
목차
개요
순차성에서 벗어나야 하고 컴퓨터에 제한을 가하지 않아야 한다는 것은 분명하다.
데이터의 정의를 명시하고 데이터의 우선순위와 데이터에 관한 설명을 제공해야 한다.
절차가 아니라 관계를 명시해야 한다.
- 그레이스 머레이 호퍼, 미래의 경영과 컴퓨터(1962)
 데이터셋이 매우 크거나 질의 처리량이 매우 높은 경우 복제로는 부족하다.
데이터셋이 매우 크거나 질의 처리량이 매우 높은 경우 복제로는 부족하다. 그렇기에 데이터를 파티션으로 쪼갤 필요가 있는데, 이러한 작업을 샤딩이라 한다.
왜 데이터 파티셔닝을 하는가?
주된 이유는 확장성이다.
비공유 클러스터(shared-nothing cluster)에서 다른 파티션은 다른 노드에 저장될 수 있기에 대용량 데이터셋이 여러 디스크에 분산될 수 있고 질의 부하는 여러 프로세서에 분산될 수 있다.
크고 복잡한 질의는 어렵지만 여러 노드에서 병렬 실행도 가능하다.
파티셔닝 지원 데이터베이스
파티셔닝 지원 데이터베이스는 과거 다음 제품들에서 개척되었다.
•
테라데이터(Teradata)
•
탠텀 논스톱 SQL(Tandem NonSteop SQL)
그리고 최근에는 NoSQL , 하둡 기반 데이터 웨어하우스에서 재발견되었다.
어떤 시스템들은 트랜잭션 작업 부하용, 어떤 시스템들은 분석용으로 설계되었지만, 파티셔닝의 기본 원칙은 두 종류의 작업부하에 모두 적용된다.
이번 포스팅에서
•
대용량 데이터셋을 파티셔닝 하는 몇 가지 방법
•
데이터 색인과 파티셔닝의 상호작용 방식
•
재균형화(rebalancing)
•
요청 라우팅
에 대해 개략적으로 살펴보도록 하자.
파티셔닝과 복제
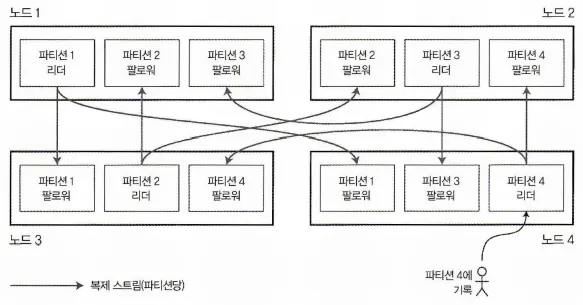
복제와 파티셔닝 조합: 각 노드는 어떤 파티션에게는 리더로 어떤 파티션에게는 팔로워로 동작한다.
파티셔닝과 복제는 별개가 아니다.
함께 사용할 경우
•
하나의 노드에 여러 파티션을 저장할 수 있다.
•
리더 팔로워 복제 모델을 사용할 경우
◦
위 그림과 같이 각 노드별로 파티션이 여러개가 되고
◦
각각의 파티션은 팔로우가 될 수도 리더가 될 수도 있다.
▪
리더는 노드 별로 하나의 노드에 할당되는게 효율적이다.
•
각 레코드는 한 파티션에 속할지라도 여러 노드에 저장하기에 내결함성을 보장할 수 있다.
◦
각 파티션의 리더 역할은 다른 노드에 존재하기 때문에 가능하다.
키-값 데이터 파티셔닝
대량의 데이터를 파티셔닝한다고 할 때 어떤 레코드를 어떤 노드에 저장할 지 어떻게 결정해야 할까?
파티셔닝의 목적은 데이터와 질의 부하를 노드 사이에 고르게 분산시키는 것이다.
모든 노드가 동일한 분량을 담당한다고 하면 노드를 N대 사용할 때 이론상 모든 성능(읽기, 쓰기, 저장하기)은 N배만큼 증가한다.
하지만…
파티셔닝이 고르게 이뤄지지 않아 특정 파티션이 데이터가 더 많을수도, 질의를 더 많이 받을 수도 있다. 이런 상황을 쏠렸다(skewed)고 말한다. 이런 쏠림이 있으면 파티셔닝의 효과는 떨어진다.
N개의 노드로 파티셔닝을 한다고 할지라도 그 중 하나의 노드가 모든 요청을 처리하게 되면, 파티셔닝의 의미가 없을 수 있다.
이와 같이 불균형하게 부하가 높은 파티션을 핫스팟이라고 한다.
