


목차
 이 포스팅은 왜 하는가?
이 포스팅은 왜 하는가?
기존의 SQL만 사용하던 내게 Redis와 같은 NoSQL은 사실 기존 서비스에 인터페이스로 제공되고 있어 내가 따로 신경쓰지 않아도 되는 부분 뿐이기에 추가적인 공부보단 필요할때만 찾아서 보는 편이였다.
하지만, 2023년 하반기 신규서버 구축을 하면서 인증및 코드데이터 캐싱의 필요성이 생기면서 공부할 필요성을 느끼게 되었다. 그렇기에 기본적인 사용법이나 기능들에 대해 살펴보고 하나의 포스팅으로 기본 개념을 잡는데까지는 문제가 없도록 해 볼 목적으로 포스팅을 작성하게 되었다.
그럼 시작해보자.
아차차
이런 포스팅 말고 더 자세하고 깊게 Redis에 대해서 확인하고 싶다면 다음 사이트를 참고하는걸 추천한다.
본문은 너무 방대한 자료에서 내게 필요한 부분들만 추려서 정리하는 용도이다.

NoSQL(Not only SQL) 이란?
Redis는 NoSQL이다. 그럼 NoSQL은 무엇인가?
NoSQL은 비관계형 데이터베이스로 기존 SQL과 비교해서 저장하는 데이터의 종류나 저장 방식, 확장방식들이 모두 차이가 난다. SQL이 데이터 유형에 제약을 두고 높은 신뢰성과 안전성을 제공한다면 NoSQL은 이러한 제약을 없애 반전형 혹은 비정형 데이터를 다루며 속도와 유연성, 그리고 확장성을 제공한다.
즉, 안전성을 일정부분 포기하고 성능을 선택한 데이터베이스라고 보면 된다.
그럼 SQL과 NoSQL의 주요 차이점은?
SQL
•
Stands for Structured Query
•
관계형 데이터베이스
•
구조화 쿼리 언어 사용과 정적 스키마
•
수직적 확장
•
테이블 기반
•
다중 행 트랜잭션에 적합
NoSQL
•
Not Only SQL
•
비관계형 데이터베이스
•
구조화되지 않은 데이터를 위한 동적 스키마
•
수평적 확장
•
문서(Document), Key-Value, 그래프 기반
•
비정형 데이터(ex: 문서, JSON)에 적합
그럼 Redis는?
Remote Dictionary Server
Redis는 위에서 소개한 NoSQL DBMS중 하나로 특히 빠른 성능과 유연한 데이터 구조, 그리고 간편한 확장성을 제공한다. 그럼 많은 NoSQL중 Redis가 많이 사용되는 이유가 있을텐데 그 이유가 뭘까?
우선, Redis는 단순한 key-value store지만, 다양한 데이터 구조(List, Set, Hash, Sorted Set)들을 지원한다. 그리고 In-Memory 기반의 Database이기에 매우 빠른 속도도 지원한다는 장점이 있다. 그렇기에 캐싱이나 세션 관리, 채팅과 같이 실시간성이 중요한 기능들에서 많이 사용되고 있다. 그 밖에도 여러 기능들을 제공하는데 좀 더 자세히 알아보자.
Redis의 특징
Redis는 다양한 기능들을 제공하는데 이에 대해 알아보면 좋을 것 같다.
•
높은 성능과 속도
◦
In-Memory 기반 데이터베이스인 Redis는 매우 빠르게 데이터를 읽기 및 쓰기 속도를 제공하기에 실시간 애플리케이션, 빅 데이터 애플리케이션과 같이 고성능이 요구되는 환경에서 중요하다.
•
개발자의 사용 용이성
◦
문법적으로도 정말 간단한 편이고, 라이브러리를 통해 여러 개발 언어를 지원하고 또 애플리케이션에서 작성해야 하는 개발 코드 양도 적은편이다. 즉 사용하기가 편하다.
•
캐싱 및 메시지 큐 기능
◦
구독/알람(Pub/Sub)기능과 리스트를 이용한 간단한 큐 구현을 통해 메시징 및 작업 큐 관리를 쉽게 할 수 있다.
