목차
정적 컨텐츠
•
파일을 웹브라우저에 그대로 전달해주는(내려주는) 방식
•
스프링 부트에서는 정적 컨텐츠 기능을 기본으로 제공한다.
◦
파일 경로가 다음과 같은 경우: /static, /public, /resources, /META-INF/resources
•
정적 컨텐츠를 내려주는 과정
1.
웹 브라우저에서 컨텐츠 요청
2.
스프링 컨테이너에서 해당 Path에 해당하는 컨트롤러가 있는지 확인
3.
없을 경우 resources 내부에 있는 해당 Path에 해당하는 컨텐츠 검색
4.
있을 경우 해당 컨텐츠를 내려준다.
MVC와 템플릿 엔진
•
◦
Model: 의미있는 비즈니스 로직을 담당하는 계층
◦
View: 화면을 그리는 책임만을 담당하는 계층
◦
Controller: 클라이언트의 요청을 받아서 적절한 서비스계층을 호출하고, 그 결과를 반환하는 책임을 담당하는 계층
•
MVC 구조와 템플릿 엔진간의 연계 방식
1.
웹 브라우저(클라이언트)에서 컨텐츠 요청
•
Ex: localhost:8080/hello-mvc?name=catsbi
2.
Request Path에 매핑되는 컨트롤러 메서드 검색 후 호출
•
Ex: @GetMapping(”hello-mvc”) public String helloMvc(...){...}
3.
실행된 메서드는 작성된 로직 수행 후 ViewResolver에게 렌더링 될 View 파일 경로/이름 반환.
4.
템플릿 엔진처리(ex: Thymeleaf)로 HTML 파싱 된 소스파일을 클라이언트에게 반환.
5.
웹 브라우저(클라이언트)는 해당 HTML 파일을 사용자에게 보여준다.
API
•
ViewResolver를 사용하여 사용자에게 보여지는 화면(Ex: HTML) 소스를 반환하지 않는다.
•
HTTP의 Body 영역에 문자 내용을 직접 반환한다.
•
스프링에서는 애노테이션 기반으로 이런 동작을 제어할 수 있다.
◦
메서드 단위는 @ResponseBody를 사용하면 값을 그대로 Body에 담아 반환한다.
◦
클래스 단위는 @RestController를 사용하면 값을 그대로 Body에 담아 반환한다.
•
ViewResolver 대신 HttpMessageConverter가 동작한다.
 Client의 HTTP 요청의 Accept 헤더와 서버의 컨트롤러 반환 타입 두 가지를 조합하여 HttpMessageConverter가 선택된다.
Client의 HTTP 요청의 Accept 헤더와 서버의 컨트롤러 반환 타입 두 가지를 조합하여 HttpMessageConverter가 선택된다.
Client의 HTTP 요청의 Accept 헤더와 서버의 컨트롤러 반환 타입 두 가지를 조합하여 HttpMessageConverter가 선택된다. ◦
기본 문자처리: StringHttpMessageConverter
◦
기본 객체처리: MappingJackson2HttpMessageConverter
◦
기타 처리(ex: byte): HttpMessageConverter
•
지금은 거의 대부분 JSON 형식으로 반환을 하는 추세이다.
DI(Dependency Injection) 방법
1.
@Autowired 애노테이션을 활용한 주입 방법
•
필드 직접 주입
@Autowired
private MemberService memberService;
Java
복사
•
생성자 주입
private MemberService memberService;
@Autowired
public xxxController(MemberService memberService){ ... }
Java
복사
TIP: 필드가 단 하나뿐이라면 @Autowired 애노테이션이 없어도 자동 주입을 해준다.2.
final 키워드를 활용한 생성자 주입 방법
private final MemberService memberService;
private final LottoService lottoService;
public xxxController(MemberService memberService, LottoService lottoService){ ... }
Java
복사
→ 클래스에 컴포넌트 애노테이션( @Controller, @Service 등도 내부적으로 @Component를 포함하는 메타 애노테이션이다.) 이 있는경우 Bean 등록을 하기 위해서 객체를 생성하는데 final 키워드가 있는 멤버필드가 있다면 생성시점에서 해당 필드들을 모두 주입 해 줘야 하기에 @Autowired 애노테이션이 없더라도 해당 컴포넌트들을 찾아서 주입 해 준다.
