
목차
개요

만물은 변한다. 그대로 있는 것은 아무것도 없다.
- 에베소의 헤라클레이토스, 플라톤이 크라틸로스에서 인용(기원전 360년)
과거(2015년)의 카카오톡
현재(2022년)의 카카오톡
애플리케이션은 시간이 지남에 따라 변화하고, 이 변화는 간단하게는 UI변경부터 복잡하게는 기능 추가 비즈니스 로직 추가까지 될 수 있다.
대부분의 경우 애플리케이션 기능의 변경이 되기 위해서는 저장하는 데이터도 변경해야 하는데, 변경되는 필드의 타입 혹은 추가되는 필드는 기존 데이터 저장소가 아닌 새로운 곳에 저장소를 만드는 식으로 새로운 방법으로 제공해야 할 수도 있다.
그런데 이렇게 새롭게 추가 혹은 변경된 기능이 반영된 코드와 데이터는 대규모 애플리케이션에서 다음과 같은 이유로 양방향 호환성이 필요하다.
•
서버 측 애플리케이션은 한 번에 몇 개의 노드에 새 버전을 배포한 뒤 안정성을 확인한 뒤 나머지 노드에서도 실행되도록 순회식 업그레이드(rolling upgrade)(or 단계적 롤아웃(staged rollout)방식을 사용한다. 이런 방식은 새로운 버전의 서비스를 무중단으로 출시할 수 있다는 장점이 있다.
•
클라이언트측에서는 임의로 업데이트를 설치하지 않을 수도 있다.
즉, 애플리케이션의 새로운 버전이 즉시 반영이 안된다는 점인데, 이 경우 새 버전과 구 버전이 동시에 공존하는 상황이 생길 수 있고, 이 때 하위 호환성(신 버전의 코드가 구 버전의 데이터를 읽을 수 있어야 한다.)과 상위 호환성(구 버전의 코드가 신 버전의 새로운 데이터를 읽을 수 있어야 한다.)
둘 다 제공해야 하는데, 비교적 쉬운 하위호환성에 비해 상위 호환성은 구버전의 코드가 새 버전에 의해서 추가된 내용들을 무시할 수 있어야 하기에 난이도가 높다.
그렇기에 이번 장에서는 이러한 양측 호환성을 모두 만족시키는 시스템을 어떻게 만드는지에 대해 알아본다.
JSON, XML, Protocol Buffers, Thrift, Avro와 같이 데이터 부호화를 위한 데이터 형식과, 웹 서비스의 대표 상태 전달(Representational State Transfer, REST), 원격 프로시저 호출(remote procedure call), 액터(actor), 메세지 큐 같은 메세지 전달 시스템에서 다양한 데이터 부호화 형식이 데이터 저장과 통신에 어떻게 사용되는지도 알아본다.
데이터 부호화 형식
데이터는 메모리내에 다음과 같은 데이터 구조로 저장되어 CPU에서 접근하고 조작할 수 있도록 보통은 포인터를 이용해 최적화된다.
•
객체(Object)
•
구조체(struct)
•
목록(list)
•
배열(array)
•
해시 테이블(hash table)
•
트리(tree)
이러한 데이터 구조가 파일에 쓰거나 네트워크를 통한 전송이 필요할때는 스스로를 포함한 일련의 바이트열(Ex: JSON) 형태로 부호화해야 한다.
이처럼 인메모리에 적재된 데이터를 바이트열로 전환하는 부호화(직렬화나 마샬링이라고도 한다.)과정과 그 반대 과정인 복호화(파싱, 역직렬화, 언마샬링 이라고도 한다.)을 통해 두 가지 표현사이의 전환이 필요하다.
용어 충돌
직렬화는 트랜잭션의 맥락에서도 사용되는데 완전히 다른 의미로, 직렬화가 조금 더 일반적인 용어일지라도 단어의 중복 사용을 피하기 위해 해당 포스팅에서는 부호화를 사용한다.
언어별 형식
많은 프로그래밍 언어는 인메모리 객체를 바이트열로 부호화하는 기능을 내장하고 있다.
(Ex: java: java.io.Serializable, Ruby: Marshal, Python: pickle)
각각의 프로그래밍 언어는 내장된 부호화 라이브러리를 이용해 인메모리 객체를 저장하고 복원할 수 있어 편리하지만 문제점도 다음과 같이 많이 산재해 있다.
•
제한되는 유연성
: 특정 프로그래밍 언어로 부호화/복호화를 할 경우 다른 언어에서는 해당 데이터를 사용하기가 매우 까다롭다. 즉, 꽤나 오랜 시간동안 처음 선택한 프로그래밍 언어로만 코드를 작성해야 하고, 다른 언어를 사용할 수도 있는 시스템과의 연동에 어려움이 생길 수 밖에 없다.
•
보안 문제
: 동일한 객체 유형의 데이터를 복원하려면 복호화 과정이 임의의 클래스를 인스턴스화 할 수 있어야 한다. 이 때 공격자가 임의의 바이트열을 복호화할 수 있는 애플리케이션을 얻으면 임의의 클래스를 인스턴스화할 수 있고 공격자가 원격으로 임의 코드를 실행하는 상황이 생길 수 있다.
•
상위 호환성 / 하위 호환성
:부호화 라이브러리는 데이터를 빠르고 쉽게 부호화 하기 위해 상위,하위 호환성을 등한시하고는 하는데, 이로 인해 호환성 문제가 생길 수 있다.
•
효율성
: 부호화 및 복호화에 드는 비용 역시 처음에는 고려하지 않는데, 자바의 내장 부호화 라이브러리는 성능이 좋지 않고 비대해지는 부호화로 유명하다.
이런 문제점들 때문에 일반적으로는 내장된 부호화 라이브러리를 사용하는것은 권장되지 않는다.
JSON과 XML, 이진 변형
JSON과 XML(혹은 CSV도)은 다양한 프로그래밍 언어에서 공통으로 읽고 쓸 수 있는 표준화된 부호화다. 그만큼 널리 알려져 있고, 지원되고 있지만 XML은 장황함과 복잡함으로, JSON은 숫자의 정밀도 문제로 비판받기도 한다.
JSON, XML, CSV의 미묘한 문제점
•
수(number)의 부호화에는 많은 애매함이 있다. XML과 CSV에서는 수와 숫자(digit)로 구성된 문자열을 구분할 수 없다.(외부 스키마 참조는 제외). JSON은 문자열과 수를 구분하지만 정수와 부동소수점 수를 구별하지 않고 정밀도를 지정하지 않는다.
•
부족한 정밀도는 큰 수를 다루면서 문제가 된다. 보다 큰 정수는 IEEE 754 배정도 부동소수점 수에서는 정확하게 표현할 수 없기에 이런 수는 부동소수점 수를 사용하는 언어에서는 파싱할 때 부정확해질 수 있다.
