
목차
개요
잘못될 수 있는 것과 잘못될 수 없는 것 사이의 주된 차이점은 잘못될 수 없는 것이 잘못됐을 때는 잘못을 파악하거나 고치는 것은 거의 불가능하다는 점이다.
- 더글라스 애덤스, 대체로 무해함(1992)
해당 챕터의 주제인 복제라는 키워드는 네트워크로 연결된 여러 장비에 동일한 데이터의 복사본을 유지한다는 의미다. 즉 Catsbi라는 데이터를 네트워크의 연결된 device1, device2, device3,… deviceN 에서 모두 복사본을 가지고 있다는 의미이다.
어째서 이런 데이터 복제가 필요한 것일까?
1.
지연 시간
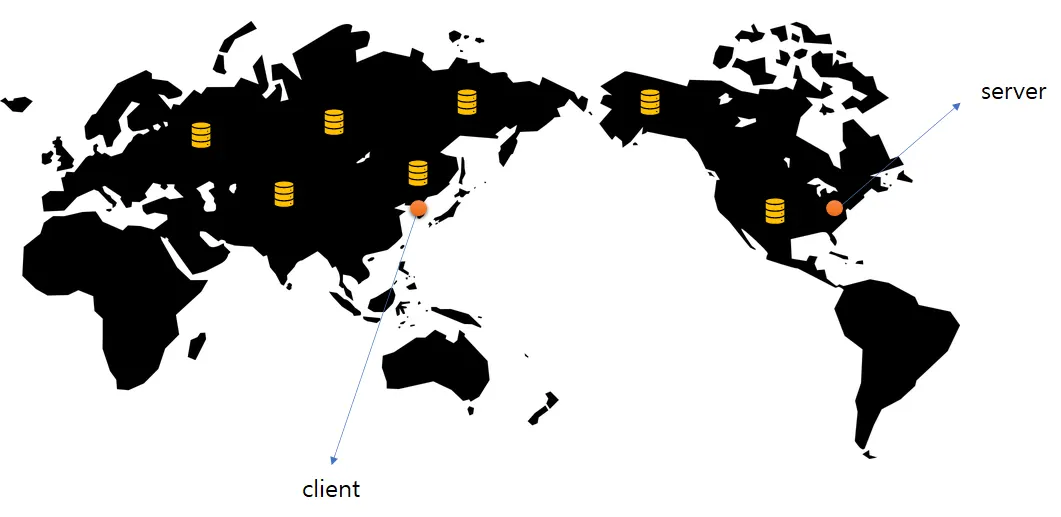
지리적으로 클라이언트와 데이터가 가까히 있을수록 지연시간을 줄일 수 있다.
2.
고가용성
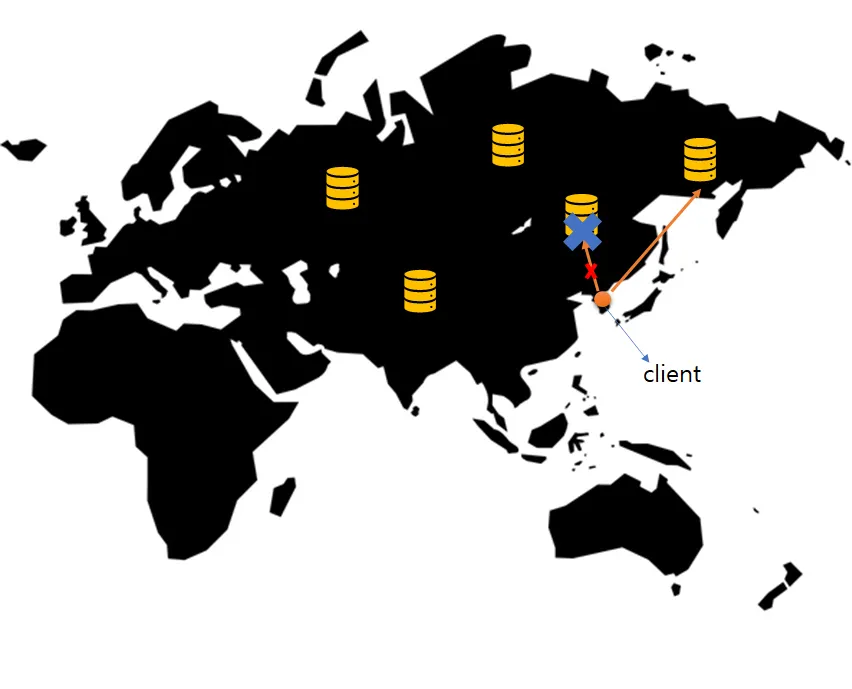
기존의 연결되던 서버에 장애가 발생해도 지속적으로 동작을 할 수 있도록 가용성을 높힌다.
3.
읽기 질의 처리량

읽기 질의를 제공하는 장비가 요청하는 질의보다 적을 경우 위와 같은 병목(bottleneck)현상이 발생할 수 있다. 이를 장비의 수를 늘려서 읽기 처리량을 늘릴 수 있다.
불변 데이터의 복제는 쉽다. 하지만…
복제중인 데이터가 시간이 지나도 변경되지 않는 데이터(immutable)라면 그냥 모든 노드에 데이터를 복사하면 끝이다.
하지만, 데이터가 변경될 수 있는 데이터(mutable)일 경우 복제된 데이터의 변경 처리도 책임져야 하는데 이는 복제의 큰 어려움이라 할 수 있고 노드 간 변경을 복제하기 위해 인기있는 세 가지 알고리즘을 알아 볼 것이다. 대부분의 분산 데이터베이스는 이 세 가지 방법 중 하나를 사용한다.
•
단일 리더(single-leader) 복제
•
다중 리더(multi-leader) 복제
•
리더 없는(leaderless) 복제
이번 장에서는 이 알고리즘에 대해 알아보고, 그 밖에 복제에서 고려해야 하는 트레이드오프에 대해서도 알아본다. (Ex: 동기/비동기, 잘못된 복제본 처리, …)
리더와 팔로워
복제 서버(replica)
데이터베이스의 복사본을 저장하는 각 노드를 복제 서버(replica)라 부른다.
 어떻게 모든 복제 서버에 동일한 데이터를 유지할 수 있을까? 리더 기반 복제(leader-based replication)(or 능동(active)/수동(passive), master - slave 복제)
어떻게 모든 복제 서버에 동일한 데이터를 유지할 수 있을까? 리더 기반 복제(leader-based replication)(or 능동(active)/수동(passive), master - slave 복제)리더 기반 복제
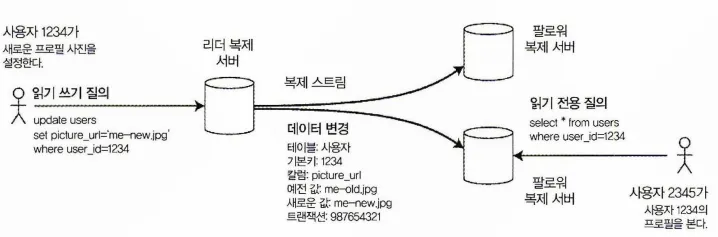
•
복제 서버 중 하나를 리더(leader)(or master, primary)로 지정한다.
◦
클라이언트는 쓰기 질의 요청을 리더에게 보내야 한다.
◦
리더는 먼저 로컬 저장소에 새로운 데이터를 기록한다.
•
다른 복제 서버는 팔로워(follower)(읽기 복제 서버(read replica), Slave, 2차(secondary), 핫 대기(hot standby))라고 한다.
◦
리더가 로컬 저장소에 변경을 기록하면 이를 복제 로그(replication log)나 변경 스트림(change stream)의 일부로 팔로워에게 전송한다.
◦
팔로워는 전달받은 로그를 기반으로 리더가 처리한 것과 동일한 순서로 모든 쓰기를 적용해 로컬 복사본을 갱신한다.
이러한 복제 모드는 postgreSQL(v9.0 ), MySQL, 오라클 데이터 가드, SQL 서버의 상시 가용성 그룹과 같은 여러 관계형 데이터베이스에 내장된 기능이다.
), MySQL, 오라클 데이터 가드, SQL 서버의 상시 가용성 그룹과 같은 여러 관계형 데이터베이스에 내장된 기능이다.(몽고DB, 리싱크DB, 에스프레소같은 일부 비관계형 데이터베이스에서도 사용한다. )
더하여, 꼭 데이터베이스뿐 아니라 분산 메세지 브로커에서도 사용되며, 일부 네트워크 파일 시스템, 복제 블럭 디바이스에서도 유사하게 사용된다.
sync vs async 복제
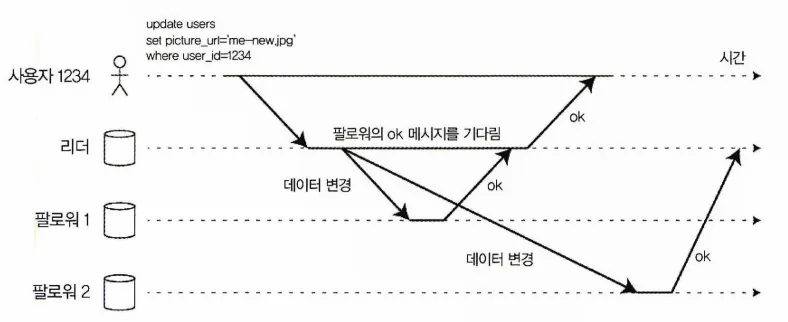
팔로워1(동기식), 팔로워2(비동기식) 리더 기반 복제
•
팔로워1은 동기식 복제로 리더는 팔로워의 응답을 기다린다.