•
영속성 옵션
◦
In-Memory 기반의 데이터베이스지만, 데이터를 디스크에 저장하는 다양한 옵션도 제공한다.
◦
RDB(Redis Database)와 AOF(Append only file)를 통해 영속성을 제공할 수도 있다.
•
클러스터 모드(Cluster Mode)
◦
여러 노드에 데이터를 분산해서 저장할 수 있으며 필요에 따라 스케일 아웃을 할 수도 있다. (안전성 & 고가용성 제공)
•
Single Thread
◦
단일 thread에서 모든 작업(task)를 처리한다.
◦
동시성은 좀 떨어질 수 있지만, 이미 속도가 빠르기에 단일 스레드로 안전성을 확보할 수 있다.
•
스냅샷(Snapshot)
◦
Redis에서는 특정 시점에 데이터를 디스크에 저장해 보관할 수 있고, 장애 발생 시 복구에 사용할 수 있다.
•
넓은 생태계
◦
Redis가 대중적으로 많이 사용되는 NoSQL이기에 생태계가 안정되어 여러 트러블 슈팅 문서들이 공유되고 있기에 커뮤니티의 도움을 받기 편하다.
참고: RDB(Redis Database)와 AOF(Append Only File)
Redis에서 데이터 영속성을 제공하기 위한 메커니즘이다. 장단점이 있기에 Redis에서는 두 메커니즘을 함께 사용할 수 있도록 설정할 수 있다.
RDB(Redis Databse)
: 특정 시점에 Redis dataset의 스냅샷을 생성하는데 생성 간격(혹은 패턴)을 지정하면 전체 데이터 세트에 대한 스냅샷을 생성한다. 이 스냅샷을 통해 Redis서버 재시작시 데이터를 복구할 수 있다.
redis.conf 파일에서 관련 설정(ex: 생성 주기)을 조정할 수 있다.
AOF(Append Only File)
AOF는 Redis에서 수행된 모든 쓰기 연산을 파일에 기록한다. 그렇기에 Redis 서버가 의도치 않게 종료되더라도 AOF 파일로 대부분의 데이터 복구가 가능해진다. 하지만, 지속적으로 데이터가 추가되는 만큼 파일의 크기도 커질 것이고, 이 또한 부담이 될 수 있다. 그래서 Redis는 자동으로 AOF 파일을 재작성해 크기를 최적화한다. 이 메커니즘은 Redis의 안전성을 높힌다는 장점은 있지만, 디스크 쓰기가 많이 발생하기 때문에 성능적으로 불리한 부분이 있다.
Redis는 언제 사용할까?
빠르고 좋다는 특징에 대해 알아봤다면 이제 이 Redis가 언제 사용되면 좋을지 사용사례에 대해서도 좀 알아보면 내가 관련 기능을 개발할 때 도입 기술로 Redis를 고려할 수 있지 않을까? 생각이 들어서 작성해보는 Redis 사용 사례
•
캐싱(Caching)
◦
데이터베이스 쿼리, 웹페이지, API호출의 결과 같이 자주 사용되는 데이터를 캐시에 저장해서 반복되는 호출에 더 빠르게 접근할 수 있도록 해서 성능 개선을 하는데 사용된다.
◦
Ex: 임시 비밀번호(OTP), 로그인 세션(Session)
•
메시징 및 큐 시스템
◦
Pub/Sub기능과 리스트 데이터 구조를 사용해 메시징작업 및 큐 시스템을 구현할 수 있다.
◦
애플리케이션 간 메시지 교환을 통해 계층간의 커플링을 없앨 수 있다.
•
실시간 분석
◦
실시간 트래픽 분석, 사이트 방문자 추적, 소셜 미디어 피드 처리와 같이 Redis의 빠른 속도를 활용한 실시간 분석에서 유리하다.
•
Geospatials
◦
Redis는 Geospatials 데이터 처리 기능을 제공한다. 이를 활용해 위치 기반서비스나 위치 추적, 범위 탐색과 같은 기능등을 사용할 수 있다.