•
JSON과 XML은 유니코드 문자열은 지원하지만 이진 문자열을 지원하지 않는다. 사람들은 이진데이터를 Base64를 사용해 텍스트로 부호화해 이런 제한을 피하지만, 해당 값이 Base64로 부호화되었기에 해석해야한다는 사실을 스키마를 사용해 표현한다.
다만, 이 방법은 데이터 크기를 33% 증가시키며 정공법은 아니다.
•
필요에 따라 XML과 JSON은 스키마를 지원하는데, 구현하기가 어렵고 스키마의 정보에 따라 데이터의 해석이 달라져서 XML/JSON 스키마를 사용하지 않는 애플리케이션은 필요한 부호화/복호화 로직을 하드코딩해야 할 가능성이 생긴다.
•
CSV는 스키마가 없기에 각 로우와 칼럼의 의미 정의는 애플리케이션이 직접 해야 한다. 새로운 로우나 칼럼 추가를 변경해야 할 때 수동 처리를 해야하고 이스케이핑도 규정되어있기는 하지만, 모든 파서가 규칙을 정확하게 구현하지는 않아 문제가 생길 여지가 있다.
하지만, 그럼에도 불구하고 JSON, XML, CSV는 사용하기 충분하다. 사실 더 중요한건, 데이터 구조가 얼마나 좋은 구조인지가 아니라, 각각의 조직간의 협의를 통해 규격을 맞추는 것이다.
이진 부호화
JSON은 XML보다 간결하지만 그래도 두 방식 모두 이진 형식과 비교하면 많은 공간을 사용한다.
그렇기에 JSON(메시지팩(MessagePack), BSON, BJSON, UBJSON, BISON, 스마일(Smile)등)과 XML(WBXML, Fast Infoset) 용으로 사용 가능한 다양한 이진 부호화가 개발되었다.
이런 형식은 다양한 요구조건 하에 만들어져 채택되었지만, JOSN, XML의 텍스트 버전처럼 널리 채택되지는 못했다. 이런 형식들 중 일부는 데이터타입 셋을 확장하지만(ex: 정수와 부동소수점 수의 구분 혹은 이진 문자열 지원) JSON/XML 데이터 모델은 변경하지 않고 유지했다.
특히 스키마를 지정하지 않기 때문에 부호화된 데이터 안에 모든 객체의 필드 이름을 포함해야 한다.
다음 JSON 문서를 이진 부호화 해보자.
{
"userName" : "Martin",
"favoriteNumber": 1337,
"interests" : ["daydreaming", "hacking"]
}
JSON
복사
이진 부호화 할 레코드
위 JSON문서를 JSON용 이진 부호화 형식 중 하나인 메시지팩으로 부호화 해보자.
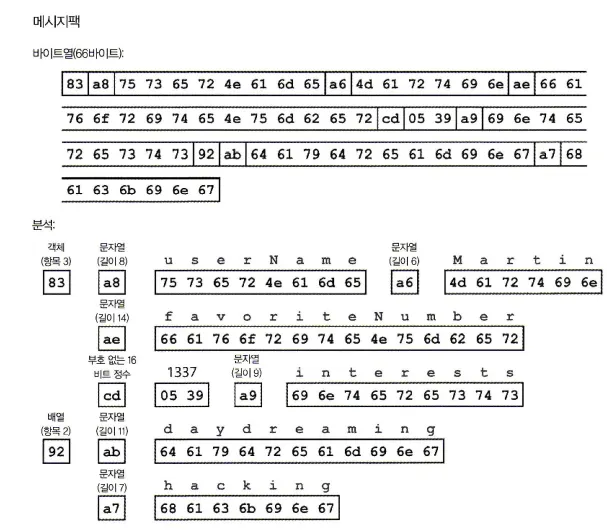
메시지팩으로 부호화한 예제 레코드
1.
위 그림의 바이트열을 보면 첫 번째 파이트는 0x83인데 0x뒤의 8과 3은 각각 이어지는 애용이 세 개의 필드(하위 4비트=0x03)를 가진 객체(상위 4비트: 0x80)라는 뜻이다. 여기서 객체가 15개 넘는 필드를 가진다면 다른 타입 지시자를 얻어 필드 수를 2 또는 4바이트로 부호화한다.
2.
두 번째 바이트인 0xa8은 이어지는 내용이 8바이트 길이(하위 4비트=0x03)의 문자열(상위 4비트=0xa9)이라는 의미다.
3.
다음 8바이트는 필드 이름인 userName의 아스키 코드다. 길이는 예전에 표시됐기 때문에 문자열이 끝나는 곳을 표시(또는 이스케이핑)할 필요가 없다.
4.
다음 7바이트는 앞에 0xa이 붙고 Martin 이라는 6글자 문자열 값을 부호화 한다.
이진 부호화는 길이가 66바이트로 텍스트 JSON 부호화로 얻은 81바이트(공백은 제거)보다 약간 작다. JSON의 모든 이진 부호화는 이와 비슷하다. 다만, 이런 작은 공간의 절약이 가독성을 해칠 만큼 가치가 있는지는 확실치 않다.
스리프트와 프로토콜 버퍼
스리프트
아파치 스리프트(Apache Thrift)와 프로토콜 버퍼(Protocol Buffers, protobuf)는 같은 원리를 기반으로 한 이진 부호화 라이브러리다. 이 두 라이브러리 모두 부호화할 데이터를 위한 스키마가 필요한데 다음 레코드를 스리프트와 프로토콜 버퍼로 부호화하려면 스리프트는 스리프트 인터페이스 정의언어(interface definition language, IDL)로 스키마를 기술해야한다.
•
JSON
{
"userName" : "Martin",
"favoriteNumber": 1337,
"interests" : ["daydreaming", "hacking"]
}
JSON
복사
•
IDL
struct Person {
1: required string userName,
2: optional i64 favoriteNumber,
3: optional list<string> interests
}
JSON
복사
•
protocol buffers
message Person {
required string user_name = 1;
optional i64 favorite_number = 2;
repeated string interests = 3;
}
JSON
복사
이렇게 생성된 스키마를 부호화하면 어떤 모습이 될까?
스리프트는 다음과 같은 두 가지 이진 부호화 형식이 있다.
