
목차
개요
SQL 튜닝을 진행하기 전 기본적으로 알아야 할 용어들을 짚고 넘어간다.
물리 엔진과 오브젝트 용어
푸드코트와 유사한 MySQL 수행 프로세스
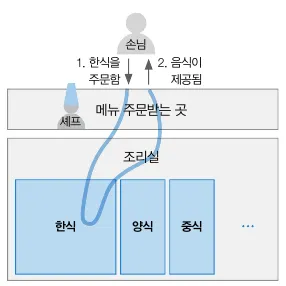
푸드코트의 주문 프로세스
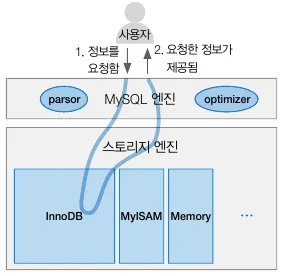
SQL 수행 프로세스
MySQL에서 데이터를 저장하고, 저장된 데이터를 가공하는 연산은 일상생활과 비교해서 큰 차이가 없다.
1.
사용자가 음식을 주문하듯, 정보를 요청한다.
2.
요청이 들어오면 푸드코트에선 조리가 가능한지, 메뉴판에 있는 음식인지 확인하듯이 MySQL엔진은 문법 에러가 있는지, DB에 존재하는 테이블을 대상으로 SQL문을 작성했는지와 같은 세부 사항을 검사한다(파싱 작업을 하는 파서(Parser 역할)
3.
사용자가 요청한 요리(데이터)를 빠르고 효율적으로 찾아가는 계획 수립(옵티마이저 역할)
4.
이 계획을 토대로 조리실(스토리지 엔진)에서 데이터를 찾아 주문 받는 곳(MySQL 엔진)으로 전달
•
전달받은 데이터에서 불필요한 부분을 필터링하고 필요한 연산을 수행한 뒤 사용자에게 결과를 알려준다.
•
DB Engine Keywords
1. 스토리지 엔진
•
(InnoDB, MyISAM, Memory…) 와 같은 스토리지 엔진은 사용자가 요청한 SQL을 토대로 DB에 저장된 디스크나 메모리에서 필요한 데이터를 가져오는 역할을 수행한다.
•
저장 방식에 따라 각각 다른 스토리지 엔진을 선택해 사용할 수 있다.
•
필요할 경우 외부에서 스토리지 엔진을 가져와 활성화해서 사용할 수 있다.
•
일반적으로 온라인 환경의 트랜잭션 발생 데이터 처리는 OLTP(Online Transaction Processing )환경으로 InnoDB 엔진을 사용한다.
•
대량 쓰기 트랜잭션은 MyISAM엔진을 사용한다.
•
메모리 데이터를 로드해 빠르게 읽기 위해선 Memory 엔진을 사용한다.
2. MySQL 엔진
•
사용자가 요청한 SQL 문을 문법 검사, 오브젝트 활용 검사를 하고, 최소 단위로 분리해 원하는 데이터를 빠르게 찾는 경로를 모색하는 역할을 수행한다.
•
SQL문의 시작 및 마무리 단계에 관여하며 스토리지 엔진으로부터 필요한 데이터만을 가져오는 핵심 역할을 담당한다
SQL Process Keywords
1. 파서
•
MySQL 엔진에 포함되는 오브젝트
•
SQL을 쪼개 최소단위로 분리하고 트리를 만들며 문법 검사를 수행한다.
2. 전처리기
•
파서에서 생성한 트리를 토대로 구조적인 문제를 파악한다.
•
테이블, 열, 함수, 뷰와 같은 오브젝트가 정상적인지 권한은 있는지 확인한다.
3. 옵티마이저
•
전달된 파서 트리를 토대로 필요하지 않은 조건을 제거하거나 연산 과적을 단순화한다.
•
테이블 접근 순서, 인덱스 사용 여부, 인덱스 선택, 임시테이블 사용 여부와 같은 실행 계획을 수립한다.
