

목차
0. Previous
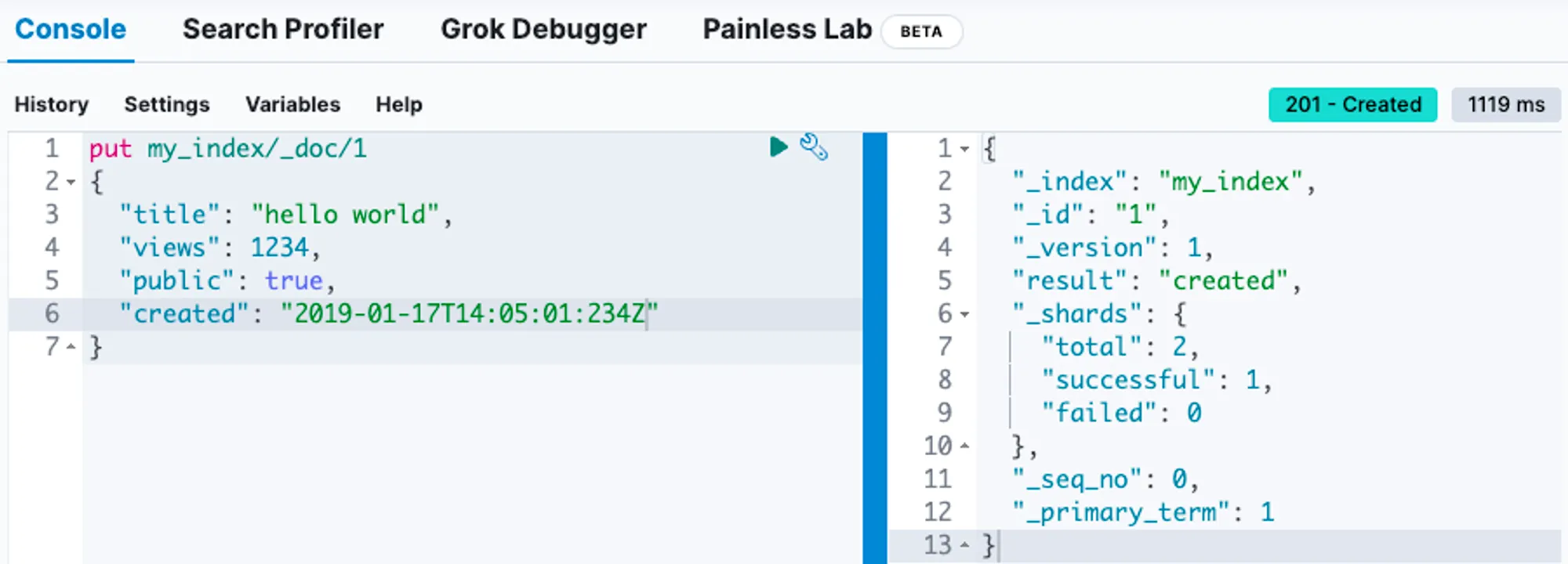
Kibana의 Management > Dev Tool을 이용해 Query Command 테스트가 가능하다.
1. ES 기본 동작
1-1. 문서 색인
•
ES에 문서를 색인하기 위해서 _id가 지정되거나 혹은 지정되지 않아도 된다.
•
_id가 지정되는 경우
post my_index/_doc/[_id값]
{ [문서 내용] }
Bash
복사
•
_id를 지정하지 않는 경우에는 ES가 자동으로 _id를 생성해준다.
1-2. 문서 조회
GET [인덱스 이름]/_doc/[_id값]
Bash
복사
1-3. 문서 업데이트
POST [인덱스 이름]/_update/[_id값]
{
"doc": { [문서 내용] }
}
Bash
복사

•
업데이트가 완료되면 response 의 result가 updated로 노출된다.
