
목차
Previous
1회차에서는 요약보다는 최대한 그대로 작성하며 원본 그대로 학습하고 회차가 반복되며 요약할 예정
아키텍처란?
개요
•
소프트웨어 아키텍트는 고수준의 정책에 집중하기에 코드를 안봐도 된다는 거짓말에 속지말자. 코드의 양은 줄어들 수 있지만, 프로그래밍 작업에는 지속적인 참여가 필요하다.
•
소프트웨어 시스템의 아키텍처란 시스템을 구축했던 사람들이 만들어낸 시스템의 형태
◦
컴포넌트 분할 방법, 분할된 컴포넌트의 배치방식, 컴포넌트간의 의사소통 방식등..
•
아키텍처 안의 소프트웨어 시스템이 쉽게 개발, 배포, 운영, 유지보수 되도록 만들어진다.
•
시스템 아키텍처는 시스템의 동작여부와는 큰 관련이 없다.
◦
엉망인 아키텍처의 시스템도 그런대로 잘 동작한다.
◦
문제는 운영이 아닌 배포, 유지보수, 지속되는 개발 과정에서 생길 것이다.
•
아키텍처의 주 목적은 시스템의 생명주기를 지원하는 것이다.
개발
개발하기 힘든 시스템은 수명이 길지도 않을 뿐더러 건강하지도 않을 것이다.
그렇기에 시스템 아키텍처는 개발팀이 시스템을 쉽게 개발할 수 있도록 만들 필요가 있다.
그런데 팀의 구조나 규모에 따라 아키텍처 관련 결정도 달라질 수 있는데, 만약 신규 프로젝트의 개발자 팀이 5명정도로 소규모라면, 서로 협의하에 모놀리틱( monolitic )구조로 시스템을 개발할 수도 있다. 반면, 7명으로 구성된 다섯 팀이 시스템을 개발한다면 시스템을 신뢰할 수 있고 안정된 인터페이스를 갖춘 잘 설계된 컴포넌트 단위로 분리하지 않으면 개발이 진척되지 않는다. 다른 요소를 고려하지 않는다면 이 시스템에서 아키텍처는 각 팀마다 하나씩 다섯 개의 컴포넌트로 발전될 가능성이 다분하다.
이런 아키텍처는 시스템을 배포,운영,유지보수하는데 있어서 최선일 가능성은 낮다. 하지만, 일정에 쫒겨서 개발을 하다보면 이 아키텍처로 귀착될 가능성이 높다.
배포
개발된 시스템을 사용하기 위해선 배포가 되어야 한다. 그런데 매 번 배포하는 비용이 크다면 시스템의 유용성은 떨어지게 된다. 그렇기에 소프트웨어 아키텍처는 시스템을 한 번에 쉽게 배포할 수 있도록 만드는데 목표를 두어야 한다.
문제는 개발 초기에 배포 전략을 거의 고려하지 않는다는 점인다. 이로 인해 나중에 배포할 때 비용이 큰 아키텍처가 만들어 질 수 있다. 예를 들어 MSA(Micro-service Architecture)를 사용하기로 결정했다가 배포 시점에 너무 많아진 마이크로 서비스들로 인해 곤욕을 치를 수 있다.
만약 배포 문제를 초기에 고려했다면, 더 적은 서비스를 사용하고, 서비스 컴포넌트와 프로세스 수준의 컴포넌트를 하이브리드 형태로 융합하며, 좀 더 통합된 도구를 사용하여 상호 연결을 관리했을 것이다.
운영
업무 규칙
애플리케이션을 업무 규칙과 플러그인으로 구분하기 위해선 업무 규칙이 실제로 무엇인지를 이해해야 한다. 그럼 업무 규칙이란 무엇일까? 엄밀히 말해 업무 규칙은 사업적으로 수익을 얻거나 비용을 줄일 수 있는 규칙 또는 절차다. 더 엄밀히는 컴퓨터상으로 구현했는지와 상관엇ㅂ이, 업무 규칙은 사업적으로 수익을 얻거나 비용을 줄일 수 있어야 한다. 이는 사람이 수동으로 직접 수행하더라도 마찮가지다.
대출에 N%의 이자를 부과한다는 사실은 으행이 돈을 버는 업무 규칙으로 이러한 부분을 컴퓨터 프로그램으로 하던, 직원이 직접 계산을 하든 상관없다. 이러한 규칙을 핵심 업무 규칙(Critical Business Rule)이라 부른다. 핵심 업무 규칙은 보통 데이터를 요구하는데, 예를 들어 대출에는 대출 잔액, 이자율, 지급 일정이 필요하다. 이러한 데이터를 핵심 업무 데이터(Critical Business Data)라고 부른다.
이런 데이터는 시스템으로 자동화되지 않은 경우에도 존재하는 데이터다.
핵심 규칙과 핵심 데이터는 본질적으로 결합되어 있기 때문에 객체로 만들 좋은 후보가 된다.
우리는 이런 유형의 객체를 엔티티라 부른다.
엔티티
컴퓨터 시스템 내부의 객체로서, 핵심 업무 데이터를 기반으로동작하는 일련의 조그만 핵심 업무 규칙을 구체화한다. 엔티티 객체는 핵심 업무 데이터를 직접 포함하거나 핵심 업무 데이터에 매우 쉽게 접근할 수 있다. 엔티티의 인터페이스는 핵심 업무 데이터를 기반으로 도작하는 핵심 업무 규칙을 구현한 함수들로 구성된다.
예를 들어 대출을 의미하는 Loan 엔티티가 UML 클래스로 표현하면 다음과 같다. Loan 엔티티는 세 가지 핵심 업무 데이터를 포함하며, 데이터와 관련된 세 가지 핵심 업무 규칙을 인터페이스로 제공한다. 이러한 종류의 클래스를 생성할 때, 업무에서 핵심적인 개념을 구현하는 소프트웨어는 한데 모으고, 구축 중인 자동화 시스템의 나머지 모든 고려사항과 분리시킨다.
이 클래스는 업무의 대표자로서 독립적으로 존재한다.
이 클래스는 데이터베이스, 사용자 인터페이스, 서드파티 프레임워크에 대한 고려사항들로 인해 오염되어서는 안 된다.

Loan 엔티티
이 클래스는 어떤 시스템에서도 업무를 수행할 수 있으며, 시스템의 표현 형식이나 데이터 저장 방식, 그리고 해당 시스템에서 컴퓨터가 배치되는 방식과도 무관하다. 엔티티는 순전히 업무에 대한 것이며, 이외의 것은 없다.
유스케이스
모든 업무 규칙이 엔티티처럼 순수하지는 않다. 자동화된 시스템이 동작하는 방법을 정의 및 제약함으로써 수익을 얻거나 비용을 줄이는 업무 규칙도 있다. 이러한 규칙은 자동화된 시스템의 요소로 존재해야만 의미가 있으므로 수동 환경에서는 사용될 수 없다.
예를 들어 은행 직원이 신규 대출을 생성할 때 사용하는 애플리케이션을 상상해보자.
은행에서 대출 담당자가 신청자의 신상정보를 수집하여 검증한 후, 신청자의 신용도가 500보다 낮다면 대출 견적을 제공하지 않기로 결정했다고 해 보자. 따라서 시스템에서 신상정보 화면을 모두 채우고 검증한 후, 신용도가 하한선보다 높은지가 확인된 이후에 대출 견적 화면으로 진행되어야 한다는 식으로 은행에서 업무 요건을 기술했다고 해보자.
바로 이것이 유스케이스이다. 유스케이스는 자동화된 시스템이 사용되는 방법을 설명한다.
유스케이스는 사용자가 제공해야 하는 입력, 사용자에게 보여줄 출력, 그리고 해당 출력을 생성하기 위한 처리 단계를 기술한다. 엔티티 내의 핵심 업무 규칙과는 반대로 유스케이스는 애플리케이션에 특화된(application-specific) 업무 규칙을 설명한다.
다음 그림은 위 유스케이스의 예다.

마지막 줄에 Customer를 언급하고 있는데, 이는 Customer 엔티티에 대한 참조이고, 은행과 고객의 관계를 결정짓는 핵심 업무 규칙은 바로 이 Customer 엔티티에 포함된다. 유스케이스는 엔티티 내부의 핵심 업무 규칙을 어떻게, 그리고 언제 호출할지를 명시하는 규칙을 담는다. 엔티티가 어떻게 춤을 출지를 유스케이스가 제어하는 것이다.
주목할 또 다른 사실은 인터페이스로 들어오는 데이터와 인터페이스에서 되돌려주는 데이터를 형식 없이 명시한다는 점만 빼면, 유스케이스는 사용자 인터페이스를 기술하지 않는다는 점이다.
유스케이스만 봐서는 이 애플리케이션이 웹을 통해 전달되는지, 리치 클라이언트인지, 콘솔 기반인지, 아니면 순수한 서비스인지 구분하기는 불가능하다.
이 부분은 매우 중요한데, 유스케이스는 시스템이 사용자에게 어떻게 보이는지는 설명하지 않는다. 이보단 애플리케이션에 특화된 규칙을 설명하며, 이를 통해 사용자와 엔티티 사이의 상호작용을 규정한다. 시스템에서 데이터가 들어오고 나가는 방식은 유스케이스와 무관하다.
유스케이스는 객체이고, 애플리케이션에 특화된 업무 규칙을 구현하는 하나 이상의 함수를 제공한다. 또한 유스케이스는 입력 데이터, 출력 데이터, 유스케이스가 상호작용하는 엔티티에 대한 참조 데이터 등의 데이터 요소를 포함한다.
엔티티는 자신을 제어하는 유스케이스에 대해 아무것도 알지 못한다. 이는 의존성 역전 원칙을 준수하는 의존성 방향에 대한 또 다른 예다. 엔티티와 같은 고수준 개념은 유스케이스와 같은 저수준 개념에 대해 아무것도 알지 못한다. 반대로 저수준인 유스케이스는 고수준인 엔티티에 대해 알고 있다.