핫스팟을 피하기 위해서는..?
1.
무작위 할당
:핫스팟은 하나의 노드에 부하가 가중되는 것이니 핫스팟을 피하기 위해서는 부하가 여러 노드로 골고루 분산되도록 하면 되는데, 가장 단순한 방법은 레코드를 할당할 노드를 무작위로 선택하는 것이다.
하지만, 이 방식을 사용할 경우 레코드를 읽으려고 할 때 해당 레코드가 어느 노드에 있는지 알 수 없기 때문에 모든 노드에 병렬 질의를 실행해야 한다.
2.
키-값 데이터 모델 사용
: 항상 기본키를 통해 레코드에 접근한다. 모든 항목이 제목의 알파벳 순으로 정렬돼 있기에 언제나 찾고자 하는 항목을 빨리 찾을 수 있다.
1번 방식은 간단하지만, 매 번 병렬 질의를 실행해야 한다는점에서 문제가 된다. 그렇기에 두 번째 방법인 키-값 데이터 모델을 사용하는 파티셔닝에 대해 알아보자.
키 범위 기준 파티셔닝

키 범위를 기준으로 파티셔닝된 백과사전
•
각 파티션에 연속된 범위의 키를 할당하는 식으로 파티셔닝을 한다.
•
각 범위들 사이의 경계를 알면 어떤 키가 어느 파티션에 속하는지 찾기 쉽다.
•
특정 파티션이 어떤 노드에 할당됐는지 알면 적절한 노드로 요청을 직접 보낼 수 있다.
•
키 범위 크기가 반드시 동일할 필요는 없다.
◦
데이터 분포가 균일하지 않을 수 있기 때문이다.
▪
1권(A-B)과 12권(T-Z)
•
데이터를 고르게 분산시키기 위해서는
◦
파티션 경계를 데이터에 맞춰 조정해야 한다.
•
파티션 경계는
◦
관리자가 수동으로 선택하거나
◦
DB에서 자동으로 선택되게 할 수 있다.
•
각 파티션 내에서는 키를 정렬된 순서로 저장할 수 있다.
◦
범위 스캔이 용이해진다.
키 범위 파티셔닝의 단점
키 범위 기준 파티셔닝은 특정한 접근 패턴이 핫스팟을 유발하는 단점이 있다.
scenario.
농장에 각종 센서들을 설치하고 센서 네트워크 데이터를 저장하는 애플리케이션이 있다고 가정한다.
키를 타임스탬프로 할 경우 파티션은 시간 범위에 대응된다.
날짜별로 파티션이 배정된다면, 하루 종일 쓰기 연산이 발생할 때마다 모두 동일한 파티션으로 전달되어 해당 파티션에만 부하가 걸려 핫스팟이 된다.
Plain Text
복사
이런 문제를 회피하기 위해서는
•
키의 첫 번째 요소로 타임스탬프 말고 다른걸 사용해야 한다.
◦
Ex: 센서명 첫 번째 요소로 지정하고 그 다음 요소로 타임스탬프를 사용한다.
키의 해시값 기준 파티셔닝
분산 데이터스토어는 쏠림(skewed) 현상, 그리고 핫스팟의 문제가 있다. 그래서 해시 함수를 사용해서 파티셔닝에 필요한 키를 만든다. 좋은 파티셔닝용 해시 함수는
•
쏠린 데이터도 균일하게 분산되게 할 수 있다.
•
암호적으로 강력할 필요는 없다.
◦
카산드라와 몽고DB는 MD5
◦
볼드모트는 파울러 놀 보(Fowler-Noll-Vo)함수를 사용한다.
•
프로그래밍 언어의 내장 해시 함수는 파티셔닝에 적합하지 않을 수도 있다.
◦
자바(Object.hashCode()), 루비(Object#hash) 는 같은 키를 넣어도 다른 프로세스에서는 다른 해시값을 반환할 수 있다.
참고: 왜 자바의 hashCode는 동일한 키에 다른 해시값을 반환할까?자바의 재정의되지 않은 Object.hashCode는 동등성 비교가 아닌 동일성 비교에 사용된다.
객체의 내부 변수들만 사용하는게 아니라 메모리 번지를 이용해 해시코드를 만들어 반환하기에 객체마다 다른 값을 반환한다.
즉, 동일한 키라고 하더라도 해당 키를 가진 객체의 메모리 번지는 다르기에 다른 해시값을 반환하는 것.
이러한 해시 함수를 사용해서 해시값 범위를 할당하고, 해시값이 파티션의 범위에 속하는 모든 키를 그 파티션에 할당하면 다음과 같은 모습이 나온다.