•
Feature flags
◦
신규 기능의 테스트 및 배포를 관리하기 위한 Feature Flags 시스템 구축에 사용될 수 있다.
◦
사용자별 기능 제공(Premium Service), A/B 테스팅과 같은 기능등을 수행할수도 있다.
Redis 데이터 타입과 명령어
사실 대부분 Strings 타입으로 서버에서 Object to JSON으로 변환한 문자열을 저장하는 용도로만 사용한다.
하지만, 생각보다 많은 데이터타입이 있고 또 지원하는 기능들도 많았는데 빠르게 훑어보도록 하자.
Strings
문자열, 숫자, 직렬화된 객체(JSON string)등을 저장한다.
•
가장 기본적인 데이터 타입으로 텍스트 또는 이진 데이터를 저장한다.
•
키-값 쌍으로 데이터를 저장하며 최대 512MB의 크기를 가진다.
•
캐싱, 카운터, 문자열 저장과 같은 용도로 사용된다.
•
명령어
◦
저장: SET ${key} ${value}
◦
조회: GET ${key}
◦
다중 저장: MSET ${key1} ${value1} ${key2} ${value2} …${keyN} ${valueN}
◦
다중 조회: MGET ${key1} … ${keyN}
◦
숫자 타입 값 증가: INCR ${key}
◦
숫자 타입 커스텀 값 증가: INCRBY ${key1} ${IncreaseValue}
•
depth를 가지는 경우 콜론(:)을 사용해 구분한다 (Ex: set food:kimchi:ko:price 1000)
•
겹쳐쓰기 방지 옵션(NX): set ${key} ${value} NX
◦
데이터베이스에 같은 키가 없을 경우에만 저장한다.
•
이미 키가 있을 경우에만 저장 옵션(XX): set ${key} ${value} NX
명령어 더 자세히
List
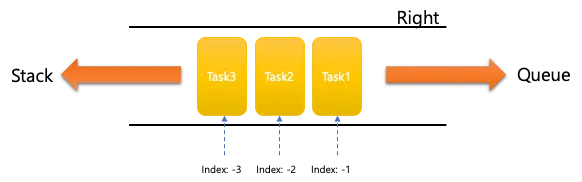
Redis List
목록을 저장하며 중복이 있고 순서가 있는 컬렉션
•
String을 Linked List로 저장하며 push/pop에 최적화되어있다(O(1))
◦
QUEUE(FIFO) , Stack(FILO)구현에 사용할 수 있다.
•
메시징 큐, 최근 항목 목록 조회 등에 사용된다.
•
명령어
◦
좌측부터 값 저장: LPUSH ${key} ${value1} ${value2} ${value3} … ${valueN}
◦
우측에서 값 꺼내기: RPOP ${key}
◦
좌측에서 값 꺼내기: LPOP ${key}
◦
범위 조회: LRANGE ${key} ${startIndex} ${endIndex}
◦
범위 제외 제거: LTRIM ${key} ${startIndex} ${endIndex}
Set
목록을 저장하며 중복이 없고 순서도 없는 컬렉션
•
Set Operation 사용이 가능해 합집합 교집합 차집합 기능을 제공한다.
•
태그, 고유한 요소 모음등에 사용된다.
•
명령어
◦
저장: SADD ${key} ${value1} ${value2} ${value3} … ${valueN}
◦
전체 조회: SMEMBERS ${key}
◦
카디널리티 조회: SCARD ${key}
◦
특정 아이템 포함여부 조회(contains): SISMEMBER ${key} ${value}
◦
교집합 조회 : SINTER ${key1} ${key2}
◦
차집합 조회: SDIFF ${key1} ${key2}
▪
좌측에 위치한 key가 기준이 된다.
◦
합집합 조회: SUNION ${key1} ${key2}
Sorted Set
각 요소가 스코어를 통해 연결되어 정렬된 집합으로 기존 Set 타입에 추가적으로 score 속성이 저장된다.
•
내부적으로 Skip List와 Hash Table로 이뤄져 있다.
•
score 값에 따라 정렬을 유지한다.
•
score가 동일할 경우 lexicographically(사전 편찬 순)으로 정렬한다.