어째서 엔티티는 고수준이고, 유스케이스는 저수준일까? 그 이유는 유스케이스는 단일 애플리케이션에 특화되어 있으며, 따라서 해당 시스템에 입/출력에 가깝게 위치하기 때문이다.
엔티티는 수 많은 다양한 애플리케이션에서 사용될 수 있도록 일반화된 것이기에, 각 시스템의 입/출력과는 더 멀리 떨어져 있다. 그래서 유스케이슨느 엔티티에 의존하지만, 엔티티는 유스케이스에 의존하지 않는다.
요청 및 응답 모델
유스케이스는 입력 데이터를 받아 출력 데이터를 생성한다.
여기서 제대로된 유스케이스 객체라면, 데이터를 사용자 혹은 또 다른 컴포넌트와 통신하는 방식에 대해 눈치챌 수 없어야 한다. 유스케이스의 코드가 HTML이나 SQL에 대해 알 필요도 없고 알아서도 안된다.
유스케이스는 단순한 요청 데이터 구조를 입력으로 받아들이고, 단순한 응답 데이터 구조를 출력으로 반환한다. 이들 데이터 구조는 어떤 것에도 의존하지 않는다. HttpRequest나 HttpResponse같은 표준 프레임워크 인터페이스로부터 파생되지도 않는다. 마찮가지로 웹에 대해서도 알지 못한다.
최종적으로 웹 뿐 아니라 그 어떤 사용자 인터페이스에도 종속되는게 없다.
이처럼 요청 및 응답 모델이 독립적이지 않다면 그 모델에 의존하는 유스케이스도 결국 해당 모델이 수반하는 의존성에 간접적으로 결합되어 버린다.
엔티티 객체를 가리키는 참조를 요청 및 응답 데이터 구조에 포함하려는 유혹을 받을 수도 있다. 엔티티와 요청/응답 모델은 상당히 많은 데이터를 공유하기에 이런 방식이 적합해 보일 수도 있다.
하지만 이 유혹을 떨쳐내야 한다. 두 객체의 목적은 완전히 다르다. 시간이 지날수록 두 객체는 각기 다른 이유로 서로 변경될 것이고 두 객체를 어떤 식으로든 함께 묶는 행위는 공통 폐쇄 원칙과 단일 책임 원칙을 위배하게 된다. 결국 코드에는 수많은 떠돌이 데이터가 만들어지고 수많은 조건문이 추가되어 버린다.
결론
•
업무 규칙은 소프트웨어 시스템이 존재하는 이유로 핵심적인 기능이다.
•
업무 규칙은 수익을 내고 비용을 줄이는 코드를 수반한다.
•
사용자 인터페이스나 데이터베이스와 같은 저수준의 관심사로 인해 오염되어서는 안되고 원래 그대로의 모습으로 남아있어야 한다.
•
업무 규칙을 표현하는 코드는 반드시 시스템의 심장부에 위치해야 하고, 덜 중요한 코드는 이 심장부에 플러그인되야 한다.
•
업무 규칙은 시스템에서 가장 독립적이고 재사용성이 높은 코드여야 한다.
소리치는 아키텍처
우리가 만든(혹은 만들) 애플리케이션 아키텍처를 살펴보았을때 상위 수준의 디렉터리 구조, 최상위 패키지에 담긴 소스파일을 볼 때 이 아키텍처는 “커피 재고 관리 시스템이야!” 라고 파악할지 아니면 “재고 관리 시스템이야!” 라고할지 그것도 아니면 “스프링/하이버네이트야!” 혹은 기타 등등 무엇이야! 라고 할까?
아키텍처의 목적
좋은 아키텍처는 유스케이스를 중심에 두기 때문에 프레임워크나 도구 환경에 구애받아서는 안된다.
주택에 대한 계획서를 예로 생각해보면, 아키텍트는 우선적으로 주택이 거주하기 적합한 공간인지를 우선 충족시키고 그 다음 외장재(벽돌,석조,향나무등)를 소유주가 결정한다.
즉, 좋은 소프트웨어 아키텍처는 프레임워크, 데이터베이스, 웹 서버와 같은 기타 개발 환경 문제나 도구에 대해서는 결정을 미룰 수 있도록 만든다.
좋은 아키텍처는 유스케이스에 중점을 두고 지엽적인 관심사에 대한 결합을 분리시킨다.
웹
웹은 아키텍처일까? 시스템이 웹을 통해 전달된다는 사실이 시스템의 아키텍처에 영향을 줄까?
물론, 아니다. 웹은 전달 메커니즘이고 애플리케이션 아키텍처에서도 그와 같이 다뤄야 한다.
애플리케이션이 웹을 통해 전달된다는 사실은 세부사항이고 시스템 구조를 지배해서는 안된다. 실제 애플리케이션을 웹으로 전달할지 여부는 미루어야 할 결정사항 중 하나이다.
시스템 아키텍처는 시스템이 어떻게 전달될지에 대해서 가능하면 모르는게 맞다. 큰 부작용이 없이 근본적인 아키텍처를 고치지 않고서도 시스템은 콘솔 앱,웹 앱, 리치 클라이언트 앱, 웹서비스 앱으로 전달할 수 있어야 한다.
프레임워크는 도구일 뿐이다.
프레임워크는 강력하고 유용하다. 하지만, 신봉해서는 안된다. 눈이 아플정도로 면밀하게 프레임워크를 살펴보고 비판적으로 보자. 프레임워크는 도움이 되지만 비용이 얼마나 드는지 고민해보고 프레임워크를 어떻게 사용할지, 그리고 프레임워크를 사용하지 않으려면 어떻게 해야할지 고민할 필요가 있다. 그렇게 해서 아키텍처를 유스케이스 중점으로 두고 보존할 수 있을지를 고민할 수 있다.
프레임워크가 아키텍처의 중심을 차지하는 일을 막을 수 있도록 전략을 개발하자.
테스트하기 쉬운 아키텍처
아키텍처가 유스케이스를 최우선으로 한다면, 그리고 프레임워크와 적절한 거리를 둔다면, 프레임워크를 준비하지 않고도 유스케이스 전부에 대해 단위테스트를 할 수 있어야 한다.
테스트를 돌리는데 있어 웹 서비스가 반드시 필요한 상황이 오지 않도록 해야한다.
데이터베이스도 반드시 연결되어 있어야만 테스트를 돌릴수 있어서도 안된다.
엔티티 객체는 반드시 오래된 방식의 간단한 객체(plain old object)여야 하고, 프레임워크나 데이터베이스, 또는 여타 복잡한 것들에 의존해서는 안 된다.
유스케이스 객체가 엔티티 객체를 조작해야 한다. 최종적으로 프레임워크로 인한 어려움을 겪지 않고도 반드시 이 모두를 있는 그대로 테스트할 수 있어야 한다.
결론
아키텍처 시스템을 이야기해야 하며, 시스템에 적용한 프레임워크에 대해 이야기해선 안된다.
우리가 헬스 케어 시스템을 구축하고 있다면, 새로 투입된 개발자는 소스 저장소를 헬스 케어 시스템이군! 이라고 첫 인상을 가져야 한다. 즉 시스템이 어떻게 전달될지 모르는 상태에서도 시스템의 모든 유스케이스를 이해할 수 있어야 한다.
클린 아키텍처
지난 수십년간 시스템 아키텍처 관련해서 여러 아이디어를 봐왔다.
•
헥사고날 아키텍처(Hexagonal Architecture)
◦
포트와 어댑터(Ports and Adapters)라고도 알려졌다.
•
DCI(Data, Context and Interaction)
•
BCE(Boundary-Control-Entity)
이 아키텍처들은 모두 세부적인 면에서는 차이가 있더라도 내용은 비슷하다.
목표는 모두 동일하게 관심사의 분리(separation of concerns)다. 모두 소프트웨어를 계층으로 분리함으로써 관심사의 분리라는 목표를 달성할 수 있었는데, 각 아키텍처는 최소한 업무 규칙을 위한 계층하나와, 사용자와 시스템 인터페이스를 위한 또 다른 계층 하나를 반드시 포함한다.
그리고 이 아키텍처는 모두 시스템이 다음과 같은 특징을 지니도록 만든다.
•
프레임워크 독립성.
◦
프레임워크 존재 여부에 의존하지 않는다. 그래서 프레임워크 선택의 유연성을 제공하고, 프레임워크가 지닌 제약사항이 시스템에 들어가도록 강제하지 않는다.
•
테스트 용이성
◦
업무 규칙은 UI, 데이터베이스, 웹 서버, 또는 기타 외부 요소가 없어도 테스트할 수 있다.
•
UI 독립성
◦
시스템의 나머지 부분을 변경하지 않고도 UI를 쉽게 변경할 수 있다.
•
데이터베이스 독립성
◦
오라클, MS SQL, MYSql, 몽고DB, 빅테이블, 카우치등으로 교체가능하다. 업무 규칙은 데이터베이스에 결합되지 않는다.
•
모든 외부 에이전시에 대한 독립성
◦
업무 규칙은 외부 세계와의 인터페이스에 대해 전혀 알지 못한다.
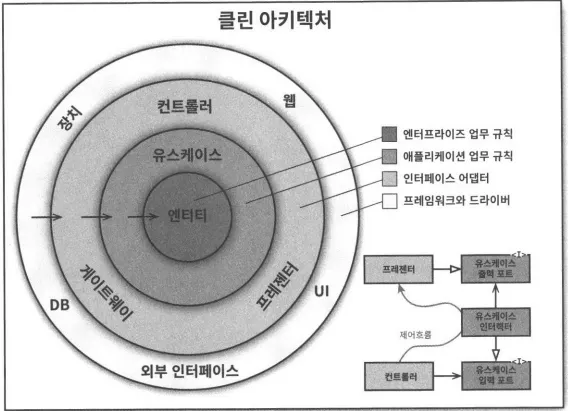
클린 아키텍처
위 다이어그램은 이런 아키텍처 전부를 실행 가능한 하나의 아이디어로 통합하려는 시도로 볼 수 있다.
