
1. 함수형 인터페이스와 람다 표현식 소개
함수형 인터페이스(Functional Interface)
•
추상 메소드를 딱 하나만 가지고 있는 인터페이스
(두 개의 메소드가 있다면 함수형 인터페이스가 아닙니다.)
•
SAM(Single Abstract Method) 인터페이스
•
@FunctionalInterface 애노테이션을 가지고 있는 인터페이스
@FunctionalInterface
public interface RunSomething {
void doIt();
//void doItAgain();
static void printName(){
System.out.println("catsbi");
}
default void printAge(){
System.out.println("33");
}
}
Java
복사
⇒ 위 코드를 보면 printName()과 printAge 메소드도 있는데 함수형 인터페이스가 아닐까요? 답은 함수형 인터페이스(Functional Interface)가 맞다 입니다. 중요한건 static 메소드와 default메소드가 있는게아니라 추상 메소드 가 1개만 있어야 한다는 것입니다.
⇒@FunctionalInterface 함수형 인터페이스를 정의할일이 있을때는 인터페이스에 이 어노테이션을 붙혀주면 더 명시적으로 구분할 수 있고 함수형 인터페이스 규칙을 위반하면 컴파일시 에러가 발생하게 됩니다.
그렇다면 이 함수형 인터페이스를 어떻게 구현하여 사용할까요?
기존의 방법
: 익명 내부 클래스를 만들어 사용.
public class Foo {
public static void main(String[] args) {
//익명 내부 클래스(anonymous inner class)
RunSomething runSomething = new RunSomething() {
@Override
public void doIt() {...}
};
}
}
Java
복사
자바 8 이후의 방법
람다표현식(Lambda Expressions)을 이용하여 간략하게 구현
public class Foo {
public static void main(String[] args) {
RunSomething runSomething = () -> System.out.println("Hello");
}
}
Java
복사
만약 함수내에서 처리해야하는게 하나가 아니라면 아래와 같이 사용합니다.
public class Foo {
public static void main(String[] args) {
RunSomething runSomething = () -> {
System.out.println("Hello");
System.out.println("two line");
};
}
}
Java
복사
[실행 결과]
람다 표현식(Lambda Expressions)
•
함수형 인터페이스의 인스턴스를 만드는 방법으로 사용될 수 있습니다.
•
코드를 줄일 수 있습니다.
•
메소드 매개변수, 리턴타입, 변수로 만들어 사용할 수도 있습니다.
자바에서 함수형 프로그래밍
•
함수를 (일급 객체)First class object로 사용할 수 있다.
:RunSomething runSomething = () -> System.out.println("Hello");
자바에서는 이런 형태를 특수한 형태의 오브젝트라고 볼 수 있습니다. 함수형 인터페이스를 인라인 형태로 구현한 오브젝트라 볼 수 있는데, 자바는 객체지향언어(OOP)이기 때문에 이 함수를 메소드 매개변수, 리턴타입, 변수로 만들어서 사용할 수 있습니다.
•
고차 함수(Higher-Order Function)
◦
함수가 함수를 매개변수로 받을 수 있고 함수를 리턴할 수도 있다.
⇒ 자바에서는 함수가 특수한 형태의 오브젝트일 뿐이기에 가능합니다.
•
순수 함수(Pure Function)
@FunctionalInterface
public interface RunSomething {
int doIt(int number);
}
public class Foo {
public static void main(String[] args) {
RunSomething runSomething = (number) -> {
return number + 10;
};
System.out.println(runSomething.doIt(1));//11
System.out.println(runSomething.doIt(1));//11
System.out.println(runSomething.doIt(1));//11
}
}
Java
복사
⇒ 수학적인 함수에서 가장 중요한 것은 입력받은 값이 동일할 때 결과가 같아야 한다는 것입니다. 매개변수로 1을 넣었으면 몇번을 호출하던 11이 나와야합니다. 이런 결과를 보장하지 못하거나 못할 여지가 있다면 함수형 프로그래밍이라고 할 수 없습니다.
