
목차
개요

왜 코틀린을 사용하려고 하나요?
익숙한 자바, 자바스크립트, C++등을 제치고 새로 나온 코틀린을 써야 하는 이유를 설득해야 한다.
가장 자주 활용되는 이유로는 안정성(safety)이 있다.
•
애플리케이션이 갑자기 종료되고
•
장바구니에 넣은 제품들이 결제가 안되는
여러 상황들을 직접 얘기하지 않아도 안전성이 중요하다는 사실은 모두 인지하고 있다.
코틀린은 기존 언어들보다 많이 안전해진 언어지만, 그럼에도 더 안전하게 사용하기 위해서는 개발자가 적절하게 사용을 해줘야 한다. 이번 장에서는 코틀린을 안전하게 사용하기 위한 방법들에 대해 알아보자.
1. 가변성을 제한하라
객체는 상태(state)를 가질 수 있다.
그리고 이런 상태는 바뀔 수도 있는데 보통 이렇게 바뀔 수 있는 상태는 var를 사용하거나 mutable객체를 사용하면 된다.
var a = 10
var list: MutableList<Int> = mutableListOf()
Kotlin
복사
이처럼 변할 수 있는 상태를 가진다는 건 유용하지만 관리의 어려움이 생각보다 높다.
무엇이 어려운가?
1.
디버깅의 어려움
: 상태를 갖는 부분들의 관계를 이해해야 하고, 상태 변경이 잦을수록 이를 추적하는건 어려워 질 수 밖에 없다. 또한 변경이 잦고 여러 클라이언트가 상태를 변경할 수 있다면 예상하지 못한 상황에 오류를 발생시킬 수도 있다.
2.
추론의 어려움
: 상태가 가변(mutability)이라면 코드의 실행을 추론하기 어려워진다.
시점에 따라 값이 달라질 수 있어, 현재 어떤 값을 가지는가에 따라 코드의 실행을 예측할 수 있다. 심지어 이 값이 계속 동일하게 유지된다고 보장 할 수도 없다.
3.
동시성의 어려움
: 멀티스레드 환경에서는 변경이 일어나는 모든 부분에서 충돌이 가능하기 때문에 적절한 동기화를 고려해야 한다.
4.
테스트의 어려움
: 테스트하기 어렵다. 모든 상태를 테스트해야 하기에 변경이 많을수록 더 많은 조합을 테스트 해야 한다.
5.
변경 알림의 어려움
: 상태 변경으로 인해 해당 값을 의존하는 영역에 알려줘야 하는 경우도 있다. 만약, 변경 가능한 상태가 이름(Name)이고, 이 요소를 가지는 컬렉션이 이름순으로 정렬을 했다면 이름이 변경되었을 때마다 재 정렬이 되야 한다.
말로만 하는 것보다 코드를 통해 살펴보자.
val num = 0
for (i in 1..1000) {
thread {
Thread.sleep(10)
num += 1
}
}
Thread.sleep(5000)
println(num)
// 1000이 아닐 확률이 높고
// 매번 다른 결과를 출력한다.
Kotlin
복사
suspend fun main() {
var num = 0
coroutineScope {
for (i in 1..1000) {
launch {
delay(10)
num += 1
}
}
}
println(num)
}
Kotlin
복사
좌측은 멀티 스레드를 활용해 프로퍼티를 수정하는 코드로 스레드간 충돌에 의해 일부 연산이 제대로 수행되지 않아 의도하지 않은 결과가 출력될 것이고,
우측의 코루틴을 활용한 코드 역시 충돌이 줄어들 순 있지만, 문제가 사라지는 것은 아니다.
그렇기에 추가적으로 동기화를 구현해줘야 한다.
fun main() {
val lock = Any()
var num = 0
for (i in 1..1000) {
thread {
Thread.sleep(10)
synchronized(lock) {
num += 1
}
}
}
Thread.sleep(1000)
println(num)
}
Kotlin
복사
가변성은 시스템의 상태를 나타내기에 중요한 요소로 아예 없애기는 요원하다.
하지만, 변경이 일어나야 하는 부분을 최소화하여 결정하고 사용해서, 관리의 어려움을 조금이나마 덜 필요가 있다.
코틀린에서 가변성 제한하기
코틀린의 객체 설계는 기본적으로 불변(immutable)하기 쉽게 설계되어 있다.
그렇기에 불변 객체, 프로퍼티 변경 막기등이 상당히 쉬운편이다.
이 중에서 자주 사용되는 방식들은
•
읽기 전용 프로퍼티(val)
•
가변 컬렉션과 읽기 전용 컬렉션 구분하기
•
데이터 클래스의 copy
가 있다.
읽기 전용 프로퍼티(val)
프로퍼티에 val 키워드를 통해 읽기 전용으로 만들 수 있는데, 이렇게 선언된 프로퍼틴 값(value)처럼 동작하며, 기본적으로 불변으로 동작한다.
val a = 10
a = 20 //Error
Kotlin
복사
물론, 읽기 전용 변경 가능한 객체(mutable object)일 경우 참조 주소는 변하지 않지만 내부 정보가 바뀔 수 있다.
val list = mutableListOf(1,2,3)
list.add(4)
println(list.size) // 4
Kotlin
복사
읽기 전용 프로퍼티는 다른 프로퍼티를 활용하는 사용자 정의 게터로도 정의 할 수 있다.
var firstName: String = "한솔"
var lastName: String = "이"
val fullName
get() = "$lastName $firstName"
Kotlin
복사
코틀린의 프로퍼티는 기본적으로 캡슐화되어 있고, 추가적으로 이런 사용자 정의 접근자(getter,setter)를 가지는데 이 특성덕분에 API를 유연하게 정의하거나 변경할 수 있다.
