
목차
개요

데이터 군집을 저장하는 클래스를 표준화한 설계
이전(JDK 1.2 이전)에는 Vector, Hashtable, Properties같은 컬렉션 클래스들을 이용해서 서로 다른 방식으로 컬렉션 관리를 했으나 JDK1.2 이후로는 컬렉션 프레임웍이 등장하며 표준화된 방식으로 데이터군집을 다룰 수 있게 되었다.
이 컬렉션 프레임워크는 다수의 데이터를 다루는데 필요한 대부분의 기능들을 공통화해서 개발자가 사용하기 편하도록 지원하며 컬렉션 프레임워크의 지원 스펙만 잘 공부해도 다양한 구현체 컬렉션(ArrayList, HashMap, HashSet)등을 사용하는게 몹시 쉬워진다.
핵심 인터페이스
•
컬렉션 프레임워크에서는 데이터 군집의형태를 크게 3가지로 나눠서 이 각각의 데이터군집 형태를 인터페이스로 정의했다.
◦
List, Set, Map
•
이 중에서 List와 Set은 또 공통부분들이 있어서 Collection 인터페이스로 정의했다.
List
•
순서가 있는 데이터의 집합으로 데이터의 중복을 허용한다.
•
구현 클래스
⇒ ArrayList, LinkedList, Stack, Vector ...
Set
•
순서를 유지하지 않는 데이터의 집합, 데이터의 중복을 허용하지 않는다.
•
구현 클래스
⇒ HashSet, TreeSet ...
Map
•
키와 값의 쌍(pair)으로 이루어진 데이터 군집으로 순서는 유지되지 않는다.
•
키는 중복을 허용하지 않지만, 값은 중복을 허용한다.
•
구현 클래스
⇒ HashMap, TreeMap, Hashtable, Properties...
컬렉션 프레임웍의 모든 컬렉션 클래스는 위 세가지 콜렉션 중 하나를 구현하고 있다.
Collection 인터페이스
List와 Set의 공통부분을 정의한 조상객체 Collection에서는 다음과 같은 메서드가 정의되어 있다.
List 혹은 Set 인터페이스를 구현하는 콜렉션들은 위 메서드들이 모두 지원되기에 필요에따라 사용할 수 있다.
이외에 람다와 스트림에 관련된 메서드가 추가되었는데 이는 14장 람다와 스트림에서 설명한다.
List 인터페이스
중복을 허용하면서 저장순서가 유지되는 컬렉션
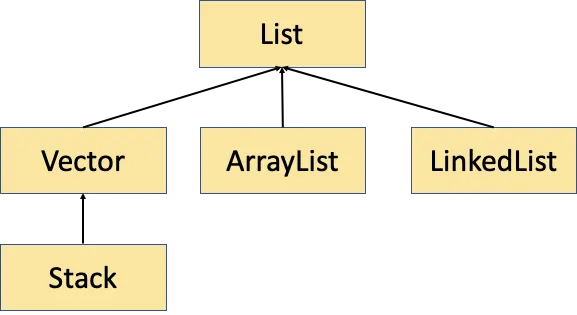
List의 상속 계층도
•
List 구현체는 기본적으로 배열기반이다.
•
LinkedList는 예외적으로 연결기반의 콜렉션이다.
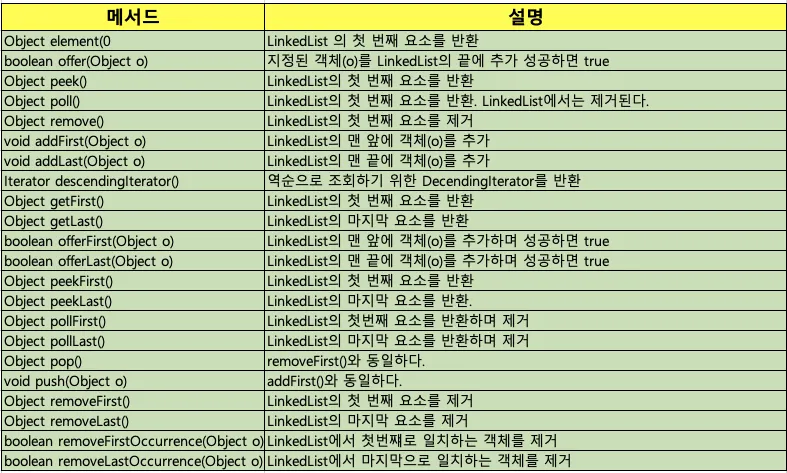
지원 메서드
Set 인터페이스
중복을 허용하지 않고 저장 순서가 유지되지 않는 컬렉션
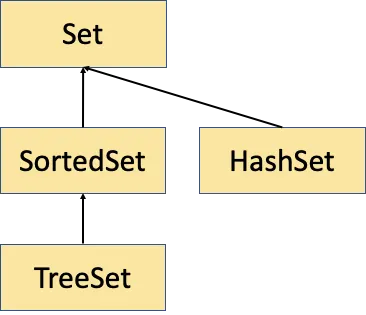
Set 상속 계층도
Map 인터페이스
키(key)와 값(value)를 하나의 쌍으로 묶어 저장하는 컬렉션
키는 중복이 허용되지 않지만, 값은 중복을 허용한다.
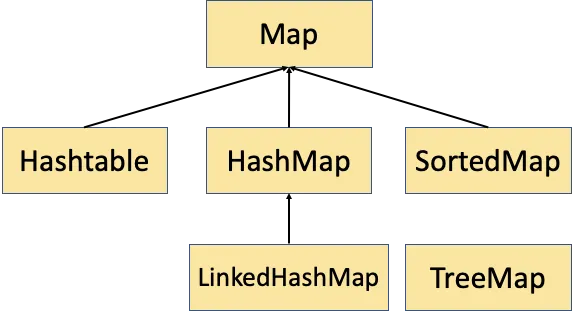
Map의 상속계층도
지원메서드
•
Map의 값(value)들은 중복을 허용하기 때문에 Collection타입으로 반환을 한다.
•
Map의 키(key)들은 중복을 허용하지 않기에 Set타입으로 반환한다.
Map.Entry 인터페이스
Map인터페이스의 내부 인터페이스로 Map에 저장되는 key-value 쌍을 다루기 위해 내부적으로 Entry 인터페이스를 정의했다.

Map.Entry인터페이스 메서드
다양한 컬렉션 클래스
1-1. ArrayList
•
컬렉션 프레임웍에서 가장 많이 사용되는 컬렉션 클래스.
•
List 인터페이스를 구현하기에 데이터의 저장순서가 유지되고 중복을 허용한다.
•
Vector를 개선한 클래스로 구현원리나 기능측면에서 유사점이 많다.