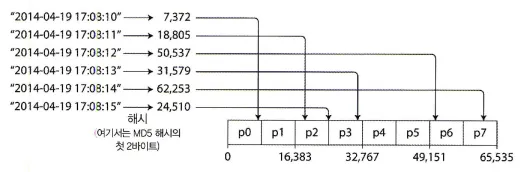
키의 해시값 기준 파티셔닝
이 기법은 키를 파티션 사이에 균일하게 분산시키는데 좋다.
파티션 경계는 크기가 동일하도록 나눌 수도 있고 무작위에 가깝게 선택할 수도 있다.
이런 기법을 일관성 해싱이라 부르기도 한다.
참고: 일관성 해싱
일관성 해싱은 CDN(Content Delivery Network)같은 인터넷 규모의 캐시 시스템에서 부하를 균등하게 분산시키는 방법이다. 중앙 제어나 분산 합의(distributed consensus)가 필요하지 않도록 파티션 경계를 무작위로 선택한다.
하지만, 이 방법은 데이터베이스에서 실제로 잘 동작하지 않아 잘 사용되지 않는다.
혼동하기 쉽기에 일관성 해싱이라는 단어 대신 해시 파티셔닝을 쓰는게 좋다.
Plain Text
복사
문제점
•
범위 질의가 어려워진다.
•
인접한 키들이 모든 파티션에 흩어져 정렬 순서가 유지되지 않는다.
DB별 전략
•
몽고 DB
◦
해시 기반 샤딩 모드를 활성화하면 범위 질의가 모든 파티션에 전송돼야 한다.
•
리악, 카우치베이스, 볼드모트
◦
기본키에 대한 범위 질의가 지원되지 않는다.
•
카산드라
◦
테이블 선언시 여러 칼럼을 포함하는 복합 기본키를 지정할 수 있다.
◦
키의 첫 부분에만 해싱을 적용해 파티션 결정에 사용한다.
◦
남은 칼럼은 SS테이블에서 데이터를 정렬하는연쇄된 색인으로 사용한다.
쏠린 작업부하와 핫스팟 완화
동일한 키에 편중되는 작업
해시 함수를 이용해 핫스팟을 줄이려 시도를 하지만, 클라이언트가 항상 동일한 키를 읽고 쓰는 경우에는 하나의 파티션으로 모든 요청이 쏠리게 된다.
트위터나 인스타그램에서 수백만의 팔로워를 가지고 있는 유명인사들이 새로운 글을 올린다면, 우리가 우려한 동일한 키에서 막대한 양의 작업이 수행될 수 있다. 모두 동일한 ID의 해시값을 사용하기에 해싱도 도움이 되지 않는다.
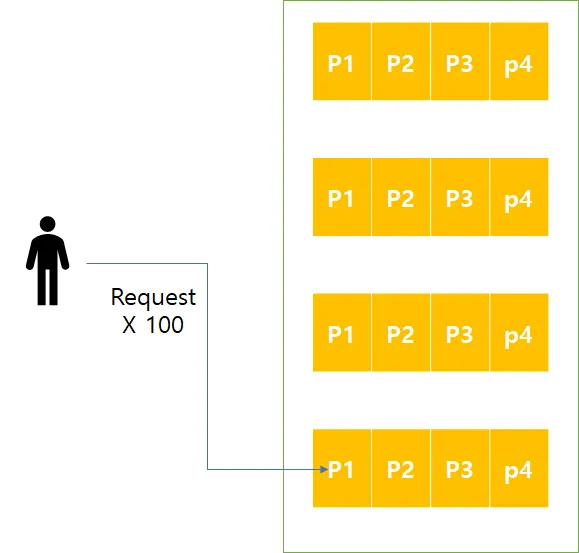
모두 동일한 키로 요청을 하는 상황
쏠린 작업부하 완화책
•
데이터 시스템에서 크게 쏠린 작업부하를 자동으로 보정하지 못하기에
◦
애플리케이션에서 쏠림을 완화해야한다.
•
어떻게?
◦
각 키의 시작이나 끝에 임의의 숫자를 붙혀서 해결할 수 있다.
•
하지만
◦
다른 키에 쪼개서 쓰면 읽기를 실행할 때 추가작업이 필요해진다.
◦
추가적으로 저장해야 할 정보도 있다.
•
그렇기에
◦
요청이 몰리는 소수의 키에만 적용하는게 적절하다.
◦
쓰기 처리량이 낮은 키에 적용하면 불필요한 오버헤드가 생긴다.