◦
팔로워가 응답을 하지 않을 경우 리더는 모든 쓰기를 차단(block)하고 기다린다.
•
팔로워2는 비동기식 복제로 리더는 메시지를 전송하지만 응답을 기다리지 않는다.
◦
팔로워가 변경 내용을 적용하기까지 시간을 보장할 수 없다.
▪
Ex: 팔로워가 장애 복구 중, 네트워크 문제 등
모든 팔로워가 동기식이라면?
동기식 복제의 경우 리더는 팔로워의 응답을 계속해서 기다려야 한다. 그런데, 모든 팔로워가 동기식 복제를 사용한다면, 임의의 노드 하나에서 장애가 발생했을 때 전체 시스템이 멈추게 된다.
그렇기에 데이터베이스에서 동기식 복제를 사용하려면 팔로워 하나는 동기식, 그 외에는 비동기식으로 하는 것을 의미한다.
그리고 여기서 동기식 팔로워가 특정 이유등으로 사용할 수 없거나 느려지게 되면, 기존의 비동기식 팔로워를 동기식으로 바꿈으로써 최소한 리더와 동기식 팔로워 하나 총 두 개의 노드에는 최신 복사본이 있는것을 보장할 수 있게 되는데, 이러한 설정을 반동기식(semi-synchronous)이라 한다.
리더 기반 복제는 완전한 비동기식 구성
보통 리더 기반 복제는 완전히 비동기식으로 구성한다.
그렇기에 리더가 잘못된다면 복제되지 않은 쓰기는 모두 유실된다. 하지만 모든 팔로워에 문제가 생겨도 리더는 계속해서 쓰기 처리를 할 수 있다는 장점을 가진다.
클라이언트 입장에서는 내가 요청한 쓰기의 지속성이 보장되지 않는다는 문제가 있지만, 그럼에도 불구하고 팔로워가 많거나 지리적으로 분산되어있다면 비동기식 복제를 많이 사용한다.
참고. 체인 복제
완전한 비동기식 구성에서 리더가 잘못되었을 경우 발생하는 데이터 유실을 막기 위한 방법 중 하나로 MS의 애저(Azure) 저장소와 같은 일부 시스템에 성공적으로 구현된 동기식 복제의 변형이다.
새로운 팔로워 설정
새로운 팔로워가 리더의 데이터 복제본을 정확히 가지고 있다고 어떻게 보장할까? 데이터베이스를 잠근 후 복제를 할 경우 일관성은 확보할 수 있지만, 가용성 목표를 놓치게 된다.
그렇기에 중단없이 팔로워 설정을 할 수 있어야 하는데 다음과 같이 할 수 있다.
•
DB를 잠그지 않고 리더의 DB 스냅숏을 가져온다.
•
스냅숏을 새로운 팔로워 노드에 복사한다.
•
팔로워는 리더와 연결해 스냅숏 이후 발생한 데이터 변경을 요청한다.
•
팔로워가 스냅숏 이후의 변경을 모두 처리했을 때 따라잡았다고 말한다.
참고: 로그 일련번호, 이진로그 좌표
팔로워가 리더와 연결했을 때 정확하게 스냅숏 이후 발생한 변경을 가져오고 싶다면, 정확한 스냅숏의 위치를 알아야 한다. postgreSQL에서는 로그 일련번호(log sequence number), MySQL에서는 이진로그 좌표(binlog coordinate)라 부른다.
노드 중단 처리
별도의 중단시간 없이 개별 노드를 재부팅할 수 있다면 운영 및 유지보스 측면에서 큰 장점이다.
그럼 어떻게 개별 노드에 장애가 발생해도 전체 시스템은 정상적으로 유지되고, 노드 중단의 영향을 최소화 할 수 있을까? (리더 기반 복제의 고가용성)
1. 팔로워 장애: 따라잡기 복구
팔로워 장애 복구는 매우 쉽게 복구가능하다.
1.
결함 발생 직전 최종 수행 트랜잭션을 알아낸다.
2.
리더와 연결한 뒤 연결이 끊어진 동안 발생한 데이터 변경을 모두 요청한다.
3.
미처리 변경을 모두 적용하여 리더를 따라잡으면 복구 해결
2. 리더 장애: 장애 복구
리더의 장애를 처리하는건 매우 까다로운 장애 복구(failover) 과정을 거쳐야 한다.
1.
팔로워 중 하나를 리더로 승격한다.
2.
클라이언트는 새로운 리더에게 쓰기를 전송하기 위해 재설정을 한다.
3.
다른 팔로워는 새로운 리더로부터 데이터 변경을 소비해야 한다.
이러한 장애 복구 과정을 수동 혹은 자동으로 진행할 수 있는데, 수동의 경우 관리자가 장애 알림을 받고 적절한 조치를 취한다면 자동 장애 복구는 다음과 같은 단계로 구성된다.

1.
리더 장애 판단
: 리더가 일정 시간 동안 응답하지 않을 경우(timeout) 죽은 것으로 간주한다.
2.
새로운 리더 선택
: 합의(Ex: 복제 서버 다수결) 혹은 선출된 제어 노드(controller node)에 의해 새로운 리더가 선정될 수 있다.
3.
시스템 재설정
: 리더가 새로 선정되었으면 다음과 같은 새로운 설정들이 필요하다.
•
클라이언트는 새로운 리더에게 쓰기 요청을 보내야 한다.
•
시스템은 이전 리더가 팔로워가 되고 새로운 리더를 인식할 수 있게 해야 한다.
장애 복구 과정에서 발생할 수 있는 문제점
•
비동기식 복제를 할 경우 이전 리더의 쓰기 데이터 유실 가능성
◦
이전 리더가 처리하지 못한 쓰기를 모두 폐기해 해결할 수 있지만, 내구성이 떨어지게 된다.
•
개인 정보 유출
◦
이전 리더가 데이터베이스의 새로운 로우의 기본키 할당을 위해 자동증가 카운터를 사용했는데, 새로운 리더는 이전 리더의 쓰기가 유실된 경우 이 사실을 알 수 없기에 예전에 할당한 기본키를 재사용하게 되는데, 이 경우 불일치가 발생하여 개인정보가 잘못된 사용자에게 공개될 수 있다.
•
스플릿 브레인(split brain)
◦
두 노드가 모두 자신이 리더라고 믿는 상황. 두 리더가 쓰기를 받으면서 충돌을 해결하는 과정을 거치지 않으면 데이터가 유실 혹은 오염될 수 있다.
•
불필요한 장애 복구
◦
리더가 죽었다고 판단하는 타입아웃 시간을 너무 길게하면 리더가 작동하지 않은 시간부터 복구까지 시간이 오래걸린다. 그렇다고 너무 짧은 타임아웃 시간은 불필요한 장애 복구가 있을 수 있다.
복제 로그 구현
다양한 리더 기반 복제 방법들에 대해 알아보자.
구문 기반 복제 과정
•
리더는 모든 쓰기 요청(구문(statement))을 기록하고
•
쓰기를 실행한 다음
•
구문 로그를 팔로워에게 전송한다.
◦
RDB는 전달받은 SQL문을 파싱하고 실행한다.
문제점은
•
비결정적 함수(Ex: NOW(), RAND(), …)호출 시 복제 서버마다 다른 값을 생성할 수 있다.
•
자동증가 칼럼(auto increament)을 사용하거나 DB에 있는 데이터에 의존하는 경우, 각각의 복제 서버들은 모두가 동일한 순서로 실행되야 한다. 이는 여러 트랜잭션이 동시에 수행되는 것을 제한하게 한다.
•
부수 효과를 가진 구문(Ex: trigger, stored procedure, custom function)이 조금이라도 비결정적이라면 각 복제 서버에서 다른 사이드 이펙트가 발생할 수 있다.
해결책은
•
리더가 구문을 기록할 때 모든 비결정적 함수 호출을 고정 값을 반환하도록 대체할 수 있다.
(엣지 케이스들로 인해 다른 복제 방법을 선호한다.)
