

목차
1. 인덱스 설정
인덱스 설정

GET [인덱스 이름]/_settings
Bash
복사
•
number_of_shard
◦
인덱스가 데이터를 몇 개의 샤드로 분리할 지 지정
◦
reindex를 하지 않는한 바꿀 수 없다.
•
number_of_replicar
◦
샤드 하나당 복제본 샤드의 갯수 지정
◦
변경이 가능하다.
PUT [인덱스 이름]/_settings
{
[변경 사항]
}
Bash
복사
PUT my_index/_settings
{
"index.number_of_replicas":0
}
Bash
복사
refresh_interval
•
ES refresh 수행 주기
•
-1로 지정하면 주기적으로 수행하지 않는다.
•
null로 업데이트해서 설정 전으로 되돌릴 수 있다.
PUT my_index/_settings
{
"index.refresh_interval": "1s" # 1초마다 refresh를 하겠다는 의미
}
Bash
복사
index.search.idle.after
•
마지막 쿼리 수행 이후 해당 설정 시간이 지나면 새로운 쿼리 요청이 오기전까지 refresh를 수행하지 않는다.
인덱스 생성
•
설정값 없이 인덱스를 생성하면 모두 기본값으로 지정되는데, 프로덕션 환경에선 적절하지 않다.
PUT [인덱스 이름]
{
"settings": {
[인덱스 설정]
}
}
Bash
복사
PUT my_index2
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 2
}
}
Bash
복사
•
number_of_shard와 replicas 정보가 의도한대로 2로 설정되어 있다.

GET my_index2 결과
매핑과 필드 타입
매핑
•
바로 위 GET my_index2 의 결과 중 mappings라는 key가 보인다.
•
매핑(mapping)은 문서가 인덱스에 어떻게 색인되고 저장되는지를 정의하는 부분이다.
•
JSON 문서의 각 필드를 어떤 방식으로 분석하고 색인할지, 어떤 타입으로 저장할지 지정한다.
•
다음 샘플 데이터를 입력 후 mappings를 확인해보자.
PUT my_index2/_doc/1
{
"title":"hello world",
"views": 1234,
"public": true,
"point":4.5,
"created": "2019-01-17T14:05:01:234Z"
}
GET my_index2
Bash
복사
: 각 필드에 타입과 관련된 정보가 생성되었다.
ES는 새로운 필드가 들어오면 자동으로 문서의 내용을 보고 타입 추론 후 매핑 정보를 생성한다.
이렇게 ES가 자동으로 생성해주는 매핑을 동적 매핑(dynamic mapping) 이라 부른다.
당연히, 반대로 사용자가 직접 지정하는 방법을 명시적 매핑(explicit mapping)이라 부른다.
"mappings": {
"properties": {
"created": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"point": {
"type": "float"
},
"public": {
"type": "boolean"
},
"title": {
"type": "text",
"fields": {
"keyword": {
//멀티 매핑
"type": "keyword",
"ignore_above": 256
}
}
},
"views": {
"type": "long"
}
}
}
Bash
복사
운영 환경에서는 명시적 매핑을 사용하자.
•
대부분의 설정은 한 번 지정되면 사실상 변경이 불가능하다.
•
운영 환경에서 대용량 데이터 처리시에는 기본적으로 명시적 매핑을 사용하자.
PUT mapping_test
{
"mappings": {
"properties": {
"createdDate": {
"type": "date",
"format": "strict_date_time || epoch_millis"
},
"keywordString" :{
"type": "keyword"
},
"textString":{
"type": "text"
}
}
},
"settings": {
"number_of_replicas": 1,
"number_of_shards": 1
}
}
# 매핑정보 추가하기
PUT mapping_test/_mapping
{
"properties":{
"longValue": {
"type":"long"
}
}
}
Bash
복사
필드 타입
•
심플 타입
◦
직관적인 데이터 자료형
◦
숫자형(long, integer, short, float, ..)