파티셔닝과 보조 색인
보조 색인이 연관되면
기존의 키-값 데이터 모델을 이용한 파티셔닝 방식으로는 구현 복잡도가 많이 높아진다.
또한, 보조 색인은 파티션에 깔끔하게 대응되지 않는 문제점도 있다.
그렇기에 HBase나 볼드모트같은 DB에서는 보조색인을 지원하지 않는다.
하지만 보조 색인은,
•
RDB의 핵심 요소이고 문서 데이터베이스에서도 흔하고
•
데이터 모델링에 매우 유용하다.
그래서 리악(Riak)같은 일부 DB에서는 보조 색인을 지원하기 시작했고, 솔라나 엘라스틱서치같은 검색 서버에서는 존재 이유이다. 그럼 이런 보조 색인을 지원하는 DB에서는 어떻게 파티셔닝을 해야 할까? 두 가지 방법이 있다. 문서 기반 파티셔닝과 용어 기반 파티셔닝이다.
문서 기준 보조 색인 파티셔닝
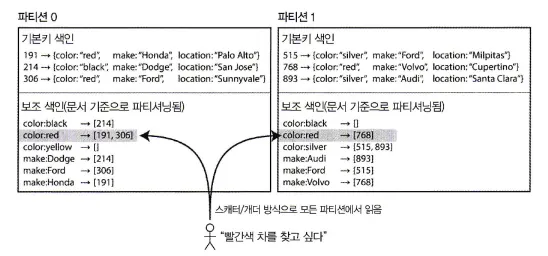
문서 기준 보조 색인 파티셔닝
•
각 항목에는 document ID라 부르는 고유 ID가 있으며, DB는 이 ID를 기준으로 파티셔닝을 한다.
◦
위 그림의 191, 214, 306, 515, 768, 893
◦
파티션 0: 0 < ID < 499 , 파티션 1: 500 < ID < 999 이런 방식으로 파티셔닝을 한다.
•
각 파티션은 완전히 독립적으로 동작한다.
•
각 파티션은 자신의 보조 색인을 만들고, 유지하며 해당 파티션에 속하는 문서만 담당한다.
◦
다른 파티션이 어떤 데이터를 가지고 있는지에 대해 알지 못한다.
•
지역 색인(local index)라고도 한다.
•
빨간색 자동차는 파티션 0, 파티션 1 둘 다 존재한다. 빨간색 자동차를 모두 찾기 위해서는 모든 파티션에 질의를 보내 결과를 집계해야한다.
◦
파티셔닝된 DB에 이런 식으로 질의를 보내는 방법을 스캐터/개더(scatter/gather)라 한다.
◦
꼬리 지연 시간 증폭이 발생하기 쉽다.
◦
하지만, 많이 사용된다.
▪
몽고DB, 리악, 카산드라, 엘라스틱서치, 솔라클라우드, 볼트DB
용어 기준 보조 색인 파티셔닝
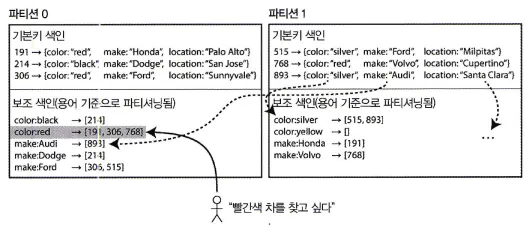
용어 기준 보조 색인 파티셔닝
•
각 파티션의 보조 색인이 지역성이 아닌 전역성을 가지도록 만들 수 있다.
◦
보조색인이 자기 파티션 뿐 아니라 모든 파티션의 데이터를 담당하도록 만든다.
◦
이를 전역 색인이라고 한다.
•
전역 색인도 파티셔닝해야 하지만 기본키 색인과 다른 방식을 사용한다.
•
위 그림을 보면
◦
자동차 색상을 알파벳으로 정렬한 다음
◦
a부터 r까지는 파티션 0
◦
s부터 z까지는 파티션 1에 저장되도록 파티셔닝 한다.
•
이처럼 용어에 따라 색인의 파티션이 결정되는 색인을
◦
용어 기준으로 파티셔닝 됐다(term-partitioned)고 한다.
◦
용어는 문서에 등장하는 모든 단어를 말한다.
•
여기서 용어가 아닌 용어의 해시값을 사용할 수도 있다.
◦
이 경우 부하는 더 고르게 되지만 범위 질의가 복잡해진다.
하지만 장점만 있지는 않다.
•
전역 색인은 쓰기가 느리고 복잡하다.
◦
단일 문서를 쓸 때 해당 색인의 여러 파티션에 영향을 줄 수 있기 때문이다.