•
Object 배열을 이용해 데이터를 순차적으로 저장한다.
•
배열을 저장할 공간이 부족해지면 더 큰 배열을 생성해 기존 내용을 복사한 뒤 그 다음 저장한다.
public class ArrayList extends AbstractList implements List, RandomAccess, Cloneable, java.io.Serializable {
...
transient Object[] elementData; // Object 배열
...
}
Java
복사
지원 메서드
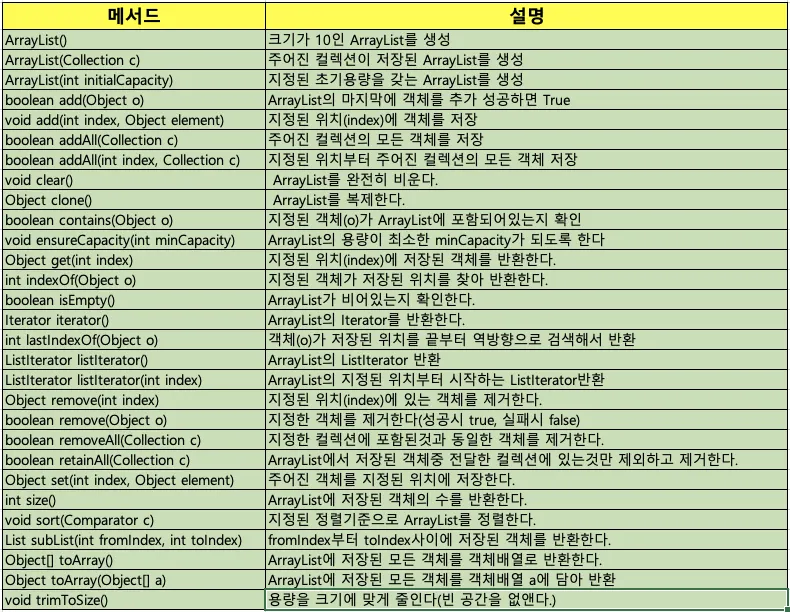
ArrayList 지원 메서드
ArrayList의 remove 메서드의 동작 원리
1.
ArrayList의 처음부터 삭제하는 경우
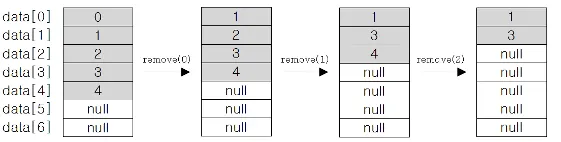
for(int i=0; i<list.size(); i++){
list.remove(i);
}
Java
복사
•
콜렉션의 끝이아닌 부분은 어딜 삭제하던 배열 복사가 이뤄진다.
2.
ArrayList의 중간부터 삭제하는 경우
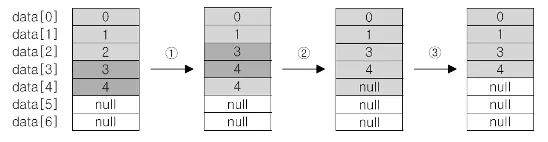
3.
ArrayList의 마지막부터 삭제하는 경우
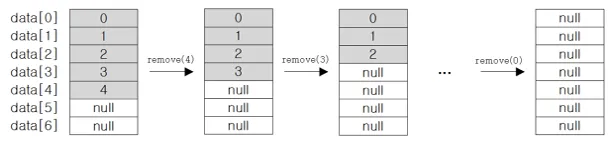
장단점
•
장점
◦
배열은 구조가 간단하고 데이터를 읽는데 걸리는 시간이 짧다.
•
단점
◦
크기를 변경할 수 없다.
⇒ 크기를 변경해야 하는경우 새로운 배열을 생성후 데이터를 복사해야 한다.
⇒ 변경을 막기위해 초기에 크기를 크게 잡으면 메모리가 낭비된다.
◦
비순차적인 데이터의 추가, 삭제에 시간이 많이 걸린다.
⇒ 데이터를 추가하거나 삭제하기위해, 다른 데이터를 옮겨야 한다.
⇒ 다만, 순차적인 데이터 추가(끝에 추가)와 삭제(끝부터 삭제)는 빠르다.
1-2 LinkedList
•
배열이 가진 장점과 단점중 단점이였던 크기변경의 제약과, 비순차적인 데이터의 추가및 삭제에 걸리는 시간을 개선하기위해 나온 자료구조가 LinkedList이다.
•
불연속적으로 존재하는 데이터를 서로 연결(link)한 형태로 구성되어 있다.

•
하나하나의 저장공간을 노드(Node)라 할 수 있는데 내부에는 자신의 다음 노드의 참조주소값과 저장할 객체를 가지고 있다.
clas Node{
Node next;//다음 요소의 주소 저장
Object object;
}
Java
복사
•
이러한 LinkedList는 그냥 연결리스트구조가 아니라 이중 연결리스트, 이중 원형 연결리스트 등이 있어서 각각의 연결리스트가 가진 단점을 해결할 수 있다.
◦
연결리스트: 이동방향이 단방향이며 이전 요소에 대한 접근이 어렵다.

◦
이중 연결리스트: 노드에 다음노드 뿐 아니라 이전 노드를 추가해 노드간의 연결성을 확대시켰다.

◦
이중 원형 연결리스트: 최초의 노드와 마지막 노드간에도 연결을 해 노드간의 연결이 원을 이루도록 하여 요소에대한 접근성을 한층 높혔다.
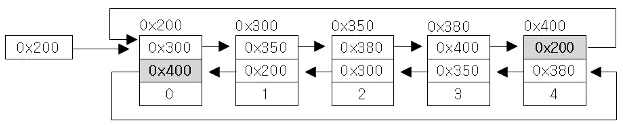
지원 메서드
List 인터페이스를 구현하기에 대부분 ArrayList와 제공 메서드가 비슷하기에 몇몇 추가적인 메서드만 설명한다.
정리
List를 구현하는 두가지 자료구조인 ArrayList와 LinkedList는 서로 장단점이 있어 필요에따라 사용하면 된다.
◦
ArrayList : 데이터 접근이 빠르지만 비순차적인 데이터 추가/삭제가 느리다.
◦
LinkedList: 데이터 접근이 느리지만 비순차적인 데이터 추가/삭제가 빠르다.