1. 바이너리 프로토콜(BinaryProtocol)
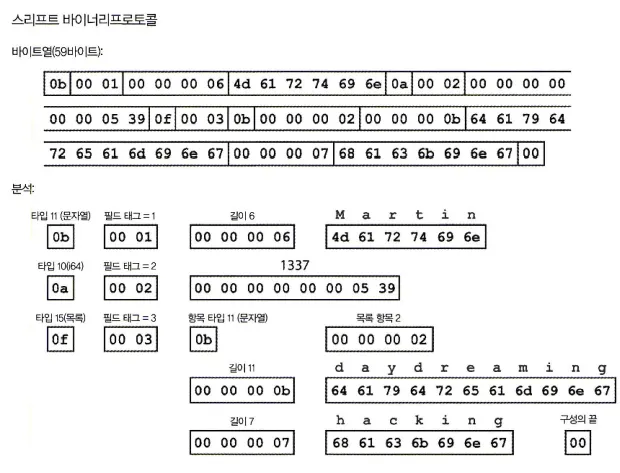
바이너리프로토콜을 이용한 부호화
위 그림에서 바이트열과 분석을 살펴보면, 메시지팩과 유사하지만, 필드 이름(username, favoriteNumber, interests)이 없는 대신 부호화된 데이터는 숫자(1, 2, 3)같은 필드 태그(field tag)를 포함한다. 필드 태그는 필드의 별칭같이 상요되며 철자 없이도 어떤 필드를 다루는지 알려주는 쉬운 방법이다.
2. 스리프트 컴팩트프로토콜
의미상으로는 바이너리프로토콜과 같지만 동일한 정보를 더 줄여서 부호화 한다.
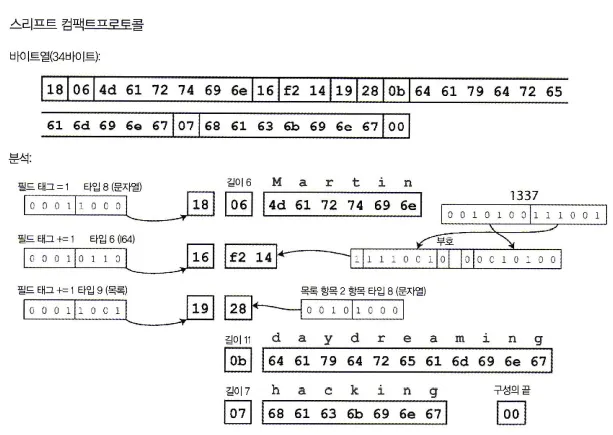
컴팩트프로토콜을 이용한 부호화
그럼 어떻게 크기를 더 줄여서 부호화를 할 수 있는 것일까?
•
필드 타입과 태그 숫자를 단일 바이트로 바꾼다.
•
가변 길이 정수(variable-length integer)를 사용해 부호화한다.
•
숫자 1337을 8바이트 모두 사용하는 대신 2바이트로 부호화한다.

→ -64~63 사이의 값은 1바이트로 부호화하고 -8192 ~ 8191 사이의 값은 2바이트로 부호화
프로토콜 버퍼
프로토콜 버퍼는 다음과 같이 동일한 데이터를 부호화 하며 비트를 줄여 저장하는 처리 방식이 약간 다르지만 스리프트의 컴팩트프로토콜과 매우 비슷하다.
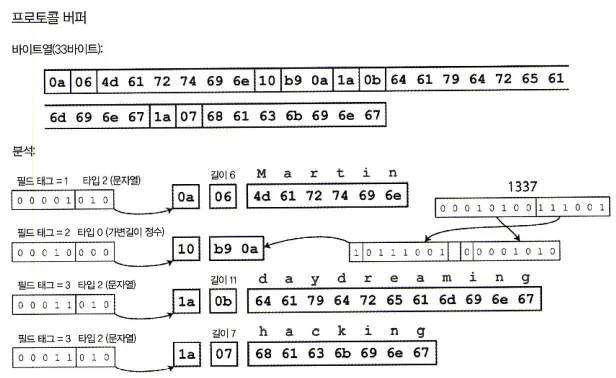
프로토콜 버퍼를 사용한 부호화
required, optional은 어디에 사용되는가
상단의 스리프트 및 프로토콜 버퍼의 스키마 정의에서 분명 required나 optional 키워드를 봤는데, 필드를 부호화하면서 별다른 차이점을 보지 못했다. 해당 키워드는 required같은 경우 필드가 설정되지 않은 경우를 실행 시에 확인할 수 있어 버그를 잡을 때 유용하다.
필드 태그와 스키마 발전
스키마가 시간이 흐르면서 변하는 것을 스키마 발전(schema evolution)이라 부르는데 스리프트와 프로토콜 버퍼는 어떻게 상위 호환성과 하위 호환성을 모두 유지하면서 스키마를 변경할까?
1. 필드 추가시 상위 호환성과 하위 호환성 유지하기

프로토콜 버퍼를 사용해 부호화된 레코드
부호화된 레코드는 부호화된 필드의 연결일 뿐이다.
각 필드를 보면 필드 태그가 있고 이를 식별자로 사용하고 데이터타입(ex: 문자열, 정수)을 주석으로 단다. 필드값을 설정하지 않았다면 부호화 레코드에서 생략을 하면 된다.
부호화된 데이터를 보면 필드 이름은 표기되지 않았는데, 그렇기에 스키마에서 필드 이름을 바꾸는 것도 가능하다. 하지만 필드 태그는 기존의 모든 부호화된 데이터를 인식 불가능하게 만들 수 있기에 변경할 수 없다.
필드에 새로운 태그 번호를 부여하는 식으로 스키마에 새로운 필드를 추가할 수 있는데, 예전 코드에서 새로운 코드로 기록한 데이터를 읽으려는 경우 해당 필드를 무시할 수 있고, 데이터타입 주석은 파서가 몇 바이트를 생략할 수 있는지 알려준다. 이를 통해 상위 호환성을 유지할 수 있다.
또한, 각 필드에 식별자로 사용되는 태그 번호가 있는 동안 태그 번호는 항상 같은 의미를 가지기에 새로운 코드가 예전 데이터를 항상 읽을 수 있다.
여기서 주의할 점이 있는데 새로운 필드를 추가하는 경우 이 필드가 required여서는 안된다.
새로운 필드를 required로 추가하면 예전 코드는 새로운 필드를 기록하지 않기 때문에 새로운
코드가 예전 코드로 기록한 데이터를 읽는 작업은 실패한다. 그렇기에 하위 호환성을 유지하려면 추가되는 필드는 optional로 하거나 기본 값을 가져야 한다.
2. 필드 삭제시 상위 호환성과 하위 호환성 유지하기
필드 추가할 때 호환성 문제를 해결하는 방식의 반대로 하면 필드 삭제시에도 호환성을 유지할 수 있다. 즉, optional 필드만 삭제할 수 있고 같은 태그 번호는 재사용하지 않으면, 필수 데이터를 못읽거나 태그 번호가 중첩되어 잘못된 데이터가 파싱되는 문제를 해결할 수 있다.
