
목차
1장의 목적
이펙티브 자바의 첫 시작 객체 생성과 파괴 챕터에서는 제목 그대로 객체를 언제, 어떻게 만들어야 하는지, 그리고 언제 어떻게 객체를 파괴해야하는지, 그리고 객체가 파괴되기 전 후로 수행해야할 정리작업과 불필요한 객체 생성을 피하는 방법등에 대해 알아본다.
•
객체의 적절한 생성시점 학습
•
올바른 객체 생성 방법 학습
•
불필요한 객체 생성을 피하는 방법 학습
•
객체가 파괴되기 전/후로 수행해야 할 정리 작업을 관리하는 방법 학습
1. 생성자 대신 정적 팩토리 메소드를 고려하라
클래스의 인스턴스를 얻는 가장 기본적이고 쉬운 방법은 public 생성자다.
class Study {
private Long id;
private String name;
private int limit;
private StudyStatus studyStatus;
public Study() {}
public Study(String name, int limit){
this.name = name;
this.limit = limit;
}
}
Java
복사
전통적인 public 생성자 사용법.
그런데, 이런 public 생성자만 사용해서 인스턴스를 생성할 때 불편함을 느낀적은 없을까?
위 예제에서는 Study의 이름과 수용인원만 있기에 생성자도 두 개의 파라미터만 넣으면 되고 두 파라미터는 타입도 다르기에 알아보기도 어렵지 않다. 하지만, 필드값이 3~4개가 넘어가고 변수 타입이 동일한것들도 많아진다면 어떨까? 해당 클래스의 인스턴스를 생성하는것의 난이도는 확 올라간다.
그렇기에 우리는 정적 팩토리 메소드(static factory method)를 만들어 사용할 수 있다.
(디자인 패턴의 팩토리 메소드 패턴(Factory Method)와는 다르다.)
클래스의 인스턴스를 반환하는 단순한 정적 메서드인 이 정적 팩토리 메소드는 이미 많이 쓰이고 있는데, 대표적으로 기본형 변수의 래퍼클래스(Wrapper Class)을 보면 알 수 있다. 다음은 boolean 타입 의 래퍼 클래스인 Boolean의 valueOf 정적 팩토리 메서드이다.
public static Boolean valueOf(boolean b){
return b ? Boolean.TRUE : Boolean.FALSE;
}
Java
복사
→ valueOf 메서드는 boolean 기본형 변수를 Boolean 객체 참조로 변환해서 반환한다.
그럼 이 정적 팩토리 메소드를 왜 써야하고 어떠한 장/단점이 존재하는지 알아보자.
장점
첫 번째. 이름을 가질 수 있다.
: 변수가 많은 클래스의 public 생성자의 가장 큰 문제 중 하나는 내가 입력할 파라미터를 하나하나 구분하는게 쉽지않을 뿐더러 파라미터와 생성자만으로는 내가 반환받을 객체의 특성을 한 번에 이해하기 어렵다.
예를들어 Study 클래스의 생성자 Study(String, int, StudyStatus) 를 보고 단 번에 어떤 특성의 Study 인스턴스인지 알 수 있을까? 반면 정적 팩토리 메소드를 사용하면 Study.newStudy를 사용한다면 과연 전자와 후자중 어느것이 '새로운 스터디' 를 생성한다는 점을 알기 쉬울까?
내가 전달 할 파라미터의 타입, 갯수에 따라서 public 생성자를 여러개 만들어서 다양한 매개변수에 대응할 수 있다. 하지만, 모두 결국 public 생성자이고 매개변수의 종류나 타입만 달라지기에 가독성이 떨어지는건 동일하다.
아니 오히려 생성자의 종류가 많아짐에따라 임의의 생황에서 어느 생성자를 호출해야 할지 혼동하기 쉽다.
반면, 이름을 가질 수 있는 정적 팩토리 메서드에는 이런 문제가 발생하지 않는다. 한 클래스에서 시그니처는 같지만 기대되는 특성이 다른 인스턴스가 필요하다면 생성자를 정적 팩토리 메소드로 바꾸고 네이밍을 통해 그러한 특성의 차이를 드러내는게 좋다.
public static Study newStudy(String name, int limit) {
return new Study(name, limit, DRAFT);
}
public static Study endedStudy(String name, int limit) {
return new Study(name, limit, ENDED);
}
Java
복사
→ 동일한 시그니처이지만 메소드명을 통해 반환될 스터디의 특성을 추측할 수 있다.
두 번째. 호출 될 때마다 인스턴스를 새로 생성하지 않아도 된다.
정적 팩토리 메소드를 사용하면 매번 인스턴스를 새로 생성하지 않고 기존에 만들어두거나 생성한 인스턴스를 캐싱해서 재활용 함으로써 불필요한 객체 생성을 피할 수 있다.
위에서 설명한 Boolean.valueOf(boolean)이 이런 장점을 사용한 대표적인 예이다.
특히나, 규모가 커서 생성 비용이 큰 객체의 경우 요청될 때마다 생성하게되면 비용소모가 상당히 커짐으로써 성능이 떨어질 수밖에 없는데, 정적 팩토리 메소드를 사용해 이런 성능저하를 막을 수 있다.
이처럼 같은 요청에는 같은 인스턴스를 반환하는 방식으로 인스턴스의 라이프 사이클을 통제할 수 있는데, 이러한 클래스를 인스턴스 통제(instance-controlled) 클래스라 부른다. 이렇게 인스턴스를 통제하면 싱글톤 패턴을 적용할수도 있고, 인스턴스화 불가(noninstantiable)로 만들수도 있다. 이와같이 인스턴스를 통제해서 동일한 값에 동일한 인스턴스(a==b && a.equals(b))는 플라이웨이트 패턴의 핵심이고 열거형(enum)은 인스턴스가 하나만 만들어짐을 보장한다. 간단한 플라이웨이트 패턴을 사용해 정적 팩토리 메소드를 사용해보자.
(참고로 모든 예제코드의 완성본은 Git에 첨부되어 있다. )
코드
세 번째. 반환 타입의 하위 타입 객체를 반환할 수 있는 능력이 있다.
Arrays 유틸 클래스에서 asList를 통해 List Collection을 만들어 사용해본적이 있다면, 이 세 번째 장점을 이해할 수 있다. 반환객체의 클래스를 자유롭게 선택할 수 있다는 유연성은 내가 구현체를 공개하지 않고 구현체를 반환할 수 있기에 API를 작게 유지할 수 있다. 이 장점이 인터페이스 기반 프레임워크의 핵심 기술이기도 하다.
예를들어 자바에서 제공하는 유틸 클래스중 java.util.Collections에서는 수정 불가, 동기화 기능 등이 들어간 컬렉션 구현체를 제공해주는데 모두 정적 팩토리 메서드를 통해 얻도록 한다.
이때, 이 컬렉션 프레임워크는 구현체를 따로 공개하지 않기에 API의 외견에서 구현체가지 신경쓸 필요가 없어 컴팩트한 개발이 가능해진다. 그렇기에 우리는 인터페이스에 정의된 메서드만 인지하면 되기에 사용법 학습에 대한 비용도 최소한으로 사용이 가능해진다.
다음은 java.util.Arrays 유틸클래스의 정적 팩토리 메서드인 asList()이다.
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}
Java
복사
→ List의 하위 구현체인 ArrayList로 값을 래핑해 반환한다. 하지만 사용자는 이러한 구현체까지 알 필요가 없다.
