
목차
패러다임 개요
해당 책에서는 세 가지 패러다임에 대해 소개를 하는데, 이에 대해 하나씩 알아보자.
•
구조적 프로그래밍(structured programming)

구조적 프로그래밍은 제어흐름의 직접적인 전환에 대해 규칙을 부과한다.
: 최초로 만들어지진 못했지만, 최초로 적용된 패러다임.
무분별한 점프(goto 문장)가 프로그램 구조에 해롭다는 점을 근거로 제시하며 이러한 점프 대신 if/then/else와 do/while/until 과 같이 익숙한 구조로 대체한다.
•
객체지향 프로그래밍(object-oriented programming)
객체 지향 프로그래밍은 제어흐름의 간접적인 전환에 대해 규칙을 부과한다.
알골(ALGOL)언어의 함수 호출 스택 프레임(stack frame)을 힙(heap)으로 옮기면 함수 호출이 반환된 이후에도 함수에서 선언된 지역 변수가 오래 유지된다는 점을 발견했는데, 이런 함수를 클래스의 생성자로, 지역 변수는 인스턴스 변수, 중첩 함수는 메서드가 되었다.
함수 포인터를 특정 규칙에 따라 사용하는 과정을 통해 다형성이 등장하게 되었다.
•
함수형 프로그래밍(functional programming)
함수형 프로그래밍은 할당문에 대해 규칙을 부과한다.
불변성(immutability)과 심볼(symbol)의 값이 변경되지 않는다는 람다 계산법의 기초 개념을 토대로 만들어졌는데, 함수형 언어에는 할당문이 전혀 없고,
이런 세 가지 패러다임을 보면, 각각의 패러다임은 프로그래머에게서 권한을 박탈한다.
모두 개발자에게 무엇을 할 수 있게 해준다기보단 무엇을 하지 못하게 막는 제약조건들이다.
(goto문을 사용하지마라, 함수 포인터, 할당문을 사용하지마라 등등…)
구조적 프로그래밍을 설명하며 얘기하겠지만, 개발에 대해서 수학적 접근이 아닌 과학적 접근을 함으로써, 정답을 확신하기보다는 하지말아야 할 점들을 제약하며 결과적으로 클린한 구조와 코드를 추구하도록 하는게 패러다임들의 목적이다. 세 가지 패러다임과 아키텍처의 세 가지 큰 관심사(함수, 컴포넌트 분리, 데이터 관리)가 서로 어떻게 연관되는지에 대해 알아보자.
구조적 프로그래밍
수학이 아닌 과학
데이크스트라 라는 개발자는 증명(proof)이라는 수학적 원리를 이용하여 프로그램을 공리, 정리 , 따름정리, 보조정리로 구성되는 유클리트 계층구조를 만들고자 했다. 그럼으로써 코드가 올바르다는 사실을 스스로 증명하고자 하였다. 결론부터 얘기하면 증명을 통한 수학적 접근으로 유클리드 계층 구조를 만드는것은 실패했다.
데이크스트라는 수학적으로 유클리드 계층 구조를 만들기 위해 연구를 진행하다가 goto 문장이 제대로 사용되어 모듈을 분리하는데 문제가 되지 않는 경우 if/then/else와 do/while 과 같이 분기와 반복이라는 단순한 제어 구조에 해당한다는 점을 발견했다. 그리고 이런 제어 구조는 순차 실행(sequential execution)과 결합했을 때 더욱이 특별해지는데, 프로그램은 순차(sequence), 분기(selection), 반복(iteration) 세 가지 구조로 모두 표현이 가능하다는 점이다.
이러한 사실은 모듈을 증명 가능하게 하는 제어 구조가 모든 프로그램을 만들 수 있는 제어 구조의 최소 집합과 동일하다는 점으로 구조적 프로그래밍은 이렇게 탄생했다.
•
순차 구문(sequential statement)
: 각 순차 구문의 입력을 순차 구문의 출력까지 수학적으로 추적하며, 일반적인 수학적 증명 방식과 다를 바 없다.