•
줄여서 ZSet이라고 부른다.
•
순서를 가지기 때문에 범위검색(ZRANGE)검색이 가능하다.
•
게임의 리더보드나 순위 시스템 등에서 활용된다.
•
명령어
◦
저장: ZADD ${key} ${score1} ${value1} ${score2} ${value2} … ${socreN} ${valueN}
◦
범위 조회: ZRANGE ${key} ${startIndex} ${endIndex}
▪
startIndex: 0, endIndex: -1로 조회할 경우 전체를 조회한다.
◦
범위 조회(Revers): ZRANGE ${key} ${startIndex} ${endIndex} REV WITHSCORES
◦
랭킹 조회: ZRANK ${key} ${value}
Hash
field-value 구조를 갖는 데이터 타입
•
키-값 쌍 컬렉션을 저장하는데 사용되며 문자열 필드와 값을 가진다.
•
객체나 구조체와 같이 다양한 속성을 갖는 객체의 데이터를 저장할 때 유용하다.
•
사용자 프로필, 상품 정보와 같은 데이터 저장시 유리하다.
•
명령어
◦
저장: HSET ${key} ${field1} ${value1} ${field2} ${value2} … ${fieldN} ${valueN}
◦
조회: HGET ${key} ${field}
◦
다중 조회: HMGET ${key} ${field1} ${field2} ${fieldN}
◦
숫자타입의 값 증가: HINCRBY ${key} ${field} ${value}
Stream
append-only log에 consumer group과 같은 기능을 더한 자료 구조
•
영속성 옵션에 사용되는 AOF와 유사하다.
•
Stream에 추가되는 이벤트는 고유한 id를 할당받는데 이 id를 통해 조회를 할 경우 O(1)의 시간복잡도를 가진다.
•
Consumer Group이라는 기능을 제공해 분산 시스템에서 다수의 consumer의 이벤트를 안정적으로 처리할 수 있다.
•
고유 아이디는 1703673197581-0 이와 같은 구조로 하이픈(-)을 기준으로 좌측은 시간정보 우측은 동일한 시간내에 넘버링으로 보면 된다.
•
명령어
◦
Stream Entry 추가: XADD ${key} * ${field1} ${value1} ${field2} ${value2} …
▪
*을 추가해야 고유 아이디 자동생성이 된다.
◦
범위 조회 : XRANGE ${key} - +
◦
entry 제거: XDEL ${key} ${ID}
◦
구독 형식의 Entry 조회: XREAD ${count} ${count-num} STREAM ${key} ${start-id}
•
예시
◦
Stream 추가하기
xadd event * action click id catsbi target button
xadd event * action click id pobi target image
Kotlin
복사

Stream 조회
◦
Stream 범위 조회
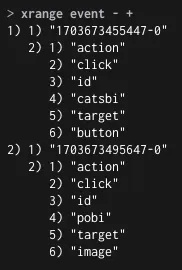
Stream 범위 조회
◦
Stream 삭제 및 조회
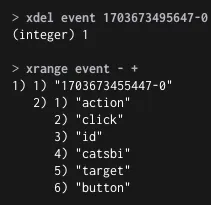
Stream 삭제
Bitmaps
비트 단위의 연산을 지원하는 데이터 타입, 각 비트는 0 또는 1의 값을 가진다.
•
실제 데이터 타입은 아니고, String에 binary operation을 적용한 것이다.
•
최대 42억개 binary 데이터 표현이 가능하다()
•
비트 연산을 사용해 효율적인 데이터 처리가 가능하다.
•
비트 연산을 통해 사용자의 공통 행동 지표나 특정 기간 활성화 유저 파악등에 사용될 수 있다.
•
출석 체크나 플래그 설정등에 사용된다.
•
명령어
◦
저장: SET ${key} ${offset} {value}
◦
카운트 조회: BITCOUNT ${key}
◦
비트연산: BITOP ${operation} ${destkey} ${key1} ${key2}
▪
operaion은 and, or, xor, not 등이 있다.
▪
비트 연산 결과를 destkey에 저장한다.