또한, 읽기 전용 프로퍼티는 getter 또는 delegate로 정의할 수 있는데, 어떻게 정의하냐에 따라 스마트 캐스트(smart-cast)기능을 사용할 수 있기도 하다.
val firstName: String? = "한솔"
val lastName: String = "이"
val fullName: String?
get() = firstName?.let {"$it $lastName"}
val fullName2: String? = firstName?.let {"$it $lastName"}
fun main() {
if(fullName != null) {
println(fullName.length)
//Smart cast to 'String' is impossible, because 'fullName' is a property
//that has open or custom getter
}
if (fullName2 != null) {
println(fullName2.length)
}
}
Kotlin
복사
println(fullName.length) 에서는 스마트 캐스트 시도시 컴파일 에러가 발생하는데, 이는 게터를 활용하기에 값을 사용하는 시점의 name에 따라 다른 결과가 나올 수 있기 때문이다.
가변 컬렉션과 읽기 전용 컬렉션 구분하기
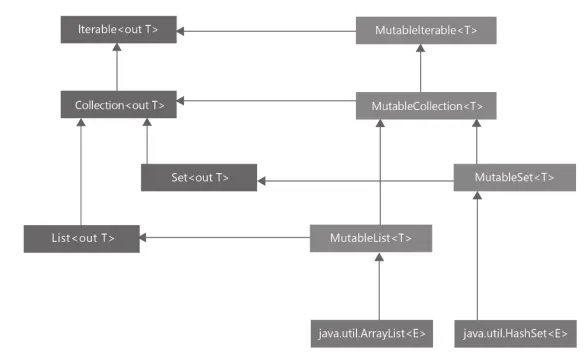
코틀린의 컬렉션 인터페이스 계층
코틀린의 컬렉션은 변경 가능 컬렉션과 읽기 전용 컬렉션으로 구분된다.
읽기 전용 컬렉션은 아예 변경을 위한 메서드를 따로 제공하지도 않는다. 하지만, 그렇다고 읽기 전용 컬렉션이 내부의 값을 변경할 수 없다는 의미는 아니다.
fun main() {
val immutableList = listOf(1, 2, 3, 4, 5)
val convertedList = immutableList.map { it + 1 }
println("convertedList = ${convertedList}")
//convertedList = [2, 3, 4, 5, 6]
}
Kotlin
복사
당장 위 코드만 봐도 map을 통해 내부 값이 변경된 것을 확인 할 수 있다.
이렇게 불변 객체임에도 변경이 가능한건 내부적으로 실제 원소를 위 변조한게 아닌 새로운 List를 만들어 반환했기 때문이다. Iterable<T>.map의 내부 로직은 다음과 같다.
public inline fun <T, R> Iterable<T>.map(transform: (T) -> R): List<R> {
return mapTo(ArrayList<R>(collectionSizeOrDefault(10)), transform)
}
public inline fun <T, R, C : MutableCollection<in R>> Iterable<T>.mapTo(destination: C, transform: (T) -> R): C {
for (item in this)
destination.add(transform(item))
return destination
}
Kotlin
복사
map 함수를 잘 보면 반환하는 타입 구현체가 ArrayList인 것을 볼 수 있다.
즉, 코틀린이 불변하지 않은 컬렉션을 외부적으로 불변하게 보이게 만든다는 것인데, 이런 방식 덕분에 안전성을 확보할 수 있게 된다.
그런데, 개발자가 다운캐스팅을 시도하는 경우가 있는데, 이는 허용해선 안되는 문제이다.
val list = listOf(1, 2, 3, 4, 5)
//해선 안되는 다운 캐스팅
if(list is MutableList) {
list.add(4)
}
Kotlin
복사
위와 같은 컬렉션 다운캐스팅 로직은 규약 위반이자, 추상화를 무시하는 행위라고 볼 수 있다.
그렇기에 안전하지도 않다. 그렇기에 코틀린에서 읽기 전용 컬렉션을 변경 가능한 컬렉션으로 변경해야 한다면 toMutableList를 활용하도록 하자.
val list = listOf(1, 2, 3, 4, 5)
val mutableList = list.toMutableList()
mutableList.add(4)
Kotlin
복사
데이터 클래스의 copy
객체가 mutable할 경우 무엇보다 예측하기 어렵고 위험하다는 단점이 있다.
다음 코드를 보자.
class FullName(var first: String, var second: String) : Comparable<FullName> {
private val name: String
get() = "$first $second"
override fun compareTo(other: FullName): Int = name.compareTo(other.name)
override fun toString(): String {
return "FullName(name='$name')"
}
}
fun main() {
val names: SortedSet<FullName> = TreeSet()
val person = FullName("AAA", "AAA")
names.add(person)
names.add(FullName("ONE", "TWO"))
names.add(FullName("THREE", "FOUR"))
println(names)
//[FullName(name='AAA AAA'), FullName(name='ONE TWO'), FullName(name='THREE FOUR')]
println(person in names) // true
person.first = "ZZZ"
println(names)
//[FullName(name='ZZZ AAA'), FullName(name='ONE TWO'), FullName(name='THREE FOUR')]
println(person in names) // false
}
Kotlin
복사
person의 속성을 변경한 이후 person in names 로직이 false를 반환하는 것을 볼 수 있다. 이는
set이나 map이 내부적으로 해시 테이블을 사용하는데, 해시 테이블은 처음 요소를 넣을 때 요소의 값을 기반으로 버킷을 결정하기 때문에, 나중에 요소에 변경이 있으면, 요소를 찾을 수 없게 되버리는 것이다. ( 해당 내용은 Item 14 hashCode 규약을 지켜라에서 자세히 살펴본다.)
하지만 불변 객체(immutable)객체는 변경할 수 없다는 단점이 있기 때문에 자신의 일부를 변경한 새로운 객체를 만들어내는 메서드를 가져야 한다.
class User( val name: String, val surname: String) {
fun withSurname(surname: String) = User(name, surname)
}
var user = User("lee", "hansol")
user = user.withSurname("catsbi")
println(user)//User(name=lee, surname=catsbi)
Kotlin
복사
이런 메서드를 매 번 새로 만드는 것이 귀찮다면 data한정자를 이용하면 copy 메서드를 자동으로 구현해주고 copy 메서드를 활용해 모든 기본 생성자 프로퍼티가 동일한 새로운 객체를 만들어 낼 수 있다.
data class User( val name: String, val surname: String) {
fun withSurname(surname: String) = User(name, surname)
}
var user = User("lee", "hansol")
user = user.copy(surname="catsbi")
println(user)//User(name=lee, surname=catsbi)
Kotlin
복사
다른 종류의 변경 가능 지점
변경할 수 있는 리스트를 만들어야 한다고 하면 다음과 같이 두 가지 선택지가 있다.
val list1: MutableList<Int> = mutableListOf()
var list2: List<Int> = listOf()
list1.add(1)
list2 = list2 + 1
list1 += 1 //list1.plusAssign(1)
list2 += 1 //list2 = list2.plus(1)
Kotlin
복사
두 방법 모두 정상 동작하지만 각각 장단점이 존재한다.