•
분기(selection)
: 열거법을 재적용하는 식으로 처리했는데, 분기를 통한 각 경로를 열거하고, 두 경로가 수학적으로 적절한 결과를 만들어내면 증명은 신뢰할 수 있게 된다.
•
반복(iteration)
: 반복이 올바름을 증명하기위해 데이크스트라는 귀납법(induction)을 사용했는데, 열거법에 따라 1의 경우가 올바름을 증명했다. 그리고 N의 경우가 올바르다고 가정하면 N+1 도 올바름을 증명하며 , 이 경우에도 열거법을 사용했다.
기능적 분해
구조즉 프로그래밍을 통해 모듈을 증명가능한 작은 단위로 재귀적으로 분해할 수 있게 되었는데, 이는 결국 모듈을 기능적으로 분해할 수 있음을 의미한다. 그렇기에 거대한 문제 기술서를 받아도 고수준의 기능으로 분해하고 이를 또 다시 저수준의 함수로 분해하는 분해 과정을 끝없이 반복할 수 있다. 그리고 이렇게 분해한 기능들은 구조적 프로그래밍의 제한된 제어구조를 이용해 표현이 가능하다. 이런 방식을 토대로 1970년대 후반 ~ 1980년대에는 구조적 분석(structured analysis)이나 구조적 설계(structured design)와 같은 방식이 인기였다고 한다.
이런 기법들을 활용해 프로그래머는 대규모 시스템을 모듈과 컴포넌트로 나눌 수 있고 더 나아가 모듈과 컴퓨터를 입증할 수 있는 기능들로 세분화 할 수 있게 되었다.
하지만, 그럼에도 끝내 증명은 이뤄지지 못했다. 유클리드 계층구조는 결국 만들어지지 않았는데, 대부분의 프로그래머는 세세한 기능 하나하나를 모두 하드하게 증명하는 과정에서 이득을 얻을 수 없다고 생각한다.
과학적 방법(scientific method)
여기서 중요한 점은 과학에서는 이론과 법칙을 증명하지 못한다.
뉴턴의 운동 제 2법칙인 라던가 만유인력의 법칙인 도 증명할 수 없다. 소수점 이하 많은 자리의 정확도로 측정할 수도 있지만, 수학적으로 증명은 할 수 없다. 그리고 이런 점이 수학적 증명과 과학적 증명의 차이점이다. 과학즉 방법은 반증은 가능하지만 증명은 불가능하다. 결론적으로 과학은 증명 가능한 서술이 거짓임을 입증하는 원리를 이용하는 것이다.
테스트
이런 과학적 방법을 테스트와 연관시켜보면 이렇다. 테스트는 버그가 있음을 보여줄 수는 있지만, 버그가 없음을 보여줄 수는 없다. 즉, 프로그램이 잘못되었음을 테스트를 통해 반례를 보여줄 순 있지만 프로그램이 맞다고 증명할 수는 없다. 다만 테스트가 충분히 작성되어서 목표에 부합할 만큼은 참이라고 느낄 수 있도록 해주는게 전부이다.
정리하자면…
구조적 프로그래밍은 프로그램을 증명 가능한 세부 기능 집합으로 재귀적으로 분해할 것을 강요한다. 그 다음, 테스트를 통해 증명 가능한 세부 기능들이 거짓인지를 증명하려 시도한다. 그리고 이런 프로그램의 실패를 증명하는 테스트들이 실패한다면, 이 기능들은 목표에 부함할 만큼은 참이라고 여길 수 있게 된다.
객체 지향 프로그래밍
좋은 아키텍처
좋은 아키텍처를 만드는일은 객체 지향(Object-Oriented) 설계 원칙을 이해하고 응용하는데서 출발하는데, OO란 무엇일까?
이런 OO의 본질을 설명하기 위해 세 가지 키워드를 꺼낼 수 있는데, 다음과 같다.
