목차
개요

항상 주변을 단정히 정돈하는 사람은 단지 찾기를 너무 귀찮아하는 사람이다.
- 독일 속담
데이터베이스는 기본적으로 데이터를 저장하고, 저장한 데이터를 제공하는 두 가지의 동작을 수행한다. 말 그대로 저장소 역할을 하고 있는데, 저장하는 데이터 혹은 요청하는 데이터가 많아지고, 조건들이 많아질수록 어떻게 저장하고 어떻게 데이터를 가져올지에 대해 고민해야 한다.
애플리케이션 개발자는 처음부터 사용가능한 여러 저장소 엔진 중에 애플리케이션에 적합한 엔진을 선택해야 한다.

특정 작업부하(workload)에서 좋은 성능을 내게끔 저장소 엔진을 조정하려면 저장소 엔진이 내부에서 수행되는 작업에 대해 대충이라도 알고있을 필요가 있다.
특히 트랜잭션 작업부하 최적화 저장소 엔진과 분석 최적화 엔진은 차이가 크기 때문에 인지를 하고 애플리케이션 요구사항에 맞는 엔진을 선택해야 한다.
이번 장에서는 관계형 데이터베이스와 NoSQL 데이터베이스에 사용되는 저장소엔진에 대해 알아본다.
데이터베이스를 강력하게 만드는 데이터 구조
데이터베이스에서 특정 키의 값을 찾기 위해서 매번 처음부터 키를 비교하면서 값을 찾는것은 너무 비효율적이다.
데이터의 수가 N만큼 늘어난다면 검색 비용도 N만큼 늘어난다. 그렇기에 특정 키의 값을 효율적으로 찾기 위해서 다른 데이터 구조가 필요하다.

색인
색인을 이용해 데이터베이스에서 특정 키의 값을 효율적으로 찾을 수가 있다.
색인의 일반적인 개념은 어떤 부가적인 메타데이터를 유지하는 것으로 이 메타데이터가 이정표 역할을 해서 원하는 데이터 위치를 찾는데 도움을 준다. 이러한 색인은 다음과 같은 특징을 가진다.
•
많은 데이터베이스에서 색인의 추가및 삭제를 허용한다.
•
데이터베이스의 내용에 영향을 주지 않는다.
•
질의 성능에만 영향을 준다.
•
나중에 추가적으로 유지보수하는 경우 쓰기 과정에서 오버헤드가 발생한다.
•
쓰기 속도를 느리게 만든다. (색인도 갱신해야 하기 때문이다.)
이러한 색인은 내가 잘 선택했을 경우 질의 속도에서 많은 이익을 가져올 수 있다.
하지만, 데이터베이스에서 자동으로 색인하지 않기 때문에 애플리케이션 개발자 혹은 데이터베이스 관리자가 적절한 색인을 수동으로 만들어줘야 색인의 장점을 극대화 할 수 있다.
해시 색인
여러 종류의 데이터가 있지만, 가장 기본적인 데이터인 키-값 데이터를 색인해보자.
이 키-값 데이터를 모아놓은 저장소는 파이썬의 dictionary type, 자바의 해시 맵(HashMap)과 유사하다. 이 해시 맵을 이용해 디스크 상의 데이터를 색인 해 볼 수 있을 것 같다.

단순히 파일에 추가하는 방식으로 데이터 저장소를 구성할 때 사용할만한 간단한 색인전략은 키를 데이터 파일의 바이트 오프셋에 매핑해 인메모리 해시 맵을 유지하는 것이다.
(바이트오프셋: 값을 바로 찾을 수 있는 위치)
파일에 새로운 키-값 쌍을 추가할 때마다 추가한 데이터의 오프셋을 반영하기 위해 해시 맵도 새로 갱신해야 한다.(키 삽입&갱신 모두 해당된다.)
비트캐스크(Bitcask)
리악(Riak)의 기본 저장소 엔진인 비트캐스크는 해시 색인을 사용하는데, 모든 해시 맵을 메모리에 유지하기 때문에 사용 가능한 램(RAM)에 모든 키가 저장된다는 조건을 전제로 고성능 읽기/쓰기를 보장한다. 또한, 데이터 파일의 일부가 파일 시스템 캐시에 있다면 읽기에 디스크 입출력이 필요 없다.
비트캐스크와 같은 저장소 엔진은 각 키의 값이 자주 갱신되는 상황에 매우 적합하다.
유튜브의 동영상 주소와 재생 횟수가 키-값(URL - 재생횟수) 쌍인 경우 키의 값이 자주 갱신되는 대표적인 예다. 즉, 작업 부하에서 키당 쓰기 수가 많지만 모든 키를 메모리에 적재할 수 있는 상황 말이다.
메모리가 부족하다면?
파일에 추가만 한다면 결국 디스크 공간은 부족해질 수 밖에 없다. 그렇기에 특정 크기의 세그먼트(segment)로 로그를 나누어서 해결을 할 수 있다.
특정 크기에 도달하면 세그먼트 파일을 닫고 새로운 세그먼트 파일에 이후 쓰기를 구행한다.

세그먼트 컴팩션(segment compaction)
위 그림과 같이 세그먼트는 컴팩션을 수행하여 중복된 키를 버리고 각 키의 최신 값만 유지할 수 있다. 이러한 컴팩션은 세그먼트를 더 작게 만들 수 있기 때문에 동시에 여러 세그먼트를 병합할 수도 있다.

