
목차
개요
어떤 저자들은 2단계 커밋에서 유발되는 성능이나 가용성 문제 때문에 생기는 비용이 너무 커서 이를 지원할 수 없다고 주장했다.
우리는 항상 트랜잭션 없이 코딩하는 것보다 트랜잭션을 과용해서 병목지점이 생기는 성능 문제를 애플리케이션 프로그래머가 처리하게 하는 게 낫다고 생각한다.
- 제임스 코벳 외, 스패너: 구글의 전역 분산 데이터베이스(2012)
냉혹한 현실 세계에서 데이터 시스템은 여러 문제가 생길 수 있다.
•
DB SW/HW는 쓰기 연산이 실행 중일 때를 포함해 언제든 실패할 수 있다.
•
애플리케이션은 (연속된 연산이 실행되는 도중도 포함해) 언제든 죽을 수 있다.
•
네트워크가 끊기면 애플리케이션과 DB의 연결이 갑자기 끊기거나 DB 노드 사이의 통신이 안 될 수 있다.
•
여러 클라이언트가 동시에 데이터베이스에 쓰기를 실행해서 다른 클라이언트가 쓴 내용을 덮어쓸 수 있다.
•
클라이언트가 부분적으로만 갱신되서 비정상적인 데이터를 읽을 수 있다.
•
클라이언트 사이의 경쟁 조건은 예측하지 못한 버그를 유발할 수 있다.
시스템이 신뢰를 지니려면 이런 문제들을 처리해 전체 시스템의 치명적인 장애로 이어지는 것을 막아야 한다. 그러나 내결함성을 갖춘 시스템을 구현하려면 비용이 크다.
모든 에러 케이스에 대해 고민해야 하고 테스트를 통해 해결책이 실제로 동작하는지도 확인해봐야 한다.
트랜잭션은 이런 문제를 단순화하는 메커니즘으로 채택되어 왔다.
트랜잭션은 애플리케이션에서 몇 개의 읽기와 쓰기를 하나의 논리적 단위로 묶는 방법이다.
개념적으로 한 트랜잭션 내의 모든 읽기와 쓰기는 한 연산으로 실행된다.
트랜잭션은 전체가 성공(커밋)하거나 실패(어보트, 롤백) 한다. 트랜잭션이 실패하면 애플리케이션에서 안전하게 재시도가 가능하다. 트랜잭션을 쓰면 애플리케이션에서 오류 처리를 하기가 훨씬 단순해진다. 원인이 무엇이든 연산이 어떤건 성공하고 어떤건 실패하는 부분적 실패를 걱정하지 않아도 된다.
트랜잭션이라는 키워드가 자주 사용되기에 뻔해 보일 수 있다.
하지만, 트랜잭션은 당연한것도 자연 법칙도 아니다.
DB에 접속하는 애플리케이션에서 프로그래밍 모델을 단순화하려는 목적으로 만든 것이다. 트랜잭션을 사용함으로써 애플리케이션에서 어느 정도 잠재적은 오류 시나리오와 동시성 문제를 무시할 수 있다. DB에서 대신 이런 일을 도맡아 주기 때문이다.
•
이를 안전성 보장(safety guarantee)이라 한다.
모든 애플리케이션이 트랜잭션이 필요하진 않고, 종종 트랜잭션의 보장을 완화 혹은 안쓰는게 이득이다. (성능 향상이나 고가용성을 노릴 수 있다.) 어떤 안전성 속성은 트랜잭션 없이도 보장될 수 있다.
그럼 트랜잭션은 언제 필요한가?
이 질문에 대답하기 위해서는 트랜잭션이 제공하는 안전성 보장이 무엇이 있고, 비용은 어떤지 이해해야 한다.
이번 장에서는 문제가 생길 수 있는 케이스를 알아보고, 방지하기 위해 DB에서 사용하는 알고리즘을 살펴본다. 특히 동시성 제어 분야를 깊게 다루며, 발생할 수 있는 다양한 종류의 경쟁 조건과 DB에서 커밋 후 읽기(read committed), 스냅숏 격리(snapshot isolation), 직렬성(serializability) 같은 격리 수준을 어떻게 구현하는지 설명한다.
애매모호한 트랜잭션의 개념
현재 모든 RDB 와 일부 NoSQL은 트랜잭션을 지원한다.
200년대 후반 NoSQL이 인기를 얻으며
•
새로운 데이터 모델을 선택할 수 있게 하고
•
복제와 파티셔닝 기능을 제공하면서
RDB의 현 상황을 개선하는 것을 목표로 했다.
트랜잭션은 이러한 트렌드에서 피해를 받았는데, 새로운 세대의 DB중 다수는 트랜잭션을
•
완전히 포기하거나
•
과거보다 약한 보장을 의미하도록
트랜잭션의 의미를 재정의했다.
이렇게 새로 탄생한 분산 DB가 알려지면서 트랜잭션은 확장성의 안티테제이고 대규모 시스템에서 높은 성능과 고가용성을 유지하기위해서는 포기해야 하는 개념으로 알려졌다.
반면 DB 벤더에서는 트랜잭션적인 보장은 가치있는 데이터가 있는 중대한 애플리케이션에 필수적인 요구사항이라고 주장하는데, 사실 둘 다 과장이 심하다.
트랜잭션 역시 다른 기수들처럼 장점과 단점이 있다.
이런 트레이드오프를 이해하기 위해서 정상적인 운영 상황과 극단적인 환경에서 트랜잭션이 제공하는 보장의 세부 사항을 살펴볼 필요가 있다.
ACID의 의미

원자성(Atomicity), 일관성(Consistency), 격리성(Isolation), 지속성(Durability)의 약어 ACID
ACID는 트랜잭션이 제공하는 DB의 내결함성 메커니즘을 나타내는 용어들의 약어다.
하지만, 현실에선 DB마다 ACID 구현이 제각각이다.
격리성의 의미 주변에는 모호함이 많이 있다. 상위 수준의 아이디어는 견실하지만 세부 사항에는 악마가 숨어있다.
참고: ACID의 반대 BASEACID 표준을 따르지 않는 시스템은 때로 BASE라 불린다.
기본적인 가용성을 제공하고(Basically Available),
유연한 상태를 가지며(Soft state),
최종적 일관성(Eventual consistency)을 지닌다는 의미.
하지만, ACID와 비교해도 충분히 모호한 단어로 ACID가 아니라는 것 빼고는 정의내리기 어렵다.
원자성
일반적으로 원자적이란 더 작은 부분으로 쪼갤 수 없는 뭔가를 가리킨다.
이 단어는 컴퓨터의 여러 분야에서 비슷하지만 미묘하게 다른 것을 의미한다.
•
다중 스레드 프로그래밍에서는
◦
스레드가 원자적 연산을 실행한다면 다른 스레드에서 절반만 완료된 연산을 관찰할 수 없다.
◦
시스템은 연산을 실행하기 전이나 실행한 후의 상태에만 있을 수 있다.
•
ACID의 맥락에서는
◦
원자성은 동시성과 관련이 없다.
◦
원자성은 여러 프로세스가 동시에 같은 데이터에 접근하려고 할 때 무슨일이 생기는지 설명하지 않는다.
◦
이 문제는 격리성(Isolation)에서 다루기 때문이다.
대신 ACID의 원자성은 클라이언트가 쓰기 작업 몇 개를 실행하려고 하는데 그 중 일부만 처리된 후 결함이 생기면, 무슨 일이 생기는지 설명한다. 여러 쓰기 작업이 하나의 원자적인 트랜잭션으로 묶여 있는데 결함 때문에 완료(커밋)될 수 없다면 어보트되고 DB는 이 트랜잭션에서 지금까지 실행한 쓰기를 무시하거나 취소해야 한다.
원자성 없이는 여러 변경을 적용하는 도중 오류가 발생하면 어떤 변경은 효과가 있고 어떤 것은 그렇지 않은지 알기 어렵다. 애플리케이션에서 재시도할 수 있지만 동일한 변경이 두 번 실행되서 중복되건 잘못된 데이터가 만들어지기 쉽다. 원자성은 이 문제를 단순하게 만들어준다. 트랜잭션이 어보트됐다면 애플리케이션에서 이 트랜잭션이 어떤 것도 변경하지 않았음을 알 수 있기에 안전하게 재시도 할 수 있다.
오류가 생겼을 때 트랜잭션을 어보트하고 해당 트랜잭션에서 기록한 모든 내용을 취소하는 능력은 ACID원자성의 결정적인 특징이다. 아마도 어보트 능력(abortablility)이 원자성보다 나은 단어겠지만 원자성이 자주 쓰이기에 이 단어를 계속 사용한다.
일관성
일관성은 굉장히 여러 의미로 쓰인다.
•
5장에서 복제 일관성(replica consistency)과 비동기식으로 복제되는 시스템에서 발생하는 최종적 일관성(eventual consistency) 문제에 대해 설명했다.
•
일관성 해싱은 어떤 시스템들에서 재균형화를 위해 사용되는 파티셔닝 방법
•
CAP 정리에서 일관성이란 단어는 선형성(linearizability)을 의미한다.
•
ACID의 맥락에서 일관성은 DB가 좋은 상태에 있어야 한다는 것에 애플리케이션에 특화된 개념
이렇게 최소 4가지 의미로 쓰이고 있다.
ACID 일관성의 아이디어는 항상 진실이어야 하는, 데이터에 관한 어떤 선언(불변식(immutable))이 있다는 것이다. 예를 들어 회계 시스템에서 모든 계좌에 걸친 대변과 차변은 항상 맞아떨어져야 한다. 트랜잭션이 이런 불변식이 유효한 DB에서 시작하고 트랜잭션에서 실행된 모든 쓰기가 유효성을 보존한다면 불변식이 항상 만족된다고 확신할 수 있다.
하지만, 일관성의 아이디어는 애플리케이션의 불변식 개념에 의존하고, 일관성을 유지하도록 트랜잭션을 올바르게 정의하는 것은 애플리케이션의 책임이다.
이는 DB가 보장할 수 있는게 아니다. DB는 불변식을 위반하는 잘못된 데이터를 쓰지 못하도록 막을 수 없다.
원자성, 격리성, 지속성은 DB의 속성인 반면 (ACID에서의) 일관성은 애플리케이션의 속성이다. 애플리케이션에서 일관성을 달성하기 위해 DB의 원자성과 격리성 속성에 기댈 수는 있지만 DB만으로 되는 것은 아니다 따라서 C는 실제로는 ACID에 속하지 않는다.
격리성
대부분 동시에 여러 클라이언트에서 DB에 접속한다.
클라이언트들이 서로 DB의 다른 부분을 읽고 쓰면 문제가 되지 않지만, 동일한 DB 레코드에 접근하면 동시성 문제(경쟁 조건)에 맞닥뜨리게 된다. 다음 그림이 동시성 문제가 발생하는 상황이다.
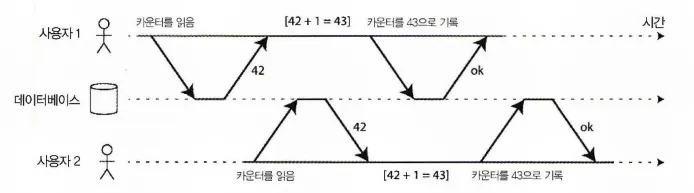
동시에 카운터를 증가시키는 두 클라이언트 사이의 경쟁조건
•
DB에 저장된 카운터를 증가시키는 두 개의 클라이언트가 있다.
•
각 클라이언트는 현재 값을 읽어 1을 더한 후 새 값을 다시 기록한다.
•
두 클라이언트가 한 번씩 조회를 했기 때문에 각 1씩 총 2가 증가되야한다.
◦
최초 DB의 카운트는 42였기에 42 + 2 = 44가 되야한다.
•
하지만, 실제로는 경쟁 조건 때문에 43이 되었다.
ACID에서 격리성은 동시에 실행되는 트랜잭션은 서로 격리된다는 것을 의미한다. 트랜잭션은 다른 트랜잭션을 방해할 수 없다. 고전적인 DB 책에서는 격리성을 직렬성이라는 용어로 공식화 한다. 직렬성은 각 트랜잭션이 전체 DB에서 실행되는 유일한 트랜잭션인 것처럼 동작할 수 있다는 것을 의미한다. DB는 실제로는 여러 트랜잭션이 동시에 실행됐더라도 트랜잭션이 커밋됐을 때의 결과가 트랜잭션이 순차적으로(하나씩 차례로) 실행됐을 때의 결과와 동일하도록 보장한다.
하지만 이런 직렬성 격리(serializable isolation)는 성능 손해를 동반하기에 잘 사용되지는 않는다.
오라클의 경우 직렬성보다 보장이 약한 스냅숏 격리를 구현해서 사용한다.
지속성
DB 시스템의 목적은 데이터를 잃어버릴 염려가 없는 안전한 저장소를 제공하는 것이다.
지속성(durablility)은 트랜잭션이 성공적으로 커밋됐다면 하드웨어 결함이 발생하거나 DB가 죽어도 트랜잭션에서 기록한 모든 데이터는 손실되지 않는다는 보장이다.
단일 노드 DB에서 지속성은 일반적으로 데이터가 HDD나 SSD같은 비휘발성 저장소에 기록됐다는 뜻이다. 보통 디스크에 저장된 데이터 구조가 오염됐을 때 복구할 수 있게 해주는, 쓰기 전 로그(write-ahead log, WAL)나 비슷한 수단을 동반한다.
복제 기능이 있는 DB에서 지속성은 데이터가 성공적으로 다른 노드 몇 개에 복사됐다는 것을 의미할 수 있다. 지속성을 보장하려면 DB는 트랜잭션이 성공적으로 커밋됐다고 보고하기전 쓰기나 복제가 완료될 때까지 기다려야 한다.