◦
비트 연산 결과 조회: GETBIT ${destkey} ${field}
•
예시
SETBIT market:order:23-12-01 23 1
SETBIT market:order:23-12-01 24 1
SETBIT market:order:23-12-02 23 1
BITCOUNT market:order:23-12-01 #2
BITOP AND result market:order:23-12-01 market:order:23-12-02
GETBIT result 23 # 1
GETBIT result 24 # 0
Bash
복사
HyperLogLog
대규모 중복 요소 집합에 대한 근사 cardinality 제공하는 확률형 자료구조
•
정확성은 좀 떨어지지만 저장공간을 더 효율적으로 사용한다.
•
대규모 데이터 집합에서 고유 방문자수같이 정확도의 중요성이 비교적 낮은 기능에 사용된다.
◦
평균적으로 0.81%의 에러율을 보여준다.
•
해시 함수를 사용해 각 요소를 비트 문자열로 변환해 이 비트 문자열의 패턴을 분석해 카디널리티를 추정한다.
◦
비트패턴 분석은 해시의 값에서 처음 나타나는 1의 위치(혹은 0의 수)를 분석한다.
•
실제로 값을 저장하지는 않기 때문에 내부 값을 꺼내는 용도로 쓸 수는 없다.
•
명령어
◦
저장: PFADD ${key} ${value1} ${value2} … ${valueN}
◦
카디널리티 조회: PFCOUNT ${key}
◦
병합: PFMERGE ${destkey} ${key1} ${key2}
참고: 저장공간을 얼마나 아낄 수 있을까?
다음 스크립트를 실행해 redis에 Set 타입과 HyperLogLog 형태로 각각 저장해 메모리를 비교해보자.
for ((i=1; i<=1000; i++)) do redis-cli sadd k1 $i; done
for ((i=1; i<=1000; i++)) do redis-cli pfadd k2 $i; done
MEMORY USAGE k1 # 48304
SCARD k1 # 1000
MEMORY USAGE k2 # 2104
PFSCARD k2 # 1001
Bash
복사
2.4배 이상의 메모리 효율 차이가 나지만 카디널리티가 정확하지 않다.
Geospatial
지리적 위치 데이터를 저장 및 검색하는 데이터 타입
•
각 위치는 위도와 경도로 정의된다.
•
Redis 3.2 버전부터 지원되기 시작했다.
•
내부적으로 Sorted Sets을 사용해 관리한다.
•
반경 검색, 위치 찾기, 거리 계산과 같은 지리적 연산 기능을 제공한다.
•
명령어
◦
저장: GEOADD ${key} ${latitude} ${longitude} ${field} [… ${latitude} ${longitude} ${field}]
◦
거리 계산: GEODIST ${key} ${field1} ${field2} ${KM|M|FT|MI}
◦
조회: GEOPOS ${key} ${field1} [… ${fieldN}]
◦
위도 경도 기반 반경 검색
▪
GEORADIUS ${key} ${latitude} ${longitude} ${radius} ${KM|M|FT|MI} ${추가옵션}
◦
특정 멤버 중심 반경 검색
▪
GEORADIUSBYMEMBER ${key} ${field} ${radius} ${KM|M|FT|MI} ${추가옵션}
◦
추가옵션 상세
▪
WITHCOORD: 각 멤버의 위치(위도와 경도)를 반환한다
▪
WITHDIST: 중심점으로부터 각 멤버까지의 거리를 반환한다.
▪
WITHHASH: 각 멤버의 내부 geohash 값을 반환한다.
▪
ASC 또는 DESC: 거리에 따라 결과를 오름차순 또는 내림차순으로 정렬한다.
▪
COUNT: 반환할 최대 멤버 수를 지정한다.
BloomFilter
확률적 데이터 구조
•
요소가 데이터 집합 안에 포함되어있는지 확인할 수 있다.
•
정확성은 좀 떨어지지만 저장공간을 더 효율적으로 사용한다.
•
요소가 집합안에 포함되어 있지 않아도 포함되었다고 거짓 긍정(false positives)할 수 있다.