@Controller, @Service 등도 내부적으로 @Component를 포함하는 메타 애노테이션이다.) 이 있는경우 Bean 등록을 하기 위해서 객체를 생성하는데 final 키워드가 있는 멤버필드가 있다면 생성시점에서 해당 필드들을 모두 주입 해 줘야 하기에 @Autowired 애노테이션이 없더라도 해당 컴포넌트들을 찾아서 주입 해 준다. 3.
Setter 주입 방법
@Autowired
public void setMemberService(MemberService memberService){
//...
}
Java
복사
→ 이 방식은 Setter/Getter와 같은 접근자 메서드(Accessor)를 최소한으로 해야한다는 원칙과도 어긋나고, 주입받는 객체가 변경될 가능성도 거의 없기에 거의 사용하지 않는다.
컴포넌트 스캔(Component Scan) 원리
•
@Component 애노테이션이 있으면 스프링 빈으로 자동 등록된다.
•
@Controller, @Service, @Repository 들도 자동 등록되는 이유는 해당 애노테이션들이 내부적으로 @Component를 포함하는 메타 애노테이션이기때문이다.
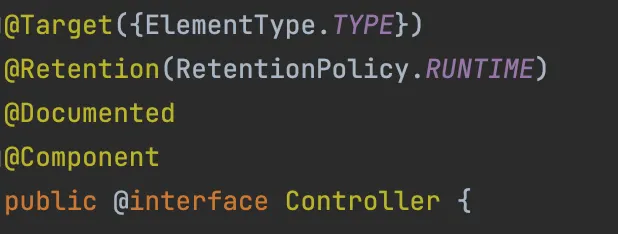
Controller 애노테이션 내부 구성
•
@ComponentScan이라는 애노테이션을 통해 컴포넌트들이스캔을 한다.
◦
@SpringBootApplication 애노테이션도 내부적으로 @ComponentScan을 가지고 있는 메타 애노테이션이다.
•
내부 속성 설정으로 스캔 범위나 예외조건등을 설정할 수 있다.
◦
basePackages
▪
패키지 경로를 지정해 탐색할 패키지의 시작 경로를 지정할 수 있다. 예를 들어, hello.core 라 지정해주면 해당 패키지 내부를 컴포넌트 스캔한다. { } 블럭 문법을 이용해 여러 패키지를 지정할 수도 있다.
▪
속성을 따로 지정하지 않으면 관례에 따라 해당 애노테이션이 존재하는 패키지가 시작 위치가 된다.
◦
excludeFilter
▪
스캔범위내에 있지만 스캔하지 않고자 하는 경우를 지정한다.
@ComponentScan(excludeFilters = @Filter(type = FilterType.ANNOTATION, classes = Configuration.class))
Java
복사
→ @Filter 애노테이션으로 지정하며 위 속성은 Configuration 클래스 애노테이션은 스캔 대상에서 제외하라는 속성이다.
데이터베이스 접속
1. 순수 JDBC
1.
환경 설정하기
//build.gradle
implementation 'org.springframework.boot:spring-boot-starter-jdbc'
runtimeOnly 'com.h2database:h2' //접속 데이터베이스 종류
Java
복사
2.
데이터베이스 연결 설정
spring.datasource.url={데이터베이스 접속 주소}
spring.datasource.driver-class-name={데이터베이스 드라이버 artifact}
spring.datasource.username={접속 유저네임}
spring.datasource.password={접속 비밀번호}
#... 기타 정보
YAML
복사
resources/application.properties(or application.yaml, application.yml, ...)
3.
스프링 빈 등록
@Configuration
public class StringConfig {
private final DataSource dataSource;
public StringConfig(DataSource dataSource){
this.dataSource = dataSource;
}
@Bean
public XxxRepository xxxRepository(){
return new JdbcXxxRepository(dataSource);
}
}
Java
복사
→ DataSource는 데이터베이스 커넥션 획득할 때 사용하는 객체로 설정정보에 넣은 커넥션 정보를 가지고 객체를 만들어 빈으로 등록한다. 그래서 주입받을 수 있다.
→ XxxRepository 빈을 등록하지만 내부적으로는 해당 객체의 하위객체를 반환함으로써 OCP
를 활용할 수 있다.(OCP: 확장에는 열려있고 수정, 변경에는 닫혀있다.)
4.