복제와 지속성
지속성의 의미는 계속해서 바뀌어왔다.
과거에는 아카이브 테이브에 기록하는 것
그 후에는 디스크나 SSD에 기록하는 것
최근에는 복제를 의미하게 됐다. 어떤 구현이 더 좋을까? 사실 완벽한 것은 없다.
•
데이터를 디스크에 기록하면 장비가 죽었을 때 데이터가 손실되지는 않지만 장비를 수리하거나 디스크를 다른 장비에 옮겨 달 때까지 접근할 수 없다. 복제 구성된 시스템이라면 여전히 데이터를 사용할 수 있다.
•
연관성이 있는 결함, 예를 들어 정전이나 특정한 입력을 받을 때 모든 노드를 죽이는 버그는 한 번에 모든 복제 서버를 죽여 메모리에만 저장된 데이터를 손실시킬 수 있다. 따라서 인메모리 DB에서는 디스크에 쓰는게 여전히 적절하다.
•
비동기식으로 복제되는 시스템에서는 리더가 동작할 수 없는 상태가 되면 최근에 쓴 데이터가 손실될 수 있다.
•
전원이 갑자기 나가면 특히 SSD에서 제공해야 하는 보장을 위반하는 사례가 종종 있었다.
•
저장 엔진과 파일시스템 구현 사이의 미묘한 상호작용을 추적하기 어려운 버그를 유발할 수 있으며 장비가 죽은 후 디스크에 있는 파일이 오염될 수 있다.
•
디스크에 있는 데이터는 나도 모르게 점차적으로 오염될 수 있다. 데이터가 얼마 동안 오염된 상태에 있었다면 복제와 최근 백업도 오염됐을지 모른다. 이런 경우 과거의 백업을 써서 데이터 복원을 시도해야 한다.
•
한 연구에서 30~80% 사이의 SSD는 사용한지 4년 이내에 최소 하나의 배드 블록이 생긴다는게 발견됐다.
•
SSD의 전원 연결이 끊어지면 온도에 따라서 몇 주 내에 데이터 손실이 생기기 시작할 수 있다.
현실에서 절대적 보장을 제공하는 한 가지 기법은 없다.
•
디스크에 쓰기
•
원격 장비에 복제하기
•
백업 등..
여러 방법을 포함해 위험을 줄이려는 기법이 있을 뿐이다. 이들은 함께 쓸 수 있으며 그래야만 한다.
항상 이론적인 보장은 적당히 조절해 듣는게 현명하다.
단일 객체 연산과 다중 객체 연산
요약하면 ACID에서 원자성과 격리성은 클라이언트가 한 트랜잭션 내에서 여러 번의 쓰기를 하면 DB가 어떻게 해야 하는지를 서술한다.
•
원자성
◦
쓰기를 이어서 실행하는 도중 오류가 발생하면 트랜잭션은 어보트돼야 하고 그때까지 쓰여진 내용은 폐기돼야 한다. 다시 말해 DB는 전부 반영되거나 아무것도 반영되지 않는 것을 보장함으로써 부분 실패를 걱정할 필요가 없게 도와준다.
•
격리성
◦
동시에 실행되는 트랜잭션들은 서로를 방해하지 말아야 한다. 예를 들어, 한 트랜잭션이 여러 번 쓴다면 다른 트랜잭션은 그 내용을 전부 볼 수 있든지 아무것도 볼 수 없든지 둘 중 하나여야만 한다.
이 정의는 한 번에 여러 객체(로우, 문서, 레코드)를 변경할 수 있다고 가정한다.
다중 객체 트랜잭션은 흔히 데이터의 여러 조각이 동기화된 상태로 유지돼야 할 때 필요하다.
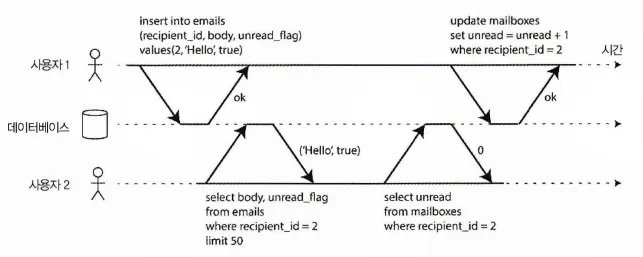
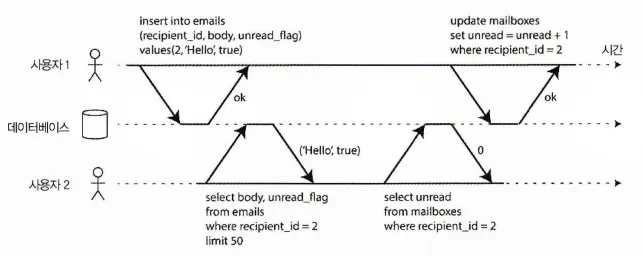
격리성 위반: 트랜잭션이 다른 트랜잭션에서 썼지만 커밋되지 않은 데이터를 읽음(dirty read)
위 그림은 이메일 애플리케이션에서 가져온 플로우다.
어떤 사용자가 읽지 않은 메시지 갯수를 확인하기 위해 다음과 같은 쿼리를 실행할 수 있다.
SELECT COUNT(*) FROM emails WHERE recipient_id = 2 AND unread_flag is true
SQL
복사
하지만, 이메일이 너무 많으면 이 쿼리는 너무 느릴 것 같기에 메세지 갯수를 별도로 필드에 저장하는 일종의 비정규화를 수행하고 싶을 수 있다.
그럼 이제 새로운 메세지가 올 때마다 해당 필드(안 읽은 메세지 갯수)를 증가 시켜야 하고, 반대로 메시지를 읽으면 감소 시켜줘야 한다.
위 그림에서 사용자2는 아직 읽지 않은 메시지가 하나 있지만, 아직 메세지 갯수에 대한 업데이트는 이뤄지지 않았기 때문에 읽지 않은 메세지 개수가 0으로 나온다.
격리성은 사용자2가 삽입된 이메일과 갱신된 개수를 모두 보거나 모두 보지 못하게 하고 일관성이 깨진 중간 지점을 보는 일이 없게 해준다.
다음 그림은 원자성의 필요성을 보여준다.
트랜잭션 실행 도중 어느 시점에서 오류가 발생하면 우편함의 내용과 읽지 않은 메세지 개수가 동기화되지 않을 수 있다. 원자적 트랜잭션에서는 개수 갱신을 실패하면 트랜잭션이 어보트되고 삽입된 이메일은 롤백된다.
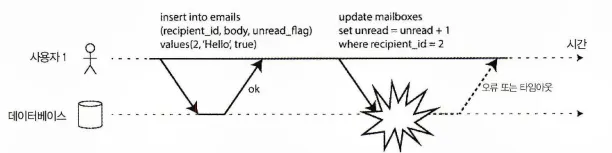
원자성 오류가 발생하면 트랜잭션에서 이전에 실행한 쓰기를 취소해서 일관성이 깨지지 않도록 한다.
다중 객체 트랜잭션은 어떤 읽기 연산과 쓰기 연산이 동일한 트랜잭션에 속하는지 알아낼 수단이 있어야 한다. RDB에서 이것은 전형적으로 클라이언트와 DB 서버 사이의 TCP 연결을 기반으로 한다.
어떤 특정 연결 내에서 BEGIN TRANSACTION 문과 COMMIT 문 사이의 모든 것은 같은 트랜잭션에 속하는 것으로 여겨진다.
사실 이 방식은 이상적이지 않다. TCP 연결이 끊기면 트랜잭션은 어보트 되야 한다.
클라이언트가 커밋 요청을 보냈지만 서버가 커밋 여부를 확인해주기 전에 연결이 끊긴다면 클라이언트는 트랜잭션이 커밋됐는지 아닌지 알 수가 없다. 이 문제를 해결하기 위해 트랜잭션 관리자는 특정 TCP 연결에 엮이지 않은 고유한 트랜잭션 식별자를 사용해 연산을 묶을 수 있다.
반면 NoSQL은 이런 식으로 연산을 묶는 방법이 없는 경우가 많다. 다중 객체 API가 있더라도(이를테면 키-값 저장소는 한 연산 내에서 여러 키를 갱신하는 다중 put(multi-put) 연산을 제공할 수 있다.) 반드시 트랜잭션 시맨틱을 뜻하지는 않는다.
어떤 키에 대한 연산은 성공하고 나머지 키에 대한 연산은 실패해서 DB가 부분적으로 갱신된 상태가 될 수 있다.
단일 객체 쓰기
원자성과 격리성은 단일 객체를 변경하는 경우에도 적용된다.
예를 들어 20KB의 JSON 문서를 DB에 쓴다고 하자.
첫 10kb를 보낸 후 네트워크 연결이 끊기면 DB는 파싱 불가능한 10KB JSON을 저장할 것인가?
DB가 디스크에 저장된 기존 값을 덮어쓰는 도중 전원이 나가면 기존 값과 새 값이 함께 붙어 있게 될까?
문서를 쓰고 있을 때 다른 클라이언트에서 그 문서를 읽으면 부분적으로 갱신된 값을 읽게 될까? 이 문제들은 굉장히 혼란스럽기에 저장소 엔진들은 거의 보편적으로 한 노드에 존재하는 (키-값 쌍 같은) 단일 객체 수준에서 원자성과 격리성을 제공하는 것을 목표로 한다.
원자성은
•
장애 복구(crash recovery)용 로그를 써서 구현할 수 있다.
격리성은
•
각 객체에 잠금을 사용해 한 스레드가 점유할 수 있도록 구현할 수 있다.
어떤 DB는 증가 연산처럼 더 복잡한 원자적 연산을 제공하기도 한다.
증가 연산은 read-modify-write 주기를 반복할 필요를 없앤다. 비슷하게 유명한 것으로 compare-and-set 연산이 있다. 이 연산은 변경하려는 값이 누군가에 의해 동시에 바뀌지 않았을 때만 쓰기가 반영되도록 허용한다. 이러한 단일 객체 연산은 여러 클라이언트에서 동시에 같은 객체에 쓰려고 할 때 갱신 손실(lost update)을 방지하기에 유용하다.
하지만, 일반적으로 쓰이는 의미의 트랜잭션이 아니다. compare-and-set 과 다른 단일 객체 연산은 경량 트랜잭션(light-weight-transaction)으로 불리거나 마케팅 목적으로 ACID 라고 간주되기도 하지만 이런 용어는 오해의 소지가 있다. 트랜잭션은 보통 다중 객체에 대한 다중 연산을 하나의 실행단위로 묶는 메커니즘으로 이해된다.
다중 객체 트랜잭션의 필요성
많은 분산 데이터스토어는 다중 객체 트랜잭션 지원을 포기했다.
다중 객체 트랜잭션은 여러 파티션에 걸쳐서 구현하기가 힘들고 고가용성 및 고성능이 요구되는 상황에 방해되는 시나리오도 있기 때문이다. 하지만 분산 데이터베이스에서 근본적으로 트랜잭션을 막는 것은 아무것도 없다. (9장에서 분산 트랜잭션 구현에 대해 알아본다.)
그렇지만 다중 객체 트랜잭션이 정말 필요할까?
키-값 데이터 모델과 단일 객체 연산만 사용해서 애플리케이션을 구현하는게 가능할까?
단일 객체 삽입, 갱신, 삭제만으로 충분한 사용 사례도 있다.
하지만 많은 다른 경우에는 여러 개의 다른 객체에 실행되는 쓰기 작업은 코디네이션돼야 한다.
•
관계형 데이터 모델에서 테이블의 로우는 종종 다른 테이블의 로우를 참조하는 외래키를 갖는다.(그래프형 모델에서 정점은 다른 정점에 연결된 간선(edge)이 있다.)
다중 객체 트랜잭션은 참조가 유효한 상태로 유지되도록 보장해준다. 서로 참조하는 여러 레코드를 삽입할 때 참조 키는 정상적이어야 하고 최신 정보를 반영해야 한다. 그렇지 않으면 데이터가 비정상적으로 만들어진다.
•
문서 데이터 모델에선 함께 갱신되야 하는 필드들이 단일 객체로 다뤄지는 동일한 문서 내에 존재하는 경우가 흔하다. 단일 문서를 갱신할 때는 다중 객체 트랜잭션이 필요 없다. 하지만 조인 기능이 없는 문서 데이터베이스는 비정규화를 장려하기도 한다.
비정규화된 정보를 갱신할 때는 한 번에 여러 문서를 갱신해야 한다. 트랜잭션은 이런 상황에서 비정규화된 데이터가 동기화가 깨지는 것을 방지하는데 유용하다.
•
보조 색인이 있는 데이터베이스(순수 키-값 저장소를 제외한 거의 모든 데이터베이스)에서는 값을 변경할 때마다 색인도 갱신돼야 한다. 트랜잭션 관점에서 색인은 서로 다른 데이터베이스 객체다. 예를 들어 트랜잭션 격리성이 없으면 어떤 색인에서는 레코드가 보이지만 다른 색인은 아직 갱신되지 않아서 레코드가 보이지 않을 수 있다.
트랜잭션이 없더라도 이런 애플리케이션들을 구현할 수 있다.
하지만 원자성이 없으면 오류 처리가 훨씬 더 복잡해지고 격리성이 없으면 동시성 문제가 생길 수 있다.
오류와 어보트 처리
트랜잭션의 핵심 기능은 오류가 생기면 어보트되고 안전하게 재시도할 수 있다는 것이다. ACID DB는 이 철학을 바탕으로 한다.
DB가 원자성, 격리성, 또는 지속성 보장을 위반할 위험이 있으면 트랜잭션이 절반 정도 완료된 상태에 머물게 하는 대신 트랜잭션을 완전히 폐기한다.
