
목차
34. int 상수 대신 열거 타입을 사용하라
정수 열거 패턴의 단점
public class Foods {
public static final int APPLE_FUJI = 0;
public static final int APPLE_PIPPIN = 1;
public static final int APPLE_GRANNY_SMITH = 2;
public static final int ORANGE_NAVEL = 0;
public static final int ORANGE_TEMPLE = 1;
public static final int ORANGE_BLOOD = 2;
}
Java
복사
과일을 종류별로 상수로 저장해놓은 Foods 클래스
위 클래스는 품종별 사과와 오렌지를 정수 상수처럼 묶어서 작성해놓은 Foods 클래스이다.
이런 정수 열거 패턴 기법에는 단점이 있으며 다음과 같다.
•
타입 안전을 보장할 수 없다.
•
표현력이 좋지 않다.
•
오렌지를 건네야 할 메서드에 사과를 보내고 동등 연산자(==)로 비교해도 컴파일러는 경고를 내보내지 않는다.
•
자바에서 별도의 namespace를 지원하지 않아서 접두어(APPLE, ORANGE)를 붙혀야 한다.
•
상수를 나열한 것 뿐이기에 깨지기 쉽다.
⇒ 컴파일시 그 값이 클라이언트 파일에 그대로 새겨지는데, 상수의 값이 바뀌면 클라이언트도 다시 컴파일해야한다.
이러한 단점으로 정수 열거 패턴의 변형인 문자열 열거 패턴(String enum pattern)도 있지만, 이역시 더 나쁘면 나쁘지 좋지는 않다. 숫자가 아니라 문자를 사용하게되면서 미숙한 개발자는 문자열 값을 그대로 사용하며 하드코딩 할 수 있기 때문이다. 이는 런타임 버그와 문자열 비교에 따른 성능저하를 유발시킨다.
그래서 다시 본론으로 돌아와 위에서 언급한 여러 단점들때문에 열거 타입이라는 대안책을 자바에서 제시했고 이 대악책을 사용하면 위와같은 단점들을 모두 해결할 수 있다.
열거 타입
public enum Apple{
FUJI, PIPPIN, GRANNY_SMITH
}
public enum Orange{
NAVEL, TEMPLE, BLOOD
}
Java
복사
위 코드는 기본적인 열거 타입 코드이며 겉보기엔 다른 언어(Ex: C, C++, C#)의 열거 타입과 비슷해보인다. 하지만 이 열거 타입은 완전한 형태의 클래스라서 다른 언어의 열거타입보다 강력하다.
열거타입의 특징
•
열거 타입 자체는 클래스이다.
•
상수 하나당 자신의 인스턴스를 하나씩 만들어 public static final 필드로 공개한다.
•
밖에서 접근할 수 있는 생성자를 제공하지 않기에 사실상 final이다.
•
열거 타입 선언으로 만들어진 인스턴스들은 딱 하나씩만 존재함이 보장된다.
⇒ 즉 인스턴스 통제되며 싱글턴이다.
•
타입 안전성을 제공한다.
•
namespace가 있어서 이름이 같은 상수도 공존할 수 있다.
•
임의의 메서드나 필드를 추가할 수 있고 임의의 인터페이스를 구현하게 할 수도 있다.
•
열거 타입은 자신 안의 정의된 상수들의 값을 배열에 담아 반환하는 정적메서드(values)를 제공한다.
열거타입은 언제 필요할까?
1. 각 상수와 연관된 데이터를 해당 상수 자체에 내제시키고 싶을 경우
: 태양계의 여덟 행성을 열거타입으로 작성한다고 예를 들어보자. 각 행성에는 질량과 반지름이 있고, 이 속성을 이용해 표면중력을 계산할수도 있다. 즉 각각의 행성에 질량,반지름, 표면중력과 같은 연관정보를 각각의 행성(상수)마다 저장을 하고싶을 때, 열거 타입으로는 다음과 같이 작성할 수 있다.
public enum Planet {
MERCURY(3.302e+23, 2.439e6),
VENUS(4.869e+24, 6.052e6),
EARTH(5.975e+24, 6.378e6),
MARS(6.419e+23, 3.393e6),
JUPITER(1.899e+27, 7.149e7),
SATURN(5.685e+26, 6.027e7),
URANUS(8.683e+25, 0.556e7),
NEPTUNE(1.024e+26, 2.477e7);
private final double mass; //질량(kg)
private final double radius; //반지름(meter)
private final double surfaceGravity; //표면중력(m / s^2)
//중력상수(m^3 / kg s^2)
private static final double G = 6.67300E-11;
Planet(double mass, double radius) {
this.mass = mass;
this.radius = radius;
surfaceGravity = G * mass / (radius * radius);
}
public double mass() { return mass; }
public double radius() { return radius; }
public double surfaceGravity() { return surfaceGravity; }
public double surfaceWeight(double mass) {
return mass * surfaceGravity; // F = ma
}
}
Java
복사
⇒ 각 열거 타입 상수 오른쪽 괄호 안 숫자는 생성자에 넘겨지는 매개변수다. (Planet 에서는 질량과 반지름이다. )
⇒ 열거 타입 상수 각각을 특정 데이터와 연결지으려면 생성자에서 데이터를 받아 인스턴스 필드에 저장하면 된다.
⇒ 열거 타입은 기본적으로 불변이기에 모든 필드는 final이어야 한다.
⇒ 필드는 public으로 해도 되지만 private로 두고 별도의 public접근자 메서드를 두는게 낫다.
Q. 열거타입에서 상수를 하나 제거하면 어떻게 될까?
A. 제거한 상수를 참조하지 않는 클라이언트에는 아무 영향이 없다.
특정 클래스에서만 사용된다면 멤버 클래스로 만든다.
열거 타입이 이곳 저곳 널리 사용된다면 톱레벨 클래스로 만드는게 맞다.
하지만, 특정 톱레벨 클래스에서만 사용된다면 해당 클래스의 멤버 클래스로 만들도록 하자.
예를들어, 소수 자릿수의 반올림 모드를 뜻하는 열거 타입 java.math.RoundingMode는 BigDecimal이 사용한다. 하지만 BicDecimal이 아닌 다른 영역에서도 유용한 개념이기에 RoundingMode를 톱레벨로 올렸다. 그 덕에 다양한 곳에서 이 개념을 더 일관된 모습으로 사용할 수 있게 된다.
열거 타입을 잘 쓰기위한 여러 사용법
1. 열거 타입의 상수마다 다른 동작을 해야하는 경우.
위에서 우리는 Planet 열거 타입을 통해 상수들이 각각 다른 데이터와 연결될수 있도록 했다.
하지만 여기서 한 걸음 더 나아가 상수마다 다른 동작을 해야한다면 어떨까?
예를들어 사칙연산의 종류를 열거 타입으로 선언하고 동작하는 연산까지 열거 타입으로 직접 동작하도록 해야한다고 하면 어떨까?
PLUS, MINUS, TIMES, DIVIDE가 각각 다르게 연산을 해야한다. 우선 간단한 방법으로는 switch 문을 이용해 분기하는 방법이 있을 것이다.
public enum Operation {
PLUS, MINUS, TIMES, DIVIDE;
public double apply(double x, double y) {
switch (this) {
case PLUS: return x + y;
case MINUS: return x - y;
case TIMES: return x * y;
case DIVIDE: return x / y;
}
throw new AssertionError("알 수 없는 연산: "+ this);
}
}
Java
복사
실제고 동작을 해보면 에러없이 잘 동작할 것이다. 하지만 이 코드는 몇가지 문제가 있다.
1.
throw문은 실제로 도달할 일이 없지만 기술적으로 도달할 수 있기에 생략시 컴파일할 수 없다.
2.
새로운 상수의 추가 혹은 삭제시 매번 로직을 수정해야 해서 깨지기 쉽다.
이런이유로 상수의 상태에 따른 분기를 직접 제어하며 코드를 구현하는것은 비효율적이며 더 나은 수단을 사용해야하는데 다행히도 열거 타입에서는 그러한 수단을 제공한다.