•
캡슐화(encapsulation)
•
상속(inheritance)
•
다형성(polymorphism)
OO는 이 세 가지 개념을 적절하게 조합 혹은 최소 세 가지 요소를 반드시 지원해야 한다고 한다.
과연 그럴까?
캡슐화?
캡슐화는 데이터와 함수를 응집해 불필요한 정보를 은닉하고 필요한 정보만 노출하게 함으로써 유사한 군집끼리 최소한의 결합도를 가질 수 있도록 돕는데, OO 언어가 이런 캡슐화를 쉽고 효율적으로 제공한다. 자바에서는 흔히 private나 public 접근제어자등을 이용하면 된다.
하지만, 이런 개념은 OO에서만 국한된 것은 아니고, 사실 다른 언어에서도 완벽하게 캡슐화를 할 수가 있다. 다음은 간단한 C 프로그램이다.
struct Point;
struct Point* makePoint(double x, double y)
double distance (struct Point *p1, struct Point *p2);
C
복사
Point.h
#include "point.h"
#include <stdlib.h>
#include <math.h>
struct Point {
double x, y;
}
struct Point* makePoint(double x, double y) {
struct Point* p = malloc(sizeof(struct Point));
p-> x = x;
p-> y = y;
return p;
}
double distance(struct Point* p1, struct Point* p2) {
double dx = p1->x - p2->x;
double dy = p1->y - p2->y;
return sqrt(dx*dx+dy*dy);
}
C
복사
Point.c
위 코드를 보면 point.h를 사용하는 입장에서 struct Point의 멤버에 접근할 방법이 전혀 없다. 클라이언트 입장에서 makePoint() 함수나 distance() 함수를 호출할 순 있지만 Point 구조체의 데이터 구조와 함수가 어떻게 구현되었는지는 알 수 없다. 위 코드는 OO가 아닌 언어임에도 충분하게 캡슐화가 이뤄졌다. 오히려 C++이나 Java, C#등 OO언어에서 구현체와 헤더를 분리하는 방식을 버리고 이로 인해 캡슐화가 더 심하게 훼손되었다. 즉 OO를 제공한다고 주장한 언어들은 실제로는 캡슐화를 약화시켜온 것이다.
상속?
상속은 단순하게 변수와 함수를 하나의 유효 범위로 묶어서 재정의하는 일이라 할 수 있다.
그리고 이러한 방식은 OO언어가 있기 전에도 C 프로그래머가 언어의 도움없이 작성할 수 있었다.
struct NamedPoint;
struct NmaedPoint* makeNamedPoint(double x, double y, char* name);
void setName(struct NamedPoint* np, char* name);
char* getName(struct NamedPoint* np);
C
복사
namedPoint.h
#include "namedPoint.h"
#include <stdlib.h>
struct NamedPoint {
double x, y;
char* name;
};
struct NamedPoint* makeNamedPoint(double x, double y, char* name) {
struct NamedPoint* p = malloc(sizeof(struct NamedPoint));
p->x = x;
p->y = y;
p->name = name;
return p;
}
void setName(struct NamedPoint* np, char* name) {
np-> name = name;
}
char* getName(struct NamedPoint* np) {
return np->name;
}
C
복사
namedPoint.c
#include "point.h"
#include "namedPoint.h"
#include <stdio.h>
int main(int ac, char** av) {
struct NamedPoint* origin = makeNamedPoint(0.0, 0.0, "origin");
struct NamedPoint* upperRight = makeNamedPoint(1.0, 1.0, "upperRight");
printf("distance=%f\n", distance((struct Point*) origin, (struct Point*) upperRight));
}
C
복사
main.c
NamedPoint 데이터 구조는 마치 Point로부터 파생된 구조인 것처럼 동작한다.
이는 NamedPoint에 선언된 두 변수의 순서가 Point와 동일하기 때문인데, 이는 NamedPoint가 Point를 포함하는 상위 집합으로, Point에 대응하는 멤버 변수의 순서가 그대로 유지된다.
실제로 C++에서는 이 방법을 이용해 단일 상속을 구현했다.
