
목차
개요

컴퓨터가 인식할 수 있는 코드는 바보라도 작성할 수 있지만, 인간이 이해할 수 있는 코드는 실력 있는 프로그래머만 작성할 수 있다.
- 마틴 파울러(Martin Fowler)(Refactoring)
주니어 개발자들이 (종종 시니어도) 코드를 작성 하다 보면 여러 슈가코드의 달콤함에 취해 짧고 복잡하게 나만 알 수 있는 코드를 작성하고, 다른 사람이 내 코드를 어려워 하는 게 내가 실력이 더 뛰어나서 인 것 마냥 기세등등 하는 경우가 빈번하게 있다.
APL로 구현한 존 코웨이의 생명 게임(Game of Life)
하지만, 이는 뛰어난 것이 아니다. 위 코드는 정말 짧고 간결하다. 하지만 보자마자 어떤 코드인지 알 수가 있는가? 심지어 평범한 키보드로는 입력할 수 없는 글자도 포함되어 있다.
코틀린은 간결성을 목표로 설계된 언어가 아니라 가독성(readability)을 좋게 하는 데 목표를 두고 설계된 프로그래밍 언어이다.
즉, 코드를 짧게 작성하는 것이 아니라 읽기 쉽게 하는 것이 목표라고 할 수 있다.
간결성은 가독성을 목표로 두고, 나아가는 과정에서 발생하는 부가적인 효과일 뿐이다.
이번 장에서는 코틀린을 어떻게 읽기 쉽게 작성하는지, 원하는 것을 숨기거나 혹은 강조하는 많은 코틀린의 기능들을 어떻게 사용하는지에 대해 알아보도록 한다.
11. 가독성을 목표로 설계하라
개발자가 코드를 작성하는 데는 1분이 걸리지만, 이를 읽는 데는 10분이 걸린다.
- Robert C. Martin(Clean Code)
협업을 하다 보면 남의 코드를 리뷰 해 줘야 하는 일이 빈번하다.
그런데, 내가 작성한 20 줄 짜리 코드를 완성하는데 드는 시간보다 팀원이 작성한 코드 10 줄을 해석하는데 걸리는 시간이 더 오래 걸리는 경험은 모두들 있을 것이다.

그래서 나중에는 LGTM(Look Good To Me)으로 적당히 에러 안 생기면 approve를 찍는 경험도 있을 수 있다. 입장을 바꿔 생각해보면 해석하기 쉽게 코드를 작성 할 수록 좋은 리뷰를 받을 수 있다는 의미도 되지 않을까?
즉, 우리는 항상 가독성에 신경을 쓰면서 코드를 작성해서 내가 남의 코드를 분석하던 남이 내 코드를 분석하던 시간을 아낄 수 있게 해서 전체적인 생산성을 높혀야 할 필요가 있다.
(안 그래도 부족한 개발 일정 코드 보는 시간까지 길면 언제 완료하고 고기 먹으러 가겠는가.)
다음 세 가지의 고려하면 좋을 항목에 대해 알아보자.
익숙하게 작성하자.
//case A
if (moveStrategy.movable()) {
racingCar.moveStraight()
} else {
racingCar.stop()
}
//case B
racingCar.takeIf { moveStrategy.movable() }
?.run(racingCar::moveStraight)
?: racingCar.stop()
Kotlin
복사
두 코드 모두 이동 전략에 따라 전진하거나 멈추는 로직인데 어떤게 더 좋은 코드일까
두 번째를 선택했다면, 사실 좋은 대답은 아니다.
일반적으로는 후자보다는 전자의 코드가 더 읽고 이해하기 쉽다. 일반적인 관용구(ex: if, else, call method)를 사용하고 있기 때문이다. 반면 후자의 코드는 코틀린에서 자주 사용 되긴 하지만, 좀 더 언어 범용적으로 볼 때 일반적인 관용구(safe call, takeIf, run, Elvis)는 아니다.
어느정도 코틀린에 숙련된 개발자라면 후자의 코드 역시 충분히 빠르게 읽을 수 있을 것이다.
하지만, 숙련된 개발자만을 위한 코드는 좋은 코드가 아니다. 그렇기에 가독성 측면에서는 전자(case A)의 코드가 더 좋은 코드라고 볼 수 있다.
유지보수성 측면에서도 전자의 코드가 더 좋다. if 블럭에 로직이 추가되야 할 경우 그냥 작성하면 된다. 하지만 후자(case B)는 어떨까? 전자에 비교해서 결코 쉽지 않다.
//case A
if (moveStrategy.movable()) {
racingCar.moveStraight()
observers.notifyMove(racingCar)
} else {
racingCar.stop()
observers.notifyStop()
}
//case B
racingCar.takeIf { moveStrategy.movable() }
?.run {
it.moveStraight()
observers.notifyMove(it)
}?: run {
racingCar.stop()
observers.notifyStop()
}
Kotlin
복사
훨씬 복잡하고, Elvis 연산자 측에서 표현식을 추가하려면 함수를 추가로 사용해야 한다.(run)
이와 같이 개성있고 창의적인 구조는 유연성측면, 지원성 측면에서 뒤떨어질 수 있다.