1-3 Stack과 Queue
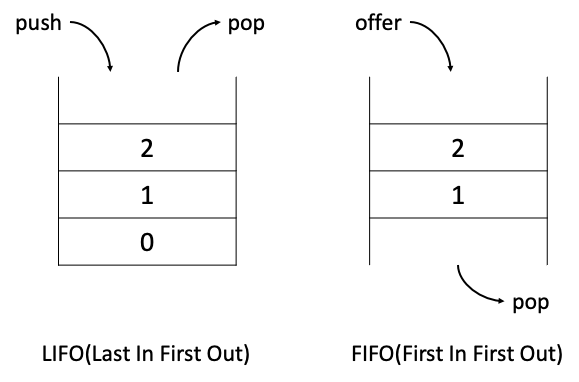
•
스택(Stack): LIFO(Last In First Out)구조로 마지막에 저장된 것을 첫 번째로 꺼낸다.
•
큐(Queue): FIFO(First In First Out)구조로 첫 번째로 저장한 것을 첫 번째로 꺼낸다.
스택과 큐의 구조
지원 메서드
•
스택 지원 메서드

•
큐 지원 메서드

스택과 큐 직접 구현해보기
•
스택 구현
import java.util.Arrays;
import java.util.NoSuchElementException;
import java.util.stream.IntStream;
public class Stack {
public static final String ERROR_EMPTY_STACK = "Stack is Empty";
int[] ints = new int[]{};
void push(int data) {
ints = Arrays.copyOf(ints, ints.length + 1);
ints[ints.length - 1] = data;
}
int pop() {
isValidPop();
int result = ints[ints.length - 1];
ints = Arrays.stream(this.ints, 0, this.ints.length - 1)
.toArray();
return result;
}
private void isValidPop() {
if (ints.length == 0) {
throw new NoSuchElementException(ERROR_EMPTY_STACK);
}
}
}
Java
복사
•
큐 구현
import java.util.Arrays;
import java.util.NoSuchElementException;
public class Queue {
public static final String ERROR_NO_SUCH_ELEMENT = "No such element";
private int[] ints = new int[]{};
public boolean add(int data) {
try{
ints = Arrays.copyOf(ints, ints.length + 1);
ints[ints.length - 1] = data;
return true;
}catch(Exception error){
System.out.println(error.getMessage());
return false;
}
}
public int poll() {
isValid();
int result = peek();
ints = Arrays.stream(this.ints, 1, this.ints.length).toArray();
return result;
}
public int peek() {
isValid();
return ints[0];
}
private void isValid() {
if(isEmpty()){
throw new NoSuchElementException(ERROR_NO_SUCH_ELEMENT);
}
}
public boolean isEmpty() {
return ints.length == 0;
}
}
Java
복사
여기서 스택과 큐를 LinkedList를 사용해 구현해보자.
추가로 LinkedList도 직접 구현해보자.
•
ListNode
import java.util.Objects;
public class ListNode {
private final int data;
private ListNode link;
public ListNode(int data, ListNode link) {
this.data = data;
this.link = link;
}
public static ListNode from(int data) {
return new ListNode(data, null);
}
public ListNode linking(ListNode node) {
link = node;
return link;
}
public ListNode next() {
return link;
}
public boolean hasNext() {
return Objects.nonNull(link);
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof ListNode)) return false;
ListNode listNode = (ListNode) o;
return data == listNode.data && Objects.equals(link, listNode.link);
}
@Override
public int hashCode() {
return Objects.hash(data, link);
}
public int getData() {
return data;
}
}
Java
복사
•
LinkedList
import java.util.Objects;
public class LinkedList {
public static final String ERROR_INVALID_POSITION = "유효하지 않은 position입니다.";
private ListNode head;
public LinkedList() {
this(null);
}
public LinkedList(ListNode head) {
this.head = head;
}
public ListNode add(int data) {
ListNode newNode = ListNode.from(data);
return add(newNode);
}
public ListNode add(ListNode newNode) {
if (isEmpty()) {
return add(null, newNode);
}
return add(head, newNode, size(head));
}
public ListNode add(ListNode head, ListNode nodeToAdd) {
if (isEmpty()) {
this.head = nodeToAdd;
return this.head;
}
return add(head, nodeToAdd, size(head));
}
private boolean isEmpty() {
return Objects.isNull(head);
}
public ListNode add(ListNode head, ListNode nodeToAdd, int position) {
isValidPosition(head, position);
ListNode beforeNode = findByPosition(head, position - 1);
ListNode afterNode = beforeNode.next();
ListNode linkedNode = beforeNode.linking(nodeToAdd);
linkedNode.linking(afterNode);
return linkedNode;
}
private void isValidPosition(ListNode head, int position) {
int size = size(head);
if (position > size || size < 0) {
throw new IllegalArgumentException(ERROR_INVALID_POSITION);
}
}
public int size() {
return size(head);
}
public int size(ListNode head) {
if (Objects.isNull(head)) {
return 0;
}
ListNode current = head;
int size = 1;
while (current.hasNext()) {
size++;
current = current.next();
}
return size;
}
public ListNode findByPosition(int position) {
isValidPosition(this.head, position);
return findByPosition(this.head, position);
}
public ListNode findByPosition(ListNode node, int position) {
if (position == 0) {
return node;
}
return findByPosition(node.next(), --position);
}
public ListNode getHead() {
return this.head;
}
public ListNode remove(ListNode head, int positionToRemove) {
ListNode resultNode = findByPosition(head, positionToRemove - 1);
ListNode nextNode = resultNode.next();
resultNode.linking(nextNode.next());
return nextNode;
}
public boolean contains(ListNode head, ListNode nodeToCheck) {
if (head.equals(nodeToCheck)) {
return true;
}
if (!head.equals(nodeToCheck) && !head.hasNext()) {
return false;
}
return contains(head.next(), nodeToCheck);
}
}
Java
복사
•
LinkedList를 활용한 ListNodeStack
import java.util.NoSuchElementException;
import java.util.Objects;
public class ListNodeStack {
public static final String ERROR_EMPTY_STACK = "Stack is Empty";
public static final String ERROR_NO_SUCH_ELEMENT = "No such element";
private ListNode head;
public void push(int data) {
if (isEmpty()) {
this.head = ListNode.from(data);
}
ListNode tail = getTail(head);
tail.linking(ListNode.from(data));
}
private boolean isEmpty() {
return Objects.isNull(head);
}
public int pop() {
isValidPop();
ListNode tail = getTail(head);