◦
date형
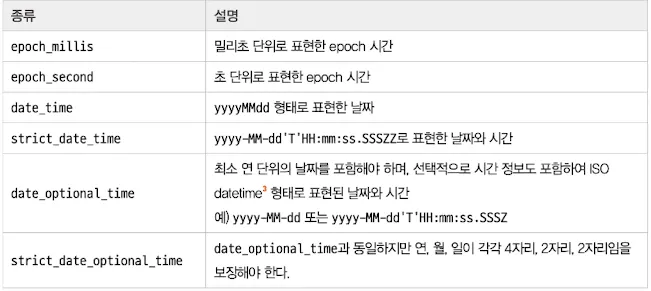
▪
format이라는 옵션으로 데이터 형식을 지정할 수 있다.
▪
Ex: strict_date_time || epoch_second
▪
날짜 비교 검색시 ES에서는 어떤 형식으로 들어오더라도 내부적으로 UTC 시간대로 변환하여 epoch milliseconds 형식의 long 숫자로 색인한다.
◦
배열은 별도의 타입은 없고 대괄호[ ] 를 이용하면 된다.
•
계층 구조를 지원하는 타입
◦
필드 하위에 다른 필드가 들어가는 계층 구조 데이터 타입
◦
object
▪
JSON 문서는 필드로 또 다른 객체를 가질 수 있다.
▪
계층 구조에 대한 매핑 정보는 계층적으로 나타난다.
put object_test/_doc/1
{
"price": 2770.75,
"spec": {
"cores":12,
"memory":128,
"storage":8000
}
}
get object_test
###################
"mappings": {
"properties": {
"price": {
"type": "float"
},
"spec": {
"properties": {
"cores": {
"type": "long"
},
"memory": {
"type": "long"
},
"storage": {
"type": "long"
}
}
}
}
}
Bash
복사
◦
하위의 계층화된 속성정보는 평탄화된 키-값으로 색인한다.
{
"price": 2770.75,
"spec.cores": 12,
"spec.memory": 128,
"spec.storage": 8000
}
Bash
복사
◦
계층화된 구조가 배열타입일 경우에는 다음과 같이 색인된다.
put object_test/_doc/2
{
"spec":[
{
"cores":12,
"memory":128,
"storage":8000
},
{
"cores":6,
"memory":64,
"storage":8000
},
{
"cores":6,
"memory":32,
"storage":4000
}
]
}
# 다음과 같이 평탄화되어 색인된다.
{
"spec.cores": [12, 6, 6]
"spec.memory": [128, 64, 32]
"spec.storage": [8000, 8000, 4000]
}
Bash
복사
◦
nested
▪
object 타입과 비슷하지만 배열 내 각 객체를 독립적으로 취급한다.
▪
다른 필드 복합 조건이 object가 or조건에 가깝다면 nested는 and조건에 가깝다.
타입 | object | nested |
용도 | 일반적인 계층 구조 | 배열 내 각 객체를 독립적으로 취급해야 하는 상황 |
성능 | 상대적으로 가볍다 | 상대적으로 무겁다 |
검색 | 일반적인 쿼리 사용 | 전용 nested 쿼리로 감싸서 사용 |
•
text 타입과 keyword 타입
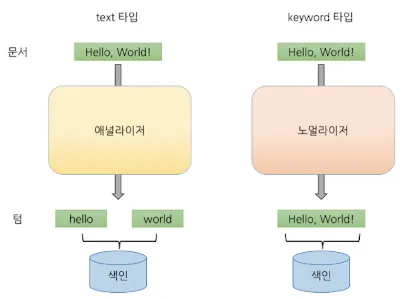
text 타입과 keyword타입의 역색인 과정
◦
둘 다 문자열 필드 타입이다.
◦
text
▪
애널라이저를 통해 값을 분석 후 토크나이징 한 뒤 역색인이 된다. (term)
▪
전문 검색에 적합하다.
▪
fielddata 캐시를 사용한다.
◦
keyword
▪
노멀라이저를 통해 간단한 전처리 후 전체 키워드를 역색인한다.
▪
일치 검색에 적합하다.
▪
doc_values 캐시를 사용한다.
참고: doc_value와 fielddata
•
doc_values
◦
디스크 기반 자료구조로 파일 시스템 캐시를 통해 정렬,집계,스크립트 작업을 수행할 수 있도록 지원한다.
◦
text, annotion_text를 제외한 대부분의 필드는 doc_values를 지원한다.