•
항상 최상의 실행 계획을 세우지는 못한다.
•
개발자가 적절히 실행 계획을 수립하는것을 도우는 식으로 쿼리 튜닝을 할 수 있다.
4. 엔진 실행기
•
MySQL 엔진과 스토리지 엔진 양 측 영역에 걸치는 오브젝트
•
옵티마이저의 실행 계획을 참고해 스토리지 엔진에서 데이터를 가져온다.
•
읽어온 데이터를 정렬, 조인, 필처링 하는 추가작업을 수행한다.
DB Object Keywords
: 데이터 베이스를 구성하는 요소 중 하나로 오브젝트라 불리는 객체들이 있는데, 테이블, 로우, 컬럼과 같은 기본적인 키워드는 생략한다.
1. 고유 인덱스
•
인덱스를 구성하는 열들의 데이터가 유일하다.
•
차례로 정렬되는 인덱스 열의 데이터는 서로 중복되지 않고 유일성을 유지한다.
ALTER TABLE 학생
ADD UNIQUE INDEX 연락처_인덱스(연락처);
SQL
복사
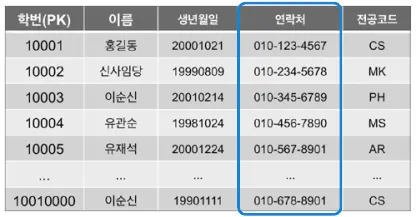
연락처 컬럼을 고유 인덱스로 설정한다.
•
기본 키(Primary Key)와 유사해보이지만, 고유 인덱스는 Nullable하다는 차이가 있다.
2. 비고유 인덱스
•
고유 인덱스에서 Unique 속성만 제거했다고 보면 된다.
•
데이터가 신규 입력되어 인덱스가 재정렬되더라도 인덱스 열의 중복 체크를 거치지 않고 단순한 정렬 작업을 수행한다.
ALTER TABLE 학생
ADD INDEX 이름_인덱스(이름);
SQL
복사
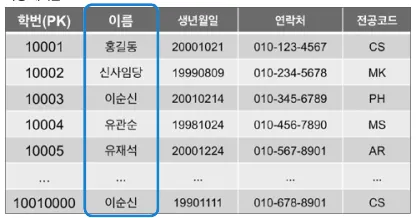
논리적인 SQL 개념 용어
서브쿼리 위치에 따른 SQL 용어

서브쿼리: 쿼리안의 보조 쿼리
가장 바깥쪽의 SELECT문인 메인 쿼리를 기준으로 내부에 SELECT 문을 추가로 작성해 서브쿼리를 만든다. 이러한 내부 SELECT문은 위치에 따라 부르는 용어가 달라지는데, 크게 SELECT절, FROM절, WHERE절로 나뉜다.
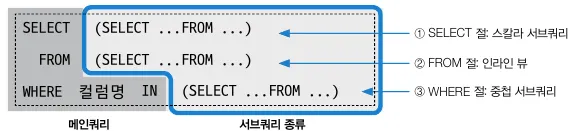
서브쿼리 위치별 SQL 용어
1. 스칼라 서브쿼리
•
메인쿼리의 SELECT 절에 있는 또 다른 SELECT절을 스칼라 서브쿼리라 한다.
•
SELECT절에는 최종 출력하는 열들이 나열되기에 스칼라 서브쿼리의 결과 건수와 일치해야 한다.
◦
서브쿼리 결과값이 2개 이상 나올 경우 에러가 발생
2. 인라인뷰
•
FROM절에 있는 SELECT 절을 인라인 뷰라고 한다.
•
내부에서 일시적으로 뷰를 생성하는 방식이기에 인라인뷰라고 불린다.
•
인라인 뷰의 결과는 내부적으로 메모리나 디스크에 임시 테이블을 생성해 활용한다.
3. 중첩 서브쿼리
•
WHERE 절에 있는 SELECT절을 중첩 서브쿼리라 한다.