Java 8 부터는 인터페이스에서도 static 키워드를 통해 정적 메서드를 가질 수 있다. 그렇기에 public 정적 멤버들도 공통된 부분들은 인터페이스에 위치시켜도 상관이 없어졌다. 다만 private 정적 메서드는 아직 java 9 이상에서만 허락되기에 정적 필드와 정적 멤버 클래스는 여전히 public이어야 한다.
네 번째. 입력 매개변수에 따라 다른 클래스의 객체를 반환할 수 있다.
단순히 하위타입을 반환한다는 점을 넘어 파라미터의 상태(값, 크기등) 에 따라 다른 하위타입을 반환 할 수도 있다. 예를 들어, 강의를 위해 강의실 객체 인스턴스를 만들어야 하는 상황에서 항상 같은 인원을 수용하는 동일한 강의실이 아니라 인원수에 따라 다른 타입의 강의실(small, medium, big)을 반환받고 싶을때, 정적 팩토리 메소드를 사용하면 호출 할때 전달하는 수강인원 파라미터로 매번 적절한 구현체를 생성해 반환해줄 수 있다.
또한, 호출하는 입장에서는 그런 내부 구현체까진 알 필요도 없기에 의존관계가 생기지 않는다.
코드
다섯 번째, 정적 팩토리 메소드를 작성하는 시점에는 반환할 객체의 클래스가 없어도 된다.
위에서 작성한 코드들에서는 다 이미 구현되어있는 구현체를 기준으로 유연함을 제공해줬다.
하지만, 이를 넘어서 정적 팩토리 메서드를 작성하는 시점에 구현되있지 않은 객체의 클래스를 반환할수도 있다.
이 부분이 서비스 제공자 프레임워크(Service Provider Framework)의 근간이 되는 개념으로 제공자(provider)가 서비스의 구현체이다. 그리고 이 구현체들을 클라이언트에 제공하는 역할을 프레임워크가 통제해서 클라이언트를 구현체로부터 분리해준다. (DIP)
서비스 제공자 프레임워크는 다음 3개의 핵심 컴포넌트로 이뤄진다.
•
서비스 인터페이스(service interface): 구현체의 동작을 정의한다.
•
제공자 등록 API(provider registration API): 제공자가 구현체를 등록 할 때 사용하는 제공자 등록 API
•
서비스 접근 API(service access API): 클라이언트가 인스턴스를 얻을 때 사용하는 서비스 접근 API
클라이언트는 서비스 접근 API를 이용해서 원하는 구현체를 가져올 수 있는데, 조건을 명시하지 않을 경우 기본 구현체 혹은 지원하는 구현체들을 돌아가며 반환한다. 이러한 서비스 접근 API가 서비스 제공자 프레임워크의 근간인 유여한 정적 팩토리 메소드의 실체다.
그 밖에 서비스 제공자 인터페이스(Service Provider Interface)라는 컴포넌트가 쓰이기도하는데 이는 서비스 인터페이스의 인스턴스를 생성하는 팩토리 객체를 설명해준다. 이러한 서비스 제공자 인터페이스가 없다면
리플렉션을 이용해서 구현체를 인스턴스화 해준다.
•
구현 예 : JDBC
⇒ Connection: 서비스 인터페이스 역할
⇒ DriverManager.registerDriver: 제공자 등록 API 역할
⇒ DriverManager.getConnection : 서비스 접근 API 역할
⇒ Driver: 서비스 제공자 인터페이스 역할
단점
첫 번째, 상속을 할 땐 public or protected 생성자가 필요하기에 정적 팩토리 메서드만 사용하면 하위 클래스를 만들 수 없다.
컬렉션 프레임워크의 유틸리티 구현 클래스들을 상속할 수 없다.
(interface에 정의한 정적 메소드를 상속해서 오버라이딩 할 수 없다는 의미)
이러한 제약은 상속보다는 컴포지션(위임)을 유도하고 불변 타입으로 만들기7 위해서 이 제약을 지켜야한다는 점에서 오히려 장점이 될 수도 있다.
두 번째, 정적 팩토리 메소드는 프로그래머가 찾기 힘들다.
public 생성자는 API 설명에도 나와있기 때문에 사용자가 쓰기가 명확하지만, 정적 팩토리 메서드는 인스턴스화 하기위한 방법을 직접 찾아야한다. 그러기위해 API 문서 작성을 잘 작성해놓고, 정적 팩토리 메소드명을 관례를 최대한 따라서 짓는 방식으로 사용자가 찾기 쉽도록 해야 한다. 다음은 정적 패토리 메소드에서 사용하는 명명 방식이다.
•
from: 매개변수를 하나를 받아 해당 타입의 인스턴스를 반환하는 형변환 메서드
⇒ Date d = Date.from(instant);
•
of: 여러 매개변수를 받아 적합한 타입의 인스턴스를 반환하는 집계 메서드
⇒ Set<Rank> faceCards = EnumSet.of(JACK, QUEEN, KING);
•
valueOf: from과 of의 더 자세한 버전
⇒ BigInteger prime = BigInteger.valueOf(Integer.MAX_VALUE);
•
instance or getInstance: (매개변수가 있다면) 매개변수로 명시한 인스턴스를 반환하지만, 같은 인스턴스임을 보장하지는 않는다.
⇒ StackWalker luke = StackWalker.getInstance(options);
•
create or newInstance: instance 혹은 getInstance와 같지만, 매번 새로운 인스턴스를 생성해 반환함을 보장한다.
⇒Object newArray = Array.newInstance(classObject, arrayLen);
•
getType: getInstance와 같으나, 생성할 클래스가 아닌 다른 클래스에 팩토리 메서드를 정의할 때 쓴다.
⇒ FileStore fs = Files.getFileStore(path)
•
newType: newInstance와 같으나 생성할 클래스가 아닌 다른 클래스에 팩토리 메서드를 정의할 때 쓴다.
⇒ BufferedReader br = Files.newBufferedReader(path)
•
type: getType과 newType의 간결한 버전
⇒ List<Complaint> litany = Collections.list(legacyLitany);
2. 생성자에 매개변수가 많다면 빌더를 고려하라.
정적 팩토리 메소드와 public 생성자 둘 다 공통적인 한계점이 있다.
바로 선택적인 매개변수가 많을 경우 대응하는게 어렵다는 점이다. 예를들어 식품의 영양정보를 표현하는 클래스를 만든다고하면 이미지와 같이 나트륨, 칼로리, 탄수화물, 당류, 지방, 트랜스지방, 포화지방 등등 매우 많은 선택적 항목들이 있는데, 제품에 따라 이런 선택항목에서 대부분의 값이 0으로 설정된다. (우측 그림을 보면 과자의 영양 정보에서 콜레스테롤, 당류가 0이다)
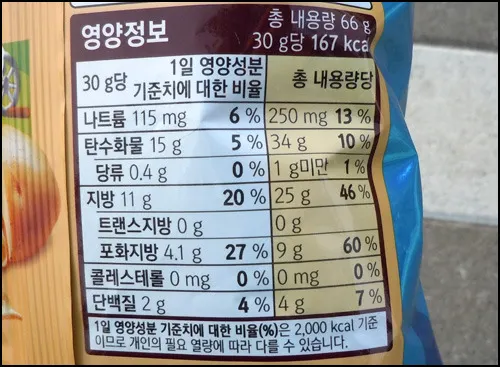
이런 영양정보 클래스를 생성자 혹은 정적 팩토리 메소드로 표현하면 어떻게 될까?