의존성 규칙
위 동심원은 소프트웨어에서 서로 다른 영역을 표현하는데 안으로 들어갈수록 고수준의 소프트웨어가 된다. 바깥쪽 원은 메커니즘이고, 안쪽 원은 정책이다. 이러한 아키텍처가 동작할 수 있도록 하는 가장 중요한 규칙은 의존성 규칙(Dependency Rule) 이다.
소스 코드 의존성은 반드시 안쪽으로, 고수준의 정책을 향해야 한다.
내부의 원에 속한 요소는 외부의 원에 속한 어떤 것도 알지 못한다. 특히 내부의 원에 속한 코드는 외부에 선언된 어떤 것에 대해서도 그 이름을 언급해서는 안된다. 여기에는 함수, 클래스, 변수, 그리고 소프트웨어 엔티티로 명명되는 모든 것이 포함된다.
같은 이유로, 외부의 원에 선언된 데이터 형식도 내부의 원에서 절대로 사용해서는 안된다. 특히 그 데이터 형식이 외부의 원에 있는 프레임워크가 생성한 것이라면 더더욱 사용해서는 안된다. 우리는 외부 원에 위치한 어떤 것도 내부의 원에 영향을 주지 않기를 바란다.
엔티티
엔티티는 전사적인 핵심 업무 규칙을 캡슐화한다.
엔티티는 메서드를 가지는 객체이거나 일련의 데이터 구조와 함수의 집합일 수도 있다. 기업의 다양한 애플리케이션에서 엔티티를 재사용할 수만 있다면, 그 형태는 그다지 중요하지 않다.
전사적이지 않은 단순한 단일 애플리케이션에서는 엔티티는 해당 애플리케이션의 업무 객체가 되는데, 이 경우 엔티티는 가장 일반적이고 고수준인 규칙을 캡슐화 한다.
외부의 무언가가 변경되더라도 엔티티가 변경될 가능성은 지극히 낮다. 예를 들어 페이지 네비게이션이나 보안과 관련된 변경이 발생하더라도 업무 객체가 영향을 받지는 않을 것이다.
운영 관점에서 특정 애플리케이션에 무언가 변경이 필요하더라도 엔티티 계층에는 절대로 영향을 주어서는 안된다.
유스케이스
유스케이스 계층의 소프트웨어는 애플리케이션에 특화된 업무 규칙을 포함한다. 또한 유스케이스 계층의 소프트웨어는 시스템의 모든 유스케이스를 캡슐화하고 구현한다. 유스케이스는 엔티티로 들어오고 나가는 데이터 흐름을 조정하며, 엔티티가 자신의 핵심 업무 규칙을 사용해 유스케이스의 목적을 달성하도록 이끈다. 이 계층에서 발생한 변경이 엔티티에 영향을 줘서는 안되며, 데이터베이스, UI, 또는 여타 공통 프레임워크와 같은 외부 요소에서 발생한 변경이 계층에 영향을 줘서도 안된다. 유스케이스 게층은 이러한 관심사로부터 격리되어 있다.
하지만 운영 관점에서 애플리케이션이 변경된다면 유스케이스가 영향을 받으며, 따라서 이 계층의 소프트웨어에도 영향을 줄 것이다. 유스케이스의 세부사항이 변하면 이 계층의 코드 일부는 분명 영향을 받을 것이다.
인터페이스 어댑터(Interface Adaptor)
이 계층은 일련의 어댑터들로 구성된다.
어댑터는 데이터를 유스케이스와 엔티티에게 가장 편리한 형식에서 데이터베이스나 웹 같은 외부 에이전시에게 가장 편리한 형식으로 변화한다. 이 계층은, 예를 들어 GUI의 MVC 아키텍처를 모두 포괄한다. 프레젠터(Presenter), 뷰(View), 컨트롤러(Controller)는 모두 인터페이스 어댑터 계층에 속한다. 모델은 그저 데이터 구조 정도에 지나지 않으며, 컨트롤러에서 유스케이스로 전달되고 다시 유스케이스에서 프레젠터와 뷰로 되돌아 간다.
마찬가지로 이 계층은 데이터를 엔티티와 유스케이스에게 가장 편리한 형식에서 영속성용으로 사용 중인 임의의 프레임워크가 이용하기 편리한 형식으로 변환한다. 이 원 안에 속한 어떤 코드도 데이터베이스에 대해 조금도 알아선 안된다. 예컨데 SQL 기반의 데이터베이스를 사용한다면 모든 SQL은 이 계층을 벗어나선 안된다. 특히 이계층에서도 데이터베이스를 담당하는 부분으로 제한되어야 한다. 또한 이 계층에는 데이터를 외부 서비스와 같은 외부적인 형식에서 유스케이스나 엔티티에서 사용되는 내부적인 형식으로 변환하는 또 다른 어댑터가 필요하다.
프레임워크와 드라이버
가장 바깥족 계층은 일반적으로 데이터베이스나 웹 프레임워크 같은 프레임워크나 도구들로 구성되는데, 이 계층에선 안쪽 원과 통신하기 위한 접합 코드 외에는 특별히 더 작성해야 할 코드가 그다지 많지 않다. 프레임워크와 드라이버 계층은 모든 세부사항이 위치하는 곳으로 웹, 데이터베이스 모두 세부사항이다. 우리는 이러한 것들을 모두 외부에 위치시켜 피해를 최소화한다.
원은 네개여야만 하는가?
위의 동심원은 그저 개념을 설명하기 위한 예시로 더 많은 원이 필요할 수도 있다.
중요한점은 어떤 경우에도 의존성 규칙은 적용된다는 것으로 소스 코드 의존성은 항상 안쪽을 향해야 한다. 안쪽으로 이동할수록 추상화와 정책의 수준은 높아진다. 따라서 가장 안쪽 원은 가장 범용적이고 높은 수준을 가진다.
경계 횡단하기
동심원 그림 우측 하단 다이어그램에 원의 경계를 횡단하는 방법을 보여주는 예시가 있다.
여기서 컨트롤러와 프레젠터가 다음 계층에 속한 유스케이스와 통신하는 모습을 확인할 수 있다.
우선 제어흐름을 주목해보면 컨트롤러에서 시작해 유스케이스를 지난 후 프레젠터에서 실행되면서 마무리된다. 다음 소스 코드 의존성도 살펴보면 각 의존성은 유스케이스를 향해 안쪽을 가리킨다.
이처럼 제어흐름과 의존성 방향이 반대인 경우, DIP를 이용해 해결할 수 있다.
자바같은 경우 인터페이스와 상속 관계를 적절히 배치함으로써, 제어흐름이 경계를 가로지르는 바로 그 지점에서 소스 코드 의존성을 제어흐름과 반대로 만들 수 있다.
예를 들어 유스케이스에서 프레젠터를 호출해야 한다고 가정하면, 이 때 직접 호출해선 안되는데, 직접 호출해버리면 내부의 원에서 외부 원에 있는 어떤 이름도 언급해선 안된다는 의존성 규칙을 위배하기 때문이다. 따라서 우린 유스케이스가 내부 원의 인터페이스를 호출하도록 하고, 외부 원의 프레젠터가 그 인터페이스를 구현하도록 만든다.
아키텍처 경계를 횡단할 때 언제라도 동일한 기법을 사용할 수 있다. 우리는 동적 다형성을 이용해 소스 코드 의존성을 제어흐름과 반대로 만들 수 있고, 이를 통해 제어흐름이 어느 방향으로 흐르더라도 의존성 규칙을 준수할 수 있다.
경계를 횡단하는 데이터는 어떤 모습인가?
경계를 가로지르는 데이터는 흔히 간단한 데이터 구조로 이루어져 있다.
기본적인 구조체나 간단한 데이터 전송 객체(Data Transfer Object)등 원하는 대로 고를 수 있다. 또는 함수를 호출할 때 간단한 인자를 사용해 데이터로 전달할 수도 있다. 그게 아니라면 데이터를 해시맵으로 묶거나 객체로 구성할 수도 있다. 중요한 점은 격리되어 있는 간단한 데이터 구조가 경계를 가로질러 전달된다는 사실이다. 꾀를 부려 엔티티 객체나 데이터베이스의 행(Row)을 전달하는 잃은 좋지 않다. 우리는 데이터 구조가 어떤 의존성을 가져 의존성 규칙을 위배하게 되는 일은 바라지 않는다.
따라서 경계를 가로질러 데이터를 전달할 때, 데이터는 항상 내부의 원에서 사용하기 편리한 형태를 가져야 한다.
전형적인 시나리오
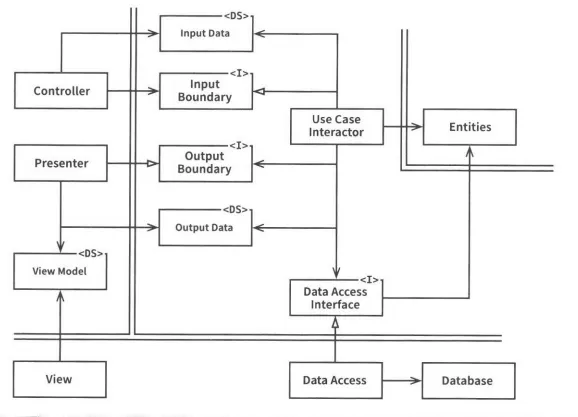
위 다이어그램은 데이터베이스를 사용하는 웹 기반 자바 시스템의 시나리오를 보여준다.
웹 서버는 입력데이터를 모아서 좌측 상단의 Controller로 전달한다. Controller는 데이터를 평범한 자바 객체(POJO)로 묶은 뒤, InputBoundary 인터페이스를 통해 UseCaseInteractor로 전달한다.