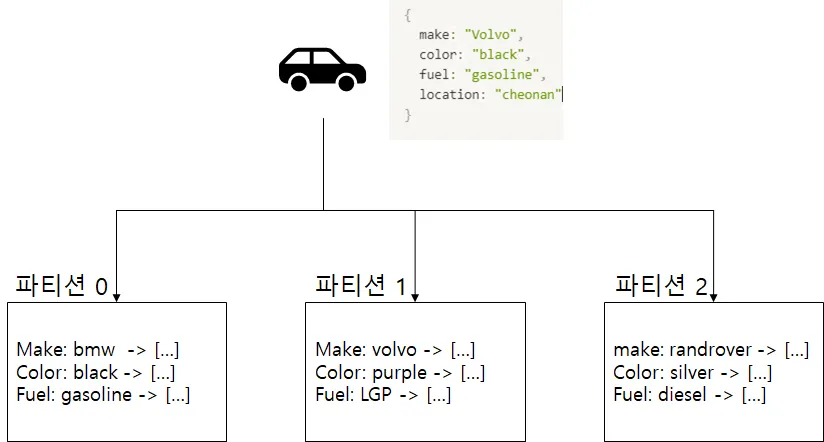
하나의 쓰기가 3개의 파티션에 영향을 준다.
•
쓰기에 영향받는 모든 파티션에 걸친 트랜잭션을 실행해야 하는데
◦
모든 DB에서 분산 트랜잭션을 지원하지는 않는다.
현실에서는
•
전역 보조 색인은 대게 비동기로 갱신된다.
•
아마존 다이나모DB는 문제가 생기면(Ex: 인프라 결함등) 반영 지연시간이 길어질 수 있다.
•
리악의 검색 기능이나 오라클의 데이터 웨어하우스에서 사용될 수 있다.
파티션 재균형화
시간이 지나면서 데이터베이스에는 변화가 생긴다.
scenario
- 질의 처리량이 증가해 늘어난 부하를 처리하기 위해 CPU 추가를 하고 싶다.
- 데이터셋 크기가 증가해 데이터셋 저장에 사용할 디스크와 램을 추가하고 싶다.
- 장비에 장애가 발생해 그 장비가 담당하던 역할을 다른 장비가 넘겨받아야 한다.
Plain Text
복사
DB에 시간이 흐르면서 발생하는 상황
이런 변화가 생길 때 데이터와 요청은 다른 노드로 옮겨져야 하는데, 클러스터에서 한 노드가 담당하던 부하를 다른 노드로 옮기는 과정을 재균형화(rebalancing)라고 한다.
재균형화로 기대하는 부분
그럼 우리가 재균형화를 통해 기대하는 부분은 무엇일까?
•
재균형화 후, 부하(데이터 저장소, 읽기 쓰기 요청)가 클러스터 내에 있는 노드들 사이에 균등하게 분배돼야 한다.
•
재균형화 도중에도 DB는 읽기 쓰기 요청을 받아들여야 한다.
•
재균형화가 빨리 실행되고 네트워크와 디스크I/O 부하가 최소화 되도록 노드들 사이에서 데이터가 필요 이상으로 옮겨져서는 안된다.
재균형화 전략
쓰면 안되는 방법: 해시값에 모드N 연산을 실행
•
모드(mod) 연산은 다음과 같이 진행된다.
◦
해시값이 십진수를 사용한다고 가정한다.
◦
노드는 10대가 있다고 가정한다.
hash(key): 123456 mod 10 = 6
Plain Text
복사
mod N 연산시 노드 할당
•
노드가 계속해서 변경되는 경우
◦
노드가 11대: 123456 mod 11 = 3
◦
노드가 12대: 123456 mod 12 = 0
•
노드 변경에 따라 재균형화 비용이 너무 커진다.
파티션 개수 고정
파티션을 노드 대수보다 많이 만들고 각 노드에 여러 파티션을 할당하는 방법
•
노드가 10대라면
•
DB는 처음부터 파티션을 1,000개로 나눈 후
•
각 노드마다 100개 가량의 파티션을 할당한다.
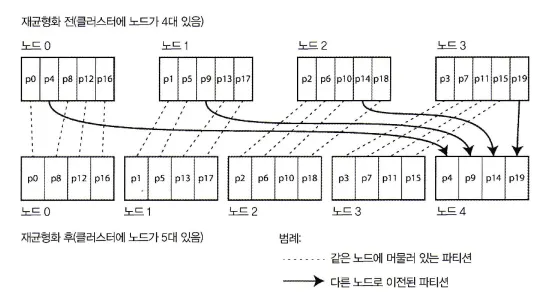
DB 클러스터에 새 노드가 추가되는 경우
클러스터에 노드가 추가될 경우
•
새 노드는 기존 노드에서 파티션 몇 개를 뺏어올 수 있다.