◦
정렬등의 작업을 할 일이 없는 필드는 doc_values를 끌 수 있다. (속성을 false로 )
•
fielddata
◦
fielddata는 정렬, 집계, 스크립트 작업 수행 시 역색인 전체를 읽어 힙 메모리에 올리는데, 이는 OOM등의 문제 발생 가능성이 있다. 그렇기에 기본적으로는 비활성화(false) 상태이다.
◦
text는 정렬, 집계, 스크립트 작업이 필요할 경우 fielddata라는 캐시를 이용한다.
◦
어지간해선 활성화시키지 말자
_source
•
문서 색인 시점에 ES에 전달된 원본 JSON 문서를 저장하는 메타데이터 필드
•
_source 필드 자체는 역색인 대상이 아니라 검색 대상이 되진 않는다.
•
비활성화 할 경우 재인덱싱이나 업데이트등을 사용할 수 없으니 활성화 해두자.
•
디스크 공간이 절약해야만 한다면 이 설정을 비활성화 하기보단 인덱스 데이터 압축률을 높히자.
PUT codec_text
{
"settings": {
"index": {
"codec": "best_compression" # default(LZ4), best_compression(DEFLATE)
}
}
}
Bash
복사
index
•
해당 필드의 역색인을 만들 것인지 지정할 수 있다.
•
ES 8.1부터는 설정을 false로 설정해도 doc_value를 통해 검색이 수행될 수 있다.
◦
성능은 떨어지지만 디스크 공간을 절약한다.
•
설계 시점에 검색 대상이 될 가능성이 없거나 어쩌다 한번씩만 검색되는 필드는 index를 false로 하는 것도 고려할 수 있다.
put mapping_test/_mapping
{
"properties": {
"notSearchableText": {
"type":"text",
"index": false
},
"docValuesSearchableText": {
"type": "keyword",
"index": false
}
}
}
put mapping_test/_doc/4
{
"textString": "Hello, World!",
"notSearchableText": "World, Hello!",
"docValuesSearchableText": "hello"
}
get mapping_test/_search
{
"query": {
"match": {
"docValuesSearchableText": "hello"
}
}
}
Bash
복사
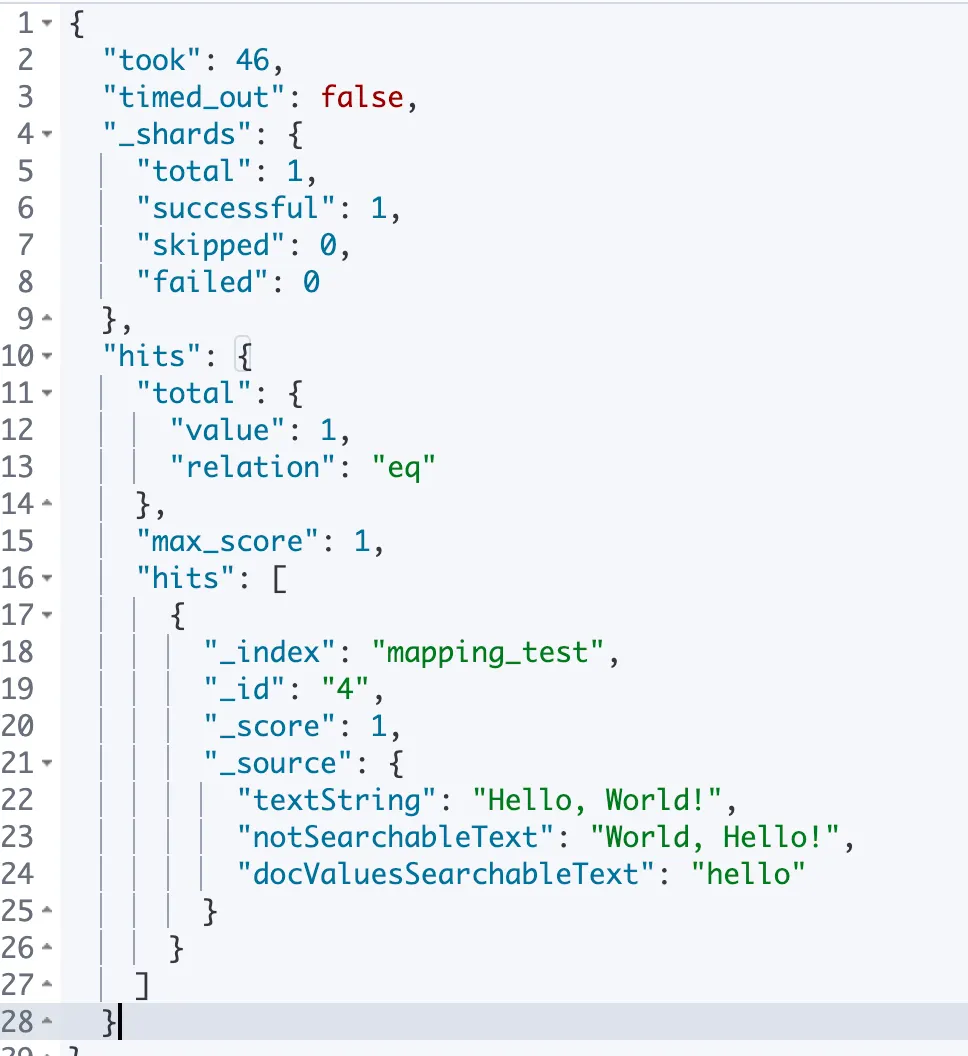
•