열거 타입에 추상 메서드를 선언 후 각 상수별로 클래스 몸체(constant-specific class body)를 재정의하는 방법인데 이를 상수별 메서드 구현(constant-specific method implementation)이라 한다.
public enum Operation {
PLUS {
@Override
public double apply(double x, double y) {
return x + y;
}
},
MINUS {
@Override
public double apply(double x, double y) {
return x - y;
}
},
TIMES {
@Override
public double apply(double x, double y) {
return x * y;
}
},
DIVIDE {
@Override
public double apply(double x, double y) {
return x / y;
}
};
public abstract double apply(double x, double y);
}
Java
복사
상수별 메서드 구현(constant-specific method implementation)
apply 메서드가 추상 메서드로 선언되어 바로 옆에 붙어있기에 새로운 상수를 추가 할 때 apply를 재정의하지 않으면 컴파일되지 않는다. 또한 이 방법은 상수별 데이터와 혼용할수도 있다.
public enum Operation {
PLUS("+") {
@Override
public double apply(double x, double y) {
return x + y;
}
},
MINUS("-") {
@Override
public double apply(double x, double y) {
return x - y;
}
},
TIMES("*") {
@Override
public double apply(double x, double y) {
return x * y;
}
},
DIVIDE("/") {
@Override
public double apply(double x, double y) {
return x / y;
}
};
public final String symbol;
Operation(String symbol) {
this.symbol = symbol;
}
public abstract double apply(double x, double y);
@Override
public String toString() {
return symbol;
}
}
Java
복사
각 상수에 연결된 데이터로 상수별 심볼(symbol)을 선언해줬고 toString을 재정의해 해당 연산을 의미하는 심볼을 반환하도록 했다. 이를 사용하면 이 사칙연산 열거타입을 편하게 사용할 수 있다.
public static void main(String[] args) {
double x = 2D;
double y = 4D;
for (Operation op : Operation.values()) {
System.out.printf("%f %s %f = %f%n", x, op, y, op.apply(x,y));
}
}
Java
복사
실행결과를 보면 이 열거타입이 얼마나 사용하기 편한지 알 수 있다. 상수에 대한 심볼을 출력하기위해 따로 로직을 작성할 필요도 없고 연산을 위해 분기할 필요도 없다.
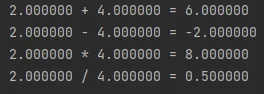
실행 결과
상수별 메서드 구현의 단점과 그 해결책
상수별 메서드 구현을 통해 각각의 상수가 다른 동작을 할 수 있게 구현을 해보았다.
그런데, 사칙연산 같은경우에는 각각의 상수가 모두 다 다른 동작을 해야 하기 때문에 문제가 없었지만, 만약 동작이 같은 타입도 있을 경우엔 어떨까? 이처럼 상수별 메서드 구현에서는 열거 타입 상수끼리 코드를 공유하기 어렵다는 단점이 있다.
좀 더 이해하기 쉬운 예를 들어보자.
•
열거타입 명: PayrollDay
•
상수: 일주일 각각의 날짜 (MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY, SUNDAY)
•
업무시간(분): 8 * 60( 1일 8시간 근무 기준)
•
추가조건
◦
주중 오버타임은 잔업시간이 주어진다.
◦
주말에는 무조건 잔업수당이 주어진다.
public enum PayrollDay {
MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY, SUNDAY;
private static final int MINS_PER_SHIFT = 8 * 60;
int pay(int minutesWorked, int payRate) {
int basePay = minutesWorked * payRate;
int overtimePay;
switch (this) {
case SATURDAY: case SUNDAY: //주말
overtimePay = basePay / 2;
break;
default://주중
overtimePay = minutesWorked <= MINS_PER_SHIFT
? 0
: (minutesWorked - MINS_PER_SHIFT) * payRate / 2;
}
return basePay + overtimePay;
}
}
Java
복사
코드는 나름 간결하게 잘 작성되어 있다. 하지만, 여기에는 치명적인 문제가 있다.
이 코드는 주말과 주중을 구분하고 주중에 오버타임에 대해서는 구분을 해놨지만 그외의 잔업이 발생하는 경우에 대한 고려가 전혀 되어있지 않다. 휴가 기간에 일을 할 수도 있고 공휴일에 대한 조건도 없다. 이 경우 그때그때 매번 case를 추가하거나 조건들을 고쳐줘야하는 문제가 있다.
그럼 이를 해결하기 위해서는 어떻게 해야할까?
전략 패턴(Strategy Pattern)을 사용하자.
잔업수당을 계산하는 로직 자체 두 가지(평일, 휴일)를 private 중첩 열거 타입으로 만들어 옮기고, PayrollDay 열거타입의 생성자에서 주입받도록 하는 것이다. 이렇게되면 잔업수당 계산을 전략 열거 타입에 위임하여 따로 분기처리 나 상수별 메서드 구현이 필요없게 된다.
public enum PayrollDay {
MONDAY(WEEKDAY), TUESDAY(WEEKDAY),
WEDNESDAY(WEEKDAY), THURSDAY(WEEKDAY), FRIDAY(WEEKDAY),
SATURDAY(WEEKEND), SUNDAY(WEEKEND);
private final PayType payType;
PayrollDay(PayType payType) {
this.payType = payType;
}
int pay(int minutesWorkd, int payRate) {
return payType.pay(minutesWorkd, payRate);
}
enum PayType {
WEEKDAY {
@Override
int overtimePay(int mins, int payRate) {
return minWorked <= MINS_PER_SHIFT
? 0
: (minWorked - MINS_PER_SHIFT) * payRate / 2;
}
},
WEEKEND {
@Override
int overtimePay(int mins, int payRate) {
return minsWorked * payRate / 2;
}
};
abstract int overtimePay(int mins, int payRate);
private static final int MINS_PER_SHIFT = 8 * 60;
int pay(int minsWorked, int payRate) {
int basePay = minsWorked * payRate;
return basePay + overtimePay(minsWorked, payRate);
}
}
}
Java
복사
코드는 조금 복잡해지지만 switch문 없이도 상수별 메서드 구현이 가능하면서도 중복도 최소화하여 동일한 로직이 필요한경우도 유연하게 대처 가능하다.
그럼 switch문은 무조건 없는게 좋을까?
꼭 그렇지는 않다. 기존 열거 타입에 상수별 동작을 혼합해 넣을 경우 switch문이 좋은 선택이 될 수 있다. 예를 들어 사칙연산 열거 타입인 Operation이 있고 각각의 타입의 반대 연산을 반환하는 inverse라는 메서드를 구현해야 한다면 switch문이 적절한 선택이 될 수 있다.
public static Operation inverse(Operation op) {
switch(op) {
case PLUS: return Operation.MINUS;
case MINUS: return Operation.PLUS;
case TIMES: return Operation.DIVIDE;
case DIVIDE: return Operation.TIMES;
default: throw new AssertionError("알 수 없는 연산" + op);
}
}
Java
복사
열거 타입은 결국 언제 써야 할까?
대부분의 경우 열거 타입의 성능이 정수 상수와 비교해서 크게 차이가 나지 않는다.
그럼 이 열거 타입은 언제 쓰는게 좋을까?
필요한 원소를 컴파일타임에 다 알 수 있는 상수 집합이라면 항상 열거 타입을 사용하자.
위에서 작성했던 태양계 행성, 요일, 사칙연산과 같은 타입들은 당연히 이에 포함된다.
 참고: Lambda식을 이용한 상수별 메서드 구현
참고: Lambda식을 이용한 상수별 메서드 구현
Java 8 이후 람다식을 이용해 메서드를 일급 함수로 구현할 수 있게 되었기에 기존에 작성한 상수별 메서드 구현을 좀 더 간단하게 리팩터링 할 수 있다.
public enum OperationV3 {
PLUS("+", (a, b) -> a + b),
MINUS("-", (a, b) -> a - b),
TIMES("*", (a, b) -> a * b),
DIVIDE("/", (a, b) -> a / b);
public final String symbol;
public final ToDoubleBiFunction<Double, Double> function;
OperationV3(String symbol, ToDoubleBiFunction<Double, Double> function) {
this.symbol = symbol;
this.function = function;
}
public double apply(double a, double b) {
return this.function.applyAsDouble(a, b);
}
@Override
public String toString() {
return symbol;
}
}
Java
복사
정리
•
열거 타입은 정수 상수보다 가독성과 안전성 부분에서 뛰어나다.
