
목차
개요

한 사람의 영향도가 너무 큰 시스템은 성공하기 어렵다. 초기 설계가 완료되고 상당히 견고해지면 여러 사람이 다양한 관점을 가지고 각각 실험을 진행하며 실제 테스트가 시작된다.
- 도널드 크누스
요즘 많은 데이터 시스템에서 제공하는 데이터 처리 방식은 요청 혹은 지시를 보낸 후 시스템으로부터 결과를 반환받는 방식이다. DB, 캐시, 검색 색인, 웹 서버 등 많은 시스템에서 이런 방식으로 동작한다.
특히 웹과 같은 HTTP/REST기반 API 때문에 요청/응답 방식의 상호작용이 매우 흔해져서 당연하게 여기기 쉽지만, 이 방법만이 시스템을 구축하는 유일한 방법은 아니다.
서비스(온라인 시스템)
: 서비스는 클라이언트로부터 요청이나 지시가 올 때까지 기다린다.
요청 하나가 들어오면 서비스는 가능한 빨리 요청을 처리한 뒤 응답을 되돌려 보내려 하며 이 응답 시간이 서비스의 성능 측정에 중요한 지표가 된다.
일괄 처리 시스템(오프라인 시스템)
: 매우 큰 입력 데이터를 받아 데이터를 처리하는 작업을 수행하고 결과 데이터를 생산한다.
작업 시간이 크기에 대게 사용자가 작업이 끝날 때까지 기다리지 않는다.
대신 하루 혹은 일주일에 한 번 특정 시간대에 반복적인 일정으로 수행한다. 일괄 처리 작업에서는 처리량이 중요한 성능 지표가 된다.
스트림 처리 시스템(준실시간 시스템)
온라인과 오프라인/일괄 처리 사이 어딘가에 있기에 준실시간 처리(near-real-time processing or nearline processing)라 불린다.
일괄처리 시스템과 마찬가지로 요청에 대해 응답하지 않고 입력 데이터를 소비하고 출력 데이터를 생산한다. 다만, 스트림 처리는 입력 이벤트 발생 직후 작동한다는 차이가 있어서 일괄 처리 시스템보다는 지연 시간이 낮다.
이번 포스팅에서는 위 세 가지 시스템 구축 방식 중 일괄 처리에 대해 살펴볼 것인데, 일괄 처리는 신뢰성, 유지보수성, 확장성을 만족하는 시스템을 구축하는데 중요한 방식으로, 예를 들어 일괄 처리 알고리즘 중 맵리듀스(MapReduce)는 약간 과장해서 구글의 대규모 확장성을 제공한 알고리즘으로 불린다. 이 맵리듀스는 하둡과 카우치DB, 몽고DB등 다양한 오픈소스 시스템에서 구현됐다.
이번 포스팅에서 맵리듀스와 그 밖에 다른 일괄 처리 알고리즘, 프레임워크도 살펴본다.
그리고 현대 데이터 시스템에서 이를 어떻게 사용하는지에 대해서도 알아보자.
유닉스 도구로 일괄 처리하기
갑자기 왠 유닉스 도구인가 싶을 수 있다.
하지만, 유닉스 철학을 먼저 살펴보고 (이미 익숙한 사람도) 되새겨보는 것도 가치가 있다.
유닉스가 주는 아이디어와 교훈이 대규모 이기종 분산 시스템으로 그대로 이어진다.
웹 서버가 하나 있다고 하고, 요청이 처리될 때마다 로그 파일에 한 줄씩 추가한다고 할 때
다음 예는 로그 중 한줄로 nginx의 기본 액세스 로그 형식을 사용한다.
216.58.210.78 - - [27/Feb/2015:17:55:11 +0000] "GET /css/typography.css HTTP/1.1"
200 3377 "http://martin.kleppmann.com/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.115 Safari/537.36
Plain Text
복사
이 로그는 해석하기 위해 포맷이 필요한데 이는 다음과 같다.
$remote_addr - $remote_user [$time_local] "$request"
$status $body_bytes_sent "$http_referer" "$http_user_agent"
Plain Text
복사
이 포맷을 기반으로 로그를 분석하면 2015년 2월 27일 UTC 17시 55분 11초에 서버가 클라이언트 IP 주소 216.58.210.78로부터 /css/typography.css 파일에 대한 요청을 받았음을 가리킨다. 비인증 사용자이기에 $remote_user가 하이픈(-)으로 표시됐다.