하지만 모든 시스템이 이 철학을 따르지는 않는다.
특히 리더 없는 복제를 사용하는 DB는 최선을 다하는(best effort) 원칙을 기반으로 훨씬 더 많은 일을 한다. 요약하면 DB는 가능한 모든 것을 할 것이며 그 때문에 오류가 발생하면 이미 한 일은 취소하지 않는다. 따라서 오류 복구는 애플리케이션에게 책임이 있다.
오류는 필연적으로 발생하지만 많은 SW 개발자들은 오류 처리의 복잡한 내용은 신경쓰지 않고 낙관적인 상황만 생각하려고 한다. 이를테면 Rails의 액티브레코드나 Django같은 인기 있는 객체 관계형 매핑 프레임워크들은 어보트된 트랜잭션을 재시도하지 않는다. 오류가 발생하면 보통 예외가 스택을 따라 거품이 일듯이 솟아올라 사용자가 입력한 내용은 사라져버리고 사용자는 오류 메세지를 받게 된다.
어보트의 취지는 안전하게 재시도를 할 수 있게 하는것인데 아쉬운 일이다.
어보트된 트랜잭션을 재시도하는 것은 간단하고 효과적인 오류 처리 메커니즘이지만 완벽하진 않다.
•
트랜잭션이 실제론 성공했지만 서버가 클라이언트에게 커밋 성공을 알리는 도중 네트워크가 끊겼을 때 클라이언트는 실패했다고 생각하게 되고 재시도를 하게 되면 트랜잭션이 두 번 실행된다.
애플리케이션에 추가적인 중복 제거 메커니즘이 없다면 말이다.
•
오류가 과부하 때문이라면 트랜잭션 재시도는 문제를 개선하는게 아니라 약화시킬 수 있다. 이런 피드백 주기를 피하려면 재시도 횟수를 제한하든지 지수적 백오프(exponential backoff)를 사용하거나 가능하다면 과부화와 관련된 오류를 다른 오류와 별도로 처리하는 방법을 쓸 수 있다.
•
일시적인 오류(Ex: 교착 상태, 격리성 위반, 네트워크 단절, 장애 복구)만 재시도할 가치가 있으며 영구적인 오류(Ex: 제약 조건 위반)는 재시도해도 아무 소용이 없다.
•
트랜잭션이 DB 외부에도 부수 효과가 있다면 트랜잭션이 어보트될 때도 부수 효과가 실행될 수 있다.
예를 들어, 이메일을 보낸다면 트랜잭션을 재시도할 때마다 이메일이 다시 전송되기를 원하지는 않을 것이다. 여러 개의 다른 시스템들이 반드시 함께 커밋되거나 어보트되게 만들고 싶다면 2단계 커밋이 도움될 수 있다
•
클라이언트 프로세스가 재시도 중에 죽어버리면 그 클라이언트에서 데이터베이스에 쓰려고 했던 데이터가 모두 손실된다.
완화된 격리 수준
두 트랜잭션이 동일한 데이터에 접근하지 않으면 서로 의존하지 않기에 안전하게 병렬 실행될 수 있다. 동시성 문제는 트랜잭션이 다른 트랜잭션에서 동시에 변경한 데이터를 읽거나 두 트랜잭션이 동시에 같은 데이터를 변경하려고 할 때만 나타난다.
동시성 버그는 타이밍에 운이 없을 때만 촉발되기에 테스트로 발견하기 어렵고, 추론하기도 어렵다. 특히 다른 어떤 코드 조각에서 DB에 접근하는지 파악하기 힘든 커다란 애플리케이션에서 그렇다.
그렇기에, DB는 트랜잭션 격리를 제공한다.
애플리케이션 개발자들은 제공받은 트랜잭션 격리를 통해 동시성 문제를 감추려고 했다.
직렬성 격리는 DB가 여러 트랜잭션들이 직렬적으로 실행되는 것(즉 동시성 없이 한 번에 트랜잭션 하나만 실행)과 동일한 결과가 나오도록 보장한다는 것을 의미한다.
현실적으로 격리는 간단하지 않다.
직렬성 격리는 성능 비용이 있고 많은 DB들은 그 비용을 지불하려 하지 않는다. 따라서 모든 동시성 문제로부터 보호해주지는 않는 완화된 격리 수준을 사용하는 시스템들이 대부분이다.
완화된 트랜잭션 격리가 유발하는 동시성 버그는 단지 이론적인 문제만은 아니다.
현실에서 금전적으로 손실을 일으킬 수 있고, 고객의 데이터를 오염시킬수도 있다.
대부분 인기있는 RDB조차도 완화된 격리성을 사용하는 경우가 많아 이런 버그가 발생하는 것을 반드시 막아주지는 못한다.
우리는 도구에 의존하기보단 (동시성) 문제를 파악하고 방지할 필요가 있다.
그러면 사용 가능한 도구를 써서 신뢰성 있고 잘 동작하는 애플리케이션을 만들 수 있다.
알아볼 내용
•
현장에서 사용되는 완화된(비직렬성) 격리 수준
•
발생할 수 있는 경쟁 조건과 발생할 수 없는 경쟁 조건
◦
애플리케이션에 적합한 격리 수준을 선택할 수 있게 된다.
•
직렬성에 대해 자세한 내용
커밋 후 읽기
커밋 후 읽기(read committed) 수준에서는 두 가지를 보장해준다.
1.
DB를 읽을 때 커밋된 데이터만 보게 된다(no dirty read)
2.
DB에 쓸 때 커밋된 데이터만 덮어쓰게 된다(no dirty write)
더티 읽기 방지(prevent dirty read)
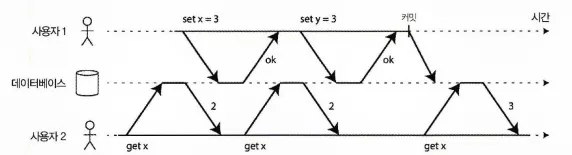
더티 읽기 방지: 사용자2는 사용자1의 트랜잭션이 커밋된 후에 x의 새 값을 보게 된다.
트랜잭션이 DB에 데이터를 썼지만 아직 커밋 or 어보트되지 않았다고 할 때 다른 트랜잭션에서 커밋되지 않은 데이터를 볼 수 있다면 이를 더티 읽기(dirty read)라 부른다.
커밋 후 읽기 격리 수준에서 실행되는 트랜잭션은 더티 읽기를 막아야 한다. 트랜잭션이 쓴 내용은 커밋된 후에야 다른 트랜잭션에게 보인다는 뜻이다.(그리고 트랜잭션이 쓴 모든 내용은 한 번에 보이게 된다.)
더티 읽기를 막는게 유용한 이유는
•
트랜잭션이 여러 객체를 갱신하는데 더티 읽기가 생기면 다른 트랜잭션이 일부는 갱신된 값을, 일부는 갱신되지 않은 값을 볼 수 있다. 부분적으로 갱신된 상태의 DB를 보는 것은 사용자에게 혼란을 줄 수 있고 다른 트랜잭션에 잘못된 결정을 하게 할 수 있다.
•
트랜잭션이 어보트되면 그때까지 쓴 내용은 모두 롤백되야 한다. DB가 더티 읽기를 허용하면 트랜잭션이 나중에 롤백될 데이터, 즉 실제로는 DB에 커밋되지 않을 데이터를 볼 수 있다.
더티 쓰기 방지(prevent dirty write)
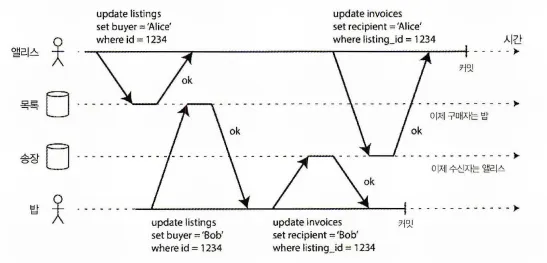
다른 트랜잭션에서 충돌하는 쓰기를 실행할 때 더티 쓰기가 있으면 내용이 섞일 수 있다.
두 트랜잭션이 DB에 있는 동일한 객체를 동시에 갱신하려고 하면 무슨 일이 생길까? 쓰기 순서가 어찌 될지는 모르지만 일반적으로 나중에 쓴 내용이 먼저 쓴 내용을 덮어쓴다고 가정한다.
먼저 쓴 내용이 아직 커밋되지 않은 트랜잭션에서 쓴 것이고 나중에 실행된 쓰기 작업이 커밋되지 않은 값을 덮어써버리면 어떻게 될까? 이를 더티 쓰기(dirty write)라 부른다.
커밋 후 읽기 격리 수준에서 실행되는 트랜잭션은 더티 쓰기를 방지해야 한다. 보통 먼저 쓴 트랜잭션이 커밋되거나 어보트 될 때까지 두 번재 쓰기를 지연시키는 방법을 사용한다.
더티 쓰기를 막는게 유용한 이유는
•
트랜잭션들이 여러 객체를 갱신하면 더티 쓰기는 나쁜 결과를 유발할 수 있다.
◦
위 그림과 같이 두 사용자가 동시에 동일한 차를 주문하려고 할 때 DB에는 각각 구매자와 수신자를 저장하는 두 번의 쓰기가 필요하다.
◦
동시에 두 사용자가 쓰기를 할 때 더티 쓰기가 된다면, 구매자와 수신자가 각기 다른 결과가 생길 수 있다.
◦
커밋 후 읽기는 이런 사고를 막아준다.
하지만,
•
커밋 후 읽기는 다음과 같은 두 번의 카운터 증가 사이에 발생하는 경쟁 조건은 막지 못한다.
◦
첫 번째 트랜잭션이 커밋된 후 두 번째 쓰기가 일어났기에 더티 쓰기가 아니다.
◦
갱신 손실 방지 파트에서 이런 문제를 막는 방법도 알아본다.
격리성 위반: 트랜잭션이 다른 트랜잭션에서 썼지만 커밋되지 않은 데이터를 읽음(dirty read)
커밋 후 읽기 구현
커밋 후 읽기는 매우 널리 쓰이는 격리 수준으로 다음 DB에선 기본 설정이기도 하다.
•
오라클 11g
•
postgreSQL,
•
SQL server 2012
•
MemSQL
가장 흔한 방법으로 DB는 로우 수준 잠금을 사용해 더티 쓰기를 방지한다. 트랜잭션에서 특정 객체(로우나 문서)를 변경하고 싶다면 먼저 해당 객체에 대한 잠금을 획득해야 한다. 그리고 트랜잭션이 커밋되거나 어보트될 때까지 잠금을 보유하고 있어야 한다.
오직 한 트랜잭션만 어떤 주어진 객체에 대한 잠금을 보유할 수 있다. 다른 트랜잭션에서 동일한 객체에 쓰기를 원한다면 첫 번째 트랜잭션이 커밋되거나 어보트된 후에야 잠금을 얻어 진행할 수 있다. 이런 잠금은 커밋 후 읽기 모드(또는 더 강한 격리 수준)에서 DB에 의해 자동으로 실행된다.
더티 읽기를 어떻게 막을 수 있을까?
한 가지 선택은 동일한 잠금을 써서 객체를 읽기 원하는 트랜잭션이 잠시 잠금을 획득한 후 읽기가 끝난 후 바로 해제하는 것이다. 이렇게 하면 객체가 변경됐으나 아직 커밋되지 않은 값을 갖고 있을 때 읽기가 실행되지 않도록 보장할 수 있다.
하지만 읽기 잠금을 요구하는 방법은 현실적으로 잘 동작하지 않는다.
읽기만 실행하는 여러 트랜잭션들이 오랫동안 실행되는 쓰기 트랜잭션 하나가 완료될 때까지 기다려야 할 수 있기 때문이다. 읽기만 실행하는 트랜잭션들의 응답 시간에 해를 끼치며 운용성이 나쁘다. 잠금 대기 때문에 애플리케이션 일부에서 발생한 지연이 애플리케이션의 다른 부분까지 연쇄 효과를 미칠 수 있다.
이런 이유로 대부분의 DB는 모든 객체에 대해 과거에 커밋된 값과 현재 쓰기 잠금을 갖고 있는 트랜잭션에서 쓴 새로운 값을 모두 기억하고, 해당 트랜잭션이 실행 중인 동안 그 객체에 읽기 요청을 하는 다른 트랜잭션들에게는 과거의 값을 읽게 한다.
새 값이 커밋된 후 다른 트랜잭션은 새 값을 읽을 수 있게 된다.
스냅숏 격리와 반복 읽기
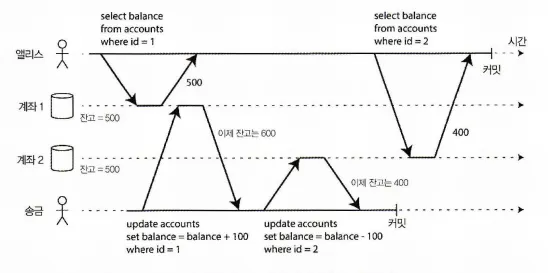
읽기 스큐: 앨리스는 일관성이 깨진 상태인 DB를 본다.
커밋 후 읽기 격리를 사용하더라도 동시성 문제로부터 자유로울 순 없다.
위 그림과 같이
•
앨리스는 1,000달러의 저축을 두 계좌에 500달러씩 나눠 놓았다.
•
계좌 2에서 계좌 1로 100달러를 전송하는 트랜잭션을 실행한다.
◦
작업 1 : 계좌 1은 잔고를 +100으로 업데이트한다.
◦
작업 2 : 계좌 2는 잔고를 -100 으로 업데이트한다.
•
앨리스는
◦
최초 계좌 1에서 잔고를 조회할 때 500을 확인했고,
◦
계좌 2에서 잔고를 조회할 때는 작업 2가 수행된 이후이기에 400을 확인했다.