•
각 상수를 각각 다른 데이터와 동작과 연결시킬 수 있다.
•
하나의 메서드가 상수별로 다른 동작을 해야 할 경우 switch가 아니라 상수별 메서드 구현을 사용하자.
•
상수 몇몇이 같은 동작을 공유할 경우 전략 열거 타입 패턴을 사용하자.
35. ordinal 메서드 대신 인스턴스 필드를 사용하라
요약
•
열거타입의 상수가 몇 번째 위치를 반환하는 ordinal 메서드는 특별한 경우(EnumSet, EnumMap)가 아니라면 사용하지 말자.
•
순서가 필요하다면, 인스턴스 필드를 사용하도록 하자.
oridnal의 문제
열거 타입은 해당 상수가 몇 번째 위치인지를 반환하는 ordinal 메서드를 제공한다.
public enum Ensemble {
SOLO, DUET, TRIO, QUARTET, QUINTET, SEXTET, SEPTET, OCTET, NONET, DECTET;
public int numberOfMusicians(){ return ordinal() + 1; }
}
Java
복사
위 Ensemble 열거 타입은 합주단의 종류를 연주자가 1명인 솔로부터 10명인 디텍트까지 정의한 열거타입이다.
위 열거 타입에서 numberOfMusicians메서드를 호출하면 적절한 숫자가 반환되며 원하는대로 동작을 한다.
하지만, 사실 이 코드는 치명적인 문제가 있다. 바로 선언 순서에 영향을 받는다는 점인데 만약 SOLO와 DUET의 위치를 서로 바꾸면 DUET의 numberOfMusicians 메서드 반환값은 1이 되고 SOLO는 2가 되버린다.
또한 값이 동일한 상수를 추가할수도 없고, 값이 비는 곳도 비워둘 수 없다. 위 열거 타입에서 12명이 연주하는 3중 4중주(triple quartet)을 추가한다고 할 때, 나는 의도한 12명만 추가할게 아니라 11명 짜리 상수도 채워야하는데 11명짜리 연주를 일컫는 말이 없다.
해결책
사실 해결책은 간단하다. ordinal을 안쓰면된다. 그리고 연결된 데이터 값은 ordinal 메서드가 아닌 인스턴스 필드에 저장하도록 하자.
public enum EnsembleV2 {
SOLO(1), DUET(2), TRIO(3), QUARTET(4), QUINTET(5),
SEXTET(6), SEPTET(7), OCTET(8), NONET(9), DECTET(10), TRIPLE_QUARTET(12);
private final int numberOfMusicians;
EnsembleV2(int numberOfMusicians) {
this.numberOfMusicians = numberOfMusicians;
}
public int numberOfMusicians() {
return numberOfMusicians;
}
}
Java
복사
애초에 Enum API Doc에도 ordinal 메서드에 대해서 대부분의 프로그래머는 이 메서드를 쓸 일이 없고, EnumSet, EnumMap과 같이 열거 타입 기반의 범용 자료구조에서 사용될 목적이라 작성되어있다.
36. 비트 필드 대신 EnumSet을 사용하라.
요약
•
EnumSet클래스는 비트 필드 수준의 명료함과 성능, 그리고 열거 타입 자체의 장점도 제공한다.
•
비트 필드를 직접 다룰 때 겪어야 할 난해한 코드와 오류를 이미 다 해결해놓은 EnumSet을 사용하자.
•
(자바9까진) 불변 EnumSet을 만들 수 없기에 수정 전에는 Collections.unmodifiableSet으로 EnumSet을 감싸 사용할 수 있다.
비트 필드(bit field)
비트별 OR를 사용해 여러 상수를 하나로 모은 집합을 비트 필드(bit field)라 한다.
public class Text {
public static final int STYLE_BOLD = 1 << 0; //1
public static final int STYLE_ITALIC = 1 << 1; //2
public static final int STYLE_UNDERLINE = 1 << 2; //4
public static final int STYLE_STRIKETHROUGH = 1 << 3; //8
public void applyStyles(int styles) {
}
}
Java
복사
비트 필드 열거 상수
위와 같은 비트 필드 열거 상수가 있다고 할 때 다음과 같이 만들어진 집합을 비트 필드(bit field)라 한다.
⇒ text.applyStyles(STYLE_BOLD | STYLE_ITALIC);
이러한 비트필드를 사용하면 비트연산을 사용해 합집합과 교집합 같은 집합 연산을 효율적으로 수행할 수 있다.
그런데 왜 EnumSet을 사용해야할까? 그 이유는 다음과 같은 문제점 때문이다.
•
정수 열거 상수의 단점을 그대로 가진다.
•
비트 필드 값이 그대로 출력되면 해석하기가 어렵다.
•
비트 필드 하나에 녹아 있는 모든 원소를 순회하기도 까다롭다.
•
최대 몇 비트가 필요한지 API 작성 시 미리 예측해 적절한 타입을 선택해야 한다.(ex: int or long)
대안책
java.util 패키지의 EnumSet클래스는 열거 타입 상수의 값으로 구성된 집합을 효과적으로 표현해준다.
내부가 비트 벡터로 구현되어 있으며 원소가 64개 이하인 경우 EnumSet전체를 대부분 long 변수 하나로 표현하여 비트 필드에 비견되는 성능을 보여준다.
removeAll과 retainAll과 같은 대량 작업은 비트를 효율적으로 처리할 수 있는 산술 연산을 써서 구현했다.
즉, 비트를 직접 다룰 때 겪는 문제들을 EnumSet에서 대부분 해결해준다.
다음 코드는 위의 비트 열거 상수를 EnumSet으로 수정한 코드이다.
public class Text {
public enum Style { BOLD, ITALIC, UNDERLINE, STRIKETHROUGH }
//어떤 Set을 넣어도 되지만 EnumSet이 제일 좋다.
public void applyStyles(Set<Style> styleSet){ ... }
}
Java
복사
몹시 간결하다. 그리고 applyStyles메서드를 호출할 때는 인수로 EnumSet을 전달하면된다.
text.applyStyles(EnumSet.of(Style.BOLD, Style.ITALIC));
Java
복사
applyStyles 메서드에서 그럼 EumSet이 가장 효율이 좋으면 Set이 아닌 EnumSet으로 해도 되지않을까? 생각 할 수 있지만, 인터페이스로 받는게 일반적으로 좋은 습관이다. 이렇게 하면 좀 특이한 클라이언트에서 다른 Set 구현체를 넘겨도 문제없이 동작하기 때문이다.
37. ordinal 인덱싱 대신 EnumMap을 사용하라
요약
•
ordinal 메서드로 얻은 값을 배열이나 맵의 인덱스로 사용할 수 있지만, 좋은 생각이 아니다.
•
대신 EnumMap을 사용하면 내부적으로 배열을 사용하기에 콜렉션의 타입안전성과 배열의 속도를 모두 가진다.
•
다차원 관계는 EnumMap(..., EnumMap<...>>으로 표현하자.
•
즉, 콜렉션의 장점과 배열의 장점을 모두 가져가고 싶다면 EnumMap을 고려해보자.
Enum.ordinal 그룹핑
Enum에서 제공하는 ordinal 메서드는 열거타입의 상수의 위치기반으로 인덱스를 반환한다.
그러다보니 어떤 코드에서는 이 인덱스를 기준으로 배열을 관리해서 그룹핑을 시도하는 경우가 있다.
다음 코드는 식물을 나타내는 Plant 클래스로 내부적으로 식물의 생애주기를 Enum필드로 갖는다.
public class Plant {
enum LifeCycle { ANNUAL, PERENNIAL, BIENNIAL }
final String name;
final LifeCycle lifeCycle;
public Plant(String name, LifeCycle lifeCycle) {
this.name = name;
this.lifeCycle = lifeCycle;
}
@Override
public String toString() {
return name;
}
}
Java
복사
그럼 이러한 식물(Plant)가 여럿 있다고 할 때 필요에 의해 생애주기를 기준으로 집합을 만들어 관리하고 싶다고 하자. 이 경우 각 집합은 배열로 관리되며 배열의 인덱스를 LifeCycle 의 ordinal 값으로 관리할 수 있다는 생각을 할 수 있다. 다음 코드는 그러한 생각하에 나온 코드이다.