UseCaseInteractor는 이 데이터를 해석해 Entities가 어떻게 춤출지를 제어하는데 사용한다. 또한 UseCaseInteractor는 DataAccessInterface를 사용해 Entities가 사용할 데이터를 데이터베이스에서 불러와 메모리로 로드한다. Entities가 완성되면 UseCaseInteractor는 Entities로부터 데이터를 모아 다른 평범한 자바 객체인 OutputData를 구성한다. 그러고 나서 OutputData는 OutputBoundary 인터페이스를 통해 Presenter로 전달된다.
Presenter가 맡은 역할은 OutputData를 ViewModel과 같이 화면에 출력할 수 있는 형식으로 재구성하는 일이다. ViewModel 또한 평범한 자바 객체다. ViewModel은 주로 문자열과 플래그로 구성되며, View에선 이 데이터를 화면에 출력한다. OutputData에서는 Date객체를 포함할 수 있는 반면 Presenter는 ViewModel을 로드할 때 Date객체를 사용자가 보기에 적절한 형식의 문자열로 변환한다. 이 변환은 Currency 객체나 다른 업무 관련 데이터 모두에 똑같이 적용된다. Button과 MenuItem의 이름은 ViewModel에 위치하며, 해당 Button과 MenuItem을 비활성화할지를 알려주는플래그 또한 ViewModel에 위치한다.
따라서 ViewModel에서 HTML페이지로 데이터를 옮기는 일을 빼면 View에서 해야 할 일은 거의 없다. 의존성의 방향에 주목하라. 모든 의존성은 경계선을 안쪽으로 가로지르며, 따라서 의존성 규칙을 준수한다.
결론
이상의 간단한 규칙들을 준수하는 일은 어렵지 않고, 향후에 겪을 수많은 고통거리를 줄여준다.
소프트웨어를 계층으로 분리하고 의존성 규칙을 준수한다면 본질적으로 테스트하기 쉬운 시스템을 만들게 될 것이며, 그에 따른 이점을 누릴 수 있다. 데이터베이스나 웹 프레임워크와 같은 시스템의 외부 요소가 구식이 되더라도, 이들 요소를 야단스럽지 않게 교체할 수 있다.
프레젠터와 험블 객체
프레젠터는 험블 객체(Humble Object)패턴을 따른 형태로, 아키텍처 경계를 식별하고 보호하는 데 도움이 된다.
험블 객체 패턴
험블 객체 패턴은 디자인 패턴으로, 테스트하기 어려운 행위와 테스트하기 쉬운 행위를 단위 테스트 작성자가 분리하기 쉽게 하는 방법으로 고안되었다.
아이디어는 매우 단순한데, 행위들을 두 개의 모듈 또는 클래스로 나눈다. 이들 모듈 중 하나가 험블(Humble)이다. 가장 기본적인 본질은 남기고 테스트하기 어려운 행위를 모두 험블 객체로 옮긴다.
나머지 모듈에는 험블 객체에 속하지 않은, 테스트하기 쉬운 행위를 모두 옮긴다.
예를 들어 GUI의 경우 단위 테스트가 어려운데, 화면을 보면서 각 요소가 필요한 위치에 적절히 표시되었는지 검사하는 테스트는 매우 작성하기 어렵기 때문이다.
하지만 GUI에서 수행하는 행위의 대다수는 쉽게 테스트가 가능하다. 험블 객체 패턴을 사용해 두 부류의 행위를 분리해 프레젠터와 뷰라는 서로 다른 클래스로 만들 수 있다.
프레젠터와 뷰
뷰는 험블 객체이고 테스트가 어렵다. 이 객체에 포함된 코드는 가능한 간단하게 유지한다.
뷰는 데이터를 GUI로 이동시키지만, 데이터를 직접 처리하지는 않는다.
프레젠터는 테스트하기 쉬운 객체다. 프레젠터의 역할은 애플리케이션으로부터 데이터를 받아 화면에 표현할 수 있는 포맷으로 만드는 것이다. 이를 통해 뷰는 데이터를 화면으로 전달하는 간단한 일만 처리하도록 만든다.
예를 들어 애플리케이션에서 어떤 필드에 날짜를 표시하고자 한다면, 애플리케이션은 프레젠터에 Date객체를 전달한다. 그러면 프레젠터는 해당 데이터를 적절한 포맷의 문자열로 만들고, 이 문자열을 뷰 모델(View Model)이라고 부르는 간단한 데이터 구조에 담는다. 그러면 뷰는 뷰 모델에서 이 데이터를 찾는다. 만약 애플리케이션에서 화면에 금액을 표시하고자 한다면, 애플리케이션은 프레젠터에 Currency 객체를 전달한다.
프레젠터는 해당 객체를 소수점과 통화 표시가 된 포맷으로 적절히 변환해 문자열을 생성한 후 뷰 모델에 저장한다. 만약 금액이 음수일 때 빨간색으로 변해야 한다면, 간단히 불(Boolean)타입 플래그를 뷰 모델에 두고 적절한 값으로 설정한다.
화면에 보이는 버튼은 모두 이름이 있을 것인데, 그 이름은 뷰 모델 내부에서 문자열로 존재하며, 프레젠터에 의해 뷰 모델에 위치하게 된다. 특정 버튼을 비활성해야 한다면, 프레젠터는 뷰 모델에서 적절한 불 타입 플래그를 설정한다. 메뉴 아이템 이름은 모두 뷰 모델에서 문자열로 존재하고, 그 값은 프레젠터가 로드한다. 모든 라디오 버튼, 체크 박스, 텍스트 필드의 이름 또한 프레젠터가 적절한 문자열과 불 타입 플래그로 뷰 모델에 설정한다.
수치를 담은 테이블을 화면에 표시해야 한다면, 프레젠터는 적절한 형식의 문자열이 테이블 형태를 가지도록 뷰 모델에 로드한다.
화면에 표시되고 애플리케이션에서 어느 정도 제어할 수 있는 요소라면 무조건 뷰 모델 내부에 문자열, 불(boolean)또는 열거형(enum)형태로 표현한다.
뷰는 뷰 모델의 데이터를 화면으로 로드할 뿐이며, 이 외에 뷰가 맡은 역할은 없다. 그렇기에 뷰는 보잘것 없다.(humble)
테스트와 아키텍처
테스트 용이성은 아키텍처가 지녀야 할 속성으로 오랫동안 알려져 왔다.
험블 객체 패턴이 좋은 예인데, 행위를 테스트하기 쉬운 부분과 테스트하기 어려운 부분으로 분리해 아키텍처 경계가 정의되기 때문이다. 프레젠터와 뷰 사이의 경계는 이러한 경계 중 하나이며, 이 밖에도 수 많은 경계가 존재한다.
데이터베이스 게이트웨이
유스케이스 인터랙터와 데이터베이스 사이에는 데이터베이스 게이트웨이가 위치한다.
이 게이트웨이는 다형적 인터페이스로, 애플리케이션이 데이터베이스에 수행하는 생성, 조회, 갱신, 삭제 작업과 관련된 모든 메서드를 포함한다. 예를 들어 애플리케이션에서 어제 로그인한 모든 사용자의 성을 알 수 있어야 한다면, UserGateway 인터페이스는 getLastNamesOfUsersWhoLoggedInAfter라는 메서드를 제공할 것이고, 이 메서드는 날짜를 인자로 받아 사용자 성들을 담은 목록을 반환할 것이다.
위에서도 얘기했지만 유스페이스 계층은 SQL을 허용하지 않기에 필요한 메서드를 제공하는 게이트웨이 인터페이스를 호출한다. 그리고 인터페이스의 구현체는 데이터베이스 계층에 위치한다. 이 구현체는 험블 객체다. 구현체에서 직접 SQL을 사용하거나 데이터베이스에 대한 임의의 인터페이스를 통해 게이트웨이의 메서드에서 필요한 데이터에 접근한다. 이와 달리 인터랙터는 애플리케이션에 특화된 업무 규칙을 캡슐화하기 때문에 험블 객체가 아니다. 따라서 테스트하기 쉬운데, 게이트웨이는 스텁(Stub)이나 테스트 더블(test-double)로 적당히 교체할 수 있기 때문이다.
데이터 매퍼
주제를 데이터베이스로 돌려서 하이버네이트 같은 ORM은 어느 계층일까?
객체 관계 매퍼(Object Relational Mapper, ORM)같은건 사실 없다. 어째서일까? 객체는 데이터 구조가 아니기 때문이다. 최소한 객체를 사용하는 사람 관점에서 객체는 데이터 구조가 아니다. 데이터는 모두 private로 선언되기에 객체의 사용자는 데이터를 볼 수 없다. 사용자는 객체에서 public 메서드만 볼 수 있다.
따라서 사용자 관점에서 볼 때 객체는 단순히 오퍼레이션의 집합이다.
객체와 달리 데이터 구조는 함축된 행위를 가지지 않는 public 데이터 변수의 집합이다. ORM보단 차라리 데이터 매퍼(Data Mapper)라 부르는게 나아보이는데, 관계형 데이터베이스 테이블로부터 가져온 데이터를 데이터 구조에 맞기 담아주기 때문이다.
이러한 ORM 시스템은 어디에 위치해야 할까? 물론 데이터 베이스 계층이다. 실제로 ORM은 게이트웨이 인터페이스와 데이터베이스 사이에서 일종의 또 다른 험블 객체 경계를 형성한다.
서비스 리스너
애플리케이션이 다른 서비스와 통신해야 한다면, 또는 애플리케이션에서 일련의 서비스를 제공해야 한다면, 우리는 여기서 서비스 경계를 생성하는 험블 객체 패턴을 찾을 수 있을까?
물론 가능하다. 애플리케이션은 데이터를 간단한 데이터 구조 형태로 로드한 뒤, 이 데이터 구조를 경계를 가로질러 특정 모듈로 전달한다. 그럼 해당 모듈은 데이터를 적절한 포맷으로 만들어 외부 서비스로 전송한다. 반대로 외부로부터 데이터를 수신하는 서비스의 경우, 서비스 리스너(service listener)가 서비스 인터페이스로부터 데이터를 수샌하고, 데이터를 애플리케이션에서 사용할 수 있게 간단한 데이터 구조로 포맷을 변경한다. 그런 후 이 데이터 구조는 서비스 경계를 가로질러 내부로 전달된다.