클러스터에 노드가 제거될 경우
•
제거되는 노드의 파티션들이 기존 노드로 할당될 수 있다.
그 밖에 특징들
•
파티션은 노드 사이에서 통째로 이동하며 개수나 파티션에 할당된 키도 변경되지 않는다. 어떤 노드에 어떤 파티션이 할당되는지만 변한다.
•
파티션 할당 변경은 즉시 반영되는게 아니기 때문에 변경 도중에 읽기 쓰기 실행시 기존에 할당된 파티션을 사용한다.
•
클러스터에 다른 스펙의 하드웨어가 섞여있을 수 있다.
◦
성능이 더 좋은 노드에 파티션을 더 할당할 수 있다.
•
처음 설정된 파티션 개수가 사용 가능한 최대 노드 수가 된다.
◦
미래를 고려해서 충분히 높은 값으로 선택해야 한다.
•
파티션 크기가
◦
너무 크면 재균형화를 실행할 때와 노드 장애 복구 비용이 너무 크다.
◦
너무 작으면 오버헤드가 너무 커진다.
◦
적절한 파티션 크기를 찾아야 한다.
동적 파티셔닝
파티션 고정은 최초 설정을 너무 크게 해도, 너무 작게 해도 문제가 될 수 있고 불편하다.
파티션의 경계를 잘 못 지정하면 데이터가 한 파티션에 저장되고 나머지 파티션은 비어있을 수도 있다.
그래서 몇몇 DB는 파티션을 동적으로 만든다.
HBase나 리싱크DB처럼 키 범위 파티셔닝을 사용하는 DB는 파티션을 동적으로 만든다.
•
파티션 크기가 설정된 값을 넘어서면
◦
파티션을 두 개로 쪼개 각 파티션이 쪼개진 데이터를 포함한다.
•
파티션 크기가 임곗값 아래로 떨어지면
◦
인접한 파티션과 합쳐질 수 있다.
◦
B트리의 최상위 레벨에서 실행되는 작업과 유사하다.
특징
•
큰 파티션이 쪼개지면 부하의 균형을 맞추기 위해 분할된 파티션 중 하나가 다른 노드로 이동될 수 있다.
•
파티션 개수가 전체 데이터 용량에 맞춰 조정된다는 이점이 있다.
•
비어있는 DB는 파티션 경계를 어디로 할지에 대해 사전 정보가 없다.
◦
그렇기에 시작 시점에는 파티션이 하나
◦
데이터셋이 작을 땐 모든 쓰기 요청이 하나의 노드에서 실행된다.
▪
나머지 노드들은 유휴 상태
◦
HBase와 몽고DB에선 비어있는 DB에 초기 파티션 집합을 설정할 수 있도록 하며 이를 사전 분할(pre-splitting)이라 부른다.
◦
키 범위 파티셔닝은 사전 분할을 하려면 키가 어떤 식으로 분할될지 미리 알아야 한다.
노드 비례 파티셔닝
동적 파티셔닝도, 파티션 개수 고정도 개별 파티션의 크기는 데이터셋 크기에 비례한다.
두 경우 모두 파티션의 개수는 노드 대수와 독립적이다.
카산드라와 케타마(Ketama)에서 사용되는 세 번째 방법은
파티션 개수가 노드 대수에 비례하게 하는 것이다.
즉,
•
노드 대수가 동일한 시점에서는
◦
개별 파티션의 크기가 데이터셋 크기에 비례해서 증가하고,
•
노드 대수가 증가하는 시점에서는
◦
개별 파티션의 크기는 다시 작아진다.
데이터 용량이 클수록 보통 데이터를 저장할 노드도 많이 필요하기에 이 방법을 쓰면 개별 파티션 크기도 상당히 안정적으로 유지된다.
새 노드가 클러스터에 추가되면 고정된 개수의 파티션을 무작위로 선택해 분할하고, 각 분할된 파티션의 절반은 그대로 두고 다른 절반은 새 노드에 할당한다. 이렇게 되면 파티션을 무작위로 선택했기 때문에 분할이 균등하지 않을 수 있지만 여러 파티션에 대해 평균적으로 보면 새 노드는 기존 노드들이 담당하던 부하에서 균등한 몫을 할당받게 된다.
파티션 경계를 무작위로 선택하려면 해시 기반 파티셔닝을 사용해야 한다.
최근에 나온 해시 함수를 쓰면 메타데이터 오버헤드를 낮추면서도 비슷한 효과를 얻을 수 있다.