ListNode tailPrev = getTailPrev(head, tail);
tailPrev.linking(null);
return tail.getData();
}
private ListNode getTail(ListNode node) {
if (!node.hasNext()) {
return node;
}
return getTail(node.next());
}
private ListNode getTailPrev(ListNode node, ListNode tail) {
if (node.next().equals(tail)) {
return node;
}
isAllowProgress(node);
return getTailPrev(node.next(), tail);
}
private void isAllowProgress(ListNode node) {
if (!node.hasNext()) {
throw new NoSuchElementException(ERROR_NO_SUCH_ELEMENT);
}
}
private void isValidPop() {
if (isEmpty()) {
throw new NoSuchElementException(ERROR_EMPTY_STACK);
}
}
}
Java
복사
•
LinkedList를 활용한 Queue
import java.util.NoSuchElementException;
import java.util.Objects;
public class ListNodeQueue {
public static final String ERROR_NO_SUCH_ELEMENT = "No such element";
private ListNode head;
public boolean add(int data) {
try {
return add(ListNode.from(data));
} catch (Exception error) {
System.out.println(error.getMessage());
return false;
}
}
private boolean add(ListNode newNode) {
if (isEmpty()) {
this.head = newNode;
return true;
}
ListNode beforeHead = this.head;
this.head = newNode;
newNode.linking(beforeHead);
return true;
}
private ListNode getTail(ListNode node) {
if (!node.hasNext()) {
return node;
}
return getTail(node.next());
}
public int poll() {
isValid();
int result = peek();
if (isEqualsHeadAndTail()) {
this.head = null;
return result;
}
ListNode tailPrev = getTailPrev(head, getTail(head));
tailPrev.linking(null);
return result;
}
private boolean isEqualsHeadAndTail() {
return Objects.equals(getTail(head), head);
}
public int peek() {
isValid();
return getTail(head).getData();
}
private ListNode getTailPrev(ListNode node, ListNode tail) {
if (node.next().equals(tail)) {
return node;
}
isAllowProgress(node);
return getTailPrev(node.next(), tail);
}
private void isAllowProgress(ListNode node) {
if (!node.hasNext()) {
throw new NoSuchElementException(ERROR_NO_SUCH_ELEMENT);
}
}
private void isValid() {
if (isEmpty()) {
throw new NoSuchElementException(ERROR_NO_SUCH_ELEMENT);
}
}
public boolean isEmpty() {
return Objects.isNull(head);
}
}
Java
복사
Queue의 변형 - Deque, PriorityQueue, BlockinigQueue
자바에서 Queue는 인터페이스로 이를 구현한 여러 구현체가 있는데, 몇가지 구조를 소개한다.
•
PriorityQueue - 우선순위 큐
⇒ 저장한 순서에 관계없이 우선순위가 높은것부터 꺼내는 특징이 있다.
⇒ Null은 저장할 수 없다.
⇒ 저장공간으로 배열을 사용하며 각 요소는 힙(heap)이라는 자료구조의 형태로저장한다.
(힙은 이진트리의 한 종류로 가장 큰 값이나 가장 작은 값을 빠르게 찾을 수 있는 특징이 있다.)
⇒ 예) 입력[5,3,1,4,2] → 출력[1,2,3,4,5]
⇒ 객체를 넣을때는 비교할 수 있는 방법을 제공해야 한다.
⇒ 기본타입은 래퍼클래스로 오토박싱(auto-boxing)되며 해당 래퍼 클래스에서 비교하는 로직을 정의하고있기에 사용이 가능한 것이다.
•
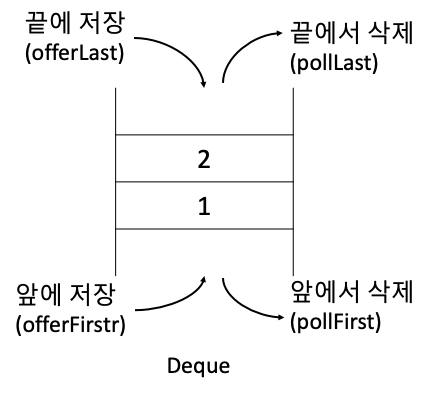
Deque(Double-Ended Queue)
⇒ Stack과 Queue의 결합으로 양 끝에서 저장(offer)과 삭제(poll)이 가능하다.
⇒ 구현클래스는 ArrayDeque, LinkedList가 있다.
⇒ 스택 혹은 큐로 사용할 수 있다.
•
BlockingQueue - 블로킹 큐
⇒ 비어있을 때 꺼내기와 가득 차 있을 때 넣기를 지정된 시간동안 지연시킨다(block)
⇒ 멀티쓰레드에서 사용할 수 있다.
1-4. Enumeration, Iterator, ListIterator
•
컬렉션에 저장된 데이터를 접근하는데 사용되는 인터페이스
•
Enumeration은 Iterator의 구 버전
•
ListIterator는 Iterator의 접근성을 향상시킨 것(단방향 → 양방향)
Iterator
•
컬렉션에 저장된 요소들을 읽어오는 방법을 표준화한 인터페이스
•
기존에는 각각의 데이터군집 클래스들이 데이터를 순회하는 방법들이 모두 달랐다.
•
지원 메서드

•
예제 코드
List<Integer> list = new ArrayList<>();
for (int index = 0; index < 10; index++) {
list.add(index);
}
Iterator<Integer> iterator = list.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
Java
복사
참고: Map은 어떻게 Iterator를 사용해야 할까?List와 Set은 위 예제코드처럼 Iterator를 통해 value를 순회할 수 있다. 그럼 Key/Value 가 쌍으로 있는 Map은 어떻게 Iterator를 바로 사용할수는 없다.
대신, keySet(), values(), entrySet() 메서드를 통해 키와 값, 혹은 엔트리 인터페이스타입으로 Set 형태로 콜렉션을 얻어온 후 여기서 iterator() 호출로 Iterator를 얻을 수 있다.
→ 예제 코드
Map<String, Integer> map = new HashMap<>();
for (int index = 0; index < 10; index++) {
map.put("key"+index, index);
}
Iterator<String> keyIt = map.keySet().iterator();
while (keyIt.hasNext()) {
System.out.println("keyIt.next() = " + keyIt.next());
}
System.out.println();
Iterator<Integer> valueIt = map.values().iterator();
while (valueIt.hasNext()) {
System.out.println("valueIt.next() = " + valueIt.next());
}
System.out.println();
Iterator<Map.Entry<String, Integer>> entryIt = map.entrySet().iterator();
while (entryIt.hasNext()) {
Map.Entry<String, Integer> entry = entryIt.next();
System.out.println("entry.getKey() = " + entry.getKey());
System.out.println("entry.getValue() = " + entry.getValue());
}
Java
복사
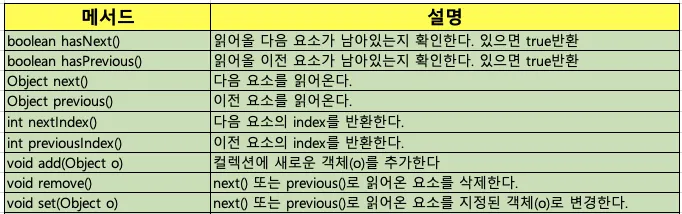
ListIterator
•
Iterator의 접근성을 단방향에서 양방향으로 확장시킨 것
•
지원 메서드
•
예제 코드
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
list.add(i);
}
ListIterator<Integer> listIterator = list.listIterator();
while (listIterator.hasNext()) {
System.out.println("listIterator.hasNext() = " + listIterator.hasNext());
System.out.println("listIterator.next() = " + listIterator.next());
}
System.out.println("listIterator.hasNext() = " + listIterator.hasNext());
System.out.println();
while (listIterator.hasPrevious()) {
System.out.println("listIterator.hasPrevious() = " + listIterator.hasPrevious());
System.out.println("listIterator.previous() = " + listIterator.previous());
}
System.out.println("listIterator.hasPrevious() = " + listIterator.hasPrevious());
Java
복사
◦
기존 Iterator와는 다르게 previous로 양방향 이동이 가능하다.