두 방법 모두 변경 가능 지점(mutating point)가 존재하지만, 위치가 다르다. 첫 번째는 구체적인 리스트 구현 내부에 변경 가능 지점이 존재한다. 그렇기에 내부적으로 적절한 동기화가 되어 있는지 확신할 수 없기 위험하다.
두 번째 방법은 프로퍼티 자체가 변경 가능 지점으로 멀티스레드 안전성은 더 높다고 볼 수 있다.
그리고 mutable property를 사용하면 변경 추적을 할 수 있다. 예를 들어 Delegates.observable을 사용해 변경 시점을 출력할 수 있다.
var names by Delegates.observable(listOf<String>()) {_, old, new ->
println("Names changed from $old to $new")
}
fun main() {
names += "One"
names += "Two"
//Names changed from [] to [One]
//Names changed from [One] to [One, Two]
}
Kotlin
복사
mutable 컬렉션에서 이처럼 관찰(observe)하도록 하려면, 추가 구현이 필요하기에 mutable property에 읽기 전용 컬렉션을 넣어 사용하는게 편하다. 이렇게 하면 객체를 변경하는 여러 메서드 대신 setter를 사용하면 되고, private하게 만들어줄 수도 있다.
var announcements = listOf<Announcedment>()
private set
Kotlin
복사
mutable collection을 사용하는게 더 간단해보이지만, 실제로는 mutable property를 사용하는게 객체 변경 제어에 더 용이하다.
참고로 두 방식을 섞는 방식은 변경될 수 있는 두 지점 모두 동기화를 구현해야 하고, 또한 모호성이 발생해 +=를 사용할 수 없게 된다.
var list3 = mutableListOf<Int>() // bad case
Kotlin
복사
변경 가능 지점 노출하지 않기
상태를 나타내는 mutable 객체를 외부에 노출하는건 아주 위험하다.
언제 어디서 객체의 정보를 마음대로 위변조 할 지 알 수 없다. 그렇기에 이를 방지할 두 가지 방법을 고려하도록 하자.
1.
방어적 복제(defensive copying)
class UserHolder {
private val user: MutableUser()
fun get(): MutableUser {
return user.copy()
}
}
Kotlin
복사
2.
가변성 제한
data class User(val name: String)
class UserRepository{
private val storedUsers: MutableMap<Int, String> =
mutableMapOf()
fun loadAll(): Map<Int,String> = storedUsers
}
Kotlin
복사
읽기 전용 슈퍼타입으로 업캐스트해 가변성을 제한한다.
정리
•
var보단 val을 사용하는게 좋다.
•
mutable property보단 immutable property를 사용하는게 좋다.
•
mutable 객체와 클래스보단 immutable 객체와 클래스를 사용하는게 좋다.
•
변경이 필요하다면 immutable data class로 만들고 copy를 활용하자.
•
컬렉션에 상태를 저장해야 한다면, mutable 컬렉션 보단 읽기 전용 컬렉션을 사용하자.
•
변경 지점을 적절히 설계하고, 불필요한 변경 지점을 만들지 않는게 좋다.
•
mutable 객체를 외부에 노출하지 않는게 좋다.
2. 변수의 스코프를 최소화하라
요소의 스코프는 요소를 볼 수 있는(visible) 컴퓨터 프로그램 영역이다.
즉, 변수를 볼 수 있는 범위를 최소화 하라는 의미라고 볼 수 있다. 어째서일까? 보기 힘들면 로직을 작성하기도 힘들지 않을까?
코틀린에서 스코프는 기본적으로 중괄호{}로 만들어지며, 내부 스코프에서 외부 스코프에 있는 요소에만 접근할 수 있다.
val a = 1
fun fizz() {
val b = 2
print(a + b)
}
val buss = {
val c = 3
print(a + c)
}
//이 위치에서는 a를 사용할 수 있지만, b와 c는 사용할 수 없다.
Kotlin
복사
fizz와 buzz함수의 스코프에선 외부 스코프에 있는 변수에 접근할 수 있다.
하지만, 외부 스코프에서 내부 스코프에 정의된 변수(Ex: b, c)에는 접근할 수 없다.
다음 변수 스코프를 제한하는 세 종류의 코드를 보자.
//case 1
var user: User
for(i in users.indices) {
user = users[i]
print("User at $i is $user")
}
//case 2
for(i in users.indices) {
val user = users[i]
print("User at $i is $user")
}
//case 3
for((i, user) in users.withIndex()) {
print("User at $i is $user")
}
Kotlin
복사
위에서부터 아래로 갈수록 좋은 스코프 제한 방식이다. 그 이유에 대해 살펴보면
첫 번째 코드는 user라는 변수는 for 반복문 스코프 외부에서도 사용가능 하기 때문에 print()에 출력되는 결과가 의도치 않게 변경될 수 있다. 반면 case 2, 3은 user의 스코프를 반복문 내부로 제한한다.
여기에 추가적으로 case 2는 내부에 user를 할당하고 있는데, 이 내부에 새로운 스코프가 생성된다면 이 역시 마찮가지로 내부의 내부 스코프에서 참조 가능하기에 위험성은 존재한다. 마지막 3번째는 가장 좁은 스코프를 가진다.
이렇게 스코프를 좁게 만드는게 좋은 이유는 바로 프로그램 추적 및 관리가 쉬워지기 때문이다.
코드를 분석할 때는 어떤 시점에 어떤 요소가 있는지를 파악해야 하는데, 요소가 많아져서 변경될 수 있는 부분이 많다면, 프로그램을 이해하기 힘들어진다. 이는 우리가 immutable property를 선호하는 이유와 비슷하다.