운영: 자동 재균형화와 수동 재균형화
자동 재균형화
•
관리자의 개입 없이 시스템이 자동으로 언제 파티션을 노드 사이에 이동할지를 결정한다.
•
일상적인 유지보수에 손이 덜가기에 편리하다.
•
언제 재균형화가 될지 예측하기 어렵다.
•
재균형화는 비용이 큰 연산인데,
◦
자동 장애 감지와 조합될 경우 불필요한 상황에서 재균형화를 시도하며 연쇄장애가 발생할 수 있다.
수동 재균형화
•
관리자가 명시적으로 파티션을 노드에 할당하도록 설정하고 관리자가 재설정할 때만 파티션 할당이 변경된다.
반자동 재균형화
완전히 수동으로 하기에는 인적 부담이 크고, 완전히 자동으로 하기에는 재균형화의 시점을 파악하기 힘들고, 불필요한 재균형화로 비용이 낭비될 수 있다.
그렇기에 자동으로 파티션 할당은 제안하지만, 반영은 관리자가 확정해야 하도록 하는 반자동 재균형화가 있다.
카우치베이스, 리악, 볼드모트가 이런 반자동 재균형화 방식을 사용한다.
요청 라우팅
클라이언트의 요청을 어느 노드로 연결해야하는지 어떻게 확인할까?
서비스 찾기(service discovery)
네트워크를 통해 접속되는 소프트웨어, 그 중에서도 고가용성을 지향하는 소프트웨어는 모두 클라이언트에서 어떤 노드로 접속해야 할지 어떤 IP와 포트 번호로 접속해야 할지 서비스 찾기(service discovery)를 고려해야 한다. 그래서 여러 회사에서 자체 서비스 찾기 도구를 개발했고, 이 중 대다수가 오픈소스로 공개되었다. (Ex: 넷플릭스 유레카)
세 가지 서비스 찾기 방법
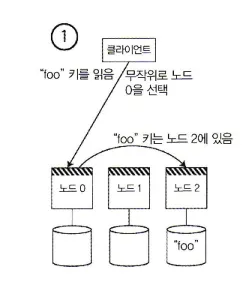
1.
클라이언트는 아무 노드에 접속하게 한 뒤,
•
해당 노드에 요청을 적용할 파티션이
◦
있다면, 노드에서 요청을 직접 처리하면 된다.
◦
없다면, 요청을 올바른 노드로 전달해서 응답을 받고 클라이언트에게 응답을 전달한다.
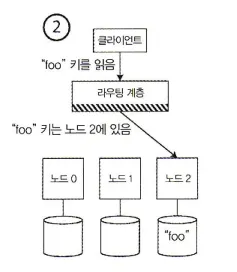
2.
클라이언트는 모든 요청을 라우팅 계층으로 먼저 보낸다. 라우팅 계층에선 각 요청을 처리할 노드를 알아내고 그에 따라 해당 노드로 요청을 전달한다.
•
라우팅 계층 자체에선 아무 요청도 처리하지 않는다.
•
파티션 인지(partition-aware) 로드 밸런서로 동작할 뿐이다.
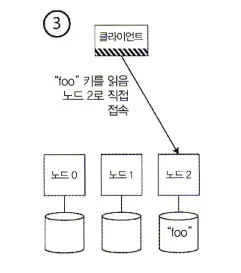
3.
클라이언트가 파티셔닝 방법과 파티션이 어떤 노드에 할당됐는지를 알고 있게 한다.
이 경우 클라이언트는 중개자 없이 올바른 노드로 직접 바로 접속할 수 있다.
공통적으로
•
라우팅 결정을 내리는 구성요소(노드 중 하나, 라우팅 계층, 클라이언트)가 노드에 할당된 파티션의 변경 사항을 어떻게 아는지가 핵심 문제다.
◦
이 문제는 참여하는 모든 곳에서 정보가 일치해야 하기에 다루기 어렵다.
◦
일치하지 않을 경우 요청이 잘못된 노드로 전송될 수 있다.