◦
사이드 이펙트가 없다.(함수 밖에 있는 값을 변경하지 않는다.)
◦
상태가 없다.(함수 밖에 있는 값을 사용하지않는다.)
public class Foo {
public static void main(String[] args) {
//int baseNumber = 10; //---(1)
RunSomething runSomething = new RunSomething() {
//int baseNumber = 10; //---(2)
@Override
public int doIt(int number) {
return number + baseNumber;
}
};
}
}
Java
복사
⇒ (1), (2) 위치에 있는 변수는 둘 다 외부값이라 할 수 있고, 이를 접근하거나 변경하려하면 순수함수라 할 수 없습니다.(물론, 문법적으로 (1) 위치에 있는 지역변수를 참조할수는 있지만 참조하게 될 경우 다른 곳에서 해당 변수를 변경할 수 없습니다.(final 변수 취급)
정리
자바에서 함수형 프로그래밍을 할 수 있도록 제공된 함수형 인터페이스(Functional Interface)와 람다 표현식(Lambda Expressions) 에 대해 알아보았습니다. 이는 굳이 함수형 프로그래밍을 안하더라도 사용할 수 있습니다.
하지만, 함수형 프로그래밍을 하겠다고하면 이 두가지를 사용함에 있어서 순수 함수, 불변성에 대해 고려할 필요가 있습니다.
2. 자바에서 제공하는 함수형 인터페이스
Java가 기본으로 제공하는 함수형 인터페이스

자바에서 미리 정의해둔 자주 사용할만한 함수 인터페이스
•
Function<T, R>
•
BiFunction<T, U, R>
•
Consumer<T>
•
Supplier<T>
•
Predicate<T>
•
UnaryOperator<T>
•
BinaryOperator<T>
함수 인터페이스 분석
1. Function<T, R>
: T타입을 받아서 R타입을 반환하는 함수 인터페이스
•
R apply(T t)
: T라는 타입을 받아서 R이라는 타입을 반환하는 추상 메소드
(Applies this function to the given argument)
클래스를 이용한 방법(클릭)
람다 표현식(Lambda Expressions)를 이용한 방법(클릭)
•
함수 조합용 메소드
andThen(클릭)
compose(클릭)
: 파라미터에 입력받은 결과값(함수의 결과)를 함수를 호출한 인스턴스에 전달해 apply()하는 함수
2. BiFunction<T,U,R>
: Function<T, R> 과 동일하지만 U라는 타입을 하나 더 받습니다. 그래서 T, U 타입을 받아 R을 반환하는 함수 인터페이스 입니다.
•
R apply(T t, U u)
public class Foo {
public static void main(String[] args) {
BiFunction<Integer, String, String> prefixHello = (i, s) ->{
return "hello"+i.toString() + s;
};
System.out.println(prefixHello.apply(10, "catsbi"));//hello10catsbi
}
}
Java
복사
1.
BiFunction<Integer, String, String> prefixHello = (i, s) ->{...}
⇒ 매개변수가 하나 더 늘어났다는 점을 제외하면 Function 함수 인터페이스와 동일합니다.
3. Consumer<T>
: T 타입을 받아서 로직을 수행 후 반환값은 없는 함수 인터페이스
•
accept(T t)
public class Foo {
public static void main(String[] args) {
Consumer<Integer> printT = (i) -> System.out.println(i);
printT.accept(10);
}
}
Java
복사
•
함수 조합용 메소드
◦
andThen
4. Supplier<T>
:T 타입의 값을 제공하는 함수 인터페이스
•
T get()
public class Foo {
public static void main(String[] args) {
Supplier<Integer> get10 = () -> 10;
System.out.println(get10);//10
}
}
Java
복사
1.
Supplier<Integer> get10 = () -> 10;
⇒ 내가 입력하는 값이 없기 때문에 매개변수가 없으며 T타입 의 값을 반환만 해줍니다.