응답 상태는 200으로 요청은 성공했고 응답 크기는 3,377 바이트였다. 웹 브라우저는 크롬40이고 파일이 http://martin.kleppmann.com/ 이라는 url에서 참조됐다.
단순 로그 분석
이러한 로그를 항상 직접 하나하나 분석할순 없다. 기본 유닉스 도구를 통해 직접 분석해보자.
예를 들어 웹 사이트에서 가장 인기가 높은 페이지 5개를 뽑는다고 하면 유닉스 셸에서 다음과 같이 작성할 수 있다.
cat /var/log/nginx/access.log | -- 1
awk '{print $7}' | -- 2
sort | -- 3
uniq -c | -- 4
sort -r -n | -- 5
head -n 5
Bash
복사
1.
로그를 읽는다.
2.
줄마다 공백으로 분리해서 요청 URL에 해당하는 7번째 필드만 출력한다.
•
예제상 요청 URL은 /css/typography.css가 된다.
3.
요청 URL을 알파벳 순으로 정렬한다. 특정 URL이 n번 요청되면 정렬 후엔 이 URL이 연속해서 n번 반복된다.
4.
uniq 명령은 인접한 두 줄이 같은지 확인해 중복을 제거한다.
•
-c는 중복 횟수를 함께 출력하는 옵션이다.
5.
-n 옵션으로 매 줄 첫 번째로 나타나는 숫자를 기준으로 정렬하고,
•
-r 옵션으로 내림차순 정렬한다.
6.
마지막으로 head 명령을 사용해 앞에서부터 5줄(-n 5)만 출력한다.
이처럼 실제로 많은 데이터 분석이 수 분 내에 awk, sed, grep, sort, uniq, xargs의 조합으로 결과를 얻을 수 있다.
참고: unix 명령어
•
awk: 각 줄을 필드로 분할하여 처리.
•
sed: 스트림 편집기로 파일이나 스트림의 텍스트를 변환하거나 필터링하는 데 사용한다.
•
grep: 파일에서 일치하는 문자열을 찾는다
•
sort: 파일 내용을 정렬
•
uniq: 파일에서 중복된 줄 제거
•
xargs: 명령 줄 인수를 생성하고 명령을 실행하는 데 사용한다.
정렬 vs 인메모리 집계
집계할 데이터의 양과 허용 메모리의 크기에 따라 달라진다.
•
데이터가 허용 메모리보다 적은 경우
◦
인메모리 해시 테이블에서도 잘 동작한다.
•
데이터가 허용 메모리보다 큰 경우
◦
정렬 접근법을 고려해볼 수 있다.
◦
데이터 청크를 메모리에서 정렬하고 청크를 세그먼트 파일로 디스크에 저장한 뒤, 각 세그먼트 파일 여러 개를 한 개의 큰 정렬 파일로 병합한다. 병합 정렬은 순차적 접근 패턴을 따르고 이 패턴은 디스크 상에서 좋은 성능을 낼 수 있다.
유닉스 철학
•
각 프로그램이 한 가지 일만 하도록 작성하라.
◦
새 작업을 하려면 기존 프로그램을 고쳐 확장하기보단 새로운 프로그램을 작성하라.
•
모든 프로그램의 출력은 어디서든 입력으로 사용될 수 있다고 생각하라.
◦
출력이 너저분해서는 안된다.
▪
Ex: 이진 형태, 엄격한 열 맞춤 등
◦
대화형 입력을 고집하지 마라
•
소프트웨어를 빠르게 써볼 수 있게 설계하고 구축하라.
•
프로그래밍 작업을 줄이려면 도구를 사용하라.
사실상 요즘 현대적인 개발 방법론들과도 크게 다르지 않다.(Ex: Agile, DevOps)
동일 인터페이스
유닉스는 동일한 입출력 인터페이스를 사용해서 호환성을 높힌다.
유닉스에서의 인터페이스는 파일 디스크립터로 단순하게 순서대로 정렬된 바이트의 연속이다.
단순하기 때문에 동일한 인터페이스로
•
파일시스템의 실제 파일
•
프로세스 간 통신 채널(유닉스 소켓, 표준 입력(stdin), 표준 출력(stdout))
•
장치 드라이버(/dev/audio, /dev/lp0등)\
•
TCP 연결을 나타내는 소켓
등 다른 여러가지 것을 표현할 수 있다.