결론
각 아키텍처 경계마다 경계 가까이 숨어 있는 험블 객체 패턴을 발견할 수 있었다.
경계를 넘나드는 통신은 모두 간단한 데이터 구조를 수반할 떄가 많고, 그 경계는 테스트하기 어려운 무언가와 테스트하기 쉬운 무언가로 분리될 것이다. 그리고 이러한 아키텍처 경계에서 험블 객체 패턴을 사용하면 전체 시스템의 테스트 용이성을 크게 높일 수 있다.
부분적 경계
완벽한 아키텍처 경계를 만드는 것은 매우 힘들고 많은 비용이 든다.
쌍방향의 다형적 Boundary 인터페이스, Input과 Output을 위한 데이터 구조를 만들어야 할 뿐 아니라, 두 영역을 독립적으로 컴파일하고 배포할 수 있는 컴포넌트로 격리하는 데 필요한 모든 의존성을 관리해야 한다. 이렇게 만드는것도 그렇지만 유지하는데도 많은 노력이 필욯다.
그렇기에 많은 경우에, 뛰어난 아키텍트는 이러한 경계를 만드는 비용이 크다고 판단하면서도, 한편으로는 나중에는 필요할 수도 있으니 이러한 경계에 필요한 공간을 확보하길 원할 수도 있다.
하지만 이런 선행적인 설계는 당장 필요하지 않은 작업을 해야하기에 YAGNI원칙을 위배하기에 탐탁치 않아하는 사람들이 많다.
그렇기에 부분적 경계(partial boundary)를 생각해볼 수 있다.
마지막 단계 건너뛰기
부분적 경계(partial boundary)를 생성하는 방법 하나는 독립적으로 컴파일 후 배포할 수 있는 컴포넌트를 만들기 위한 작업은 모두 수행한 후, 단일 컴포넌트에 그대로 모아만 두는 것이다. 쌍방향 인터페이스도 그 컴포넌트에 있고, 입/출력 데이터 구조도 거기에 있고, 모든 것이 완전히 준비되어 있다. 하지만 이 모두를 단일 컴포넌트로 컴파일해서 배포한다. 아무리봐도 이처럼 부분적 경계를 만들기 위해선 완벽한 경계를 만들 때 만큼의 코드량과 사전 설계가 필요하다. 하지만 다수의 컴포넌트를 관리하는 작업은 하지 않아도 된다.
즉, 추적을 위한 버전 번호, 배포 관리부담도 없다. 이러한 차별점은 결코 가볍지 않다.
이러한 접근법은 위험 요소 역시 존재하는데 시간이 흐르면서, 분리하 컴포넌트가 재사용될 가능성이 없다는 점이 명백해지고, 컴포넌트 사이의 구분이 약화되기 시작할 때 의존성이 잘못된 방향으로 선을 넘을 수 있다. 그럼 다시 이 둘을 분리하는 작업은 지루한 작업이 될 것이다.
일차원 경계
완벽한 형태의 아키텍처 경계는 양방향으로 격리된 상태를 유지해야 하기에 쌍방향 Boundary 인터페이스를 사용한다. 양방향으로 격리된 상태를 유지하기 위해서는 초기 설정뿐 아니라 지속적인 유지 비용도 크다. 추후 완벽한 형태의 경계로 확장할 수 있는 공간을 확보하기 위해 활용가능한 더 간단한 구조가 있다.

전략 패턴
위 그림은 전략 패턴을 나타내고 있는데 ServiceBoundary 인터페이스는 클라이언트가 사용하며 ServiceImpl 클래스가 구현한다. 이 방식이 미래에 필요할 아키텍처 경계를 위한 무대를 마련한다는 점은 명백하다. Client를 ServiceImpl로부터 격리시키는데 필요한 의존성 역전이 이미 적용되었기 때문이다. 또한 이 다이어그램의 위험천만한 점선 화살표에서 보듯이 이러한 분리는 매우 빠르게 붕괴될 수 있다는 점 역시 분명하다. 쌍방향 인터페이스가 없고 개발자와 아키텍트가 근명 성실하고 제대로 훈련되어 있지 않다면, 이 점선과 같은 비밀 통로가 생기는 일을 막을 방법이 없다.
퍼
퍼사드
이보다 더 단순한 경계는 퍼사드 패턴(Facade Pattern)으로 다음과 같다.
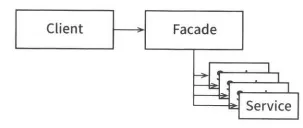
퍼사드 패턴
이 경우엔 의존성 역전도 희생한다. 경계는 Facade 클래스로만 간단히 정의된다. Facade 클래스에선 모든 서비스 클래스를 메서드 형태로 정의하고, 서비스 호출이 발생하면 해당 서비스 클래스로 호출을 전달한다. 클라이언트는 이들 서비스 클래스에 직접 접근할 수 없다.
하지만, Client가 이 모든 서비스 클래스에 대해 추이 종속성을 가진 것을 주목하자.
정적 언어였다면 서비스 클래스 중 하나에서 소스코드가 변경되면 Client도 무조건 재컴파일해야 한다. 이러한 구조에선 비밀 통로를 만들기도 쉽다.
결론
아키텍처 경계를 부분적으로 구현하는 간단한 세 가지 방법을 살펴봤다.
물론 이 외에도 방법은 많고, 세 전략은 순전히 예제로써 제시되었다.
각각의 접근법은 서로 각자 장단점을 가지는데, 적절하게 사용될 수 있는 상황이 서로 다르고 해당 경계가 실제로 구체화되지 않으면 가치가 떨어질 수 있다. 아키텍처 경계가 언제, 어디에 존재해야 할지, 그리고 그 경계를 완벽하게 구현할지 아니면 부분적으로 구현할지를 결정하는 일 또한 아키텍트의 역할이다.
계층과 경계
시스템이 세 가지 컴포넌트(UI, 업무 규칙, 데이터베이스)로만 구성된다고 생각하기 쉽다.
단순한 구조에서는 충분하지만, 대다수의 시스템에서 컴포넌트는 이보다 훨씬 많은 수가 존재한다.
간단한 컴퓨터게임을 예로 들어 생각해보자.
기본적인 게임의 컴포넌트 구성은 UI, 업무 규칙, 데이터베이스 세 가지로, 구성하는 모습을 상상하기 쉬울 것이다. UI에서 유저가 입력한 메세지를 게임 규칙으로전달하고, 게임 규칙은 게임의 상태를 영속성을 가지는 데이터 구조로 저장하면 된다.
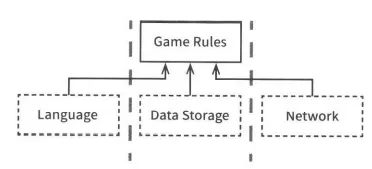
그런데, 여기서 게임이 텍스트 기반으로 UI 입력을 받는다고 할 때 다국어 지원이 되야한다면, 다음과 같은 구조가 될 것이다.
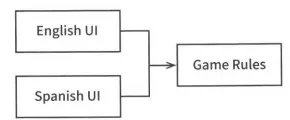
UI컴포넌트가 어떤 언어를 사용해도 게임 규칙을 재사용할 수 있다.
위와 같은 구조로 소스 코드 의존성을 관리하면 UI가 어떤 언어를 사용하던 게임 규칙을 재사용할 수 있다. 다음으로 게임의 상태를 저장소에 유지한다고 할 때 이 저장소가 무엇인지 역시 선택의 폭이 플래시 메모리, 클라우드, RAM등 여러가지가 될 수 있다. 이 경우에도 게임 규칙(업무 규칙)이 이런 세부사항을 알 필요는 없다. 그렇기에 이번에도 API를 만들어 게임 규칙이 데이터 저장소 컴포넌트와 통신하도록 한단.
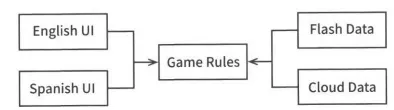
의존성 규칙 준수
물론 이 때 의존성이 적절한 방향으로 흐르도록 만들어야 한다.
여기서 끝이 아니다, 예를들어 UI에서 언어뿐 아니라 텍스트를 주고받는 메커니즘도 다양해질 수 있다. 따라서 이 변경의 축에 의해 정의되는 아키텍처 경계가 잠재되어 있을 수 있다. 위에서 얘기했던 언어나, 게임 정보 저장, 그리고 텍스트 전달에 대해 추상컴포넌트를 가지도록 하면 다음과 같은 모습이 된다.
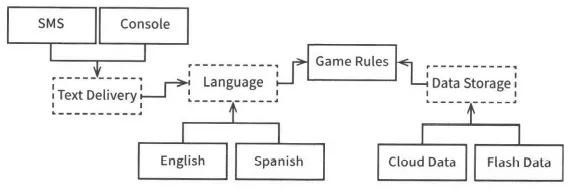
개선된 다이어그램
뭔가 많이 복잡해진 것 같지만, 사실 크게 다른건 없다. 점선으로 테두리가 그려진 박스는 API를 정의하는 추상 컴포넌트이고, 해당 API는 추상 컴포넌트 위(혹은 아래)에 컴포넌트가 구현한다. 예를 들어 Language API는 English와 Spanish가 구현한다.
API는 구현하는 쪽이 아닌 사용하는 쪽에 정의되고 소속된다.
GameRules를 살펴보면 내부 코드에서 사용하고 Language내부 코드에서 구현하는 다형적 Boundary 인터페이스를 발견할 수 있고, Language에서 사용하고 GameRules 내부 코드에서 구현하는 다형적 Boundary 인터페이스도 발견할 수 있다. 이 모든 경우에 해당 Boundary 인터페이스가 정의하는API는 의존성 흐름의 상위에 위치한 컴포넌트에 속한다.