그렇기에 우리는 인지 부하를 줄이는 방향 즉, 우리의 뇌가 익숙한 관례 패턴을 기반으로 작성을 하는게 좋다. 뇌는 짧은 코드를 빠르게 읽을 수 있지만, 익숙한 코드는 더 빠르게 읽을 수 있다.
하나의 의견에 매몰되지 말자
방금까지 후자의 run, Elvis, takeIf같은 연산자보단 일반적인 if-else가 낫다는 얘기를 했지만, 그렇다고 이 이야기를 절대 코틀린 관용구를 써선 안된다. 라고 이해해서는 안된다.
뭐든 극단적이 되어서는 안된다. 모든 선택에는 트레이드 오프가 있고, 매 상황 적절한 선택을 하는게 우리가 좋은 코드를 만들기 위해 해야 할 노력이다.
예제 코드에서는 run을 사용했지만, 코틀린의 범위 지정 함수는 run 말고도 let, also, with, apply등 다양하게 있고, 모두 좋은 코드를 위해 다양하게 활용된다.
다음과 같이 nullable한 프로퍼티가 not null인 상황에서만 로직을 수행해야 한다고 할 때, 가변 프로퍼티는 멀티 스레드를 고려해서 스마트 캐스팅이 불가능하다. 이 경우 let을 이용해 해결 할 수 있다.
data class RacingCar(val distance: Distance)
var racingCar: RacingCar? = null
fun moveCar() {
racingCar?.let { car -> //car는 RacingCar? 에서 RacingCar로 스마트 캐스팅 된다.
// logic...
}
}
Kotlin
복사
이 외에도 다음과 같은 경우 let을 유용하게 사용할 수 있다.
•
연산을 아규먼트 처리 후로 이동시킬 때
cars
.filter { it.distance == maxDistance }
.joinToString(seperator = "\n") {
"${it.name}: ${SKID_MARK.repeat(it.distance.value)}
}
.let(::print)
Kotlin
복사
: 문자열을 만드는 로직까지 파악하고 다시 처음으로 돌아가 출력한다는 내용을 파악하는 것 보다 연산 이후의 let을 통해 무엇이 출력될 지 파악하는게 더 가독성이 좋다.
•
데코레이터를 사용해서 객체를 래핑할 때
var obj = FileInputStream("/file.gz")
.let(::BufferedInputStream)
.let(::ZipInputStream)
.let(::ObjectIinputStream)
.readObject() as SomObject
Kotlin
복사
: 경로를 통해 읽은 파일이 점진적으로 어떻게 래핑(Wrapping)되는지 파악하기 쉬운 코드다.
해당 아이템 소개 초반에 이런 코드들은 숙련되지 않았으면 파악하기 힘든 코드라고 얘기를 했지만 지불 할 가치가 있다.
컨벤션
이런 가독성의 대한 의견은 개발자마다 다르다.
나는 일반적인 관용구가 더 가독성이 좋지만 누구에게는 코틀린의 관용구를 사용하는게 더 가독성이 좋다고 느낄 수도 있고, 그 외에도 함수 이름, 명시적 혹은 암묵적인 표시의 구분 등등 다양한 부분에서 의견이 갈릴 수 있다. 그래서 컨벤션 회의를 하고 팀별로 규칙들을 정하게 된다.
이렇게 컨벤션을 정하기 위해서 우리는 몇 가지 규칙들을 이해 할 필요가 있다.
•
연산자는 의미에 맞게 사용해야 한다.
: + 연산자가 곱셉이나 나눗셈으로 쓰여서는 안된다.
•
코드를 불필요하게 복잡하게 만들지 마라.
: 마지막 아규먼트가 람다일 경우의 컨벤션을 사용할 경우 그 뒤에 또 중위함수등을 붙히면 코드가 복잡해진다.
•
이미 있는 기능을 다시 만들지 말아라.
이런 모든 규칙들을 어기는 코드를 참고하자.
val abc = "A" { "B" } and "C"
print(abc) //ABC
operator fun String.invoke(f: ()-> String): String = this + f()
infix fun String.and(s: String) = this + s
Kotlin
복사
12. 연산자 오버로드를 할 때는 의미에 맞게 사용하라
연산자 오버로딩은 굉장히 강력하면서 또 재밌다. 그리고 뭔가 간지(?)가 난다.
그래서 신나서 쓰다 보면 곤경에 빠질 수 있다.
다음 코드는 팩토리얼을 구하는 코드이다.
fun Int.factorial(): Int = (1..this).product()
fun Iterable<Int>.product(): Int = fold(1) { acc, i -> acc * i}
Kotlin
복사
이 함수는 Int 확장 함수로 정의되어 있기에 굉장히 편리하게 다음과 같이 사용할 수 있다.
print(10 * 6.factorial()) // 7200
Kotlin
복사
너무 편하다…(❁´◡`❁)
그런데, 팩토리얼은 수학 시간에 ! 기호를 표현한다고 했는데, 다음과 같이 표현할 수 있지 않을까?
10 * 6!
Kotlin
복사
코틀린의 연산자 오버로딩을 이용해 이 수식을 동작하게 만들 수 있지 않을까?
operator fun Int.not() = factorial()
print(10 * !6) // 7200
Kotlin
복사
잘 동작하고 값도 정상적으로 출력 된다.