로직과 연결의 분리
유닉스에선
•
표준 입력(stdin)
•
표준 출력(stdout)
을 사용해서 키보드와 같은 입력장치로 입력을 받아 화면으로 출력한다.
혹은 파일에서 입력을 가져와 다른 파일로 출력을 재전송할 수도 있다.
파이프는 한 프로세스의 stdout을 다른 프로세스의 stdin과 연결한다.

이 경우 프로그램은 입력이 어디서부터 들어오는지 출력이 어디로 가는지 신경쓸 필요도 없는데, 이런 형태를 느슨한 결합(loose coupling)이나 지연 바인딩(late binding) 혹은 제어 반전(inversion of control)이라고도 한다.
하지만, stdin, stdout사용시 몇 가지 제약 사항이 있는데
•
프로그램의 출력을 파이프를 이용해 네트워크와 연결할 순 없다.
◦
파일을 직접 열거나, 서브프로세스로 네트워크 연결을 할 경우 프로그램의 I/O는 그 프로그램 자체와 서로 묶이게 된다.
투명성과 실험
유닉스 도구는 진행사항을 파악하기가 쉽다.
•
유닉스 명령에 들어가는 입력 파일은 일반적으로 불변으로 처리된다.
◦
다양한 명령행 옵션을 사용하더라도 입력 파일은 손상되지 않는다.
•
어느 시점에서든 파이프라인을 중단하고 출력을 파이프를 통해 less로 보내 원하는 형태의 출력이 나오는지 확인이 가능하다.
•
특정 파이프라인 단계의 출력을 파일에 쓰고 그 파일을 다음 단계의 입력으로 사용할 수 있다.
유닉스 도구를 사용하는데 가장 큰 제약은 단일 장비에서만 실행된다는 점이다.
(그래서 하둡과 같은 도구가 필요하다.)
왜 하둡과 같은 도구가 필요할까?
1. 분산 처리: 하둡은 대용량 데이터를 여러 노드에 분산시켜 처리할 수 있는 HDFS(Hadoop Distributed File System)을 사용하기에 대규모 데이터 세트를 처리하는데 효율적이다.
2. 병렬 처리: MapReduce 프레임워크를 사용해 병렬 처리를 지원한다.
그 밖에 내결함성, 확장성, 데이터 저장에서 유리하며 유닉스 도구의 한계를 극복한다.
맵리듀스와 분산 파일 시스템
맵 리듀스는 유닉스 도구와 비슷해보이지만, 대규모 분산 처리가 가능하다는 차이가 있다.
맵 리듀스는 유닉스 도구와 비슷하지만, 대규모 분산 처리를 지원한다. 입출력은 HDFS(Hadoop Distributed File System)라는 분산 파일 시스템을 사용하며, 이는 구글의 GFS를 기반으로 한다.
HDFS는 비공유 원칙에 기반하며 일반 컴퓨터로 구성됩니다. 데몬 프로세스가 실행되어 다른 노드가 파일에 접근할 수 있게 한다. 네임노드라는 중앙 서버가 파일 블록의 위치를 추적한다.
HDFS는 분산된 하나의 큰 파일 시스템으로 간주되며, 장비 실패에 대비하여 파일 블록이 여러 장비에 복제된다.. 여러 복제 방식이 있으며, 저장소 부담을 줄이는 삭제 코딩 방식도 사용된다.
HDFS는 RAID와 유사하나, 특별한 하드웨어 없이 일반 데이터 센터 네트워크에서 동작합니다. HDFS의 확장성이 뛰어나며, 비용 효율적인 대규모 데이터 저장 및 접근을 가능하게 한다.
맵리듀스 작업 실행하기
맵리듀스는 HDFS같은 분산 파일 시스템 위에서 대용량 데이터셋을 처리하는 코드를 작성하는 프로그래밍 프레임워크다. 이러한 맵리듀스의 데이터 처리 패턴은 로그 분석 예와 비슷하다.
1.
입력 파일을 읽고, 레코드로 쪼갠다.
•
웹 서버 로그 예제에서 로그의 각 줄이 레코드가 된다.
•
레코드 분리자로 \n을 사용한다.
2.