package me.catsbi.effectivejavastudy.item2.domain;
public class NutritionalInformation {
private final int calorie; //칼로리 - 필수
private final int sodium; //나트륨
private final int carbohydrate; // 탄수화물 - 필수
private final int sugars; //당류
private final int fat; //지방 - 필수
private final int transFat; // 트랜스지방
private final int saturatedFat; //포화지방
private final int cholesterol; //콜레스테롤
private final int protein; // 단백질 - 필수
public NutritionalInformation() {
this(0, 0, 0, 0, 0, 0, 0, 0, 0);
}
public NutritionalInformation(int calorie, int carbohydrate, int fat, int protein) {
this(calorie, 0, carbohydrate, 0, fat, 0, 0, 0, protein);
}
public NutritionalInformation(int calorie, int sodium, int carbohydrate, int sugars, int fat, int transFat, int saturatedFat, int cholesterol, int protein) {
this.calorie = calorie;
this.sodium = sodium;
this.carbohydrate = carbohydrate;
this.sugars = sugars;
this.fat = fat;
this.transFat = transFat;
this.saturatedFat = saturatedFat;
this.cholesterol = cholesterol;
this.protein = protein;
}
}
Java
복사
기존 방식으로 개발자들은 점층적 생성자 패턴(telescoping constructor pattern)을 사용했다. 즉 필수 매개변수만 받는 생성자부터 선택 매개변수를 받는 생성자를 점차 늘려가며 전부 받는 생성자까지 만드는 타입이다.
식품의 영양정보를 '간단히' 작성한 클래스만으로도 이렇고 사실 모든 상황에 대처하기 위해서는 점층적 생성자 패턴을 위해 생성자를 상황에 맞게 더 많이 만들어줘야 한다. 즉, 매개변수가 많아질수록 클라이언트 코드를 작성하거나 읽기가 어려워진다. 매번 매개변수의 갯수, 위치별 정확한 값들도 체크를 해야하는데, 위치가 잘못되서 지방에 50을줘야할게 당류에 50이 갈 수도 있는 것이다. 하지만, 타입이 같기에 이를 컴파일시점에 찾아낼 수 없다.
그래서 이를 개선하기 위해 나온 대안으로는 자바빈즈 패턴(JavaBeans Pattern)이 있다. 매개 변수가 없는 기본 생성자를 통해 객체를 만든 뒤 Setter를 이용해 원하는 매개변수의 값을 설정하는 방식이다.
package me.catsbi.effectivejavastudy.item2.domain;
public class NutritionalInformationV2 {
private int calorie; //칼로리 - 필수
private int sodium; //나트륨
private int carbohydrate; // 탄수화물 - 필수
private int sugars; //당류
private int fat; //지방 - 필수
private int transFat; // 트랜스지방
private int saturatedFat; //포화지방
private int cholesterol; //콜레스테롤
private int protein; // 단백질 - 필수
public NutritionalInformationV2() { }
public void setCalorie(int calorie) { this.calorie = calorie; }
public void setSodium(int sodium) { this.sodium = sodium; }
public void setCarbohydrate(int carbohydrate) { this.carbohydrate = carbohydrate; }
public void setSugars(int sugars) { this.sugars = sugars; }
public void setFat(int fat) { this.fat = fat; }
public void setTransFat(int transFat) { this.transFat = transFat; }
public void setSaturatedFat(int saturatedFat) { this.saturatedFat = saturatedFat; }
public void setCholesterol(int cholesterol) { this.cholesterol = cholesterol; }
public void setProtein(int protein) { this.protein = protein; }
}
Java
복사
package me.catsbi.effectivejavastudy.item2;
import me.catsbi.effectivejavastudy.item2.domain.NutritionalInformationV2;
public class App {
public static void main(String[] args) {
NutritionalInformationV2 v2 = new NutritionalInformationV2();
v2.setCalorie(105);
v2.setCarbohydrate(11);
v2.setSodium(30);
v2.setSugars(6);
v2.setFat(6);
v2.setTransFat(2);
v2.setSaturatedFat(4);
v2.setCholesterol(29);
v2.setProtein(1);
}
}
Java
복사
이제 점층적 생성자는 사라졌기에 점층적 생성자 패턴의 단점은 사라졌고, 가독성 측면에서도 나아졌기에 각각의 값을 매칭되는 항목에 설정하는게 쉬워졌다. 하지만, 이 또한 문제가 있다.
•
객체를 완성시키기까지 호출해야 할 메서드가 너무 많다.
•
객체가 완성되기전에는 일관성(consistency)이 무너진 상태다.
•
setter가 활성화 되어있기에 값이 위/변조 될 가능성이 높다.
•
클래스를 불변으로 만들 수 없다.
그 다음 대안책이 바로 빌더 패턴(Builder Pattern)이다. 이 빌더 패턴은 점층적 생성자의 안정성과 자바 빈즈 패턴의 가독성을 합친 디자인 패턴으로 필요한 필수 매개변수만으로 정적 팩토리 메서드를 이용해 빌더 객체를 얻은 뒤 빌더 객체가 제공하는 세터 메서드들로 필요한 선택 매개변수를 입력하는데, 각각의 세터 메서드는 값을 설정한 뒤 자기자신(Builder)을 반환하기 때문에 연속해서 메소드를 호출할 수 있고, 마지막으로 build() 메소드를 사용해 필요한 객체를 완성해 반환받는다.
public static Builder builder(int calorie, int carbohydrate, int fat, int protein) {
return new Builder(calorie, carbohydrate, fat, protein);
}
public static class Builder {
private final int calorie;
private final int carbohydrate;
private final int fat;
private final int protein;
private int sodium = 0;
private int sugars = 0;
private int transFat = 0;
private int saturatedFat = 0;
private int cholesterol = 0;
public Builder(int calorie, int carbohydrate, int fat, int protein) {
this.calorie = calorie;
this.carbohydrate = carbohydrate;
this.fat = fat;
this.protein = protein;
}
public Builder sodium(int sodium) {
this.sodium = sodium;
return this;
}
public Builder sugars(int sugars) {
this.sugars = sugars;
return this;
}
public Builder transFat(int transFat) {
this.transFat = transFat;
return this;
}
public Builder saturatedFat(int saturatedFat) {
this.saturatedFat = saturatedFat;
return this;
}
public Builder cholesterol(int cholesterol) {
this.cholesterol = cholesterol;
return this;
}
public NutritionalInformationV3 build() {
return new NutritionalInformationV3(this);
}
}
Java
복사
빌더 패턴을 적용하니 Setter가 사라짐으로써 무분별한 데이터 접근을 막음으로써 불변성을 지킬 수 있다.
그리고, 빌더안의 세터 메서드들은 자신을 반환하기때문에 연쇄적으로 호출을 할 수 있는데, 이를 플루언트 API(fluent API) 혹은 메서드 체이닝(method chaining)이라 한다.
다음은 이 빌더 패턴을 사용해 객체를 생성하는 코드인데, 매개변수의 위치를 헷갈릴리도 없고, 간결해지고 가독성이 매우 높아졌다. 하나하나의 값들이 어떤 의미인지도 구분하기 쉽다.
NutritionalInformationV3 v3 = NutritionalInformationV3.builder(105, 11, 6, 1)
.sodium(30).cholesterol(29).transFat(2).sugars(6).saturatedFat(4).build();
Java
복사
이러한 빌더패턴은 명명된 선택적 매개변수(named optional parameter)를 흉내낸 것이다.
빌더 패턴은 계층적으로 설계된 클래스와 함께 쓰기에 좋은데, 추상 클래스에서는 추상빌더를, 구체 클래스에서는 구체 빌더를 갖게함으로써 계층적으로 빌더를 빌드 할 수도 있다.
다음은 피자라는 추상 클래스와 이를 상속하는 다양한 피자들을 코드로 표현해서 계층구조의 빌더 패턴 적용사례를 살펴보자.