검색 필드를 notSearchableText로 하면 검색되지 않는 걸 볼 수 있는데 notSearchableText는 text 필드이기 때문에 doc_values를 사용하지 않기 때문이다.
•
docValuesSearchableText은 index가 꺼져있어도 doc_values설정을 통해 검색할 수 있었다.
enabled
•
object 타입 필드에만 적용된다.
•
false로 지정된 필드는 ES에서 파싱수행도 하지 않는다. 즉 _source 외에는 저장되는 곳이 없다.
•
역색인이 되지 않았기 때문에 검색도 불가능하고 정렬이나 집계도 안된다.
•
여러 타입이 혼용되는 배열도 enabled가 false면 유효성 체크를 하지 않아 저장할 수 있다.
•
데이터를 _source에서만 확인만 하면 되는 필드가 있다면 false로 설정하는 것을 고려할 수 있다.
애널라이저와 토크나이저
•
text 타입의 데이터는 애널라이저를 통해 여러 텀(term)으로 쪼개져서 색인된다.
애널라이저
•
애널라이저는
◦
0개 이상의 캐릭터 필터
▪
문자열 변형
◦
1개의 토크나이저
▪
변형된 문자열 분리
◦
0개 이상의 토큰 필터로 구성된다.
▪
분리된 토큰에 추가 변형작업 수행
◦
위 과정들을 마치면 분석 완료된 텀(term)이 완성된다.
◦
_analyze 를 통해 어떻게 분석되는지 확인 가능하다.
post _analyze
{
"analyzer": "standard",
"text": "Hello, HELLO, World!"
}
Bash
복사

애널라이저 - 캐릭터 필터
•
텍스트를 캐릭터의 스트림으로 받아 데이터를 추가,변경,삭제한다.
•
빌트인 캐릭터 필터는 다음과 같이 존재한다.
◦
HTML strip: <b>와 같은 요소 안쪽 데이터를 꺼내고, HTML 엔티티 디코딩도 한다.
◦
mapping: 치환할 대상 문자와 치환문자를 맵 형태로 보관한다.
◦
pattern replace: 정규 표현식을 이용해 문자를 치환한다.
애널라이저 - 토크나이저
•
1개의 토크나이저만 지정할 수 있다.
•
standard
◦
기본적인 토크나이저로 Unicode Text Segmentation 알고리즘을 사용하여 텍스트를 단어 단위로 나눈다.
◦
대부분의 문장 부호가 사라진다.
•
keyword
◦
들어온 텍스트를 쪼개지않고 그대로 내보낸다.
•
ngram
◦
min_gram 값 이상 max_gram 값 이하 단위로 쪼갠다.
◦
min_gram : 2 max_gram: 3 으로 설정하고 hello를 토크나이징할 경우
▪
he, hel, el, ell, ll, llo로 토크나이징 된다.