실제 사용하기
: 실제로 이 방식으로 사용되는 경우는 잦지 않기때문에 대략적으로만 소개한다.
public JdbcXxxRepository implements XxxRepository{
private final DataSource dataSource;
public JdbcXxxRepository(DataSource dataSource){
this.dataSource = dataSource;
}
@Override
public Xxx save(Xxx xxx){
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null;
try(conn = getConnection();
pstmt = conn.preparedStatement(쿼리, Statement.RETURN_GENERATED_KEYS);
rs = pstmt.executeQuery();) {
//... logic
} catch(Exception e) {
throw new IllegalStateException(e);
}
}
private Connection getConnection() {
return DataSourceUtils.getConnection(dataSource);
}
}
Java
복사
→ 아주 대략적으로 DataSource를 이용해 접속정보를 얻고 쿼리를 만들어 실행하는 정도만 작성해보았다.
스프링 JdbcTemplate
•
스프링 JdbcTemplate, MyBatis같은 라이브러리를 이용하면 위에서 본 커넥션 접속 등의 반복되는 코드들을 제거할 수 있다.
public JdbcXxxRepository implements XxxRepository{
private final JdbcTemplate jdbcTemplate;
public JdbcXxxRepository(DataSource dataSource){
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
@Override
public Xxx save(Xxx xxx){
SimpleJdbcInsert jdbcInsert = new SimpleJdbcInsert(jdbcTemplate);
jdbcInsert.withTableName("xxx").usingGeneratedKeyColumns("id");
Map<String, Object> parameters = new HashMap<>();
parameters.put("name", xxx.getName());
Number key = jdbcInsert.executeAndReturnKey(new MapSqlParameterSource(parameters));
xxx.setId(key.longValue());
return xxx;
}
@Override
public List<Xxx> findAll() {
return jdbcTemplate.query("select * from xxx", xxxRowMapper());
}
private RowMapper<Xxx> xxxRowMapper(){
return (rs, rowNum) -> {
return Xxx.builder()
.id(rs.getLong("id"))
.name(rs.getString("name"));
}
}
}
Java
복사
JPA
•
기존의 SQL, 데이터 중심 설계를 객체 중심의 설계만 고민하면 되도록 도와주는 프레임워크
•
간단한 CRUD 로직에 대한 엄청난 생산성을 가질 수 있게 해준다.
•
텍스트를 통한 쿼리 기반 데이터 CURD를 자바의 메서드 기반 CRUD로 바꿔주기에 쿼리를 잘못 작성하여 생기는 문제는 컴파일러에서 예외를 발견할 수 있어 버그 발생율도 낮춰준다.
1.
라이브러리 추가및 환경설정
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
runtimeOnly 'com.h2database:h2'
testImplementation('org.springframework.boot:spring-boot-starter-test') {
exclude group: 'org.junit.vintage', module: 'junit-vintage-engine'
}
}
Groovy
복사
build.gradle
spring.datasource.url={데이터베이스 접속 주소}
spring.datasource.driver-class-name={데이터베이스 드라이버 artifact}
spring.datasource.username={접속 유저네임}
spring.datasource.password={접속 비밀번호}
spring.jpa.hibernate.ddl-auto={create, create-drop, update, none}
#... 기타 정보
YAML
복사
2.
엔티티 작성
@Entity
@Data
public class Member {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
//...
}
Java
복사
3.
JPA 리포지토리 작성
public class JpaMemberRepository implements MemberRepository {
private final EntityManager em;
public JpaMemberRepository(EntityManager em) {
this.em = em;
}
public Member save(Member member) {
em.persist(member);
return member;
}
public Optional<Member> findById(Long id) {
Member member = em.find(Member.class, id);
return Optional.ofNullable(member);
}
//...
}
Java
복사
4.
서비스 계층에 트랜잭션 추가
@Transactional
public class MemberService{}
Java
복사
→ 스프링은 해당 클래스에서 메서드를 실행할 때 트랜잭션을 시작하고, 메서드가 정상 종료되면 트랜잭션을 커밋한다. 만약 런타임 예외가 발생하면 롤백한다.
→ (Important) JPA를 통한 데이터 변경은 트랜잭션 안에서 실행되어야 한다.
Spring Data JPA
•
Spring Data JPA를 사용하면 기존 JPA의 구현로직들마저도 라이브러리에서 제공을 해주기 때문에 더 쉽게 간단한 CRUD 기능을 사용할 수 있다.
•
JPA를 편리하게 사용하게 도와주는 기술이다.