5. Predicate<T>
:T 타입을 받아서 boolean을 리턴하는 함수 인터페이스
•
boolean test(T t)
public class Foo {
public static void main(String[] args) {
Predicate<String> startsWithCatsbi = (s) -> s.startsWith("catsbi");
Predicate<Integer> isOdd = (i) -> i%2 == 0;
System.out.println(startsWithCatsbi.test("catsbiStudyCode"));
System.out.println(isOdd.test(3));
System.out.println(isOdd.test(4));
}
}
Java
복사
•
함수 조합용 메소드
◦
And
◦
Or
◦
Negate
public class Foo {
public static void main(String[] args) {
Predicate<Integer> isOdd = (i) -> i%2 == 0;
Predicate<Integer> isEven = (i) -> i%2 == 1;
System.out.println(isOdd.and(isEven).test(4));
System.out.println(isOdd.or(isEven).test(4));
System.out.println(isOdd.negate().test(3));
}
}
Java
복사
6. UnaryOperator<T>
: Function<T, R>의 특수한 형태로 입력값 하나를 받아 동일한 타입을 리턴하는 함수 인터페이스
public class Foo {
public static void main(String[] args) {
UnaryOperator<Integer> plus10 = (i) -> i + 10;
UnaryOperator<Integer> multiply2 = (i) -> i * 2;
System.out.println(plus10.andThen(multiply2).apply(2));
}
}
Java
복사
1.
UnaryOperator<Integer> plus10 = (i) -> i + 10;
⇒ 기존 Function<T, R>과 비슷하지만 차이점은 반환 타입R 을 따로 작성하지 않는데 그 이유는 T 타입이 반환타입이 되기 때문입니다. UnaryOperator는 입력타입과 반환타입이 동일합니다.
7. BinaryOperator<T>
: BiFunction<T, U, R>의 특수한 형태로, 동일한 타입으 입력값 두 개를 받아 리턴하는 함수 인터페이스
public class Foo {
public static void main(String[] args) {
BinaryOperator<Integer> plus10Combine = (i, j) -> i + j + 10;
System.out.println(plus10Combine.apply(10, 20));//40
}
}
Java
복사
3. 람다 표현식
람다(Lambda)
(인자 리스트) → {바디}
•
인자 리스트
◦
인자가 없을 때: ()
◦
인자가 한개일 때 : (one) 또는 one 으로 괄호 생략 가능
◦
인자가 여러개일 때 : (one, two) 괄호 생략 불가능
◦
인자의 타입은 생략 가능, 컴파일러가 추론(infer)하지만 명시할수도 있습니다.
(Integer one, Integer two)
•
바디
◦
화살표 오른쪽에 함수 본문을 정의합니다.
◦
여러 줄인 경우 {} 를 사용해서 묶습니다.
◦
한 줄인 경우 생략 가능하며, return도 생략 가능합니다.
public class Foo {
public static void main(String[] args) {
Supplier<Integer> get10 = () -> 10;
Supplier<Integer> get20 = () -> {
return 20;
};
UnaryOperator<Integer> plus10 = i -> i + 10;
UnaryOperator<Integer> plus20 = (i) -> i + 20;
BinaryOperator<Integer> plus30 = (i, j) -> i + j + 30;
BinaryOperator<Integer> plus40 = (Integer i, Integer j) -> i + j + 40;
}
}
Java
복사
변수 캡처(Variable Capture)
private void run() {
int baseNumber = 10; //effective final variable
//final int baseNumber = 10; //Java 8 부터 final 생략 가능
//로컬 클래스
class LocalClass {
void printBaseNumber(){
System.out.println(baseNumber);
}
}
//익명 클래스
Consumer<Integer> integerConsumer = new Consumer<Integer>() {
@Override
public void accept(Integer integer) {
System.out.println(baseNumber);
}
};
//람다
IntConsumer printInt = (i) -> System.out.println(i + baseNumber);
printInt.accept(10);
}
Java
복사
: 로컬클래스, 익명클래스, 람다 모두 baseNumber라는 로컬 변수를 참조할 수 있습니다. 여기서 참조가능한 로컬변수는 final이거나 effecitve final 인 경우에만 참조할 수 있습니다. 그렇지 않을 경우 concurrency 문제가 생길수 있어 컴파일에서 에러가 발생합니다.