English, SMS, CloudData와 같은 구현체들은 추상 API 컴포넌트가 정의하는 다형적 인터페이스를 통해 제공되고, 실제로 서비스하는 구체 컴포넌트가 해당 인터페이스를 구현한다.
이러한 구현체들을 모두 제거한 뒤 API 컴포넌트에만 집중하면 다음과 같이 다이어그램을 단순화할 수 있다.
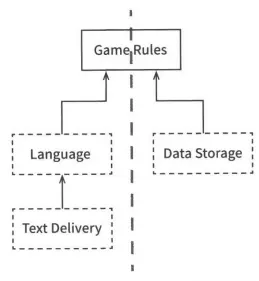
단순화된 다이어그램
다이어그램을 보면 모든 화살표는 위를 향하도록 맞춰졌다. 그 결과 GameRules는 최상위에 놓이는데, 이는 최상위 수준의 정책을 컴포넌트가 맞기에 적절하다.
정보의 흐름을 보면 모든 입력은 사용자로부터 전달받아 좌측 하단 TestDelivery컴포넌트로 전달된다. 이 정보는 Language 컴포넌트를 거쳐 GameRules에 적합한 명령어로 번역된다. GameRules는 사용자 입력을 처리하고, 우측하단의 DataStorage로 적절한 데이터를 내려보낸다. 그 뒤 GameRules는 Language로 출력을 되돌려 보내고 Language는 API를 다시 적절한 언어로 번역하여 TextDelivery를 통해 사용자에게 전달한다. 이 구성은 데이터흐름을 두 개의 흐름으로 분리하는데, 왼쪽의 흐름은 사용자와의 통신에 관여하며, 오른쪽의 흐름은 데이터 영속성에 관여한다.
두 흐름은 상단 GameRules에서 만나고, GameRules는 두 흐름이 모두 거치게 되는 데이터에 대한 최종적인 처리기가 된다.
흐름 횡단하기
하지만 이러한 데이터 흐름은 항상 두 가지일까?
만약 컴퓨터 게임이 싱글 모드가 아닌 네트워크 모드가 추가되어 여러명이 같이 즐길 수 있어야 한다면 어떨까? 그렇다면 다음과 같이 네트워크 컴포넌트가 추가되야 하고, 자연스럽게 데이터 흐름은 두 개가 아닌 세 개의 흐름으로 분리된다.
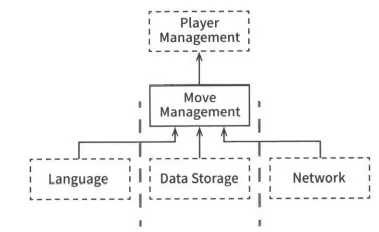
Network 컴포넌트 추가
시스템이 복잡해질수록 컴포넌트 구조는 더 많은 흐름으로 분리될 것이다.
흐름 분리하기
여기까지만 보면 모든 흐름이 결국 상단의 단일 컴포넌트에서 만난다고 생각할 수 있지만, 현실은 그렇지 않다. 계속해서 컴퓨터 게임을 예로 들어보자. GameRules 컴포넌트는 여러 게임 규칙들을 가지고 있는데, 규칙 중에는 지도와 관련된 메커니즘도 존재한다. 이 지도에 관련된 규칙들은 던전이 어떻게 연결될지 던전에 어떤 물체가 위치할지등에 대해 알고 있는데, 유저가 던전에서 던전으로 이동하는 방법이나 유저가 반드시 처리해야 하는 퀘스트를 결정하는 방법도 알고 있다.
하지만, 이보다 더 높은 수준에 또 다른 정책 집합이 있을수 있다. 여기서는 유저의 생명력이나, 퀘스트 내용, 퀘스트 보상등을 알고 있는 정책이다.
이런 정책은 유저의 생명력이 계속 줄어들도로 ㄱ하거나, 식량 발견시 생명력이 늘어나도록 한다. 저수준 정책에서는 고수준 정책에게 FoundFood(식량 발견)나 FellInFit(구덩이에 빠짐)과 같은 사건이 발생했음을 알린다. 그러면 고수준 정책에서는 유저의 상태를 관리한다. 그렇게 해서 게임이 끝낫을 때 유저의 상태나 승리 여부도 결정할 수 있다.
MoveManagement와 PlayerManagement를 분리하는 API가 필요할까? 아직은 잘 모르겠으니 몇 가지 마이크로서비스를 추가해보자. 대규모 유저가 동시에 플레이 가능한 버전의 게임이라고 해보자.
MoveManagement는 유저의 컴퓨터에서 직접 처리되지만 PlayerManagement는 서버에서 처리된다. PlayerManagement는 접속된 모든 MoveManagement 컴포넌트에 마이크로서비스 API를 제공한다.
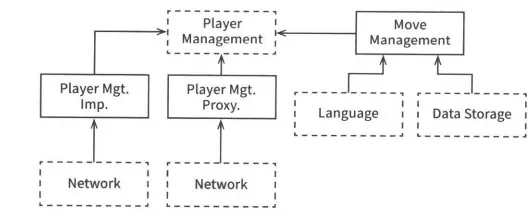
마이크로서비스 API추가하기
이로써 MoveManagement와 PlayerManagement사이에는 완벽한 형태의 아키텍처 경계가 존재한다.
결론
아키텍처 경계는 어디에나 존재한다. 아키텍트로서 우리는 아키텍처 경계가 언제 필요한지를 신중히 파악해내야 한다. 뿐만아니라 이러한 경계를 제대로 구현하기 위한 비용이 많다는 것도 알아야 한다.
그리고 동시에 이러한 경계가 무시되었을 때 나중에 다시 추가하는 비용이 크다는 사실도 알아야 한다. 그렇기에 우린 추상화가 미리 필요하리라고 미리 예측해서는 안된다(YAGNI 철학) 이 철학에서는 오버 엔지니어링이 언더 엔지니어링보다 나쁠때가 많다는 점을 말하는데, 한편으로는 아키텍처 경계가 존재하지 않는 상황에서 경계가 정말 필요하다는 사실을 발견했을 때 그제서야 경계를 추가하려면 높은 비용과 큰 위험을 감수해야 한다.
이제 ‘그래서 어쩌라고?’ 라는 생각이 들 수 있다. 우리는 미래를 내다봐야 한다. 그리고 추측하고 비용을 산정하고, 어디에 아키텍처 경계를 설정할지, 그리고 완벽하게 구현된 경계는 무엇인지와 부분적으로 구현할 경계와 무시할 경계가 무엇인지도 결정해야 한다.
다행히 이는 일회성 결정은 아니다. 프로젝트 초반에는 구현할 경계가 무엇인지와 무시할 경계가 무엇인지를 쉽게 결정할 수 없다. 대신 지켜봐야한다. 시스템이 발전함에 따라 주의를 기울여야 한다.
경계가 필요할 수 있는 시점이 오면 해당 경계를 구현하는 비용과 무시할 때 감수할 비용을 가늠하고, 결정된 사항을 자주 검토한다. 우리의 목표는 경계의 구현 비용이 그걸 무시해서 생기는 비용보다 적어지는 교차점에 경계를 구현하는 것이다.
메인 컴포넌트
모든 시스템에는 최소 하나의 컴포넌트가 존재하고 이 컴포넌트가 나머지 컴포넌트를 생성,조정,관리한다. 이러한 컴포넌트를 메인(Main)이라 부른다.
궁극적인 세부사항
메인 컴포넌트는 궁극적인 세부사항으로, 가장 낮은 수준의 정책이다.
메인은 시스템의 초기 진입점으로 운영체제를 제외하면 어떤 것도 메인에 의존하지 않는다. 메인은 모든 팩토리와 전략, 그리고 시스템 전반을 담당하는 나머지 기반 설비를 생성한 후, 시스템에서 더 높은 수준을 담당하는 부분으로 제어권을 넘기는 역할을 맡는다.
DI 프레임워크를 이용해 DI하는 일은 바로 이 메인 컴포넌트에서 이뤄져야 한다. 메인에 의존성이 일단 주입되고 나면, 메인은 의존성 주입 프레임워크를 사용하지 않고도 일반적인 방식으로 의존성을 분배할 수 있어야 한다.
크고 작은 모든 서비스들
서비스 지향 아키텍처(SOA)나 마이크로서비스아키텍처(MSA)는 최근 인기가 커져서 많은 개발자들이 알고 있는데, 그 인기의 이유를 살펴보면 다음과 같다.
•
서비스를 사용하면 상호 결합이 철저히 분리되는 것처럼 보인다.
•
서비스를 사용하면 개발과 배포 독립성을 지원하는 것처럼 보인다.
하지만, 나중에 살펴보면 둘 다 일부만 맞는 말이다.
서비스 아키텍처?
서비스를 사용한다는 것은 본질적으로 아키텍처에 해당하지 않는다.
시스템 아키텍처는 의존성 규칙을 준수하고 고수준의 정책을 저수준의 세부사항으로부터 분리하는 경계에 의해 정의된다. 단순히 애플리케이션의 행위를 분리할 뿐인 서비스라면 값비싼 함수 호출에 불과하고, 아키텍처 관점에서 그다지 중요하지 않다.
모든 서비스가 반드시 아키텍처 관점에서 중요해야 하는 것은 아니다. 기능을 프로세스나 플랫폼에 독립적이 되도록 서비스를 생성하면 의존성 규칙 준수 여부와 무관하게 도움이 되는 경우가 많다.
하지만, 서비스 그 자체로는 아키텍처를 정의하지 않는다.
함수들의 구성 형태도 이와 비슷하다. 모놀리틱 시스템이나 컴포넌트 기반 시스템에서 아키텍처를 정의하는 요소는 바로 의존성 규칙을 따르고 아키텍처 경계를 넘나드는 함수 호출들이다. 반면 시스템의 나머지 많은 함수들은 행위를 서로 분리할뿐으로 아키텍처는 전혀 중요하지 않다.