◦
사용시 hasNext(), hasPrevious()를 통해 이동가능 여부를 항상 확인하는것이 좋다.
1-5. Arrays
•
배열을 다루는데 도움을 주는 메서드가 정의된 유틸 클래스.
사용 예
1.
배열의 출력 - toString()

•
모든 타입 매개변수에 대해 대응된다.
2.
배열의 복사 - copyOf(), copyOfRange()
•
배열 전체를 복수할 때는 copyOf(), 배열의 일부 범위만 복사할때는 copyOfRange()를 사용한다.
int[] arr = {0,1,2,3,4,5};
int[] ints1 = Arrays.copyOf(arr, arr.length); //[0,1,2,3,4]
int[] ints2 = Arrays.copyOf(arr, 3);//[0,1,2]
int[] ints3 = Arrays.copyOf(arr, 8);//[0,1,2,3,4,5,0,0]
int[] ints4 = Arrays.copyOfRange(arr, 1,5); //[1,2,3,4]
int[] ints5 = Arrays.copyOfRange(arr, 5, 8); //[5,0,0]
Java
복사
•
지정된 범위의 끝은 포함되지 않는다.
•
범위가 실제 배열의 크기보다 클 경우 0으로 채워져서 반환된다.
3.
배열 채우기 - fill(), setAll()
•
fill()은 배열의 모든 요소를 지정된 값으로 채운다.
•
setAll()은 배열을 채우는데 사용할 함수형 인터페이스를 매개변수로 받는다.
⇒ 함수형 인터페이스를 구현할 객체를 매개변수로 지정하던가 람다식을 사용한다.
•
예제 코드
Random random = new Random();
int[] arr = new int[5];
Arrays.fill(arr, 9);//[9,9,9,9,9]
Arrays.setAll(arr, new Plus10());
System.out.println("Arrays.toString(arr) = " + Arrays.toString(arr));
Arrays.setAll(arr, (index)-> random.nextInt(10) * index);
System.out.println("Arrays.toString(arr) = " + Arrays.toString(arr));
Java
복사
import java.util.function.IntUnaryOperator;
public class Plus10 implements IntUnaryOperator {
@Override
public int applyAsInt(int operand) {
return operand + 10;
}
}
Java
복사
◦
FunctionalInterface를 구현하는 구현체 생성방식과, 람다식 생성방식을 모두 사용해보았다.
4.
배열의 정렬과 검색 - sort(), binarySearch()
•
sort() 메서드는 배열을 정렬해준다.
•
binarySearch()메서드는 이진검색 알고리즘으로 요소를 검색하는데, 범위가 절반씩 줄어들기에 검색 속도가 빠르다. 하지만, 배열이 정렬되어있어야 한다는 단점이 있다.
•
사용 예제
int[] arr = {5,3,7,1,2,9,4};
Arrays.sort(arr);
System.out.println("Arrays.toString(arr) = " + Arrays.toString(arr));
int findIndex = Arrays.binarySearch(arr, 3);
System.out.println("findIndex = " + findIndex);
System.out.println("arr[findIndex] = " + arr[findIndex]);
Java
복사
참고: 기본타입이 아닌 객체 배열은 어떻게 정렬과 검색을 할 수 있을까?기본타입은 래퍼클래스로 오토박싱되어 자동으로 compare되지만 사용자 정의 객체는 어떻게 정렬및 검색을 할 수있을까? 비교를 할 수있도록 해당 객체에 Comparable 인터페이스를 구현해 compareTo()를 오버라이딩해야 한다. 반환타입은 int형인데 원본객체가 더 클 경우 양수, 동일할경우 0, 더 작을 경우 음수를 반환하도록 구현하면 된다.
•
사용자 정의 객체 - Numbers
package collections;
public class Number implements Comparable {
private int number;
public Number(int number) {
this.number = number;
}
public int getNumber() {
return number;
}
@Override
public int compareTo(Object o) {
Number target = (Number) o;
return number - target.getNumber();
}
@Override
public String toString() {
return number+"";
}
}
Java
복사
•
main
int[] arr = {5,3,7,1,2,9,4};
Number[] numbers = new Number[arr.length];
for (int i = 0; i < arr.length; i++) {
numbers[i] = new Number(arr[i]);
}
Arrays.sort(numbers);
System.out.println("Arrays.toString(numbers) = " + Arrays.toString(numbers));
int index = Arrays.binarySearch(numbers, new Number(4));
System.out.println("index = " + index);
System.out.println("numbers[index] = " + numbers[index]);
Java
복사
5.
문자열의 비교와 출력 - equals(), deepEquals(), toString(), deepToString()
•
toString()은 위에 작성한것처럼 요소를 편하게 출력하게 해주는 메서드.
•
deepToString()은 다차원 배열에서 사용하는 메서드로 모든 요소를 재귀적으로 접근해 문자열을 구성한다.
•
equals()메서드는 배열의 모든 요소를 비교해 같으면 true를 반환하는 메서드이다.
•
deepEquals()메서드는 다차원 배열간 비교할 때 사용하는 메서드이다.
•
예제 코드
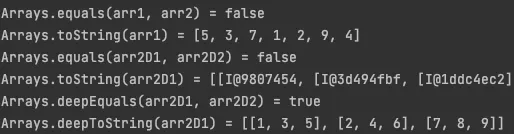
int[] arr1 = {5, 3, 7, 1, 2, 9, 4};
int[] arr2 = {10, 11, 14, 15, 13, 19};
int[][] arr2D1 = {{1, 3, 5}, {2, 4, 6}, {7, 8, 9}};
int[][] arr2D2 = {{1, 3, 5}, {2, 4, 6}, {7, 8, 9}};
System.out.println("Arrays.equals(arr1, arr2) = " + Arrays.equals(arr1, arr2));
System.out.println("Arrays.toString(arr1) = " + Arrays.toString(arr1));
System.out.println("Arrays.equals(arr2D1, arr2D2) = " + Arrays.equals(arr2D1, arr2D2));
System.out.println("Arrays.toString(arr2D1) = " + Arrays.toString(arr2D1));
System.out.println("Arrays.deepEquals(arr2D1, arr2D2) = " + Arrays.deepEquals(arr2D1, arr2D2));
System.out.println("Arrays.deepToString(arr2D1) = " + Arrays.deepToString(arr2D1));
Java
복사
실행 결과
6.