OO언어가 완전히 새로운 개념을 만들진 못했지만, 데이터 구조에 가면을 씌우는 일을 편리하게 제공했다고 볼 수 있다.
다형성?
OO언어가 등장하기 전 다형성을 표현할 수 있는 언어 역시 있었다
#include <stdio.h>
void copy() {
int c;
while ((c=getchar()) != EOF)
putchar(c);
}
C
복사
여기서 getchar()는 STDIN에서 문자를 읽고 putchar()함수는 STDOUT으로 문자를 쓴다.
여기서 STDIN, STDOUT과 같은 함수는 다형적(polymorphic)인데, 행위가 타입(STDIN, STDOUT)에 의존한다. 이는 사실상 자바 형식에서는 인터페이스가 있고 구현체가 있다. 그럼 c프로그램에서는 어떻게 구현체(장치 드라이버)를 호출할 수 있을까?
유닉스 운영체제의 경우 모든 입출력 장치 드라이버가 다섯 가지 표준 함수를 제공할 것을 요구하는데, 열기(open), 닫기(close), 읽기(read), 쓰기(write), 탐색(seek)이 표준 함수들이다.
struct FILE {
void(*open)(char* name, int mode);
void(*close)();
int(*read)();
void(*write)(char);
void(*seek)(long index, int mode);
};
C
복사
#include "file.h"
void(*open)(char* name, int mode){/*...*/}
void(*close)(){/*...*/};
int(*read)(){int c; /*...*/ return c;}
void(*write)(char){/*...*/}
void(*seek)(long index, int mode){/*...*/}
struct FILE console = {open, close, read, write, seek};
C
복사
여기서 STDIN을 FILE*로 선언하면, STDIN은 콘솔 데이터 구조를 가르키기에 getchar()는 다음과 같이 구현이 가능하다.
extern struct FILE* STDIN;
int getchar() {
return STDIN-> read();
}
C
복사
여기서 getchar()는 STDIN으로 참조되는 FILE데이터 구조의 read포인터가 가리키는 함수를 단순히 호출할 뿐이라는 것인데, 이런 점이 OO가 지니는 다형성의 근간이 된다.
즉, 다형성은 OO에서 새롭게 만들어 제공한다기보다는 예전부터 존재했었던 다형성을 좀 더 안전하고 편리하게 사용할 수 있도록 해준다는 것이다.
위에 작성한 다형성의 예를 보면, 함수에 대한 포인터를 직접 사용해 다형적 행위를 만드는 방식은 함수 포인터가 위험하기에 사용하기 조심스러운데, 이러한 기법은 프로그래머가 특정 관례를 수동으로 따르는 방식이다. 그렇기에 프로그래머가 관례를 망각하면 버그가 발생하는데, 디버깅도 힘든 문제다.
OO언어는 이런 관례를 없애주고 실수할 위험을 없애준다. OO언어를 사용하면 다형성을 사용하는게 어렵지 않은 일이 되는데, 우리는 이러한 OO언어의 능력으로 인해 OO는 제어흐름을 간접적으로 전환하는 규칙을 부과한다고 결론을 내릴 수 있다.
플러그인 아키텍처
이러한 다형성을 이용하면 각 구현체들을 프로그램의 플러그인처럼 자유롭게 변경하면서 프로그램이 장치 독립적(device independent)으로 구현할 수 있다.
이러한 플러그인 아키텍처는(plugin architecture)는 장치 독립성을 지원하기 위해 만들어 졌고, 등장 이후 거의 대부분의 운영체제에서 구현되었다.
의존성 역전
과거의 소프트웨어의 호출 트리를 살펴보면 main함수에서 시작해 고수준 함수 → 중간 수준 함수→ 저수준 함수 순으로 top-down 방식으로 함수가 호출되었는데, 이 때 호출 트리에서 소스 코드 의존성의 방향은 반드시 제어흐름(flow of control)을 따르게 된다.