@SuppressWarnings("unchecked")
Set<Plant>[] plantsByLifeCycle = new Set[Plant.LifeCycle.values().length];
for (int i = 0; i < plantsByLifeCycle.length; i++) {
plantsByLifeCycle[i] = new HashSet<>();
}
for (Plant p : garden) {
plantsByLifeCycle[p.lifeCycle.ordinal()].add(p);
}
for (int i = 0; i < plantsByLifeCycle.length; i++) {
System.out.printf("%s: %s%n", Plant.LifeCycle.values()[i], plantsByLifeCycle[i]);
}
Java
복사
물론 동작은 할 테지만 다음과 같은 많은 문제들이 있다.
•
배열과 제네릭은 호환되지 않기에 비검사 형변환을 수행해야 한다.
⇒ 깔끔한 컴파일도 되지 않을 것이다.
•
배열은 각 인덱스의 의미를 모르기에 출력 결과에 직접 레이블을 달아야 한다.
•
정확한 정숫값을 사용한다는 것을 개발자가 직접 보증해야 한다.
⇒ 정수는 열거 타입과 다르게 타입 안전하지 않기 때문이다.
이런 문제들로 운이 좋아야 ArrayIndexOutOfBoundException같은 예외를 볼 수 있고 그외에는 잘 못된 동작이 조용히 실행되면서 프로그램은 의도와 다르게 동작할 확률이 높다.
아이템 35에서도 말했지만 ordinal을 우리가 직접 쓸 일은 거의 없다. 대부분 대안책이 존재하며 다행히 이 경우에도 EnumMap이라는 대안책이 존재한다.
대안책 - EnumMap
물론 Map을 이용해 열거 타입을 키로 사용하도록 할 수도 있을 것이다.
근데 이러한 Map 구현체들 중에서도 EnumMap은 내부적으로 배열을 사용하기에 속도부분에서 아주 뛰어나다.
다음은 EnumMap을 사용해 위에서 작성한 비효율적이고 문제많은 코드를 리팩토링 해보았다.
Map<Plant.LifeCycle, Set<Plant>> plantByLifeCycle = new EnumMap<>(Plant.LifeCycle.class);
for (Plant.LifeCycle lc : Plant.LifeCycle.values()) {
plantByLifeCycle.put(lc, new HashSet<>());
}
for (Plant p : garden) {
plantByLifeCycle.get(p.lifeCycle).add(p);
}
System.out.println(plantByLifeCycle);
Java
복사
코드가 더 짧고 깔끔해졌으며 더하여 Map을 사용했기에 타입 안정적이고 성능마저 빠르다.
성능이 빠른 이유는 내부적으로 배열을 사용하기 때문인데 이러한 구현을 내부로 숨겨 Map의 타입 안전성과 배열의 성능을 모두 얻어냈다.
여기서 EnumMap의 생성자가 받는 키 타입의 Class 객체는 한정적 타입 토큰으로, 런타임 제네릭 타입 정보를 제공한다. 만약 자바 8 이상이라면 스트림을 사용해 코드를 더 리팩토링 할 수 있다.
System.out.println(Arrays.stream(garden)
.collect(Collectors.groupingBy(p -> p.lifeCycle,
() -> new EnumMap<>(Plant.LifeCycle.class),
toSet())));
Java
복사
단순한 프로그램이라면 상관없지만 맵을 자주 사용할수록 이런 리팩토링은 필수다.
주의할점은 위의 스트림을 이용한 코드는 EnumMap만 사용했을 경우와는 다르게 동작하는데, 스트림을 이용한 방식은 내용이 없는 카테고리(열거타입의 상수)에 대해서는 값을 만들지 않는다.
즉 열거타입 LifeCycle에 3개의 상수가 있다고 할 때 만일 이중 2개에 해당하는 식물들만 있다면 결과로 나온 EnumMap에는 이 두 가지 그룹에 대해서만 만든다.
EmumMap Diagram
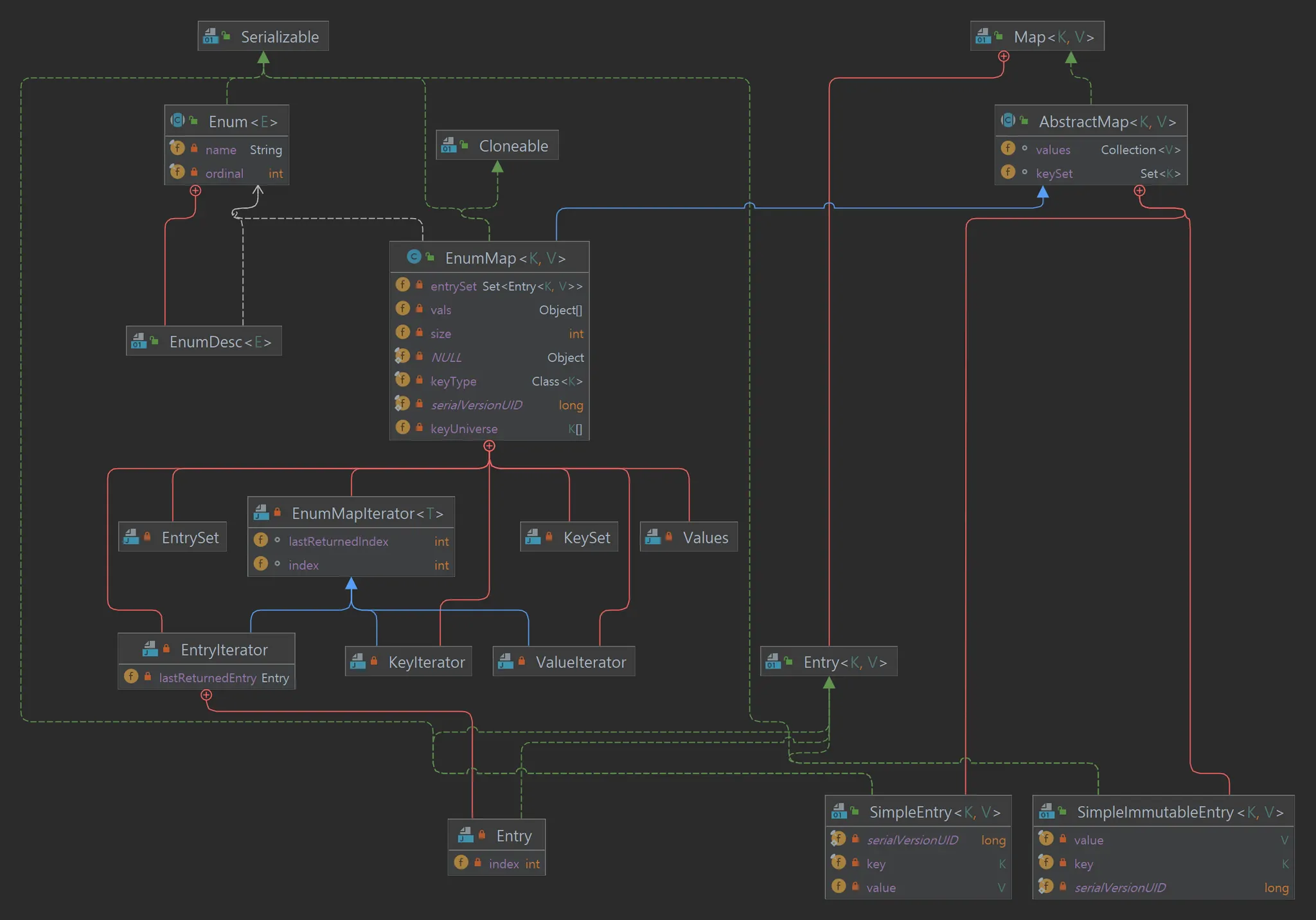
EnumMap diagram
EnumMap의 keyUniverse 라는 멤버필드에서 키를 정규타입 매개변수 배열로 관리한다.
응용 - 상태전이 배열
두 가지의 상태가 조합되면 새로운 결과가 나오게 되는 코드를 구현한다고 해보자.