쓰기 전 로그 배송
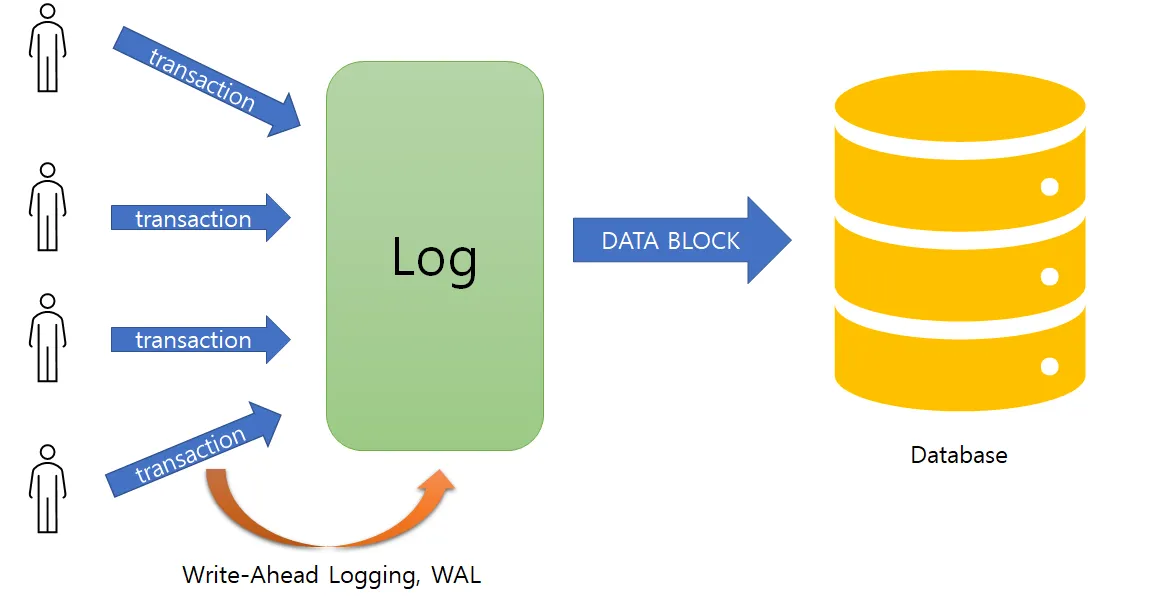
Write-Ahead Logging, WAL(읽기 전 쓰기)
일반적으로 모든 쓰기는 로그에 기록을 하는데, 완전히 동일한 로그를 사용하여 다른 노드에서 복제 서버를 구축할 수 있다.
리더는
→ 디스크에 로그를 기록하고, 팔로워에게 로그를 전송한다.
팔로워는
→ 전송받은 로그를 처리하면 리더와 동일한 데이터 구조의 복제본이 만들어진다.
이러한 복제 방식은 로그가 제일 저수준의 데이터를 기술하기 때문에 문제가 될 수 있는데, 예를 들어 B-Tree는 변경을 쓰기 전 로그(Write-aheead log, WAL)에 쓰는데, 이 때문에 복제가 저장소 엔진과 의존성이 생기게 된다. 그렇기에 리더와 팔로워의 DB 버전을 다르게 가져갈 수 없다.
소프트웨어 버전 업데이트가 필요한 경우
팔로워가 먼저 업그레이드를 한 뒤 리더를 업그레이드 하면 별도의 중단시간을 가지지 않고도 소프트웨어 업그레이드 수행이 가능하다. 팔로워들은 이미 업그레이드가 되었기 때문에 팔로워 노드 중 하나를 새로운 리더로 선정하기 위해 장애 복구를 수행할 수도 있다.
논리적(로우 기반) 로그 복제
복제 로그가 저장소 엔진과 의존성을 줄이기 위한 대안으로 다른 로그 형식을 가지는 것으로 이런 종류의 복제 로그를 논리적 로그(logical log)라 부른다.
RDB용 논리적 로그는 보통 로우 단위로 데이터베이스 테이블에 쓰기를 기술한 레코드 열이다.
•
삽입된 로우의 로그는 모든 칼럼의 새로운 값을 포함한다.
•
삭제된 로우의 로그는 식별 정보를 포함한다. (Ex: Primary Key)
•
갱신된 로우의 로그는 식별 정보와 새로운 값을 포함한다.
이러한 논리적 로그 형식은 외부 애플리케이션이 파싱하기 쉽기 때문에 데이터 웨어하우스 같은 외부 시스템에 데이터베이스의 내용을 전송하고자 할 때 유용하며 이러한 기술을 변경 데이터 캡쳐(change data capture)라 부른다.
트리거 기반 복제
트리거는 사용자 정의 애플리케이션 코드를 등록해서 데이터베이스 시스템에서 데이터 변경이 감지되면 자동으로 등록된 코드를 실행하도록 할 수 있다. 이런 기능을 통해 애플리케이션이 데이터를 변경할 수 있도록 한다. RDBMS에서는 트리거 or 스토어드 프로시저를 사용한다.
다만, 트리거 기반 복제는 다른 방식에 비해 오버헤드가 더 많고, 버그나 제한 사항이 더 많이 발생한다. 하지만 유연성 측면에서 매우 유용하다.
복제 지연 문제
복제가 필요한 이유는 내결함성 뿐 아니라 확장성과 지연 시간도 있다.
읽기 확장(read-scaling)
왜 확장성을 위해 복제가 필요할까? 리더 기반 복제의 경우 단일 노드를 거쳐야만 하는 쓰기와는 다르게 읽기는 복제 서버에서 진행해도 가능하다. 즉, 하나의 단일 노드를 거쳐야 하는 제약이 사라지면서 병목 현상을 줄일 수 있는 것이다.
그렇기에, 작업 부하가 대부분 읽기 요청인 경우 팔로워를 많이 만든 후 읽기 요청을 분산하여 리더의 부하를 없앨 수 있는데, 이런 구조(architecture)를 읽기 확장(read-scaling)이라 한다.
비동기 복제에서만 가능한 구조
•
동기식으로 모든 팔로워에 복제를 시도할 경우 네트워크 중단이나 단일 노드 장애가 전체 시스템의 장애가 될 수 있다.
최종적 일관성
비동기 팔로워에서 데이터를 읽을 때는 다음과 같이 팔로워간의 데이터 일관성이 보장되지 않아 지난 정보를 볼 수도 있다.
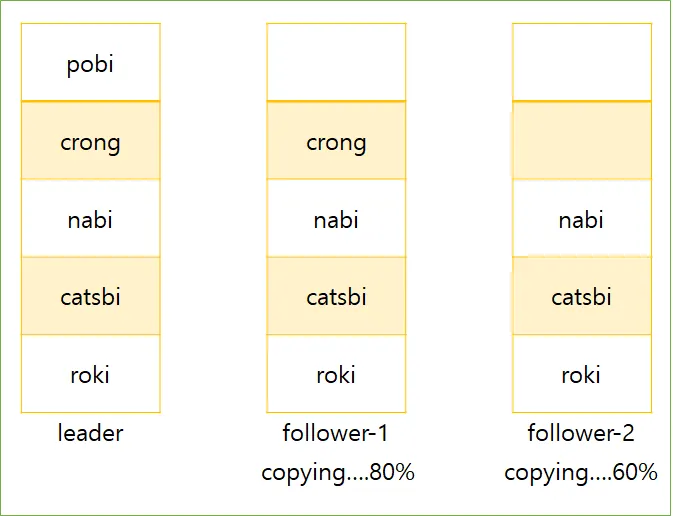
추가된 내용 팔로워 복사
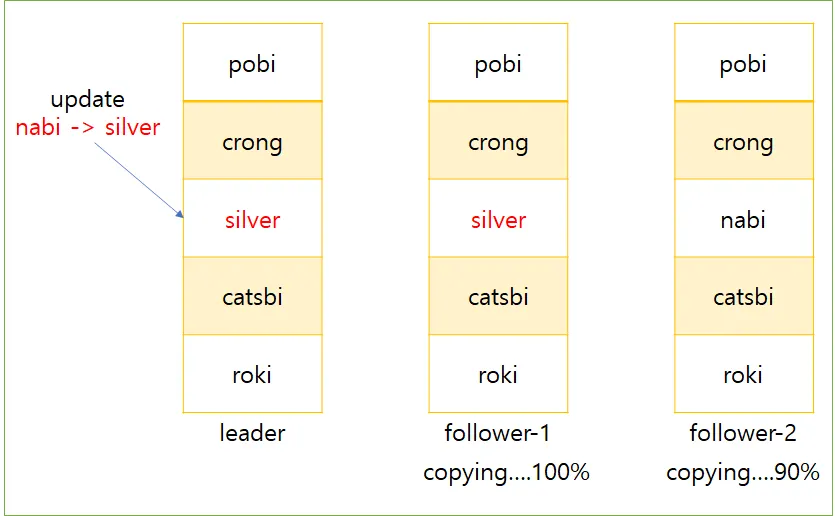
갱신된 내용 팔로워 복사
하지만, 기다리면 결국 팔로워는 리더를 따라잡고, 리더와 일치하게 되는데, 이런 효과를 최종적 일관성이라 한다.
하지만, 팔로워가 리더를 언제 따라잡을지 팔로워가 얼마나 뒤처질 수 있는지에 대한 제한이 없다. 특정 이유(시스템이 가용량 근처에서 동작하거나, 네트워크 문제가 있는 경우)로 수 분 이상 뒤처질 경우 문제가 커진다.