•
Pizza
package me.catsbi.effectivejavastudy.item2.domain;
import java.util.EnumSet;
import java.util.Objects;
import java.util.Set;
public abstract class Pizza {
public enum Topping {HAM, MUSHROOM, ONION, PEPPER, SAUSAGE}
final Set<Topping> toppings;
abstract static class Builder<T extends Builder<T>> {
EnumSet<Topping> toppings = EnumSet.noneOf(Topping.class);
public T addTopping(Topping topping) {
toppings.add(Objects.requireNonNull(topping));
return self();
}
abstract Pizza build();
protected abstract T self();
}
Pizza(Builder<?> builder) {
toppings = builder.toppings.clone();
}
}
Java
복사
→ EnumSet은 Cloneable을 구현해서 clone 메소드를 통한 복사가 가능하다.
→ 구현체 클래스에서는 self() 메서드로 자기자신을 반환하도록 한다. 이를 이용해 하위 클래스에서는 형변환 하지않고 메서드 연쇄를 지원할 수 있다. self 타입이 없는 자바에서 사용할 수 있는 이런 우회 방법을 시뮬레이트한 셀프 타입(simulated self-type)관용구라 한다.
다음은 이러한 추상 클래스 Pizza를 구현하는 다양한 피자 2개를 작성해보자.
•
뉴욕 피자
: 크기(size)를 필수로 받는다.
package me.catsbi.effectivejavastudy.item2.domain;
public class NyPizza extends Pizza {
public enum Size {SMALL, MEDIUM, LARGE}
private final Size size;
public static class Builder extends Pizza.Builder<Builder> {
private final Size size;
public Builder(Size size) {
this.size = size;
}
@Override
NyPizza build() {
return new NyPizza(this);
}
@Override
protected Builder self() {
return this;
}
}
private NyPizza(Builder builder) {
super(builder);
size = builder.size;
}
}
Java
복사
•
칼초네 피자
:소스를 넣을지 선택(sauceInside)하는 매개변수를 필수로 받는다.
package me.catsbi.effectivejavastudy.item2.domain;
public class Calzone extends Pizza {
private final boolean sauceInside;
public static class Builder extends Pizza.Builder<Builder> {
private boolean sauceInside = false;
public Builder sauceInside() {
this.sauceInside = true;
return this;
}
@Override
Calzone build() {
return new Calzone(this);
}
@Override
protected Builder self() {
return this;
}
}
private Calzone(Builder builder) {
super(builder);
this.sauceInside = builder.sauceInside;
}
}
Java
복사
피자의 하위 클래스인 칼조네피자와, 뉴욕피자는 빌더가 정의한 build 메서드는 해당하는 구체 하위 클래스를 반환하도록 선언한다. NyPizza.Builder는 NyPizza를 반환하고 Calzone.Builder 는 Calzone를 반환한다.
이렇게 하위 클래스의 메서드가 상위의 메서드가 정의한 반환 타입이 아니라 그 하위 타입을 반환하는 기능을 공변 반환 타이핑(covariant return typing) 이라 한다. 이 기능을 사용하면 클라이언트가 형변환에 신경쓰지 않아도 된다. 게다가 아이디나, 일련번호와 같은 특정 필드는 빌더가 알아서 채우게 할 수도 있다.
하지만, 장점만 있는 것은아니고 단점도 있는데, 코드만 봐도 알다시피 작성해야 하는 코드의 양이 늘어난다. 즉 코드작성에 비용이 더 커진다는 것이다. 그리고 필드의 수가 적을수록 가치가 떨어지는데 최소 4개 이상은 되야 쓸만하다. 하지만, 유지보수및 기능추가를 하다보면 변수는 계속해서 늘어나고 그렇기에 뒤늦게 작업을 하는 것보다 처음부터 빌더패턴을 적용하는게 비용을 아낄수 있을지도 모르니 잘 고려해서 사용하자.
3. private 생성자나 열거 타입으로 싱글턴임을 보증하라
싱글톤(singletone)
오직 하나의 인스턴스만을 가지는 클래스.
Stateless Object나 유일해야하는 시스템 컴포넌트를 예로 든다.
특정 클래스의 인스턴스를 하나만 관리함으로써 중복되는 불필요한 인스턴스 생성을 막을 수 있다. 하지만, 이런 싱글톤 클래스들은 테스트를 할 때 어려움이 있다. 만약 해당 싱글톤 클래스가 인터페이스를 구현한 구현체라면 해당 인터페이스를 테스트용으로 구현하는 가짜 구현체로 대체가 가능하지만 그게 아니라면 싱글톤 인스턴스를 가짜 구현으로 대체할 수 없기 때문이다.
싱글톤 생성 방식
1. 전역 상수 방식의 싱글톤
public class Student {
public static final Student INSTANCE = new Student();
private Student(){...}
...
}
Java
복사
⇒ private 생성자는 전역 불변 필드인 INSTANCE가 초기화 할 때 단 한 번 호출된다. 그 이후에는 접근가능한 생성자가 없기에 외부에서 해당 클래스의 인스턴스를 만들 수 없다.
물론, Reflection API를 이용한다면 private 생성자도 호출이 가능한데, 이를 막기 위해서는 생성자를 수정해 두 번째 객체가 생성되려 할 때 예외를 던지게 하면 된다.
private Student(){
if(Objects.nonNull(INSTANCE)){
throws new RuntimeException();
}
}
Java
복사
그럼 이런 전역 상수를 통해 싱글톤을 제공하는 방식은 어떠한 장점이 있을까?
우선, 간결하다. 따로 어떤 메소드를 호출하거나, 할 필요도 없고, final 필드이기 때문에 다른 객체를 참조할수도 없다.
2. 정적 팩토리 메소드를 사용한 싱글톤 생성
public class Student {
private static final Student INSTANCE = new Student();
private Student(){...}
public static Student getInstance(){ return INSTANCE; }
...
}
Java
복사
⇒ 정적 팩토리 메서드인 getInstance를 통해 인스턴스를 반환하며 Reflection API 를 제외하면 또 다른 Student 인스턴스를 만들 수 없다.
그럼, 이 두 번째 방식은 어떤 장점이 있을까?
우선, 내가 마음이 바뀌어서 이 클래스를 싱글톤에서 싱글톤이 아니게 바꾸는데 어려움이 없다.
getInstance메서드만 수정해서 해당 메소드를 호출 할 때마다 새로 인스턴스를 생성해서 반환해주면 된다. 그 다음으로 정적 팩토리 메소드를 제네릭 싱글톤 팩토리로 만들 수 있다는 점이고, 마지막으로 정적 팩토리의 참조를 Supplier<Student> 타입을 이용할 수 있다는 점이다. (ex: FunctionalInterface, Method reference)
정리하면, 두 번째 방법인 정적 팩토리 메소드를 사용했을 때의 장점이 필요 없는 상황이라면 첫 번째 방식인 public static 을 이용한 싱글톤 방식을 사용하면 된다.
주의점
싱글톤 클래스를 직렬화 할 때는 Serializable을 구현한다고 선언(implements)하는 것 만으로는 부족하다.