데이터타입과 스키마 발전
필드의 데이터타입이 8비트 정수에서 16비트 정수로 바꿀 경우 파서는 누락된 비트를 0으로 채울 수 있다.
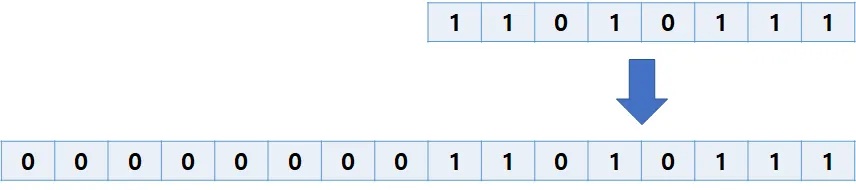
8비트 → 16비트로 데이터타입이 변하며 누락비트를 0으로 채울 수 있다.
그렇기에 새로운 코드는 예전 코드가 기록한 데이터를 쉽게 읽을 수 있다.
하지만, 반대로 새로운 코드가 기록한 데이터를 옛날 코드가 읽는다고 할 때는 문제가 생길 수 있다.
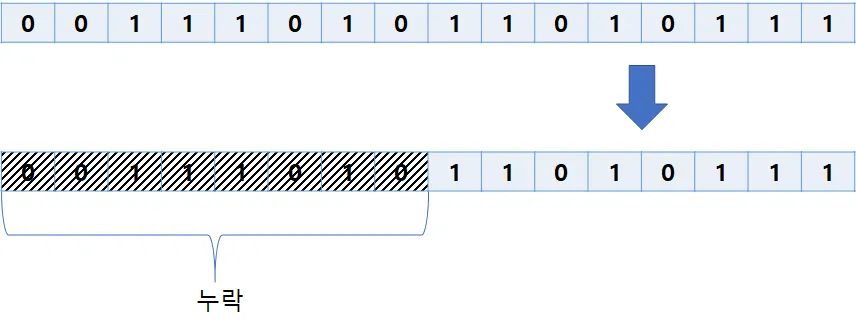
16비트 → 8비트 데이터 타입 변경시 비트가 누락될 수 있다.
위 그림과 같이 16비트 정수가 8비트 정수로 바뀌며 값이 잘리게 된다.
프로토콜 버퍼의 repeated
프로토콜 버퍼는 목록이나 배열 데이터타입은 없지만, repeated 표시자가 있다.
repeated 필드의 부호화는 레코드에 단순히 동일한 필드 태그가 여러 번 나타난다.
optional 필드를 repeated 필드로 변경해도 상관이 없는데 이전 데이터를 읽는 새로운 코드는 필드의 존재 여부에 따라 0이나 1개의 엘리먼트가 있는 목록으로 보고 예전 코드는 목록의 마지막 엘리먼트만 보게 된다.
스리프트에는 전용 목록 데이터타입이 있기에 이 목록 데이터타입은 목록 엘리먼트의 데이터타입을 매개변수로 받는다. 목록 데이터타입은 프로토콜 버퍼와는 다르게 단일 값에서 다중 값으로의 변경을 허용하지 않지만 중첩된 목록을 지원한다는 장점이 있다.
아브로
아파치 아브로는 프로토콜 버퍼와 스리프트와는 다른 이진 부호화 형식이다.
스리프트가 하둡의 사용 사례에 적합하지 않아 2009년 하둡의 하위 프로젝트로 시작했다.
아브로는 부호화할 데이터 구조를 지정하기 위해 스키마를 사용하며, 두 개의 스키마 언어가 있다.
•
IDL(Avro IDL): 사람이 편집할 수 있는 스키마 언어
record Person {
string userName;
union {null, long} favoriteNumber = null;
array<string> interests;
}
JSON
복사
•
기계가 더 쉽게 읽을 수 있는 JSON 기반 언어
{
"type":"record",
"name":"Person",
"fields":[
{"name":"userName", "type":"string"},
{"name":"favoriteNumber", "type":["null", "long"], "default": null},
{"name":"intersts", "type":{"type":"array", "items":"string"}},
]
}
JSON
복사
스키마에 태그 번호는 존재하지 않는다. 이 스키마를 이용해 레코드를 부호화 한다면 32바이트로 살펴본 모든 부호화중 가장 짧다. 부호화된 바이트열 분석은 다음과 같다.
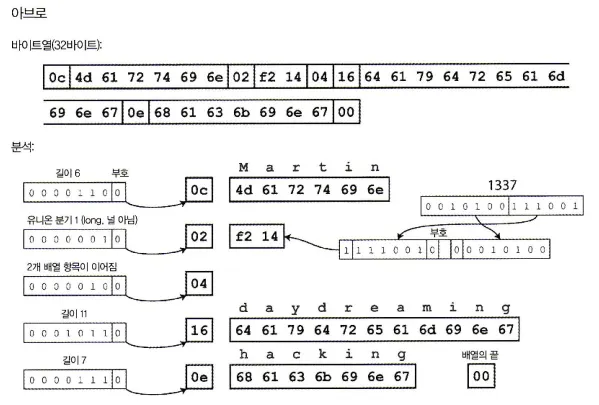
바이트열을 살펴보면 필드나 데이터타입을 식별하기 위한 정보가 없다.
부호화는 단순히 연결된 값으로 구성되고, 문자열은 길이 다음 UTF-8 바이트가 이어지지만 문자열임을 알려주는 정보가 부호화된 데이터에는 없다.
그렇기에 아브로를 이용해 이진 데이터를 파싱하려면 스키마에 나타낸 순서대로 필드를 살펴보고 스키마를 이용해 각 필드의 데이터타입을 미리 파악해야 한다. 이는 데이터를 읽는 코드가 데이터를 기록한 코드와 정확히 같은 스키마를 사용하는 경우에만 이진 데이터를 올바르게 복호화 될 수 있다.
그렇다면, 아브로는 어떻게 스키마 발전을 제공할 수 있을까?
쓰기 스키마와 읽기 스키마
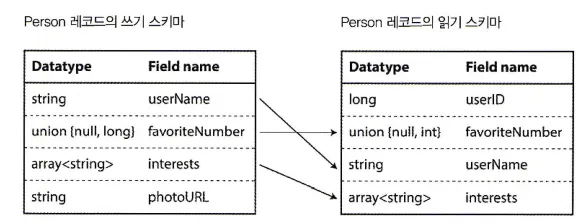
아브로 읽기(Avro reader)가 쓰기 스키마와 읽기 스키마 간 차이를 해소한다.
애플리케이션에서 어떤 목적을 가지고 데이터를 아브로로 부호화 혹은 복호화를 하길 원한다면 알고있는 스키마 버전을 통해 데이터를 부호화(복호화)할 수 있다.