세그먼트 병합과 컴팩션 동시 수행
다만, 각각의 세그먼트는 불변(immutable)하기 때문에 병합할 세그먼트는 새로운 파일을 만들어 작성한다. 이러한 세그먼트의 병합과 컴팩션은 백그라운드 스레드에서 수행할 수 있기에 컴팩션 수행 도중 이전 세그먼트 파일을 사용해 읽기 쓰기 요청의 처리를 정상적으로 수행할 수 있다.
병합 및 컴팩션이 끝난 이후에는 새로운 세그먼트를 사용하게끔 전환하고 이전 세그먼트 파일을 삭제하면 된다.
이렇게 완성된 세그먼트는 키를 파일 오프셋에 매핑한 자체 인메모리 해시테이블을 갖는데, 키의 값을 찾기 위해 최신 세그먼트 해시 맵을 확인하고, 키가 없다면 다음 최신 세그먼트를 차례대로 확인한다.
이러한 세그먼트 관리 전략을 실제로 구현하기 위해서는 다음과 같은 문제들을 고려해야 한다.
1.
파일 형식
: CSV는 로그에 가장 적합한 형식이 아니다. 바이트 단위의 문자열 길이를 부호화한 뒤 다음 원시 문자열(이스케이핑이 필요 없이)을 부호화하는 바이너리 형식을 사용하는 편이 더 빠르고 간단하다.
2.
레코드 삭제
: 키와 관련된 값을 삭제하려면 데이터 파일에 특수한 삭제 레코드(때로는 툼스톤(tombstone)이라 불림)를 추가해야 한다. 로그 세그먼트가 병합될 때 툼스톤은 병합 과정에서 삭제된 키의 이전 값을 무시하게 한다.
3.
고장(Crash) 복구
: 데이터베이스 재시작시 인메모리 해시 맵은 손실된다.
비트캐스크는 각 세그먼트 해시 맵을 메모리로 조금 더 빠르게 로딩할 수 있게 스냅숏을 디스크에 저장해 복구 속도를 높인다.
4.
부분적으로 레코드 쓰기
: 데이터베이스는 로그에 레코드를 추가하는 도중에도 죽을 수 있다.
비트캐스크 파일은 체크섬을 포함하고 있어 로그의 손상된 부분을 탐지해 무시할 수 있다.
5.
동시성 제어
: 쓰게 스레드를 하나만 두어 동시성 제어를 할 수 있다. 데이터 파일 세그먼트는 추가 전용이거나 불변(immutable)이기에 다중 스레드로 동시에 읽기를 해도 문제가 없다.
추가하지말고 덮어쓰면 안될까?
추가 전용 로그는 낭비처럼 보일 수 있다. 예전 값을 새로운 값으로 덮어쓰는건 안될까?
하지만 다음과 같은 이유로 추가 전용 설계는 좋은 설계라고 할 수 있다.
•
속도
: 추가와 세그먼트 병합은 순차적인 쓰기 작업이기에 보통 무작위 쓰기보다 빠르다. HDD에서 특히 빠르고, 일부 확장된 순차쓰기는 SSD에서도 빠르다.
•
고장 복구(Crash Recovery)
: 세그먼트가 불변이라면 값을 덮어쓰다가 데이터베이스가 죽더라도 남아있는 이전 값 부분을 이용해 다시 작성하면 된다.
•
파편화 방지
: 시간이 지날수록 조각화되는 데이터 파일 문제를 피할 수 있다.
제한 사항
해시-색인의 장점만 얘기한 것 같은데 제한 사항 또한 있다.
•
메모리에 너무 많은 키를 저장할 수 없다.
: 메모리는 용량에 제한이 있고, 디스크는 성능에 제한이 있기 때문에 너무 많은 키는 관리하기가 까다롭다.
•
범위 질의(range query)에 효율적이지 않다.
: kitty00000 ~ kitty99999사이의 모든 키를 스캔하려면 해시 맵에서 모든 개별 키를 조회해야 한다.
SS 테이블
해시 색인을 통해 키-값 데이터를 색인을 했는데, 여기서 키-값 쌍을 키로 정렬하는 형식을 정렬된 문자열 테이블(Sorted String Table) 혹은 SS테이블이라 부른다.
이러한 SS테이블을 해시 색인을 가진 로그 세그먼트보다 몇 가지 큰 장점을 가진다.
1.
세그먼트 병합이 파일이 사용 가능한 메모리보다 크더라도 간단하고 효율적이다.
병합정렬(mergesort) 알고리즘과 유사한 방식이다. 만약, 여러 세그먼트에서 동일한 키가 있다면, 가장 최신 세그먼트가 최신 값을 가지고 있기에 최근 세그먼트의 값을 유지한다.

입력 파일을 읽고 파일의 첫 번째 키를 보고 가장 낮은키를 복사 및 반복한다.
2.
특정 키를 찾기 위해 모든 키의 색인을 유지할 필요가 없다.

인메모리 색인을 가진 SS테이블
SS 테이블의 키는 정렬되어 있기 때문에 일부분의 키의 오프셋을 알고 있다면, 찾으려는 키보다 높은 우선수위의 존재하는 키의 오프셋으로 이동해 스캔하면 된다. 일부 키에 대한 인메모리 색인은 여전히 필요하지만, 수 킬로바이트 정도는 빠르게 스캔할 수 있기에 세그먼트 파일 내 수 킬로바이트당 키 하나만 색인되어있으면 된다.
참고: 모든 키와 값이 고정된 크기라면 이진 검색을 사용하면 되기에 인메모리 색인을 전혀 사용하지 않아도 된다.
3.
읽기 요청은 요청 범위 내의 여러 키-값 쌍을 스캔해야 하기에 해당 레코드들을 블록으로 그룹화하고 디스크에 쓰기 전에 압축한다(위 그림의 압축할 수 있는 블럭) 그러면 희소 인메모리 색인의 각 항목은 압축된 블록의 시작을 가리키게 된다. 압축은 디스크 공간 절약 뿐 아니라 I/O 대역폭 사용도 줄인다.
SS테이블 생성과 유지
디스크상에 정렬된 구조를 유지하는 것도 가능하지만, 난이도 측면에서 메모리에 유지하는편이 훨씬 간단하며 레드 블랙 트리(red-black tree)나 AVL 트리와 같이 잘 알려졌고 사용 가능한 트리 데이터 구조를 이용해 임의 순서로 키를 삽입하고 정렬된 순서로 해당 키를 읽을 수 있다.
이러한 데이터 구조를 이용해 저장소 엔진을 다음과 같이 만들 수 있다.
•
쓰기가 발생하면 멤테이블(memtable)이라 불리는 인메모리 균형 트리(balanced tree) 데이터 구조에 추가한다. (레드 블랙 트리가 인메모리 균형 트리 데이터 구조이다.)
•
멤테이블이 임계값보다 커지면 SS테이블 파일로 디스크에 기록하고, 그 동안의 쓰기는 새로운 멤테이블 인스턴스에 기록한다.
•
읽기 요청은 다음과 같은 우선순위로 키를 찾아 제공한다.
1.
멤테이블
2.
디스크상의 최신 세그먼트
3.
디스크상의 두 번째 세그먼트
4.
디스크상의 N 번째 세그먼트
•
백그라운드에서 종종 세그먼트 병합 및 컴팩션 과정을 수행한다.
SS 테이블 관리 전략의 문제점
데이터베이스 고장시점의 멤테이블 데이터가 손실될 수 있는 문제가 있는데, 이런 문제를 피하기 위해 쓰기를 즉시 추가할 수 있게 분리된 로그를 디스크상에 유지하고, 멤테이블이 SS테이블로 기록된 후에는 해당 로그를 버릴수도 있다. 또한, 멤테이블 복원에만 필요한 자료이기에 정렬 여부는 중요하지 않다.
LSM 트리
로그 구조화 병합 트리(Log-Structured Merge-Tree, LSM 트리)는 로그 구조화 파일 시스템의 초기작업의 기반이 되는 색인 구조로 정렬된 파일 병합과 컴팩션 원리를 기반으로 하는 저장소 엔진을 LSM 저장소 엔진이라고 부른다.
성능 최적화
1.
블룸 필터를 이용한 존재하지 않는 키 탐색 최적화
:특정 데이터의 키를 찾기위해 멤테이블부터 디스크상의 가장 오래된 세그먼트까지 스캔해야 하는 경우가 있을 수 있다. 존재하지 않는 키를 찾기 위해서 전체 세그먼트 스캔까지 하게 되면 성능 이슈가 분명 발생할 수 있다. 이를 최적화 할 필요가 있는데, 저장소 엔진은 보통 블룸 필터(Bloom filter)를 추가적으로 사용한다.
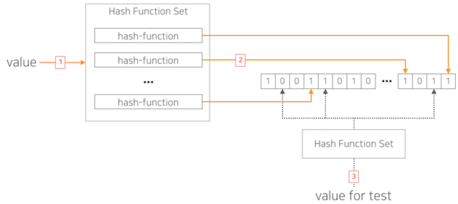
블룸 필터(Bloom filter)
: 확률적 자료구조라고도 하는 블룸필터는 특정 값이 집합에 속해 있는가를 검사하는 필터이자 이를 구성하는 자료형이라고 한다. 데이터베이스에 존재하지 않음을 알려주기에 존재하지 않는 키를 위한 디스크 읽기를 절약 할 수 있다. (더 자세히)2.
SS 테이블을 압축&병합하는 순서와 시기를 결정하는 전략 선택
:일반적으로 선택하는 전략은 크기 계층(size-tiered)과 레벨 컴팩션(leveled compaction)이다.
크기 계층 컴팩션은 상대적으로 좀 더 새롭고 작은 SS테이블을 상대적으로 오래됐고 큰 SS테이블에 연이어 병합한다. 레벨 컴팩션은 키 범위를 더 작은 SS테이블로 나누고 오래된 데이터는 개별 레벨로 이동하기에 컴팩션을 점진적으로 진행해 디스크 공간을 절약한다.
B트리
로그 구조화 색인(LSM) 사용이 점차 늘고는 있지만, 아직 가장 널리 사용되는 색인 구조는 B트리(B-tree)이며 LSM과는 상당히 다르다.
현재 대부분의 관계형 데이터베이스와 많은 비관계형 데이터베이스는 표준 색인 구현으로 B트리를 사용한다.
B트리는 SS테이블과 딱 한가지가 유사한데, 키로 정렬되니 키-값 쌍을 유지하기에 키-값 검색과 범위 질의에 효율적이라는 점이다.
LSM 트리와의 차이점
가변 크기를 가진 세그먼트로 나누고 순차적으로 세그먼트를 기록하는 LSM과는 다르게 고정 크기(4KB 혹은 더 큰) 블록이나 페이지로 나누고 한 번에 하나의 페이지에 읽기/쓰기를 한다. 디스크가 고정 크기 블록으로 배열되기에 하드웨어와 더 밀접한 설계이다.
B트리 색인을 이용한 키 검색

