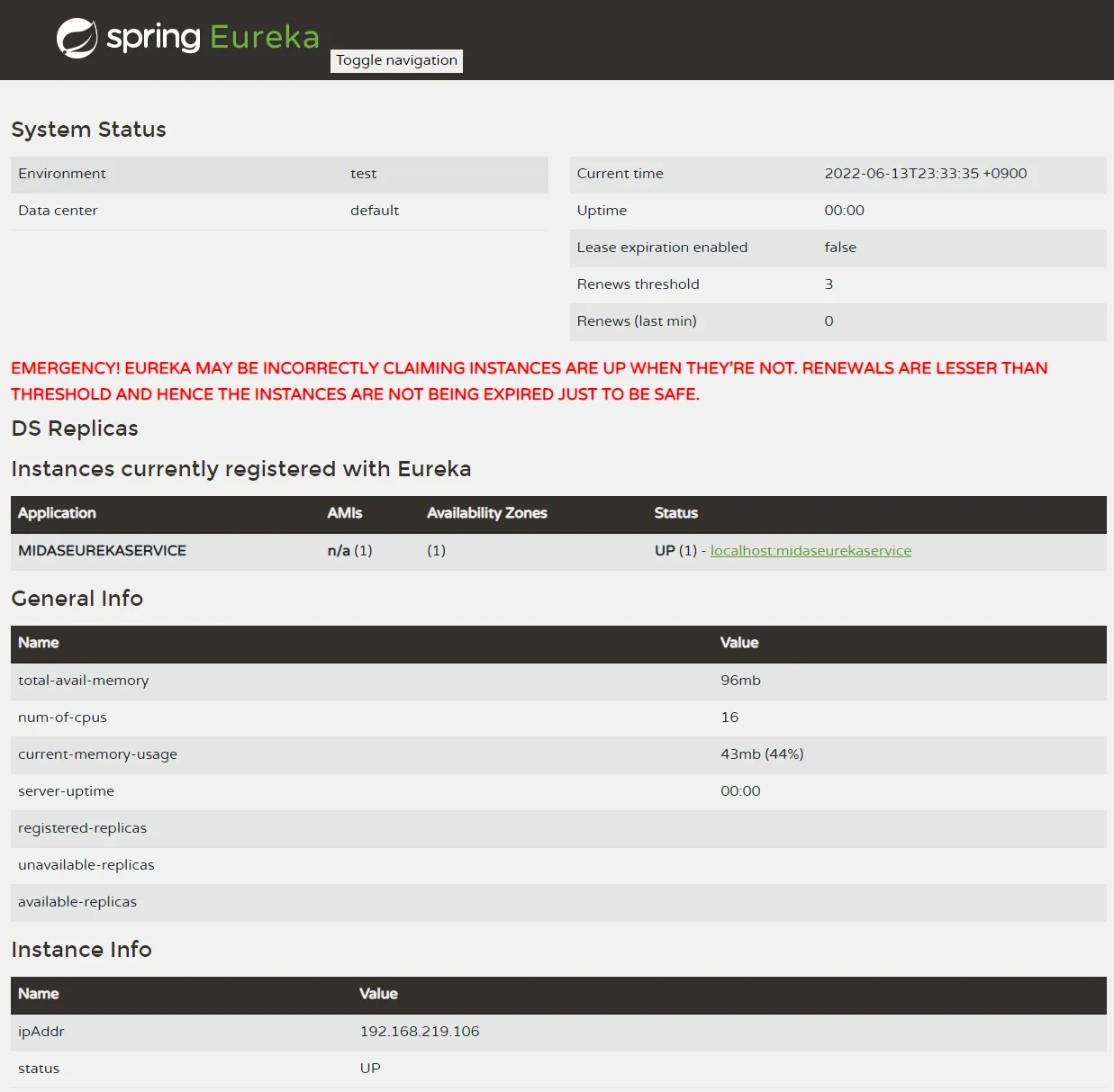
4. Postman으로 API 확인해보기
1.
http://localhost:8761/eureka/apps 으로 모든 서비스 인스턴스 확인하기
Result JSON
2.
http://localhost:8761/eureka/apps/midaseurekaservice 으로 특정 서비스 확인하기
Result JSON
Eureka APIs
1. 등록
: Eureka Client를 서버에 등록할 때 사용하는데 보통 클라이언트 애노테이션과 yaml을 이용해 자동으로 등록되기에 사용 빈도는 낮을 것으로 보인다.
POST /eureka/apps/{appID}
{
"instance": {
"instanceId": "392d9569-3a3a-4da0-9447-bfdcc14d8b30",
"hostName": "x.x.x.x",
"app": "test-service",
"ipAddr": "x.x.x.x",
"status": "UP",
"overriddenStatus": "UNKNOWN",
"port": {
"$": 8081,
"@enabled": "true"
},
"securePort": {
"$": 443,
"@enabled": "false"
},
"countryId": 1,
"dataCenterInfo": {
"@class": "com.netflix.appinfo.InstanceInfo$DefaultDataCenterInfo",
"name": "MyOwn"
},
"leaseInfo": {
"renewalIntervalInSecs": 30,
"durationInSecs": 90,
"registrationTimestamp": 0,
"lastRenewalTimestamp": 0,
"evictionTimestamp": 0,
"serviceUpTimestamp": 0
},
"metadata": {
"@class": "java.util.Collections$EmptyMap"
},
"homePageUrl": "http://192.168.4.91:8081/",
"statusPageUrl": "http://192.168.4.91:8081/actuator/info",
"healthCheckUrl": "http://192.168.4.91:8081/actuator/health",
"vipAddress": "test-service",
"secureVipAddress": "test-service",
"isCoordinatingDiscoveryServer": "false",
"lastUpdatedTimestamp": "1580878819825",
"lastDirtyTimestamp": "1580878820311"
}
}
JSON
복사
body example
2. Renew(≒ ping-pong)
유레카 클라이언트는 기본적으로 30초 주기로 서버에 HeatBeat를 보내는데, 서버측에서 90초 안에 HeartBeat를 받지 못할 경우 해당 클라이언트의 인스턴스를 제거한다.
(leaseInfo 부분에서 시간을 조회할 수 있다.)
PUT /eureka/apps/appID/{instanceID}
3. Fetch Registry
클라이언트는 서버 가동시 서버에 있는 정보를 가져와 로컬 캐시에 저장하고 이 정보를 가지고 통신을 하는데 최초 모든 정보를 요청하는 API와 그 이후 30초마다 변경된 정보만을 가져오는 API 두 가지가 있다.
GET /eureka/apps ← 모든 정보를 다 조회하는 API
GET /eureka/apps/delta ← 변경된 정보만을 가져오는 API
4. Delete
서버측에서 특정 클라이언트의 인스턴스를 제거할 때 사용한다.
HeartBeat 송수신에 문제가 생겼거나 다수의 인스턴스 실행에서 Service Discovery가 제거를 못하는 경우 수동으로 사용할 수 있다.
DELETE /eureka/apps/{appId}/{instanceID}
DELETE /eureka/apps/test-service/5a7af17d-8800-4408-9855-ac55246d070d
Plain Text
복사
example