◦
(Spring Boot와 Spring의 관계와 유사하다)
•
Spring Data JPA 계층 구조
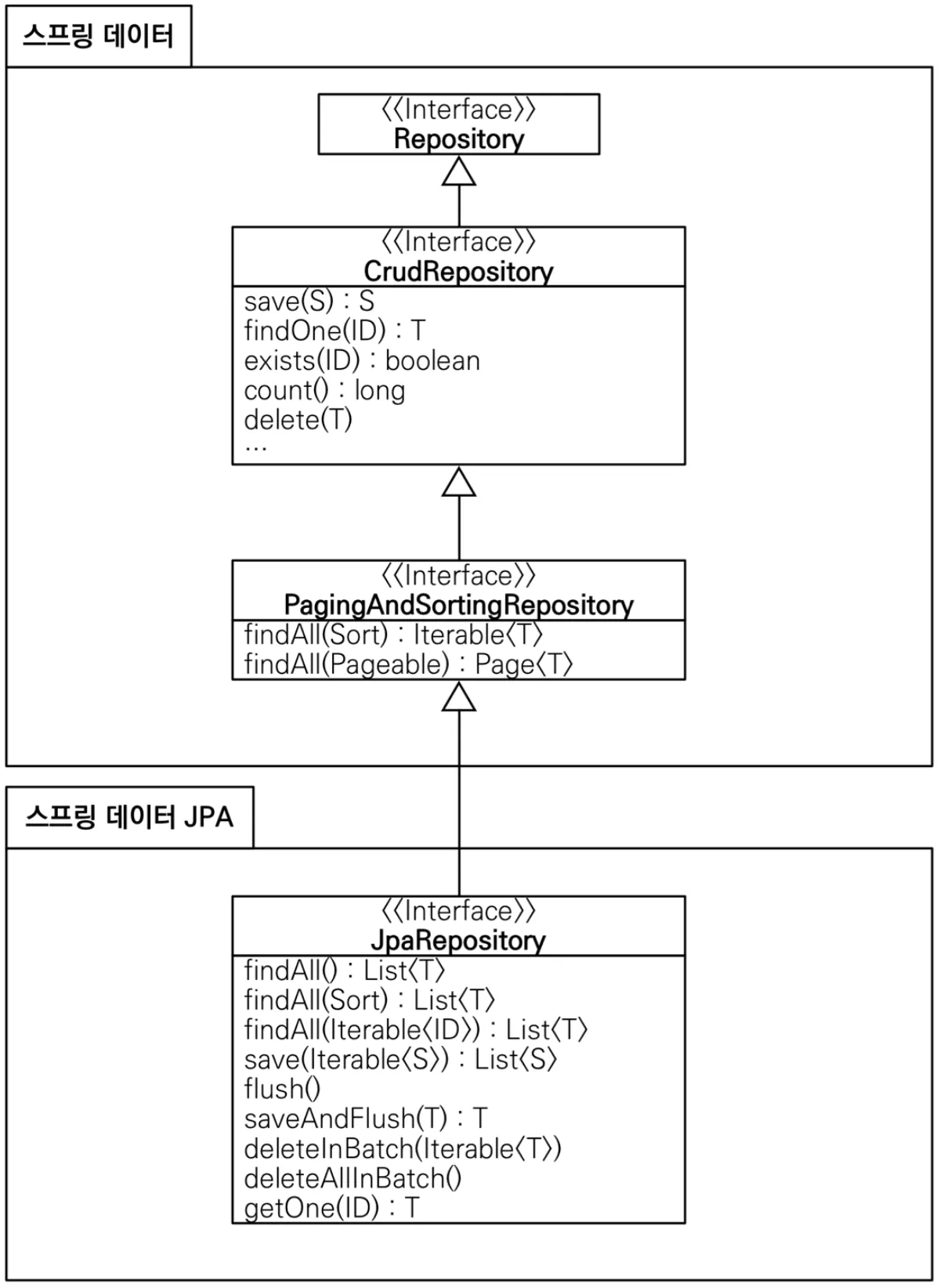
→ 인터페이스를 통해 기본적인 기능들을 제공한다.
//ex: 삭제되지 않은 나이가 10살이상인 남성 회원 조회 메서드
findByAgeGreaterThanEqualAndDeletedIsFalseAndGender(10, GenderType.MAN)
//MemberRepository
Member findByAgeGreaterThanEqualAndDeletedIsFalseAndGender(int age, GenderType type);
Java
복사
→ 페이징 기능은 PagingAndSortingRepository를 통해 자동 제공된다.