그리고 이는 서비스도 마찬가지다. 결국 서비스는 프로세스나 플랫폼 경계를 가로지르는 함수 호출에 지나지 않는다. 아키텍처적으로 중요한 서비스도 있지만, 중요하지 않는 서비스도 존재한다.
이번 챕터에서 우리가 살펴볼 서비스는 전자다.
결합 분리의 오류
시스템을 서비스들로부터 분리하면 서비스 사이의 결합이 확실히 분리된다는 이점을 얻을 수 있다. 어찌되었든 각 서비스는 서로 다른 프로세스, 혹은 서로 다른 프로세서에서 실행된다. 그렇기에 서비스는 다른 서비스의 변수에 직접 접근이 불가하다. 그리고 모든 서비스의 인터페이스는 잘 정의되어 있어야 한다.
이 내용은 어느정도 일리가 있지만, 지적할 부분 역시 존재한다.
서비스는 개별 변수 수준에서는 각자 결합이 분리된다. 하지만 프로세서 내의 또는 네트워크 상의 공유 자원 때문에 결합될 가능성은 여전히 존재한다. 더욱이 서로 공유하는 데이터에 의해 이들 서비스는 강력하게 결합되어 버린다.
예를 들어 서비스 사이를 오가는 데이터 레코드에 새로운 필드를 추가한다면, 이 필드를 사용해 동작하는 모든 서비스는 반드시 변경되어야 한다. 또한 이 서비스들은 이 필드에 담긴 데이터를 해석하는 방식을 사전에 완벽하게 조율해야 한다. 따라서 서비스들은 이 데이터 레코드에 강하게 결합되고, 서비스들 사이는 서로 간접적으로 결합되어 버린다.
인터페이스가 잘 정의되어 있어야 한다는 부분은 사실이다. 하지만 이는 함수에 경우에도 다르지 않다. 서비스 인터페이스가 함수 인터페이스보다 더 엄밀하거나, 엄격하고 더 잘 정의되는것은 아니다.
개발 및 배포 독립성의 오류
서비스를 사용함에 따라 예측되는 또 다른 이점으로는 서비스를 전담팀에서 소유및 운영한다는 점이다. 그래서 데브옵스(dev-ops)전략의 일환으로 전담팀에서 서비스를 작성하고, 유지보수하며, 운영하는 책임을 질 수 있다. 이러한 개발 및 배포 독립성은 확장 가능한(scalable)것으로 간주된다.
대규모 엔터프라이즈 시스템을 독립적으로 개발하고 배포 가능한 수십, 수백, 수천 개의 서비스들을 이용하여 만들 수 있다고 믿는다. 시스템의 개발, 유지보수, 운영 또한 비슷한 수의 독립적인 팀 단위로 분할할 수 있다고 여긴다. 이러한 믿음에도 어느정도 일리는 있지만 극히 일부일 뿐이다.
첫째로, 대규모 엔터프라이즈 시스템은 서비스 기반 시스템 외에도, 모놀리틱 시스템이나 컴포넌트 기반 시스템으로도 구축할 수 있다는 사실은 이미 역사적으로 증명되어 왔다. 따라서 서비스는 확장 가능한 시스템을 구축하는 유일한 선택지가 아니다.
둘째, ‘결합 분리의 오류’에 따르면 서비스라 해서 항상 독립적으로 개발하고, 배포하며 운영할 수 있는 것은 아니다. 데이터나 행위에서 어느 정도 결합되어 있다면 결합된 정도에 맞게 개발, 배포, 운영을 조정해야만 한다.
야옹이 문제
택시 통합 시스템을 예로 들어 앞선 두 오류에 대해 알아보자.
이 시스템은 해당 도시에서 운영되는 많은 택시 업체를 알고, 고객은 승차 요청을 할 수 있다.
고객은 승차 시간, 비용, 고급택시 여부, 운전사 경력과 같은 여러 조건들을 기준으로 택시를 선택할 수 있다. 확장 가능한 시스템을 구축하고 싶어서 수많은 작은 마이크로서비스를 기반으로 구축하기로 결정하고 개발팀 직원은 많은 소규모 팀으로 세분화 되었다.

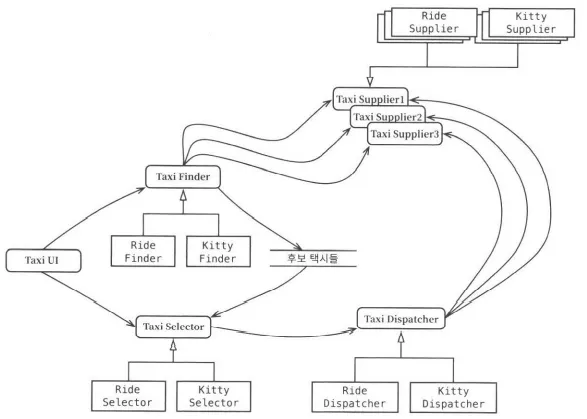
택시 통합 서비스를 구현하기 위해 배치된 서비스들
위 다이어그램은 가상의 아키텍트가 서비스를 배치하여 이 애플리케이션을 어떻게 구현했는지 보여준다. TaxiUI서비스는 고객을 담당하고, 고객은 모바일기기를 이용해 택시를 호출한다. TaxiFinder 서비스는 여러 TaxiSupplier의 현황을 검토하여 사용자에게 적합한 택시 후보들을 선별한다. TaxiFinder 서비스는 해당 사용자에게 할당된 단기 데이터 레코드에 후보 택시들의 정보를 저장한다. TaxiSelector 서비스는 사용자가 지정한 비용, 시간, 고급 여부 등의 조건을 기초로 후보 택시 중 적합한 택시를 선택한다. 이제 TaxiSelector 서비스가 해당 택시를 TaxiDispatcher 서비스로 전달하면
TaxiDispatcher 서비스는 해당 택시에 배차 지시를 한다.
이러한 시스템을 일 년 이상 문제없이 잘 운영해왔다고 가정하자.
어느날 마케팅 부서에서 도시에 야옹이를 배달하는 서비스를 제공하겠다는 발표를 하게되고 개발팀에서는 이 기능을 구현해야 하는데, 제공해야 하는 요구사항들은 다음과 같다.
•
사용자는 자신의 집(혹은 사무실)으로 야옹이를 배달주문을 할 수 있다.
•
회사는 도시 전역에 야옹이를 태울 다수의 승차 지점을 설정해야 한다.
•
야옹이 배달 주문이 오면, 근처의 택시가 선택되고, 승차 지점 중 한 곳에서 야옹이를 태운 후, 올바른 주소로 야옹이를 배달해야 한다.
•
택시 업체는 참가하는 업체도 있고, 거부하는 업체도 있을 것이다.
•
고양이 알러지 있는 운전자는 서비스에서 제외되어야 한다.
•
일반 택시 승객도 고양이 알러지를 일으킬 수 있기에, 배차를 신청한 고객이 알러지가 있다고 밝혔다면 지난 3일 사이 야옹이를 배달했던 차량은 배차되지 않아야 한다.
위와같은 요구사항들을 구현하기 위해서는 이 서비스의 모든 부분을 모두 수정해야 한다.
야옹이 배달 기능을 추가하기 위해서는 개발과 배포 전략을 신중하게 조정해야 한다. 즉 이 서비스들은 모두 결합되어 있기에 독립적으로 개발하고 배포하거나 유지될 수 없다.
이게 횡단 관심사(cross-cutting concern)가 지닌 문제다.
모든 소프트웨어 시스템은 서비스 지향이든 아니든 이 문제에 직면하게 된다.
객체가 구출하다.
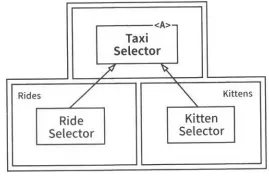
컴포넌트 기반 아키텍처에선 이러한 문제를 SOLID설계 원칙들을 활용하여, 다형적으로 확장할 수 있는 클래스 집합을 생성해 새로운 기능을 처리하도록 함을 알 수 있다. 아래 다이어그램은 이러한 전략을 보여준다.
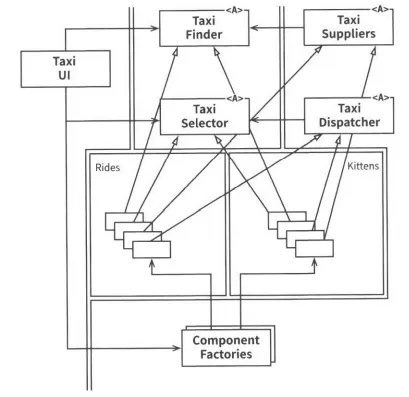
객체 지향 방식으로 횡단 관심사를 처리하기
이 다이어그램의 클래스들의 경계를 주목하자. 의존성 규칙이 잘 준수되고 있다는 점을 주목하자.
원래 서비스의 로직 중 대다수가 이 객체 모델의 기반 클래스들 내부로 녹아들었다. 하지만 배차에 특화된 로직 부분은 Rides 컴포넌트로 추출되고, 야옹이에 대한 신규 기능은 Kittens 컴포넌트에 들어갔다. 이 두 컴포넌트는 기존 컴포넌트들에 있는 추상 기반 클래스를 템플릿 메서드(Template Method)나 전략(Strategy) 패턴등을 이용해 오버라이드한다. 두 개의 신규 컴포넌트인 Rides와 Kittens가 의존성 규칙을 준수한다는 점에 주목하자. 그리고 이 기능들을 구현하는 클래스들은 UI의 제어하에 팩토리(Factories)가 생성한다는 점도 주목하자.
이 전략을 따르더라도 야옹이 기능을 구현하려면 TaxiUI는 변경해야만 한다. 하지만 그 외의 것들은 변경을 하지 않아도 된다. 대신 야옹이 기능을 구현한 새로운 jar파일이나 젬(Gem), DLL을 시스템에 추가하고, 런타임에 동적으로 로드하면 된다.