그냥 구현한다고 선언만 한 상태에서 직렬화 이후 다시 역징렬화(Deserialization)를 하게 되면 새로운 인스턴스가 생성되어 버린다. 그렇기에 이 문제를 해결하기 위해서는 모든 인스턴스 필드를 일시적(transient)이라 선언한 뒤 readResolve 메소드를 오버라이딩해서 작성해줘야 한다.
private Object readResolve() throws ObjectStreamException{
return INSTANCE;
}
Java
복사
열거타입 싱글톤
지금까지 살펴본 바로는 싱글톤을 사용하려면 고려해야할 부분들이 몇 가지가 있는데, 이런 부분들은 열거 타입 방식의 싱글톤으로 만들면 해결된다. 이 세 번째 방식을 사용한다면 직렬화문제, 리플렉션 공격들도 막을 수 있다.
package me.catsbi.effectivejavastudy.item3;
public enum SingletonV3 implements SingletonBase{
INSTANCE;
@Override
public void print() {
System.out.println("싱글톤 V3버전 열거 타입");
}
}
Java
복사
열거타입 싱글톤의 장점
•
사용이 간단하다.
위에서 작성한 SingletonV3코드를 class로 구현하면 다음과 같이 작성해야 한다.
public class SingletonV3 {
private volatile SingletonV3 INSTANCE;
private SingletonV3() {}
public SingletonV3 getInstance() {
if (INSTANCE == null) {
synchronized (SingletonV3.class) {
if (INSTANCE == null) {
INSTANCE = new SingletonV3();
}
}
}
return INSTANCE;
}
}
Java
복사
4.인스턴스화를 막으려거든 private 생성자를 사용하라.
우리는 내부적으로 인스턴스 변수와 메소드가 필요 없는 유틸리티 클래스를 사용 혹은 만들어야 할 때가 있다.
대표적으로 java.lang.Math, java.util.Arrays와 같이 수학 연산이나 배열에 관련된 메서드들을 모아놓는 유틸리티 클래스들을 사용할 수 있다. 혹은, 팩토리 패턴에서 정적 메서드를 모아놓기도 한다.
이러한 유틸리티 클래스들은 따로 인스턴스 변수나 메소드가 없이 모두 공통으로 동작하고 사용할 수 있기 때문에 인스턴스화가 될 필요가 없다. 하지만, 생성자를 명시하지 않으면 컴파일러가 자동으로 기본 생성자를 만들어주는데, 이렇게되면 사용자는 이 클래스가 자동생성된 것인지 구분할 수 없고, 인스턴스화가 될 확률도 존재하게 된다.
이를 막기위해 추상화 하는 것은 정답이 아니다. 하위 클래스를 만들어 인스턴스화를 하면 그만이기 때문이다.
public abstract class StringUtils {
public static void println(String message){
System.out.println(message);
}
}
public class StringUtilsChild extends StringUtils {
public StringUtilsChild(){
super();
}
}
Java
복사
추상클래스로 만들어도 하위 클래스에서 생성자 호출로 인스턴스화가 가능해진다.
그래서 이렇게 유틸리티 클래스의 인스턴스화를 막기 위해서 생성자의 접근제어자를 private로 만들어주면 문제는 해결된다.
public abstract class StringUtils {
//인스턴스화 방지 생성자.
private StringUtils() {
throw new AssertionError();
}
public static void print(String message) {
System.out.println(message);
}
}
Java
복사
위와같이 기본 생성자의 접근제어자가 private면 클래스 외부에서는 접근할수도 없다. 또한, 기본 생성자가 내부에서라도 호출될 경우 예외를 발생시키기에 실수로라도 내부에서도 인스턴스화가 되는일을 막아준다.
이런 private 생성자는 사용자 입장에서 존재하는데 사용은 못하는 생성자를 이해하기 힘들 수 있기에 주석을 달아주는것도 좋은 방법이다. 추가적으로 이처럼 private 생성자로 명시해주면 하위 클래스에서도 상위 클래스의 생성자를 호출할 수 없기 때문에(명시적, 묵시적 모두) 상속을 막을 수 있다.
5. 자원을 직접 명시하지 말고 의존 객체 주입을 사용하라.
싱글톤과 정적 팩토리 메소드를 통한 유틸리티 클래스는 매우 유용하고 비용소모를 줄여주지만, 모든 사용자에게 공통되지 않고 사용자별로 다른 자원이 존재해야 하고, 이 자원이 클래스의 동작에 영향을 준다면, 사용하지 않는게 좋다. 대신 이런 자원을 클래스가 자체적으로 만드는게 아니라 외부에서 전달해줌으로써 클래스의 인스턴스별로 맞는 자원을 가지게끔 하는 것인데, 이런 의존관계 주입(DI)은 객체지향 프로그래밍의 원칙중 DIP도 지켜주고, 클래스의 유연함, 재사용성, 테스트 용이성도 개선해준다.
스프링에서 사용하는 Bean들도 프레임워크가 모두 자동등록을 한 다음 필요한곳에 주입을 해주는 식이다.
예제
쇼핑몰 프로젝트에서 제품의 최종 가격을 결정해주는 클래스가 있다고 하자. 이 클래스에는 할인정책이라는 항목이 있고, 이 항목을 적용해서 제품의 최종가격을 결정한다. 그럼 이 할인정책은 하나밖에 없을까? 할인정책은 언제든지 변할 수 있다. 다음 예제를 통해 유틸리티 클래스와, 싱글톤 클래스가 어째서 이 상황에서 적절하지 않은지와 의존관계 주입이 적절한지 알아보자.
사전 준비 클래스들
1.
정적 유틸리티 클래스를 사용한 잘못된 예
package me.catsbi.effectivejavastudy.item5;
//정적 유틸리티를 잘 못 사용한 예
public class ShoppingServiceV1 {
private static final DiscountPolicy discountPolicy = new DiscountPolicy(1000);
private ShoppingServiceV1(){}
public static ShoppingResponse buy(Item item, int money){
if (!item.isPayable(money)) {
throw new IllegalArgumentException("돈이 부족합니다.");
}
int resultPrice = discountPolicy.discount(item.getPrice());
return ShoppingResponse.of(item, resultPrice);
}
}
Java
복사
→ 해당 유틸리티 클래스는 오직 1000원을 할인해주는 할인정책만 적용이 가능하다. 유연함과 재사용성이 몹시 낮다.
2.
싱글톤 클래스를 사용한 잘못된 예
package me.catsbi.effectivejavastudy.item5;
//싱글톤을 잘 못 사용한 예
public class ShoppingServiceV2 {
private static final DiscountPolicy discountPolicy = new DiscountPolicy(1000);
public static ShoppingServiceV2 instance = new ShoppingServiceV2();
private ShoppingServiceV2() { }
public static ShoppingServiceV2 getInstance() {
return instance;
}
public ShoppingResponse buy(Item item, int money) {
if (!item.isPayable(money)) {
throw new IllegalArgumentException("돈이 부족합니다.");
}
int resultPrice = discountPolicy.discount(item.getPrice());
return ShoppingResponse.of(item, resultPrice);
}
}
Java
복사
⇒정적 유틸리티 클래스와 동일하게 싱글톤 클래스 역시 할인정책은 1000원을 할인해주는 고정된 할인정책만이 사용가능하다.
결국, 할인정책을 유연하게 변경하면서 쓰기위해서는 정적 클래스가 아닌 인스턴스화가 가능하게 하면서 할인정책을 인스턴스 생성시 주입받도록 해야한다. 그렇게 하면 유연한 할인정책 적용이 가능해진다.
•
의존 객체 주입을 사용한 상품 구매 서비스 클래스
package me.catsbi.effectivejavastudy.item5;
//의존관계 주입으로 할인 정책을 외부에서 주입받음으로써 유연성과 재사용성을 키웠다.
public class ShoppingServiceV3 {
private final DiscountPolicy discountPolicy;
public ShoppingServiceV3(DiscountPolicy discountPolicy) {
this.discountPolicy = discountPolicy;
}
public ShoppingResponse buy(Item item, int money) {
if (!item.isPayable(money)) {
throw new IllegalArgumentException("돈이 부족합니다.");
}
int resultPrice = discountPolicy.discount(item.getPrice());
return ShoppingResponse.of(item, resultPrice);
}
}
Java
복사
이러한 의존 객체 주입 패턴 은 사용법도 단순하기 때문에 사실 많은 프로그래머가 이미 사용하고 있었다.