1-4 문서 검색
[GET | POST] [인덱스 이름]/_search
{
[검색 조건]
}
#Example
GET midasin/_search
{
"query": {
"match": {
"title": "Elasticsearch"
}
},
"from": 0,
"size": 10,
"sort": [
{
"timestamp": {
"order": "desc"
}
}
]
}
Bash
복사
•
Request Body는 JSON 형식으로 구성되며 다음과 같은 요소를 포함한다.
◦
query: 검색 조건을 정의하는 부분 다양한 쿼리 유형을 사용해 원하는 검색을 수행한다.
◦
from: 검색 결과에서 건너뛸 문서의 수
◦
size: 검색 결과에서 반환할 문서의 수
◦
sort: 검색 결과의 정렬 기준
•
query 유형도 위 예제의 match뿐아니라 다양한 유형들이 있다.
◦
match_all: 모든 문서를 검색한다.
◦
match: 특정 필드에서 특정 값을 일치하는 문서를 검색한다.
◦
multi_match: 여러 필드에서 특정 값을 일치하는 문서를 검색한다.
◦
bool: 여러 쿼리를 조합해 검색 조건을 정의한다.
◦
query_string: 자연어 검색 형식으로 검색 조건을 정의한다.
1-5. 문서 삭제
DELETE [인덱스 이름]/_doc/[_id값]
Bash
복사
2. ES 구조
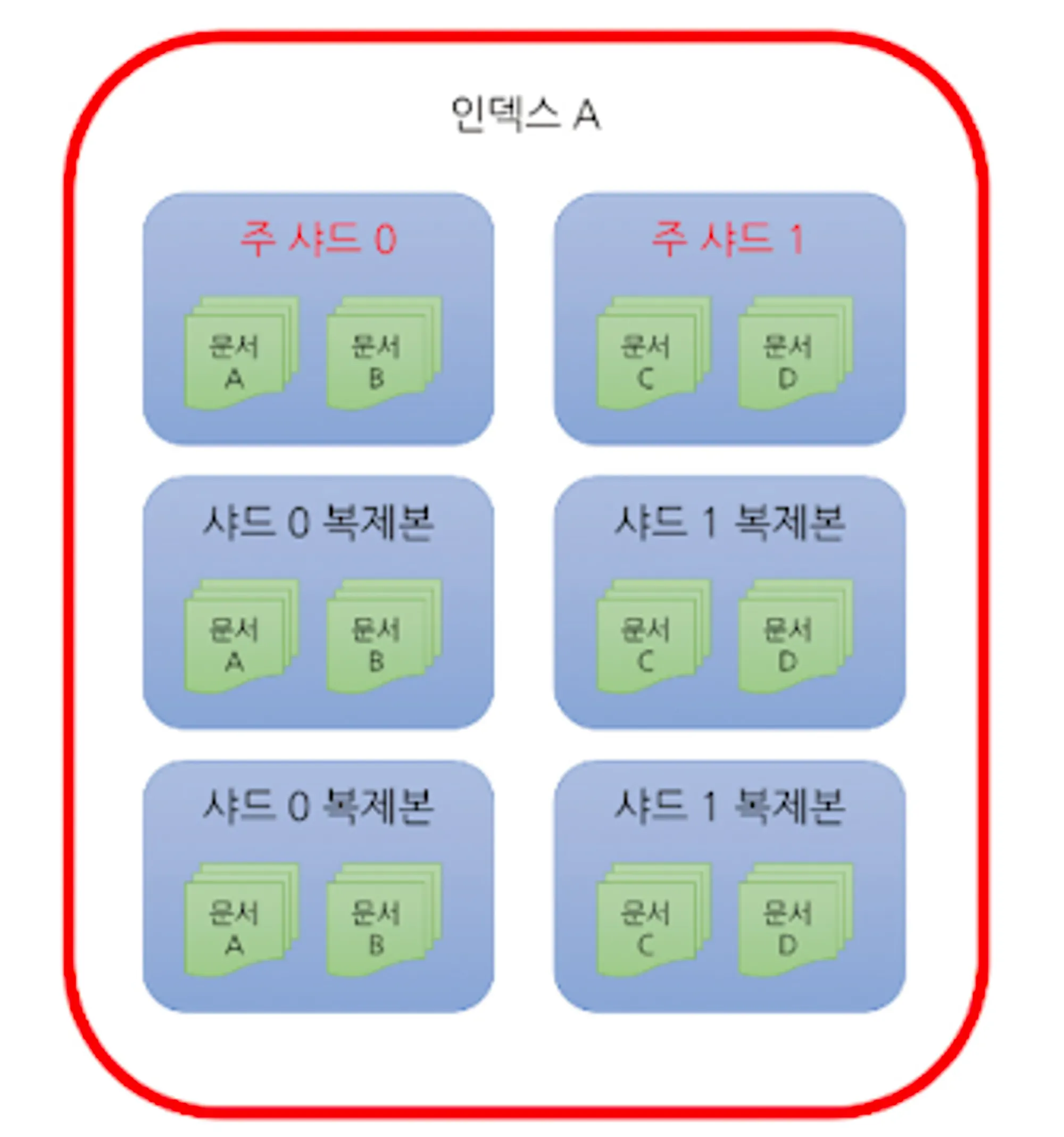
•
문서(document): ES가 저장하고 색인을 생성하는 JSON
•
인덱스: 문서를 모아놓은 단위, 클라이언트는 인덱스 단위로 ES에 검색을 요청한다.
•
샤드
◦
인덱스는 내용을 여러 샤드로 분리해 분산 저장한다.
◦
샤드의 내용을 복제한 복제본들을 가지고 있는다.
◦
원본 역할을 하는 주 샤드(primary shard)와 복제본 샤드(replication shard)로 나뉜다.
•
_id: 인덱스 내 문서에 고유되는 고유한 구분자(PK) 인덱스명과 _id 조합은 ES 클러스터 내에서 고유하다.
•
타입: ES 7버전부터는 사용하지 않는다. 현재는 타입 이름이 들어갈 자리에 _doc이라는 기본값이 들어간다.
즉, 색인된 JSON문서들이 문서(document)가 되고, 문서들이 모이면 인덱스가 된다.
이 인덱스의 내용들은 여러 샤드에 분산되어 저장되고, 샤드들은 복제되어 관리된다.
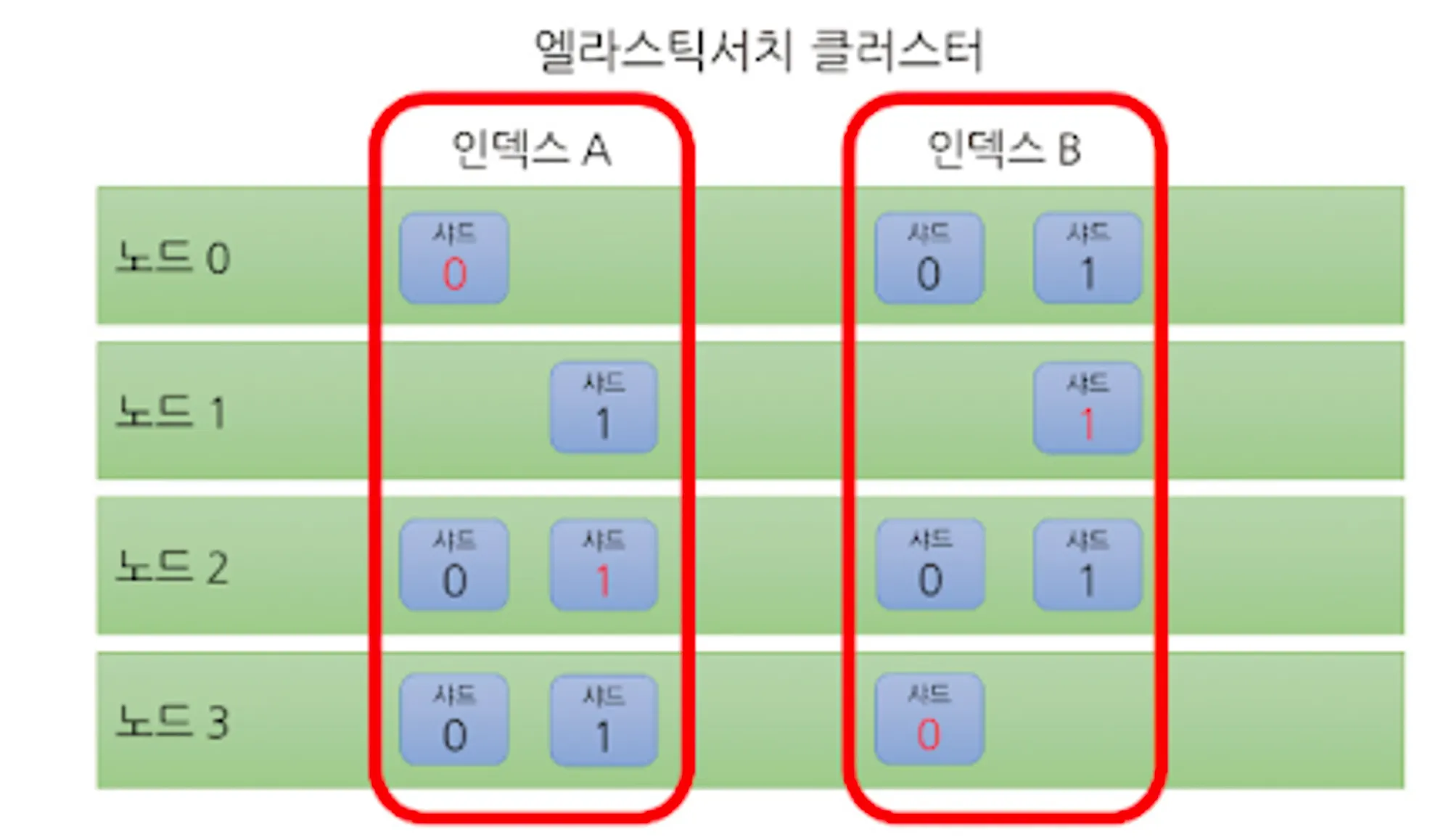
•
노드
◦