◦
두 계좌의 총 잔고는 900으로 확인이 된다.
분명, 1,000달러의 저축을 한 상태에서 따로 소비를 한 것도 아닌데, 계좌 총액을 조회했을 때 1,000달러가 아닌 900달러가 조회되었다. 이런 이상 현상을 비반복 읽기(nonrepeatable read)나 읽기 스큐(read skew)라고 한다.
앨리스가 다시 계좌를 조회하면 계좌 1에서는 600달러를 보게 될 것이다.
앨리스의 경우 몇 초만 기다렸다가 새로 고침을 해도 제대로 된 계좌 잔고를 볼 수 있으니 지속적인 문제는 아니다. 하지만, 이런 일시적 비일관성을 허용할 수 없는 경우도 있다.
백업
백업을 하려면 DB 전체의 복사본을 만들어야 하는데 DB가 크면 시간 단위로 소요될 수 있다. 백업 프로세스가 실행되는 동안에서 DB에 쓰기가 실행될 수 있다.
따라서 백업의 일부는 데이터의 과거 버전을, 다른 부분은 새 버전을 갖고있을 수 있는데 이런 백업을 사용해서 복원하면 (사라진 돈과 같은) 비일관성이 영속적이게 된다.
분석 질의와 무결성 확인
DB의 큰 부분을 스캔하는 질의를 실행하고 싶을 때가 있다. 이런 질의는 분석 작업에서 흔하거나 모든 것이 순차적으로 실행되는 주기적인 무결성 확인의 일부일 수도 있다.(데이터 오염 모니터링). 이런 질의는 다른 시점의 DB의 일부를 보게 되면 불합리한 결과를 반환할 수도 있다.
가장 흔한 해결책 스냅숏 격리
스냅숏 격리는 이런 문제의 가장 흔한 해결책이다.
각 트랜잭션은 DB의 일관된 스냅숏으로부터 읽는다. 즉 트랜잭션은 시작할 때 DB에 커밋된 상태였던 모든 데이터를 본다. 데이터가 나중에 다른 트랜잭션에 의해 바뀌더라도 각 트랜잭션은 특정한 시점의 과거 데이터를 볼 뿐이다.
스냅숏 격리는 백업이나 분석처럼 실행하는데 오래 걸리며 읽기만 실행하는 질의에 요긴하다. 질의가 실행중일 때 동시에 대상 데이터가 변경된다면 그 질의의 의미에 대해 추론하기가 매우 어렵다.
트랜잭션이 특정 시점에 고정된 DB의 일관된 스냅숏만 볼 수 있다면 이해하기가 훨씬 쉬워진다.
스냅숏 격리는 널리 쓰이는 기능이다. 다음과 같은 DB에서 지원된다.
•
PostgreSQL
•
InnoDB
◦
MySQL
◦
Oracle
◦
SQLServer
스냅숏 격리 구현
스냅숏 격리 구현은 커밋 후 읽기 격리처럼 전형적으로 더티 쓰기를 방지하기 위해 쓰기 잠금을 사용한다.
쓰기를 실행하는 트랜잭션은 같은 객체에 쓰는 다른 트랜잭션의 진행을 차단할 수 있다는 뜻이다. 그러나 읽을 때는 아무 잠금도 필요 없다. 성능 관점에서 스냅숏 격리의 핵심은 다음과 같다.
읽는쪽과 쓰는쪽 서로 결코 차단하지 않는다.
따라서, DB는 잠금 경쟁 없이 쓰기 작업이 일상적으로 처리되는 것과 동시에 일관성 있는 스냅숏에 대해 오래 실행되는 읽기 작업을 처리할 수 있다.
스냅숏 격리를 구현하기 위해 DB는 위에서 소개한 더티 읽기를 막는 데 쓰는 메커니즘을 일반화한 방법을 사용한다.
•
DB는 객체마다 커밋된 버전 여러 개를 유지할 수 있어야 한다.
◦
진행 중인 여러 트랜잭션에서 각기 다른 시점의 DB 상태를 봐야 할 수도 있기때문이다.
•
DB가 객체의 여러 버전을 함께 유지하기에 다중 버전 동시성 제어(multi-version concurrency control, MVCC)라고 한다.
DB가 스냅숏 격리가 아닌 커밋 후 읽기 격리만 제공할 필요가 있다면 객체마다 버전 두 개씩만 유지하면 충분하다. 바로 커밋된 버전과 덮어 쓰여졌지만 아직 커밋되지 않은 버전이다.
그러나 스냅숏 격리를 지원하는 저장소 엔진은 보통 커밋 후 읽기 격리를 위해서도 MVCC를 사용한다.
전형적인 방법은
•
커밋 후 읽기는 질의마다 독립된 스냅숏을 사용하고,
•
스냅숏 격리는 전체 트랜잭션에 대해 동일한 스냅숏을 사용하는 것이다.
다음 그림을 보며 MVCC기반 스냅숏 격리를 알아보자.

다중 버전 객체를 이용한 스냅숏 격리 구현
•
트랜잭션이 시작하면 계속 증가하는 트랜잭션 ID(txid)를 할당받는다.
◦
트랜잭션이 DB에 쓰기를 할 때마다 쓰기를 실행한 txid가 함께 붙는다.
•
테이블의 각 로우에는 그 로우를 테이블에 삽입한 트랜잭션의 ID를 갖는 created_by 필드가 있다.
•
처음에는 비어있는 deleted_by 필드도 있다.
◦
트랜잭션이 로우를 삭제하면 삭제 요청 트랜잭션의 txid를 설정한다.
◦
DB에서 바로 삭제되는게 아니고, 나중에 아무 트랜잭션도 더 이상 삭제된 데이터에 접근하지 않는게 확실해지면 DB의 GC 프로세스가 지워졌다고 표시된 로우들을 삭제해서 사용량을 줄인다.
일관된 스냅숏을 보는 가시성 규칙
트랜잭션은 DB에서 객체를 읽을 때 트랜잭션 ID를 사용해 어떤 것을 볼 수 있고 없는지 결정한다.
면밀하게 가시성 규칙을 정의함으로써 DB는 DB의 일관된 스냅숏을 애플리케이션에게 제공할 수 있다.
동작 방식은
1.
DB는 각 트랜잭션을 시작할 때 그 시점에 진행 중인(커밋 or 어보트되지 않은) 모든 트랜잭션의 목록을 만든다. 이 트랜잭션들이 쓴 데이터는 모두 무시된다. 설령 데이터를 쓴 트랜잭션이 나중에 커밋되더라도 마찬가지다.
2.
어보트된 트랜잭션이 쓴 데이터는 모두 무시된다.
3.
트랜잭션 ID가 더 큰(즉 현재 트랜잭션이 시작한 후에 시작한) 트랜잭션이 쓴 데이터는 그 트랜잭션의 커밋 여부에 관계 없이 모두 무시된다.
4.
그 밖의 모든 데이터는 애플리케이션의 질의로 볼 수 있다.
이 규칙들은 객체 생성/삭제 모두에 적용된다. 위 그림에서 트랜잭션12가 계좌 2를 읽으면 잔고가 500달러가 있는 것을 보게 된다. 500달러 잔고 삭제는 트랜잭션13이 실행했고(규칙3에 따라 트랜잭션12는 트랜잭션13의 삭제를 볼 수 없다), 400달러 잔고 생성은 아직 볼 수 없다.
바꿔 말하면 다음 두 조건이 모두 참이면 객체를 볼 수 있다.
•
읽기를 실행하는 트랜잭션이 시작한 시점에 읽기 대상 객체를 생성한 트랜잭션이 이미 커밋된 상태
•
읽기 대상 객체가 삭제된 것으로 표시되지 않았다. 또는 삭제된 것으로 표시됐지만 읽기를 실행한 트랜잭션이 시작한 시점에 삭제 요청 트랜잭션이 아직 커밋되지 않았다.
오래 실행되는 트랜잭션은 오랫동안 스냅숏을 사용해서 (다른 트랜잭션의 관점에서) 덮어써지거나 삭제된 지 오래된 값을 계속 읽을 수도 있다. DB는 갱신할 때 값을 교체하지 않고 값이 바뀔 때마다 새 버전을 생성함으로써 작은 오버헤드만 유발하며 일관된 스냅숏을 제공할 수 있다.
색인과 스냅숏 격리
다중 버전 DB에서 색인은 어떻게 동작할까?
하나의 선택지는 단순하게 색인이 객체의 모든 버전을 가리키게 하고 색인 질의가 현재 트랜잭션에서 볼 수 없는 버전을 걸러내게 하는 것이다. GC가 어떤 트랜잭션에게도 더 이상 보이지 않는 오래된 객체 버전을 삭제할 때 대응되는 색인 항목도 삭제된다.
현실에서는 여러 구현 세부 사항에 따라 다중 버전 동시성 제어의 성능이 결정된다. 이를테면 PostgreSQL은 동일한 객체의 다른 버전들이 같은 페이지(page)에 저장될 수 있다면 색인 갱신을 회피하는 최적화를 한다.
카우치DB, 데이토믹, LMDB에서는 다른 방법을 쓴다.
B트리를 사용하지만 추가 전용이며 쓸 때 복사되는(append-only/copy-on-write)변종을 사용한다. 트리의 페이지가 갱신될 때 덮어쓰는 대신 각 변경된 페이지의 새로운 복사본을 생성한다.
트리의 루트에 이르기까지 존재하는 부모 페이지들은 복사되고 그것들의 자식 페이지들의 새 버전을 가리키도록 갱신된다. 쓰기에 영향을 받지 않는 페이지들은 복사될 필요가 없고 변함 없는 상태로 남는다.
추가 전용 B 트리를 사용하면 쓰기를 실행하는 모든 트랜잭션(or 묶음)은 새로운 B 트리 루트를 생성하며 특정 루트는 그것이 생성된 시점에 해당하는 DB의 일관된 스냅숏이 된다. 나중에 실행되는 쓰기는 새로운 트리 루트만 생성할 수 있고 존재하는 B 트리를 변경할 수 없으므로 트랜잭션 ID를 기반으로 객체를 걸러낼 필요가 없다.
그러나 이 방법도 컴팩션과 GC를 실행하는 백그라운드 프로세스가 필요하다.
반복 읽기와 혼란스러운 이름
스냅숏 격리는 유용한 격리수준으로 특히 읽기 전용 트랜잭션에 유용하다.
하지만 이를 구현한 많은 DB에서 다른 이름을 사용한다.
•
오라클에서는 직렬성
•
PostgreSQL, MySQL 에서는 반복 읽기(repeatable read)
라고 한다.
어째서 그럴까?
⇒ SQL 표준에 스냅숏 격리의 개념이 없기 때문이다.
SQL 표준은 1975년의 시스템 R의 격리 수준 정의를 기반으로 하는데, 이 당시에는 스냅숏 격리라는 개념이 없었다. 대신 표면적으로 스냅숏 격리와 비슷해 보이는 반복 읽기는 SQL 표준에 정의돼 있다. 그래서 PostgreSQL, MySQL에서는 스냅숏 격리 수준을 반복 읽기라 부른다.
하지만, SQL 표준의 격리 수준 정의는 모호하고 부정확하며 표준이 그래야 하는 것만큼 구현 독립적이지가 않다. 여러 DB가 반복 읽기를 구현하지만 이것들이 실제로 제공하는 보장에는 커다란 차이가 있다.
결과적으로, 반복 읽기가 무슨 뜻인지 실제로 아는 사람은 아무도 없다.
갱신 손실 방지
지금까지 설명한 커밋 후 읽기와 스냅숏 격리 수준은 주로 동시에 실행되는 쓰기 작업이 있을 때 읽기 전용 트랜잭션이 무엇을 볼 수 있는지에 대한 보장과 관련되었다.
두 트랜잭션이 동시에 쓰기를 실행할 때의 문제는 무시하고, 발생할 수 있는 쓰기-쓰기 충돌(write-write conflict)의 특별한 종류인 더티 쓰기에 대해서만 설명했다.
동시에 실행되는 쓰기 트랜잭션 사이에 발생할 수 있는 흥미로운 종류의 충돌이 몇 가지 더 있다.
이 가운데 가장 널리 알려진 것은 갱신 손실(lost upate) 문제이다.
갱신 손실 문제는 애플리케이션이 DB에서 값을 읽고 변경한 후 변경된 값을 다시 쓸 때(read-modify-write 주기)발생할 수 있다. 만약 두 트랜잭션이 이 작업을 동시에 하면 두 번째 쓰기 작업이 첫 번째 변경을 포함하지 않기에 변경 중 하나는 손실될 수 있다.(나중에 쓴 것이 먼저 쓴 것을 때려눕힌다(clobber)고 말하기도 한다) 이런 패턴은 다양한 시나리오에서 발생한다.
카운터를 증가시키거나 계좌 잔고를 갱신한다.
(현재 값을 읽어서 새 값을 계산하고 갱신된 값을 다시 써야 한다)
복잡한 값을 지역적으로 변경한다.
예를 들어 JSON 문서 내에 있는 리스트에 엘리먼트를 추가한다
사용자가 편집한 내용을 저장할 때 전체 페이지 내용을 서버에 보내서 현재 DB에 저장된 내용을 덮어 쓰도록 만들어진 위키에서 두 명의 사용자가 동시에 같은 페이지를 편집한다.
이러한 갱신 손실은 흔한 문제라서 다양한 해결책이 존재한다.
해결책1. 원자적 쓰기 연산
여러 DB에서 원자적 갱신 연산을 제공한다.
이 연산은 애플리케이션 코드에서 read-modify-write 주기를 구현할 필요를 없애준다.
UPDATE counters SET value = value + 1 WHERE key = 'foo';
SQL
복사
위 질의는 대부분의 RDB에서 동시성 안전(concurrency-safe)하다.