따라서 야옹이 기능은 결합이 분리되며, 독립적으로 개발하여 배포할 수 있다.
컴포넌트 기반 서비스
서비스도 물론 이렇게 할 수 있다. 서비스가 반드시 소규모 단일체(monolith)여야 할 이유도 없고 SOLID원칙대로 설계할 수 있고 컴포넌트 구조를 갖출 수도 있다. 이를 통해 서비스 내의 기존 컴포넌트들을 변경하지 않고도 새로운 컴포넌트를 추가할 수 있다.
자바의 경우, 서비스를 하나 이상의 jar 파일에 포함되는 추상 클래스들의 집합이라 생각하자.
새로운 기능 추가 혹은 확장은 새로운 jar 파일로 만든다. 이때 새로운 jar 파일을 구성하는 클래스들은 기존 jar 파일에 정의된 추상 클래스들을 확장해서 만들어진다. 그러면 새로운 기능 배포는 서비스를 재배포하는 문제가 아니라, 서비스를 로드하는 경로에 단순히 새로운 jar 파일을 추가하는 문제가 된다. 다시 말해 새로운 기능을 추가하는 행위가 개방 폐쇄 원칙을 준수하게 된다.
다음 다이어그램이 이런 구조를 보여준다.
횡단 관심사
지금까지 알아본 바로는 아키텍처 경계가 서비스 사이에 있지 않다는 점을 알 수 있다.
오히려 서비스를 관통하며, 서비스를 컴포넌트 단위로 분할한다.
모든 주요 시스템이 직면하는 횡단 관심사를 처리하려면, 다음 다이어그램에서 보듯이, 서비스 내부는 의존성 규칙도 준수하는 컴포넌트 아키텍처로 설계해야 한다. 이 서비스들은 시스템의 아키텍처 경계를 정의하지 않는다. 아키텍처 경계를 정의하는 것은 서비스 내의 위치한 컴포넌트다.
결론
서비스는 시스템의 확장성과 개발 가능성 측면에서 유연하지만, 그 자체로는 아키텍처적으로 중요한 요소는 아니다. 시스템의 아키텍처는 시스템 내부에 그어진 경계와 경계를 넘나드는 의존성에 의해 정의된다. 시스템의 구성 요소가 통신하고 실행되는 물리적인 메커니즘에 의해 아키텍처가 정의되는 것이 아니다.
서비스는 단 하나의 아키텍처 경계로 둘러싸인 단일 컴포넌트로 만들 수 있다. 혹은 여러 아키텍처 경계로 분리된 다수의 컴포넌트로 구성할 수도 있다. 드물게는 클라이언트와 서비스가 강하게 결합되어 아키텍처적으로 아무런 의미가 없을 때도 있다.
테스트 경계
테스트는 시스템의 일부로 아키텍처에도 관여한다. 시스템의 나머지 요소가 아키텍처에 관여하는 것과 동등하게 말이다. 어떤 면에서는 정말 평범하게, 그리고 상당히 독특하게 관여한다.
시스템 컴포넌트인 테스트
테스트에 대해 고민해볼 부분이 꽤나 있다.
•
테스트는 시스템의 일부인가 별개인가?
•
테스트는 어떤 종류가 있는가?
•
단위 테스트와 통합 테스트는 서로 다른가?
•
인수 테스트, 기능 테스트, Cucumber테스트, TDD 테스트, BDD테스트, 컴포넌트 테스트 등은 어떠한가.
다행히도 아키텍처 관점에서는 모든 테스트가 동일하기 때문에 고민하지 않아도 된다.
TDD로 생성한 단위 테스트도, 대규모의 테스트도 아키텍처적으로는 동등하다.
테스트는 태생적으로 의존성 규칙을 따른다. 테스트는 세부적이며 구체적인 것으로, 의존성은 항상 테스트 대상이 되는 코드를 향한다. 실제로 테스트는 아키텍처에서 가장 바깥쪽 원으로 생각할 수 있다. 시스템 내부의 어떤 것도 테스트에는 의존하지 않고, 테스트는 시스템의 컴포넌트를 향해, 항상 원의 안쪽으로 의존한다. 또한 테스트는 독립적으로 배포가 가능하다. 사실 대부분의 경우 테스트는 테스트 시스템에만 배포하고, 상용 시스템에서는 배포하지 않는다. 따라서 배포 독립성이 달리 필요하지 않은 시스템에서도 테스트는 독립적으로 배포될 것이다.
테스트는 시스템 컴포넌트 중에서 가장 고립되어 있다. 테스트가 시스템 운영에 꼭 필요하지도 않다. 어떤 사용자도 테스트에 의존하지는 않는다. 테스트의 역할은 운영이 아닌 개발을 지원하는데 있다.
그렇다고 테스트가 시스템 컴포넌트가 아니라는 뜻은 아니다. 사실 많은 면에서 테스트는 다른 모든 시스템 컴포넌트가 반드시 지켜야 하는 모델을 표현해준다.
테스트를 고려한 설계
테스트가 지닌 극단적인 고립성이 테스트는 대체로 배포하지 않는다는 사실과 어우러져, 개발자는 종종 테스트가 시스템의 설계 범위 밖에 있다고 여긴다. 하지만, 이 관점은 치명적이다.
테스트가 시스템의 설계와 잘 통합되지 않으면, 테스트는 깨지기 쉬워지고, 시스템은 뻣뻣해져서 변경하기가 어려워진다.
물론 문제는 결합이다. 시스템에 강하게 결합된 테스트라면 시스템이 변경될 때 함께 변경되어야만 한다. 시스템 컴포넌트에서 생긴 아주 사소한 변경도 이와 결합된 수많은 테스트를 망가뜨릴 수 있다. 상황은 더 심각해질수도 있는데, 시스템의 공통 컴포넌트가 변경되면 수백, 수천개의 테스트가 망가질 수 있다. 이러한 문제를 깨지기 쉬운 테스트 문제(Fragile Tests Problem)로 알려져 있다.
깨지기 쉬운 테스트는 시스템을 뻣뻣하게 만든다는 부작용을 낳을 때가 많다. 시스템에 가한 간단한 변경이 대량의 테스트를 실패로 만든다는 사실을 알게 되면 개발자는 이런 변경을 하지 않으려 할 것이다. 이 문제를 해결하기 위해서는 테스트를 고려해서 설계해야 한다.
소프트웨어 설계의 첫 번째 규칙은 언제나 같다. 변동성이 있는 것에 의존하지 말라는 것이다.
GUI는 변동성이 크다. GUI로 시스템을 조작하는 테스트 스위트는 분명 깨지기 쉽다. 따라서 시스템과 테스트를 설계할 때, GUI를 사용하지 않고 업무 규칙을 테스트할 수 있게 해야 한다.
테스트 API
이 목표를 달성하기 위해선 테스트가 모든 업무 규칙을 검증하는 데 사용할 수 있도록 특화된 API를 만들면 된다. 이러한 API는 보안 제약사항을 무시할 수 있으며 값비싼 자원(Ex: DB)은 건너뛰고, 시스템을 테스트 가능한 특정 상태로 강제하는 강력한 힘을 지녀야만 한다. 이 API는 사용자 인터페이스가 사용하는 인터랙터와 인터페이스 어댑터들의 상위 집합이 될 것이다.
테스트 API는 테스트를 애플리케이션으로부터 분리할 목적으로 사용한다. 단순히 테스트를 UI에서 분리하는것 뿐 아니라 테스트 구조를 애플리케이션 구조로부터 결합을 분리하는게 목표다.
구조적 결합
구조적 결합은 테스트 결합 중에서 가장 강하고, 가장 은밀하게 퍼져 나가는 유형이다. 모든 상용 클래스에서 테스트 클래스가 각각 존재하고, 또 모든 상용 메서드에 테스트 메서드 집합이 각각 존재하는 테스트 스위트가 있다고 가정해보자. 이러한 테스트 스위트는 애플리케이션 구조에 강하게 결합되어 있다. 상용 클래스 메서드 중 하나라도 변경되면 딸려 있는 다수의 테스트가 변경되야 한다.
결과적으로 테스트는 깨지기 쉬워지고, 이로 인해 상용 코드를 뻣뻣하게 만든다.
테스트 API의 역할은 애플리케이션의 구조를 테스트로부터 숨기는데 있다. 이렇게 만들면 상용 코드를 리팩터링하거나 진화시키더라도 테스트에는 영향을 주지 않는다. 또한 테스트를 리팩터링하거나 진화시킬 때도 상용 코드에는 전혀 영향을 주지 않는다.
이처럼 따로따로 진화할 수 있다는 점은 필수적인데, 시간이 지날수록 테스트는 더 구체적이로 더 특화된 형태로 변하고, 반대로 사용 코드는 더 추상적이고 더 범용적인 형태로 변할 것이기 때문이다.
하지만 구조적 결합이 강하면 필수적인 진화 과정을 방해하거나 지연시킬 뿐 아니라, 상용 코드의 범용성과 유연성이 충분히 좋아지지 못하게 막는다.
보안
테스트 API가 지닌 강력한 힘을 운영 시스템에 배포하면 위험에 처할 수 있다. 위험을 피하고 싶다면, 테스트 API자체와 테스트 API중 위험한 부분의 구현부는 독립적으로 배포할 수 있는 컴포넌트로 분리해야 한다.
결론
테스트는 시스템 외부가 아닌 시스템의 일부다. 따라서 테스트에서 기대하는 안정성과 회귀의 이점을 얻기 위해선 테스트를 잘 설계해야 한다. 테스트를 시스템의 일부로 설계하지 않으면 테스트는 깨지기 쉽고 유지보수하기 어려워지는 경향이 있다. 이러한 테스트는 유지보수하기가 너무 힘들기에 결국 방바닥의 휴지처럼 버려지는 최후를 맡는다.