하지만 이렇게 사용해서는 안 된다. 위 코드를 보면 뭔가 이상하지 않은가? factorial() 메서드를 호출하는 함수의 이름이 not이다. not은 factorial보다는 논리 연산에 좀 더 어울리는 것 같다.
그리고 그게 맞는게 코틀린은 관례적으로 사용되는 연산자에 대해서 대응되는 함수들을 제공하고 있고, 이를 오버로딩해서 우리가 사용을 하는 것이다.
연산자 | 대응되는 함수 |
+a | a.unaryPlus() |
-a | a.unaryMinus() |
!a | a.not() |
++a | a.inc() |
—a | a.dec() |
a+b | a.plus(b) |
a-b | a.minus(b) |
a*b | a.times(b) |
a/b | a.div(b) |
a..b | a.rangeTo(b) |
a in b | b.contains(a) |
a += b | a.plusAssign(b) |
a-=b | a.minusAssign(b) |
a*=b | a.timeAssign(b) |
a/=b | a.divAssign(b) |
a==b | a.equals(b) |
a > b | a.compareTo(b) > 0 |
a < b | a.compareTo(b) < 0 |
a ≥ b | a.compareTo(b) ≥ 0 |
a ≤ b | a.compareTo(b) ≤ 0 |
각 연산자에 대응되는 함수는 명시적으로 존재하고 이 메서드 네이밍 시그니처가 주는 동작을 수행해야 한다. 만약 +연산자인데 각기 다른 방식으로 연산 되고 있다면 모든 연산자를 개별적으로 따로 이해해야 하기 때문에 가독성이 매우 떨어질 것이다.
그렇기에 위에서 작성했던 팩토리얼을 ! 연산자를 이용해 오버로딩하는 것은 관례에 어긋나는 잘못 된 구현 방법이다.
하지만, 애매한 경우에는..?
관례를 지켜야 한다고 했는데, 그 관례에 어긋나는지 확실하지 않는 경우에는 어떻게 해야 할까?
예를 들어, * 연산자를 함수의 실행을 세 배 한다고 다음과 같이 작성하면 어떨까?
data class Car(private var distance: Distance) {
fun move() {
distance += SPEED
}
fun getDistance(): Distance = Distance(distance.value)
}
val racingCar = Car(distance = Distance(0))
3 * { racingCar.move() }
print(racingCar.getDistance()) // Distance(value: 3)
Kotlin
복사
의미가 애매하기에 이를 잘 못된 코드가 아니라고 판단할 수도 있지만, 애초에 명확하지 않으면 헷갈릴 시간을 준다는 것 자체가 낭비일 수 있기에 차라리 infix를 활용한 확장 함수를 사용하는 게 좋다.
infix fun Int.timesRepeated(operation: () -> Unit) = {
repeat(this) { operation() }
}
val racingCar = Car(distance = Distance(0))
3 timesRepeated {racingCar.move() }
print(racingCar.getDistance()) // Distance(value: 3)
Kotlin
복사
규칙을 무시해도 되는 경우…바로 DSL
지금까지 계속 강조한 연산자 오버로딩 규칙을 무시해도 되는 경우가 있다.
바로 도메인 특화 언어(Domain Specific Language, DSL)를 설계하는 경우인데, 이 경우 해당 DSL 블럭 내부에서는 해당 도메인의 특화된 경우로 제한되기에 해당 도메인에 좀 더 특화된 방식으로 연산자 오버로딩이 사용되더라도 의미의 명확성이 충분히 성립하고 DSL 외적으로는 다시 일반적인 연산자 오버로딩 규칙을 따르기에 괜찮다.
body {
div {
+"Some text"
}
}
Kotlin
복사
HTML DSL 으로 unaryPlus 연산자가 사용되지만 DSL이기에 괜찮다.
13. Unit?을 리턴하지 말라
코틀린의 Unit 타입은 자바의 Void 타입과 유사하다.
그런데 반환 타입을 Unit? 으로 한다는 것의 의미는 Unit 혹은 null을 반환한다는 의미가 되기도 한다.
이를 이용해 이렇게 코드를 작성 할 수도 있을 것 같다.
fun verifyKey(key: String): Unit? = //...
verifyKey(key) ?: return
Kotlin
복사
이런 코드 트릭은 사실 예측하기 어렵고 무엇을 의도하는지 알기 힘들다.
그냥 Boolean을 반환하도록 하는게 훨씬 명시적이다.
fun verifyKey(key: String): Boolean = //...
if(!verifyKey(key) {
return;
}
Kotlin
복사
기본적으로 오해를 불러일으키기 쉬운 코드는 작성하지 않는 것이 좋다.
Unit?을 리턴하거나 이를 기반으로 코드를 작성하는 것 자체를 지양하도록 하자.
14. 변수 타입이 명확하지 않은 경우 확실하게 지정하라
val num = 10
val name = "catsbi"
val ids = listOf(1, 2, 3, 4, 5)
Kotlin
복사
코틀린은 타입 추론(type inference)기능을 매우 잘 지원해준다.