각 입력 레코드마다 매퍼 함수를 호출해 키와 값을 추출한다.
•
ex: aws ‘{print $7}’ 이 매퍼함수이고 URL($7)을 키로 추출하며 값은 빈 값으로 한다.
3.
키를 기준으로 키-값 쌍을 모두 정렬한다. 이 과정은 로그 예제에서 첫 번째 sort 명령에 해당한다.
4.
정렬된 키-값 쌍 전체를 대상으로 리듀스 함수를 호출한다.
맵 리듀스 작업 하나는 4가지 단계로 수행하는ㄷ 2단계(맵)과 4단계(리듀스)는 사용자가 직접 작성한 데이터 처리 코드다. 맵 리듀스 작업을 생성하려면 다음과 같이 동작하는 매퍼와 리듀서라는 두 가지 콜백 함수를 구현해야 한다.
•
매퍼(Mapper)
: 매퍼는 모든 입력 레코드마다 한 번씩만 호출되며 입력 레코드로부터 다음 레코드까지 상태를 유지하지 않기 때문에 각 레코드를 독립적으로 처리한다.
•
리듀서(Reducer)
: 맵리듀스 프레임워크는 매퍼가 생산한 키-값 쌍을 받아 같은 키를 가진 레코드를 모으고 해당 값의 집합을 반복해 리듀서 함수를 호출한다. 리듀서는 출력 레코드를 생산한다.
맵리듀스의 분산 실행
맵리듀스는 병렬로 수행하는 코드를 직접 작성하지 않고도 여러 장비에서 동시에 처리가 가능하다.
매퍼와 리듀서는 한 번에 하나의 레코드만 처리하고 입력이 어디서 오는지 출력이 어디로 가는지 신경 쓰지 않는다. 맵리듀스 프레임워크가 장비 간 데이터가 이동하는 복잡한 부분을 처리하기 때문이다.
다음 그림은 하둡 맵리듀스 작업에서의 데이터플로를 보여준다.
맵리듀스 작업의 병렬 실행은 파티셔닝을 기반으로하고, 작업 입력으로 HDFS상의 디렉터리를 사용하는 것이 일반적이고, 입력 디렉터리 내 각 파일 또는 파일 블록을 독립된 맵 태스크에서 처리할 독립 파티션으로 간주한다.
그림에서 맵 태스크를 m1, m2, m3로 표시했다.
각 입력 파일은 보통 그 크기가 수백 메가바이트에 달한다. 그림에는 없지만 각 매퍼 입력 파일의 복제본이 있는 장비에 RAM과 CPU에 여유가 충분하다면 맵리듀스 스케줄러가 입력 파일이 있는 장비에서 작업을 수행하려 한다. 이 원리를 데이터 가까이에서 연산하기라 하는데, 이 원리를 적용하면 네트워크를 통해 입력 파일을 복사하는 부담과 네트워크 부하가 감소하고 지역성이 증가한다.
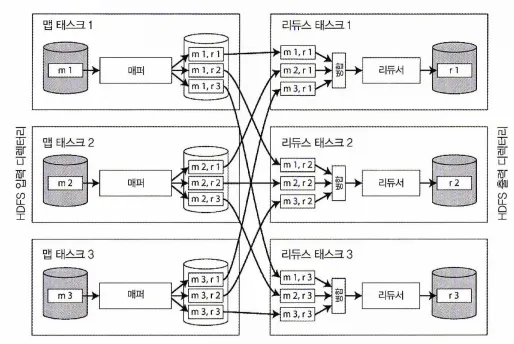
매퍼 3개와 리듀서3개로 구성된 맵리듀스 작업
•
맵 태스크의 수는 입력 파일의 블록 개수(위에서는 m1, m2, m3 세 개)로 결정되고 리듀스 태스크는 사용자가 설정할 수 있다.
◦
맵 태스크의 수는 클러스터의 하드웨어 구성, 데이터의 크기, 작업의 복잡도 등 여러 요소에 따라 결정될 수 있다.
•
매퍼의 출력은 키-값 쌍으로 구성된다.
•
같은 키를 가진 모든 키-값 쌍을 같은 리듀서에서 처리하는 것을 보장한다.
•
키-값 쌍은 반드시 정렬돼야 하지만 대게 데이터셋이 매우 크기 때문에 일반적인 정렬 알고리즘으로 한 장비에서 모두 정렬하기는 어렵기 때문에 단계를 나눠 정렬을 수행한다.