•
보통 비교연산을 위해 사용하며 비교 연산자를 비롯해 IN, EXISTS, NOT IN, NOT EXISTS 등을 많이 사용한다.
메인쿼리와의 관계성에 따른 SQL용어
1. 비상관 서브쿼리
메인쿼리와 서브쿼리간에 관계성이 없음을 의미하는데, 서브쿼리가 메인쿼리의 요소를 사용하지 않고 독자적으로 동작하는 쿼리임을 의미한다.
SELECT ...
FROM 학생
WHERE 학생.학번 in ( SELECT 학번
FROM 지도교수
WHERE 지도교수.이름 = '홍길동' )
SQL
복사
메인쿼리와 서브쿼리간의 연관성이 없다.
•
서브쿼리가 먼저 실행된 이후 해당 결과를 메인쿼리가 활용하기에 서브쿼리 → 메인쿼리 실행순서를 가진다.
참고: View merging(SQL Rewrite)비상관 서브쿼리는 DB버전이나 옵티마이저에 따라 서브쿼리가 제거되고 메인쿼리로 통합되는 뷰 병합이 작동할 수도 있다.
SELECT *
FROM 학생
WHERE 학번 IN(SELECT 학번
FROM 학생
WHERE 성별 = '남')
SQL
복사
2. 상관 서브쿼리
메인쿼리와 서브쿼리간에 관계성이 있음을 의미하는데, 비상관 서브쿼리와 반대로 서브쿼리에서 메인쿼리의 요소들을 사용할 경우 상관 서브쿼리라 할 수 있다.
SELECT ...
FROM 학생
WHERE 학생.학번 in ( SELECT 학번
FROM 지도교수
WHERE 학생.학번 = '123' )
SQL
복사
메인쿼리와 서브쿼리간의 연관성이 있다.
•
전체적인 수행 순서는 다음과 같다. 비상관 서브쿼리와 다르게 메인쿼리부터 실행된다.
1.
메인 쿼리 실행(학생.학번 데이터 가져오기)
2.
서브 쿼리 실행(지도교수.학번 = 학생.학번)
3.
메인 쿼리 실행(SELECT * FROM 학생 ~)
•
이때도 DB버전 및 옵티마이저에 따라 View Merging이 작동할 수 있다.
반환 결과에 따른 SQL 용어
1. 단일행 서브쿼리
•
서브쿼리 결과가 1건의 행으로 반환되는 쿼리
•
메인쿼리의 조건절에서는 비교 연산자등(=, <, >)을 사용해 비교한다.
•
스칼라 서브쿼리와 동일하다고 볼 수 있다.
SELECT *
FROM 학생
WHERE 학번 IN(SELECT MAX(학번)
FROM 학생)
SQL
복사
출력값이 하나인 서브쿼리(단일행 서브쿼리)
2. 다중행 서브쿼리
•
서브쿼리 결과가 여러 건의 행으로 반환되는 쿼리
•
메인쿼리의 조건절에서는 IN 구문으로 반환되는 값들을 받는다.
SELECT *
FROM 학생
WHERE 학번 IN(SELECT MAX(학번)
FROM 학생
GROUP BY 전공코드)
SQL
복사
출력값이 2개 이상인 서브 쿼리
3. 다중열 서브쿼리
•
서브쿼리 결과가 여러 열과 행으로 반환되는 쿼리
•
메인쿼리 조건절에서는 IN구문과 함께 서브쿼리에서 반환될 열들을 동일하게 나열해서 받는다.
SELECT *
FROM 학생
WHERE (이름, 전공코드) IN(SELECT 이름, 전공코드
FROM 학생
WHERE 이름 LIKE '김%')
SQL
복사
조인 알고리즘 용어
1. 드라이빙 테이블과 드리븐 테이블
SELECT 학생.학번, 학생.이름, 비상연락망.관계, 비상연락망.연락처
FROM 학생
JOIN 비상연락망
ON 학생.학번 = 비상연락망.학번
WHERE 학생.학번 IN (1, 100)
SQL
복사
학생,비상연락망 조인 쿼리
이 쿼리는 학생의 학번이 1이거나 100인 학생의 학생정보와 비상연락망 정보를 조회하는 SQL문이다. 즉, 쿼리는 학생 테이블에서 우선 학번이 일치하는 정보를 먼저 찾을 것이고 그 이후 해당 정보를 토대로 학번과 매칭되는 비상연락망 테이블의 정보를 검색할 것이다.