변수는 정의 하는 시점에 초기화 되는게 좋다.
변수는 불변 여부와 상관없이 변수를 정의하는 시점에 초기화 되는 것이 가장 좋다.
if, when, try-catch, Elvis 표현식 등을 활용해 최대한 변수를 정의할 때 초기화 하는 게 좋다.
//bad case
val user: User
if(hasValue) {
user = getValue()
} else {
user = User()
}
//normal case
val user: User = if(hasValue) getValue() else User()
Kotlin
복사
여러 프로퍼티를 한 번에 설정해야 하는 경우에는 구조 분해 선언을 활용할 수 도 있다.
//bad case
fun updateWeather(degrees: Int) {
val description: String
val color: Int
if(degrees < 5) {
description = "cold"
color = Color.BLUE
} else if(degrees < 23) {
description = "mild"
color = Color.YELLOW
} else {
description = "hot"
color = Color.RED
}
//....
}
//good case
fun updateWeather(degrees: Int) {
val (description, color) = when {
degrees < 5 -> "cold" to Color.BLUE
degrees < 23 -> "mild" to Color.YELLOW
else -> "hot" to Color.RED
}
}
Kotlin
복사
desctructuring declaration
캡처링
val primes: Sequence<Int> = sequence {
var numbers = generateSequence(2) { it + 1 }
var prime: Int
while (true) {
prime = numbers.first()
yield(prime)
numbers = numbers.drop(1)
.filter { it % prime != 0 }
}
}
fun main() {
println(primes.take(10).toList())
}
Kotlin
복사
위 코드의 흐름은
1.
먼저 numbers 시퀀스에서 첫 번째 수(2)를 가져와서 prime 변수에 할당
2.
이 소수를 yield 함수를 통해 반환하고, take(10) 함수가 이 값을 수집
3.
이제 numbers 시퀀스에서 첫 번째 소수를 제거하고, 이 소수로 나누어떨어지는 수들을 필터링하여 시퀀스를 갱신
4.
이 과정을 소수 10개가 수집될 때까지 반복합니다. 이후 toList() 함수가 이 10개의 소수를 리스트로 변환하여 반환
그래서 예상되는 출력 결과는 다음과 같다.
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29]
Kotlin
복사
하지만, 실제로 실행시켜보면 결과는 다음과 같다.
[2, 3, 5, 6, 7, 8, 9, 10, 11, 12]
Kotlin
복사
이렇게 잘못된 결과가 출력된 이유는 prime이라는 변수를 캡처했기 때문이다.
반복문 내부에서 filter를 활용해 prime으로 나눌 수 있는 숫자를 필터링하는데, 시퀀스를 활용하기 때문에 필터링이 지연된다. 그렇기에 최종적인 prime 값으로만 필터링된 것이다.
prime이 2로 설정되어 있을 때 필터링된 4를 제외하면, drop만 동작하기에 그냥 연속된 숫자가 나오는 것이다. 이러한 문제 때문에 항상 잠재적인 캡처 문제를 주의해야 한다.
정리
•
여러 이유로 변수의 스코프는 좁게 만들어서 활용하는 것이 좋다.
•
var보단 val을 사용하는게 좋다.
•
람다에서 변수를 캡처한다는 점을 기억하자.
3. 최대한 플랫폼 타입을 사용하지 말라
Platform type: 다른 프로그래밍 언어에서 전달되어 nullable인지 아닌지 알 수 없는 타입
코틀린의 주요 기능 중 하나는 널 안정성(null-safety)이다. 그렇기에 자바에서 자주 발생하는 NPE(Null-Pointer Exception) 은 거의 보기 힘들다.
그런데 코틀린과 자바와 같은 프로그래밍 언어를 연결해서 사용할 경우에는 고려해야 할 부분들이 생긴다. 자바에 다음과 같은 메서드가 있다고 하자
public class JavaTest {
public String giveName() { ... }
}
//kotlin
fun main() {
val java = JavaTest()
val name : ? = java.giveName() // 무슨 타입인가?
}
Kotlin
복사
코틀린에서 givenName() 메서드를 사용할 경우 반환 타입을 어떻게 추론할 수 있을까?
@Nullable 애노테이션이 있다면 String?으로 추론할 수 있고, @NotNull 애노테이션이 있을 경우 String으로 추론할 수 있다.
하지만, 이런 애노테이션이 없다면 자바에선 모든 것이 nullable일 수 있기 때문에 nullable이라고 가정을 할 수도 있다. 하지만 어떤 메서드는 not null이 확실할수도 있기에 이런 경우 !! 를 이용해 단정을 나타낼 수 있다.
nullable 한 generic
자바 API에서 List<User>를 반환하는데 애노테이션이 따로 없는 경우,어떻게 다뤄야 할까?
우리는 User객체들이 널이 아니라는 것을 확인해야 한다.
public class UserRepo {
public List<User> getUsers() { .. }
}
val users: List<User> = UserRepo().users!!.filterNotNull()
Kotlin
복사
platform type
플랫폼 타입은 String!처럼 타입 이름 뒤에 ! 기호를 붙여 표기한다.
이러한 노테이션이 직접적으로 코드에 나타나진 않는 대신 다음과 같이 사용한다.
public class UserRepo {
public List<User> getUsers() { .. }
}
val repo = UserRepo()
val user1 = repo.user // user1의 타입은 User!
val user2: User = repo.user // user2의 타입은 User
val user3: User? = repo.user // user3의 타입은 User?
Kotlin
복사
이러한 코드를 사용할 수 있기에, 이전에 언급했던 문제들이 사라진다.
val users: List<User> = UserRepo().users
Kotlin
복사
하지만, null이 아니라고 판단한 값이 null일 수 있기에 여전히 위험하고, 플랫폼 타입을 사용할 때 주의를 기울여야 한다. 그렇기에 연결할 언어가 자바라면 가능한 @Nullable, @NotNull 애노테이션을 붙여서 사용하는게 좋다.