NoSQL은
•
몽고DB는
◦
JSON 문서의 일부를 지역적으로 변경하는 원자적 연산을 제공한다.
•
Redis는
◦
우선순위 큐(priority queue)같은 데이터 구조를 변경하는 원자적 연산을 제공한다.
모든 쓰기가 쉽게 원자적 연산으로 표현되지는 않는다.
예를 들어 위키 페이지 갱신은 임의의 텍스트 편집을 포함한다.
보통 원자적 연산이 사용될 수 있는 상황에서는 이들이 최선이다.
원자적 연산은 보통 객체를 읽을 때 그 객체에 독점적인(exclusive) 잠금을 획득해서 구현한다.
그래서 갱신이 적용될 때까지 다른 트랜잭션에서 그 객체를 읽지 못하게 한다. 이 기법을 커서 안정성(cursor stability)이라고 부르기도 한다. 다른 선택지는 그냥 모든 원자적 연산을 단일 스레드에서 실행되도록 강제하는 것이다.
주의할 점은 객체 관계형 매핑 프레임워크를 사용하면 의도와는 다르게 DB가 제공하는 원자적 연산을 사용하는 대신 불안전한 read-modify-write 주기를 실행하는 코드를 작성하기 쉽다. 이런 코드는 잠재적으로 테스트로 발견하기 어려운 미묘한 버그의 원인이 될 수 있다.
해결책2. 명시적인 잠금
DB에 내장된 원자적 연산이 필요한 기능을 제공하지 않을 때 갱신 손실을 막는 또 다른 선택지는 애플리케이션에서 갱신할 객체를 명시적으로 잠그는 것이다.
그러면 애플리케이션이 read-modify-write 주기를 수행할 수 있고 다른 트랜잭션이 동시에 같은 객체를 읽으려고 하면 첫 번째 read-modify-write 주기가 완료될 때까지 기다리도록 강제된다.
이를테면 여러 플레이어가 동시에 같은 물체를 옮길 수 있는 다중 플레이어 게임을 생각해 보자.
이 경우 원자적 연산이 충분하지 않을지도 모른다. 애플리케이션은 플레이어의 움직임이 게임 규칙을 준수하는지도 보장해야 하는데 여기에는 DB 질의로는 합리적으로 구현할 수 없는 로직이 포함될 수 있기 때문이다. 그 대신 두 명의 플레이어가 같은 물체를 동시에 움직일 수 없도록 잠금을 사용할 수 있다.
BEGIN TRANSACTION;
SELECT * FROM figures
WHERE name = 'robot' AND game_id = 222
FOR UPDATE; -- (1)
-- 이동이 유효한지 확인 후
-- 이전의 SELECT 에서 반환된 것의 위치를 갱신한다.
UPDATE figures SET position = 'c4' WHERE id = 1234;
COMMIT;
SQL
복사
•
(1) : FOR UPDATE 절은 DB가 이 질의에 의해 반환된 모든 로우에 잠금을 획득해야 함을 가리킨다.
이 방법은 동작하지만 올바르게 동작하게 하려면 애플리케이션 로직에 대해 신중하게 생각해야 한다. 코드의 어딘가에 필요한 잠금을 추가하는 것을 잊어버려 경쟁 조건을 유발하기 쉽다.
해결책3. 갱신 손실 자동 감지
원자적 연산과 잠금은 read-modify-write주기가 순차적으로 실행되도록 강제함으로써 갱신 손실을 방지하는 방법이다. 대안으로 이들의 병렬 실행을 허용하고 트랜잭션 관리자가 갱신 손실을 발견하면 트랜잭션을 어보트시키고 read-modify-write 주기를 재시도하도록 강제하는 방법이 있다.
이 방법의 이점은 DB가 이 확인을 스냅숏 격리와 결합해 효율적으로 수행할 수 있다는 것이다. 실제로 PostgreSQL의 반복 읽기, 오라클의 직렬성, SQLServer의 스냅숏 격리 수준은 갱신 손실이 발생하면 자동으로 발견해서 문제가 되는 트랜잭션을 어보트시킨다.
그러나 MySQL(InnoDB)의 반복 읽기는 갱신 손실을 감지하지 않는다.
어떤 저자들은 DB가 스냅숏 격리를 제공하는 것으로 자격을 얻으려면 갱신 손실을 방지해야 하며, 따라서 MySQL은 이 정의에 따르면 스냅숏 격리를 제공하지 않는다고 주장한다.
갱신 손실 감지는 애플리케이션 코드에서 어떤 특별한 DB 기능도 쓸 필요가 없게 도와주므로 매우 좋은 기능이다. 잠금이나 원자적 연산을 쓰는 것을 잊어버려서 버그를 유발할 수는 있지만 자동으로 갱신 손실이 감지되어 오류가 덜 발생하게 해준다.
해결책4. Compare-and-set
트랜잭션을 제공하지 않는 DB 중에는 원자적 compare-and-set 연산을 제공하는 것도 있다.
이 연산의 목적은 값을 마지막으로 읽은 후로 변경되지 않았을 때만 갱신을 허용함으로써 갱신 손실을 회피하는 것이다. 현재 값이 이전에 읽은 값과 일치하지 않으면 갱신은 반영되지 않고 read-modify-write 주기를 재시도해야 한다.
예를 들어, 두 명의 사용자가 동시에 같은 위키 페이지를 갱신하지 못하도록 이런 방법을 시도할 수 있다. 사용자가 페이지 편집을 시작한 이후로 내용이 바뀌지 않았을 때만 갱신되게 하는 것이다.
-- DB 구현에 따라 안전할 수도 안전하지 않을 수도 있다.
UPDATE wiki_pages SET content = 'new content'
WHERE id = 1234 AND content = 'old content'
SQL
복사
내용이 바뀌어서 더는 old content와 일치하지 않으면 이 갱신은 적용되지 않는다.
따라서 갱신이 적용됐는지 확인하고 필요하다면 재시도해야 한다. 그러나 DB가 WHERE 절이 오래된 스냅숏으로부터 읽는 것을 허용한다면 이 구문은 갱신 손실을 막지 못할 수도 있다. 동시에 다른 쓰기 작업이 실행되고 있더라도 조건이 참이될 수 있기 때문이다. DB의 compare-and-set 연산에 의존하기 전에 먼저 안전한지 확인이 필요하다.
해결책5. 충돌 해소와 복제
복제가 적용된 DB에서 갱신 손실을 막는 것은 다른 차원의 문제다.
여러 노드에 데이터의 복사본이 있어서 데이터가 다른 노드들에서 동시에 변경될 수 있으므로 갱신 손실을 방지하려면 추가 단계가 필요하다.
잠금과 compare-and-set 연산은 데이터의 최신 복사본이 하나만 있다고 가정한다.
그러나 다중 리더 또는 리더 없는 복제를 사용하는 DB는 일반적으로 여러 쓰기가 동시에 실행되고 비동기식으로 복제되는 것을 허용하기에 데이터의 최신 복사본이 하나만 있으리라고 보장할 수 없다. 그런 상황에서는 잠금과 compare-and-set을 기반으로 한 기법을 적용할 수 없다.
대신 동시 쓰기 감지에서 설명했듯이 복제가 적용된 DB에서 흔히 쓰는 방법은 쓰기가 동시에 실행될 때 한 값에 대해 여러 개의 충돌된 버전(형제(sibling)라고도 한다)을 생성하는 것을 허용하고 사후에 애플리케이션 코드나 특별한 데이터 구조를 사용해 충돌을 해소하고 이 버전들을 병합하는 것이다.
원자적 연산은 복제 상황에서도 잘 동작한다. 특히 교환 법칙이 성립하는 연산이라면(즉 다른 복제본에 다른 순서로 연산을 적용해도 같은 결과가 나오는 경우) 그렇다.
예를 들어 카운터를 증가시키거나 집합에 요소를 추가하는 연산은 교환 법칙이 성립한다. 이것은 리악 2.0 자료형의 배후에 있는 아이디어로 복제본에 걸친 갱신 손실을 막아준다.
리악은 값이 여러 클라이언트에 의해 동시에 갱신될 때 어떤 갱신도 손실되지 않는 방식을 써서 자동으로 갱신을 병합한다.
반면 최종 쓰기 승리(last write wins, LWW) 충돌 해소 방법은 갱신 손실이 발생하기 쉽다.
(하지만, 많은 복제 DB는 LWW가 기본 설정이다.)
쓰기 스큐와 팬텀
더티 쓰기, 갱신 손실 말고도 동시 쓰기 작업시 발생할 수 있는 경쟁 조건은 더 있다.
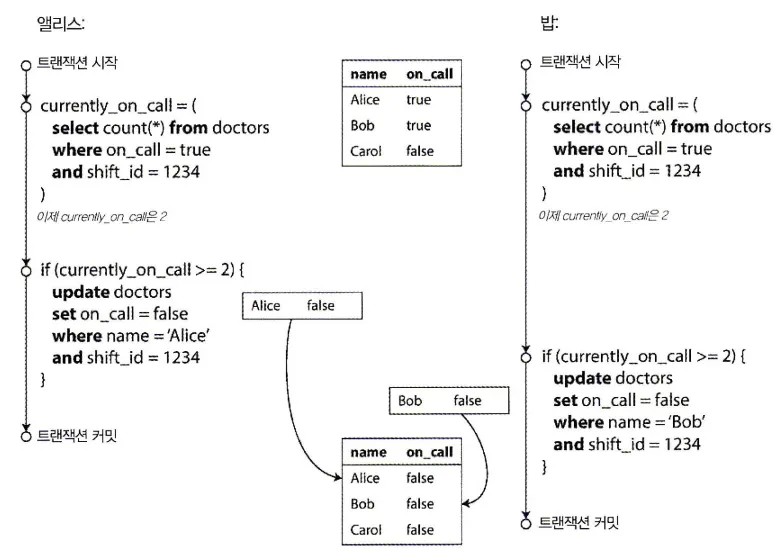
애플리케이션 버그를 유발하는 쓰기 스큐의 예
•
의사들이 병원에서 교대로 서는 호출 대기를 관리하는 애플리케이션을 만든다고 하자.
•
병원은 보통 한 시점에 여러 의사가 호출 대기 상태에 있게 하려고 하지만 최소 한 명의 의사는 반드시 호출 대기를 해야 한다.
•
의사들은 최소 한 명의 동료가 같은 교대 순번에서 호출 대기를 하고 있다면 (자기 몸이 아픈 경우)호출 대기를 그만둘 수 있다.
`위와 같은 동작을 하는 호출대기 관리 애플리케이션이 위 그림과 같이
•
앨리스와 밥이 함께 호출대기를 하고 있을 때
•
둘 다 몸이 안좋아서 호출 대기를 그만두기로 결심했다고 하고
•
거의 동시에 호출 대기 종료 버튼을 클릭한다면?
각 트랜잭션은 현재 두 명 이상의 의사가 대기중인지 확인을 하는데, 앨리스, 밥 두 명의 의사가 대기중이기에 의사 한 명이 호출 대기에서 빠져도 안전하다고 가정을 할 것이다.
DB에서는 스냅숏 격리를 사용하기에 둘 다 2를 반환하기에 두 트랜잭션 모두 다음 단계로 진행한다.
그렇게 각 트랜잭션이 모두 커밋되면 호출 대기하는 의사가 한 명도 없게 된다.
쓰기 스큐를 특징짓기
이런 이상 현상을 쓰기 스큐(write skew)라고 한다.
두 트랜잭션이 두 개의 다른 객체를 갱신하므로(앨리스와 밥이 각자 자신의 호출 대기 레코드를 갱신한다.) 더티 쓰기도 갱신 손실도 아니다.
그렇기에 충돌이 발생했다는 것이 덜 명백해 보이지만 분명히 경쟁 조건이다.
만약 두 트랜잭션이 한 번에 하나씩 실행됐다면 두 번째 의사는 호출 대기를 끄는 게 방지됐을 것이다. 트랜잭션이 동시에 실행됐기 때문에 이상 동작이 나타날 수 있었다.
쓰기 스큐를 갱신 손실 문제가 일반화된 것으로 생각할 수도 있다. 쓰기 스큐는 두 트랜잭션이 같은
객체들을 읽어서 그중 일부를 갱신할 때 나타날 수 있다. (다른 트랜잭션은 다른 객체를 갱신한다.)
다른 트랜잭션이 하나의 동일한 객체를 갱신하는 특별한 경우에( 타이밍에 따라) 더티 쓰기나 갱신 손실 이상 현상을 겪게 된다.
앞에서 갱신 손실을 막는 방법에는 여러 가지가 있다는 것을 봤다. 쓰기 스큐는 선택지가 더 제한돼있다.
•
여러 객체가 관련되므로 원자적 단일 객체 연산은 도움이 되지 않는다.
•
일부 스냅숏 격리 구현에서 제공되는 갱신 손실 자동 감지도 도움이 되지 않는다. 쓰기 스큐는 PostgreSQL의 반복 읽기, MySQL(InnoDB)의 반복 읽기, 오라클의 직렬성, SQLServer의 스냅숏 격리 수준에서 자동으로 감지되지 않는다. 쓰기 스큐를 자동으로 방지하려면 진짜 직렬성 격리가 필요하다.
•
어떤 DB에서는 제약 조건을 설정할 수 있다. 제약 조건은 DB에 의해 엄격하게 준수된다. 그러나 최소 한 명의 의사가 호출 대기를 해야 한다고 명시하려면 여러 객체와 연관된 제약 조건이 필요하다. 대부분의 DB는 이런 제약 조건 지원을 내장하지 않지만 DB에 따라 트리거나 구체화 뷰(materialized view)를 사용해 구현할 수 있다.