ES Process 하나가 하나의 노드를 구성한다.
◦
고가용성을 위해 같은 종류의 샤드를 같은 노드에 배치하지 않는다
◦
데이터, 마스터, 조정 노드 등 여러 역할 중 하나 이상의 역할을 맡는다.
▪
데이터 노드: 샤드를 보유하고 실제 읽기 쓰기 수행
▪
마스터 노드: 클러스터 관리
▪
조정 노드: 요청을 노드에 분배하고 응답을 클라이언트에게 돌려준다.
•
클러스터: ES 노드 여러개가 모여 클러스터를 구성한다.
3. ES 내부 구조와 루씬
•
문서 색인, 업데이트, 삭제등의 작업들은 인메모리 버퍼에 쌓이다가 주기적으로 디스크에 flush 된다.
•
ES는 내부적으로 DirectoryReader 클래스를 이용해 파일에 접근하고,
◦
루씬의 색인 접근을 가능하게 해주는 IndexReader 객체를 얻는다.
•
ES는 변경 내용을 검색에 반영하기 위해 DirectoryReader 객체의 openIfChange 함수를 호출하고,
◦
변경사항이 적용된 새로운 IndexReader를 열고 기존 IndexReader를 닫는다. (Refresh)
◦
Refresh는 비용이 있는 작업이기에 적절한 실행 주기를 설정해줘야 한다.
•
이 이후의 데이터는 모두 검색 대상이 된다.
참고: 루씬 commit
루씬이란?