복제 지연 발생시 발생할 수 있는 사례 및 해결책
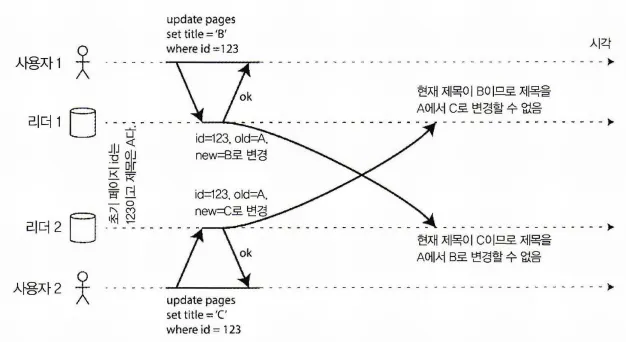
자신이 쓴 내용 읽기
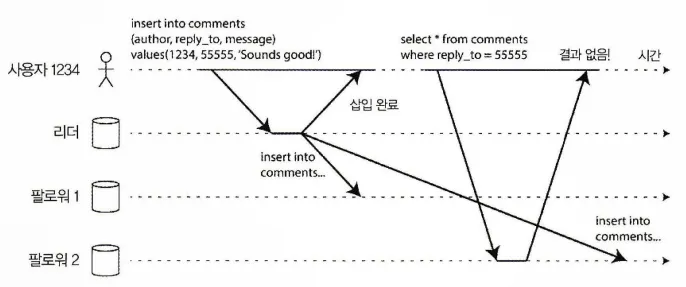
사용자가 쓰기를 진행 후 복제가 완료되지 않은 서버에서 데이터를 읽는 경우
위 그림을 보면 사용자 1234는 소리가 좋다는 코멘트를 달고, 자신이 쓴 댓글을 보려고 시도했다.
하지만, 리더에 추가된 코멘트 내용이 팔로워 모두에게 반영이 아직 안 된 상황에서 사용자 1234는 반영이 안된 팔로워 서버에 읽기 요청을 했기 때문에 결과가 없다고 나올 것이고, 이는 서비스의 신뢰도 하락 및 만족도 하락으로 이어질 수 있다.
그렇기에 리더 기반 복제 시스템에서는 쓰기 후 읽기(read-after-write) 일관성이 필요하다.
쓰기 후 일관성을 구현하는 몇 가지 방법은
•
사용자가 수정한 내용을 읽을 땐 리더에서 읽도록 한다.
◦
질의하지 않고도 무엇이 수정됐는지 알 수 있는 방법이 필요하다.
◦
Ex: 소셜 네트워크의 사용자 프로필은 소유자만 편집할 수 있다.
•
마지막 갱신시간을 기준으로 1분간 리더에서 읽기를 수행하도록 한다.
•
팔로워가 가장 최근 쓰기 타임스탬프까지 갱신을 반영하도록 하며 읽기 질의를 대기시킬 수 있다.
•
리더가 포함된 데이터센터로 라우팅하도록 해 복잡도를 낮출 수 있다.
◦
복잡도가 낮다면 팔로워가 리더를 따라잡는데 걸리는 비용이 낮아질 수 있다.
같은 사용자가 하나의 장비가 아닌 여러 장비로 서비스를 접근할 경우를 대비해 디바이스 간(cross-device) 쓰기 후 읽기 일관성도 제공되야 한다. 그러기 위해 다음 두 가지 문제점을 같이 고려해줘야 한다. •
한 디바이스에서 다른 디바이스에서 발생한 갱신을 알 수 없기에 갱신 타임스탬프 같은 메타데이터는 중앙집중식으로 관리해야 한다.
•
팔로워가 여러 데이터센터에 분산되어 있다면 디바이스가 각각 다른 데이터센터로 라우팅될 수 있다. 리더에서 읽어야 할 필요가 있는 접근일 경우 사용자 디바이스의 요청을 동일한 데이터센터로 라우팅해야 한다.
단조 읽기
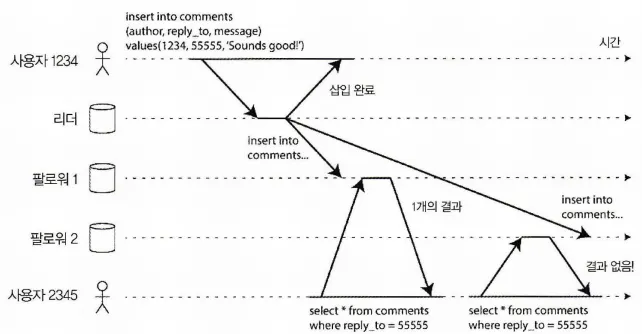
최신 복제 서버에서 읽은 뒤 예전 복제 서버에서 읽을 경우 시간 역전 현상이 발생한다.
위 그림을 보면 사용자 1234는 코멘트를 남긴 후 사용자 2345가 코멘트를 2회 확인 시도한다.
최초에는 복제가 완료된 상태인 팔로워1에서 시도했기에 새로운 코멘트를 확인할 수 있다. 하지만 재시도 하는 경우 아직 복제가 완료되지 않은 팔로워2에서 시도했기에 코멘트 내용을 확인할 수 없다. 이런 문제를 해결하기 위해 단조 읽기(monotonic read)이 필요하다.
단조 읽기는 새로운 데이터를 한 번 읽은 후에는 예전 데이터를 읽지 않는 것인데, 각 사용자가 동일한 복제 서버에서 읽기를 할 수 있도록 하는 것인데, 사용자 ID의 해시를 기반으로 복제 서버를 선택하도록 할 수 있다.
(물론, 해당 복제 서버가 고장날 경우 다른 복제 서버로 재라우팅할 필요가 있다.)
일관된 순서로 읽기
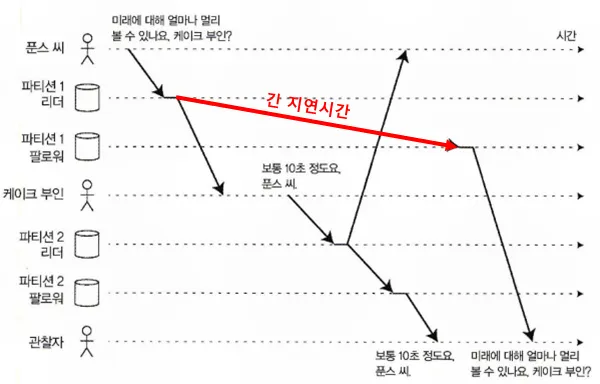
일부 파티션이 다른 것보다 느리게 복제되는 경우 관찰자는 질문보다 답변을 먼저 볼 수 있다.
푼스씨와 케이크부인의 대화를 지켜보고 있는 관찰자가 있다고 하자.
푼스씨의 질문이 먼저 나왔지만, 파티션1 리더 서버에서 파티션1 팔로워 서버로 긴 복제 지연이 있었다. 그렇기에 케이크부인의 답변이 먼저 파티션2의 리더와 팔로워까지 복제가 완료되고 관찰자가 확인할 수 있다보니, 관찰자 입장에서는 답변 후 질문을 하는 이상한 모습으로 보인다.
이런 문제를 방지하기 위해서는 일관된 순서로 읽기(Consistent Prefix Read)가 필요하다.
서로 인과성이 있는 쓰기가 동일한 파티션에 기록되게끔 하여 순서를 맞출 수 있다.
복제 지연을 위한 해결책
최종적 일관성으로 결국에는 모든 팔로워는 리더를 따라잡는다.
하지만, 따라잡기까지 걸리는 시간을 예측하기 힘들기 때문에 최종적 일관성에만 기댈수는 없다.
그렇기에 쓰기 후 읽기와 같은 방식을 사용하거나, 비동기식으로 동작하지만 동기식으로 동작하는 척 하는 것도 해결방안이다.
•
애플리케이션 코드에서 이러한 문제를 다루기에는 너무 복잡하고 잘못될 가능성이 높다.
•
트랜잭션을 이용해 애플리케이션은 더 단순하고, DB는 더 강력한 보장을 제공할 수 있다.
◦
분산 데이터베이스 환경으로전환되며 비용문제로 트랜잭션 사용 우려
다중 리더 복제
단일 리더 기반 복제는 다음과 같은 문제가 있다.
•
모든 쓰기는 해당 리더를 거쳐야 한다.
•
리더에 연결할 수 없는 경우 데이터베이스에 쓰기를 할 수 없다.
이런 문제를 해결하기 위해
•
쓰기를 허용하는 노드를 하나 이상 두는 것으로 리더를 다중으로 확장할 수 있다.
◦
각각의 리더는 다른 리더의 팔로워 역할도 한다.
◦
이런 방식을 다중 리더 설정이라 하며 마스터 마스터/ 액티브 액티브 복제라고도 한다.
다중 리더 복제의 사용 사례
다중 데이터센터 운영
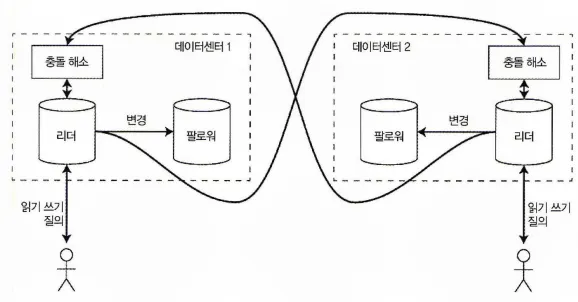
다중 데이터센터 간 다중 리더 복제
•
다중 리더 설정에서는 각 데이터센터마다 리더가 있을 수 있다.
•
각 데이터센터 내에서는 리더 기반 복제를 사용한다.
•
각 데이터센터의 리더끼리 변경 사항을 복제한다.
이러한 다중 데이터센터 환경에서 다중 리더 복제를 사용할 경우
•
사용자는 자신의 로컬 데이터센터에서 쓰기를 할 수 있고, 로컬 데이터센터는 처리된 쓰기를 비동기 방식으로 다른 데이터센터에 복제하기에 데이터센터간의 네트워크 지연은 숨겨진다.
•
데이터센터에 장애가 발생해도 각 데이터센터는 독립적으로 동작하고 장애가 회복된 데이터센터는 복제를 따라잡으면 된다.