유형이 명확할 경우 코드가 짧아지면서 가독성은 더 높아질 수 있다. 하지만 유형이 명확하지 않은 경우에는 이 개발자 입장에서 타입 추론으로 오히려 가독성이 떨어지는 결과를 얻을 수 있다.
val data = getSomeData()
Kotlin
복사
컴파일러는 타입 추론을 통해 위 getSomeData()가 어떤 타입을 반환할 지 알 수 있고 그렇기에 타입추론을 제공한다. 하지만 우리는 이 코드만 봐서는 무슨 타입을 제공하는지 알 수 없다.
그렇다고 매 번 해당 메서드 위치까지 가서 반환 타입을 확인하기에는 정말 생각보다 많이 귀찮다. 그냥 다음과 같이 타입을 명시해주면 이야기는 훨씬 쉬워진다.
val data: UserData = getSomeData()
Kotlin
복사

이러한 가독성 향상의 장점 외에도 안전을 위해서 타입을 지정 하는게 좋다.
(관련 내용은 아이템 3: 최대한 플랫폼 타입을 사용하지 말라 와 아이템 4: inferred 타입으로 리턴하지 말라에서 확인할 수 있다.)
15. 리시버를 명시적으로 참조하라
리시버(receiver)란?
함수 또는 속성이 사용될 수 있는 context를 의미한다.
특정 객체에서 메서드를 호출할 경우 그 메서드 내부에선 호출된 객체를 this를 통해 참조할 수 있다. 이 때 this가 가리키는 객체를 리시버(receiver)라 한다.
리시버를 명시적으로 작성할 때와 그렇지 않을 때의 차이를 코드를 통해 파악해보자.
•
리시버를 표시하지 않는 퀵정렬 코드
fun <T : Comparable<T>> List<T>.quickSort(): List<T> {
if (this.size < 2) return this
val pivot = first()
val (smaller, bigger) = drop(1).partition { it < pivot }
return smaller.quickSort() + pivot + bigger.quickSort()
}
Kotlin
복사
•
리시버를 명시한 퀵정렬 코드
fun <T : Comparable<T>> List<T>.quickSort(): List<T> {
if (this.size < 2) return this
val pivot = this.first()
val (smaller, bigger) = this.drop(1).partition { it < pivot }
return smaller.quickSort() + pivot + bigger.quickSort()
}
Kotlin
복사
두 코드 모두 결과는 동일하다. 그럼 굳이 리시버를 명시 할 필요가 있을까?
위와 같은 경우 블럭{} 내부에 리시버가 하나뿐이였다. 그렇기에 별도로 리시버를 지정해주지 않아도 우리는 해당 메서드가 어떤 리시버의 메서드인지 파악을 할 수 있었다.
그렇다면 해당 블럭 내부의 스코프 범위에서 리시버가 하나가 아닌 둘 이상이라면 어떨까?
apply, with, run 함수를 사용할 때 이런 상황이 자주 생길 수 있다. 다음 코드를 보자.
class Node(val name: String) {
fun makeChild(childName: String) = create("$name.$childName")
.apply { print("Created ${name}") }
fun create(name: String): Node? = Node(name)
}
fun main() {
val node = Node("parent")
node.makeChild("child")
}
Kotlin
복사
실행 결과로 무엇이 출력 될 거라고 예상가는가?
단순하게 생각했을 때 예상되는 흐름은 다음과 같다.
1.
create("$name.$childName")
: Node(”parent.child”) 가 반환되고,
2.
Created + Node(”parent.child”).name이 호출되니
3.
Created parent.child 가 출력 될 것이다.
라고 예상할 수 있다. 하지만, 실제로 출력되는 결과는 Created parent이다. 왤까?
좀 더 이해하기 쉽게 리시버를 명시해서 파악해보자.
class Node(val name: String) {
fun makeChild(childName: String) = create("$name.$childName")
.apply { print("Created ${this?.name}") } // <-- 요기에 리시버 명시
fun create(name: String): Node? = Node(name)
}
fun main() {
val node = Node("parent")
node.makeChild("child") // Created parent.child
}
Kotlin
복사
이처럼 리시버를 명시하고 반환타입이 nullable이기에 safe call로 unpack한 뒤 호출해서 정상적으로 Created parent.child가 출력 될 것이다.
사실 이 방식은 apply의 잘못된 사용 예라고 한다. also를 사용했다면 명시적으로 it을 사용해야 하고 자연스레 리시버가 명시되게 되며, apply를 사용할 때보다 nullable처리에 안전한 선택이 될 수 있다.
class Node(val name: String) {
fun makeChild(childName: String) = create("$name.$childName")
.also { print("Created ${it?.name}") } // <-- 요기에 리시버 명시
fun create(name: String): Node? = Node(name)
}
fun main() {
val node = Node("parent")
node.makeChild("child") // Created parent.child
}
Kotlin
복사
그렇다면, 리시버가 하나 이상인 경우에는 어떻게 작성 할 수 있을까?