참고: 기타 지원 애노테이션
•
Jetbrain(org.jetbrains.annotations의 @Nullable, @NotNull)
•
Android(androidx.annotation, com.android.annotations, android,support.annotations의 @Nullable, @NonNull)
•
JSR-305(java.x.annotation의 @Nullable, @CheckForNull, @Nonnull)
•
JavaX(javax.annotation의 @Nullable, @CheckForNull, @Nonnull)
•
FindBugs(edu.umd.cs.findbugs.annotations의 @Nullable, @CheckForNull, @PossiblyNull, @NonNull)
•
ReactiveX(io.reactivex.annotions의 @Nullable, @NonNull)
•
Eclipse(org.eclipse.jdt.annotation의 @Nullable, @NonNull)
•
Lombok(lombok의 @NonNull)
4. inferred 타입으로 리턴하지 말라
코틀린은 타입 추론(type inference)을 강력하게 지원한다.
이런 타입 추론을 사용할 때 위험한 부분들이 있는데 이를 피하기 위해서 우선 기억할 점은
inferred 타입은 정확하게 우측 피연산자에 맞게 설정(추론)된다.
open class Animal
class Dog: Animal()
fun main() {
var animal = Zebra()
animal = Animal() // error: Type mismatch
}
Kotlin
복사
슈퍼 클래스나 인터페이스로 설정되지 않는다.
일반적으로는 타입을 명시적으로 지정(var animal: Animal)하는 방식으로 해결할 수 있지만, 직접 조작할 수 없는 라이브러리(or 모듈)는 이렇게 쉽게 해결할 수 없고, 그로 인해 문제가 생길 수 있다.
다음과 같은 CarFactory 인터페이스가 있다고 하자. 그리고 디폴트로 생성되는 자동차가 있다고 하자.
val DEFAULT_CAR: Car = Fiat126P()
interface CarFactory {
fun produce(): Car
}
Kotlin
복사
그런데 생각해보니 대부분의 자동차 공장에서 Fiat126을 생성하기에 이를 default하게 설정해줄 수 있다. 더하여 DEFAULT_CAR는 Car로 명시적으로 타입 지정이 되어있기에 함수의 리턴 타입도 제거해준다.
interface CarFactory {
fun produce() = DEFAULT_CAR
}
Kotlin
복사
여기까진 문제가 없다.
그런데 여기서 타입추론을 믿고 Car를 명시적으로 지정하지 않아도 된다고 판단해서 DEFAULT_CAR의 타입 명시도 제거해버린다면?
val DEFAULT_CAR = Fiat126P()
Kotlin
복사
언뜻 봐서는 문제가 안될 것 같다. 하지만 CarFactory에선 이제 Fiat126P외의 자동차를 생산할 수 없게 된다. 이런 문제가 외부 라이브러리라면 수정할 수도 없고 제작자에게 요청할 수 밖에 없다.
그렇기에 리턴 타입은 외부에서 확인할 수 있게 명시적으로 지정해주는 것이 좋다.
5. 예외를 활용해 코드에 제한을 걸어라
함수가 확실하게 동작해야 하는 형태가 있을 경우, 예외를 활용해 제한을 걸어주는게 좋다.
코틀린에서는 이렇게 동작에 제한을 걸 때 다음과 같은 방법들을 사용할 수 있다.
•
require: argument를 제한할 수 있다.
•
check: 상태와 관련된 동작을 제한할 수 있다.
•
assert: 어떤 것이 true인지 확인할 수 있다. (테스트 모드에서만 동작한다.)
•
return 또는 throws와 함께 활용하는 Elvis 연산자
이러한 제한은 어떤 장점이 있을까
•
문서를 읽지 않은 개발자도 문제를 확인할 수 있다.
•
문제가 있을 경우에 함수가 예상하지 못한 동작을 하지 않고 예외를 throw 함으로써 예상 못 한 동작하는 것을 예외를 던짐으로써 막을 수 있다.
•
코드가 일정 수준 자체 검사가 된다.
•
스마트 캐스트 기능을 활용할 수 있게 된다. 즉 캐스팅 횟수를 줄일 수 있다.
require
함수를 정의할 때 타입 시스템을 활용해 argument에 제한을 거는 코드를 사용한다.
fun method(param: String) {
require(validate(param) {
"invalid parameter Input: $param"
}
}
Kotlin
복사
require 함수는 제한을 확인하고, 제한을 확인하지 못할 경우 IllegalArgumentException을 던지며 블록 내에 작성된 메시지를 Exception Message로 활용한다.
이와 같은 형태의 입력 유효성 검사 코드는 메서드 최상단에 위치하기에 문서를 보지 않은 개발자도 쉽게 확인할 수 있다.
check
상태와 관련된 제한을 걸 때 사용하는 함수로 다음과 같은 경우 사용된다.
•
특정 객체가 미리 초기화되어 있어야만 처리를 하게 하고 싶은 함수
•
사용자가 로그인 했을 때만 처리를 하게 하고 싶은 함수
•
객체를 사용할 수 있는 시점에 사용하고 싶은 함수
//특정 객체가 미리 초기화되어 있어야만 처리를 하게 하고 싶은 함수
fun speak(text: String) {
check(isInitialized)
}
//사용자가 로그인 했을 때만 처리를 하게 하고 싶은 함수
fun getUserInfo(): UserInfo {
checkNotNull(token)
}
//객체를 사용할 수 있는 시점에 사용하고 싶은 함수
fun next(): T {
check(isOpen)
}
Kotlin
복사
check 함수는 require와 비슷하지만, throw하는 예외가 IllegalStateException으로 argument 의 유효성보다는 현재 상태에 대한 유효성을 검증하는데 사용한다.
그렇기에 일반적으로 require 블록을 먼저 작성하고 그 뒤에 check를 나중에 작성한다.
Assert 계열 함수 사용
요소가 10개 들어있는 컬렉션에서 5개를 꺼낸다면 함수의 크기는 5여야 한다.