•
비동기 복제를 사용하는 다중 리더 설정에서는 네트워크 중단에도 쓰기 처리는 진행될 수 있기 때문에 네트워크 문제에서 내성을 가지게 된다.
하지만, 다중 리더 복제를 사용하면 동일한 데이터를 두 개의 데이터센터에서 동시에 변경할 수 있기 때문에 이 때 발생하는 쓰기 충돌을 해소해야 한다.
참고: 다중 리더 기능 제공 도구일부 DB에서는 기본적으로 다중 리더 설정을 제공하지만, 외부에서 구현한 도구를 사용해서 다중 리더 설정을 사용하기도 한다.
- MySQL: 텅스텐 리플리케이터(Tungsten Replicator)
- PostgreSQL: BDR
- Oracle: 골든게이튼(Goldengate)
Plain Text
복사
오프라인 작업을 하는 클라이언트
사용자는 오프라인 환경에서도 작업을 해야하는 일이 발생한다.
내가 핸드폰 혹은 노트북과 같은 디바이스에서 캘린더 앱으로 일정 관리(CRUD)를 할 수 있어야하고, 온라인 환경이 되었을 때는 오프라인 환경에서 작업한 내용이 동기화되어 다른 장비에서도 동일한 화면을 볼 수 있어야 한다.
모바일 캘린더 앱 일정 관리
그렇기에 각 디바이스는 리더처럼 동작하는 로컬 데이터베이스가 있어야 하고, 온라인 환경이 되었을때 디바이스의 로컬 데이터베이스간 다중 리더 복제를 비동기 방식으로 수행하는 동기화 프로세스가 있어야 한다. 이 때 복제 지연(오프라인 → 온라인이 되는 시간)은 최대 몇 일 이상이 걸릴 수도 있다.
아키텍처 관점에서 이러한 설정이 데이터센터 간 다중 리더 복제와 동일하다.
각각의 디바이스를 데이터센터로 보면 되는데, 이런 디바이스 간 네트워크 연결의 신뢰도는 낮기에 다중 리더 복제가 올바르게 동작하기는 까다롭다.
카우치DB는 이런 다중 리더 설정을 쉽게 하기 위한 도구 중 하나이다.
협업 편집
컨플루언스나 노션, 구글 스프레드시트 등에서는 여러명이 동시에 동일한 문서를 편집할 수 있다.
이런 애플리케이션을 실시간 협업 편집 애플리케이션이라 한다.
•
한 사용자가 문서를 편집하며 발생한 변경점이 로컬 복제 서버에 적용한 뒤 동일한 문서를 편집하는 다른 사용자와 서버에 비동기 방식으로 복제한다.
•
사용자들의 변경점이 겹치는 경우 편집 충돌이 발생할 수 있다.
•
편집 충돌이 없음을 보장하기 위해서는 문서의 잠금을 얻어야 하는데, 이렇게 되면 리더에서 트랜잭션을 사용하는 단일 리더 복제와 동일하다.
•
빠른 협업을 위해 변경 단위를 매우 작게(Ex: 단일 키 입력)해서 잠금을 피할 수 있다.
◦
이 방법은 충돌 해소가 필요한 경우 및 다중 리더 복제에서 발생하는 모든 문제를 야기시킨다.
쓰기 충돌 다루기
동일한 레코드 동시 쓰기 - 쓰기 충돌
다중 리더 복제는 쓰기가 동시에 이뤄지다보니 쓰기 충돌이 발생하는데, 이러한 쓰기 충돌은 해소가 필요하다.
동기 대 비동기 충돌 감지
•
동기식으로 충돌 감지를 만들 경우
◦
쓰기가 성공한 사실이 응답되기 전까지 모든 복제써버에 쓰기 금지
◦
다중 리더 복제의 주요 장점을 잃는다.
•
비동기식으로 충돌 감지를 만들 경우
◦
다중 리더 설정에서 두 쓰기는 모두 성공하고 특정 시점에 충돌을 감지한다.
◦
사용자에게 충돌을 알리는 시점이 너무 늦을 수 있는 단점이 있다.
충돌 회피
•
특정 레코드의 모든 쓰기가 동일한 리더를 거치도록 한다.
•
충돌 회피가 실패하는 경우
◦
데이터센터에 장애가 발생해 동일한 리더를 거치도록 할 수 없게 된다.
◦
사용자의 위치가 다른 데이터센터가 더 가깝도록 이동한다.
•
다른 리더에서 동시 기록 가능성을 대처해야 한다.
일관된 상태 수렴
•
다중 리더 설정에서는 여러 서버에서 발생하는 쓰기에 순서가 없어 최종 값을 알기 때문에
•
DB는 수렴(convergent) 방식으로 충돌을 해소해야 한다.
◦
모든 변경이 복제되어 모든 복제서버에 동일한 최종 값이 전달되게 해야 한다는 의미
수렴 충돌 해소를 달성하는 몇가지 방법은•
각 쓰기에 고유 ID(ex: UUID) 부여 후 우선 순위가 높은 쓰기를 고르는 방식
◦
데이터 유실의 위험이 있다.
◦
고유 ID를 타임스탬프로할 경우 최종 쓰기 승리(last write wins, LWW)라 한다.
•
각 복제 서버에 공유 ID를 부여 후 우선 순위가 높은 복제 서버에서 생긴 쓰기가 우선시되도록 하는 방식
◦
데이터 유실의 위험이 있다.
•
명시적 데이터 구조에 충돌을 기록해 모든 정보를 보존한다.
◦
차후 충돌을 해소하는 애플리케이션 코드를 작성한다.
사용자 정의 충돌 해소 로직
대부분의 다중 리더 복제 도구는 애플리케이션 코드를 사용해 충돌 해소 로직 작성을 한다.이 로직은 쓰기나 읽기 수행 중에 실행될 수 있다.
•
쓰기 수행 중에는
◦
DBMS에서 충돌 감지시 충돌 핸들러를 호출한다.
◦
일반적으로 사용자에게 충돌 내용을 표시하지 않고 백그라운드 프로세스에서 실행된다.
•
읽기 수행 중에는
◦
충돌 감지시 모든 충돌 쓰기를 저장 후 다음 읽기 시점에 반환한다.
◦
애플리케이션은
▪
사용자에게 충돌 내용을 보여줄 수도 있고
▪
자동으로 충돌을 해소한 뒤 결과를 DB에 다시 기록할 수도 있다.(Ex: 카우치DB)
참고:자동 충돌 해소
데이터 수정시 발생하는 충돌을 자동으로 해소하는 몇 가지 연구가 있다.
● 충돌 없는 복제 데이터 타입(conflict-free replicated datatype, CRDT)
: set, map, 정렬 목록, 카운터 등을 위한 데이터 구조의 집합으로 여러 사용자가 편집할 수 있고 합리적인 방법으로 충돌을 자동 해소한다.
● 병합 가능한 영속 데이터 구조(mergeable persistent data structure)
: Git 과 유사하게 명시적으로 히스토리를 추적하고 삼중 병합 함수(three-way merge function)을 사용한다.(CRDT는 two-way merge 사용)
● 운영 변환(operational transformation)
: 협업 편집 애플리케이션(ex: 구글 스프레드시트, 노션, 컨플루언스, ...)의 충돌 해소 알고리즘
Plain Text
복사
다중 리더 복제 토폴로지
복제 토폴로지
⇒ 쓰기를 한 노드에서 다른 노드로 전달하는 통신 경로
원형 토폴로지
•
MySQL에서 기본으로 제공하는 토폴로지
•
각 노드가 하나의 노드로부터 쓰기를 받고, 다른 한 노드에 전달한다.
•
쓰기가 모든 복제 서버에 도달하기위해 여러 노드를 거쳐야 한다.
•
한 노드에 장애가 생기면 노드간 복제에 방해가 된다.
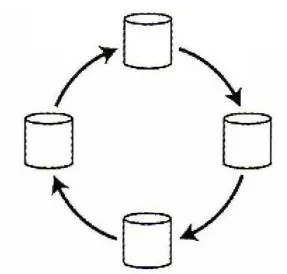
원형 토폴로지(circular topology)
별 모양 토폴로지
•
지정된 루트 노드가 다른 모든 노드에 쓰기를 전달한다.
•
트리로 일반화 할 수 있다.
•
쓰기가 모든 복제 서버에 도달하기위해 여러 노드를 거쳐야 한다.
•
한 노드에 장애가 생기면 노드간 복제에 방해가 된다.
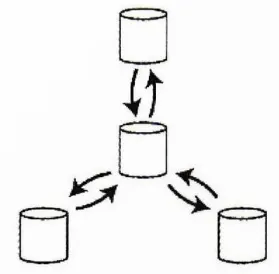
별 모양 토폴로지(star topology)
전체 연결 토폴로지
•
모든 리더가 각자의 쓰기를 다른 모든 리더에게 전송한다.
•
원형, 별 모양 토폴로지에 비교해 단일 장애점(single point of failure)을 피할 수 있어 내결함성이 더 뛰어나다.
•
네트워크 연결 속도 문제로 일부 복제 메세지가 다른 메세지를 추월할 수 있다.