한 스코프에 리시버가 하나 이상인 경우 레이블을 지정하지 않고 리시버를 사용할 경우 가장 가까운 리시버를 참조한다. 그렇기에 좀 더 외부에 있는 리시버를 사용하고자 할 경우 레이블을 사용해 이를 해결할 수 있다.
class Node(val name: String) {
fun makeChild(childName: String) = create("$name.$childName")
.apply{ print("Created ${this?.name} in ${this@Node.name}") }
fun create(name: String): Node? = Node(name)
}
fun main() {
val node = Node("parent")
node.makeChild("child") // Created parent.child in parent
}
Kotlin
복사
@DslMarker
Kotlin DSL을 사용하는 경우 여러 리시버를 가진 요소들이 중첩되어도 리시버를 명시적으로 붙이지 않는다. (원래 그렇게 설계되었기 때문이다.)
하지만, 때로는 DSL에서 외부의 함수를 사용할 경우 문제가 될 수 있는 경우가 있는데, 다음 코드를 보자. HTML 의 table요소를 만드는 HTML dsl이다.
table {
tr {
td { + "Column 1" }
td { + "Column 2" }
}
tr {
td { + "Value 1" }
td { + "Value 2" }
tr {
td { + "Column 1" }
td { + "Column 2" }
}
}
}
Kotlin
복사
bold처리까지 해서 파악하기 쉽겠지만, 어디가 문제인지 보이는가?
모든 스코프에서 외부 스코프에 있는 리시버의 메서드를 사용할 수 있으면 위와 같이 tr 스코프안에서 table스코프의 tr 함수를 호출할 수 있게 되고, 이는 문제가 될 수 있다.
이러한 문제를 막기 위해 외부 리시버를 사용하는 것을 막기 위해서 코틀린에서는 메타 애노테이션을 제공하는데 그게 @DslMarker다.
@DslMarker
annotation class HtmlDsl
fun table(f: TableDsl.() -> Unit) { /*..*/ }
@HtmlDsl
class TableDsl { /*..*/ }
Kotlin
복사
위와 같이 사용하면 암묵적으로 외부 리시버를 사용하는 것이 금지된다.
table {
tr {
td { + "Column 1" }
td { + "Column 2" }
}
tr {
td { + "Value 1" }
td { + "Value 2" }
tr { // Compile Error
td { + "Column 1" }
td { + "Column 2" }
}
}
}
Kotlin
복사
그래도 굳이 외부 리시버의 함수를 사용하고 싶다면 레이블을 명시해서 사용할 수 있다.
table {
tr {
td { + "Column 1" }
td { + "Column 2" }
}
tr {
td { + "Value 1" }
td { + "Value 2" }
this@table.tr {
td { + "Column 1" }
td { + "Column 2" }
}
}
}
Kotlin
복사
정리하자면
코드 길이를 줄일 수 있다는 이유로 리시버를 제거하는 것은 지양 하는게 좋다.
리시버가 하나가 아닌 경우 리시버를 명시해서 예기치 못한 문제를 방지할 수 있을 뿐더러 가독성도 높아진다. 스코프가 여럿일 경우 this는 가장 가까운 외부 리시버를 참조하기에 가장 가까운 리시버가 무엇인지 파악하기 힘들다.
굳이 외부 리시버를 사용해야 하는 상황이 온다면 레이블을 명시하고, 이런 레이블 작성을 강제하기 위해서 @DslMarker 메타 애노테이션을 사용할 수 있다.
16. 프로퍼티는 동작이 아닌 상태를 나타내야 한다.
자바에서 코틀린으로 넘어온 개발자라면, 자바의 필드와 코틀린의 프로퍼티가 동일하다고 생각할 수 있다. 다음 코드를 보자.
//kotlin
var name: String? = null
//java
String name = null;
Kotlin
복사
둘 다 값을 저장한다는 공통점을 가지기에 동일하다고 판단할 수 있지만, 프로퍼티는 필드와 다르게 좀 더 많은 기능을 제공한다.
다음과 같이 Foo라는 클래스가 있다고 할 때 new Foo(”catsbi”) 로 인스턴스를 생한 뒤 System.out.println(foo.name) 을 호출하면 우리가 예상하듯 힙(heap)영역에서 저장된 name 인스턴스 필드를 가져와 catsbi가 출력 될 것이다.
//java
@AllArgsConstructor
class Foo {
String name;
}
Kotlin
복사
그럼 코틀린의 경우는 어떨까?
class Foo(name: String?) {
var name: String? = name
}
fun main() {
var foo = Foo("catsbi")
println(foo.name) // ??
}
Kotlin
복사
결과부터 말하면 동일하게 catsbi가 출력 될 것이다.
그런데 여기서 코틀린은 좀 더 사용자 정의 getter/setter를 가질 수 있다. 우리가 자바에서 사용하는 getName(), setName()이 아니라 foo.name, foo.name = bar 만 작성해도 getter,setter에 접근할 수 있다는 것이다.
•
사용자 정의 get/set 사용하기
class Foo(name: String?) {
var name: String? = name
get() = field?.uppercase()
set(value) {
if(!value.isNullOrBlank()) {
field = value
}
}
}
Kotlin
복사
이 코드에서는 field라는 식별자를 볼 수 있을 것이다.
이는 프로퍼티의 데이터를 저장해두는 백킹 필드(backing field)에 대한 레퍼런스이다.