B 트리 색인을 이용한 키 검색
각 페이지는 주소나 위치를 이용해 식별이 가능하다.
그렇기에 하나의 페이지가 다른 페이지를 참조할 수 있는데, 이는 포인터와 비슷하지만, 메모리가 아닌 디스크에 있다는 차이가 있다. 위 그림은 B트리 색인을 이용한 키 검색인데, 다음과 같은 과정을 가진다.
1.
한 페이지가 B트리의 루트(root)로 지정된다.
2.
키가 251이 포함된 범위를 찾아서 200과 300사이를 나눈 페이지로 이동한다.
3.
좀 더 세분화된 페이지에서 동일하게 251이 포함된 250 ~ 270범위를 나타내는 페이지로 이동한다.
4.
해당 페이지는 최종적인 개별 키(리프 페이지(leaf page))를 포함하며, 이 페이지에서 내가 찾고자 하는 키의 값을 포함하거나 값을 찾을 수 있는 페이지의 참조를 확인할 수 있다.
이러한 탐색 과정에서 한 페이지가 하위 페이지를 참조하는 수를 분기 계수(branching factor)라고 부른다. 위 탐색 과정의 분기 계수는 6이다.
B트리 값 추가 및 갱신
새로운 키로 값을 추가하고 싶다면 새로운 키가 포함되는 페이지를 찾아 키와 값을 추가하고, B트리에 존재하는 키의 값을 갱신하려면 키를 포함하고 있는 리프 페이지를 검색한 뒤 페이지의 값을 바꾼 뒤 디스크에 다시 기록한다.
그런데, 새로운 키가 포함되는 페이지가 여유 공간이 없을 경우 해당 페이지를 반으로 나눠 두 개의 페이지로 만들고 상위 페이지가 새로운 키 범위의 하위 부분들을 알 수 있게 갱신한다.