부호화를 위한 쓰기 스키마(writer’s schema)와 복호화를 위한 읽기 스키마(reader’s schema) 는 서로 동일하지 않아도 된다. 단지 호환이 가능하면 되고, 아브로 라이브러리는 양 스키마를 함께 살펴보고 다음 쓰기 스키마에서 읽기 스키마로 데이터를 변환해 차이를 해소한다.
여기서 양 스키마의 필드 순서가 달라도 상관없는데, 스키마 해석(schema resolution)에선 이름으로 필드를 일치시키기 때문이다.
스키마 발전 규칙
아브로는 스키마의 버전관리를 통해 상위 호환성과 하위 호환성을 유지한다.
더하여 호환성을 유지하기 위해 기본값이 있는 필드만 추가및 삭제가 가능하다. 기본값이 있기에 옛날 스키마와 최신 스키마간의 불일치하는 필드는 기본값으로 제공된다.
아브로는 null을 허용하지 않기 때문에 필드에 null을 허용하기 위해서는 유니온 타입(union type)을 사용해야 한다. 예를 들어 union { null, long, string } field;는 field가 수나 문자열 또는 널일 수 있다는 의미다.
그 대신 아브로는 optional, required 표시자를 가지지 않는다.
또한, 아브로는 타입을 변환할 수 있기에 필드의 데이터타입 변경이 가능하고, 필드 이름 변경도 가능하긴 하지만 조금 까다롭다.
그러면 쓰기 스키마는 무엇인가?
아브로를 사용하는 상황에 따라 읽기는 특정 데이터를 부호화한 쓰기 스키마를 다르게 알아낼 수 있다.
•
많은 레코드가 있는 대용량 파일
: 아브로의 일반적인 용도는 동일한 스키마로 부호화된 수백만 개 이상의 레코드를 포함한 큰 파일을 저장하는 용도이다. 이 경우 파일의 쓰기는 시작 부분에 한 번만 쓰기 스키마를 포함시키면 된다. 아브로는 이를 위해 파일 형식(객체 컨테이너 파일(object container file)을 명시한다.
•
개별적으로 기록된 레코드를 가진 데이터베이스
: 데이터베이스의 다양한 레코드는 여러 쓰기 스키마를 서로 다른 시점에 사용할 수 있다.
부호화된 레코드의 시작 부분에 버전 번호를 포함하고 데이터베이스에는 스키마 버전 목록을 유지해서 읽기 시점에 레코드를 가져와 버전 번호를 추출해 데이터베이스에서 쓰기 스키마를 가져온 다음 남은 레코드를 복호화 할 수 있다.
•
네트워크 연결을 통해 레코드 보내기
: 두 프로세스가 양방향 네트워크 연결을 통해 통신할 때 연결 설정에서 스키마 버전 합의를 할 수 있다. 이후 연결을 유지하는 동안 합의된 스키마를 사용한다. 아브로 RPC 프로토콜이 이처럼 동작한다.
동적 생성 스키마
아브로는 스키마에 태그 번호가 포함 되어 있지 않다. 프로토콜 버퍼나 스리프트와는 다르다.
이 차이점은 아브로가 동적 생성 스키마에 더 친숙하다는 점에서 오는데, 예를 들어보자.
파일로 덤프할 내용을 가진 관계형 데이터베이스가 있는 상황에서 텍스트 형식(JSON, CSV, XML)의 문제점을 피하기 위해 이진 형식을 사용한다고 가정하자.
Plain Text
복사
아브로를 사용한다면 관계형 스키마로부터 아브로 스키마를 쉽게 생성할 수 있다.
그리고 이 스키마를 이용해 데이터베이스 내용을 부호화하고 아브로 객체 컨테이너 파일로 모두 덤프할 수 있다. 각 데이터베이스 테이블에 맞게 레코드 스키마를 생성하고 각 칼럼은 해당 레코드의 필드가 된다. 데이터베이스의 칼럼 이름은 아브로의 필드 이름에 매핑된다.
이제 데이터베이스 스키마가 변경되면(Ex: 테이블에 칼럼 하나 추가, 다른 칼럼 하나를 삭제한 경우) 갱신된 데이터베이스 스키마로부터 새로운 아브로 스키마를 생성하고 새로운 아브로 스키마로 데이터를 내보낸다. 데이터를 내보내는 과정은 스키마 변경에 신경 쓸 필요가 없다.
새로운 데이터 파일을 읽는 사람은 레코드 필드가 변경된 사실을 알게 되지만 필드는 이름으로 식별되기 때문에 갱신된 쓰기 스키마는 여전히 이전 읽기 스키마와 매치가능하다.
코드 생성과 동적 타입 언어
•
정적 타입 언어에서 유용한 스리프트와 프로토콜 버퍼
: 스키마를 정의한 후 선택한 프로그래밍 언어로 스키마를 구현한 코드를 생성할 수 있는 스리프트와 프로토콜 버퍼는 복호화된 데이터를 위해 효율적인 인메모리 구조를 사용하고 데이터 구조에 접근하는 프로그램을 작성할 때 IDE에서 타입 확인 및 자동 완성이 가능한 정적 타입 언어에서 유용하다.
•
동적 타입 언어에서 유용한 아브로
: 아브로와 같은 동적 생성 스키마의 경우 코드 생성은 데이터를 가져오는데 불필요하다. 즉, 명시적 컴파일 단계가 없는 동적 타입 언어(ex: 자바스크립트, 루비, 파이썬)처럼 코드 생성이 불필요하다.
참고: 아브로는 코드 생성을 선택적으로 제공한다.: 아브로는 정적 타입 언어를 위해 코드생성도 선택적으로는 제공한다.
하지만, 코드 생성 없이도 사용할 수 있다. 쓰기 스키마를 포함하는 객체 컨테이너 파일이 있다면 아브로 라이브러리를 사용해 간단히 열어 JSON파일을 보는 것과 같이 데이터를 볼 수 있다. 이 파일은 필요한 메타데이터를 모두 포함하기에 자기 기술(self-describing)적이다.
스키마의 장점
XML 스키마, JSON 스키마는 분명 간단하고 널리 사용되고 있다.
하지만, 앞서 알아본 프로토콜 버퍼, 스리프트, 아브로는 스키마를 사용해 이진 부호화 형식을 기술하는데 이를 이용하면 훨씬 더 간단하고 자세한 유효성 검사 규칙을 지원한다.
많은 데이터 시스템은 이진 부호화를 독자적으로 구현하기도 한다.
예를 들어 대부분의 RDB는 질의를 데이터베이스로 보내고 응답을 받을 수 있는 네트워크 프로토콜이 있다. 이러한 프로토콜은 일반적으로 특정 데이터베이스에 특화되어있고, 데이터베이스 벤더는 데이터베이스 네트워크 프로토콜로부터 응답을 인메모리 데이터 구조로 복호화하는드라이버(Ex: ODBC, JDBC API)를 제공한다.