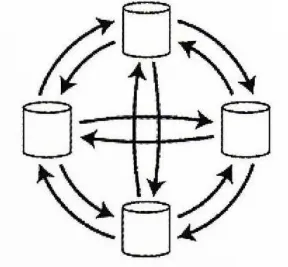
전체 연결 토폴로지
(all-to-all topology)
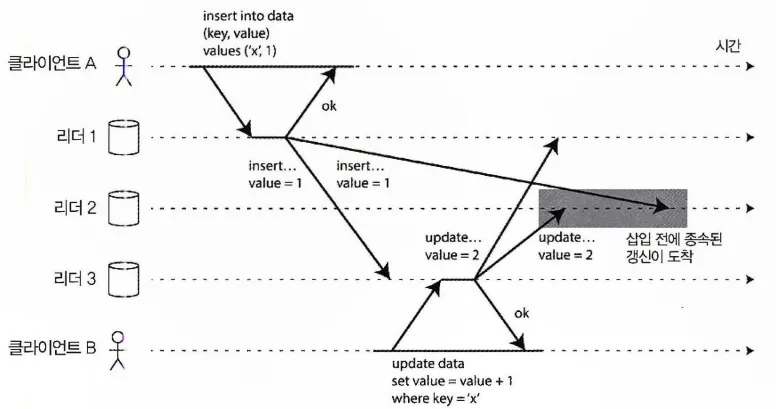
전체 연결 토폴로지의 추월 문제
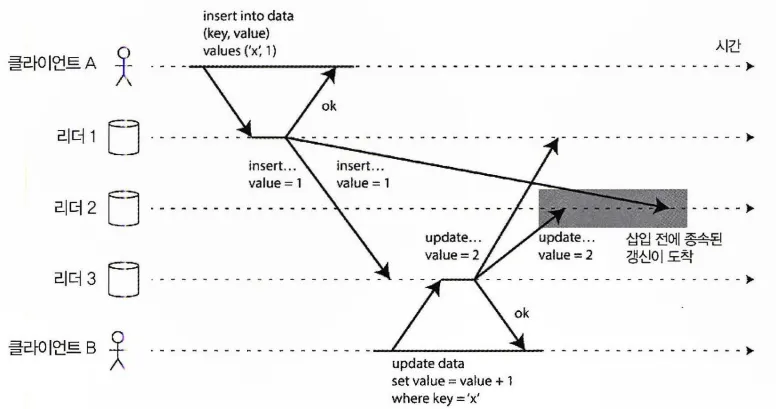
다중 리더 복제에서 일부 복제 서버에 쓰기가 잘못된 순서로 도착할 수 있다.
위 그림을 보면 클라이언트A의 쓰기 작업이 리더2에는 네트워크 연결 문제로 늦게 도착했다. 그래서 클라이언트B가 요청한 데이터 갱신 쓰기 작업이 리더2에 도착했을 땐 아직 클라이언트A의 쓰기 작업이 도착하지 않았기에 정상적으로 작업이 수행될 수 없다.
이런 인과성의 문제를 해결하기 위해 이벤트를 올바르게 정렬할 필요가 있는데, 버전 벡터(version vector) 라는 기법을 사용할 수 있다.
리더 없는 복제
리더의 개념을 버리고 모든 복제 서버가 쓰기 작업을 할 수 있게 허용하는 방식
•
RDB가 과반을 넘으면서 대부분 잊혀진 개념이였으나 아마존이 내부적으로 다이나모(Dynamo) 시스템에서 사용한 후 다시 DB 아키텍처로 유행했으며 이런 종류의 DB를 다이나모 스타일이라 한다.
•
코디네이터 노드(coordinator node)는 클라이언트를 대신해서 클라이언트의 쓰기 요청을 전송해준다.
◦
쓰기 순서를 따로 관리하지 않는다.
노드가 다운됐을 때 데이터베이스에 쓰기
노드 장애시 복구 과정
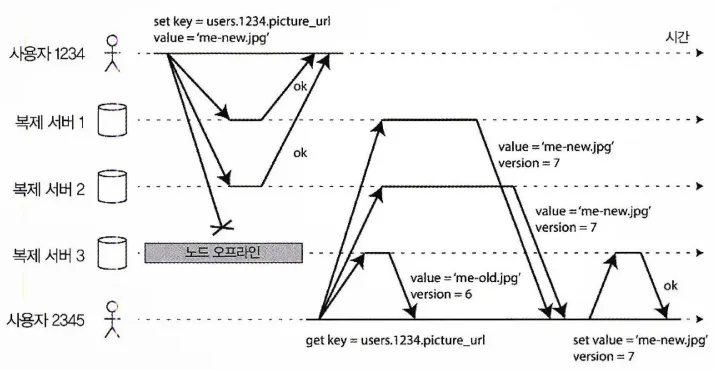
정족수(quorum) 쓰기, 정족수 읽기와 노드 중단 후 읽기 복구
노드가 다운됐을 때 쓰기를 하기 위해서
•
리더 기반 설정에선 장애 복구를 실행하고 기다려야 하지만
•
리더 없는 설정에서는 장애복구가 필요 없다.
◦
대신 다른 (충분한)복제 서버가 쓰기를 확인하면 충분하다.
장애가 복구된 노드는 장애시간 동안 발생한 쓰기가 모두 누락되어 있다.
그래서 해당 노드에서 데이터를 읽을 경우 오래된(outdated) 값을 얻게 된다.
그렇기에 해당 노드의 데이터를 최신화 하기 위해서는
•
병렬로 여러노드에 읽기 요청을 전송해서 여러 노드에서 다른 응답을 받은 다음
•
버전 숫자를 사용해 최신 값을 결정한다.
읽기 복구와 안티 엔트로피
모든 복제 서버가 동일한 데이터를 가지는 일관성을 보장할 수 있어야 한다.
장애가 발생한 노드가 장애 복구 후 일관성을 회복해야 하는데 다이나모 스타일 데이터스토어는 두 가지 메커니즘을 주로 사용한다.
•
읽기 복구
◦
값을 자주 있는 상황에 적합한 접근 방식이다.
◦
여러 노드에서 병렬로 읽기를 수행한 다음 가장 최신 버전의 값으로 최신화한다.
•
안티 엔트로피 처리
◦
백그라운드 프로세스가 복제 서버간 데이터 차이를 지속적으로 찾는다.
▪
발견한 누락 데이터를 다른 서버로 복사한다.
◦
특성 순서로 복사하기에 데이터 복사까지 지연이 있을 수 있다.
읽기와 쓰기를 위한 정족수
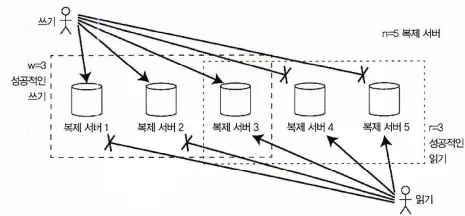
정족수가 w + r > n 인 환경의 읽기/쓰기
n개의 복제 서버가 있다고 할 때 쓰기 정족수와 읽기 정족수를 어떻게 설정할지에 대해 고민해볼 수 있다.
만약 복제 서버가 3개(n=3) 있다고 가정한다면
•
쓰기 정족수가 2개(w=2)는 되야
◦
하나의 서버가 고장나도 나머지 두 개의 서버 중 하나는 최신값을 가지고 있다.
•
읽기 정족수도 2개(r = (n+1) - w)는 되야
◦
최소 하나의 노드에서 최신 값을 읽을 수 있다.
◦
좀 더 일반화 하면 w + r > n 이면 최신 값을 읽을 수 있다.
다시말해 n=3일 경우 w=2, r=2는 되야
•
쓰기에서 최신 값을 유실하지 않고 읽기에서 최신 값을 읽을 수 있다.
•
다이나모 스타일 데이터베이스에서 n, w, r 파라미터는 대게 설정 가능하다.
•
일반적으로 n은 홀수로 하고 w = r = (n+1) / 2(반올림) 으로 설정한다.
•
쓰기가 적고 읽기가 많은 작업 부하는 w = n , r = 1 로 설정하면
◦
읽기가 빨라질 수 있다.
◦
다만, 노드 하나가 고장나면 모든 DB 쓰기가 실패한다.
또한, 고장난 복제 서버가 많아져서 w, r의 설정값보다 정상 복제 서버의 수가 떨어진다면 읽기나 쓰기는 에러를 반환한다.
참고: 정족수란?
정족수(定足數)는 여러 사람의 합의로 운영되는 의사기관에서 의결을 하는데 필요한 최소한의 참석자 수이다. 의사기관은 그 구성원이 전원이 참석하여 운영하는 것이 이상적이나, 현실에서는 전원 참석이 어려운 경우가 많이 있다. 하지만 지나치게 많은 구성원이 불참했을 때 극소수의 구성원만으로 의결을 하는 것은 부당하므로 정족수를 정하게 된다.
- 위키 백과(link)
정족수 일관성의 한계
읽기, 쓰기 정족수가 w + r > n 을 만족하는 경우에도 오래된 값을 반환하는 에지 케이스가 있다.
case 1
즉, r개의 노드와 w개의 노드가 겹치지 않는 것을 보장하지 않는다.
쓰기 노드와 읽기 노드의 중복이 없다.
case 2
동시에 두 개의 쓰기가 발생할 경우 순서를 알 수 없기에
case 3
읽기와 쓰기가 동시에 발생하면, 쓰기는 일부 복제 서버에만 반영될 수 있다.