정상적으로 구현되어 있다면 해당 내용은 참일 것이다. 그런데 함수가 올바르게 작성되어 있지 않을 수도 있다. 이러한 구현 문제로 인한 문제를 예방하기 위해선 단위 테스트를 사용하는 게 좋다.
test("Stack pops correct number of elements") {
val stack = Stack(10) { it }
val actual = stack.pop(5)
actual shoudHavSize 5
}
Kotlin
복사
하지만, 이런 테스트 케이스는 특정 케이스에 대해서만 테스트하기에 다른 모든 상황에서도 괜찮을지 알 수 없다. 그렇기에 모든 pop 호출 위치에서 검증을 해도 괜찮을 것으로 보인다.
다음과 같이 함수 호출 위치에서 단언문을 작성할 수도 있다.
fun pop(num: Int = 1): List<T> {
//...
assert(ret.size == nul)
return ret
}
Kotlin
복사
다만, 이런 단언문은 코틀린/JVM 환경에서 -ea JVM 옵션을 활성해야만 확인 가능하다.
함수에서 assert 사용할 경우 장점
•
Assert 계열 함수는 코드를 자체 점검하며, 더 효율적으로 테스트 할 수 있게 해준다.
•
특정 상황이 아닌 모든 상황에 대한 테스트를 할 수 있다.
•
실행 시점이 정확하게 어떻게 되는지 확인할 수 있다.
•
실제 코드가 더 빠른 시점에 실패하게 만들어 예기치 못한 동작을 추적하기 쉽다.
nullability와 스마트 캐스팅
이런 제한 블록들(require, check)은 true일 경우 앞으로도 true일거라고 가정한다.
그렇기에 이를 활용해 타입 비교를 했다면, 스마트 캐스트가 작동한다.
fun changeDress(person: Person) {
require(person.outfit is Dress)
val dress: Dress = person.outfit
}
Kotlin
복사
또한, null check에서도 유용하다.
class Person(val email: String?)
fun sendEmail(person: Person, message: String) {
require(person.email != null) //이 이후로 email은 not null임이 보장된다.
val email: String = person.email
}
Kotlin
복사
nullability를 목적으로 우측에 throw나 return을 두고 Elvis 연산자를 활용하는 경우도 많다.
fun sendEmail(person: Person, message: String) {
val email: String = person.email ?: return
//...
}
Kotlin
복사
fun sendEmail(person: Person, message: String) {
val email: String = person.email ?: run {
log("Email not sent, no email address")
return
}
//...
}
Kotlin
복사
정리
•
제한을 훨씬 더 쉽게 확인할 수 있다.
•
애플리케이션을 더 안정적으로 지킬 수 있다.
•
코드를 잘못 쓰는 상황을 막을 수 있다.
•
스마트 캐스팅을 활용할 수 있다
6. 사용자 정의 오류보단 표준 오류를 사용하라
일반적으로는 require, check, assert 함수를 이용해 대부분의 코틀린 오류를 처리할 수 있다.
하지만, 이외의 다양한 상황에서 발생하는 예외에 대해서는 어떻게 해야할까?
inline fun <reified T> String.readObject(): T {
//...
if(incorrectSign) {
throw JsonParsingException()
}
//...
return result
}
Kotlin
복사
위 코드에서 JsonParsingException은 입력된 JSON 파일 형식에 문제가 있을 경우 던져지는 예외로 표준 라이브러리에서 적절한 예외가 없어서 사용자 정의 예외를 사용했다.
하지만, 이런 경우를 제외하고는 왠만해서는 표준 라이브러리의 예외를 사용하는것이 좋다. 어째서일까? 해당 코드를 나 혼자만 사용할 것이라면 사용자 정의 예외를 많이 사용해도 큰 문제는 되지 않는다. 하지만, 협업관계에서 혹은 내가 제공하는 API를 외부에서 사용하려고 할 때 나만 알 수 있는 여러 사용자 정의 예외들을 만들었다면, 이에 대한 설명을 모두 해줘야 하고, 사용하는 클라이언트 측에서도 해당 예외에 대한 학습이 필요하다.
하지만, 표준 라이브러리의 예외는 이미 많은 개발자들이 숙지하고 있기에 이런 과정들을 생략할 수 있다. 더하여 비슷한 의미의 표준 예외가 있는데 사용자 정의 예외를 던지면 의미의 혼동도 생길 수 있다.
일반적으로 사용되는 예외 몇 가지
•
IllegalArgumentException: 파라미터에 문제가 있을 경우 던져지는 예외
•
IllegalStateException: 현재 상태가 적절지 못해 진행이 불가능한 경우 던지는 예외
•
IndexOutOfBoundsException: 인덱스 파라미터 값이 범위를 벗어났을 경우 던지는 예외로 보통 컬렉션이나 배열과 함께 사용된다.
•
ConcurrentModificationException: 동시 수정(concurrent modification)을 금지했는데 발생했을 경우 던지는 예외
•
UnsupportedOperationException: 사용자가 사용하려고 했던 메서드가 현재 객체에선 사용할 수 없는 경우 던지는 예외
•
NoSuchElementException: 사용자가 사용하려고 했던 요소가 존재하지 않음을 나타내는 예외
7. 결과 부족이 발생할 경우 null과 Failure를 사용하라
코틀린에서는 여러 상황들로 인해 함수가 결과를 만들어내지 못하는 상황에서 크게 두 가지 방식으로 처리할 수 있다.
•
null 또는 실패를 나타내는 sealed 클래스를 반환한다(Ex: Failure)
•
예외를 throw한다.
잠깐, 여기서 예외는
정보를 전달하는 방법으로 사용해선 안된다. 예외는 특별한 상황을 나타내야 하며 처리 되어야 한다.
예외를 정보 전달 목적으로 사용해서 안되는 이유
1.
예외가 전파되는 과정을 추적하지 못한다.
2.
코틀린의 모든 예외는 비검사 예외로 사용자가 예외를 처리하지 않을 수도 있다. 즉 실제 API사용시 파악하기 힘들다.
3.
예외의 목적과 다르게 사용해선 안된다.
4.
try-catch 블록 내부에 코드를 배치할 경우, 컴파일러 최적화가 제한적이다.
반면, 첫 번째로 설명했던 null과 Failure는 예상되는 오류를 표현할 때 굉장히 좋다.