스키마를 기반으로 하는 이진 부호화는 좋은 속성들을 많이 가지고 있다.
•
부호화된 데이터에서 필드 이름을 생략할 수 있어서 이진 JSON 변형보다 크기가 작을 수 있다.
•
복호화 시점에서 스키마가 필요하기 때문에 스키마가 최신 상태인지 확신할 수 있다.
(반면 수동으로 관리하는 문서는 실제와 달라지기 쉽다.)
•
스키마 데이터베이스를 유지하면 스키마 변경이 적용되기 전 상위 호환성과 하위 호환성을 확인할 수 있다.
•
정적 타입 언어 사용자에게 스키마로부터 코드를 생성하는 기능은 유용하다.
(컴파일 시점에 타입 체크가 가능하기 때문이다.)
요약하자면 스키마 발전은 스키마리스(schemaless) 또는 읽기 스키마(schema-on-read) JSON 데이터베이스가 제공하는 것과 동일한 종류의 유연성을 제공하며 데이터나 도구 지원도 더 잘 보장한다.
데이터플로 모드
프로세스간에 데이터를 전달하는 방법은 다양하다. 그렇기에 데이터플로는 추상적인 개념일 수 밖에 없다. 데이터를 누가 부호화하고 복호화 할지, 프로세스간 데이터를 전달하는 보편적인 방법에 대해 살펴보자.
데이터베이스를 통한 데이터플로
데이터베이스에 기록하는 프로세스는 데이터를 부호화하고 반대로 읽는 프로세스는 데이터를 복호화한다.
현재 데이터베이스에 기록한 데이터를 나중에 읽어서 복호화 하기 위해서는 하위 호환성이 유지되야 한다. 보통 애플리케이션은 변경되기 마련이고, 현재와 미래의 데이터는 달라질 가능성이 높다.
그렇기에 하위 호환성이 유지되지 않는다면, 미래의 애플리케이션은 과거의 데이터를 복호화 할 수 없다. 반대로 새로운 버전의 코드를 과거 버전의 코드가 읽는 경우도 생기는데, 이 때를 위해 상위 호환성도 필요하다.
재부호화 필드 유실
애플리케이션 레벨에서 데이터베이스의 값을 모델 객체로 복호화 및 재부호화(reencode)하는 변환 과정에서 새로운 버전과 기존 버전간의 코드 차이로 인해 필드가 유실 될 수 있다. 다음 그림을 보자.
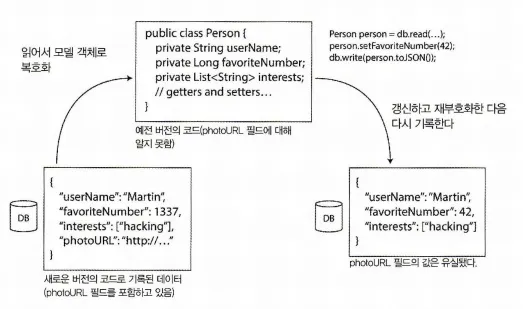
새로운 버전과 예전 버전간의 재부호화 변환과정에서 발생하는 데이터 유실
데이터베이스에 저장된 Person 정보를 애플리케이션에서 읽어 복호화하여 모델 객체(Person)으로 만든다. 그리고 이를 다시 재부호화하는데, 여기서 potoURL 필드의 값이 유실되었다.
다양한 시점에 기록된 다양한 값
데이터베이스의 값은 언제나 갱신할 수 있기 때문에 각각의 값들이 갱신된 시간이 각각 다를 수 있다. 반대로 갱신을 하지 않으면 원래의 부호화 상태로 그대로 있게 되는데 이런 상황을 데이터가 코드보다 더 오래 산다(data outlives code)라고 한다.
데이터를 새로운 스키마로 다시 기록(rewriting)(마이그레이션)하는 작업은 가능하지만, 대용량 데이터셋의 경우 비용이 크기에 이런 상황은 보통 피하게 된다. 대신 기존 데이터를 다시 기록하지 않고 Null을 기본값으로 갖는 새로운 칼럼을 추가하는 간단한 스키마 변경을 허용한다.
보관 저장소
데이터 덤프를 할 때는 보통 최신 스키마를 사용해 부호화하는데 시점에 무관하게 데이터를 보관한다는 것 때문에 데이터의 복사본을 일관되게 부호화하는 편이 낫다.
데이터 덤프는 한 번 기록 후 변하지 않기에 아브로 객체 컨테이너 파일과 같은 형식이 적합하며, 파케이와 같은 분석 친화적인 칼럼 지향 형식으로 데이터를 부호화할 기회이기도 하다.
서비스를 통한 데이터플로: REST와 RPC
서버는 네트워크를 통해 API 공개 및 클라이언트의 질의에 응답할 수 있다.
이 때 서버가 공개한 API를 서비스라고 한다.
이 서비스는 웹을 통해서 질의를 할 수도 있고 다른 서비스를 통해서 질의를 할 수도 있다.
서비스 지향 설계(service-oriented architecture, SOA)
위에서 언급한 하나의 서비스가 다른 서비스의 일부 기능이나 데이터가 필요할 경우 해당 서비스에 요청을 보내는데, 이런 애플리케이션 개발 방식을 서비스 지향 설계(SOA)라 부른다.
SOA란?
: 대규모 컴퓨 시스템 구축시 사용되는 개념으로 비즈니스 로직을 추상화 하고 추상화된 로직을 서비스로 판단해 그 서비스를 네트워크를 통해 연동하여 시스템 전체를 구축해 나가는 방법론이다. 각각의 서비스는 자신이 맡은 책임에 집중할 수 있고, 각 서비스간 결합도를 낮춰서 유연성과 확장성을 가져올 수 있다.
마이크로서비스 설계(microservices architecture, MSA)
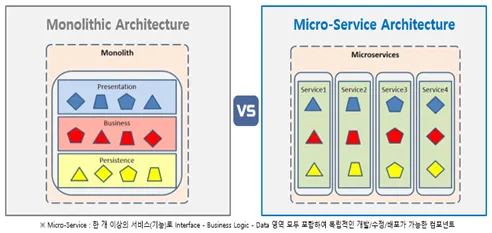
서비스 지향 설계가 더욱 개선되어 나온 개념으로 명확한 정의는 존재하지 않지만, 독립적으로 배포가능한 각각의 기능을 수행하는 서비스들로 구성된 구조라고 볼 수 있다.
그리고 여기서도 각각의 서비스는 서로 필요한 기능들을 질의할 수 있다.