B트리에서 키-값 추가시 페이지에 여유 공간이 없는 경우
이러한 알고리즘은 트리가 계속 균형을 유지하는 것을 보장한다.
n개의 키를 가진 B트리는 깊이가 항상 이며 대부분의 데이터베이스는 B트리의 깊이가 3~4단계 정도면 충분하다.
신뢰할 수 있는 B트리 만들기
B트리는 LSM과는 다르게 새로운 데이터를 디스크 상의 페이지에 덮어쓴다.
그렇기에 덮어쓰기가 페이지 위치를 변경하지 않고, 모든 참조는 변하지 않는다. 무조건 파일에 추가만 되는 로그 구조화 색인(LSM)과는 다르다.
B트리에 값을 추가할 때 페이지가 너무 많아져서 페이지를 나눠야 하는 경우, 두 하위 페이지의 참조를 상위페이지에 갱신시켜야하는데, 일부 페이지만 기록하고 데이터베이스가 고장난다면 색인은 훼손될 수 있고 고아 페이지(orpan page)가 발생할 수 있다.
그렇기에, 이런 고장 상황에서 자가복구가 가능하도록 전략이 필요한데, 일반적으로 디스크 상에 쓰기 전 로그(write-ahead log, WAL)(재실행 로그(redo log)라고 하는 데이터 구조를 추가해 B트리를 구현한다. WAL은 트리 페이지에 변경된 내용을 적용하기 전 B트리의 변경 사항을 기록하는 추가 전용 파일이다.
다중 스레드 환경에서 B 트리 동시 접근
다중 스레드 환경에서 동시에 여러 스레드가 B 트리에 접근할 경우 주의하지 않으면 동시성 문제가 발생하기 쉽다. 그렇기에 보통 래치(latch)(가벼운 잠금(lock))로 트리의 데이터 구조를 보호한다.
(ex: java의 CountDownLatch)
B 트리 최적화
•
쓰기 시 복사 방식(copy-on-write scheme)을 사용해 페이지 고장 복구를 해결한다.
변경된 페이지는 다른 위치에 기록하고 트리에 상위 페이지의 새로운 버전을 만들어 새로운 위치를 가리키게 한다. 이는 동시성 제어에도 유용하다.
•
페이지에 전체 키를 저장하는게 아닌 키를 축약해 사용해 공간을 절약할 수 있다. 페이지 하나에 키를 더 많이 채우면 트리는 더 높은 분기 계수와 낮은 트리 깊이 수준을 가질 수 있다. 이러한 변형을 때로 B+ 트리라 부른다.
•
리프 페이지를 디스크 상에 연속된 순서로 트리에 배치가 될 수록, 질의가 정렬된 순서로 키 범위의 많은 부분을 스캔할 때 효율적이다. 하지만 트리가 커질수록 순서를 유지하기 힘들다.
•
트리에 포인터를 추가하여 리프 페이지가 양쪽 형제 페이지에 대한 참조를 가지면 상위 페이지로 이동하지 않고도 키를 스캔할 수 있다.
•
프랙탈 트리(fractal tree)같은 B트리 변형은 디스크 찾기를 줄이기 위해 로그 구조화 개념을 일부 빌렸다.
참고: 프랙탈 트리(Fractal-Tree)
B트리의 단점을 보완하기위해 고안된 알고리즘으로 MySQL의 스토리지 엔진(TokuDB)에 적용되어 있다. B트리의 문제인 인덱스 키 검색 및 변경 과정중 디스크의 랜덤I/O 이 많이 필요한 점을 최소화하고 순차 I/O로 변환해서 처리할 수 있게 한다.
평균적인 처리 능력이 B 트리보다 400배 정도 빠르고 TokuDB의 키 추가 및 삭제는 InnoDB보다 100배가량 빠르다는 장점이 있지만 동시성처리에서 InnoDB보다 불안정하다는 단점도 가지고 있다.
B 트리와 LSM 트리 비교
보통 LSM트리는 쓰기에서 빠르고 B트리는 읽기에서 더 빠르다고 여기는데, 읽기에서 LSM이 더 느린 이유는 각 컴팩션 단계에 있는 여러 데이터 구조와 SS테이블을 확인해야 하기 때문이다.
하지만, 이런 특징보단 작업부하의 세부 사항이 더 중요하다. 저장소 엔진의 성능을 측정할 때 고려하면 좋은 몇 가지를 알아보자.
LSM 트리의 장점
•
B트리보다 높은 쓰기 처리량
: B트리 색인은 모든 데이터 조각을 쓰기 전 로그 한 번과 트리 페이지에 한 번(페이지가 분리될 때 다시 기록)해서 두 번 기록해야 한다. 로그 구조화 색인도 SS테이블의 반복된 컴팩션과 병합으로 여러 번 데이터를 다시 쓰고, 이처럼 데이터베이스에 한 번 쓰기 위해 디스크에 여러 번의 쓰기를 야기하는 효과를 쓰기 증폭(write amplification)이라 한다.
이처럼 쓰기가 많은 애플리케이션에서는 디스크 쓰기 속도가 성능 병목일텐데, LSM트리는 보통 B트리보다 쓰기 처리량을 높게 유지할 수 있다. 쓰기 증폭도 더 낮고 트리에서 여러 페이지를 덮어쓰는게 아니라 순차적으로 컴팩션된 SS테이블 파일을 쓰기 때문이다.
HDD에서는 순차쓰기가 임의쓰기보다 훨씬 빠르기 때문에 이런 차이는 중요하다.
•
B트리보다 높은 압축률
: LSM트리는 압축률이 B트리보다 더 좋기 때문에 디스크에 더 적은 파일을 생성한다.
B트리 저장소 엔진은 파편화로 인해 디스크 공간 일부가 남는데 LSM트리는 페이지 지향적이지 않고 주기적으로 파편화를 없애기 위해 SS테이블을 다시 기록하기 때문에 저장소 오버헤드가 더 낮고, 레벨 컴팩션(level compaction을 사용하면 더 그렇다.
•
SSD에서 더 유리할 가능성이 높다.
: 대부분의 SSD 펌웨어는 내부적으로 로그 구조화 알고리즘을 사용해 임의 쓰기를 순차 쓰기로 전환하기에 저장소 엔진의 쓰기 패턴이 SSD에 영향을 주는지는 확실치 않다.
하지만, 낮은 쓰기 증폭과 파편화 감소는 SSD에게 유리하고 데이터를 더 밀집할수록 가능한 I/O 대역폭 내에서 더 많은 읽기/쓰기 요청이 가능하다.
LSM 트리의 단점
•
컴팩션 과정이 진행중인 읽기/쓰기 성능에 영향을 준다.
: 디스크의 자원은 한정적인데, LSM트리에서 백그라운드에서 컴팩션을 점진적으로 수행하면서 동시 접근에 영향을 주지않으려 하다보면 컴팩션 과정이 끝날때까지 요청이 대기해야 하는 상황이 생기기 쉽다. 보통은 문제가 없지만, 로그 구조화 저장소 엔진의 상위 백분위 질의의 응답 시간은 때때로 꽤 길기에 문제가 될 수 있다.
그에 비해 B트리의 성능은 로그 구조화 저장소 엔진보다 예측하기 쉽다.
•
유한한 디스크 쓰기 대역폭 대비 높은 쓰기 처리량
: LSM은 높은 쓰기 처리량을 제공하는데 이게 너무 높을 경우 컴팩션이 유입 쓰기 속도를 따라가지 못할 수 있는데, 이 경우 디스크 상에 병합되지 않은 세그먼트 수가 디스크 공간이 부족할 때까지 증가한다. 이렇게 세그먼트 수가 많아지면, 읽기 작업을 위해 확인해야 할 세그먼트 파일의 수도 많아져서 읽기 또한 느려진다.
보통 SS 테이블 기반 저장소 엔진은 유입 쓰기의 속도를 조절하지 않기에 명시적 모니터링이 필요하다.
•
여러 세그먼트에 같은 키의 복사본이 존재할 수 있다.
: B트리가 색인의 한 곳에만 키가 있는 반면 로그 구조화 저장소 엔진은 여러 세그먼트에 같은 키의 다중 복사본이 존재할 수 있기 때문에 강력한 트랜잭션 시맨틱(semantic)을 제공하는 데이터베이스에는 B 트리가 훨씬 매력적이다.
많은 RDB에서 트랜잭션 격리(transactional isolation)는 키 범위의 잠금을 사용해 구현한 반면 B트리 색인에서는 트리에 직접 잠금을 포함시킨다.
그래서 B 트리와 LSM 트리중 무엇을 사용해야 하는가?
기존 데이터 저장소는 많은 작업부하에 대해 지속적으로 좋은 성능을 제공하는 B트리가 지속적으로 활용 될 것이고, 새로운 데이터 저장소에서는 로그 구조화 색인이 점차 인기를 얻고 있다.
요구사항에 맞는 저장소 엔진을 결정하기 위해 테스트를 통해 경험적으로 결정하는 것도 나쁘지 않다.
기타 색인 구조
보조 색인(secondary index)
RDB에서는 CREATE INDEX를 이용해 보조 색인을 생성할 수 있는데, 주로 조인 질의를 효율적으로 수행하는데 결정적인 역할을 한다.
보조 색인은 키-값 색인에서 쉽게 생성할 수 있는데, 기본키 색인과는 키가 고유하지 않다는 차이점을 가진다. 즉 같은 키를 가진 많은 로우(문서, 정점)가 있을 수 있다.
이 점은 색인의 각 값에 일치하는 로우 식별자 목록을 만들거나 로우 식별자를 추가해 각 키를 고유하게 만드는 방법이 있다. 어느 쪽이든 보조 색인으로 B트리 및 로그 구조화 색인을 사용할 수 있다.
색인 안에 값 저장하기
색인에서 키는 질의가 검색하는 대상이 되지만 값은 그렇지 않다.
값은 질문의 실제 로우(문서, 정점)거나 다른 곳에 저장된 로우를 가리키는 참조다.
여기서 후자인 경우 로우가 저장된 곳을 힙 파일(heap file)이라 하고 순서 없이 데이터를 저장한다. (추가 전용이거나 나중에 새로운 데이터로 덮어 쓰기 위해 삭제된 로우를 기록할 수도 있다.)
힙 파일 접근은 여러 보조 색인이 존재할 때 데이터 중복을 피할 수 있어 일반적으로 사용된다.
각 색인은 힙 파일에서 위치만 참조하고 실제 데이터는 일정한 곳에 유지한다.
힙 파일 접근 방식은 키를 변경하지 않고 값을 갱신할 때 효율적이다.
새로운 값이 이전 값보다 많은 공간을 필요로 하지 않으면 레코드를 제자리에 덮어쓸 수 있다. 하지만, 새로운 값이 많은 공간을 필요로 할 경우 힙에서 충분한 공간이 있는 새로운 곳으로 위치를 이동해야 한다. 이 경우 모든 색인이 레코드의 새로운 힙 위치를 가리키게끔 갱신하거나 이전 힙 위치에 전방향 포인터를 남겨둬야 한다.
색인에서 힙 파일로 다시 이동하는 일은 읽기 성능에 불이익이 너무 많아서 어떤 상황에서는 색인 안에 바로 색인된 로우를 저장하는 편이 바람직하며, 이를 클러스터드 색인(clustered index)이라 한다.
MySQL의 InnoDB 저장소 엔진은 테이블의 기본키가 항상 클러스터드 색인이고 보조 색인(힙 파일의 위치가 아닌) 기본키를 참조한다.
클러스터드 색인과 비클러스터드 색인 사이의 절충안을 커버링 색인(covering index) 이나 포괄열이 있는 색인(index with included column)이라 한다. 이 색인은 색인 안에 테이블의 칼럼 일부를 저장해서 색인만을 사용해 일부 질의에 응답이 가능하다.
다만, 이런 절충안도 추가적인 저장소가 필요하고 쓰기 과정에 오버헤드가 발생하며, 애플리케이션 단에서 복제로 인한 불일치를 파악할 수 없기에 데이터베이스는 트랜잭션 보장을 강화하기위해 별도의 노력이 필요하다.
다중 칼럼 색인
하나의 키가 아닌 여러 키를 가지고 동시에 질의를 해야한다면 기존에 설명한 색인으로는 부족하다.
다중 칼럼 색인의 가장 일반적인 유형은 결합 색인(concatenated index)이다.
결합 색인은 하나의 칼럼에 다른 칼럼을 추가하는 방식으로 하나의 키에 여러 필드를 단순히 결합한다. 이 방법은 순서가 정렬되어 있기 때문에 최초 컬럼 혹은 최초 컬럼 + 두 번째 컬럼 조합을 가진 키를 찾을 때도 사용할 수 있지만, 첫 번째 컬럼을 제외하고 두 번째 컬럼부터 질의하는 경우에는 쓸모가 없다.
다차원 색인은 한 번에 여러 칼럼에 질의하는 좀 더 일반적인 방법이다.