그렇기에 예측할 수 있는 범위의 오류는 null과 Failure, 예측하기 어려운 정말 예외적인 범위는 예외를 throw하는 게 좋다. 다음 예제 코드를 보자.
inline fun <reified T> String.readObjectOrNull(): T? {
//...
if(incorrectSign) {
return null
}
//...
return result
}
inline fun <reified T> String.readObjectOrNull(): T? {
//...
if(incorrectSign) {
return Failure(JsonParsingException())
}
//...
return Success(result)
}
sealed class Result<out T>
class Success<out T>(val result: T):Result<T>()
class Failure<out T>(val throwable: Throwable):Result<Nothing>()
class JsonParsingException: Exception()
Kotlin
복사
이렇게 표시되는 오류(JsonParsingException)는 다루기 쉽고 놓치기 어렵다.
만약 null을 처리해야 한다면 사용자는 safe call을 하거나 Elvis연산자등을 이용해 null-safe하게 작성할 수 있다.
val age = userText.readObjectOrNull<Person>()?.age ?: -1
Kotlin
복사
Result같은 공용체(union type)를 반환하기로 했다면, when 표현식을 사용해 처리할 수 있다.
val age = userText.readObjectOrNull<Person>()
val age = when(person) {
is Success -> person.age
is Failure -> -1
}
Kotlin
복사
우리는 nullable을 반환하지 않도록 해야 한다. 만약, null이 반환될 수 있다는 경고를 하려면 명시적으로 getOrNull등을 사용해 무엇이 반환되는지 시그니처를 알려줄 수 있도록 하는게 좋다.
즉, 정리하자면
•
메서드 시그니처가 non-null으로 예상되는 경우 (Ex: get)
◦
함수가 반환값을 정상적으로 만들지 못할경우 예외를 throw한다.
◦
함수가 반환값을 정상적으로 만들 경우 해당 값을 반환한다.
•
메서드 시그니처가 nullable으로 예상되는 경우(Ex: getOrNull)
◦
함수가 반환값을 정상적으로 만든 경우 해당 값을 반환한다.
◦
함수가 반환값을 정상적으로 만들지 못할 경우 null을 반환한다.
◦
추가적인 정보를 전달하길 원하면 sealed result 같은 클래스를 활용하자.
▪
실패했을 땐 Failure, 성공했을 땐 Success등으로 상태와 내부 프로퍼티로 추가 정보를 제공할 수 있다.
8. 적절하게 null을 처리하라
코틀린은 언어 차원에서 null-safe를 지원하며 NPE(NullPointerException)을 줄이기 위한 여러가지 방법을 제시한다.
null은 명확인 의도하에 사용해야 한다.
•
String.toIntOrNull
: Int로 변환이 불가능한 경우 null을 반환한다.
•
Interable<T>.firstOrNull(()→ Boolean)
◦
조건에 해당하는 요소가 없을 경우 null을 반환한다.
이처럼 null은 명확한 의도를 충분히 가져야 한다. 개발자가 별도의 문서를 보지 않고도 nullable함을 알 수 있게 시그니처를 제공해야, nullable한 값을 반환할 것을 예측할 수 있고, 처리할 수 있다.
Null 안전성
코틀린에선 모든 타입이 기본적으로 null을 허용하지 않는 notNull 타입이다. 따라서 초기화되지 않은 변수가 null값을 반환할 수 있는 함수는 컴파일 에러를 발생시킨다. 하지만, 상황에따라 nullable한 값을 반환해야 하는경우는 존재 할 수 밖에 없고, 이런 경우 코틀린에서는 nullable 타입에는 ?를 붙혀 표현한다.
val printer: Printer? = getPrinter()
Kotlin
복사
Nullable 타입 다루기
기본적으로 nullable 타입은 세 가지 방법으로 처리할 수 있다.
1. 안전하게 처리하기
nullable한 타입을 안전하게 처리하는 방법은 safe call, smart casting 그리고 Elvis연산자를 사용하는 것이다.
printer?.print() // safe call
if(printer != null) {
printer.print() // smart cast
}
printer?.print() ?: DefaultPrinter.print() // Elvis operator
Kotlin
복사
safe call은 printer가 null이 아닐 경우 print() 함수를 호출하고 null일 경우 null을 반환한다.
그리고, smart cast는 분기문내의 평가식이 true라는건 not null임이 보장되는 것이기에 그 내부 블럭에서는 printer의 타입이 nullable이 아닌 non-null타입으로 간주한다.
두 가지 방법 모두 사용자 관점에서 가장 안전한 방식이다.
추가적으로 Elvis 연산자를 이용해 printer가 null일 경우에 대한 로직을 작성할 수 있는데 return을 이용한 반환부터 throw를 통한 예외 던지기까지 모든 표현식이 허용된다.
참고: 방어적 프로그래밍과 공격적 프로그래밍
•
방어적 프로그래밍(defensive programming)
: 수 많은 상황에 대한 방어 코드로 안전성을 높히는 방식의 프로그래밍.
예를 들어, 사용자의 닉네임이 null일 경우 Guest로 기본 지정해준다. 등이 있다.
•
공격적 프로그래밍(offensive programming)
: 방어적으로 처리할 수 없는 예상치 못한 상황이 발생했을 때는 이러한 상황을 개발자에게 알려야 한다. 아이템 5에서 제안했던 require, check, assert등이 이런 공격적 프로그래밍을 위한 도구이다.
2. throw Exception
printer가 반드시 print() 함수를 실행시켜야 하는상황일 경우 DefaultPrinter.print()같은 추가 로직을 실행하거나 printer가 null이 아닐 경우에만 실행하는 방식으로는 부족하다.
이런 경우에는 강제로 오류를 발생시켜 개발자가 알 수 있게끔 하는게 좋다. 오류를 강제로 발생시킬 때는 throw, !!, requireNotNull, checkNotNull등을 활용할 수 있다.
fun process(user: User) {
requireNotNull(user.name)
val context = checkNotNull(context)
val networkService = getNetworkService(context) ?: throw NoInternetConnection()
networkService.getData { data, userData -> show(data!!, userData!!)
}
Kotlin
복사
참고: not-null assertion(!!)은 사용하지 말자.