참고로 val로 만들 경우 set은 필요가 없고 읽기 전용 프로퍼티이기에 field가 만들어지지 않는다.
name과 같이 var로 만들어 가변적인 프로퍼티를 파생 프로퍼티(derived property)라 부른다.
코틀린의 모든 프로퍼티는 이와 같이 기본적으로 캡슐화가 되어 있다.
이를 이용해서 자주 사용하고 많이 사용되는 값을 이슈로 인해 바꿔야 하는 경우 프로퍼티를 이용해서 쉽게 해결할 수 있다.
예를 들어 자주 사용되는 값이 Date타입이라고 할 때 직렬화 등의 이슈로 해당 타입으로 저장할 수 없다면 어떻게 해야 할 까? 데이터를 millis라는 별도의 프로퍼티로 옮기고, 이를 활용해 date 프로퍼티에 데이터를 저장하지 않고 wrap/unwrap 하도록 코드를 수정만 해주면 된다.
var date: Date
get() = Date(millis)
set(value) {
millis = value.time
}
Kotlin
복사
프로퍼티는 필드라기보다는 일종의 접근자 개념이기 때문에 인터페이스에서도 프로퍼티를 정의할 수 있고, 확장을 통해 재정의 가능하게 작성할 수도 있다.
interface Person {
val name: String
}
class Catsbi : Person {
override val name: String
get() = TODO("Not yet implemented")
}
open class Parent {
open val firstName: String = "KIM"
}
class Child: Parent() {
override val firstName: String = "LEE"
}
Kotlin
복사
또한 프로퍼티는 위임도 가능하다.
val db: Database by lazy { connectToDb() }
Kotlin
복사
프로퍼티는 접근자 개념이라고 말했듯이 본질적으로 함수이기에 확장 프로퍼티를 만드는 것 역시 가능하다.
val Developer.language: DevelopLanguage
get() = DevelopLanguage.JAVA
val Developer.salary: Long
get() = SalaryAnalysticsApi.findByLevel("JUNIOR")
val Developer.keyboard: Keyboard
get() = Keyboard(name = "moonlander", switches = KeySwitches.MX_BROWN)
Kotlin
복사
주의 사항
프로퍼티가 함수를 대신할 수 있다는 점 때문에 필드와 함수의 경계가 흐려질 수 있고, 그러다 보면 프로퍼티를 함수처럼 사용할 수도 있는데, 엄연히 말해서 프로퍼티로 함수를 완전히 대체하는 것은 좋지 않다. 다음 코드를 보면 sum 프로퍼티로 Tree 자료구조의 확장 프로퍼티를 선언했다.
//worst use case
val Tree<Int>sum: Int
get() = when (this) {
is Leaf -> value
is Node -> left.sum + right.sum
}
Kotlin
복사
sum이라는 프로퍼티를 보면 모든 요소를 반복 처리하기에 알고리즘이라고 할 수 있다.
하지만, 우리가 getter를 사용하며 알고리즘을 수행하고 계산비용이 소모될 것이라고 예상하지 않는다. 그렇기에 이러한 처리는 프로퍼티가 아닌 함수로 구현하는게 좋다.
//good use case
val Tree<Int>sum: Int = when (this) {
is Leaf -> value
is Node -> left.sum + right.sum
}
Kotlin
복사
프로퍼티가 아닌 함수를 사용하는게 좋은 경우
그럼 이렇게 경계선이 흐릿해보이는 상황에서 언제 무엇을 쓰는게 좋을지 어떻게 정할까?
책에서는 다음과 같은 상황들에서는 프로퍼티 대신 함수 사용을 권장한다.
1.
연산 비용이 높거나, 복잡도가 O(1)보다 큰 경우
: 우리가 .fieldName 이런식으로 dot(.)을 통해 프로퍼티를 호출할 경우 일반적으로 비용이 크게 소비될 것이라고 생각하지 않는다. 즉, 사용자가 해당 프로퍼티의 호출 비용이 높다고 생각하지 않기 때문에 의도치 않은 연산 비용이 들게 될 수 있기 때문에 비용이 높은 작업이 필요한 경우 함수로 만드는게 좋고, 이를 기반으로 캐싱등의 리팩토링도 고려할 수 있다.
2.
비즈니스 로직을 포함하는 경우
: 로깅, 리스너 통지, 바인드된 요소 변경과 같은 단순한 동작 이상의 행위 역시 1번과 같은 이유로 사용자는 예상하지 못하기에 함수를 사용하는게 더 적절하다.
3.
결정적이지 않은 경우
: 반복적인 호출에 동일한 값이 나오지 않는다면 비결정적인 동작이기에 이런 경우 함수를 사용하는게 좋다.
4.
변환의 경우
: 보통 toDouble(), toInt(), toIntOrNull()등의 변환함수가 제공되는데 프로퍼티로 변환 작업을 수행하는건 적절한 책임이 아니다. 그리고 보통 프로퍼티는 명사구로 짓기에 이런 변환 동작을 표현하기에 적절하지 않다.
5.
getter에서 프로퍼티 상태 변경이 일어나야 하는 경우
: getter를 호출하며 내부적으로 상태가 변경이 있을 것이라고 예상하지는 않는다.
5가지의 이유를 들었는데, 공통된 사항들이 보이지 않는가?