특히 지리 공간 데이터에서 중요한데, 특정 위도와 경도를 범위 질의로 찾으려고 하는 경우
위도 동경 120 ~ 180, 경도 북위 30 ~ 80 까지의 위치한 모든 도시를 찾는다고 한다면 SQL로는 다음과 같이 표현할 수 있다.
SELECT * FROM cities WHERE latitude > 120 and latitude < 180
AND longitude > 30 and longitude < 80;
SQL
복사
이러한 질의는 표준 B 트리나 LSM 트리 색인으로는 효율적인 응답이 불가능하다. 위도 범위내의 도시나, 경도 범위 안의 도시 목록을 가져올 순 있지만 둘을 동시에 가져오지 못한다.
이를 해결하기 위한 방법으로는 이차원 위치를 공간 채움 곡선(space-filling curve)을 이용해 단일 숫자로 변환하여 일반 B트리 색인을 사용하는 것과, R트리처럼 전문 공간 색인(specialized spatial index)을 사용하는 것이다. (Ex: PostGIS는 R트리 같은 지리 공간 색인을 구현했다.)
참고: 공간 채움 곡선
평면상의 정사각형 영역을 모두 채우는 곡선. 총칭하여 공간을 채우는 곡선(space filling curve)라고 하지만 최초로 제시한게 페아노의 곡선이다.