!! 연산자는 null에 강제로 접근하게 하기에 NPE 위험성을 높힌다.
!! 연산자는 절대로 null이 나오지 않는다는게 확실한 경우 사용되지만, 이러한 확신을 가지긴 힘들고, 사용을 하다보면 SuppressWarning과 같이 무분별하게 사용하다가 문제에 맞닥드리게 될 확률이 높다.
3. 리팩토링으로 nullable 타입이 나오지 않게 바꾸기
null을 반환하는 것 자체로 하나의 중요한 메세지를 전달하는게 아니라면 nullability를 피해야 한다. nullable한 타입은 항상 적절한 처리 방식을 작성함으로써 추가 비용이 발생한다.
nullability를 피하기 위한 몇 가지 방법에 대해 알아보자.
•
메서드 시그니처를 통해 nullability 구분하기
: List<T>에는 get과 getOrNull이 존재한다. Int에도 toInt와 toIntOrNull이 존재한다. 메서드 시그니처를 구분해 nullability를 구분할 수 있다.
•
클래스 생성 이후 최초 사용 시점 이전에 확실하게 설정된다는 보장이 있을 경우 lateinit 프로퍼티와 notNull 델리게이트를 사용하라.
•
null 대신 빈 컬렉션을 반환하라. List<Int>?와 List<Int?> 를 같은 컬렉션을 빈 컬렉션으로 둘 때와 null로 둘 때 의미는 완전히 다르다.
•
null enum이 아닌 None enum을 사용하라.
enum class Foo { BAR, BAZ, NONE }
//bad case
fun getFoo() {
return values.find {...} ?: null
}
//good case
fun getFoo() {
return values.find{ ... } ?: Foo.NONE
}
Kotlin
복사
9. use를 사용해 리소스를 닫아라
JDBC, Stream, Connection,Socket등 코틀린/JVM에서 사용하는 라이브러리에는 많은 리소스들이 있는데, 이런 리소스들은 모두 AutoCloseable을 상속받는 Closeable인터페이스를 구현하고 있다.
이러한 리소스들은 가만히 냅둬도 리소스에대한 레퍼런스가 사라지면 GC에 의해 정리될 수 있지만, 언제 될지 유추하기 힘들고, 리소스를 유지하는 비용도 만만치 않다. 그렇기에 명시적으로 close를 호출해 리소스를 닫아주는게 좋다. Java에서는 try-with-resource를 이용해 이런 처리를 해줬는데, 코틀린에서는 use 함수를 이용해 대응할 수 있다.
fun countCharactersInFile(path: String): Int {
val reader = BufferedReader(FileReader(path))
reader.use {
return reader.lineSequence().sumBy { it.length }
}
}
Kotlin
복사
다음과 같이 작성 해 줄 수도 있다. 코틀린 에서는 람다 매개변수로 리시버가 전달되는 형태도 있기에 다음과 같이 작성할 수도 있다.
fun countCharactersInFile(path: String): Int {
BufferedReader(FileReader(path)).use { reader ->
return reader.lineSequence().sumBy { it.length }
}
}
Kotlin
복사
파일을 리소스로 사용하는 경우 한 줄씩 읽어서 처리할 수 있도록 useLine함수도 제공된다.
fun countCharactersInFile(path: String): Int {
File(path).useLines { lines ->
lines.sumBy { it.length }
}
}
Kotlin
복사
코드가 상당히 줄어든 모습을 볼 수 있다. 메모리에 파일의 내용을 한 줄씩만 유지하기에 대용량 파일도 적절하게 처리할 수 있다.
10. 단위 테스트를 만들어라
코드를 더 안전하게 만드는 방법은 바로 다양한 종류의 테스트를 하는 것이다.
단위 테스트는 다음과 같은 내용들을 확인한다.
•
normal usecase(happy path라고도 표현한다.)
: 요소가 사용될꺼라 예상되는 일반적인 테스트. 일반적으로 성공 테스트라고 지칭한다.
test("1 + 1은 2를 반환한다.") {
1 + 1 shouldBe 2
}
Kotlin
복사
•
normal failed test
: 제대로 동작하지 않을꺼라 예상되는 부분에 대해서 혹은 과거 문제가 생겼던 부분에 대해 테스트한다.
test("0으로 나눌 경우 예외를 던진다") {
shouldThrow<ArithmeticException> {
30 / 0
}
}
Kotlin
복사
•
edge case, invalid args test
: Int의 경우 Int.MAX_VALUE를 사용하는 경우, nullable의 경우 null이거나 null로 채워진 객체를 사용하는 경우, 피보나치의 수의 경우 음의 정수를 넣을 경우 등, 의도와 다른 아규먼트에 대한 테스트
이러한 단위 테스트는 개발자가 만들고 있는 요소가 제대로 동작하는지를 빠르게 피드백 할 수 있기에 많은 도움이 된다. 이러한 테스트는 계속해서 축적되기에 회귀 테스트(기존에 누적된 테스트를 기반으로 전체 혹은 부분을 반복적으로 테스트하는 것)도 쉽다.
회귀테스트가 쉬워지면 프로젝트가 커질수록 기능 변경하나에 얽힌 사이드 이펙트를 파악하기도 쉬워지고, 코드 개선이나 유지보수성을 높히는데 큰 도움을 줄 수 있다.
하지만, 단위 테스트를 따로 작성하는 시간, 깨지기 쉬운 테스트 자체를 유지보수해야하는 문제, 양질의 테스트 케이스 작성의 어려움, 팀원간의 소통 등 단점들도 많기 때문에, 트레이드 오프를 계산하고, 팀원을 설득하는 과정을 가지고 올바르게 단위 테스트하는 방법을 알고 있어야 한다.
그리고 다음과 같은 부분들에 대한 테스트를 작성하는 방법에 대해서도 알아야 한다.
•
복잡한 로직 영역
•
수정이 빈번하고 리팩토링이 생길 수 있는 영역
•
비즈니스 영역
•
공용 API영역
•
문제가 자주 발생하는 영역
•
수정해야 하는 프로덕션 버그(프로덕션 환경에서 발생하는 버그)