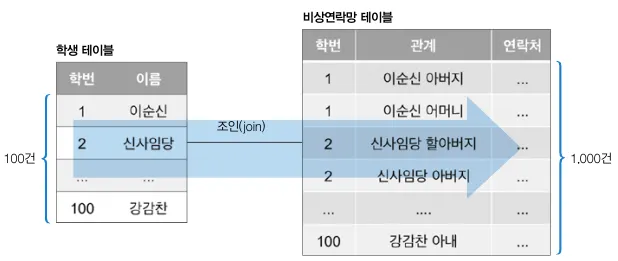
드라이빙 테이블과 드리븐 테이블
•
먼저 접근하는 테이블을 드라이빙 테이블(= OUTER TABLE)
•
결과를 통해 데이터를 검색하는 테이블을 드리븐 테이블(=INNER TABLE)
•
가능한 적은 결과가 반환될 것으로 예상되는 드라이빙 테이블을 선정하고, 조인 조건절의 열이 인덱스로 설정되도록 구성해야 한다.
2. 중첩 루프 조인
•
중첩 루프 조인(nested loop join, NL join)은
◦
드라이빙 테이블의 데이터 1건당
◦
드리븐 테이블을 반복해 검색하며
◦
최종적으로 양쪽 테이블에 공통된 데이터를 출력한다.
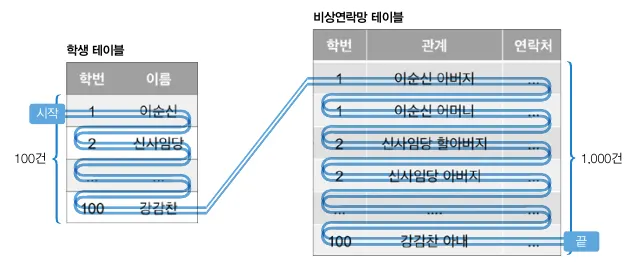
극단적인 중첩 루프 조인 개념도
1.
학번 1을 학생 테이블에서 검색하고자 학생 테이블 100건에 모두 접근한다.
2.
학번 1과 동일한 데이터를 가졌는제 매칭하기위해 비상연락망 테이블 1,000건에 모두 접근한다.
3.
학번 100을 학생 테이블에서 검색하고자 학생 테이블 100건에 모두 접근한다.
4.
학번 100과 동일한 데이터를 가졌는제 매칭하기위해 비상연락망 테이블 1,000건에 모두 접근한다.
결론적으로 결과를 반환하기 위해 학번 1(100 + 1,000)과 학번 100(100 + 1,000) 총 2,200건의 데이터에 접근해야 한다. 위 그림 예시에선 데이터가 정렬 되있다고 가정했으나 실제로는 데이터가 뒤엉켜있을 확률이 높다.
그렇다면 학생과 비상연락망 테이블에 학번 열로 인덱스가 생성되어 있다면 얼마나 비용이 줄어들까? 인덱스가 생성되어 있다는 가정하에
1.
학번 1인 데이터는 학생 인덱스에 접근 이후 비상연락망 인덱스에 접근한다.
2.
학번 100인 데이터는 학생 인덱스에 접근 이후 비상연락망 인덱스에 접근한다.
인덱스를 기반으로 접근하기에 다음 그림과 같이 총 6건의 데이터에 접근하게 된다.