페아노 곡선
참고: R트리
B 트리와 비슷하지만 다차원의 공간 데이터를 저장하는 색인이다.
공간을 최소 경계 사각형(MBR, Minimum Bounding Rectangle)로 분할해 저장한다. MBR끼리는 겹칠수도 있고 상위 MBR은 하위 MBR들을 포함하는 계층적인 트리구조이다. 각 노드는 미리 정의된 범위내에서 유동적인 개수의 자식 노드들의 정보(MBR과 포인터)를 가진다.
- 위키백과(link)
이러한 다차원 색인은 지리학적인 위치 뿐 아니라 색상 범위를 검색하기 위해 3차원 색인(빨강, 초록, 파랑)을 사용하거나 날씨를 검색하기 위해 2차원 색인(날짜, 기온)을 사용할 수도 있다.
전문 검색과 퍼지 색인
정확한 키에 대한 특정 값 혹은 범위 질의가 아닌 유사한 키에 대한 검색은 어떻게 할 수 있을까?
이처럼 애매모호한(fuzzy) 질의에는 다른 기술이 필요하다.
루씬과 같은 전문 검색 엔진은 특정 단어를 검색할 때 다음과 같은 기술 지원을 한다.
•
해당 단어의 동의어로 질의를 확장한다.
•
동일한 문서에서 서로 인접해 나타난 단어를 검색하거나 혹은 언어학적으로 텍스트를 분석해 사용한다.
•
문서나 질의의 오타에 대처하기위해 특정 편집 거리(edit distance) 내 단어를 검색할 수 있다.
(편집 거리: 한 글자가 추가되거나 삭제되거나 교체되었을 때 편집 거리 1이라 칭한다.)
루씬은 용어 사전을위해 SS 테이블 같은 구조를 사용하는데, 이 구조는 작은 인메모리 색인이 필요하며, 키를 찾는데 필요한 정렬 파일의 오프셋을 질의에 알려주는데 사용한다.
루씬에서 인메모리 색인은 여러 키 내 문자에 대한 유한 상태 오토마톤(finite state automaton)으로 트라이(trie)와 유사하며, 레벤슈타인 오토마톤(levenshtein automaton)으로 변환할 수 있다.
레벤슈타인 오토마톤은 특정 편집 거리 내에서 효율적인 단어 검색을 제공한다.
참고: 유한 상태 오토마톤, 레벤슈타인 오토마톤
유한한 개수의 상태를 가지게 해주는 추상적 기계(인터페이스의 API개념이 아닐까?) 를 유한 상태 오토마톤이라 하며, 단어 검색에서 주어진 레벤슈타인 거리 안에 문자열 집합들을 정확히 인지하는 유한 상태 오토마톤를 생성하도록 해주는게 레벤슈타인 오토마톤이다.
즉, 많은 질의들을 단일 문자열에 대해 비교하고 최대한의 거리로 비교하는데 빠른 방법을 제공하는게 레벤슈타인 오토마톤이다.
모든 것을 메모리에 보관
갈수록 램이 저렴해지고 용량이 커지면서 데이터셋 대부분을 메모리에 보관하는 방식도 현실성을 가지게 되고 이로 인해 인메모리 데이터베이스가 개발되었다.
인메모리 데이터베이스는 기존 인메모리 키-값 저장소와 다르게 데이터의 지속성을 목표로 하기에 특수 하드웨어를 사용하거나 디스크에 변경 사항의 로그를 기록하거나 디스크에 주기적인 스냅샷을 기록하거나 다른 장비에 인메모리 상태를 복제하는 방법이 있다.
특수 하드웨어 장비를 사용하지 않는 다면 데이터베이스 재시작시 디스크나 네트워크를 통해 복제본에 상태를 적재해야하는데, 그렇다 하더라도 디스크는 지속성을 위한 추가 전용 로그이고, 읽기는 메모리에서 제공되기 때문에 인메모리 데이터베이스라고 할 수 있다.
우리가 흔히 사용하는 레디스(Redis)나 카우치베이스(Couchbase)도 비동기로 디스크에 기록하기 때문에 약한 지속성을 제공한다.
인메모리 데이터베이스는 디스크에서 읽지 않아도 된다는게 성능상 장점은 아니다.
메모리가 충분하지 않을 때 가장 최근에 사용하지 않은 데이터를 메모리에서 디스크로 내보내고 나중에 다시 접근할 때 메모리에 적재하는 안티 캐싱(anti-caching)접근 방식을 이용해 가용 메모리보다 더 큰 데이터셋을 지원하게끔 확장할 수 있다.
이는 전체 메모리 페이지보다 개별 레코드 단위로 작업할 수 있기 때문에 효율적으로 메모리를 관리할 수 있다.
트랜잭션 처리나 분석?
보통 애플리케이션은 색인을 사용해 일부 키에 대한 적은 수의 레코드를 찾는다. 그리고 레코드는 사용자 입력 기반으로 추가 및 갱신된다. 이런 애플리케이션은 대화식이기에 이런 접근 패턴을 온라인 트랜잭션 처리(online trrasaction processing, OLTP)이라 한다.
하지만, 시간이 흐르면서 데이터베이스를 데이터 분석(data analytic)에도 점점 더 많이 사용하기 시작했다. 데이터 분석은 기존 트랜잭션과 접근 패턴이 매우 다르다.
사용자에게 소수의 원시 데이터를 반환하는게 아닌 많은 수의 레코드를 스캔한 뒤 일부 칼럼만 읽어서 집계 통계(카운트, 합, 평균 등)를 계산해야 한다.
이런 질의는 사용자보다는 비즈니스 분석가가 작성하여 회사 경영진의 의사 결정을 돕는 보고서 작성용으로 사용되며 이런 접근 패턴을 온라인 분석 처리(online analytic processing, OLAP)라고 부른다.
이 두가지 접근 패턴(OLTP, OLAP)는 다음과 같은 특성을 가진다.
특성 | 트랜잭션 처리 시스템(OLTP) | 분석 시스템(OLAP) |
주요 읽기 패턴 | 질의당 적은 수의 레코드, 키 기준으로 가져옴 | 많은 레코드에 대한 집계 |
주요 쓰기 패턴 | 임의 접근, 사용자 입력을 낮은 지연 시간으로 기록 | 대규모 불러오기(bulk import, ETL) 또는 이벤트 스트림 |
주요 사용처 | 웹 애플리케이션을 통한 최종 사용자/소비자 | 의사결정 지원을 위한 내부 분석가 |
데이터 표현 | 데이터의 최신 상태(현재 시점) | 시간이 지나며 일어난 이벤트 이력 |
데이터셋 크기 | 기가바이트에서 테라바이트 | 테라바이트에서 페타바이트 |
처음에는 둘 다 동일한 데이터베이스를 사용했으나, 최근에 들어서는 OLTP 시스템을 분석 목적으로 사용하지 않고 개별 데이터베이스에서 분석을 수행하는 경향을 보였으며, 이러한 개별 데이터베이스를 데이터 웨어하우스(data warehouse)라고 불렀다.
데이터 웨어하우징
OLTP 시스템은 사용자에게 제공되며 고가용성과 낮은 지연 시간이 매우 중요하다.
그렇기 때문에 OLTP 데이터베이스에 즉석 분석 질의(ad hoc analytic query)를 함부로 실행시켰다간 서비스의 전체 서비스 퀄리티 하락으로 이어질 수 있기 때문에 문제가 될 수 있다.
그렇기 때문에 비즈니스 분석가 입장에선 부담없이 비용이 큰 분석 쿼리를 작업할 공간이 필요하고, 그래서 데이터 웨어하우스라는 OLTP에 영향을 주지 않는 개별 데이터베이스가 존재하며, 이는 회사 내의 모든 다양한 OLTP 시스템에 있는 데이터의 읽기 전용 복사본이다.
데이터는 OLTP 데이터베이스에서 (주기적인 데이터 덤프나 지속적인 갱신 스트림을 사용해) 추출(extract)하고 분석 친화적인 스키마로 변환(trasnform)하여 데이터 웨어하우스에 적재(load)한다. 이러한 과정을 ETL(Extract-Transform-Load)이라 한다.
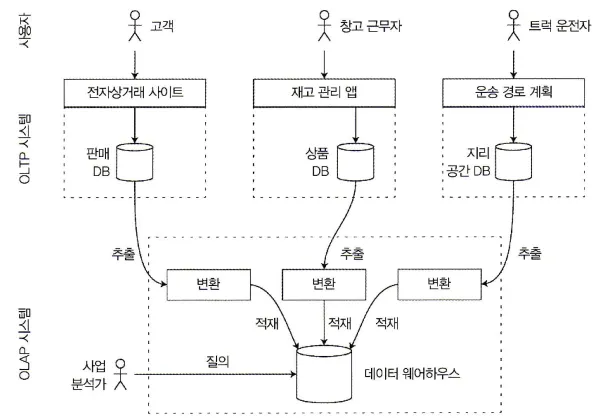
ETL의 간략한 개요
OLTP 데이터베이스와 데이터 웨어하우스의 차이점
SQL은 일반적으로 분석 질의에 적합하기에 데이터웨어 하우스는 일반적인 관계형 모델을 사용하고, SQL 질의를 생성하고 결과를 시각화하고 분석가가 드릴 다운(drill-down), 슬라이싱(slicing), 다이싱(dicing)같은 작업을 통해 데이터를 탐색할 수 있게 해주는 여러 그래픽 데이터 분석 도구가 있다.
OLTP나 데이터 웨어하우스 둘 다 SQL 질의 인터페이스를 지원한다는 공통점이 있지만, 둘은 서로 매우 다른 질의 패턴에 맞게 최적화되었기 때문에 내부는 완전히 다르다. 그렇기에 다수의 데이터베이스 벤더 역시 트랜잭션 처리와 분석 작업부하를 둘 다 지원하기보단 하나에 특화되도록 지원하는데 중점을 둔다.
참고: 드릴 다운(drill-down), 슬라이싱(slicing), 다이싱(dicing)
드릴 다운은 요약된 정보에서 상세 정보까지 계층을 나눠 구체적으로 분석하는 작업.
슬라이싱과 다이싱은 상세한 분석을 위해 주어진 큰 규모의 데이터를 작은 단위로 나누고 원하는 세부 분석 결과를 얻을 때까지 반복한다는 의미.
분석용 스키마: 별 모양 스키마와 눈꽃송이 모양 스키마
많은 데이터 웨어하우스는 별 모양 스키마(star schema)(차원 모델링(dimensional modeling)이라고도 함)로 상당히 정형화된 방식을 사용한다.