예를들어 액체(LIQUID)에서 고체(SOLID)로의 전이는 응고(FREEZE)가 되고, 액체에서 기체(GAS)로의 전이는 기화(BOIL)가 된다는 점을 코드로 구현해보자. 우선은 ordinal을 사용하는 안좋은 코드이다.
public enum PhaseV1 {
SOLID, LIQUID, GAS;
public enum Transition {
MELT, FREEZE, BOIL, CONDENSE, SUBLIME, DEPOSIT;
private static final Transition[][] TRANSITIONS = {
{null, MELT, SUBLIME},
{FREEZE, null, BOIL},
{DEPOSIT, CONDENSE, null}
};
public static Transition from(PhaseV1 from, PhaseV1 to) {
return TRANSITIONS[from.ordinal()][to.ordinal()];
}
}
}
Java
복사
얼핏보면 멋져보인다. 두 상태(Phase)를 조합해서 그 결과를 반환하는 해당 코드는 다음과 같은 문제가 있다.
•
컴파일러는 ordinal과 배열 인덱스의 관계를 알 수 없기에 Phase나 Transition의 상태 혹은 상수의 순서가 바뀌었을 때 이를 인지해서 상전이 표TRANSITIONS를 맞춰 수정하지 않으면 런타임 오류가 날 것이다.
•
상태가 커질수록 상전이 표의 크기는 기하급수적으로 커진다.
즉, 이런 상태전이 코드역시 EnumMap을 사용하는게 좋다.
public enum Phase {
SOLID, LIQUID, GAS;
public enum Transition {
MELT(SOLID, LIQUID), FREEZE(LIQUID, SOLID),
BOIL(LIQUID, GAS), CONDENSE(GAS, LIQUID),
SUBLIME(SOLID, GAS), DEPOSIT(GAS, SOLID);
private final Phase from;
private final Phase to;
Transition(Phase from, Phase to) {
this.from = from;
this.to = to;
}
private static final Map<Phase, Map<Phase, Transition>> m =
Stream.of(values()).collect(groupingBy(t -> t.from,
() -> new EnumMap<>(Phase.class),
toMap(t -> t.to,
t -> t,
(x, y) -> y,
() -> new EnumMap<>(Phase.class))));
public static Transition from(Phase from, Phase to) {
return m.get(from).get(to);
}
}
}
Java
복사

Collectors.groupingBy()메서드에서 요구하는 매개변수 타입

Collectors.toMap()메서드에서 요구하는 매개변수 타입
코드는 꽤나 복잡하다. 이 맵의 타입인 Map<Phase, Map<Phase, Transition>>은 이전 상태에서 이후 상태로의 전이로의 맵에 대응시키는 맵이라는 의미인데, 이러한 맵의 맵을 초기화 하기 위해 Collector는 2개를 차례로 사용했다.
첫 번째 수집기인 groupingBy에서 전이를 이전 상태를 기준으로 묶고, 두 번째 수집기인 toMap에선 이후 상태를 전이에 대응시키는 EnumMap을 생성해준다.
여기서 (x, y)→ y 코드부분은 선언만하고 실제로 사용되지는 않는다. 단순히 EnumMap을 얻기위해서 MapFactory가 필요하기에 수집기로 점층적 팩토리를 제공받기 위해서이다.
이 반환타입의 구조는 다음과 같이 볼 수 있다.
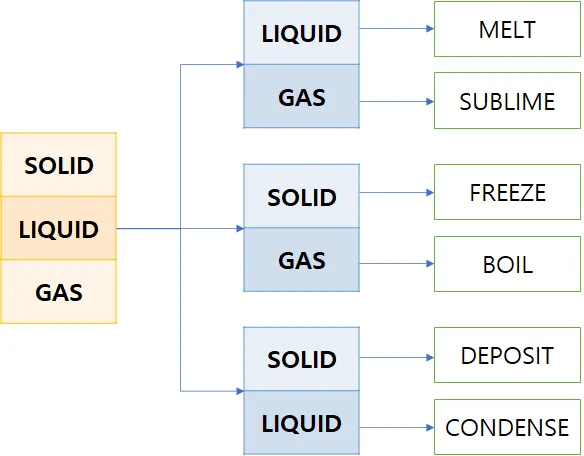
Phase 열거타입의 내부 구조
이 코드는 새로운 상태의 추가 및 삭제에 몹시 유연하다. 만약 위 코드에서 PLAZMA상태가 추가되고 전이 목럭에 IONIZE(GAS, PLASMA)와 DEIONIZE(PLAZMA, GAS)가 추가된다면 다음과 같이 추가만 해주면된다.
public enum Phase {
SOLID, LIQUID, GAS, PLASMA;
public enum Transition {
MELT(SOLID, LIQUID), FREEZE(LIQUID, SOLID),
BOIL(LIQUID, GAS), CONDENSE(GAS, LIQUID),
SUBLIME(SOLID, GAS), DEPOSIT(GAS, SOLID);
IONIZE(GAS, PLASMA), DEIONIZE(PLASMA, GAS);
...//나머진 그대로
}
}
Java
복사
이 코드는 새로운 상태가 추가되었지만 기타 행위를 의미하는 로직들을 따로 수정해줄 필요가 없다.
38. 확장할 수 있는 열거 타입이 필요하면 인터페이스를 사용하라.
요약
•
열거 타입 자체는 확장할 수 없다.
•
인터페이스와 인터페이스를 구현하는 기본 열거타입을 같이 사용해 확장한 것처럼 사용할 수 있다.
•
열거 타입끼리는 상속이 불가능하기에 공통기능은 다음과 같이 사용할 수 있다.
1.
(Stateless인 경우) 인터페이스에 Default Method를 구현한다.
2.
(Stateful인 경우)별도의 도우미 클래스나 정적 도우미 메서드로 분리한다.
타입 안전 열거 패턴(typesafe enum pattern)
이펙티브자바 초판에서 소개되었던 타입 안전 열거 패턴을 소개를 했었다.
public class TypesafeOperation {
private final String type;
private TypesafeOperation(String type) {
this.type = type;
}
public String toString() {
return type;
}
public static final TypesafeOperation PLUS = new TypesafeOperation("+");
public static final TypesafeOperation MINUS = new TypesafeOperation("-");
public static final TypesafeOperation TIMES = new TypesafeOperation("*");
public static final TypesafeOperation DIVIDE = new TypesafeOperation("/");
}
Java
복사
클래스를 이용하고, 생성자를 private로 만들어 최초 정의된 객체만 참조할 수 있게 했다. 열거 타입과 비슷하게 사용할 수 있지만, 사실 단 하나를 제외하곤 모든 부분에서 열거 타입이 우수하다.
바로 타입 안전 열거 패턴은 확장이 가능하지만 열거 타입은 그럴수 없다는 점이다.
물론, 대부분 상황에서 열거 타입을 확장하려는 시도가 좋은생각은 아니다. 확장 타입 원소는 기반 타입 원소로 취급되지만 반대의 경우는 성립하지도 않고 기반타입 + 확장타입 원소를 모두 순회할 방법도 딱히 없다.
그리고 확장성을 높히려고 할 때 고려할 설계와 구현이 너무 복잡해진다.
하지만, 확장할 수 있는 열거 타입이 어울리는 경우가 있긴 하다. 위에서도 작성한 연산 코드(operation code)인데, 연산 코드의 각 원소는 특정 기계가 수행하는 연산을 의미한다. (ex: 계산기의 연산 기능) 그럼 이 경우 우리는 어떻게 확장을 해야 할까?
인터페이스를 활용한 확장
다행히 열거 타입은 임의의 인터페이스를 구현할 수 있다.
이 점에서 착안해 연산코드용 인터페이스를 정의한 뒤 열거 타입에서 이 인터페이스를 구현하게 하면 된다. 그럼 이제 간단한 계산용 인터페이스와 이를 구현하는 열거 타입을 만들어보자.
1.
Operation 인터페이스
@FunctionalInterface
public interface Operation {
double apply(double x, double y);
}
Java
복사
⇒ 연산을 수행하라는 간단한 apply 메서드만 정의했다.
2.
BasicOperation 열거 타입
public enum BasicOperation implements Operation {
PLUS("+") {
@Override
public double apply(double x, double y) { return x + y; }
},
MINUS("-") {
@Override
public double apply(double x, double y) { return x - y; }
},
TIMES("*") {
@Override
public double apply(double x, double y) { return x * y; }
},
DIVIDE("/") {
@Override
public double apply(double x, double y) { return x / y; }
};
private final String symbol;
BasicOperation(String symbol) {
this.symbol = symbol;
}
@Override
public String toString() { return symbol; }
}
Java
복사
⇒ 열거 타입 각각의 상수에서 Operation 인터페이스의 apply 메서드를 구현한다.