◦
무의미한 공백 문자도 token_chars 속성으로 토큰에 포함시킬 타입의 문자 지정 가능
▪
Letter : 언어의 글자로 분류되는 문자
▪
Digit : 숫자로 분류되는 문자
▪
whitespace : 띄어쓰기나 줄바꿈
▪
punchuation : !나 “같은 문장 부호
▪
symbol : $나 ⎇같은 기호
▪
custom : custom_token_chars 설정을 통해 따로 지정한 커스텀 문자
◦
우선적으로 token_chars 지정되지 않은 문자를 기준으로 토크나이징을 한 뒤 속성에 따라 단어를 토크나이징 한다.
◦
RDB의 Like 유사검색과 유사하게 검색을 구현하고 싶을 때 활용한다.
◦
min_gram과 max_gram의 값 차이는 index.max_ngram_diff으로 제한을 설정할 수 있다.
•
edge_ngrma
◦
ngram과 유사하지만 토큰의 시작 글자를 단어의 시작글자로 고정시킨다.
◦
Hello, World를 토크나이징 할 경우 Hel, Hell, Wor, Worl으로 토크나이징된다.
애널라이저 - 토큰 필터
•
토크나이저를 통해 만들어진 토큰 스트림을 받아 토큰에 대한 후처리를 한다. (추가,변경,삭제)
•
내장 토큰은 다음과 같이 존재한다.
◦
lowercase / uppercase : 토큰을 대/소문자로 만든다.
◦
stop: 불용어를 지정해 제거할 수 있다. (ex: the, a, an, in등)
◦
synonym: 유의어 사전 파일을 지정해 지정된 유의어를 치환한다.
◦
pattern_replace: 정규식을 사용해 토큰의 내용을 치환한다.
◦
stemmer : 지원되는 몇몇 언어의 어간 추출 수행(not korean)
◦
trim: 토큰 전후 공백 제거
◦
truncate: 지정한 길이로 토큰을 자른다.
내장 애널라이저
•
필터와 토크나이저를 조합해둔 내장 애널라이저가 몇 가지 존재한다.
•
standard(default)
◦
standard 토크나이저 + lowercase 토큰 필터
•
simple
◦
letter가 아닌 문자 단위로 토크나이징 후 lowercase 토큰 필터 적용
•
whitespace
◦
whitespace 토크나이저로 구성
•
stop
◦
standard 애널라이저 + stop 토큰 필터
•
keyword
◦
keyword 토크나이저로 구성되어 있다.
◦
분석을 하지 않고 하나의 큰 토큰을 그대로 반환한다.
•
pattern
◦
pattern 토크나이저 + lowercase 토큰 필터
•
language
◦
여러 언어의 분석 지원( 한국어는 지원하지 않는다.)
•
fingerprint
◦
standard 토크나이저
◦
+ lowercase 토큰필터
◦
+ ASCII folding 토큰필터
◦
+ stop 토큰필터
◦
+ fingerprint 토큰필터
애널라이저를 매핑에 적용
•
전체적인 default analyzer 설정과, 타입별 analyzer 지정이 가능하다.
put analyzer_test
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"type": <애널라이저 타입>
}
}
}
},
"mappings": {
"properties": {
"defaultText": {
"type": "text"
},
"standardText": {
"type": "text",
"analyzer": <애널라이저 타입>
}
}
}
}
Bash
복사
•
커스텀 애널라이저를 직접 매핑할수도 있다.
put analyzer_test2
{
"settings": {
"analysis": {
"char_filter": {
"my_char_filter": {
"type": "mapping",
"mappings": [
"i. => 1.",
"ii. => 2.",
"iii. => 3.",
"iv. => 4."
]
}
},
"analyzer": {
"my_analyzer": {
"char_filter": [ "my_char_filter" ],
"tokenizer": "whitespace",
"filter": ["lowercase"]
}
}
}
},
"mappings": {
"properties": {
"myText": {
"type":"text",
"analyzer":"my_analyzer"
}
}
}
}
Bash
복사
참고: 한국어 형태소 분석 애널라이저 플러그인
•
공식적으로 ES에서 한국어 형태소 분석을 지원하진 않지만, nori라는 플러그인을 통해 분석할 수 있다.
•
설치 방법
elasticsearch-plugin install [플러그인 이름]
#elasticsearch-plugin install anaysis-nori
Bash
복사
◦
이후 analyzer 속성의 값을 nori로 지정해서 분석하면 된다.