주키퍼(ZooKeeper)
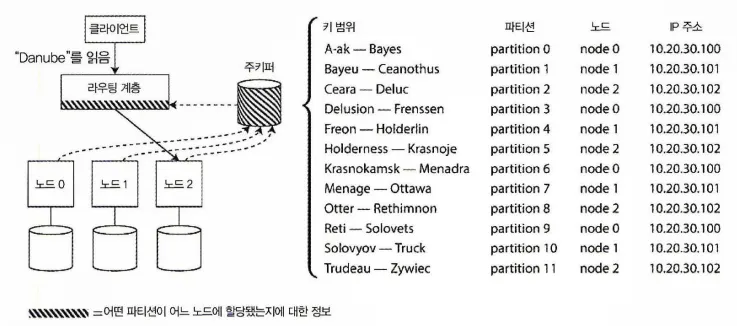
분산 데이터 시스템에서 클러스터 메타데이터를 추적하기 위한 코디네이션 서비스
•
각 노드는 주키퍼에 자신을 등록하면
•
주키퍼는 파티션과 노드 사이의 신뢰성 있는 할당 정보를 관리한다.
◦
라우팅 계층, 파티션 인지 클라이언트 같은 구성요소에서 주키퍼에 있는 정보를 구독할 수 있다.
여러 코디네이션 서비스 사용 예
•
Linkedin의 에스프레소는 헬릭스(Helix)를 써서 클러스터를 관리하며 라우팅 계층을 관리한다.
◦
헬릭스는 주키퍼에 의존한다.
•
Hbase, 솔라클라우드, 카프카도 파티션 할당 추적에 주키퍼를 사용한다
•
몽고DB는 자체 설정 서버(config server) 구현에 의존하고 몽고스(mongos)라는 데몬을 라우팅 계층으로 사용한다.
•
카산드라와 리악은 가십 프로토콜(gossip protocol)을 사용해 클러스터 상태 변화를 노드 사이에 퍼트린다.
◦
외부 코디네이션 서비스에 의존하지 않는 방식
•
카우치베이스는 목시(moxi)라는 라우팅 계층을 설정해 클러스터 노드로부터 변경된 라우팅 정보를 알아낸다.
병렬 질의 실행
처리해야 할 데이터가 갈수록 많아져 빅데이터 시대가 되면서, 고려해야할 점이 늘어났다.
•
비용
◦
저장해야 할 데이터의 양, 애플리케이션의 수가 급속도로 늘면서 스토리지 증설과 신규 도입에 필요한 비용이 너무나 커져 스토리지 가상화를 통한 씬 프로비져닝(Thin provisioning)을 이용해 가용율을 높히려 했지만 한계가 있었다.
•
성능
◦
대용량 데이터 처리에 요구되는 성능이 부족해져갔다. SAN, Infiniband등의 고속 스토리지 네트워크를 적용하고 스토리지의 I/O성능을 높혀도 병목현상은 생기고 성능 이슈는 발생할 수 밖에 없었다.
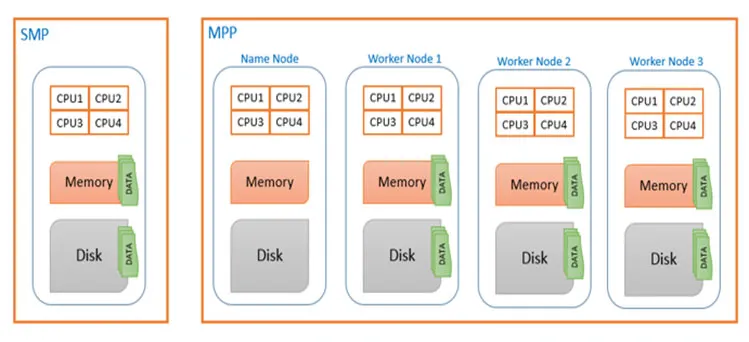
이와 같이 여러 애플리케이션 서버가 통합 스토리지 레이어에서 데이터를 저장하는 구조를 SMP(Symmetric Multi-Processing)이라 하는데, 해당 구조에서 이런 부족한 성능을 올리기 위해서는 scale-up 방식을 사용해야 했는데, 비용 문제 뿐 아니라 근본적인 해결책이 아니였다는 것이다.
그래서 SMP의 한계를 벗어나기 위해 데이터를 다수의 서버에 분산시키고, 서버들을 하나의 클러스터로 구성해 병렬 처리하는 플랫폼을 개발해서 사용하기 시작했다. 이런 방식은 단위 트랜잭션 처리 성능은 부족해도 대용량 데이터를 관리하는데 있어서 비용이나 성능에서 SMP보다 뛰어나고 scale-out 방식의 확장도 가능한 유연성을 제공했다. 이처럼 분석용으로 사용되는 대규모 병렬 처리(massively parallel processing, MPP) RDB는 다음과 같은 복잡한 종류의 질의도 지원한다.
•
MPP 질의 최적화기는 복잡한 질의를 여러 실행 단계, 파티션으로 분해해 DB 클러스터 내의 서로 다른 노드에서 병렬적으로 실행될 수 있다.