•
Set과 비교해 실제 값을 저장하는게 아니기 때문에 매우 적은 메모리를 사용한다.
•
일반적으로 비트 배열로 구현되며 초기엔 모든 비트가 0으로 설정된다.
•
요소의 해시값을 구해 나온 인덱스에 해당하는 비트를 1로 설정한다.
•
웹 크롤링이나 네트워크 보안, 캐시 미스 최소화등에서 사용된다.
•
명령어
◦
저장: BF.MADD ${key} ${value} [… ${value}]
◦
요소 확인(contains): BF.EXISTS ${key} ${value}
참고: HyperLogLog와 다른점이 뭘까 ?
둘 다 정확도를 포기하고 저장공간을 확보한 데이터 타입으로 비슷해보이는데 어떤 차이가 있을까?
HyperLogLog | Bloom Filter | |
목적 | Cardinality 추정에 사용된다. | Membership Test에 사용된다. |
알고리즘 | 해시 함수와 선행 0의 수를 기반으로한 통계적 추정을 사용한다. | 비트 배열과 해시 함수를 사용한다. |
오차 타입 | 추정치에 작은 오차를 가진다. | 거짓 긍정(False Positives)을 가진다. |
명령어 요약
구분 | SET | GET | POP | REM | INCR | 집합연산 |
Strings | SET | GET | - | DEL | INCR | - |
Lists | LPUSH | LRANGE | LPOP | LREM | - | - |
Sets | SADD | SMEMBERS | SPOP | SREM | - | SUNION |
ZSets | ZADD | ZRANGE | ZPOPMIN | ZREM | ZINCRBY | ZUNION |
Hashes | HSET | HGET | - | HDEL | HINCRBY | - |
Streams | XADD | XREAD | - | XDEL | - | - |
데이터 타입이 생각보다 많다…
실제로 사용해본 데이터 타입은 Strings 뿐이였고 모두 애플리케이션에서 직렬화와 역직렬화를 통한 객체 관리용도로만 사용을 했기에 이렇게 데이터 타입이 많을줄은 몰랐는데, 생각보다도 많은 데이터 타입이 존재하고 기본적으로 제공하는 기능들도 생각보다 많다는 사실을 알게 되었다.
하지만, 여기서 끝이 아니다. Redis에는 여러 특수 명령어들이 존재해서 이를 잘 활용하면 응용할 수 있는 범위가 또 늘어난다. 이제 알아보자.
Redis Pub/Sub

Redis에서는 알람(Publish) 과 구독(Subscribe)이라는 기능을 이용해 메세지를 주고받는 기능을 제공한다.
크게 어렵게 생각할 것 없다. 유튜브에서 우리가 좋아하는 채널을 구독하고 해당 채널에서 새로운 영상이 올라올때 우리의 핸드폰 등으로 알림이 울리는것도 pub/sub이라 할 수 있다.
언뜻 보면 Stream과 유사해보이지만, Stream은 메시지가 보관될뿐더러 Stream과 다르게 Pub/Sub에서는 메시지를 보관(queuing)하지 않을 뿐더러 Subscribe 하지 않을 때 발행된 메시지는 수신할 수 없다는 차이가 있다.
이제 그럼 명령어를 하나씩 살펴보자
명령어
•
구독하기: SUBSCRIBE [channel [channel …]]
: 지정한 채널로 보내진(publishing) 메시지를 받는다. 채널을 하나 이상 구독할 수 있다.
•
채널 패턴 구독하기: PSUBSCRIBE [pattern [pattern …]]
: 채널을 패턴으로 등록하며 패턴은 glob-style을 지원한다.
•
'?'는 한 글자를 대치한다. h?llo는 hello, hallo, hxllo 같은 것을 의미한다.
•
'*'은 공백이나 여러 글자를 대치한다. h*llo는 hllo, heeeello 같은 것을 의미한다.
•
h[ae]llo는 'a' 나 'e'만 올 수 있다. 그래서 hello, hallo는 되고, hillo는 안된다.
•
구독 해제하기: UNSUBSCRIBE [channel [channel …]]
: 구독했던 채널을 삭제해서 더이상 메시지를 수신하지 않는다. 이 때 채널명을 지정하지 않을 경우 모든 채널을 삭제한다.