좀 더 쉽게 설명하면, 프로퍼티는 보통 명사구로 짓는다. 즉 특정 상태를 표현한다. 하지만 명사구인 프로퍼티에서 동사구의 동작등이 수행되는것을 우리는 예상하지 않기에 동작에 필요한 비용을 고려하지 않는다. 그렇기에 프로퍼티에는 높은 비용, 혹은 동작등이 필요한 작업을 사용하지 않는게 좋다.
17. 이름 있는 아규먼트를 사용하라.
메서드의 매개변수가 하나 이상인데 타입이 동일하다면 어떤 문제가 있을까?
다음은 과자의 영양정보를 담는 클래스이다.
data class NutritionalInformation(
private val calorie: Int, //칼로리 - 필수
private val sodium: Int = 0, //나트륨
private val carbohydrate: Int, //탄수화물 - 필수
private val sugars: Int = 0, //당류
private val fat: Int, //지방 - 필수
private val transFat: Int, //트랜스지방
private val saturatedFat: Int = 0, //포화지방
private val cholesterol: Int = 0, //콜레스테롤
private val protein: Int //단백질 - 필수
)
Kotlin
복사
자바였다면 위와 같은 클래스를 만들기 위해서는 생성자에 인수를 작성할 때 순서에 아주 민감하고
휴먼에러가 발생하기 쉬운 코드가 작성될 것이다.
//Java 였다면....
NutritionalInformation info = new NutritionalInformation(
377, 115, 15, 4, 11, 0, 4, 0, 2
)
Java
복사
차례대로 나트륨, 탄수화물, 당류, 지방, 트랜스지방, 포화지방, 콜레스테롤, 단백질..가독성이 낮다.
자바에서는 빌더 패턴을 사용하거나 변수를 사용해서 의미를 명확하게 한다.
int calorie = 377;
int sodium = 115;
int carbohydrate =15;
int sugars = 4;
int fat = 11;
int transFat = 0;
int saturatedFat = 4;
int cholesterol =0;
int protein =2;
//local variable 사용
NutritionalInformation info = new NutritionalInformation(
calorie,sodium,carbohydrate,sugars,fat,transFat,saturatedFat,cholesterol,protein
)
//builder pattern 사용
NutritionalInformation info = NutritionalInformation.builder()
.calorie(377)
.sodium(115)
.carbohydrate(15)
.sugars(4)
.fat(11)
.transFat(0)
.saturatedFat(4)
.cholesterol(0)
.protein(2)
.build();
Java
복사
하지만, 변수를 사용하는 방식은 여전히 휴먼에러의 문제가 발생할 여지가 크고, 빌더패턴은 별도로 패턴을 구현해야하는 비용문제가 크다. 코틀린에서는 이 경우 named parameter를 사용해 저비용 고신뢰성을 갖출 수 있다.
//kotlin named parameter
val info = NutritionalInformation(
calorie = 377,
sodium = 115,
carbohydrate = 15,
sugars = 4,
fat = 11,
transFat = 0,
saturatedFat = 4,
cholesterol = 0,
protein = 2
)
Kotlin
복사
이처럼 이름 있는 아규먼트(named parameter)는 이름 기반으로 값이 무엇을 나타내는지 알 수 있고 파라미터 입력 순서와 무관하기에 휴먼 에러에서도 안전할 수 있다.
특히 다음과 같은 경우 더욱 더 named parameter 사용을 권장한다.
•
default argument
•
같은 타입의 파라미터가 많은 경우
•
함수 타입의 파라미터가 있는 경우(단 마지막 경우는 제외)
default argument
프로퍼티가 default argument를 가질 경우, 항상 이름을 붙혀 사용하는 것이 좋다.
보통 함수이름은 필수 파라미터와 관련되어 있기 때문에 기본 값(default value)을 갖는 옵션 파라미터(optional parameter)에 대해서는 설명이 생략되어 있거나 모호하게 작성되어 있는데, 이러한 경우 이름을 붙여 사용하는게 좋다.
(사실 이건 코틀린 뿐 아니라 다른 상황도 마찮가지이다. 코틀린같은 경우에도 키워드 인수로 선택적인 동작을 제공하자고 하는데 default argument에 이름을 붙여 사용하는 걸 추천한다.)
같은 타입의 파라미터가 많은 경우
위에서 영양정보를 봤다면 이미 충분히 이해했을 것이다.
타입이 같은 파라미터가 이어서 작성되어 있다면, 휴먼에러가 발생하기 쉽다. 다른 예제를 보자
fun sendEmail(to: String, message: String)
Kotlin
복사
위 함수는 메일을 보내기 위한 함수인데 보낼 대상자 정보(to)와 메세지 내용(message)가 동일한 타입이다. 여기서 클라이언트가 to와 message를 반대로 작성해도 컴파일 에러는 발생하지 않을 것이다. 그렇기에 이 경우 named parameter를 사용하는게 좋다.
sendEmail(
to = "catsbi@midasin.com"
message = "hello, ..."