또한 할인정책은 final 키워드 때문에 불변이 보장되기에 여러 사용자가 할인정책 변경에 대한 우려 없이 사용할 수 있다. 이러한 의존객체주입은 생성자, 정적 팩터리, 빌더 모두 똑같이 응용이 가능하다.
예제 코드
이 뿐만 아니라 생성자에 매개변수로 자원 팩토리를 넘겨주는 방식으로 변형해서 사용할 수도 있는데, 대표적으로 Java8에서 소개된 Supplier<T>인터페이스가 팩토리를 표현한 예다. 가령 예를들어 자동차를 요구 대수만큼 생성해 반납해주는 create 메소드를 만든다고 하면 다음과 같이 사용할 수 있다.
public static List<Car> create(Supplier<? extends Car> generator, int count) {...}
Java
복사
⇒ 완성 코드는 Git 을 참고하도록 하자.
물론 이런 의존 객체 주입을 통해 유연성및 테스트 용이성을 개선해줄 수 있지만, 의존성이 수백, 수천개가 되면 역시 비용소모가 상당히 높은데 이런 경우 의존 객체 주입 프레임워크(대거, 주스, 스프링...)들을 써서 해소할 수 있다.
6. 불필요한 객체 생성을 피하라.
불필요한 객체란 무엇인지부터 생각해보자. 다음 코드를 보자.
String a = new String("hi");
String b = new String("hi");
String c = new String("hi");
Java
복사
문자열 변수 a,b,c는 모두 "hi"라는 문자열을 가지게된다. 하지만, 이 세 문자열이 참조하는 주소는 모두 다르다. 각각의 변수는 모두 다른 영역을 참조하게 되는데, 동일한 문자열을 이처럼 여러개 중복 생성하는것은 메모리 낭비다.
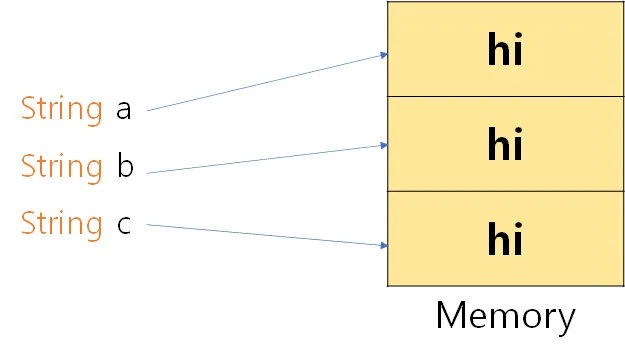
그럼 어떻게 사용해야 할까?
String s = "hi";
Java
복사
이렇게 리터럴로 선언을 해 두면 컴파일시점에서 상수 풀(constant pool)에 해당 String 인스턴스를 저장하며 같은 JVM안에서 동일한 리터럴을 발견하면 동일한 인스턴스를 사용하게 함으로써 여러 문자열이 hi라는 리터럴을 바라보게 되어도 모두 동일한 인스턴스를 바라보게 됨으로써 모든 코드가 같은 객체를 재사용한다는게 보장된다.
그럼 이런 기본타입이 아닌 클래스에서는 어떤 방법이 있을까?
바로, 정적 팩토리 메소드를 사용해 불필요한 객체 생성을 피할 수 있다. 즉, Boolean(String)생성자 대신 Boolean.valueOf(String)을 사용하는 것이다. 생성자는 호출시점에 항상 새로운 인스턴스를 만들지만 팩토리 메소드는 내가 작성함에 따라서 재사용이 가능하게 코드를 작성할 수 있다.
이렇게 중복되어 반복 사용이 요구되는 개체같은 경우 객체생성을 최소화하여 재사용함을 권장하는데, 생성 비용이 비쌀수록 캐싱해서 재사용하는 것이 중요해진다. 자바에서는 대표적으로 정규표현식용 클래스 Pattern이 생성비용이 높은 클래스다. String클래스의matches 메소드를 사용하게되면 내부로직에서 Pattern 인스턴스를 만들어 1회 사용하고 바로 버려져 가비지 컬렉션 대상이 되는데, 해당 정규표현식이 반복되서 사용되는 빈도가 높아질수록 동일한 Pattern 인스턴스가 생성되고 버려지는 비용이 불필요하다.
그래서 이런 경우 해당 Pattern 인스턴스를 정적 상수로 캐싱해놓고 사용하는게 효율적이다.
package me.catsbi.effectivejavastudy.item6;
import java.util.regex.Pattern;
public class StringUtils {
private static final Pattern ROMAN = Pattern
.compile("^(?=.)M*(C[MD]|D?C{0,3})(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$");
//worst case
static boolean isRomanNumeralV1(String s) {
return s.matches("^(?=.)M*(C[MD]|D?C{0,3})(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$");
}
//good case
static boolean isRomanNumeralV2(String s) {
return ROMAN.matcher(s).matches();
}
}
Java
복사
주의점
객체가 불변이라면 재사용해도 문제가 없다.
하지만 불변이 보장되지 않는 상황도 있는데, 어댑터 패턴(link) 을 생각해보면 실제 객체를 연결해주는 제 2의 인터페이스 역할을 하는 어댑터같은 경우 사용자는 이 어댑터를 사용할 때 뒷 단에서 매번 같은 인스턴스가 반환될 지 동일한 내용에 대해서 동일한 인스턴스를 반환해줄지 알 수 없다.
불필요한 객체를 만들어주는 또 한 가지 경우 - 오토박싱(auto boxing)
기본타입과 래퍼클래스(Wrapper Class)간에 자동으로 상호변환해주는 기술인 오토박싱(언박싱)은 기본타입과 래퍼클래스간의 구분을 흐리게 해준다. 하지만 이런 점 때문에 프로그래머가 혼용해서 써도 에러가 발생하지 않으니 성능상의 문제가 발생할 수 있다. 다음 코드를 보자
private static long sum(){
Long sum = 0L;
for(long i=0; i <= Integer.MAX_VALUE; i++){
sum += i;
}
return sum;
}
Java
복사
로직상 문제가 있는 코드는 아니지만, 위 코드는 성능적으로 몹시 비효율적인 코드다.
문제의 핵심은 값들이 더해지는 결과 변수인 sum과 for문안에서 1씩 증감하며 sum에 더해지는 값인 i의 타입에 있다. sum의 타입은 래퍼클래스인 Long 타입의 인스턴스다. 그리고 i는 기본 타입인 long이다.
이말인즉슨, long 타입인 i는 반복문이 돌 면서 sum에 더해질때마다 새로운 Long 인스턴스를 만든다는 것이다. 결과적으로, 박싱된 기본 타입보다는 기본 타입을 사용하고 의도치 않은 오토박싱이 숨어들지 않도록 주의를 해야한다는 점을 알 수 있다.
오해하지 말아야 할 부분
불필요한 객체 생성을 피하라는 것을 단순하게 객체 생성의 비용이 크니까 피해야 한다고 오해해서는 안된다.
요즘 JVM에서 불필요하게 생성된 작은 객체들을 생성및 회수하는 일은 별로 부담되는 작업이 아니다.
데이터베이스를 연결과 같이 비용이 몹시 높아 재사용하는 편이 명확히 좋은편인 경우가 아니라면 객체 풀을 만들어서 객체들을 모아놓는 것은 코드를 헷갈리게 하고, 메모리 사용량을 늘려 성능을 떨어뜨린다.