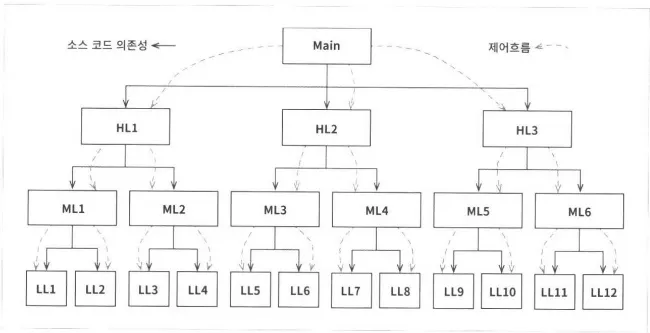
소스 코드 의존성 vs 제어 흐름
함수를 호출하기 위해서는 C에서는 #include, 자바에서는 import구문, C#에서는 using구문을 이용해서 해당 함수가 포함된 모듈을 지정해야 한다. 이러한 제약 조건으로 인해 제어 흐름은 시스템의 행위에 따라 결정되어 소스 코드 의존성은 제어흐름에 따라 결정된다.
하지만, 다형성이 들어가면서 무언가 달라지기 시작한다.
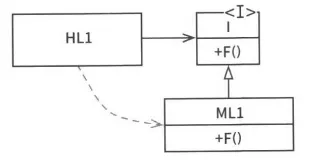
의존성 역전
위 의존성 역전 그림을 보면 HL1 모듈은 ML1 모듈의 F()함수를 호출하는데, 소스 코드에서는 인터페이스 I를 통해 F()함수를 호출한다. 그리고 이 인터페이스는 런타임에는 존재하지 않고, HL1은 ML1 모듈의 함수 F()를 호출할 뿐이다.
여기서 중요한건 ML1과 I인터페이스 사이의 소스 코드의 의존성(상속 관계)이 제어흐름과는 반대로 흐른다는 것이다. 이런 점을 의존성 역전(dependency inversion) 이라고 하는데, OO 언어가 다형성을 안전하고 편리하게 사용할 수 있게 하는 점은 소스 코드 의존성을 어디서든 역전시킬 수 있다는 뜻이기도 하다.
즉, 소스 코드 의존성이 제어흐름의 방향과 일치시켜야 한다는 제약 조건이 사라지는 것이다.
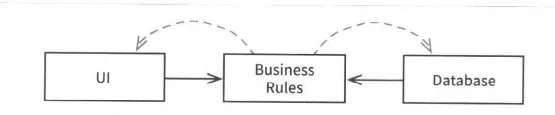
위와 같이 업무 규칙이 데이터베이스와 사용자 인터페이스에 의존하는 대신 시스템의 소스 코드 의존성을 반대로 배치해 데이터베이스와 UI가 업무 규칙에 의존하게 만들 수 있다.
이렇게 의존성 역전을 하게 됨으로써 가질 수 있는 이점은 다음과 같다.
•
배포 독립성(independent deployability)
:플러그인 아키텍트 적용을 할 수 있다. UI와 데이터베이스가 업무 규칙의 플러그인이 되어서 각각의 컴포넌트들은 배포 가능한 단위로 컴파일이 가능해지고 이 배포 단위의 의존성 역시 소스 코드 사이의 의존성과 동일하다. 따라서 업무규칙, UI 데이터베이스 컴포넌트를 각각 독립적으로 배포할 수 있고 각각의 변경사항은 업무 규칙에 영향을 주지 않는다.
•
개발 독립성(independent developability)
: 시스템의 모듈을 독립적으로 배포할 수 있다는 말은 각각의 모듈을 각기 다른 팀에서 모듈을 독립적으로 개발할 수 있다는 것이고, 이를 개발 독립성이라 한다.
정리
OO를 설명하기 위해 여러 개념들에 대해 알아봤는데, 소프트웨어 아키텍트 입장에서는 다형성을 활용해 전체 시스템의 모든 코드 의존성에 대한 절대적인 제어 권한을 확보할 수 있는 능력이라 할 수 있다.