서비스와 데이터베이스
서비스는 클라이언트와 질의를 하고, 데이터베이스도 질의 언어를 통해 질의를 한다. 그렇기에 유사해보이지만, 결정적인 차이는 캡슐화에 있다.
데이터베이스는 질의 언어를 이용한 질의를 허용하기 때문에, 내부 정보가 모두 허용된다.
하지만, 서비스는 미리 정해진 요청과 응답을 허용하는 애플리케이션 특화 API를 공개하며, 이는 캡슐화도 제공한다. 즉, 서비스는 클라이언트가 할 수 있는 일과 할 수 없는 일에 대한 제약을 세분화해 적용할 수 있다.
SOA, MSA의 목표는 결국 서비스를 배포와 변경에 독립적으로 만들어 애플리케이션의 변경 및 유지보수를 더 쉽게 할 수 있게 만드는 것이다.
이 말은 바꿔말하면 각 서비스는 각 팀에게 할당될 것이고 각 팀은 서비스를 다른 팀과 조율없이 새로운 버전을 출시할 수 있어야 한다. 그렇게되면 예전 버전과 현재 버전의 서버 및 클라이언트가 혼용될텐데 서비스와 클라이언트가 사용하는 데이터 부호화는 서비스 API의 버전 간 호환이 가능해야 한다.
웹 서비스
HTTP를 기본 프로토콜로 사용하는 서비스를 웹 서비스라 지칭한다.
하지만, 우리가 웹 서비스라고 부르는 API들을 웹뿐 아니라 다른 상황에서도 사용된다.
1.
핸드폰과 같은 사용자 디바이스 요청
2.
SOA, MSA 구조에서 각 조직 서비스에 요청
3.
인터넷을 통해 다른 조직의 서비스에 요청하는 서비스
그렇기에 웹 서비스라고 표현하기에는 약간 문제가 있다.
이러한 웹 서비스는 REST , SOAP를 통해 서비스 질의를 하는게 대표적이다.
•
REST
프로토콜이 아닌 HTTP의 원칙을 토대로 한 설계 철학
간단한 데이터 타입을 강조하며 URL을 사용해 리소스 식별을 하고 캐시 제어, 인증, 콘텐츠 유형 협상에 HTTP 기능을 사용한다. 이러한 REST원칙에 따라 설계된 API를 RESTful이라고 한다.
•
SOAP(Simple Object Access Protocol)
네트워크 API 요청을 위한 XML 기반 프로토콜
HTTP 상에서 일반적으로 사용되지만 HTTP와 독립적이며 HTTP기능 대부분을 사용하지 않는다. 대신 다양한 기능을 추가한 광범위하고 복잡한 여러 관련 표준(WS-* 이라 알려진 웹 서비스 프레임워크)을 제공한다.
API를 웹 서비스 기술 언어(Web SErvice Description Language, WSDL)이라 부르는 XML 기반 언어를 사용해 기술하는데, WSDL은 사람이 읽을 수 있게 설계하지 않았기에 도구 지원 및 코드 생성과 IDE에 크게 의존한다.
그렇기에 SOAP 벤더가 지원하지 않는 프로그래밍 언어 사용자는 SOAP서비스와 통합이 어렵다.
이러한 벤더간 상호운용성 문제로 많은 대기업이 SOAP를 사용하는 반면 작은 기업에서는 선호하지 않는다.
원격 프로시저 호출(RPC) 문제
원격 프로시저 호출(remote procedure call, RPC)는 원격 네트워크 서비스 요청을 같은 프로세스 안에서 특정 프로그래밍 언어의 함수나 메서드를 호출하는 것과 동일하게 사용 가능하게 해준다. (이런 추상화를 위치 투명성(location transparency)이라 한다.)
이러한 RPC를 이용한 네트워크 요청은 로컬 함수 호출과는 다르기 때문에 문제가 있다.
예측 가능한 로컬 함수 호출과 다르게 네트워크 요청은 다양한 이유로 요청에 응답하지 않을 수 있는데, 이런 문제는 일상적이고 또 제어하기도 힘들다.
그렇기에 네트워크 문제를 같이 고려해야 한다.
•
네트워크 요청은 타임아웃(timeout)으로 결과 없이 반환될 수 있는데, 이 경우 무슨 일이 있었는지 쉽게 알 수 없다. 원격 서비스로부터 응답을 받지 못한다면 요청을 제대로 보냈는지 아닌지를 알 수 있는 방법이 없다.
•
실패한 네트워크 요청을 재시도할 때 요청이 실제로는 처리되고 응답만 유실될 수 있다. 이 경우 중복 제거 기법(멱등성(idempotence))을 적용하지 않으면 재시도는 작업이 여러 번 수행되는 원인이 된다.
•
네트워크 요청은 함수 호출보다 느리고, 지연 시간도 다양하다. 네트워크 환경 혹은 부하에 따라 같은 작업의 지연 시간도 천차만별이 될 수 있다.
•
네트워크 요청시 모든 매개변수는 네트워크를 통해 전송할 수 있게 바이트열로 부호화해야 한다. 매개변수가 큰 객체일 경우 문제가 될 수 있다.
•
RPC 프레임워크는 하나의 언어에서 다른 언어로 데이터 타입을 변환해야 하는데 모든 언어가 같은 타입을 가지는 것은 아니기에 깔끔하지 않은 모습이 될 수 있다.
RPC의 현재 방향
RPC는 문제가 많아보인다. 하지만 그럼에도 불구하고 RPC는 사라지지 않았고, 지금까지 언급한 모든 부호화(프로토콜 버퍼, 스리프트, 아브로) 모두 RPC 프레임워크가 존재한다.
스리프트와 아브로는 RPC 지원 기능을 내장하고 있고, gRPC는 프로토콜 버퍼를 이용한 RPC 구현이다. 피네글(Finagle)은 스리프트를 사용하고 있고 Rest.li는 HTTP위에 JSON을 사용한다.
차세대 RPC 프레임워크는 원격 요청과 로컬 함수 호출의 차이점을 더 분명이 한다.
•
피네글, Rest.li
: 실패할 수 있는 비동기 작업의 캡슐화를 위해 퓨처(future)(promise))를 사용한다. 퓨처는 병렬로 여러 서비스에 요청을 보내야 하는 상황을 간소화하고 요청 결과를 취합한다.
•
gRPC
: 하나의 요청및 응답뿐 아니라 시간에 따른 일련의 요청과 응답으로 구성된 스트림을 지원한다.
이러한 프레임워크 중 일부는 서비스 찾기(service discovery)를 제공한다.