•
직렬성 격리 수준을 사용할 수 없다면 트랜잭션이 의존하는 로우를 명시적으로 잠그는 것이 차선책이다. 의사 문제의 경우 다음과 같은 식으로 질의를 작성할 수 있다.
BEGIN TRANSACTION;
SELECT * FROM doctors
WHERE on_call = true
AND shift_id = 1234 FOR UPDATE; -- (1)
UPDATE doctors
SET on_call = false
WHERE name = 'Alice'
AND shift_id = 1234;
COMMIT;
SQL
복사
(1) : 전처럼 FOR UPDATE는 DB에게 이 질의가 반환하는 모든 로우를 잠그라고 지시한다.
추가적인 쓰기 스큐의 예
쓰기 스큐는 처음엔 어려운 문제로 보이지만, 한 번 알고나면 쓰기스큐가 생길 수 있는 상황을 더 알아낼 수 있다. 다음 예를 보자.
회의실 예약 시스템
동시에 같은 회의실을 중복 예약할 수 없게 하고 싶다고 가정해보자. 누군가 예약을 하려고 할 때 먼저 충돌하는 예약(즉 회의실이 같고 시간대가 겹치는 예약)이 있는지 확인하고, 없다면 회의를 예약한다
BEGIN TRANSACTION;
-- 정오에서 오후 1시까지의 시간과 겹치는 예약이 존재하는지 확인
SELECT COUNT(*) FROM bookings
WHERE room_id = 123
AND end_time > '2022-01-01 12:00' AND start_time < '2022-01-01 13:00';
-- 이전 질의가 0을 반환했다면
INSERT INTO bookings (room_id ,start_time, end_time, user_id)
VALUES(123, '2022-01-01 12:00', '2022-01-01 13:00', 666);
COMMIT;
SQL
복사
회의실 예약 시스템은 중복된 예약을 피하려고 한다(스냅숏 격리에서는 안전하지 않다.)
결과부터 말하자면, 스냅숏 격리는 다른 사용자가 동시에 충돌되는 회의를 삽입하는걸 막아줄 수 없다. 스케줄이 충돌하지 않도록 보장하기 위해서는 다시 한 번 직렬성 격리가 필요하다.
다중 플레이어 게임
갱신 손실을 막기 위해 잠금을 사용한다고 할 때 잠금은 플레이어들이 두 개의 다른 물체를 게임판 위의 같은 위치로 옮기거나 잠재적으로 게임의 규칙을 위반하는 다른 이동을 하는 것을 막아주진 않는다.
준수하고자 하는 규칙의 종류에 따라 유일성 제약을 쓸 수 있을지도 모르지만 그렇지 않으면 쓰기 스큐에 취약하다.
사용자명 획득
각 사용자가 유일한 사용자명을 가져야 하는 웹사이트에서 두 명의 사용자가 동시에 같은 사용자명으로 계정 생성을 시도할 수 있다.
트랜잭션을 사용해 이름이 점유됐는지 확인하고 그렇지 않으면 그 이름으로 생성할 수 있다. 하지만 앞의 예와 마찬가지로 스냅숏 격리에선 안전하지 않다. 여기서는 유일성 제약 조건이 간단한 해결책이다.
⇒ 사용자명을 등록하려고 하는 두 번쨰 트랜잭션은 제약 조건을 위반해 어보트된다.
이중 사용(double-spending) 방지
사용자가 돈이나 포인트를 지불할 수 있는 서비스는 사용자가 갖고 있는 것보다 더 많이 지불하지 않는지 확인해야 한다.
지불 예정 항목을 사용자 계좌에 삽입하고 그 계좌에 있는 모든 항목을 나열한 후 그 합이 양수인지 확인하는 확인하는 방법으로 구현하려고 할지도 모르겠다. 쓰기 스큐가 발생하면 동시에 삽입된 두 개의 지불 항목이 모여서 잔고가 음수가 되게 하는 일이 생길 수 있지만 어떤 트랜잭션도 다른 쪽에 알려주지 못한다.
쓰기 스큐를 유발하는 팬텀
위에서 언급한 여러 쓰기 스큐의 예는 다음과 같은 패턴을 따른다.
1.
SELECT 질의가 어떤 검색 조건에 부합하는 로우를 검색함으로써 어떤 요구사항을 만족하는지 확인한다.
2.
첫 번째 질의의 결과에 따라 애플리케이션 코든느 어떻게 진행할지 결정한다.
3.
애플리케이션이 계속 처리하기로 결정했다면 DB에 쓰고 트랜잭션을 커밋한다.
a.
쓰기 이후 2단계가 결정되는 조건들이 변하게 된다.
이와같이 어떤 트랜잭션에서 실행한 쓰기가 다른 트랜잭션의 검색 질의 결과를 바꾸는 효과를 팬텀(PHANTOM)이라고 한다.
스냅숏 격리는 읽기 전용 질의에서는 팬텀을 회피하지만, 읽기 쓰기 트랜잭션에서는 팬텀이 쓰기 스큐의 특히 까다로운 경우를 유발할 수 있다.
충돌 구체화
팬텀의 문제가 잠글 수 있는 객체가 없다는 것이라면 인위적으로 DB에 잠금 객체를 추가할 수 있지 않을까?
회의실 예약의 경우 시간 슬롯과 회의실에 대한 테이블을 만드는 것을 생각해보자.
•
테이블의 각 로우는 특정한 시간 범위(Ex: 15분) 동안 사용되는 특정한 회의실에 해당한다.
•
회의실과 시간 범위의 모든 조합에 대해 로우를 미리 만들어둘 수 있다.
•
예약 트랜잭션은 테이블에서 원하는 회의실과 시간 범위에 해당하는 로우를 잠글 수 있다.(SELECT FOR UPDATE)
•
잠금을 획득한 후 전처럼 겹치는 예약이 있는지 확인 후 새 예약을 삽입할 수 있다.
◦
추가된 테이블은 예약 정보를 저장하는 데 사용되지 않는다.
◦
단지 회의실과 시간 범위가 동일한 예약이 동시에 변경되는 것을 막는 데 사용하는 잠금의 모음일 뿐이다.
이러한 해결책을 충돌 구체화(materializing conflict)라고 한다.
팬텀을 DB에 존재하는 구체적인 로우 집합에 대한 잠금 충돌로 변환하기 때문이다.
유감스럽게도 충돌을 구체화하는 방법은 알아내기 어렵고 오류가 발생하기 쉽다. 그리고 동시성 제어 메커니즘이 애플리케이션 데이터 모델로 새어 나오는 것도 보기 좋지 않다.
그래서 충돌 구체화는 다른 대안이 불가능할 때 최후의 수단으로 고려해야 한다. 대부분의 경우에 직렬성 격리 수준이 훨씬 더 선호된다.
직렬성
이번 챕터에서 경쟁 조건을 유발하기 쉬운 트랜잭션의 예를 몇 가지 살펴봤다.
어떤 경쟁 조건은 커밋 후 읽기나 스냅숏 격리 수준으로 방지되지만, 쓰기 스큐와 팬텀과 관련된 특히나 까다로운 경우도 있다.
이런 내용들은 더욱이나
•
격리 수준은 이해하기 어렵고 DB마다 구현에 일관성이 없다.
•
애플리케이션 코드를 보고 특정한 격리 수준에서 해당 코드를 실행하는게 안전한지 알기 어렵고 특히 동시에 일어나는 모든 일을 알지 못할 수도 있는 거대한 애플리케이션은 더 그렇다.
•
경쟁 조건을 감지하는 데 도움이 되는 좋은 도구가 없다. 동시성 문제는 보통 비결정적이라서 테스트하기가 어렵다.
이런 문제들은 쭉 있어왔고, 이에 대한 응답도 쭉 간단했다.
직렬성 격리를 사용하자.
직렬성 격리는 가장 강력한 격리 수준으로 알려져 있는데, 트랜잭션들이 병렬 실행이 되더라도 최종 결과는 동시성 없이 한 번에 하나씩 직렬로 실행될 때와 같도록 보장한다.
즉, DB가 발생할 수 있는 모든 경쟁 조건을 막아준다.
각각의 여러 DB들은 대부분 다음 세 가지 기법
•
트랜잭션 순차적 실행
•
2단계 잠금(2PL)
•
낙관적 동시성 제어(optimistic concurrency control)
중에서 하나를 사용한다. 이번 챕터에선 단일 노드 DB의 관점에서 기술들을 설명한다.
그리고 이렇게 완벽해보이는 직렬성 격리를 모두 사용하는건 아닌 이유도 알아보도록 하자.
실제적인 직렬 실행

동시성 문제를 피하는 가장 간단한 방법은 동시성을 제거하는 것이다.
한 번에 트랜잭션 하나씩만 직렬로 단일 스레드에서 실행하면 된다. 그러면 트랜잭션 사이의 충돌을 감지하고 방지하는 문제를 완전히 회피할 수 있다. 결과적으로 격리 수준은 당연히 직렬성 격리가 된다.
최근(2007)에서야 단일 스레드 루프에서 트랜잭션을 실행하는게 실현 가능하다고 결론내려졌는데,
과거 높은 성능을 위해 다중 스레드 동시성이 필수적인 것으로 여겨졌는데 단일 스레드 실행이 가능하게 된 이유는 무엇일까?
•
램 가격이 저렴해져서
◦
많은 사용사례에서 활성화된 데이터셋 전체를 메모리에 유지할 수 있을 정도가 되었고,
◦
트랜잭션이 접근해야 할 데이터가 메모리에 있다면 훨씬 빠르게 트랜잭션이 실행될 수 있다.
•
OLTP 트랜잭션이 보통 짧고 실행하는 읽기와 쓰기의 개수가 적고,
◦
오래 실행되는 분석 질의는 전형적으로 읽기 전용이라 직렬 실행 루프 밖에서
▪
스냅숏 격리를 사용해 일관된 스냅숏을 사용해 실행할 수 있다.
트랜잭션을 순차적으로 실행하는 방법은
•
볼트DB/H-스토어
•
레디스
•
데이토믹
에서 구현되어 있으며, 이렇게 단일 스레드로 실행되도록 설계된 시스템이 오히려 동시성을 지원하는 시스템보다 성능부분에서 우위를 점할수도 있다. 왤까?
잠금을 코디네이션하는 오버헤드를 피할 수 있기 때문이다.
물론, 이들의 처리량은 CPU 코어 하나의 처리량으로 제한되기에 단일 스레드를 활용하려면 트랜잭션이 전통적인 형태와는 다르게 구조화돼야 한다.
트랜잭션을 스토어드 프로시저 안에 캡슐화하기

항공권 예약은 여러 과정(장소선택, 날짜선택, 탑승정보선택, 지불하기등)을 거쳐야 한다.
DB 초창기에는 DB 트랜잭션이
•
사용자 활동의 전체적인 흐름을 포함하려 했다.
•
여러 단계의 과정을 가지는 경우(Ex: 항공권 예약)
•
각 과정들이
◦
하나의 트랜잭션으로 표현되고
◦
원자적으로 커밋될 수 있다면
•
깔끔하다고 생각했다.
하지만, 불행하게도…
사람은 모든 과정을 반응하고 결정하는데 (컴퓨터 기준) 오랜 시간이 걸린다.
그렇다면,
•
트랜잭션은 사용자의 입력을 기다려야 하고,
•
DB는 유휴 상태이면서 잠재적인 동시 실행 트랜잭션을 지원해야 한다.
하지만,
•
대부분의 DB는 이를 효율적으로 처리할 수 없기에
•
대부분의 OLTP 애플리케이션은 트랜잭션 내에서
◦
대화식으로 사용자 응답을 대기하는 것을 회피함으로써 트랜잭션을 짧게 유지한다.
◦
웹의 경우 동일한 HTTP 요청 내에서 커밋된다는 뜻으로 하나의 요청은 하나의 트랜잭션이라 볼 수 있다.
물론, 사람이 주요 경로(critical path)에서 제외되었지만 트랜잭션은 계속 상호작용하는 클라이언트/서버 스타일로 실행돼 왔다. 한 번에 구문 하나씩을 실행하는 방식이다.
Device 1
Application: 질의 요청
상호작용Device 2
DB Server: 질의 처리 및 응답
DB에서 동시성을 허용하지 않고 한 번에 하나의 트랜잭션을 처리하면,
•
DB가 애플리케이션의 현재 트랜잭션의 다음 질의를 발행하기를 대기하는데, 대부분의 시간을 쓰게 되며 처리량은 몹시 떨어지게 된다.
그래서 단일 스레드에서 트랜잭션을 순차적으로 처리하는 시스템들은
상호작용하는 다중 구문 트랜잭션을 허용하지 않는다.
대신 애플리케이션은 트랜잭션 코드 전체를 스토어드 프로시저 형태로 DB에 미리 제출해야 한다. 다음 그림을 보자.
트랜잭션에 필요한 데이터는 모두 메모리에 있고, 스토어드 프로시저는 네트워크나 디스크I/O 대기 없이 매우 빨리 실행된다고 가정한다.
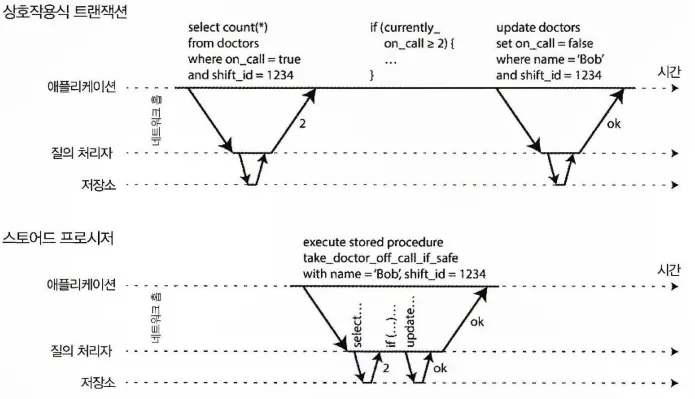
상호작용식 트랜잭션과 스토어드 프로시저의 차이점
스토어드 프로시저의 장단점
스토어드 프로시저는 꽤 다양한 이유로 안좋은 평가를 받고 있다.