•
채널 패턴 해제하기: PUNSUBSCRIBE [pattern [pattern …]]
: 구독했던 채널 패턴을 삭제해서 더 이상 메시지를 수신하지 않는다. 패턴을 지정하지 않으면 모든 패턴을 삭제한다.
구
•
메시지 알림 전송하기: PUBLISH channel message
: 메시지를 지정한 채널로 전송하며, 메시지를 받는 클라이언트 수를 반환한다.
•
서머에 등록된 채널이나 패턴 조회 : PUBSUB subcommand [argument [argument …]]
◦
subcommand는 다음과 같이 3가지가 존재한다.
▪
channel, numsub: 채널 관련 명령
▪
numpat: 패턴 관련 명령
◦
패턴을 입력하지 않으면 등록된 모든 채널명을 보여준다.
참고: 클러스터에서 Pub/Sub
클러스터에서 Publish할 경우 클론을 포함한 모든 노드에게 보낸다. 그래서 해당 메시지를 슬레이브 노드에서도 subscribe할 수 있다. 반대의 경우도 동일하다.
참고: 더 자세한 내부 구조 확인이 필요할 경우

참고: Spring Boot에서 Redis Pub/Sub 구현해보기
작성중 …
Redis Pipeline
다수의 요청이 들어왔을 경우 이를 하나씩 Redis에서 저장한다고 생각해보자.
Redis에서 정말 빠른 속도로 저장을 해서 다수의 저장 요청을 처리하는데 큰 시간이 들지 않는다고 하면, 이 과정은 무리없이 깔끔하게 잘 끝난걸까?
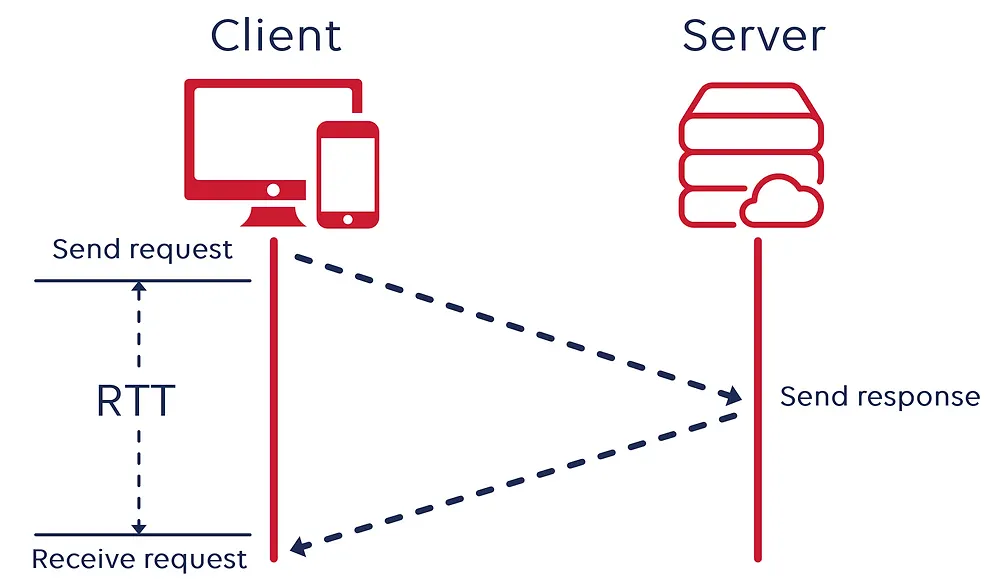
우리가 여기서 놓치지 말아야 할 맹점은 네트워크 비용이다.
하나의 요청을 레디스에서 0.1ms에 처리한다고 하더라도 RTT(Round-Trip Times) 비용이 250ms라면 하나의 요청을 처리하는데 드는 시간은 250.1 ms 인 것이고 이는 내가 1초에 3개의 요청만을 처리할 수 있다는 결론이 나오게 된다. 이렇게 되면 redis가 in-memory기반이든 disk기반이든 네트워크 비용때문에 기대했던 퍼포먼스를 볼 수 없게된다.