◦
각 맵 태스크는 키의 해시값을 기반으로 출력을 리듀서로 파티셔닝한다.
◦
그 다음 각 파티션을 매퍼의 로컬 디스크에 정렬된 파일로 기록한다.
•
기록이 완료되면 맵리듀스 스케줄러는 매퍼에서 출력 파일을 가져올 수 있다고 리듀서에게 알려준다.
•
리듀서는 각 매퍼와 연결해 리듀서가 담당하는 파티션에 해당하는 키-값 쌍 파일을 다운로드한다.
◦
이 키-값 쌍은 반드시 정렬되야하는 것은 아니고 정렬이 필요한 경우 사용자가 지정한 함수를 기반으로 정렬된다.
•
리듀서를 기준으로 파티셔닝, 정렬, 매퍼로부터 데이터 파티션을 복사하는 과정을 셔플(shuffle)이라 한다.
•
리듀스 태스크는 매퍼로부터 파일을 가져와 정렬된 순서를 유지하며 병합한다.
◦
매퍼와 리듀서는 서로 다른 머신에서 실행되는데, 이 때 데이터 전송에 네트워크 비용이 발생할 수 있다.
•
리듀서는 키와 반복자(iterator)를 인자로 호출하는데, 이 반복자로 전달된 키와 동일한 키를 가진 레코드를 모두 훑을 수 있다.
•
리듀서는 임의의 로직을 사용해 이 레코드들을 처리하고 여러 출력 레코드를 생성할 수 있으며 이 출력 레코드는 분산 파일 시스템에 파일로 기록된다.
맵리듀스 워크플로
로그 분석 예제에서 단일 맵리듀스 작업으로 URL당 페이지뷰 수를 구할 수는 있지만, 가장 있기 있는 URL을 구할 수는 없고, 추가적인 정렬 작업이 필요하다.
떄문에 맵리듀스 작업을 연결해 워크플로(workflow)로 구성하는 방식은 일반적이다.
맵리듀스 작업 하나의 출력을 다른 맵리듀스 작업의 입력으로 사용하는 방식이다.
연결된 맵리듀스 작업은 유닉스 명령 파이프라인보단 각 명령의 출력을 임시 파일에 쓰고 다음 명령이 그 임시 파일로부터 입력을 읽는 방식에 더 가깝다. 일괄 처리 작업의 출력은 작업이 성공적으로 끝났을 때만 유효하기 때문에 워크플로 상에서 해당 작업의 입력 디렉터리를 생성하는 선행 작업이 완전히 끝나야만 다음 작업을 시작할 수 있다.
리듀스 사이드 조인과 그룹화
여러 데이터셋에서 한 레코드가 다른 레코드와 연관이 있는건 일반적이다.
RDB에서는 외래키(foreign key), 문서 모델에선느 문서 참조(document reference)라 하고 그래프 모델에선 간선(edge)라 부른다. 연관된 레코드 양쪽 모두에 접근해야 하는 코드가 있다면 조인은 필수다. 비정규화 작업으로 조인을 줄일 순 있지만 완전히 제거하기는 어렵다.
DB에서 적은 수의 레코드만 관련된 질의를 실행하면 일반적으로 색인을 사용해 빠르게 찾는다.
질의가 조인을 포함하면 여러 색인을 확인해야 할 수도 있다. 하지만, 맵리듀스에선 이러한 색인 개념이 없다. 그렇기 때문에 파일 집합이 입력으로 주어진 맵리듀스 작업이 있다면, 입력 파일 전체 내용을 읽는데 DB에서는 이를 전체 테이블 스캔(full table scan)이라 부른다.
사용자 활동 이벤트 분석 예제
다음은 일괄 처리 작업의 전형적인 조인 예제이다.
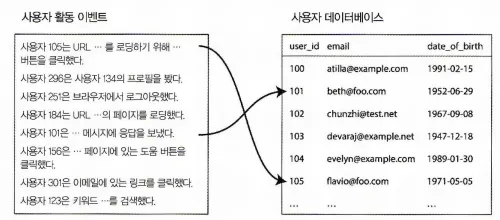
사용자 활동 이벤트 로그와 사용자 프로필 데이터베이스간 조인
•
왼쪽은 로그인 사용자가 웹사이트에서 활동한 이벤트로그
◦
활동 이벤트(activity event) 또는 클릭스트림 데이터(clickstream data))
•
우측은 사용자 데이터베이스이다.