OO를 사용해 아키텍트가 플러그인 아키텍처를 구성할 수 있고, 고수준의 정책을 포함하는 모듈은 저수준의 세부사항을 포함하는 모듈에 대해 독립성을 보장할 수 있다. 그리고 각각의 저수준의 세부사항을 포함하는 모듈에 대해 독립성이 보장될 수 있게 되고 이는 배포 독립성과 개발 독립성을 가질 수 있다는 것이다.
함수형 프로그래밍
public class Squint {
public static void main(String args[]) {
for (int i=0; i<25; i++)
System.out.println(i*i);
}
}
Java
복사
위 로직은 25까지 정수의 제곱을 출력하는 로직을 자바로 구현한 것이다. 이 로직에서 함수라 할 만한 기능들을 하나하나 분리해서 정리해보자.
1.
0부터 24까지 반복한다.
2.
제곱한다.
3.
출력한다.
여기서 자바 프로그램은 가변 변수(mutable variable)를 사용하는데, 가변 변수는 프로그램 실행 중 상태가 변경될 수 있고, 위 로직에서 반복문을 제어하는 지역변수 i 가 가변 변수다.
여기서 리스프에서 파생한 클로저(Clojure)라는 함수형 언어로 위 로직을 작성하면 다음과 같다.
(println (take 25 (map (fn [x] (* x x)) (range))))
//---------------------------------spread logic
(println ;___ 출력한다.
(take 25 ;___ 처음부터 25까지
(map (fn [x] (* x x));__제곱을
(range)))) ;___정수의
Clojure
복사
여기서 range, println, take, map등은 모두 함수로 리스프에서는 함수를 괄호안에 넣는 방식으로 호출한다. (range)는 range 함수를 호출한다고 보면 된다.
이 클로저 프로그램에서는 자바의 i 와 같은 가변 변수가 전혀 없다. 클로저에선 x와 같은 변수가 한 번 초기화되면 변하지 않는다(immutable variable) 이런 부분은 함수형 언어에서 변수는 변경되지 않는다는 점을 시사한다.
불변성과 아키텍처
아킽텍처를 고려함에 있어 변수가 변경하고 안하고가 왜 중요할까?
그 이유는 다음 문제들이 모두 가변 변수로 인해 발생하기 때문이다.
•
경합 조건(race condition)
•
교착상태 조건(deadlock)
•
동시 업데이트(concurrent update)
그렇기에 반대로 어떤 변수도 갱신되지 않는다면 위와 같은 문제가 발생하지 않는다고 생각할 수 있다. 아키텍트는 동시성(concurrency) 문제에 항상 관심을 가져야 하는데, 스레드 세이프(thread-safe)한 시스템을 갈구해야 한다.
그럼 불변성은 실현 가능한가?
저장 공간이 무한하고 프로세서의 속도가 무한하다면 충분히 가능하다. 모든 변수를 새로 생성하면 된다. 하지만, 무한대가 아니라면 어느정도의 타협을 해야 하는 불변성을 확보할 수 있다.
그럼 어떤 타협을 해야할까?
가변성의 분리
중요한 타협 포인트는 애플링케이션 혹은 애플리케이션 내부의 서비스를 가변 컴포넌트와 불변 컴포넌트로 분리하는 일이다. 불변 컴포넌트에서는 불변 변수(immutable variable)만 가지고 함수형 방식으로만 처리되야 한다. 그리고 이런 불변 컴포넌트는 변수의 상태를 변경할 수 있는 하나 이상의 다른 컴포넌트와 서로 통신한다.
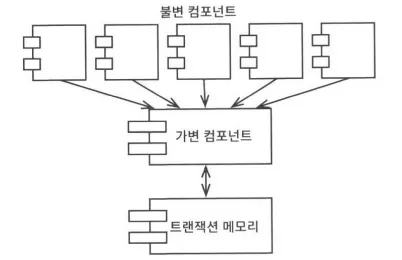
상태 변경과 트랜잭션 메모리(transactional memory)
트랜잭션 메모리와 같은 실천법을 사용해 최대한 thread-safe하게 가변 변수를 보호한다.