그래서 Redis에서는 Pipeline을 통해 이러한 네트워크 비용을 줄여서 문제를 해결할 수 있다.
Redis Pipeline은 redis에 요청할 명령어를 일괄로 처리해서 RTT시간을 최적화 하는 방법으로 더 쉽게말하면 여러 명령어를 하나씩 요청하는게 아니라 묶어서 한 번에 요청해 RTT 시간을 최소화하는 것으로 대부분의 클라이언트 라이브러리에서도 지원하기에 사용하기도 어렵지 않다.
간단한 사용 예제
코틀린 코드를 이용해 간단하게 Redis Pipeline을 사용하는 예제를 확인해보자.
(Jedis 라이브러리는 spring-session-data-redis 모듈에 하위 모듈에 포함되어 있고, 없다면 Jedis 의존성을 추가해야 한다.)
import redis.clients.jedis.Jedis
fun main() {
// Redis 서버에 연결
val jedis = Jedis("localhost")
try {
// Redis pipeline 시작
val pipeline = jedis.pipelined()
// Pipeline에 여러 명령 추가
pipeline.set("key1", "value1")
pipeline.set("key2", "value2")
pipeline.incr("counter")
pipeline.get("key1")
// Pipeline 실행 및 결과 가져오기
val results = pipeline.syncAndReturnAll()
// 결과 출력
println(results) // [OK, OK, (counter의 새로운 값), value1]
} catch (e: Exception) {
e.printStackTrace()
} finally {
// Redis 연결 종료
jedis.close()
}
}
Kotlin
복사
Redis Transaction
Redis도 Transaction은 제공한다.
모두 알겠지만 다시 한 번 리마인드하자면 Transaction은 다수의 명령을 하나의 작업 단위(Transaction)으로 묶어서 처리하는 것으로 모두 성공하거나 모두 실패하는 두 개의 결과를 가짐으로써 원자성(Atomicity)을 보장하도록 한다.
그럼 Redis에선 어떻게 Transaction을 이용할 수 있을까? 작업의 순서가 있어야 하고, 다른 작업들이 껴들지 못하도록 잠금(Lock)도 필요하다. Redis에서는 이를 명령어를 통해서 해결한다.
명령어
•
트랜잭션 시작: MULTI
◦
트랜잭션 시작 이후 입력한 명령어는 바로 실행되지 않고 큐(queue)에 쌓인다.
•
커밋: EXEC
◦
정상적으로 처리되어 큐(queue)에 쌓여있는 명령어를 일괄적으로 실행한다.
•
롤백: DISCARD
◦
큐(queue)에 쌓여있는 명령어를 일괄적으로 폐기한다.
•
잠금(Lock): WATCH
◦
낙관적 락(Optimistic Lock) 기반의 잠금을 지정한다.
◦
해당 명령어를 사용하면 이 후에 UNWATCH 되기전에 EXEC나 트랜잭션외의 명령만 허용한다.
RDBMS의 Transaction과의 차이점
Redis에서도 Transaction을 제공하긴하지만 아무래도 RDBMS에서 제공되는 Transaction과는 차이가 있다.
다음 쿼리를 실행하면 어떤 결과가 나올지 예상해보자.
MULTI
HSET test 2 3
SET test 4
EXEC
# 1) "ReplyError: WRONGTYPE Operation against a key holding the wrong kind of value"
# 2) "OK"
get test
Bash
복사
우리가 아는 Transaction이라면 nil 이 나와야 할 것이다.
하지만 실행해보면 4가 나온다.
Redis의 Transaction은 잘못된 명령어가 있다고 하더라도 정상적으로 사용한 명령어에 대해서는 잘 적용된다.
공식 문서에서는 이렇게 설계한 이유를 다음과 같이 밝혔다.
이런 문제는 대부분 개발 과정에서 날 수 있는 에러이며 Production에서는 거의 발생하지 않는 에러이며. rollback을 채택하지 않은 대신 높은 성능을 유지할 수 있다,
잠금(Lock)
작성중….