여기까지만 보면 람다 가 굳이 차이점도 없어 보입니다. 이 람다가 로컬클래스, 익명클래스 와 가장 큰 차이점은 쉐도잉에 있습니다.
쉐도잉이란?
: 가려진다는 의미로 좌측 그림을 보면 A라는 클래스가 있습니다. 그리고 이 클래스 안에는 name이라는 변수가 선언되있습니다.
그리고aa라는 메소드가 있고 그 안에는 name이라는 변수가 선언되있습니다. 여기서 메소드 내의 name은 메소드의 외부이자 클래스의 내부의 name 변수를 가립니다. 그래서 클래스의 name이 hansol일지라도 메소드 내부의 name이 catsbi라면 name은 catsbi가 됩니다.

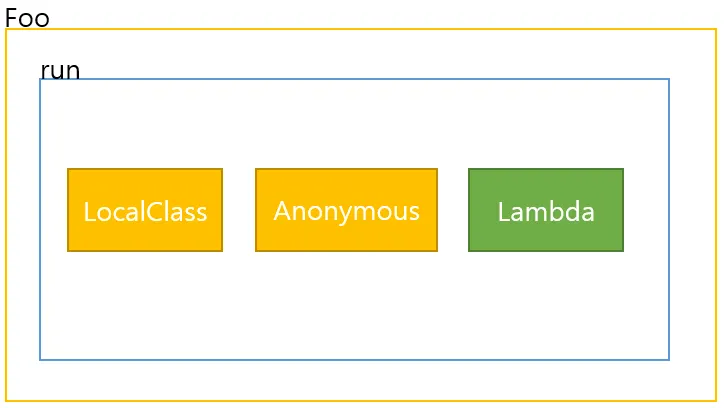
로컬 클래스나 익명 클래스, NestedClass는 내부에 변수가 선언되는데 그 변수와 동일한 이름이 외부에 클래스 내부에 있다면 클래스 내부의 변수는 가려지게됩니다. 즉, 쉐도잉이 되는데요.
람다는 그렇지않습니다. 람다는 항상 자신이 속한 스코프를 참조합니다.
즉, 람다는 표현식내에 같은 이름의 변수를 선언할 수 없습니다. (같은 스코프니까!)
Effective Final
java8 부터 허용된 개념으로 기존에는 final 키워드를 붙혀야만 익명클래스, 로컬클래스에서 사용이 가능했으나 java 8 이후 final을 붙히지 않더라도 어느곳에서도 해당 변수의 값을 변경하지 않는다면 사실상 final로 보기 때문에 로컬 클래스, 익명클래스, 람다에서 사용이 가능합니다.
4. 메소드 레퍼런스
개요
기존에 람다 표현식(Lambda Expression)은 직접 인라인으로 기능들을 구현했습니다. 하지만, 매번 소소한 기능부터 복잡한 기능까지 새로 구현을 하는 것은 매우 비효율적입니다.
람다를 통해 이미 존재하는 메소드를 호출하거나 생성자 호출, 혹은 인스턴스의 메소드를 호출하는 것이라면 어떨까요? 이를 메소드 레퍼런스를 사용해 매우 간결하게 표현할 수 있습니다.
기본 보기
Search
코드를 통한 학습
•
Greeting.java
: 메소드 레퍼런스로 사용될 레퍼런스 클래스
public class Greeting {
private String name;
public Greeting() {
}
public Greeting(String name) {
this.name = name;
}
public String getName() {
return name;
}
public String hello(String name) {
return "hello " + name;
}
public static String hi(String name) {
return "hi " + name;
}
}
Java
복사
⇒ 메소드 레퍼런스 예제의 레퍼런스로 사용될 예제 클래스 Greeting 입니다.