배열을 List로 변환 - asList(Object... obj)
•
배열을 List에 담아 반환하는 메서드
•
가변인자 타입이라 저장할 요소들만 나열하는 식으로 사용이 가능하다.
•
예제 코드
List<Integer> integers1 = Arrays.asList(new Integer[]{1, 2, 3, 4, 5});
List<Integer> integers2 = Arrays.asList(1, 2, 3, 4, 5);
System.out.println("integers1 = " + integers1);
System.out.println("integers2 = " + integers2);
Java
복사
주의: 해당메서드를 이용해 만든 List는 크기를 변경할 수 없기에 추가 및 삭제가 불가능하다. 저장된 내용의 수정만 가능하다. 만약 크기 변경이 가능해져 추가 삭제가 가능한 List가 필요하다면 다음과 같이사용한다.List list = new ArrayList(Arrays.asList(1,2,3,5));
Java
복사
1.6 Comparator, Comparable
객체를 정렬하는데 필요한 메서드를 정의한 인터페이스
Comparable
: 기본 정렬기준을 구현하는데 사용하며, Integer, Double 과 같은 wrapper 클래스나 String, Date, File같은 제공 클래스들을 기본적으로 오름차순으로 정렬되도록 구현되어 있다.
즉, Comparable을 구현한 클래스는 정렬이 가능하다고 생각하면 된다.
Comparator도 정렬을 지원하는 인터페이스인 것에서는 동일하지만 기본 정렬기준과 다르게 정렬하고 싶을 때 사용하는 인터페이스다. 보통 익명 클래스나 람다식을 사용해서 구현을 많이 하는편이고, 오름차순 정렬을 내림차순 정렬로 정렬하고자 할 때 많이 사용한다.
public interface Comparator{
int compare(Object o1, Object o2);
boolean equals(Object obj);
}
public interface Comparable {
public int compareTo(Object o);
}
Java
복사
•
compare, compareTo는 이름과 매개변수만 약간 다를 뿐 목적은 같다.
•
둘 모두 비교하는 값이 더 클 경우 음수를, 반대는 양수 그리고 동일할 경우 0을 반환하도록 구현해야 한다.
⇒ 단순히 양수,음수만 전달하는게아니라 정확한 두 값의 차이가 반대의 경우로 계산할때도 같아야 한다.
•
equals 메서드는 Comparator를 구현하는 클래스는 오버라이딩이 필요할 수도 있다는 점을 알리기 위해 정의한 것일 뿐 compare(Object o1, Object o2)만 구현하면 된다.
1.7 HashSet
순서가 없고, 중복도 없는 Set 컬렉션 구현체.
•
HashSet은 내부적으로는 HashMap을 이용해 만들어졌으며 해싱(hashing)을 이용해 구현했기에 붙혀진 이름.
•
지원 메서드 자체는 List와 같은 Collection 인터페이스
•
HashSet은 객체를 저장하기전 중복이 존재하는지 확인한 뒤 중복이 아닐 경우에만 저장한다.
⇒ 중복일 경우 false를 반환한다.
•
HashSet은 저장 순서를 유지하지 않기에 저장 순서를 유지하고자 한다면 LinkedHashSet을 사용해야 한다.
•
요소를 추가(add , addAll)하기 전 요소의 중복 검사를 하는데, 이 검사를 위해 equals() and hashCode()를 사용해 비교하기 때문에, 오버라이딩 되어 있어야 한다.
참고: load factor는 컬렉션 클래스에 저장공간이 가득 차기전 미리 용량을 확보하기 위한 것으로 이 값을 0.8로지정하면 저장공간의 80%가 채워졌을 때 용량이 두 배로 늘어난다. 기본값은 0.75(75%)이다.1.8 TreeSet
순서가 없고, 중복도 없는 Set 컬렉션 구현체.
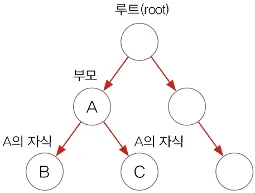
이진 검색 트리(binary search tree) 자료구조 형태의 컬렉션 클래스
•
정렬, 검색, 범위검색에 높은 성능을 보인다.
•
레드-블랙 트리(Red-Black tree)로 구현되어 있다.
•
LinkedList처럼 여러 노드(Node)가 서로 연결된 구조이다.
◦
각 노드는 최대 2개의 노드를 연결할 수 있다.
◦
최초의 루트(Root)노드부터 시작해 계속 확장해 나갈 수 있다.
binary tree
•
이진트리를 코드로 보면 다음과 같다.
class TreeNode {
TreeNode left; //좌측 자식 노드
Object element; //객체 저장용 참조변수
TreeNode right; //우측 자식 노드
}
Java
복사
•
이진 검색 트리(binary search tree)의 특징
→ 모든 노드는 최대 2개의 자식노드를 가질 수 있다.
→ 왼쪽 자식노드의 값은 부모노드의 값보다 작고 우측자식노드의 값은 부모노드의 값보다 커야 한다.
→ 노드의 추가 삭제가 오래걸린다(순차적으로 지정하지 않음)
→ 검색(범위검색)에 유리하다.
→ 중복된 값을 저장하지 못한다.
이진트리 검색 흐름
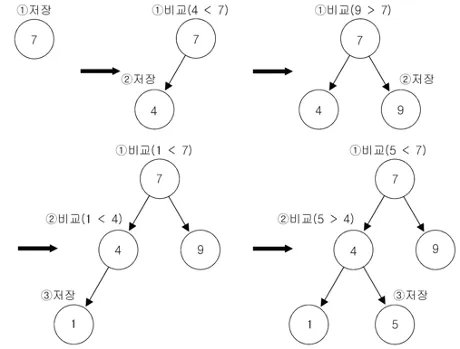
[7, 4, 9, 1, 5]의 순서로 값을 저장한다고 할 때의 저장 흐름은 다음과 같다.
1.
7 저장
2.
4가 입력되면 7과 비교 후 4가 더 작기에 좌측 노드(left)에 저장
3.
9가 입력되면 7과 비교 후 9가 더 크기에 우측 노드(right)에 저장
4.
1이 입력되면 7과 비교 후 1이 더 작기에 좌측 노드로 이동
a.