3.
ExtendedOperation 열거 타입
: 지수 연산과 나머지 계산이라는 연산이 확장될 필요가 있다고 가정해서 추가해보자.
public enum ExtendedOperation implements Operation {
EXP("^") {
@Override
public double apply(double x, double y) { return Math.pow(x, y); }
},
REMAINDER("%") {
@Override
public double apply(double x, double y) { return x % y; }
};
private final String symbol;
ExtendedOperation(String symbol) {
this.symbol = symbol;
}
@Override
public String toString() { return symbol; }
}
Java
복사
⇒ 이 열거타입의 연산은 기존 연산을 사용하던 곳은 어디든 사용할 수 있다.
⇒ Operation 인터페이스를 사용하도록 작성되어 있기만 하면 된다.
이렇게 구현한 인터페이스와 열거 타입은 이제 열거타입에서 따로 추상 메서드를 선언하지 않아도 되고 인터페이스덕분에 다형성도 보장된다. 개별 인스턴스 수준에서뿐 아니라 타입 수준에서도 기본 열거 타입 대신 확장된 열거 타입을 넘겨 확장된 열거 타입의 원소 모두를 사용하게 할 수도 있다.
이렇게 유연하게 사용할 수 있도록 코드 두 가지 방법으로 작성해볼 수 있다.
1.
한정적 타입 토큰을 이용한 방법
public class OperationApp {
public static void main(String[] args) {
double x = 4, y = 2;
test(ExtendedOperation.class, x, y);
}
private static <T extends Enum<T> & Operation> void test(
Class<T> opEnumType, double x, double y) {
for (Operation op : opEnumType.getEnumConstants()) {
System.out.printf("%f %s %f = %f%n", x, op, y, op.apply(x, y));
}
}
}
Java
복사
⇒ test 메서드에 인수로 ExtendedOperation 의 class 리터럴을 넘겨 이를 이용한 방법이다.
⇒ <T extends Enum<T> & Operation> 매개변수의 선언은 Class 객체가 열거타입인 동시에 Operation 인터페이스의 구현체여야 한다는 의미다.
2.
한정적 와일드카드 타입을 넘기는 방식
public static void main(String[] args) {
double x = 4, y = 2;
testV2(Arrays.asList(ExtendedOperation.values()), x, y);
}
private static void testV2(Collection<? extends Operation> opSet, double x, double y) {
for (Operation op : opSet) {
System.out.printf("%f %s %f = %f%n", x, op, y, op.apply(x, y));
}
}
Java
복사
⇒ 인수로 Collection<? extends Operation> 타입의 한정적 와일드카드 타입을 넘기는 방식
⇒ 코드가 좀 덜 복잡하고 test메서드가 좀 더 유연해졌다.
⇒ 특정 연산에서 EnumMap이나 EnumSet을 사용할 수 없다는 단점이 있다.
제약사항
인터페이스를 활용해 열거 타입을 확장가능한 것처럼 만들어봤다.
하지만, 열거타입끼리는 구현을 상속할 수 없다는 점을 인지하고 있어야 한다. 디폴트 메서드는 안되고 인터페이스를 구현하는 열거타입 모두에 정의된 메서드가 들어가야 한다.
예제처럼 짧은경우에는 문제가 없지만, 규모가 커지고 공유하는 기능이 많아질수록 이 부분을 별도의 도우미 클래스나 정적 도우미 메서드로 분리하는 방식으로 코드 중복을 없앨 수 있다.
39. 명명 패턴보다 애너테이션을 사용하라.
명명 패턴의 단점
//JUnit3 시절 명명패턴을 사용하는 테스트 메서드
public class TestWorld extends TestCase {
//메소드명의 접두사에 반드시 'test'가 붙어야 한다.
public void testSafetyOverride(){
//...
}
}
Java
복사
•
오타에 취약하다.
⇒ Ex: 테스트 프레임워크 JUnit 3에서는 테스트메서드명을 test로 시작하게 했는데, 실수로 이름을 testSafeOverride가 아니라 tsetSafeOverride로 지어버리면 이 메서드를 무시해버린다.
•
올바른 프래그램 요소에서만 사용되리라 보증할 방법이 없다.
⇒ 메서드가 아닌 클래스명을 TestSafeMechanisms으로 지어 내부의 메서드를 테스트하길 기대할 수 있지만 JUnit은 클래스 이름에는 관심이 없기에 모두 무시해버린다.
•
프로그램 요소를 매개변수로 전달할 마땅한 방법이 없다.
⇒ 특정 예외를 던져야 성공하는 테스트가 있다고 할 때 기대하는 예외 타입을 테스트에 매개변수로 전달해야하는데 방법이 마땅히 없다.
대안책 - 애너테이션
JUnit4 에서 본격적으로 도입된 애너테이션은 명명패턴의 단점을 해결해주는 대안책이다.
이러한 애너테이션의 구조와 이를 사용한 테스트코드를 작성해보며 명명패턴의 단점을 어떻게 보완하는지 살펴보자.
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface CatsbiTest {
}
Java
복사
마커(marker) 애너테이션 타입 선언
•
애너테이션 선언데 작성된 애너테이션(@Target, @Retention, ...)을 메타 애너테이션(meta-annotation)이라 한다.
•
@Retention(RetentionPolicy.RUNTIME)
⇒이 애너테이션이 런타임에도 유지되야 한다는 의미다.
•
@Target({ ElementType.ANNOTATION_TYPE, ElementType.METHOD })
⇒ 이 애너테이션이 애노테이션 타입의 메타 애너테이션이나 메소드에 사용할 수 있다는 의미
//JUnit4 부터 사용되는 애노테이션 기반 테스트 메서드
public class Sample{
@CatsbiTest public static void m1(){ } //성공해야 한다.
public static void m2() { }
@CatsbiTest public static void m3() { //실패해야 한다.
throw new RuntimeException("실패");
}
@CatsbiTest public void m5(){ } //정적 메서드가 아니다.
public static void m6(){ }
@CatsbiTest public static void m7(){ //실패해야 한다.
throw new RuntimeException("실패");
}
public static void m8(){ }
}
Java
복사
마커 애너테이션을 사용한 예
•
@Test 애노테이션 붙지 않은 m2, m6, m8 메서드는 무시된다.
•
m5 메서드는 정적 메서드가 아니라 인스턴스 메서드이기에 @Test를 잘못 사용했다.
•
m3, m7은 예외를 던지기에 실패한다.
Sample 클래스에 @Test 애너테이션을 통해 성공하는 메서드, 실패하는메서드, 무시되는 메서드까지 작성을 해봤다. 명명패턴과는 다르게 메서드명을 어떻게 작성하던 @Test 애너테이션을 붙혀주면 테스트 대상이된다. 애너테이션을 실수로 @Tset이라 오타를 낸다 하더라도 컴파일러에서 에러를 잡아주기에 오타로인한 실수도 없다.
@Test 애너테이션이 코드에 직접적인 영향을 주진 않는다. 다만, 이 애너테이션에 관심있는 프로그램에게 추가 정보를 제공할 뿐이다.
즉, 애너테이션이 사용된 코드를 그대로 둔 채 이 애너테이션에 관심있어하는 도구에서 특별한 처리를 할 기회를 준다는 것이다. 다음의 RunTests가 그 예다.
public class RunTests {
public static void main(String[] args) throws Exception {
int tests = 0;
int passed = 0;
Class<?> testClass = Class.forName("me.catsbi.effectivejavastudy.chapter5.item39.Sample");
for (Method m : testClass.getDeclaredMethods()) {
if (m.isAnnotationPresent(CatsbiTest.class)) {
tests++;
try {
m.invoke(null);
passed++;
} catch (InvocationTargetException wrappedExc) {
Throwable exc = wrappedExc.getCause();
System.out.println(m + " 실패: " + exc);
} catch (Exception exc) {
System.out.println("잘못 사용한 @Test: " + m);
}
}
}
System.out.printf("성공: %d, 실패: %d%n", passed, tests-passed);
}
}
Java
복사
•
[실행 결과]

•
Class.forName메서드로 Sample 클래스의 정보를 비한정적 와일드카드 타입의 testClass로 가져온다.