인덱스가 있을 경우의 중첩 루프 조인 개념도
인덱스의 경우 인덱스로 정의된 열 기준으로 순차 정렬되지만, 인덱스를 이용해 테이블의 데이터를 찾아가는 과정에선 랜덤 액세스가 발생한다. 그렇기에 랜덤 액세스를 줄일 수 있도록 데이터의 액세스 범위를 좁히는 방향으로 인덱스를 설계하고 사용해야 한다.
3. 블록 중첩 루프 조인
•
접근하는 테이블 중 인덱스가 없는 테이블이 있을 경우 전체 데이터를 비효율적으로 참고해야하는데 이런 비효율성을 개선하기 위해 블록 중첩 루프 조인(block nested loop join, BNL Join)이 탄생했다.
•
드라이빙 테이블에 대해 조인 버퍼(Join buffer) 라는 개념을 도입해 조인 성능의 향상을 기대한다.
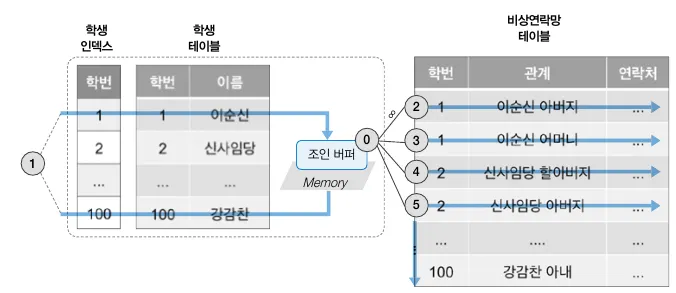
1.
드라이빙 테이블인 학생 테이블에서 1, 100 학번의 데이터를 검색한다.
2.
검색된 데이터를 조인 버퍼에 가득 채워질때까지 적재한다.
3.
조인버퍼와 비상연락망 테이블의 데이터를 비교한다.
a.
조인버퍼와 ② 데이터를 조인하고,
b.
조인 버퍼와 ③ 데이터를 조인하는 식으로 반복해 비상연락망 모든 데이터에 접근한다.
4.
한 번의 테이블 풀 스캔으로 원하는 데이터를 모두 찾을 수 있다.
•
블록 해시 조인 방식은 BNL Join과 과정이 유사해 추가 설명은 생략한다.
4. 배치 키 액세스 조인
•
접근할 데이터를 미리 예상하고 가져오는데 착안한 조인 알고리즘
(batched key access join, BKA Join)
•
블록 중첩 루프 조인에서 활용한 드라이빙 테이블의 조인 버퍼 개념을 그대로 사용하는데 추가적으로 드리븐 테이블에 필요한 데이터를 미리 예측하고 정렬된 상태로 담는 랜덤 버퍼의 개념을 도입한다.
•
미리 예측된 데이터를 가져와 정렬된 상태에서 랜덤 버퍼에 담기 때문에, 랜덤 액세스가 아닌 시퀀셜 액세스를 수행한다.
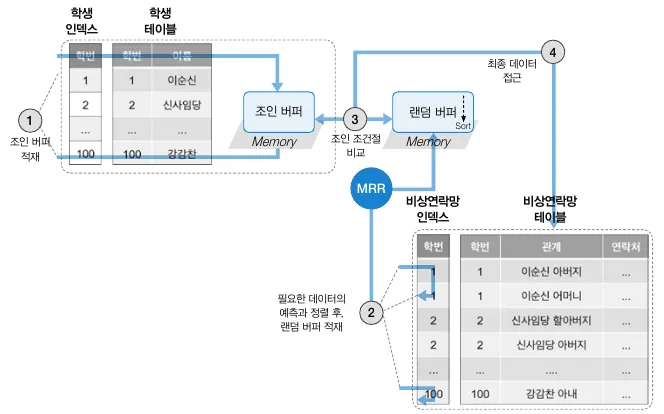
1.
드라이빙 테이블에서 필요한 데이터를 추출해 조인 버퍼에 적재한다.
2.
드리븐 테이블의 인덱스 기반으로 필요한 데이터를 예측해 랜덤 버퍼에 적재한다.
3.