•
사용자 활동과 사용자 프로필 정보를 연관시켜야 하는데,
◦
프로필에 나이와 생일이 있다면, 이 시스템으로 특정 연령군에서 어떤 페이지가 가장 인기있는지 확인할 수 있다.
◦
하지만, 활동 이벤트는 사용자 ID만 포함하고 있기 때문에 단일 활동 이벤트마다 모든 사용자 프로필 정보를 합치는건 비용 낭비다.
▪
그래서 활동 이벤트에 사용자 프로필 DB를 조인해야 한다.
•
이 조인을 간단하게 구현하는 방법은 활동 이벤트를 하나씩 훑으며 모든 사용자 ID마다 원격 서버에 있는 사용자 DB에 질의를 보내는 것이지만,
◦
과부하로 성능에 문제가 있을 확률이 높다.
•
따라서, DB의 사본을 가져와 사용자 활동 이벤트 로그가 저장된 분산 파일 시스템에 넣는 방법을 사용할 수 있다. 그러면 사용자 데이터베이스와 사용자 활동 레코드가 같은 HDFS 상에 존재하고 맵리듀스를 사용해 연관된 레코드끼리 모두 같은 장소로 모아 효율적으로 처리가 가능하다.
정렬 병합 조인
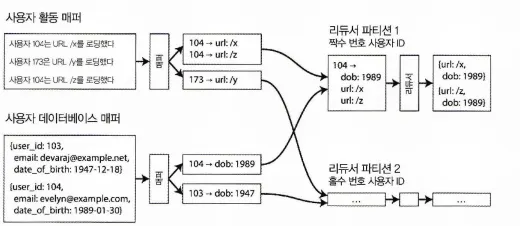
사용자 ID를 키로 하는 리듀스 측 정렬 병합 조인. 입력 데이터셋을 여러 파일로 파티셔닝해 파일 각각을 매퍼에서 병렬 처리할 수 있다.
위 그림에서 키는 사용자ID이다. 한 매퍼는 활동 이벤트에서 사용자 ID를 키로, 활동 이벤트를 값으로 추출하고 다른 매퍼는 사용자 데이터베이스를 훑어 사용자 ID를 키로 사용자 생일을 값으로 추출한다.
여기서 리듀서가 항상 사용자 DB를 먼저 보고 활동 이벤트를 시간 순으로 보게 하는 식으로 맵리듀스에서 작업 레코드를 재배열하기도 하는데 이를 보조 정렬(secondary sort)라고 한다.
보조 정렬 후 리듀서가 수행하는 실제 조인 로직은 간단하다.
•
리듀서 함수는 모든 사용자 ID당 한 번만 호출되고,
•
보조 정렬 덕에 첫 번째 값은 사용자 DB의 생년월일 레코드로 예상할 수 있다.
리듀서는 지역 변수에 생년월일을 저장하고 그 다음부터 같은 사용자 ID가 동일한 활동 이벤트를 순회해서 본 URL(viewed-url)과 본 사람의 연령(viewer-age-in-years)의 쌍을 출력한다.
그러면 맵리듀스 작업들이 각 URL마다 본 사람의 연령 분포를 계산하고 연령대별로 클러스터링 할 수 있다.
리듀서는 특정 사용자 ID의 모든 레코드를 한 번에 처리하기에 한 번에 한 명의 레코드만 메모리에 유지하면 되고 네트워크로 요청을 보낼 필요도 없다. 이 알고리즘을 정렬 병합 조인(sort-merge join)이라고 한다. 매퍼 출력이 키로 정렬된 후 리듀서가 조인의 양측의 정렬된 레코드 목록을 병합하기 때문이다.
같은 곳으로 연관된 데이터 가져오기
•
병합 정렬 조인 결과는 모든 데이터를 한 곳으로 모으고, 그렇기에 사용자 ID별로 리듀서를 한 번만 호출한다.
•
필요한 데이터는 미리 정렬했기에 리듀서는 높은 처리량과 낮은 메모리 사용량을 가질 수 있다.
•
매퍼가 키-값 쌍을 보낼 때 키는 목적지의 주소 역할을 한다.