)
Kotlin
복사
함수 타입 파라미터
일반적으로 함수 타입 파라미터는 마지막에 위치하는게 좋다. 함수 이름이 함수 타입 아규먼트를 설명해주기도 한다. 예를 들어 repeat 함수를 생각해보면 repeat함수 다음 오는 람다는 반복될 블록을 의미한다.
repeat(5) {
println("hello,")
} //hello,hello,hello,hello,hello,
Kotlin
복사
하지만, 위와 같이 표현할 수 있는건 일반적으로 마지막에 위치하는 함수 파라미터 뿐이다.
그 밖의 모든 함수 타입 아규먼트는 named parameter를 사용하는게 좋다.
observable.getUsers()
.subscribeBy(
onNext = { users: List<User> -> ...},
onError = {throwable: Throwable -> ...},
onCompleted = { ...}
)
Kotlin
복사
즉, 정리하자면…
named parameter는 여러 상황에서 유용하게 사용될 수 있다.
자바와 비교해서 더 높은 신뢰도를 더 낮은 비용으로 제공할 수 있고,
사용자에게는 더 높은 가독성과 휴먼 에러 방지를 할 수 있고, 의미가 모호한 옵션 파라미터에 대해서도 의미를 파악하기 쉽게 해 줄 수 있다.
18. 코딩 컨벤션을 지켜라

코틀린을 작성 할 때는, 아니 모든 언어를 작성할 때는 각각의 언어에 맞는 범용적인 코딩 컨벤션이 있고, 이러한 컨벤션이 모든 프로젝트에서 최고의 선택일 순 없어도, 최선으로 나아가는 방향과 다르지 않기에 최대한 지켜주는것이 좋다. 이런 코딩 컨벤션을 지킴으로써 우리는 다음과 같은 이점을 가져올 수 있다.
•
어떤 프로젝트를 접해도 (비교적)쉽게 코드를 이해할 수 있다.
•
다른 외부 개발자의 프로젝트의 코드도 (비교적)쉽게 이해할 수 있다.
•
다른 개발자도 내 코드의 작동 방식을 쉽게 추측할 수 있다.
•
코드를 병합하고, 한 프로젝트의 코드 일부를 다른 코드로 이동하는 것이 쉽다.
그렇기에 우리는 코틀린 코딩 컨벤션에 익숙해 질 필요가 있다.
아직 익숙하지 않거나 내가 놓치는 부분들도 잡아주기 위해서 도구를 사용할 수도 있는데, 주로 IntelliJ formmater를 이용하거나 ktlink를 사용한다.
참고: IntelliJ formatter는 다음과 같이 사용하면 된다.
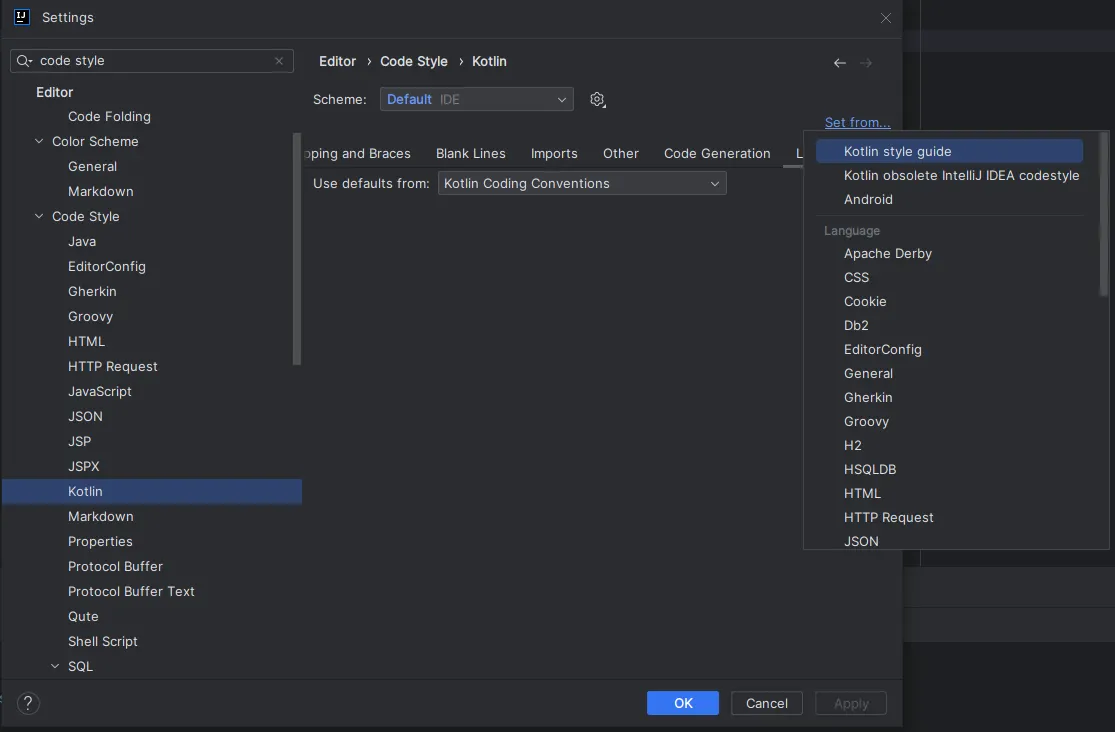
settings → Editor → Code Style → Kotlin → Set From…