•
getDeclaredMethods메서드로 testClass에 정의된 모든 메서드 정보를 향상된 for문으로 반복한다.
•
반복 요소인 메서드정보 m이 isAnnotationPresent메서드로 CatsbiTest 애너테이션이 붙어있는지 확인하여 테스트를 실행한다.
•
테스트 메서드가 예외를 던지면 리플렉션 메커니즘이 InvocationTargetExcxeption으로 감싸 다시 던진다.
⇒ 이 메서드에서는 던져진 InvocationTargetException안에 담긴 원래 예외를 getCause메서드로 추출해 출력한다.
이 코드는 정상적으로 동작하지만 테스트의 목적에는 성공뿐아니라 예외를 의도하는 테스트도 있을 수 있다. 이를 테스트 하기위해서는 이 코드로는 부족하다. 다음 코드를 보자!
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface ExceptionTest {
Class<? extends Throwable> value();
}
Java
복사
매개변수를 하나 받는 애너테이션 타입
•
특정 예외를 던져야만 성공하는 테스트를 만들기 위해 @ExceptionTest 애노테이션을 만들었다.
•
타입이 Class<? extends Throwable>인 매개변수를 가진다.
public class Sample2 {
@ExceptionTest(ArithmeticException.class)
public static void m1() {
int i = 0;
i = i / i;
}
@ExceptionTest(ArithmeticException.class)
public static void m2() {
int[] ints = new int[0];
int i = ints[0];
}
@ExceptionTest(ArithmeticException.class)
public static void m3() {}
}
Java
복사
매개변수 하나짜리 애너테이션(ExceptionTest)를 사용한 코드
int tests = 0;
int passed = 0;
Class<?> testClass = Class.forName("me.catsbi.effectivejavastudy.chapter5.item39.Sample2");
for (Method m : testClass.getDeclaredMethods()) {
if (m.isAnnotationPresent(ExceptionTest.class)) {
tests++;
try {
m.invoke(null);
System.out.printf("테스트 %s 실패: 예외를 던지지 않음%n", m);
} catch (InvocationTargetException wrappedExc) {
Throwable exc = wrappedExc.getCause();
Class<? extends Throwable> excType = m.getAnnotation(ExceptionTest.class).value();
if (excType.isInstance(exc)) {
passed++;
} else {
System.out.printf("테스트 %s 실패: 기대한 예외 %s, 발생한 예외 %s%n", m, excType.getName(), exc);
}
} catch (Exception exc) {
System.out.println("잘못 사용한 @ExceptionTest: " + m);
}
}
}
System.out.printf("성공: %d, 실패: %d%n", passed, tests-passed);
Java
복사
•
기존에 작성한 RunTests와 유사하지만, 실패 테스트이기에 catch문에 필요한 로직이 작성된다.
•
m.getAnnotation(ExceptionTest.class).value()
⇒ 메서드에 붙은 @ExceptionTest 애너테이션에 작성된 매개변수값을 반환한다.
⇒ 만약 @ExceptionTest(RuntimeException.class)라면 반환값은 RuntimeException이 된다.
•
해당 예외의 클래스파일이 컴파일타임엔 존재하나 런타임에는 존재하지 않을 수 있다.
⇒ 이 경우 테스트 러너가 TypeNotPresentException을 던진다.
만약 예외가 하나가 아닌 여러개라면?
매개변수가 하나인 애노테이션 value에 대해 학습을 해보았다.
그럼 매개변수가 단수가 아닌 복수로 선언되어 매개변수들 중에서 하나가 발생하면 성공하도록 하려면 어떻게 해야할까? 애너테이션 메커니즘에는 이를 대처하는 방법들이 있는데 크게 두 가지에 대해 알아보자.
1.
배열을 사용하기
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface ExceptionTests{
Class<? extends Throwable>[] value();
}
Java
복사
배열 매개변수를 받는 애너테이션 타입
•
단일 원소 배열에 최적화했지만 앞서 작성했던 @ExceptionTest(RuntimeException.calss)처럼 기존의 단일 매개변수 선언도 수정없이 모두 수용이 된다.
배열 매개변수를 받는 애너테이션 문법은 아주 유연해서 사용하기도 아주 편하다.
@ExceptionTests({IndexOutOfBoundsException.class, NullPointerException.class})
public static void doublyBad() {
List<String> list = new ArrayList<>();
/**
* 자바 API 명세에 따르면 다음 메서드는 IndexOutOfBoundsException나
* NullPointerException를 던질 수 있다.
*/
list.addAll(5, null);
}
Java
복사
int tests = 0;
int passed = 0;
Class<?> testClass = Class.forName("me.catsbi.effectivejavastudy.chapter5.item39.Sample3");
for (Method m : testClass.getDeclaredMethods()) {
if (m.isAnnotationPresent(ExceptionTests.class)) {
tests++;
try {
m.invoke(null);
System.out.printf("테스트 %s 실패: 예외를 던지지 않음%n", m);
} catch (InvocationTargetException wrappedExc) {
Throwable exc = wrappedExc.getCause();
int oldPassed = passed;
Class<? extends Throwable>[] excTypes = m.getAnnotation(ExceptionTests.class).value();
for (Class<? extends Throwable> excType : excTypes) {
if (excType.isInstance(exc)) {
passed++;
break;
}
}
if (passed == oldPassed) {
System.out.printf("테스트 %s 실패: %s %n", m, exc);
}
} catch (Exception exc) {
System.out.println("잘못 사용한 @ExceptionTest: " + m);
}
}
}
System.out.printf("성공: %d, 실패: %d%n", passed, tests-passed);
Java
복사
•
m.getAnnotation(ExceptionTests.class).value()
⇒ 반환값이 단일 원소가 아닌 배열이기에 이를 반복문으로 순회하며 예외가 일치하는지 확인한다.
2.
@Repeatable 메타 애너테이션을 활용하는 방법
•
여러 개의 값을 받는 방법으로는 배열 매개변수 뿐 아니라 @Repeatable 메타애너테이션을 다는 방식도 있다.
•
@Repeatable 애너테이션을 단 애너테이션은 하나의 프로그램 요소에 여러 번 달수도 있다.
•
사용하기 위해선 애너테이션을 반환하는 컨테이너 애너테이션을 하나 더 정의하고 @Repeatable에 이 컨테이너 애너테이션의 클래스 객체를 전달해야 한다.
•
컨테이너 애너테이션은 내부 애너테이션 타입의 배열을 반환하는 value 메서드를 정의해야 한다.
•
적절한 보존정책(@Retention)과 적용 대상(@Target)을 명시해야 한다.
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@Repeatable(ExceptionTestContainer.class)
public @interface ExceptionTest {
Class<? extends Throwable> value();
}
Java
복사
@Repeatable 애너테이션으로 반복 가능한 애너테이션 타입
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface ExceptionTestContainer {
ExceptionTest[] value();
}
Java
복사
컨테이너 애너테이션
이제 이렇게 선언한 애너테이션을 활용해 위에서 작성한 doublyBad()메서드의 애너테이션을 고쳐보자.
@ExceptionTest(IndexOutOfBoundsException.class)
@ExceptionTest(NullPointerException.class)
public static void doublyBad() {
List<String> list = new ArrayList<>();
list.addAll(5, null);
}
Java
복사
반복 가능 애너테이션을 두 번 단 코드
이렇게 작성을 해도 문제없이 컴파일되지만 주의점이 있으며 다음과 같다.
•
반복 가능 애너테이션을 여러 개 달면 하나만 달았을 때와 구분하기 위해 해당 컨테이너 애너테이션 타입이 적용된다.
•
getAnnotationByType메서드는 이 둘을 구분하지 않기 때문에 반복 가능 애너테이션과 컨테이너 애너테이션을 모두 가져오지만, isAnnotationPresent 메서드는 둘을 구분하기에 이전과 같이 단순히 isAnnotationPresent로 반복 가능 애너테이션이 달렸는지 검사하면 의도와 다른 결과를 반환하다.
•
구분없이 모두 검사하기위해서는 둘을 따로따로 확인해야한다.
//before
if (m.isAnnotationPresent(ExceptionTest.class)) {
//...