이 경우 읽기가 최신 값을 반환하는지 여부가 분명하지 않다.
case 4
쓰기가 일부 성공 일부 실패로 설정한 w 수보다 성공 서버가 낮을 경우
•
성공한 복제 서버에서는 롤백하지 않는다.
◦
쓰기가 실패한 것으로 보고될 경우 이어지는 읽기에 해당 쓰기 값이 반환될 수도 아닐 수도 있다.
case 5
새 값을 전달하는 노드가 고장날 경우
•
예전 값을 가진 노드에서 데이터가 복원되고
•
새로운 값을 저장한 노드 수가 W보다 낮아져 정족수 조건이 깨질 수 있다.
case 6
모든 과정이 정상 동작해도 시점의 문제로 에지 케이스가 있을 수 있다.
따라서…
•
정족수는 설정해 최근의 쓴 값을 반환하게끔 설정할 수는 있지만
◦
절대적으로 보장할 수는 없다.
•
견고한 보장을 위해서 일반적으로 트랜잭션이나 합의가 필요하다.
최신성 모니터링
운영 관점에서 DB가 최신 결과를 반환하는지 모니터링하는 것은 매우 중요하다.
리더 기반 복제에서는
•
복제 지연에 대한 지표를 노출하며 모니터링 시스템에 제공된다.
◦
모든 쓰기가 리더를 통하기에 가능한 구조이다.
◦
리더의 현재 위치에서 팔로워의 현재 위치를 빼면 복제 지연량 체크도 가능하다.
리더 없는 복제에서는
•
쓰기가 적용된 순서를 고정할 수 없기 때문에 모니터링이 더 어렵다.
•
읽기 복구만 사용(안티 엔트로피 )하는 경우 읽기가 드문 값은
)하는 경우 읽기가 드문 값은◦
얼마나 오래된 값인지 제한이 없어 아주 오래된 값일 수 있다.
느슨한 정족수와 암시된 핸드오프
정족수는 내결함성이 없다.
네트워크의 중단으로 다수의 DB노드와 클라이언트는 쉽게 연결이 끊어질 수 있다. DB노드들이 모두 정상이라 할지라도 DB 노드들이 모두 죽은 것과 동일하다.
이 경우, 응답 가능한 노드가 w 나 r보다 적을 가능성이 있기 때문에 정족수를 충족하기 힘들어진다.
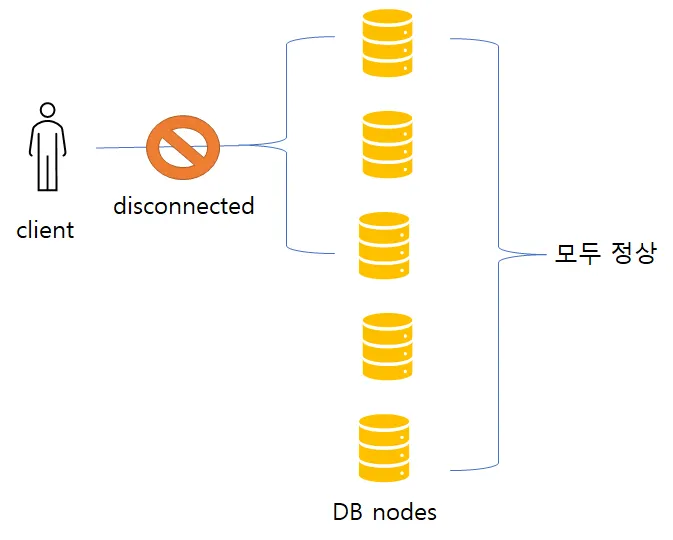
여기서 일반적으로는 w나 r 노드 정족수를 만족하지 않기 때문에 모든 요청에 오류를 반환하게 된다.
하지만….
노드가 n개 이상인 대규모 클러스터인 상황이라면 정족수 구성에 들어가지 않는 일부 DB 노드를 임시로 사용하는건 어떨까?
이처럼 일단 쓰기를 받아들이고 값이 저장되는 n개 노드에 속하지는 않지만 연결은 가능한 노드에 기록하는 것을 느슨한 정족수라 부른다.
비유하면, 내 집 문에 잠겼을 때 옆 집 문을 두드려 소파에 잠시 머물 수 있는지 묻는 것
그리고, 네트워크 장애 상황이 해제되면
•
임시로 수용한 모든 쓰기를 해당 홈 노드로 전송한다.
◦
이러한 방식을 암시된 핸드오프라 부른다.
느슨한 정족수는
•
쓰기 가용성을 높히는데 유용하다.
•
암시된 핸드오프가 완료될 때까진 r노드의 읽기가 저장된 데이터를 본다는 보장이 없다.
•
모든 일반적인 다이나모 구현에서 선택사항이다.
◦
리악에서는 기본적으로 활성화
◦
카산드라, 볼드모트는 비활성화
다중 데이터센터 운영
리더 없는 복제도
•
동시 쓰기 충돌
•
네트워크 중단
•
지연 시간 급증
을 허용하기 때문에 다중 데이터 센터 운영에 적합하다.
여러 DB 시스템은 각각의 방식으로 다중 데이터 센터 지원을 구현했는데,
•
카산드라와 볼드모트는
◦
n 개의 복제 서버 수에는 모든 데이터센터의 노드가 포함되고
◦
설정에서 각 데이터센터마다 n개의 복제 서버 중 몇개를 보유할지 지정할 수 있다.
◦
클라이언트의 각 쓰기는
▪
데이터 센터 상관없이 모든 복제 서버에 전송되지만
▪
클라이언트는 로컬 데이터센터 안에서 정족수 노드의 확인 응답을 기다리기에
•
데이터센터간 연결의 지연과 중단에 영향을 받지 않는다.
▪
다른 데이터센터에 대한 높은 지연 시간의 쓰기는
•
대게 비동기로 발생하게끔 설정한다.


•
리악은
◦
클라이언트와 DB간 연결이 하나의 데이터센터에서 이뤄지기 때문에
▪
n은 하나의 데이터센터 안에 있는 복제 서버 수를 나타낸다.
◦
DB 클러스터의 데이터센터간 복제는
▪
백그라운드에서 비동기로 일어나고
▪
다중 리더 복제 방식과 유사하다.

동시 쓰기 감지
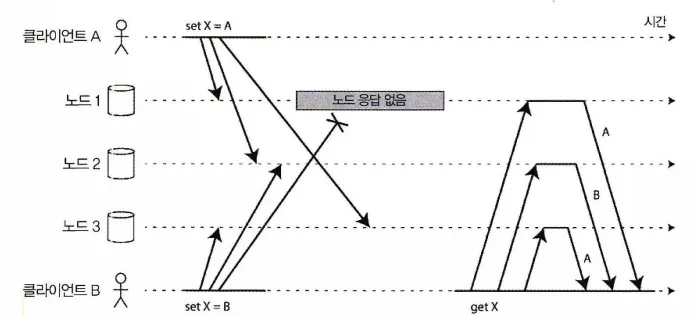
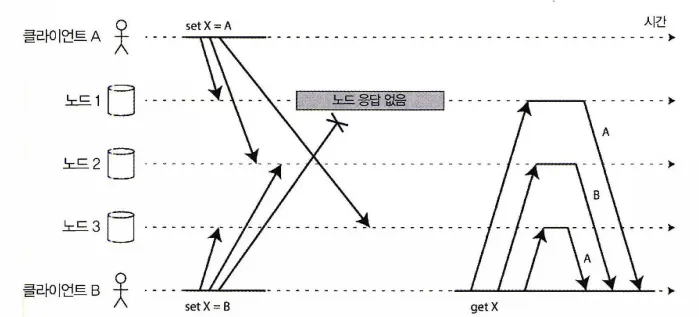
다이나모 스타일 데이터스토어에서 동시 쓰기, 잘 정의된 순서가 없다.
다이나모 스타일 데이터베이스는 동시에 같은 키에 쓰는 것을 허용한다.
그렇기에 엄격한 정족수를 사용해도 충돌이 발생할 수 있다.
여기서 문제는 위 그림과 같이 여러 이유(네트워크 지연, 부분 장애등)로 이벤트가 노드별로 다른 순서로 도착할 수 있다.
•
클라이언트A는 X의 값을 A로
•
클라이언트B는 X의 값을 B로
쓰기 이벤트를 발생시키는데, 각각의 노드들이 요청을 받는 시점이 각기 다르다.
그렇기에 각 노드에게 X의 값을 조회하면 각기 다른 값을 반환하는 상황이 발생하며 일관성이 깨지게 된다. 이러한 충돌을 해소하기 위한 충돌 해소 기법 몇 가지를 좀 더 자세히 살펴보자.
최종 쓰기 승리(동시 쓰기 버리기)
가장 최신 값으로 모든 복제 서버를 덮어쓰는 방식
여기서 최신 값이 무엇인지 이벤트 순서가 정해지지 않았기에 알 수 없다.
다만, 임의로 순서를 정할 수 있는데,
•
쓰기에 타임스탬프를 붙혀 가장 큰 타임스탬프를 선택하는 충돌 해소 알고리즘을 최종 쓰기 승리(LWW)라 부른다.
•
카산드라에서 제공하는 충돌 해소 방법이고 리악에서는 선택적으로 제공한다.
최종 쓰기 승리(LWW) 는
•
최종적 수렴 달성이 목표지만,
•
지속성을 희생한다.