템플릿
•
인덱스 설정, 매핑, 애널라이저같은 설정들을 템플릿화해서 반복작업을 없앨 수 있다.
인덱스 템플릿
PUT _index_template/my_template
{
"index_patterns": [
"pattern_test_index-*",
"another_pattern-*"
],
"priority": 1,
"template": {
"settings" : {
"number_of_shards": 2,
"number_of_replicas": 2
},
"mappings": {
"properties": {
"myTextField": {
"type": "text"
}
}
}
}
}
Bash
복사
•
index_pattern
◦
해당 템플릿을 지정할 인덱스의 네이밍 패턴을 지정한다. priority를 통해 여러 템플릿 중 우선순위 조정도 가능하다.
컴포넌트 템플릿
•
인덱스 템플릿에서 중복되는 블록을 쪼개어 재사용할 수 있게 만들어둔 템플릿
PUT _component_template/my_shard_settings
{
"template": {
"settings": {
"number_of_shards": 2,
"number_of_replicas": 2
}
}
}
PUT _index_template/my_template2
{
"index_patterns": ["timestamp_index-*"],
"composed_of": ["timestamp_mappings", "my_shard_settings"]
}
Bash
복사
라우팅
•
ES에서 인덱스를 구성하는 샤드 중 몇 번 샤드를 대상으로 작업할지 지정하기 위해 사용하는 값
•
작업 대상 샤드 번호는 지정된 라우팅 값을 해시한 후 주 샤드의 개수로 나머지 연산을 수행한 값이 된다.
•
라우팅 값을 지정하지 않으면 _id 값이 기본값이 된다.
•
검색 시(_search) 라우팅 값을 queryString에 작성하면 해당 샤드를 대상으로 검색한다.
put routing_test
{
"settings": {
"number_of_shards":5,
"number_of_replicas":1
}
}
put routing_test/_doc/1?routing=myid
{
"login_id":"myid",
"comment": "hello world",
"created_at": "2020-09-08T22:14:09.123Z"
}
get routing_test/_search?routing=myid
Bash
복사

routing 값 지정 하지 않은 경우

routing 값을 지정한 경우
•
운영 환경에서 라우팅 값을 지정해주는게 성능부분에서 크게 도움이 된다.
◦
Ex: 게시판에서 사용자별 댓글을 색인하고자 할때 사용자의 아이디로 라우팅 값을 지정하면 사용자별 댓글을 조회할 때 검색 성능을 끌어올릴 수 있다.
라우팅 필수 지정 설정
•
라우팅값을 설정하는 것이 선택적(Optional)이 아닌 필수적(required)으로 정책을 통일하고 싶다면 mappings._routing.required 속성 설정을 통해 라우팅 값 명시를 필수로 설정할 수 있다.
PUT routing_test2
{
"mappings": {
"_routing": {
"required": true
}
}
}
PUT routing_test2/_doc/1
{
"comment": "index without routing"
}
Bash
복사

라우팅 값 없이 저장 결과
정리
◦
ES에서 인덱스는 상세설정이 가능한만큼 설정에 주의가 필요하다.
◦
number_of_shard를 통해 인덱스가 몇 개의 샤드로 분리할 지 지정한다.
◦
number_of_replicas를 통해 샤드의 복제본 수를 지정한다.
◦
refresh_interval속성으로 refresh 주기를 정할 수 있다.
◦
인덱스는 자동보단 수동으로 직접 설계해주자
◦
운영 환경에서는 명시적 매핑(explicit mapping)을 사용해주자.
◦
text 타입은 애널라이저를 통해 여러 term으로 쪼개져서 색인된다.
◦
애널라이저는 캐릭터 필터, 토크나이저, 토큰 필터로 구성되어 있다.
◦
한국어는 nori라는 애널라이저 플러그인을 통해 형태소 분석을 할 수 있다.
◦
애널라이저나 인덱스 설정들을 템플릿화 할 수 있다.
◦
템플릿의 중복되는 블록을 분리해 컴포넌트화 할 수 있다.
◦
라우팅 값을 지정해서 검색할 대상 샤드를 좁힐 수 있다.
◦
required속성을 통해 라우팅 지정 정책을 강제할 수 있다.