별 모양 스키마 예제
스키마 중심에 사실 테이블(fact table)이 있고, 이 테이블의 로우는 특정 시간에 발생한 이벤트에 해당한다. 웹 사이트 트래픽을 분석한다면 각 로우가 페이지 뷰나 사용자 클릭에 해당하는데, 이런 개별 이벤트를 사실 테이블에 담기에 사실 테이블은 매우 커질 수 있다.
애플이나 월마트, 이베이같은 대기업의 웨어하우스에는 수십 페타바이트의 트랜잭션 내역이있는데 대부분 사실 테이블이다.
이런 사실 테이블의 다른 칼럼은 차원 테이블(dimension table)이라 부르는 다른 테이블을 가리키는 외리 키 참조다. 사실 테이블의 각 로우는 이벤트를 나타내고 차원은 이벤트의 속성을 나타낸다.
•
누가(who)
•
어떻게(how)
•
언제(when)
•
왜(why)
무엇을(where)
이러한 템플릿의 변형을 눈꽃송이 모양 스키마(snowflake schema)라고 하며 차원이 하위 차원으로 더 세분화된다. 쉽게 말해 하위 차원테이블이 모두 실제 값만을 저장하는게아닌 또다른 차원테이블의 외래키를 저장하여 세분화하는 것이다. 이는 별 모양 스키마보다 더 정규화됐지만, 작업 난이도가 더 올라가기 때문에 분석가들은 별 모양 스키마를 더 선호한다.
칼럼 지향 저장소
테이블에 로우가 수십, 수백개가 아닌 수천만, 수억개가 되고 크기도 페타바이트가 된다면 효율적인 저장 및 질의는 매우 어려운 문제가 된다.
사실 테이블은 칼럼이 100개 이상인 경우가 많지만, 질의에 필요한 칼럼은 몇 개 되지 않는다(4~5개)
어떻게 이런 분석 질의를 효율적으로 실행시킬 수 있을까?
대부분의 OLTP 데이터베이스 저장소는 로우 지향방식으로 데이터를 배치한다. 테이블에서 한 로우의 모든 값은 서로 인접하게 저장된다. 이 점은 문서 데이터베이스와 유사하다. 문서 데이터베이스에선 전체 문서가 보통 하나의 연속된 바이트 열로 저장한다.
칼럼 지향 저장소의 기본 개념은 간단하다.
모든 값을 하나의 로우에 함께 저장하는게 아니라 각 칼럼별로 모든 값을 함께 저장한다. 각 칼럼이 개별 파일에 저장하면 질의에 사용되는 칼럼만 읽고 구분 분석하면 된다. 이 방식을 사용하면 작업량이 많이 줄어든다.

관계형 데이터를 로우 단위가 아닌 칼럼 단위로 저장한다.
칼럼 지향 저장소 배치는 각 칼럼 파일에 포함된 로우가 모두 같은 순서라는 점에 의존하기 때문에 로우의 전체 값을 다시 모으려면 개별 칼럼 파일의 23번째 항목을 가져온 뒤 테이블의 23번째 로우 형태로 함께 모아 구성할 수 있다.
칼럼 압축
압축을 통해 데이터를 압축하면 디스크 처리량을 줄일 수 있는데, 칼럼 지향 저장소는 대게 압축에 적합하다. 다음 그림을 보면 칼럼값 product_sk에는 많은 값이 반복됨을 알 수 있다.
이런 특징은 압축을 하기 좋은 징조이다. 압축 방법은 다양하지만, 다음 그림과 같은 경우 데이터 웨어하우스에서 특히 효과적인 비트맵 부호화(bitmap encoding)이다.

압축된 단일 칼럼의 비트맵 색인 저장소
칼럼에서 고유 값의 수는 로우 수에 비해 적다. 위 product_sk만 봐도 18개의 데이터가 있지만 고유한 값은 6가지(29, 30, 31, 68, 69, 74) 뿐이다. 그렇기에 n개의 고유 값을 가진 칼럼을 가져와 n개의 개별 비트맵으로 변환할 수 있다. 위 그림과 같이 고유 값 하나가 하나의 비트맵이고 각 로우는 한 비트를 가지기에 로우가 해당 값을 가질 경우 비트는 1이고 아니면 0이다.
여기서 고유 값(n)이 클수록 대부분의 비트맵은 0이 더 많아지는데 이를 희소(sparse)하다고 말하는데, 이 경우 위 그림의 하단처럼 런 렝스 부호화(run-length encoding)할 수 있다.
이러한 비트맵 색인은 데이터 웨어하우스에서 일반적으로 사용되는 질의종류에 매우 적합하다.
1.
WHERE product_sk IN (30, 68, 69)
: product_sk가 30, 68, 69 인 비트맵 세 개를 적재해 비트 OR 연산을 하면 해당 조건에 해당하는 값이 몇 번째 인덱스에 존재하는지 쉽게 확인할 수 있다.

2.
WHERE product_sk = 31 AND store_sk = 3
: product_sk = 31과 store_sk = 3인 비트맵을 적재해 비트 AND를 연산하면, 해당 계산은 각 칼럼에 동일한 순서로 로우가 포함되기 때문에 한 칼럼의 비트맵에 있는 k번째 비트는 다른 칼럼의 비트맵에서 k번째 비트와 같은 로우에 해당한다.

참고: 칼럼 지향 저장소와 칼럼 패밀리
카산드라와 HBase는 빅테이블로부터 내려오는 칼럼 패밀리란 개념이 있다.
하지만, 이를 칼럼 지향적이라 부르기엔 오해의 소지가 많다. 각 칼럼 패밀리 안에는 로우 키에 따라 로우와 모든 칼럼을 함께 저장하며 칼럼 압축을 사용하지 않는다. 따라서 빅테이블 모델은 여전히 대부분 로우 지향이다.
메모리 대역폭과 벡터화 처리
수백만이 넘는 로우를 스캔해야 할 때 데이터 웨어하우스 질의는 디스크로부터 메모리로 데이터를 가져오는 대역폭이 큰 병목이다.
그리고 분석용 데이터베이스 개발자는 메인 메모리에서 CPU 캐시로 가는 대역폭을 효율적으로 사용하고 CPU 명령 처리 파이프라인에서 분기 예측 실패(branch misprediction)와 버블(bubble)을 피하며 최신 CPU에서 단일 명령 다중 데이터(single-instruction-multi-data, SIMD)명령을 사용하게끔 신경써야 한다.
칼럼 저장소 배치는 CPU 주기를 효율적으로 사용하기에 적잡한데, 예를 들어 질의 엔진은 압축된 칼럼 데이터를 CPU의 L1캐시에 딱 맞게 덩어리로 나눠 가져오고 이 작업을(함수 호출이 없는) 타이트 루프(tight loop)에서 반복한다. CPU는 함수 호출이 많이 필요한 코드나 각 레코드 처리를 위해 분기가 필요한 코드보다 타이트 루프를 훨씬 빠르게 실행할 수 있다.
칼럼 압축을 사용하면 같은 양의 L1 캐시에 칼럼의 더 많은 로우를 저장할 수 있다. 앞에서 설명한 비트 AND 와 OR같은 연산자는 압축된 칼럼 데이터 덩어리를 바로 연산할 수 있게 설계할 수 있다.
이런 기법을 벡터화 처리(vectorized processing)라고 한다.
분기 예측실패와 버블
분기 예측 실패를 알기위해선 분기 예측을 알 필요가 있다.
분기 예측이란 CPU 처리성능 향상을 위해 명령(instruction)처리 과정을 여러 단계로 세분화 하는기법인 파이프라인을 통한 명령 실행 중 조건 분기 명령의 실행이 종료될 때까지 다음 명령을 대기하지 않고 분기를 예측 실행해 파이프라인 처리 성능 저하를 최소화하는 CPU 실행 기술이며, 이런 예측이 실패하는 것을 분기예측실패라 한다. 어떤 방식으로 분기를 예측하는지에 대해서는 주제와 벗어나기에 생략한다. 그리고 파이프라인에서 구조적 해저드를 해소하기 위해 버블을 넣는데, 이 때 명령의 처리를 진행하지 않는다.
칼럼 저장소의 순서 정렬
칼럼 저장소에서 로우가 저장되는 순서가 반드시 중요한건 아니다.
삽입된 순서로 저장하는 방식이 가장 쉽다. 하지만, 이전의 SS 테이블에서 했던 것처럼 순서를 도입해 이를 색인 메커니즘으로 사용할 수 있다.
각 칼럼을 독립적으로 정렬할 수는 없다. 그렇게 되면 칼럼의 어떤 항목이 동일한 로우에 속한다는 것을 보장할 수 없게 되기 때문이다. 한 칼럼의 k번째 항목이 다른 칼럼의 k번째 항목과 같은 로우에 속한다는 것을 보장하기에 로우를 재구성할 수 있기 때문이다.