•
DB 벤더마다 스토어드 프로시저용 언어가 있는데,
◦
범용 프로그래밍 언어의 발전을 따라잡지 못해서 조잡하며, 라이브러리 생태계가 빈약하다.
•
DB에서 실행되는 코드는 관리하기가 어렵다. (디버깅, 버전 관리, 배포, 테스트, 모니터링)
•
DB는 성능에 더 민감하기에 (애플리케이션과 보통 1:N 관계이기에 ) 잘못된 스토어드 프로시저는 애플리케이션보다 큰 문제가 될 수 있다.
하지만, 현대의 스토어드 프로시적 구현은 기존의 범용 프로그래밍 언어를 사용할 수 있도록 하고 있다. 예를 들어,
•
볼트DB는 Java, Groovy를 사용하고,
•
데이토믹은 Java, Clojure 를 사용하고,
•
레디스는 Lua를 사용한다.
그래서,
•
범용 프로그래밍 언어를 사용하는 스토어드
•
메모리에 저장되는 데이터
라는 조건하에 트랜잭션들을 단일 스레드에서 실행한다는 생각은 현실성을 가질 수 있고, 좋은 성능(처리량)도 기대할 수 있다.
파티셔닝
모든 트랜잭션을 순차적으로 실행하면 동시성 제어는 훨씬 간단해지지만 DB의 트랜잭션 처리량이 단일 장비에 있는 단일 CPU 코어의 속도로 제한된다.
읽기 전용 트랜잭션은 스냅숏 격리를 사용해 다른 곳에서 실행될 수 있지만, 쓰기 처리량이 높은 애플리케이션에선 단일 스레드 트랜잭션 처리자가 심각한 병목이 될 수 있다.
여러 CPU 코어와 여러 노드로 확장하기 위해 데이터를 파티셔닝 할 수도 있다.
각 트랜잭션이 단일 파티션 내에서만 데이터를 읽고 쓰도록 데이터셋을 파티셔닝 할 수 있다면 각 파티션은 다른 파티션과 독립적으로 실행되는 자신만의 트랜잭션 처리 스레드를 가질 수 있다. 이 경우 각 CPU 코어에 각자의 파티션을 할당해 트랜잭션 처리량을 CPU 코어 개수에 맞춰 선형적으로 확장할 수 있다.
하지만, 여러 파티션에 접근해야 하는 트랜잭션이 있을 경우, DB는 해당 트랜잭션이 접근하는 모든 파티션에 걸쳐 코디네이션을 해야 한다. 스토어드 프로시저는 전체 시스템에 걸쳐 직렬성을 보장하기 위해 모든 파티션에 걸쳐 잠금을 획득한 단계에서 실행돼야 한다.
여러 파티션에 걸친 트랜잭션은 추가적인 코디네이션 오버헤드가 있기에 단일 파티션 트랜잭션보다 매우 느리다. 트랜잭션이 단일 파티션에서 실행될 수 있는지에 대한 여부는 애플리케이션에서 사용되는 데이터 구조에 매우 크게 의존한다.
단순한 키-값 데이터는 파티셔닝이 쉽지만, 여러 보조 색인이 있는 데이터는 여러 파티션에 걸친 코디네이션이 많이 필요할 수 있다.
직렬 실행 요약
트랜잭션 직렬 실행은 몇 가지 제약 사항 안에서 직렬성 격리를 획득하는 실용적인 방법이 됐다.
•
모든 트랜잭션은 작고 빨라야 한다. (꼬리 지연 시간 증폭)
•
활성화된 데이터셋이 메모리에 적재될 수 있는 경우로 사용이 제한된다.
•
쓰기 처리량이 단일 CPU코어에서 처리할 정도로 충분히 낮아야 한다.
◦
그렇지 않으면 여러 파티션에 걸친 코디네이션이 필요하지 않도록 트랜잭션 파티셔닝이 필요해진다.
•
여러 파티션에 걸친 트랜잭션도 쓸 수 있지만 제한이 엄격하다.
2단계 잠금(2PL)
2PL ≠ 2PC
2단계 잠금(2PL)과 2단계 커밋(two-phase commit, 2PC)는 비슷하게 보이지만 완전히 다르다.
2단계 잠금은 기존 잠금과 비슷하지만, 잠금 요구사항이 더 강하다.
쓰기를 실행하는 트랜잭션이 없는 객체는 여러 트랜잭션에서 동시에 읽을 수 있지만, 객체에 쓰기를 하려고 하면 독점적인 접근이 필요하다.
그리고, 잠금이 풀리길 기다리는 트랜잭션은 2PL에서는 객체의 과거 버전을 읽는 것도 금지된다.
2PL에서 쓰기 트랜잭션은 다른 쓰기 트랜잭션 뿐 아니라 읽기 트랜잭션도 진행하지 못하게 막고 그 역도 성립한다. 이는 스냅숏 격리의 읽는 쪽과 쓰는 쪽 양 측이 서로를 막지 않는다는 원칙과 큰 차이점이다.
다만, 이 차이점으로 인해 2PL은 직렬성을 제공하고 앞에서 설명한 갱신 손실과 쓰기 스큐를 포함한 모든 경쟁 조건으로부터 보호해준다.
2단계 잠금 구현
2PL은
•
MySQL(InnoDB), SQLServer에서 직렬성 격리 수준을 구현하는데 사용되고,
•
DB2에서 반복 읽기 격리 수준을 구현하는데 사용된다.
읽기/쓰기 양 쪽을 막는 것은 DB의 각 객체에 잠금을 사용해 구현한다.
잠금은 공유 모드(shared mode)나 독점 모드(exclusive mode)로 사용될 수 있다.
잠금은 다음과 같이 사용된다.
•
트랜잭션이 객체를 읽기 원할 경우 공유 모드로 잠금을 획득해야 한다.
◦
동시에 여러 트랜잭션이 공유 모드로 잠금을 획득하는 것은 가능하다.
◦
독점 모드로 잠금이 있을 경우 완료될 때까지 기다려야 한다.
•
트랜잭션이 객체에 쓰기를 원한다면 독점 모드로 잠금을 획득해야 한다.
◦
다른 어떤 트랜잭션도 잠금을 동시에 획득할 수 없기에 모드에 상관없이 객체에 잠금이 있을 경우 대기해야 한다.
•
트랜잭션이 객체를 읽다가 쓰기를 실행할 때는 공유 → 독점으로 잠금을 업그레이드 해야한다.
•
트랜잭션이 잠금을 획득한 후에는 종료될 때까지 잠금을 가지고 있어야 한다.
◦
잠금을 획득할 때, 잠금을 해제할 때를 합쳐 2단계 잠금이라 한다.
교착 상태
트랜잭션 A는 트랜잭션 B의 잠금이 해제되기를 기다리고,
트랜잭션 B는 트랜잭션 A의 잠금이 해제되기를 기다리면서 멈춰 있는 상황을 교착 상태라 한다. DB는 이런 교착 상태를 자동으로 감지 후 하나의 트랜잭션을 어보트시켜 다른 트랜잭션들이 진행할 수 있게 하며, 이 때 어보튿된 트랜잭션은 애플리케이션에서 재시도해야 한다.
2단계 잠금의 성능
2단계 잠금은 잠금을 획득하고 해제하는 2 단계에서 오버헤드가 발생하고, 동시성이 낮아지는 이유로 성능 부분에서 약점을 가진다.
그렇기에 2PL을 실행하는 DB는 작업부하에 경쟁이 있다면 지연 시간이 아주 불안정하고 높은 백분위에서 매우 느릴 수 있다. 트랜잭션 하나만 느릴 수 있고, 한 트랜잭션이 많은 데이터에 접근하고 잠금을 많이 획득해 시스템의 다른 부분이 서서히 멈추도록 만들 수도 있다.
또한, 교착 상태에서 트랜잭션이 어보트되어 재시도할 경우 작업을 전부 다시 해야한다.
서술 잠금
직렬성 격리를 쓰는 DB는 팬텀(phantom)을 막아야 한다.
어떻게?
개념상으로는 서술 잠금(predicate lock)이 필요하다.
서술 잠금은 위에서 설명한 공유/독점 잠금과 비슷하게 동작하지만 특정 객체(Ex: 테이블 내의 한 로우)에 속하지 않고 다음과 같이 어떤 검색 조건에 부합하는 모든 객체에 속한다.
SELECT *
FROM bookings
WHERE room_id = 123
AND end_time > '2018-01-01 12:00'
AND start_time < '2018-0101 13:00';
SQL
복사
서술 잠금이 접근을 제한 하는 방법은
•
트랜잭션 A가 어떤 조건에 부합하는 (WHERE …) 객체를 읽기 원한다면 질의의 조건에 대한 공유 모드 서술 잠금을 획득해야 한다.
◦
여기서도 다른 트랜잭션이 독점 잠금을 가지고 있으면 기다려야 한다.
•
트랜잭션 A가 어떤 객체를 삽입, 갱신, 삭제하길 원한다면, 기존 값 혹은 새로운 값 중에 기존의 서술 잠금에 부합하는게 있는지 확인이 필요하다.
◦
다른 트랜잭션에서 부합하는 서술 잠금을 가지고 있을 경우 마찬가지로 기다려야 한다.
이 서술 잠금(predicate lock)의 가장 중요한 점은 현재의 데이터 뿐 아니라
미래에 추가될 수 있는 객체(팬텀)에도 적용할 수 있다는 것이다.
색인 범위 잠금
현재가 아닌 미래의 데이터까지 잠금을 적용한다는 서술 잠금의 개념은 좋아보이지만, 진행중인 트랜잭션들이 획득한 잠금이 많을수록 조건에 부합하는 잠금을 확인하는데 시간이 오래 걸릴 수 밖에 없다.
그렇기에 대부분의 DB는 실제로는 색인 범위 잠금(index-range locking, 다음 키 잠금(next-key locking)이라고도 한다) 을 구현한다. 이것은 서술 잠금을 간략하게 근사한 것이다.
•
정오와 오후 1시 사이 123번 방을 예약하는 것에 대한 서술 잠금은
◦
모든 시간 범위에 123번 방을 예약하는 것에 대한 잠금으로 근사할 수 있다.
◦
또는, 정오와 오후 1시 사이에 모든 방을 잠그는 것으로 근사할 수도 있다.
어떤 방법을 사용하던 간략화한 검색 조건이 색인 중 하나에 붙으며 다른 트랜잭션이 같은 방을 사용하거나 시간이 겹치는 예약을 삽입, 갱신, 삭제하길 바란다면 색인의 같은 부분을 갱신해야 한다. 이 과정에서 공유 잠금을 발견하고 잠금이 해제될 때까지 기다리게 된다.
이 방법을 쓰면 팬텀과 쓰기 스큐로부터 보호해주는 효과를 낳는다.
서술잠금보다 정밀하지는 않지만 오버헤드가 더 낮기에 좋은 타협안이 된다.
직렬성 스냅숏 격리(SSI)
완화된 격리수준은 높은 성능에 비해 경쟁 조건에 취약하다.
직렬성 격리는 경쟁 조건에 안전하지만 성능 혹은 확장성에 취약하다.
이 둘의 장점이 공존하는 직렬성 스냅숏 격리(serializable snapshot isolation, SSI)라는 알고리즘이 있다. 완전한 직렬성도 제공하면서 스냅숏 격리에 비해 약간 떨어지지만 좋은 성능을 보여준다.
이 SSI는 단일 노드 데이터베이스나 분산 데이터베이스에서 모두 사용되는데, 아직 역사가 짧기에 실무에서 성능을 증명하는 중이지만, 앞으로가 기대되는 알고리즘이다.
비관적 동시성 제어 대 낙관적 동시성 제어
2단계 잠금은 이른바 비관적 동시성 제어 메커니즘이다.
잘못될 가능성이 보일 경우 무리하지 않고 안전해질 때까지 기다린다는 원칙을 기반으로 한다.
직렬 실행에서 트랜잭션이 실행되는 동안 전체 DB에 독점 잠금을 획득하는 것도 같은 개념으로 볼 수 있다. 여기서는 트랜잭션이 아주 빨리 실행되도록 해서 잠금시간을 줄이는 방법으로 비관주의를 보완한다.
이에 반해 직렬성 스냅숏 격리는 낙관적 동시성 제어 기법이다.
위험한 상황이 발생할 가능성이 있을 때 트랜잭션을 막는 대신 괜찮아질 것이라는 희망으로 계속 진행한다는 의미이다.
경쟁이 심해질 경우 어보트시켜야 할 트랜잭션의 비율이 높아지면 성능이 떨어질 수 밖에 없는데, 시스템이 이미 최대 처리량에 근접했다면 재시도되는 트랜잭션으로부터 발생하는 부가적인 트랜잭션 부하가 성능을 저하시킬 수 있다.

낙관적인 모습
하지만 예비 용량이 충분하고 트랜잭션 사이의 경쟁이 너무 심하지 않으면 낙관적 동시성 제어 기법은 비관적 동시성 제어보다 성능이 좋은 경향이 있다.
경쟁은 가환(commutative) 원자적 연산을 써서 줄일 수 있다.
SSI는 스냅숏 격리를 기반으로 하기에 트랜잭션에서 실행되는 모든 읽기는 DB의 일관된 스냅숏을 보게 된다. 이 부분이 이전의 낙관적 동시성 제어 기법과 크게 다른 점이다.