그룹화 및 세션화
데이터 그룹화는 특정 키를 기준으로 레코드를 묶는 것으로, SQL에서의 GROUP BY절과 유사하다. 그룹화된 데이터에 대해 다양한 집계 연산을 수행할 수 있다.
•
각 그룹의 레코드 수를 카운트(페이지뷰 카운트 예제와 같이 SQL로는 COUNT(*)로 표현할 수 있다.)
•
특정 필드 내 모든 값을 더하기(SQL로는 SUM(fieldname))
•
어떤 랭킹 함수를 실행했을 때 상위 k개의 레코드 고르기
맵리듀스에서 그룹화를 구현하는 방법은 매퍼가 키-값 쌍을 생성할 때 그룹화할 대상을 키로 사용하는 것이다. 그 결과, 같은 키를 가진 모든 레코드가 같은 리듀서로 모이게 된다.
세션화는 사용자 세션별 활동 이벤트를 분석하는 과정으로, 예를 들어 A/B 테스트 결과 확인이나 마케팅 활동 분석 등에 활용된다. 여러 웹 서버에서 발생한 특정 사용자의 활동 이벤트를 세션 쿠키나 사용자 ID 등을 그룹화 키로 사용하여 모으는 것이다. 이 과정에서 다른 사용자의 이벤트는 서로 다른 파티션으로 분산된다.
쏠림 다루기
키 하나에 너무 많은 데이터가 연관되어있다면 같은 키를 가지는 모든 레코드를 같은 장소로 모으는 패턴은 제대로 동작하지 않는다. 소셜 네트워크로 예를 들면 사람들 대다수는 많아야 수백 명 정도 연결되는 데 반해서 소수의 유명 인사는 팔로워가 수백만 명에 이르기도 한다. 이렇게 불균형한 활성데이터베이스 레코드를 린치핀 객체(linchpin object) 또는 핫 키(hot key)라 한다.
유명 인사 하나의 활동을 리듀서 하나로 모은다면 상당한 쏠림 현상이 발생하는데 이를 핫스팟이라고 한다.
이런 상황에 핫스팟을 완화할 몇 가지 알고리즘이 있다.
•
Pig의 쏠린 조인(skewed join) 메서드
◦
어떤 키가 핫 키인지 결정하기 위해 샘플링 작업을 수행한다.
◦
핫 키로 조인할 다른 입력은 핫 키가 전송된 모든 리듀서에 복제한다.
◦
핫 키를 여러 리듀서에 퍼트려 처리하도록 하는 방법
◦
Crunch에서 제공하는 공유 조인(chared join) 메서드가 비슷한 기법이다.
▪
샘플링 대신 핫 키를 명시적으로 지정해야 하는 차이가 있다.
◦
랜덤화를 사용하는 기법과도 비슷하다.
•
Hive의 쏠린 조인(skewed join) 최적화
◦
핫 키는 테이블 메타데이터에 명시적으로 지정한다.
▪
관련된 레코드를 별도 파일에 저장한다.
◦
해당 테이블에서 조인할 때 핫 키를 가지는 레코드는 맵 사이드 조인(map-side join)을 사용해 처리한다.
핫 키로 레코드를 그룹화하고 집계하는 작업은 두 단계로 수행된다.
첫 번째 맵리듀스 단계는 레코드를 임의의 리듀서로 보내어 핫 키 레코드의 일부를 그룹화 하고 키별로 집계해 간소화한 값을 출력한다.
두 번째 맵리듀스 단계는 첫 단계에서 나온 값을 키별로 모두 결합해 하나의 값으로 만든다.
맵 사이드 조인
위에서 설명한 조인 알고리즘은 리듀서에서 수행하기 때문에 리듀스 사이드 조인(reduce-side join)이라 한다. 입력 데이터를 준비하는 역할을 하는데,
•
입력 데이터에 대한 특정 가정이 없어도 된다는 장점이 있지만,
•
정렬 후 리듀서로 복사한 뒤 리듀서 입력을 병합하는 모든 과정에 고비용의 단점이 있다.
하지만, 입력 데이터에 대해 특정 가정이 가능하다면 맵사이드 조인(map-side join)으로 조인을 더 빠르게 수행할 수 있다. 각 매퍼가 할 작업은 입력 파일 블럭 하나를 읽어 해당 분산 파일 시스템에 출력하는게 전부다.