}
//after
if (m.isAnnotationPresent(ExceptionTest.class)
|| m.isAnnotationPresent(ExceptionTestContainer.class)){
//....
}
Java
복사
정리
•
애너테이션이 나온이상 절대다수의 상황에서 명명패턴보다 애너테이션 활용이 유리하다.
•
명명패턴의 제약사항들을 애너테이션은 모두 해결해준다.
(오타문제, 의도와 다른 사용, 매개변수에 대한 유연함)
40. @Override 애너테이션을 일관되게 사용하라
개요
public class Food {
//,,,
@Override
public boolean equals(Object o) {
//...
}
@Override
public int hashCode() {
//...
}
}
Java
복사
Object의 equals, hashCode 메서드를 재정의하는 코드
Ide를 사용해 개발을 하다보면 누구나 한 번이상은 봤을 애너테이션이 @Override 애너테이션이다. 이 애너테이션은 메서드 선언에만 달 수 있고 상위 타입의 메서드를 재정의 했음을 알려주는 애너테이션이다. 자동으로 붙는 경우가 많고 없을때도 대체적으로 잘 동작하기에 유의미한 효과를 아는 사람이 생각보다 많지는 않다.
이 애너테이션을 일관되게 사용하면 여러 버그들을 예방할 수 있다.
그럼 실제로 코드를 작성해보면서 @Override 애너테이션의 효과를 살펴보자.
문제 발생 코드
영어 알파벳 2개로 구성된 문자열 클래스인 Bigram 코드를 다음과 같이 작성을 했다.
public class Bigram {
private final char first;
private final char second;
public Bigram(char first, char second) {
this.first = first;
this.second = second;
}
public boolean equals(Bigram b) {
return b.first == first && b.second == second;
}
public int hashCode() {
return 31 * first + second;
}
}
Java
복사
public static void main(String[] args) {
Set<Bigram> s = new HashSet<>();
for (int i = 0; i < 10; i++) {
for (char ch = 'a'; ch <= 'z'; ch++) {
s.add(new Bigram(ch, ch));
}
}
System.out.println("s.size() = " + s.size());
}
Java
복사
이 메인 로직의 실행결과를 어떻게 예상하는가? 코드를 적당히 훑고 생각을 한다면 a부터 z까지 26개의 알파벳을 소문자 두 개로 구성된 바이그램 클래스를 Set에 10번 반복해 추가하였다.
하지만, Set은 중복을 허용하지 않기 때문에 Bigram(a,a), Bigram(b,b), ..., Bigram(z,z)까지 26개만 있어야 하니 size메서드의 결과로 26을 기대할 수 있다.
하지만 실행결과는? 다음과 같다.
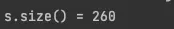
중복을 허용하지 않는데 어째서 260개가 그대로 다 들어간것일까?
Set은 중복을 허용하지 않기위해 Object객체에서 선언한 equals, hashCode를 이용한다.
그리고 우리가 볼때 Bigram은 두 메서드도 구현을 해놨다. 그런데 어째서 제대로 동작을 안한 것일까?
이유는 위에 작성한 Bigram의 equals는 오버라이딩이아니라 오버로딩이기 때문이다!
Object의 equals 메서드는 매개변수로 Object 타입을 받는다. 즉 Bigram의 equals는 매개변수 타입이 다르기 때문에 이는 재정의가 아닌 다중정의가 된 것이고 Set에서는 Object의 equals를 사용했는데 해당 로직은 객체 식별성(identity)만을 비교하기에 모두 다른 객체로 인식한 것이다.
@Override 애너테이션 활용
Bigram 클래스의 equals에 @Override 애너테이션을 붙히고 다시 실행해보자.
public class Bigram {
//...
@Override
public boolean equals(Bigram b) {
return b.first == first && b.second == second;
}
}
Java
복사
컴파일러는 다음과 같이 컴파일 오류를 발생시킬 것이다.
java: method does not override or implement a method from a supertype
위치도 정확히 알려주기에 우린 바로 문제를 파악할 수 있고 올바르게 고칠 수 있다.
public class Bigram {
private final char first;
private final char second;
public Bigram(char first, char second) {
this.first = first;
this.second = second;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Bigram)) return false;
Bigram bigram = (Bigram) o;
return first == bigram.first && second == bigram.second;
}
@Override
public int hashCode() {
return Objects.hash(first, second);
}
}
Java
복사
이제 문제없이 동작하고 실행결과도 의도한대로 26이 나올 것이다.
그러니 상위 클래스의 메서드를 재정의하려는 모든 메서드에 @Override 애너테이션을 달자.
다만, 구체 클래스에서 상위 클래스의 추상 메서드를 재정의하는 경우에는 재정의가 강제되기 때문에 굳이 @Override 애너테이션을 달아주지 않아도 무관하다.
정리
•
@Override 애너테이션은 우리가 할 수 있는 실수를 컴파일러에서 바로 알려줄 수 있다.
◦
실수로 메서드명을 다르게하거나 반환타입을 다르게하거나 매개변수를 다르게 해 오버라이딩이 아닌 오버로딩을 할 수 있다.
•
구체클래스에서 상위 클래스의 추상 메서드를 재정의하는 경우에는 애너테이션을 달지 않아도 된다.
⇒ 붙혀준다고해서 문제될 것도 없다!
41. 정의하려는 것이 타입이라면 마커 인터페이스를 사용하라
Previous
마커 인터페이스(Marker interface)
: 아무 메서드도 담고 있지 않고, 단지 자신을 구현하는 클래스가 특정 속성을 가지는 것을 표시해주는 인터페이스
(Ex: Serializable Interface는 자신의 구현체 인스턴스가 직렬화 할 수 있음을 알려준다.)
마커 인터페이스가 마커 애너테이션보다 나은 점
마커 애너테이션(Marker Annotation)이 등장하면서 마커 인터페이스를 대체할 수 있을꺼라 생각하지만, 마커 인터페이스는 다음 두 가지 면에서 마커 애너테이션보다 낫다.
1.
마커 인터페이스는 구현체 인터페이스를 구분하는 타입으로 쓸 수 있지만, 마커 애너테이션은 불가능하다.
: 마커 인터페이스는 하나의 타입이기에 컴파일 시점에서 오류를 발견할 수 있다. 하지만 마커 애너테이션은 런타임에야 발견할 수 있다. 예를들어 개발자가 인수로 Serializable 인터페이스의 구현체를 받아서 직렬화를 해야할 필요가 있다면 매개변수로 write(Serializable s){ ... } 를 구현하면 직렬화의 구현체가 아닌 객체는 전달할 수 없고 컴파일 단계에서 에러를 발견할 수 있다. 하지만. Object타입으로 인수를 받되 마커 애너테이션으로 직렬화 여부를 판단해야한다면 런타임에야 문제를 확인할 수 도 있다.
2.
적용 대상을 더 정밀하게 지정할 수 있다.
: 마커 애너테이션에서는 적용 대상(@Target)을 ElementType.TYPE으로 지정할 수 있다.
클래스, 인터페이스, 열거 타입, 애너테이션에 달 수 있는데 이 말은 이 이상의 더 세밀하게 제한은 할 수 없음을 의미한다. 만약 특정 인터페이스를 구현한 구현체만 매개변수로 받고싶다고 하면 이를 사용(마킹)하고싶은 클래스에서만 인터페이스를 구현하여 전달하면된다.
하지만, 애너테이션의 경우 이런 세밀한 지정은 힘들다.
마커 애너테이션이 마커 인터페이스보다 나은 점
1.
거대한 애너테이션 시스템의 지원을 받고있다.
:이 경우 애너테이션을 적극적으로 활용하는 프레임워크에서는 마커 애너테이션을 사용하는게 일관성을 지킬 수 있다.
그럼 언제 무엇을 써야하는가?
•
클래스와 인터페이스외의 프로그램 요소는 마킹이 필요한 경우 애너테이션을 쓸 수밖에 없다.
•
클래스나 인터페이스는 마킹이 필요할 때 이 객체를 매개변수로 받는 메서드를 쓸 일이 있을까 고민하자.
◦
(Yes 라면) 마커 인터페이스를 사용함으로써 컴파일 타임에 오류를 잡아낼 수 있다.
◦
(No 라면) 마커 애너테이션을 선택해서 일관성을 지킬 수 있다.

