
개요
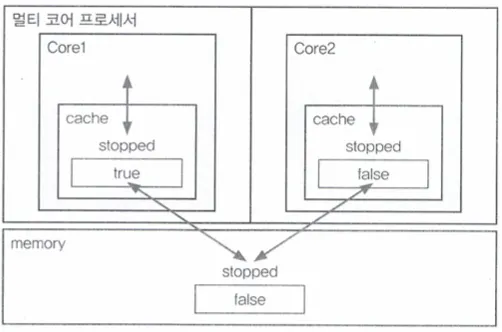
자바의정석 chapter 13 - 멀티코어 프로세서의 캐시와 메모리간의 통신
멀티 코어 프로세서는 각각의 코어가 별도의 캐시를 가지고 있다.
그리고 각각의 코어는 메모리에서 읽어온 값을 캐시에 저장하고 읽어서 작업을 수행하는데,
같은값을 다시 읽을때는 먼저 캐시를 확인 후 없을때만 메모리에서 읽어온다.
그러다보니 위 그림처럼 코어의 캐시에 저장된 값과 메모리에 저장된 값이 불일치하는 경우가 생길 수 있다.
그래서 나온게 volatile 이라는 키워드이고 해당 키워드를 이용해 이러한 문제를 해결한다.
Q.어떻게?
A. volatile 키워드를 붙힐 경우 코어가 변수의 값을 캐시가 아닌 메모리에서 읽는다.
Happends-Before
JDK 5부터 volatile 키워드는 단순히 해당 변수의 작업(읽기/쓰기)의 원자성만 보장하는 것이 아니라 이 스레드가 volatile 변수를 수정하기 전에 수정한 모든 변수들이 함께 메모리에 저장(flushed)된다.
volatile 변수를 메모리에서 읽을때도 마찮가지로 다른 모든 변수들도 같이 읽어들여진다.
주의점
volatile 키워드는 변수의 작업(읽기/쓰기)를 원자화 하는 것이지 동기화 하는 것은 아니다.
즉 동기화가 필요할 때 volatile이 synchronized 블럭을 대체할 수 없다는 의미이다.
volatile long balance;
synchronized int getBalance() {
return balance;
}
synchronized void withdraw(int money){
if(balance >= money) {
balance -= money;
}
}
Java
복사
⇒ balance 변수가 volatile로 작업을 원자화 했으니 getBalance의 synchronized 키워드가 불필요해보일 수 있다. 하지만 해당 키워드로 동기화를 하지 않을 경우 특정 스레드에서 withdraw()가 호출되어 lock이 걸리고 로직이 처리되는 중에도 getBalance() 가 호출이 가능해질 수 있다.
 참고 - synchronized
참고 - synchronized
synchronized 를 사용해도 volatile과 동일한 효과를 얻을 수 있다.
스레드가 synchronized 블럭으로 들어갈 때와 나올 때, 캐시와 메모리간의 동기화가 이뤄지면서 값의 불일치가 해소되기 때문이다.
참고- volatile로 long과 double 원자화
JVM은 데이터를 4Byte단위로 처리하기에 int와 int보다 작은 타입들은 한번에 읽고 쓸 수 있다. 이 말은 하나의 명령어로 읽기/쓰기가 가능하다는 의미인데, 그럼 4Byte이상인 타입은 어떻게 해야 할까?
long이나 double과 같이 크기가 8Byte인 변수는 하나의 명령어로 읽기/쓰기를 할 수 없기 때문에 변수의 값을 읽는 과정에 다른 스레드가 끼어들 수 있다. 그럼 어떻게 해결을 해야할까?
이 때, volatile을 사용하면 된다.volatile은 해당 변수에 대한 읽기/쓰기를 원자화 하는데, 이는 작업을 더 이상 나눌 수 없게 한다는 의미가되고 작업 중간에 다른 스레드에서 끼어들 수 없게 된다는 의미가 된다.
정리
•
캐시가 아닌 메모리에서 값을 읽도록 하는 키워드
•
변수의 값을 작성할 때 메모리에까지 작성해 변수의 값 불일치를 막는다.
•
멀티 쓰레드 환경에서 작업(읽기/쓰기)의 원자성이 보장되야 할 경우 volatile이 적절하다.