이진 부호화 형식을 사용하는 사용자 정의 RPC 프로토콜이 RESTful API 와 비교해서 더 성능적으로 우수할 수 있지만, RESTful API는 개발의 용이성(테스트, 디버깅의 편의성)과 범용성(모든 주요 프로그래밍 언어는 RESTful API를 지원한다.)과 다양한 도구 생태계(서버, 캐시 로드 밸런서, 프록시, 방화벽, 모니터링, 디버깅 도구, 테스팅 도구 등)가 있다.
그렇기에 같은 데이터센터 내의 같은 조직이 소유한 서비스간 요청에서는 RPC 프레임워크를 사용하기 적절하지만, 그 외 공개 API는 REST가 주로 사용된다.
데이터 부호화와 RPC의 발전
RPC는 조직 경계를 넘나드는 통신에 사용된다. 즉 서비스 호환성 유지를 더 어렵게 만든다는 것인데,
서비스 제공자와 소비자는 서로를 제어할 수 없기에 강제 업그레이드가 불가능하다. 그렇기에 안그래도 어려운 호환성은 거의 무한정 유지되야한다. (그래서 이펙티브 자바에서는 public API를 주의해서 선언하라고 한다. )
만약 호환성을 깨는 변경이 필요하다면 서비스 제공자는 보통 여러 버전의 서비스 API를 함께 유지한다. (자바에서는 그 후 @Deprecated 를 통해 API 제공 종료 공지를 미리 하고는 한다. )
API 버전 관리가 어떻게 되야하는지에 대해서는 규칙이나 합의는 없다.
다만, RESTful API는 URL혹은 HTTP Accept 헤더에 버전 번호를 사용하는게 일반적이다.
API키를 특정 클라이언트 식별에 사용하는 서비스는 클라이언트의 요청 API의 버전을 서버에 저장하고 버전 선택을 별도 관리 인터페이스를 통해 갱신 할 수도 있다.
메시지 전달 데이터플로
RPC와 데이터베이스 간 비동기 메시지 전달 시스템(asynchronous message-passing system)
•
클라이언트의 요청(보통 메세지라고 함)을 낮은 지연 시간으로 다른 프로세스에 전달
•
메시지를 임시로 저장하는 메시지 브로커( message broker)(or 메시지 큐(message queue)나 메시지 지향 미들웨어(message-oriented middleware))라는 중간 단계를 거쳐 전송한다.
메시지 브로커 사용시 이점(RPC와 비교)
•
수신자(recipient)가 사용 불가능하거나 과부하 상태일 때 메시지 브로커가 버퍼처럼 동작해 시스템 안정성이 향상된다.
•
죽었던 프로세스에 메시지를 다시 전달할 수 있기 때문에 메시지 유실을 방지할 수 있다.
•
송신자(sender)가 수신자의 IP주소나 포트 번호를 알 필요가 없다.
•
하나의 메시지를 여러 수신자로 전송할 수 있다.
•
논리적으로 송신자는 수신자와 분리된다.
메시지 전달 통신은 단방향이라는 점이 RPC와 다르다.
즉, 송신 프로세스는 대개 메시지에 대한 응답을 기대하지 않는다. 프로세스가 응답을 전송하는 것은 가능하지만 이것은 보통 별도 채널에서 수행한다. 이런 통신 패턴이 비동기이다.
송신 프로세스는 메시지가 전달될 떄까지 기다리지 않고 메시지를 보낸 후 잊는다.
메시지 브로커
과거와 현재 메시지 브로커 추세는 좀 달라졌다.
•
과거
◦
상용 기업 소프트웨어의 우위였다.
◦
TIBCO, WebSphere, webMethods
•
현재
◦
오픈소스의 구현이 대중화되었다.
◦
RabbitMQ, ActiveMQ, HornetQ, NATS, Apache Kafka
메시지 브로커는 일반적으로 다음과 같이 사용한다.
•
프로세스 하나가 메시지를 이름이 지정된 큐(Queue)나 토픽(Topic)으로 전송한다.
•
브로커는 해당 큐(Queue)나 토픽(Topic) 하나 이상의 소비자(consumer) 또는 구독자(subscriber)에게 메시지를 전달한다.
•
동일한 토픽에 여러 생산자(producer)와 소비자가 있을 수 있다.
•
토픽(Topic)은 단방향 데이터플로만 제공한다.
◦
소비자 스스로 메시지를 다른 토픽으로 게시할 수 있다.
◦
원본 메시지의 송신자가 소비하는 응답 큐로 게시할 수 있다.
분산 액터 프레임워크
액터 모델(actor model)은
•
액터 모델(actor model)은 단일 프로세스 안에서 동시성을 위한 프로그래밍 모델이다.
•
스레드를 직접 처리하는 대신 로직이 액터에 캡슐화된다.
⇒ 경쟁 조건, 잠금(locking), 교착 상태(deadlock)관련 문제들
•
각 액터는 하나의 클라이언트나 엔티티를 나타낸다.
•
액터는 자기만의 로컬 상태를 가질 수 있고 다른 액터와 비동기 통신할 수 있다.
•
액터는 메시지 전달을 보장하지 않는다.
•
특정 에러 상황에서 메시지는 유실될 수 있다.
•
각 액터 프로세스는 한 번에 하나의 메시지만 처리한다.
◦
스레드에 대해 걱정할 필요가 없다.
◦
각 액터는 프레임워크와 독립적으로 실행할 수 있다.
•
분산 액터 프레임워크에서 여러 노드 간 애플리케이션 확장에 사용된다.
•
단일 프로세스 안에서도 메시지 유실을 가정하고 있어서 위치 투명성은 RPC보다 액터 모델에서 더 잘 동작한다.
분산 액터 프레임워크는
메시지 브로커와 액터 프로그래밍 모델을 단일 프레임워크에 통합한다.
하지만, 애플리케이션의 순회식 업그레이드를 원한다면 메시지가 버전이 상충되는 노드간의 상하위 호환성에 주의해야 한다.
인기 있는 분산 액터 프레임워크 세 가지는 다음과 같이 메시지 부호화를 처리한다.
•
Akka
◦
자바의 내장 직렬화를 사용하며 상하위 호환성을 제공하진 않는다.
◦
프로토콜 버퍼와 같은 부호화 형식으로 대체해 순회식 업그레이드 수행을 할 수 있다.
•
Orleans
◦
사용자 정의 데이터 부호화 형식을 사용한다.(순회식 업그레이드 배포 지원 X)
◦
새로운 애플리케이션 배포를 위해 새로운 클러스터를 설정하고 나서 이전 클러스터의 트래픽을 새로운 클러스터로 이전한 뒤 이전 클러스터를 종료해야 한다.
◦
사용자 정의 직렬화 플러그인을 사용할 수 있다.
•
erlang
◦
OTP에선 레코드 스키마를 변경하는 것은 어렵다.
◦
순회식 업그레이드는 가능하지만 신중하게 계획해야 한다.