학생.학번 = 비상연락만.학번 조건절을 사용하는 조인 조건절로 비교한다.
4.
동일한 데이터가 있다고 판단되면 드리븐 테이블의 데이터에 접근해 결과를 조인해 반환한다.
5. 해시 조인
•
MySQL 8.0.18부터 지원하는 조인 방식이다.
◦
MaraiDB에선 5.3 이후 블록 중첩 루프 해시라는 이름으로 지원한다.
•
조인에 참여하는 테이블의 데이터를 내부적으로 해시값으로 만들어 내부 조인을 수행한다.
•
해시값으로 내부 조인을 수행한 결과는 조인 버퍼에 저장되기에 조인열의 인덱스를 필수로 요구하지 않는다.
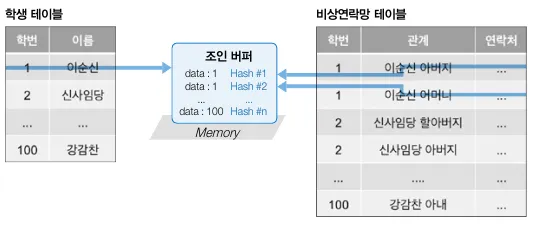
학생 테이블의 학번1 데이터는 내부적으로 생성된 해시값과 비상연락망 테이블의 학번 1의 해시값을 비교해 서로 동일한 경우 조인 버퍼에 저장한다.
개념적인 튜닝 용어
오브젝트 스캔 유형
•
테이블 스캔과 인덱스 스캔으로 구분하며
◦
테이블 스캔은 인덱스를 거치지 않고 디스크에 위치한 테이블 데이터에 접근하는 유형
◦
인덱스 스캔은 인덱스로 테이블 데이터를 찾아가는 유형
•
테이블 스캔은
◦
테이블 풀 스캔 방식이 있다.
•
인덱스 스캔은
◦
인덱스 범위 스캔
◦
인덱스 풀 스캔
◦
인덱스 고유 스캔
◦
인덱스 루스 스캔
◦
인덱스 병합 스캔 방식이 있다.
테이블 풀 스캔
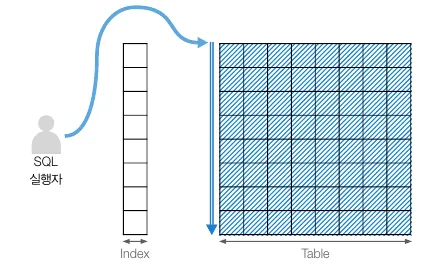
테이블 풀 스캔 개념도
•
인덱스를 거치지 않고 바로 테이블의 전체 데이터를 탐색하는 방식
•
조건절 기준 활용할 인덱스가 없거나 전체 데이터 대비 대량의 데이터가 필요한 경우 수행한다.
•
성능 측면에서는 가장 떨어진다.
인덱스 범위 스캔

인덱스 범위 스캔 개념도
•
인덱스를 범위 기준으로 스캔해 결과를 토대로 데이터를 찾는 방식
◦
BETWEEN A AND B나 <, >, like 구문과 같은 구문이 포함될 경우 해당된다.
•
범위가 넓어질수록 비효율적인 방식이다.
인덱스 풀 스캔
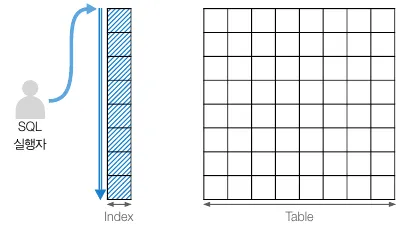
인덱스 풀 스캔 개념도
•
인덱스를 전체 탐색하는 방식
•
테이블에 접근하지 않고 인덱스로 구성된 열 정보만 요구하는 쿼리에서 사용된다.
•
테이블 풀 스캔보단 빠르지만 풀 스캔 특성상 줄일 수 있는 노력이 필요하다.