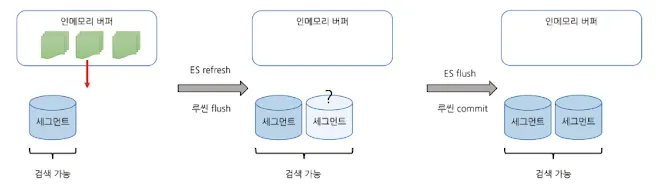
루씬 flush는 시스템 페이지 캐시에 데이터를 넘겨주는 것 까지만 보장하기에 실제로 디스크가 파일에 기록이 완료되는지를 보장하진 않는다. 그래서 fsync 시스템 콜을 통해 주기적으로 시스템 페이지 캐시와 디스크 내용의 싱크를 맞추는 작업을 하는데 이를 루씬 commit이라 한다.
중요한건 ES의 flush는 루씬 flush와 다르고, 루씬commit을 포함해 동작한다.
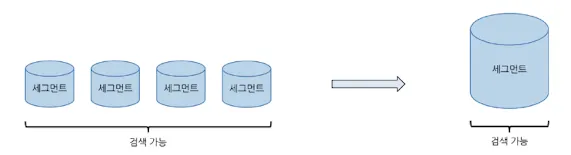
참고: 세그먼트
•
주기적으로 디스크에 쌓인 데이터가 모이면 세그먼트라는 단위가된다.
•
루씬의 검색 대상이며 불변 데이터이다.
•
중간중간 세그먼트 병합이 수행되며 이 비용은 상당히 크다.
•
삭제는 즉시삭제가 아닌 마킹을 한 뒤 차후 병합 수행시 삭제 수행된다.
루씬 인덱스와 ES 인덱스
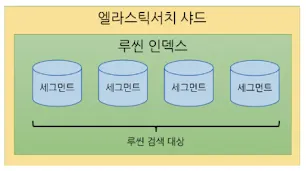
•
세그먼트가 모여 루씬 인덱스가 되는데, ES-Shard는 이 루씬 인덱스 하나를 래핑한 단위다.
•
ES는 여러 샤드의 문서를 모두 검색할 수 있는데, 루씬 인덱스 내에서만 검색할 수 있는 것과 다르게 ES는 전체 분산 검색을 가능하게 한다.
translog
•
변경사항을 한데 모아 commit할 경우 장애가 발생해 데이터가 유실될 수 있는 문제를 해결하기 위해 translog라는 작업 로그를 남긴다.
•
색인, 삭제 작업이 루씬 인덱스에 수행된 직후 기록된다.
•
기록까지 끝나야 작업 요청이 끝났다고 승인된다.
•
ES는 장애 발생시 샤드 복구 단계에서 translog를 읽는다.
•
translog가 너무 커지는걸 막기 위해 ES flush는 백그라운드에서 주기적으로 수행되며 새로운 translog를 만들어 크기를 일정하게 유지한다.
•
디스크에 fsync된 데이터만 보존된다.
정리
•
색인 대상이 되는 데이터는 JSON 타입이며 문서(document)라 한다.
•
문서가 모이면 인덱스라는 단위가 된다.
•
인덱스는 너무 크니 이를 적당히 분산해서 묶어 놓은 단위를 샤드라 한다.
•
샤드에는 주 샤드(primary shard)와 복제 샤드(replication shard)가 존재한다.
•
ES 프로세스 하나가 노드가 되며 노드는 여러 샤드를 가진다.
•
각각의 노드는 데이터, 마스터, 조정의 역할 중 하나 이상을 담당한다.
•
노드는 같은 종류의 샤드를 가지지 않는다.
•
이런 노드들이 모이면 클러스터가 된다.
•
ES 는 내부적으로 루씬이라는 코어 라이브러리를 사용한다.
•
문서(document)의 색인, 업데이트, 삭제와 같은 데이터 변경 사항은 인메모리 버퍼에 쌓인다.
•
주기적으로 flush되며 디스크에 쌓이게 되는데 이를 루씬 commit이라 한다.
•
디스크에 쌓인 데이터가 모여서 세그먼트라는 단위가 된다.
•
세그먼트가 모이면 루씬 인덱스가 되며 루씬의 검색 대상이 된다.
•
루씬 인덱스를 래핑하면 ES 샤드가 된다.