좌측노드에는 이미 4가 저장되어있기에 4와 값을 비교 후 1이 더 작기에 4의 좌측 노드(left)에 저장
5.
5가 입력되면 7과 비교 후 5가 더 작기에 좌측 노드로 이동
a.
좌측노드에는 이미 4가 저장되어있기에 4와 비교 후 5가 더 크기에 4의 우측 노드(right)에 저장
주요생성자와 지원 메서드
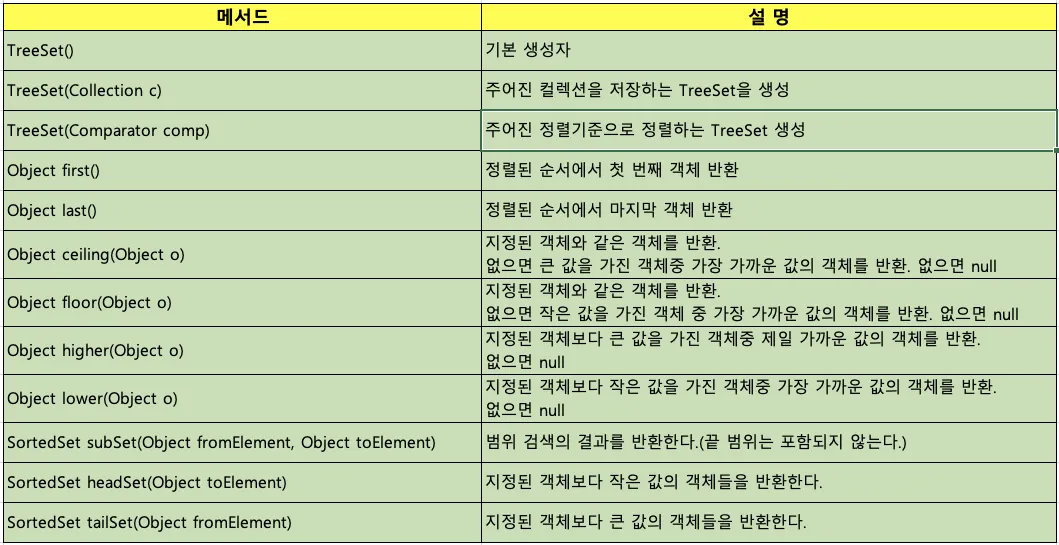
범위 검색 - subSet(), headSet(), tailSet()
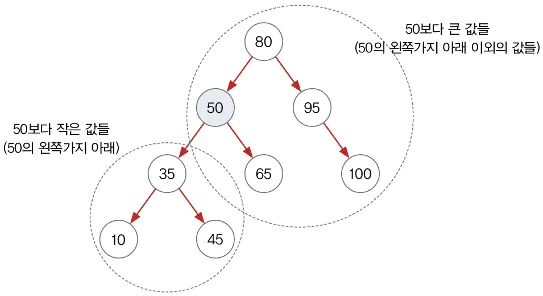
이진 검색 트리
•
노드 50을 기준으로 headSet(Object toElement)를 이용해 50보다 작은 객체들을 반환받을 수 있다.
•
노드 50을 기준으로 tailSet(Object fromElement)를 이용해 50보다 큰 객체들을 반환받을 수 있다.
•
treeSet.subSet(35, 95)를 호출했을때의 결과는? 정답
트리순회(전위, 중위, 후위)
•
이진트리의 모든 노드를 한 번씩 읽는 것을 트리 순회라 한다.
•
리스트나 스택, 큐와 같은 선형 자료구조와 다르게 트리는 계층구조라서 여러 순회 방법이 있을 수 있다.
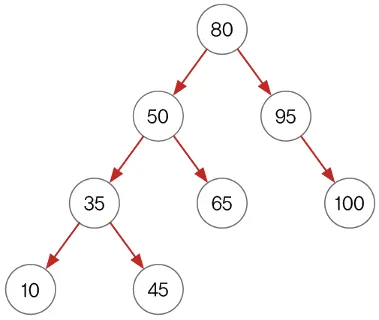
이진 검색 트리
•
전위 순회(preoder traverse)
⇒ 루트 노드(Root)부터 방문해 순회하는 방식
⇒ Root → Left → Right
⇒ 진행 방향: 80 → 50 → 35 → 10 → 45 → 65 → 95 → 100
•
중위 순회(inorder traverse)
⇒ 왼쪽 하위 트리 방문 후 루트 노드(Root)를 방문해 순회하는 방식
⇒ Left → Root → Right
⇒ 진행 방향: 10 → 35 → 45 → 50 → 65 → 80 → 95 → 100
•
후위순회(postorder traverse)
⇒ 하위 트리를 모두 방문 후 루트 노드(Root)를 방문해 순회하는 방식
⇒ Left → Right → Root
⇒ 진행 방향: 10 → 45 → 35 → 65 → 50 → 100 → 95 → 80
1.9 HashMap
순서가 없고, 키의 중복은 허용하지 않으나 값의 중복은 허용하는 데이터 군집 관리 컬렉션
Map의 상속계층도
•
Hashtable의 신 버전이 HashMap이다. 그렇기에 Hashtable보다는 HashMap을 사용하도록 하자.
→ Hashtable은 동기화가 되기때문에 동기화가 되지 않는 HashMap이 나왔다.
•
순서를 유지하고싶다면 LinkedHashMap 클래스를 사용하면 된다.
•
해싱(hashing)기법으로 데이터를 저장하며 데이터가 많아도 검색이 빠르다.
•
Map 인터페이스를 구현했으며 데이터를 키와 값의 쌍(pair)으로 저장한다.
•
내부에 키(key)와 값(value)을 갖는 Entry라는 내부 클래스를 정의해 해당 클래스의 객체 배열로써 관리한다.
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
...
transient Node<K,V>[] table;
static class Node<K,V> implements Map.Entry<K,V> {
final K key;
V value;
...
}
}
Java
복사
◦
책에는 Entry[] table 객체 배열을 사용하지만, 현재 HashMap을 뜯어보면 실제로는 Entry를 구현하는 Node객체배열이 사용된다.