인덱스 고유 스캔
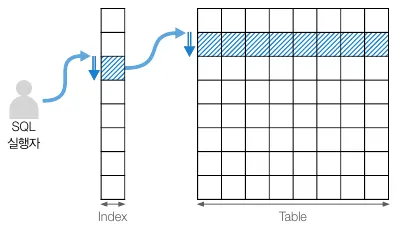
인덱스 고유 스캔
•
기본키나 고유 인덱스로 테이블에 접근하는 방식
•
인덱스 사용 방식 중 가장 효율적인 스캔 방식이다.
•
WHERE 절에 =조건으로 동작한다.
•
혹은 해당 조인 열이 기본 키이거나 고유 인덱스의 선두 열로 설정되었을 때 활용한다.
인덱스 루스 스캔
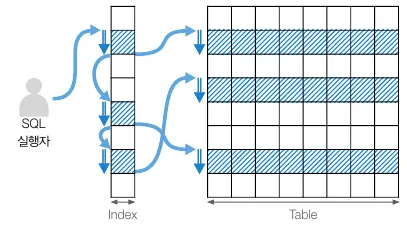
인덱스 루스 스캔 개념도
•
인덱스의 필요한 부분들만 골라 스캔하는 방식
•
WHERE 절 조건문 기준 필요한 데이터와 아닌 데이터를 구분해 불필요 인덱스 키는 무시
•
GROUP BY, MAX, MIN 함수등이 포함될 경우 사용된다.
인덱스 병합 스캔

•
테이블 내에 생성된 인덱스들을 통합해서 스캔하는 방식
•
WHERE문의 조건절의 열들이 서로 다른 인덱스로 존재할 경우 옵티마이저가 해당하는 인덱스를 가져와 활용한다.
•
통합 방식은 결합(Union), 교차(Intersection) 방식이 있다.
•
개별 인덱스를 각각 수행하기에 시간이 오래걸린다.
◦
별개로 생성된 인덱스들을 하나로 통합하는 튜닝을을 하거나
◦
쿼리가 하나의 인덱스만 사용하도록 변경해 성능을 높힐 수 있다.
디스크 접근 방식
원하는 데이터를 찾기 위해선 데이터가 저장된 스토리지의 페이지에 접근할 필요가 있는데, 페이지란 데이터 검색 최소 단위를 뜻하며 페이지 단위로 데이터 Read/Write를 수행한다.
여기서 페이지를 순차적으로 읽는 것을 시퀀셜 액세스, 임의로 열어 읽는 것을 랜덤 액세스라 한다.
시퀀셜 액세스
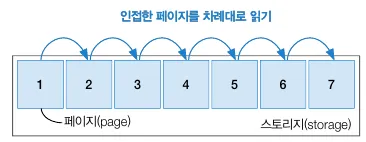
시퀀셜 액세스 개념도
•
물리적으로 인접한 페이지를 차례대로 읽는 순차 접근 방식
•
테이블 풀 스캔에서 보통 사용한다.
•
테이블 풀 스캔일 때 다중 페이지 읽기 방식으로 수행한다.
랜덤 액세스
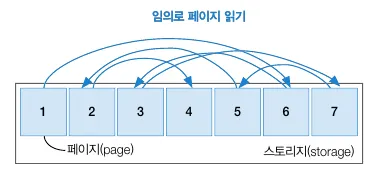
랜덤 액세스 개념도
•
물리적으로 떨어진 페이지들에 임의로 접근해 읽는 방식
•
접근 순서가 임의적이기에 디스크의 물리적인 움직임(오버헤드)이 발생한다.
•
다중 페이지 읽기가 불가능하기에 데이터 접근 수행 시간이 오래 걸린다.
•
최소한의 데이터 접근이 가능하게 접근 범위를 줄여야 한다.
조건 유형
SQL은 조건절을 기준으로 데이터가 저장된 디스크에 접근하는데, 맨 처음 디스크에서 데이터를 검색하는 조건을 액세스 조건이라 하고, 디스크에서 가져온 데이터를 추가적으로 추출 및 가공, 연산하는 조건을 필터 조건이라 한다.