SSI는 스냅숏 격리 위에 쓰기 작업 사이의 직렬성 충돌을 감지하고 어보트시킬 트랜잭션을 결정하는 알고리즘을 추가한다.
뒤처진 전제에 기반한 결정
위에서 스냅숏 격리에서 나타나는 쓰기 스큐를 설명할 때 반복되는 패턴이 있었다.
- 트랜잭션이 데이터베이스에서 어떤 데이터를 읽고,
- 그 질의 결과를 조사한 후
- 관찰한 결과를 기반으로 어떤 동작을 취할지 결정한다.
- 하지만, 스냅숏 격리하에선 트랜잭션이 커밋되는 시점에서
- 도중에 데이터가 변경됐을 수 있기 때문에
- 원래 질의의 결과가 더 이상 최선이 아닐 수 있다.
Plain Text
복사
스냅숏 격리에서 나타나는 쓰기 스큐에 반복되는 패턴
바꿔 말하면 트랜잭션은 어떤 전제를 기반으로 동작을 하는데, 나중에 커밋하는 시점에는 원래 데이터가 바뀌어 전제가 동일하지 않을 수 있다.
즉, DB는 직렬성 격리를 제공하기 위해 트랜잭션이 뒤처진 전제를 기반으로 동작하는 상황을 감지하고 트랜잭션을 어보트 시켜야 한다.
그렇다면 DB는 어떻게 질의 결과가 바뀌었는지 알 수 있을까?
•
오래된(stale) MVCC 객체 버전을 읽었는지 감지하기(읽기 전 커밋되지 않은 쓰기가 발생)
•
과거의 읽기에 영향을 미치는 쓰기 감지하기(읽은 후 쓰기가 실행)
오래된 MVCC 읽기 감지하기
스냅숏 격리는 보통 다중 버전 동시성 제어로 구현한다.
트랜잭션이 MVCC DB의 일관된 스냅숏에서 읽으면 스냅숏 생성 시점에 다른 트랜잭션이 썼지만 아직 커밋되지 않은 데이터는 무시한다. 다음 그림을 보면 트랜잭션 43은 앨리스가 on_call이 true 상태인 것으로 보게 된다.
하지만 트랜잭션 43이 커밋하기를 원할때는 트랜잭션 42가 커밋된 상태다.
일관된 스냅숏에서 읽을 땐 무시했던 쓰기지만 지금은 영향이 있고 트랜잭션 43의 전제가 더 이상 참이 아니게 된다.
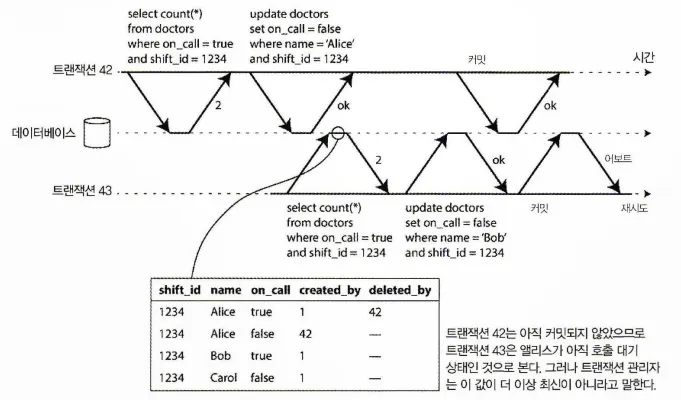
트랜잭션 MVCC 스냅숏에서 뒤처진 값을 읽었는지 감지하기
트랜잭션이 커밋하려고 할 때 DB는 무시된 쓰기 중 커밋된 게 있는지 확인이 필요하다.
커밋된 게 있다면 트랜잭션은 어보트 돼야 한다.
왜 커밋할 때까지 기다려야 할까? 왜 오래된 읽기가 감지됐을 때 트랜잭션 43을 바로 어보트시키지 않을까?트랜잭션 43이 읽기 전용 트랜잭션이라면 쓰기 스큐의 위험이 없기에 어보트될 필요는 없다. 트랜잭션 43이 읽기를 실행하는 시점에 DB는 그 트랜잭션이 나중에 쓰기를 실행할 지 알 수 없다. 게다가 트랜잭션42는 어보트될 수도 있고 트랜잭션 43이 커밋되는 시점에 아직 커밋되지 않았을 수도 있다.
따라서 결국에는 읽기가 오래되지 않은 것으로 밝혀질수도 있다. SSI는 불필요한 어보트를 피해서 일관된 스냅숏에서 읽으며 오래 실행되는 작업을 지원하는 스냅숏 격리의 특성을 유지한다.
과거의 읽기에 영향을 미치는 쓰기 감지하기
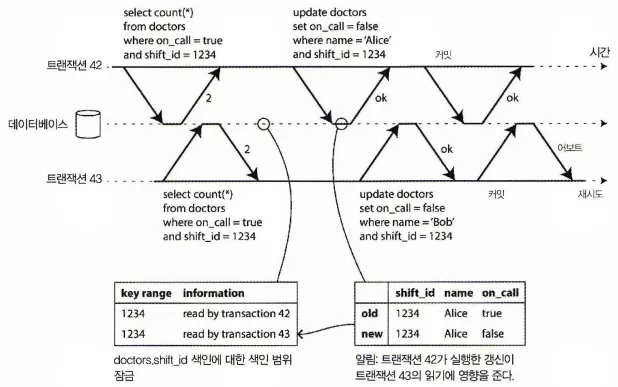
직렬성 스냅숏 격리에서 트랜잭션이 다른 트랜잭션이 읽은 데이터를 변경하는 경우 감지
데이터를 읽은 후 다른 트랜잭션에서 그 데이터를 변경하려는 경우를 고려해야 하는데, 위 그림을 보면 2단계 잠금의 맥락에서 DB가 shift_id가 1234인 모든 로우에 대해 접금을 잠글 수 있는 색인 범위 잠금을 설명했다.
SSI 잠금은 다른 트랜잭션을 차단하지 않는다는 것만 제외하고 여기서도 비슷한 기법을 사용할 수 있다.
트랜잭션42, 트랜잭션43모두 대기 순번 1234 동안의 호출 대기 의사를 검사한다. shift_id에 색인이 있으면 DB가 색인 항목 1234를 사용해 트랜잭션42, 트랜잭션43이 이 데이터를 읽었다는 사실을 기록할 수 있다. (색인이 없으면 이 정보를 테이블 수준에서 추적할 수 있다. )
이 정보는 잠시 동안만 유지하면 된다. 트랜잭션이 완료되고 동시에 실행되는 모든 트랜잭션이 완료된 후 DB는 트랜잭션에서 어떤 데이터를 읽었는지 잊어도 된다.
트랜잭션이 DB에 쓸 때 영향받는 데이터를 최근에 읽은 트랜잭션이 있는지 색인에서 확인해야 한다. 이 과정은 영향받는 키 범위에 쓰기 잠금을 획득하는 것과 비슷하지만 읽는 쪽에서 커밋될 때까지 차단하지 않는다. 이 잠금은 지뢰선(tripwrie)처럼 동작한다.
트랜잭션이 읽은 데이터가 더 이상 최신이 아니라고 트랜잭션에게 알려줄 뿐이다.
위 그림에서 트랜잭션 43은 트랜잭션 42에게 전에 읽은 데이터가 뒤처졌다고 알려주고 트랜잭션 42도 트랜잭션 43에게 알려준다. 트랜잭션 42가 먼저 커밋을 시도해서 성공한다. 트랜잭션 43이 실행한 쓰기는 트랜잭션 42에 영향을 주지만 트랜잭션 43은 아직 커밋되지 않았기에 쓰기는 아직 효과가 없다.
하지만 트랜잭션 43이 커밋하기 원할 때는 트랜잭션 42의 충돌되는 쓰기가 이미 커밋됐기에 트랜잭션 43은 어보트돼야 한다.
직렬성 스냅숏 격리의 성능
직렬성 스냅숏 격리는 트랜잭션의 읽기 쓰기 추적 세밀도가 트레이드 오프다.
•
세밀함이 높아질수록
◦
DB는 각 트랜잭션의 동작을 상세하게 추적하면서 어보트돼야 하는 트랜잭션을 정확하게 판단할 수 있지만,
◦
기록 오버헤드가 심해질 수 있다.
•
세밀함이 낮아질수록
◦
빠르지만,
◦
진짜 필요한 것보다 지나치게 많은 트랜잭션이 어보트될 수 있다.
어떤 경우에는 다른 트랜잭션에서 덮어쓴 정보를 트랜잭션이 읽어도 괜찮다.
상황에 따라 데이터가 덮어쓰여졌어도 실행 결과가 직렬적이라는 것을 증명하는게 가능하다.
(PostgreSQL은 불필요한 어보트 개수를 줄이기 위해 이 이론을 사용한다.)
2단계 잠금과 비교할 때 직렬성 스냅숏 격리의 큰 이점은
•
트랜잭션이 다른 트랜션들이 잡고 있는 잠금을 기다리느라 차단되지 않아도 된다.
•
스냅숏 격리하에서와 마찬가지로 읽기/쓰기 양 측에서 서로를 막지 않는다.
◦
질의 시간 예측이 쉽고 변동이 적게 만든다.
순차 실행과 비교할 때 직렬성 스냅숏 격리는
•
단일 CPU 코어에 처리량에 제한되지 않는다.
•
데이터가 여러 장비에 걸쳐 파티셔닝 되어 있더라도
◦
트랜잭션은 직렬성 격리를 보장하며
◦
여러 파티션으로부터 읽고 쓸 수 있다.
어보트 비율은 SSI의 전체적인 성능에 큰 영향을 미친다.
진행 시간이 긴 트랜잭션은
•
충돌이 날 확률이 높고
•
어보트되기도 쉽기 때문에
SSI는 읽기/쓰기 트랜잭션이 상당히 짧기를 요구한다.
그래도 SSI는 2단계 잠금이나 순차 실행보다는 느린 트랜잭션에 덜 민감할 것이다.
정리
트랜잭션은 애플리케이션이 어떤 동시성 문제와 어떤 종류의 HW, SW결함이 존재하지 않는 것처럼 동작할 수 있도록 도와주는 추상층(Abstract Layer)이다.
많은 종류의 오류가 간단한 트랜잭션 어보트로 줄어들고 애플리케이션은 재시도만 하면 된다.
접근 패턴이 복잡해질수록 트랜잭션은 잠재적인 오류 상황의 수를 줄여줄 수 있다.
다음과 같이 다양한 격리 수준들이 있었는데,
•
더티 읽기(dirty read)
◦
한 클라이언트가 다른 클라이언트가 썼지만 아직 커밋되지 않은 데이터를 읽는다.
◦
커밋 후 읽기 or 더 강한 격리 수준은 더티 읽기를 방지한다.
•
더티 쓰기(dirty write)
◦
한 클라이언트가 다른 클라이언트가 썼지만 아직 커밋되지 않은 데이터를 덮어쓴다.
◦
거의 모든 트랜잭션 구현은 더티 쓰기를 방지한다.
•
읽기 스큐(비반복 읽기)
◦
클라이언트는 다른 시점에 DB의 다른 부분을 본다. 이 문제를 막기 위해
▪
트랜잭션이 어느 시점의 일관된 스냅숏으로부터 읽는 스냅숏 격리를 많이 사용한다.
◦
•
갱신 손실
◦
두 클라이언트가 동시에 read-modify-write 주기를 실행한다.
◦
한 트랜잭션이 다른 트랜잭션의 변경을 포함하지 않은 채로
▪
다른 트랜잭션이 쓴 내용을 덮어써서 데이터가 손실된다.
▪
스냅숏 격리의 구현 중 어떤 것은 이런 현상을 자동으로 막아주지만, 그렇지 않은 것은 수동 잠금(SELECT FOR UPDATE)이 필요하다.
•
쓰기 스큐(write skew)
◦
트랜잭션이 무언가를 읽고 읽은 값을 기반으로 어떤 결정을 하고 그 결정을 DB에 쓴다.
◦
하지만 쓰기를 실행하는 시점에선 결정의 전제가 더 이상 참이 아니다.
◦
직렬성 격리에서만 이런 현상을 막을 수 있다.
•
팬텀 읽기(phantom read)
◦
트랜잭션이 어떤 검색 조건에 부합하는 객체를 읽는다.
◦
다른 클라이언트가 그 검색 결과에 영향을 주는 쓰기를 실행한다.
◦
스냅숏 격리는 간단한 팬텀 읽기는 막아주지만 쓰기 스큐 맥락에서 발생하는 팬텀은 색인 범위 잠금처럼 특별한 처리가 필요하다.
완화된 격리 수준은 위와 같은 이상 현상을 일부만 막아주기에 나머지는 애플리케이션에서 처리해줘야 한다.(Ex: 명시적인 잠금)
직렬성 격리는 이 모든 문제들로부터 보호해줄 수 있으며 직렬성 트랜잭션을 구현하는 방법으로는
•
트랜잭션을 순서대로 실행하기
◦
트랜잭션의 실행 시간이 짧고 처리량이 단일 CPU 코어에서 처리할 수 있을 정도면 좋은 선택이다.
•
2단계 잠금(2PL)
◦
오랫동안 직렬성을 구현하는 표준적인 방법이지만 성능 문제로 사용을 피하는 애플리케이션이 많다.
•
직렬성 스냅숏 격리(SSI)
◦
위의 두 가지 방법의 장점만 합친 새로운 알고리즘이다.
◦
낙관적 방법을 사용해 트랜잭션이 차단되지 않고 진행할 수 있게 한다.
◦
트랜잭션이 커밋을 원할 때 트랜잭션을 확인해서 실행이 직렬적이지 않다면 어보트 시킨다.