◦
여러 번의 동시 쓰기가 있고 모두 성공으로 응답되더라도
◦
쓰기 중 하나만 남고 나머지는 무시된다.
◦
동시 쓰기가 아니라도 쓰기가 삭제 될 수도 있다.
▪
(이벤트 순서화용 타임스탬프에서 설명한다.)
•
캐싱과 같이 손실된 쓰기를 허용하는 상황이 있다.
•
키를 최초 쓰기 후 불변 값(immutable variable)으로 다룸으로써 안전하게 사용할 수 있다.
이전 발생 관계와 동시성
•
다음 그림에서 클라이언트B의 작업은 클라이언트A의 작업 기반이다.
◦
B가 증가시키는 값(value + 1)은 A가 삽입한 값이기에 순서가 있다.
◦
B는 A에 인과성이 있다(causally dependent)고 한다.
•
다음 그림에서 두 개의 쓰기는 동시에 수행됐다.
◦
각 클라이언트가 작업을 시작할 때 모두 동일한 키에 작업을 수행했는지 알 수 없다.
◦
따라서 작업 간에 인과성이 없다.
작업 A와 B가 있다고 할 때
•
작업 B가 작업 A에 대해서
◦
A를 알거나
◦
A에 의존적이거나
◦
A를 기반으로 한다면
A는 B작업의 이전 발생(happens-before)이다.
한 작업이 다른 작업 이전에 발생했는지가 동시성의 의미를 정의하는 핵심이다.
•
작업 A와 B가 서로에 대해
◦
알지도 못하고
◦
의존하지도 않고
◦
기반으로 하지도 않는다면
A와 B는 동시 작업이라 말한다.
이전 발생 관계 파악하기
두 작업이 동시 작업인지, 이전 발생인지에 대한 여부를 결정하는 알고리즘을 살펴보자.
•
복제본이 하나뿐인 데이터베이스라고 가정한다.
•
두 클라이언트가 같은 장바구니에 동시에 상품을 추가하는 것을 보여준다.
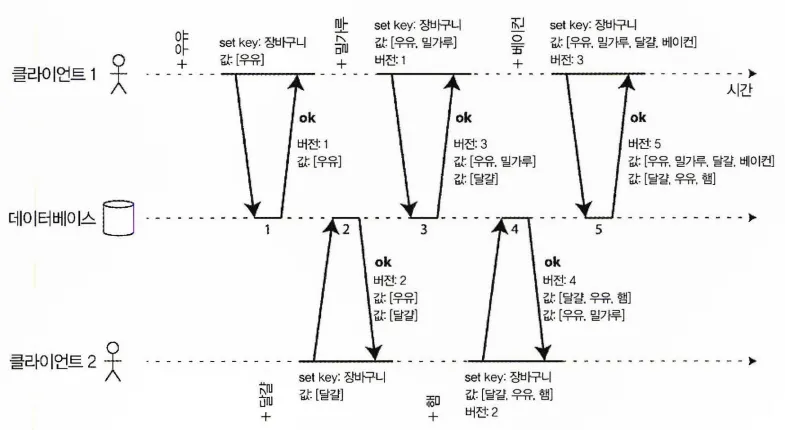
두 클라이언트가 동시에 장바구니를 수정하는 동안 인과성 파악하기
1.
클라이언트1은 장바구니에 우유를 추가한다.
•
서버는 버전 1을 할당하고 저장한다.
•
서버는 클라이언트1에게 값을 보여준다.
◦
버전1: [우유]
2.
클라이언트2는 장바구니에 달걀을 추가한다.
•
클라이언트2는 장바구니에 우유가 추가됐다는 사실을 모른다.
•
서버는 버전 2를 할당하고 저장한다.
•
서버는 클라이언트2에게 버전 2를 가진 두 개의 값을 반환한다.
◦
버전1: [우유]
◦
버전2: [달걀]
3.
클라이언트1은 장바구니에 밀가루를 추가한다.
•
버전 1과 함께 [우유, 밀가루]를 전송한다.
•
서버에서 버전 1은 [우유] 에서 [우유, 밀가루] 로 대체된다.
•
[달걀]과도 동시라는 사실을 알기에 [우유, 밀가루]를 버전 3으로 할당하고 버전 1에 덮어쓴다.
•
서버는 클라이언트1에게 버전 3을 가진 두 개의 값을 반환한다.
◦
버전3: [우유, 밀가루]
◦
버전2: [달걀]
4.
클라이언트2는 장바구니에 햄을 추가한다.
•
이전에 두 개의 버전으로 우유, 달걀을 받았기에 햄을 추가해서 합친다.
◦
버전2: [달걀, 우유, 햄]
•
합친 버전2를 서버로 전송한다.
•
서버는 버전2를 덮어쓰지만, 버전3:[우유, 밀가루]가 동시에 실행되었기 때문에
◦
버전2: [달걀, 우유, 햄] → 버전4:[달걀, 우유, 햄] 으로 덮어쓴다.
•
서버는 클라이언트2에게 버전4를 가진 두 개의 값을 반환한다.
◦
버전3: [우유, 밀가루]
◦
버전4: [달걀, 우유, 햄]
5.
클라이언트1은 장바구니에 베이컨을 추가한다.
•
클라이언트1은 이전에 버전2, 버전3정보를 알고 있었기에 이를 합친 후 베이컨 추가
◦
버전3: [우유, 밀가루, 달걀, 베이컨]
•
합친 버전3을 서버로 전송한다.
•
서버는 이전과 동일하게 기존 버전3에 덮어쓰지만 클라이언트2와 동시수행 되었기에 버전5를 할당한다.
•
서버는 클라이언트1에게 버전5를 가진 두 개의 값을 반환한다.
◦
버전4: [달걀, 우유, 햄]
◦
버전5: [우유, 밀가루, 달걀, 베이컨]
위 데이터 플로우를 도표로 보면 다음과 같다.
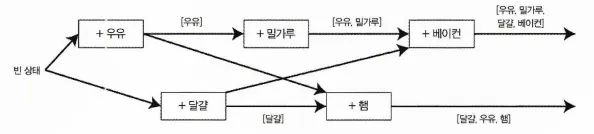
도표를 보면 화살표를 통해 작업간의 인과성을 알 수 있다.
물론, 동시에 다른 작업이 수행되었기 때문에 서버와 클라이언트가 동일한 최신 상태로 유지하지는 못한다. 하지만, 예전 버전의 값을 덮어쓰기에 손실된 쓰기는 없다.
서버는 버전 번호를 보고 두 작업이 동시에 수행됐는지 여부를 결정할 수 있는데,
•
서버는 모든 키에 대한 버전 번호를 유지하고, 키를 기록할 때마다 버전 번호를 증가시킨다.
•
클라이언트가 키를 읽을 때는 최신 버전 뿐 아니라 덮어쓰지 않은 모든 값을 반환한다.
◦
클라이언트는 쓰기 전 키를 읽어야 한다.
•
클라이언트는 이전 읽기의 버전 번호를 포함해서 키를 기록해야 한다.
◦
이전 읽기에서 받은 모든 값을 합쳐야 한다.
•
서버가 특정 버전 번호를 가진 쓰기를 받으면
◦
해당 버전 이하 모든 값을 덮어쓸 수 있다.
◦
해당 버전 이상은 유지해야 한다.
▪
유입된 쓰기와 동시에 발생했기 때문이다.
동시에 쓴 값 병합
위에서 최종적으로 장바구니에 담긴 내용은
•
버전4: [달걀, 우유, 햄]
•
버전5: [우유, 밀가루, 달걀, 베이컨]
인데, 클라이언트는 동시에 쓴 값을 합쳐 정리해야 한다.
•
병합된 장바구니 내용: [우유, 밀가루, 달걀, 베이컨, 햄]
우유, 달걀같은 중복되는 항목들은 중복만 제거해주면 된다.
하지만, 상품 추가가 아닌 상품 제거 기능까지 고려한다면 합집합으로는 해결하기 힘들어진다.
한 쪽에서 우유 상품을 제거해도 합집합 이후 삭제된 우유가 다시 나타날 수 있다.
이러한 문제를 방지하기 위해선
•
데이터베이스에서 단순히 삭제하는게 아니라
•
툼스톤 마크를 통해 상품이 제거되었음을 나타내야 한다.
버전 벡터
지금까지는 단일 복제본을 가지고 얘기를 했지만, 복제본이 단일이 아닌 다중 복제본이 된다면, 단일 버전 번호만 가지고는 충분하지 않다. 키 뿐 아니라 복제본당 버전 번호도 사용해야 한다.
각 복제본은 쓰기를 처리할 때 자체 버전 번호를 증가시키고 각기 다른 복제본의 버전 번호도 계속 추적해야 한다.
이런 복제본의 버전 번호 모음을 버전 벡터(version vector)라 부른다.
버전 벡터는
•
값을 읽을 때 DB 복제본에서 클라이언트로 보낸다.
•
값을 기록할 때 DB로 다시 전송해야 한다.
•
사용하기에 따라서 DB는 덮어쓰기와 동시 쓰기를 구분할 수 있게 된다.
•
형제 병합시
◦
하나의 복제본을 읽은 다음 다른 복제본에 다시 쓰는 작업이 안전함을 보장한다.
◦
형제가 올바르게 병합되는 한 데이터 손실은 없다.