HashMap에서 Value를 찾는 방법
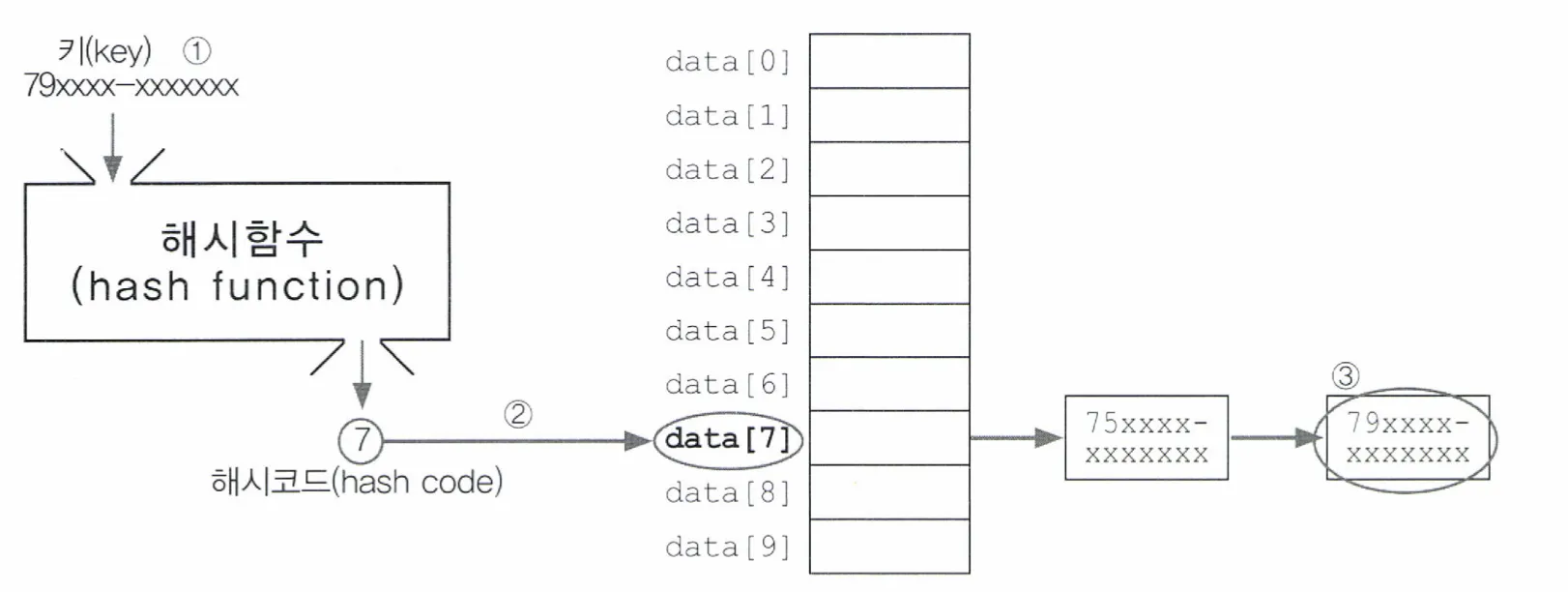
1.
검색할 키(주민등록번호)의 해시코드를 구한다.
2.
해시테이블(hashtable)에서 입력받은 키로 해시코드를 얻은 다음 배열에서 해당 위치에 요소를 찾는다.
3.
해당 요소에 연결된 링크드 리스트에서 키와 일치하는 데이터를 찾는다.
해싱화 해시함수
해싱: 해시함수를 이용해 데이터를 해시 테이블에 저장및 검색하는 기법
•
HashSet, HashMap, Hashtabe등이 해싱을 구현한 클래스다.
•
배열과 링크드리스트를 혼합해서 사용한다.
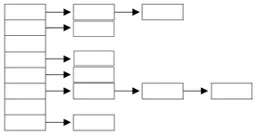
배열과 링크드리스트의 조합
•
대체로 Object에 정의된 hashCode() 메서드를 이용해 객체의 주소를 이용하는 알고리즘으로 해시코드를 만들어낸다.
참고: 해시란?
해시란 임의의 크기를 가진 데이터(Key)를 고정된 크기의 데이터(Value)로 매핑한 값.기존 자료구조가 탐색및 삽입에 선형시간이 걸린다면 해시는 인덱스를 사용해 즉시 저장하거나 찾고자하는 위치를 참조할 수 있어서 속도에서 유리함을 가진다.

1-10. TreeMap
순서가 없고, 키의 중복은 허용하지 않으나 값의 중복은 허용하는 데이터 군집 관리 컬렉션
•
TreeSet과 같이 데이터(Key)를 정렬한 뒤 저장하기 때문에 속도가 느리다.
•
TreeMap을 이용해 구현되어 있다.
•
다수의 데이터에서 개별적인 검색은 TreeMap보다 HashMap이 빠르다.
◦
정렬이나 범위검색이 필요한 경우 TreeMap을 사용한다.
1-11. Collections
콜렉션을 지원하는 유틸클래스를 제공하는 유틸 클래스
컬렉션 동기화
•
멀티 쓰레드 환경에서 공유객체는 일관성을 유지하기위해 동기화(synchronization)가 필요하다.
•
구버전 컬렉션(Vector, Hashtable)은 자체적으로 동기화 처리 기능이 있다.
→ 멀티쓰레드가 아닌 경우 성능을 떨어트린다.
•
신버전 컬렉션(ArrayList, HashMap...)은 필요한 경우에 Collections 클래스의 동기화 메서드를 이용해 동기화처리를 한다.
•
동기화 메서드는 다음과 같다.
static Collection synchronizedCollection(Colleciton c)
static List synchronizedList(List list)
static Set synchronizedSet(Set s)
static Map synchronizedMap(Map m)
static SortedSet synchronizedSortedSet(SortedSet s)
static SortedMap synchronizedSortedMap(SortedMap m)
//ArrayList를 동기화하여 사용하는 법
List syncList = Collections.synchronizedList(new ArrayList(...));
Java
복사
변경불가 컬렉션 만들기
•
컬렉션에 저장된 데이터를 보호하기 위해 컬렉션을 변경할 수 없도록 읽기전용으로 만들 때 사용한다.
•
멀티 쓰레드 프로그래밍에서 여러 쓰레드에 의해 하나의 컬렉션이 공유되면 데이터 위/변조의 위험이 있는데, 이를 방지하기 위해 사용한다.
•
다음과 같은 메서드를 사용한다.
static Collection unmodifiableCollection(Colleciton c)
static List unmodifiableList(List list)
static Set unmodifiableSet(Set s)
static Map unmodifiableMap(Map m)
static NavigableSet unmodifiableNavigableSet(NavigableSet s)
static SortedSet unmodifiableSortedSet(SortedSet s)
static NavigableMap unmodifiableNavigableMap(NavigableMap m)
static SortedMap unmodifiableSortedMap(SortedMap m)
Java
복사
싱글톤 컬렉션 만들기
•
싱글톤 패턴을 사용해 만드는 콜렉션으로 반환된 콜렉션은 변경이 불가능하다.
•
다음과 같은 메서드를 사용한다.
static List singletonList(Object o)
static Set singleton(Object o)
static Map singletonMap(Object key, Object value)
Java
복사