무엇보다, 이렇게 객체를 방어적으로 복사하는(defensive copy) 방식은 피해가 발생했을 때 객체를 반복 생성했을 때보다 훨씬 크다. 반복 생성의 부작용은 코드 형태나 성능에만 영향을 주지만, 방어적 복사가 실패했을 경우에는 버그와 보안문제로 직행한다.
7. 다 쓴 객체 참조를 해제하라.
자바에서는 가비지 컬렉터가 주기적으로 사용되지 않는 객체들을 알아서 회수해가기 때문에 프로그래머가 메모리관리에 신경써야 하는부분이 적다. 하지만, 가비지컬렉터만 믿고 코드를 짜다보면 문제가 발생할 수 있다.
일반적으로 객체 참조가 해제되서 객체를 참조하는 곳이 없게되면 가비지컬렉터는 해당 객체를 수거해간다.
하지만, 이런 참조객체가 리스트에 저장되어있다면 어떨까 리스트에 수십개의 객체를 저장해 놓은 상태에서는 특정 객체가 더 이상 리스트에서 사용되지 않고있더라도 가비지컬렉터는 이러한 객체를 수거해가지 않는다.
다음 예제는 스택을 구현한 코드이다.
package me.catsbi.effectivejavastudy.chapter6;
import java.util.Arrays;
import java.util.EmptyStackException;
public class Stack {
private Object[] elements;
private int size = 0;
private static final int DEFAULT_INITIAL_CAPACITY = 16;
public Stack() {
this.elements = new Object[DEFAULT_INITIAL_CAPACITY];
}
public void push(Object e) {
ensureCapacity();
elements[size++] = e;
}
public Object pop() {
if (size == 0) {
throw new EmptyStackException();
}
return elements[--size];
}
/**
* 원소를 위한 공간을 적어도 하나 이상 확보한다.
* 배열 크기를 늘려야 할 때마다 대략 두 배씩 늘린다.
*/
private void ensureCapacity() {
if (elements.length == size) {
elements = Arrays.copyOf(elements, 2 * size + 1);
}
}
}
Java
복사
여기서 바로 객체 배열 변수인 elements 에서 문제가 발생한다.
프로그램이 오래 구동되있을 수록 Stack 클래스의 elements 객체 배열로 인해 메모리 누수가 발생할 수 있는데, 그 이유는 위에서 밝혔듯이 객체 배열에서 더 이상 사용되지 않는 객체들도 가비지 컬렉터가 수거해가지 않기 때문이다.
그 이유는 객체 배열의 더 이상 사용되지 않는 객체들의 다 쓴 참조 주소(obsolete reference)를 여전히 가지고 있기 때문이다.
위에 작성한 코드에서는 pop 메서드를 호출할 때마다 size가 줄어들면서 객체배열 elements에서 size인덱스에 위치한 값을 반환하고 있다. 그런데 여기서 size의 인덱스 범위 밖에 있는 객체들은 어떻게 될까?
elements라는 객체 배열의 크기가 5라고 할 때 pop()메서드를 2 회 호출해서 현재 size가 3일 경우 우측과 같은 모습이 된다.
여기서 위치 4,5 에 해당하는 객체들은 size의 범위 밖에 있다. 우리가 Stack에서 elements안의 값을 꺼내는 방법은 pop()메서드가 유일한데, pop()메서드는 size를 줄여가며 size의 크기보다 작은 elemtns만 순차적으로 반환하기 때문이다.
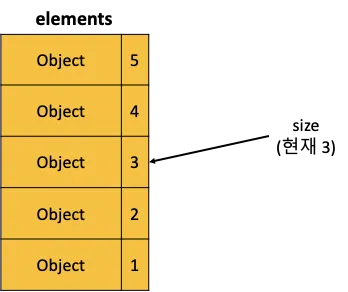
가바지 컬렉터에서는 객체 참조 하나를 살려두면 그 객체안에서 참조하는 모든 객체를 회수하지 못하기 때문에, 잠재적으로 성능에 악영향을 줄 수 있다.
해결책
해당 참조를 다 썼을 때 참조를 해제하면되는데 일반적으로 null처리를 해주면 된다.
위에 Stack 예제 코드로 치면 pop()메서드안에서 객체를 반환한 다음 반환한 위치에 참조주소를 null 처리하면 된다.
public Object pop() {
if (size == 0) {
throw new EmptyStackException();
}
Object result = elements[--size];
elements[size] = null // 참조 해제
return result;
}
Java
복사
이렇게 다 쓴 참조 객체를 null처리해주면 다시 사용하려할 때 NPE가 발생하기에 비정상적인 접근도 확인할 수 있다.
하지만, 객체 참조를 null 처리하는 것은 예외적인 경우여야 하고, 더 좋은 방법은 다 쓴 참조를 유효 범위(scope)밖으로 밀어버리는 것이다. (다만 위 Stack 예제는 스택이 자기 메모리를 직접 관리하기 때문에 메모리 누수에 취약하고 null 처리가 필요했다.)
이 예제를 통해 알아본 문제는 하나의 문제고 사실 메모리 누수의 원인은 몇가지 더 있는데, 이를 정리해보자.
메모리 누수의 원인과 해결책
다 쓴 객체의 참조를 해제하지 않기 때문에 메모리누수가 발생을하는데, 어떤경우가 있는지 알아보자.
1. 자기 메모리를 직접 관리하는 클래스에서 관리를 못해주는 경우
•
위에 작성한 Stack 예제처럼 자기메모리를 직접 관리하는 경우 더 이상 참조가 되지 않는 객체(size 범위 밖의 객체들)를 참조해제를 해주지 않는다면 가비지 컬렉터는 해당 객체가 객체 배열에서 참조하고 있기 때문에 실제로는 사용하지 않을지라도 수거하지 못한다.
•
유효범위 밖이거나 쓸 일이 없어지는 객체는 개발자가 신경써서 null처리를 해줘서 참조를 해제해주도록 한다.
2. 캐시
•
객체 참조를 캐시에 넣고 그 부분을 잊어버린다면 객체를 다 쓴 뒤에도 참조 해제가 되지않기에 메모리에 쌓여있게 된다.
•
해결책
1.
(캐시 외부에서 키(key)를 참조하는 동안만 엔트리가 살아있으면 되는 경우) WeakHashMap을 사용하면 다 쓴 엔트리는 자동으로 제거된다.
2.
엔트리의 가치를 시간이 흐름에 따라 떨어트리는 방식
: 백그라운드 스레드(ScheduledThreadPoolExecutor) 를 활용하거나 캐시에 새 엔트리를 추가하는 등 캐시에 접근하는일이 있을 때 부수 작업으로 수행하는 방법.
3.
LinkedHashMap은 removeElderstEntry 메서드를 써서 처리한다.
3. 리스너(listener)와 콜백(callback)
•
클라이언트에서 콜백을 등록만하고 해제를 하지 않는다면 콜백은 쌓여만 간다.
•
WeahHashMap같은 콜렉션에 약한참조로 저장하면 사용 후 가비지컬렉터에 수거된다.