•
기존의 방식대로 "hi "+파라미터 기능 구현
UnaryOperator<String> hi = (s) -> "hi " + s;
System.out.println(hi.apply("catsbi"));//hi catsbi
Java
복사
⇒ 기존의 람다를 이용한 방법이라면 hi라는 메소드를 직접 만들어 문자열 결합후 반환해줍니다.
하지만 이 로직은 이미 Greeting 이라는 클래스에 구현되어있습니다.
•
메소드 레퍼런스를 사용한 기능 구현
UnaryOperator<String> hi = Greeting::hi;
System.out.println(hi.apply("catsbi"));//hi catsbi
Java
복사
⇒ Greeting 클래스에 구현되어있는 static 메소드 hi를 메소드 레퍼런스(스태틱 메소드 참조)를 사용하여 호출해봤습니다. 그렇다면 static 메소드가 아닌 특정 인스턴스의 메소드를 사용해야 한다면 어떻게 해야할까요
•
특정한 인스턴스의 존재하는 메소드를 메소드 레퍼런스로 사용
Greeting greeting = new Greeting();
UnaryOperator<String> hello = greeting::hello;
System.out.println(hello.apply("catsbi"));//hello catsbi
Java
복사
⇒ Greeting 클래스의 인스턴스(greeting)을 생성후 해당 인스턴스의 메소드인 hello를 메소드 레퍼런스로 이용해 호출해봤으며 결과값으로 hello catsbi가 출력되었습니다.
여기서, 한걸음 더 나가 생성자 역시 메소드 레퍼런스로 사용해 구현할 수 있습니다.
•
생성자를 메소드 레퍼런스로 구현
//입력값이 없는 생성자 호출
Supplier<Greeting> newGreeting = Greeting::new;
Greeting greeting = newGreeting.get();
//입력값이 있는 생성자 호출
Function<String, Greeting> newGreetingWithName = Greeting::new;
Greeting catsbiGreeting = newGreetingWithName.apply("catsbi");
Java
복사
⇒ 파라미터가 따로 없이 반환값만 있는 기본 생성자의 경우 Supplier를 통해 구현합니다.
메소드 레퍼런스로 new 연산자를 사용하는데 이때 주의할점은 Greeting::new 는 Supplier 인것이지 실제 인스턴스생성이 아닙니다. 생성을 위해서는 get() 메소드를 호출하여 인스턴스를 만들어줘야합니다.
⇒ 입력값(name)이 있는 생성자의 경우 Function을 사용해줍니다. 위 코드에서는 생성자 초기값으로String 인자값을 받아 전달 후 생성된 Greeting 타입의 인스턴스를 반환합니다.
•
특정타입의 불특정 인스턴스의 메소드 참조
:names 정렬 구현
String[] names = {"catsbi", "hansol", "mosition"};
//기존의 익명클래스를 이용한 방법
Arrays.sort(names, new Comparator<String>() {
@Override
public int compare(String s, String t1) {
return 0;
}
});
//람다 표현식
Arrays.sort(names, (s, t1) -> 0);
//메소드 레퍼런스를 이용한 방법
Arrays.sort(names, String::compareToIgnoreCase);
System.out.println(Arrays.toString(names));//[catsbi, hansol, mosition]
Java
복사
⇒ 기존의 개발자들이 사용하던 방법은 익명클래스를 이용해 정렬을 구현했습니다.
하지만, java 8이후 Comparator클래스는 @FunctionalInterface가 되었고 함수형 인터페이스이기 때문에 람다표현식으로 사용할 수 있게되었습니다.
또한, 람다 표현식으로 사용할 수 있다는 말은 메소드 레퍼런스를 사용할 수 있다는 의미이기 때문에 String 클래스의 campareToIgnoreCase 메소드를 사용하며 names의 파라미터를 넘겨서 정렬해줍니다.