이러한 접근법의 간단한 예로 클로저의 atom 기능을 들 수 있다.
(def counter (atom)) ; counter를 0으로 초기화한다.
(swap! counter inc) ; counter를 안전하게 증가시킨다.
Clojure
복사
counter는 atom으로 정의된 변수다.
클로저의 atom타입은 특수한 형태의 변수로, 값을 변경하기 위해서는 swap! 함수를 사용해야 한다는 제약이 걸려 있다. swap! 함수는 변경대상인 atom 변수와 atom에 저장할 새로운 값을 인자로 받는데, 위 코드에서는 counter가 inc 함수로 계산된 (1 증가된) 값으로 변경된다.
여기서 중요한점은 swap! 함수는 비교 및 스왑(compare and swap)알고리즘 전략을 사용한다는 점인데, 진행 과정은 다음과 같다.
1.
counter 값을 읽은 후 inc 함수로 전달한다.
2.
inc 함수가 반환되면 counter의 값은 잠긴다.
3.
inc 함수로 전달했던 값과 inc 함수의 계산 결과를 비교한다.
4.
값이 같다면 inc 함수가 반환한 값이 counter에 저장되고 잠금은 해제된다.
5.
값이 같지 않다면 잠금을 해제하고 이 전략을 처음부터 재시도한다.
물론 이 atom이라는 기능이 완벽하게 동시성 문제나 교착상태 문제로부터 보호해주지는 못하지만 핵심은 변수를 변경하는 컴포넌트와 변경하지 않는 컴포넌트를 분리해야 한다는 점이다.
그렇게해서 가변컴포넌트를 최소화하고 불변컴포넌트를 늘려서 처리를 하도록 해야 한다.
이벤트 소싱
이벤트 소싱 은 상태가 아닌 트랜잭션을 저장하자는 전략으로, 상태가 필요해지면 단순의 상태의 시작점부터 모든 트랜잭션을 처리한다. (혹은 매일 자정에 상태를 계산 및 저장하고 그 이후 상태 정보가 필요하면 자정 이후의 트랜잭션만을 처리할수도 있다.)
이 전략에 필요한 데이터 저장소는 상당히 커야 할 것이다. 하지만, 이제 테라바이트도 적다고 여기는 시대이니 저장공간을 확보하는게 가능할 것이다.
그럼 이런 이벤트 소싱으로 가질 수 있는 이점은 무엇일까?
바로 저장소에서 삭제되거나 변경되는 것이 없다는 것이다. 결과적으로 애플리케이션은 CRUD가 아닌 CR만 수행한다. 또한 데이터 저장소에서 변경과 삭제가 발생하지 않기에 동시 업데이트 문제 또한 일어나지 않을 것이다.
저장 공간과 처리 능력이 충분하다면 애플리케이션은 불변성을 가질 수 있고, 따라서 완전한 함수형으로 만들 수 있다. 만약 이 이야기가 터무니 없게 들린다면, 소스 코드 버전 관리 시스템을 떠올려보자. 정확히 이 방식으로 동작한다는 사실을 떠올리자.
세 가지 패러다임 요약
•
구조적 프로그래밍은 제어흐름의 직접적인 전환에 부과되는 규율
•
객체 지향 프로그래밍은 제어흐름의 간접적인 전환에 부과되는 규율
•
함수형 프로그래밍은 변수 할당에 부과되는 규율
이 세가지 패러다임은 모두 개발자가 하지말아야 할 규율을 만들어 무언가를 앗아가고 코드를 작성하는 방식을 제한한다. 결국, 지난 시간동안 생겨나고 유행하고, 핫하다고 생각하는 패러다임은 모두 우리가 해선 안되는 것에 대한 규약이고, 이를 통해 소프트웨어가 급격하게 발전하는 기술이 아니라는 점이다. 과거부터 지금까지 도구, 하드웨어는 달라졌지만 소프트웨어의 핵심은 순차, 분기, 반복, 참조이다.