 참고: Weak Reference를 이용한 HashMap
참고: Weak Reference를 이용한 HashMap
package me.catsbi.effectivejavastudy.chapter1.item7;
import java.lang.ref.Reference;
import java.lang.ref.WeakReference;
import java.util.WeakHashMap;
public class WeakHashMapTest {
public static void main(String[] args) throws InterruptedException {
WeakReference<String> refer = new WeakReference<>("test");
WeakHashMap<Reference, Stack> weakHashMap = new WeakHashMap<>();
weakHashMap.put(refer, new Stack());
clear();
System.out.println("map size= "+ weakHashMap.size());
refer = null;
clear();
System.out.println("map size= "+ weakHashMap.size());
}
private static void clear() throws InterruptedException {
System.out.println("clear");
System.gc();
System.out.println("Sleeping");
Thread.sleep(2000);
}
}
Java
복사
→ WeakHashMap에서 사용하는 key가 null을 할당해 참조를 해제해주면 WeakHashMap에서 해당 엔트리는 GC에 의해 수거된다.
→ 하지만 GC의 실행 시점을 정확히 알 수 없고, static한 Map으로 사용되는 경우 문제의 발생요지가 높아 필요할때만 사용하자.
8. finalizer와 cleaner 사용을 피하라.
자바가 제공하는 객체 소멸자 finalizer와 cleaner는 최대한 사용을 피하는게 좋다.
예측할 수 없고 상황에따라 문제가 발생할 가능성이 너무 높다.
자바9에서는 아예 finalizer는 deprecated 된 API이기도 하다. 그 대안으로 cleaner가 나온것이긴한데, 이 cleaner가 finalizer보다는 덜 위험하긴 하지만, 여전히 에측할 수 없고, 느리고, 사용을 권장하지 않는다.
문제점
•
finalizer와 cleaner는 내가 원하는 시점에 수행이 된다는 보장이 없다.
⇒ 내가 해당 메서드를 사용해도 이게 과연 언제 수행될지 알 수 없다. 내가 원하는 시점에 호출이 되지않아서 문제가 발생하기 쉽다.
•
finalizer와 cleaner는 다른 애플리케이션 스레드보다 우선 순위가 낮아 실행 기회를 얻기도 힘들다.
⇒위의 문제와 이어지는 문제로 다른 스레드에게 우선순위에서 밀리다보니 심각할 경우 수천개의 객체들이 finalizer 대기열에서 대기만하다가 OutOfMemoryError가 발생하며 애플리케이션이 비정상 종료가 될 수 있다.
•
clearner도 백그라운드에서 수행되며 GC의 통제하에 있기에 즉각 수행된다는 보장이 없다.
•
수행시점 뿐 아니라 수행 여부조차 보장하지 않는다.
⇒ 원할 때 수행될지도 알 수 없지만, 수행이 될지도 보장할 수 없다.
•
finalizer 동작 중 발생한 예외는 무시되기에 예외 추적조차 불가능하다.
•
finalizer와 cleaner는 성능적으로도 몹시 떨어진다.
•
finalizer 공격에 노출되 보안문제가 발생할 수 있다.
⇒ 생성자나 직렬화 과정(readObject와 readResolve)에서 예외가 발생하면 해당 객체에서 악의적인 하위 클래스의 finalizer가 수행될 수 있게 된다.
⇒ final이 아닌 클래스를 공격에서 방어하고싶다면 finalizer를 명시적으로 만들어 final로 선언하자.
대안책
•
AutoCloseable을 구현한 뒤 close를 호출하도록 한다.
•
try-with-resources를 사용해 자동으로 close될 수 있도록 한다.
권유사항
•
각 인스턴스는 자신이 닫혔는지 추적하는것이 좋다. 즉, 해당 객체의 유효성을 필드로 남겨두는게 좋다.
finalizer와 cleaner의 사용처
•
close메서드를 호출하지 않았을 것에 대비한 안전망 역할.
:사용자가 close메서드를 호출하지 않았을 것에 대비한 안전망으로 즉시 호출된다는 보장은 없어도 늦게라도 회수되는것이 아예 회수되지않는 것보다는 낫다.
⇒ Ex: FileInputStream, FileOutputStream, ThreadPoolExcutor
•
네이티브 피어(Native Peer)와 연결된 객체
: 자바 객체가 아니니 GC에서 존재를 알지 못하는기에 자바 피어를 회수할 때 네이티브 객체까지 회수하지 못한다.
그렇기에 cleaner나 finalizer가 담당하기 적당한 작업이다.
다만, 성능 저하를 감당할 수 있고 심각한 자원을 가지고 있지 않을때만 해당한다.
정리
finalizer와 cleaner는 안전망 역할 혹은 중요하지 않은 네이티브 자원 회수용으로만 사용하자.
9.try-finally보다는 try-with-resources를 사용하라.
DBConnect나 FileStream 관련 라이브러리처럼 명시적으로 close 메서드를 호출해서 닫아줘야하는 자원들이 있다.
그리고 이런 라이브러리를 사용할 때 우리는 지금까지는 명시적으로 close()메서드를 호출해줬으며 다음과 같이 코드를 작성하곤 했다.
public class StringUtils {
private final StringUtils instance = new StringUtils();
private BufferedReader reader;
private StringUtils() {
}
public String firstLineOfFile(String path) throws IOException {
reader = new BufferedReader(new FileReader(path));
try {
return reader.readLine();
} finally {
reader.close();
}
}
}
Java
복사
⇒ 이 코드도 finally를 사용해 예외가 발생하더라도 안정적으로 자원을 닫아주기를 보장한다. 하지만 사용자가 명시하지 않을 가능성도 존재한다.
⇒ try 블럭 내에 또 다른 자원을 사용한다면 어떻게 될까?
//worst case
//try 문이 중복되어 가독성도 떨어질뿐 아니라 자원을 명시적으로 closing하는 것도 지저분하다.
public String firstLineOfFile(String path, String fileName) throws IOException {
BufferedReader reader = new BufferedReader(new FileReader(path));
try {
FileOutputStream outputStream = new FileOutputStream(fileName);
try {
String s = reader.readLine();
outputStream.write(s.getBytes(), 0, s.length());
} finally {
outputStream.close();
}
return reader.readLine();
} finally {
reader.close();
}
}
Java
복사
⇒ 코드의 가독성이 더 떨어졌다. 또한 try-finally를 제대로 썼지만, 여기에도 문제가 있는데 컴퓨터 기기자체가 물리적으로 문제가 생겨서 readLine() 메서드가 동작을 실패해 예외가 발생되면 close()메서드도 실패하며 예외가 발생한다면 후자의 예외가 전자의 예외를 가려버리게 되어 스택 추적이 힘들어지게되어 디버깅을 힘들게 한다.
해결책
자바 7 에서 등장한 try-with-resources가 이러한 문제의 해결책이 된다.
단, try-with-resources를 구현하기위해서는 사용하려는 자원이 AutoCloseable 인터페이스를 구현해야 한다.
다음은 위의 코드를 try-with-resources으로 수정한 코드다.
//good case
//try-with-resources를 사용한다.
public String firstLineOfFileV2(String path, String fileName) throws IOException{
try(BufferedReader reader = new BufferedReader(new FileReader(path));
FileOutputStream out = new FileOutputStream(fileName)){
String s = reader.readLine();
out.write(s.getBytes(), 0, s.length());
return s;
}
}
Java
복사
⇒ 코드도 엄청 간결해졌을 뿐 아니라 메서드내의 들여쓰기가 1depth로 유지되기에 클린코드에서 권장하는 컨벤션을 지키고있다. 그리고 readLine과 close 메서드 양측에서 예외가 발생하더라도 close에서 발생한 예외는 숨겨지며 readLine에서 발생한 예외가 기록되기에 디버깅도 쉬워진다.
정리
자원회수가 필수적인 경우에는 try-with-resources 을 사용하자. finally block을 명시해줘야 할 불편함도 사라지고,
여러개의 자원을 쉽게 회수할 수 있다.