액세스 조건
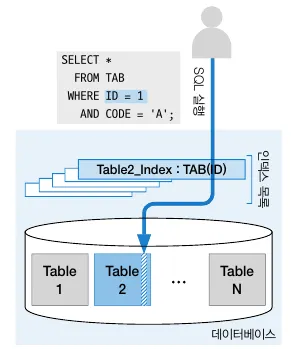
액세스 조건 예제
•
디스크에 있는 데이터에 어떻게 접근 할 지를 다루는 조건을 액세스 조건이라 한다.
•
위 예제는 WHERE 조건 절에 ID가 1이고 CODE가 ‘A’라는 조건문이 있지만
◦
ID열로 생성된 인덱스를 활용해 TABLE2 테이블의 데이터에 접근한다.
◦
만약 CODE=’A’ 조건문을 액세스 조건으로 삼을 경우 인덱스 활용 없이 테이블 풀 스캔을 해야 한다.
필터 조건

필터 조건 예제
•
액세스 조건을 이용해 MySQL 엔진으로 가져온 데이터를 기준으로 불필요 데이터 제거 및 가공하는 조건
•
디스크에서 가져온 데이터를 CODE=’A’ 필터조건으로 필터링을 수행한다.
•
필터랑 되는 데이터가 많을수록 쿼리는 비효율적이다.
•
필터 조건으로 제거될 데이터는 애초에 스토리지 엔진의 데이터 접근 과정에서 같이 제외되는 게 효율적이다.
•
실행 계획의 filtered 항목에서 필터조건으로 제거되는 데이터 비율을 확인할 수 있다.
힌트

SQL문을 이용해 데이터에 접근할 때 더 효율적으로 접근할 수 있도록 추가 정보를 제공하는게 힌트다.
다음과 같은 테이블과 인덱스 정보가 있다고 가정할 때
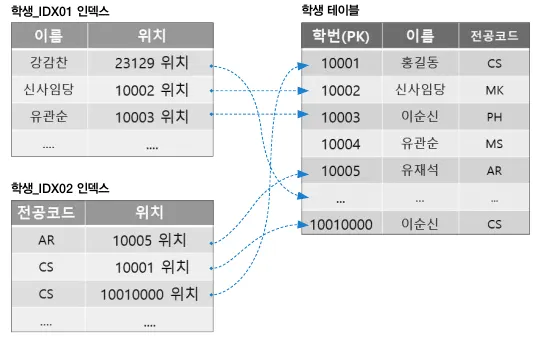
학생 테이블과 관련 인덱스 구조
•
다음과 같이 /*! */ 형태의 주석으로 힌트를 명시해서 사용할 수 있다.
SELECT 학번, 전공코드
FROM 학생 /*! USE INDEX ( 학생_IDX01) */
WHERE 이름 = '유재석';
SQL
복사
학생_IDX01 인덱스를 활용해 데이터에 접근하겠다는 힌트를 제공하는 SQL문
•
다음과 같이 주석 표기 없이 쿼리의 일부로 작성할 수도 있다.
SELECT 학번, 전공코드
FROM 학생 USE INDEX ( 학생_IDX01)
WHERE 이름 = '유재석';
SQL
복사
MySQL과 MariaDB에서 사용할 수 있는 힌트는 다양한데 자주 쓰이는 힌트는 다음과 같다.
힌트 | 설명 | 활용도 |
STRAIGHT_JOIN | FROM 절에 작성된 테이블 순으로 조인을 유도한다. | 높음 |
USE INDEX | 특정 인덱스를 사용하도록 유도한다. | 높음 |
FORCE INDEX | 특정 인덱스를 사용하도록 강하게 유도한다 | 낮음 |
IGNORE INDEX | 특정 인덱스를 사용하지 못하도록 유도한다 | 중간 |
물론, 옵티마이저는 힌트가 비효율적이라고 예측할 경우 사용자가 제안한 힌트를 무시할 수 있다.