age칼럼만 단독 정렬하는 경우
위 그림과 같이 하나의 칼럼만 정렬할 경우, 김철수 라는 이름의 유저가 offset 1인 위치이기에 이 offset을 기반으로 데이터를 모았을 때 {김철수, 29, QA, IT2001}이라는 잘못된 정보가 모이게 된다.
그렇기에 칼럼별로 저장되었을지라도 데이터는 한번에 전체 로우를 정렬해야 한다.
데이터베이스 관리자는 공통 질의에 대한 지식을 사용해 테이블에서 정렬해야 하는 칼럼을 선택할 수 있으며, 첫 번째 칼럼에서 같은 값을 가진 로우들의 정렬 순서를 두 번째 칼럼에서 정할 수 있다. 이런 특징을 이용해 그룹화와 필터링 질의에 도움을 줄 수 있다.
정렬된 순서의 또 다른 장점으로는 칼럼 압축이 있는데, 기본 정렬 칼럼에 고유 값을 많이 포함하지 않는다면 정렬한 후 기본 정렬 칼럼은 연속해서 같은 값이 연속해서 길게 반복된다.
간단한 런 렝스 부호화는 수십억 개의 로우를 가진 테이블도 수 킬로바이트로 칼럼을 압축할 수 있다.
물론 이런 압축은 첫 번째 정렬키가 가장 강력하고 두 번째, 세 번째로 내려갈수록 뒤섞여 있기에 압축률이 높지 않다. 하지만, 초반 정렬된 몇개의 칼럼을 압축하는 것은 전체적으로 여전히 이득이다.
다양한 순서 정렬
다양한 질의는 각각이 다른 정렬 순서의 도움을 받는다.
그렇다면 같은 데이터를 다양한 방식으로 정렬해 저장한다면, 질의를 처리할 때 가장 적합한 버전을 사용하면 높은 성능을 기대할 수 있다. 하나의 장비가 고장나도 데이터를 잃지 않기 위해서는 동일한 데이터를 여러 장비에 복제할 필요가 있는데(Ex: raid 구성) 복제 데이터를 서로 다른 방식으로 정렬해서 저장하면 다양한 순서정렬 데이터셋을 가질 수 있다.
칼럼 지향 저장에서 여러 정렬 순서를 갖는 것은 로우 지향 저장에서 여러 2차 색인을 갖는것과 약간 비슷하다.
하지만, 로우 지향 저장은 한 곳(힙 파일이나 클러스터드 색인)에 모든 로우를 유지하고 2차 색인은 일치하는 로우를 가리키는 포인터만 포함한다는 차이가 있다. 칼럼 저장에서는 일반적으로 데이터를 가리키는 포인터가 없고, 단지 값을 포함한 칼럼만 존재한다.
칼럼 지향 저장소에 쓰기
데이터 웨어하우스에서 칼럼 지향 저장소 뿐만아니라 압축, 정렬 모두 읽기 질의를 빠르게 하는 방법이다. 하지만, 반대로 쓰기를 어렵게 하는 방법이기도 하다.
B 트리와 같은 제자리 갱신(update-in-place)접근 방식은 압축된 칼럼에선 불가능하다.
대신 LSM트리를 이용해 쓰기 문제를 해결한다. 모든 쓰기는 먼저 인메모리 저장소로 이동해 정렬된 구조에 추가하고 디스크에 쓸 준비를 한다. 그 다음 충분한 쓰기가 모이면 디스크의 칼럼 파일에 병합하고 대량으로 새로운 파일에 기록한다.
질의는 디스크의 칼럼 데이터와 메모리의 최근쓰기를 모두 조사하여 결합해야 한다.
다만, 질의 최적화기는 이런 구별을 사용자에게 드러내지 않는다.
집계: 데이터 큐브와 구체화 뷰
자주 사용되는 값에 대한 캐시를 하면 어떨까?
데이터 웨어하우스는 구체화 집계(materialized aggregate)라는 측면을 가지고 있기에, 보통 질의에 집계 함수(COUNT, SUM, AVG, MIN, MAX)가 포함되는 경우가 많다.
그렇다면 이런 집계 일부(COUNT, SUM)을 캐시하는건 어떨까?
이런 캐시를 만드는 한 가지 방법이 구체화 뷰(materialized view)다. 관계형 데이터 모델에선 이런 (COUNT, SUM 같은)캐시를 대개 표준 (가상)뷰로 정의하는데, 표준 뷰는 테이블 같은 객체로 일부 질의의 결과가 내용이다.
구체화 뷰는 디스크에 기록된 질의 결과의 실제 복사본이지만, 가상 뷰(virtual view)는 단지 질의를 작성하는 단축키라는 차이가 있다. 가상 뷰에서 읽을 때 SQL엔진은 뷰의 원래 질의를 즉석에서 확장하고 나서 질의를 처리한다.
원본 데이터가 변경되는 경우
위에서 구체화 뷰는 복사본이라는 말을 했는데, 원본 데이터가 변경되면 이 복사본과 일치하지 않기대문에 구체화 뷰를 갱신해야 하는데, 데이터베이스는 이 작업을 자동으로 수행할 수 있다.
하지만 이런 과정에서 발생하는 쓰기는 비용이 비싸기에 OLTP 데이터베이스에서는 구체화 뷰를 자주 사용하지 않는다.
하지만, 데이터 웨어하우스에서는 읽기 비중이 크기 때문에 구체화 뷰를 사용하는 전략은 합리적이다.
데이터 큐브(data cube) 또는 OLAP 큐브라 알려진 구체화 뷰는 일반화된 구체화 뷰의 특별 사례다.

합으로 데이터를 집계한 2차원 데이터 큐브
위 그림은 사실 테이블이 2차원 테이블에만 외래 키를 가진다고 가정할 때 그릴 수 있는 2차원 테이블이다. 각각의 축은 날짜(date), 제품(product)이고 각 셀은 날짜와 제품을 결함한 모든 사실의 속성의 집계값(Ex: SUM)이다.
이러한 데이터 큐브의 장점은 특정 질의를 효과적으로 미리 계산했기에 해당 질의를 수행할 때 매우 빠른 속도를 보여준다.
하지만, 원시 데이터와 질의하는 것과 동일한 유연성을 제공하지 못한다는 단점도 가지고 있는데, 예를 들어 가격은 차원 중 하나가 아니기에 가격이 100달러 이상인 항목에서 발생한 판매량의 비율을 계산할 수는 없다. 그래서 데이터 웨어하우스 대부분은 가능한 많은 원시 데이터를 유지하려고 노력한다. 데이터 큐브의 집계 값은 특정 질의에 대한 성능 향상에만 사용한다.