브로드캐스트 해시 조인
•
작은 데이터셋과 큰 데이터 셋을 결합할 때 사용되는 방법
◦
이때 작은 데이터셋은 전체를 매퍼 메모리에 적재가능할 수 있는 크기여야 한다.
•
큰 데이터 셋의 각 파티션을 처리할 때 작은 데이터 로컬과 조인을 수행한다.
•
Pig, Hive Crunch, Cascading에서 이런 메서드를 지원한다.
파티션 해시 조인
•
두 개의 데이터 셋을 동일한 방식으로 파티셔닝 한 뒤에 같은 파티션 번호를 가진 두 데이터 셋의 파티션끼리 로컬 조인이 되는 방식
•
두 데이터 세트가 비슷하고 분산되어 있을 때 효과적이다.
•
(제대로 파티셔닝이 됐다면) 조인할 레코드가 모두 같은 번호의 파티션에 존재하기에
◦
각 매퍼는 각 입력 데이터셋 중 파티션 한 개만 읽어도 된다.
•
각 매퍼의 해시 테이블에 적재할 데이터의 양을 줄일 수 있다는 장점이 있다.
•
Hive에선 버킷 맵 조인(bucketed map join)이라 한다.
맵 사이드 병합 조인
•
이미 정렬된 두 개의 데이터 셋을 조인하는 방식
•
동일한 키를 가진 레코드를 찾아 결합한다.
•
리듀서를 사용하지 않기에 처리 시간이 단축되지만,
◦
이 방식은 두 데이터 셋이 동일한 키로 정렬되어 있어야 하고
◦
큰 데이터 셋이라면 메모리 제약이 있을 수 있다.
일괄 처리 워크플로의 출력
그럼 이러한 처리를 모두 마친 결과는 어떻게 나오는 것이고, 왜 이러한 모든 작업들을 수행하는 걸까? 일괄 처리는 데이터셋 대부분을 스캔하기 때문에 분석에 가깝다. 하지만, 맵리듀스 작업의 워크플로는 분석 목적으로 사용하는 SQL질의완 다르다.
검색 색인 구축
정해진 문서 집합을 대상으로 전문 검색이 필요핟다면 일괄 처리가 색인 구축에 효율적이다.
매퍼는 필요에 따라 문서 집합을 파티셔닝하고 각 리듀서가 해당 파티션에 대한 색인을 구축한다.
매퍼는 필요에 따라 문서 집합 파티셔닝 및 각 리듀서가 해당 파티션에 대한 색인을 구축하고 해당 색인 파일을 분산 파일 시스템에 저장한다. 검색같은 경우 읽기 전용이기에 색인 파일을 한 번 생성하면 불변(immutable)이다.
일괄 처리의 출력으로 키-값을 저장
일괄 처리 출력은 흔히 일종의 DB가 되는데, 이 같은 DB는 하둡 인프라완 별도로 사용자 요청을 받는 애플리케이션에서 질의해야 한다. 배치 프로세스의 출력을 웹 애플리케이션이 질의하는 DB로 보내는 방법으로는
•
일괄 처리 작업이 한 번에 레코드 하나씩 DB 서버로 직접 요청하기
◦
다음 이유로 좋은 아이디어는 아니다.
▪
모든 레코드마다 네트워크 요청을 하는건 느리다.
▪
맵리듀스 작업은 보통 많은 태스크를 동시에 실행하기 때문에 요청을 받는 DB도 과부하 상태에 빠지기 쉽고 질의 성능도 떨어질 수 밖에 없다.
▪
맵리듀스 작업은 일관성을 가지고 있는데, DB와 연결되서 기록된다면, 작업 중간에 실패와 재시도에 대해서 드러나게 된다. 일관되지 않은 작업 결과는 외부로 드러나선 안된다.
•
일괄 처리 작업 내부에 새로운 DB를 구축해 분산 파일 시스템의 작업 출력 디렉터리에 저장하는 방법
◦
검색 색인과 유사한 구조로 저장한다.
◦
불변하고, 벌크(bulk)로 적재해 읽기 전용 질의를 처리할 수 있다.
◦
Voldmort, Terrapin, ElephantDB, HBase bulk loading 등에서 지원한다.
일괄 처리 출력에 관한 철학
맵리듀스 작업도 유닉스 철학과 마찬가지로 출력을 취급한다.
입력을 불변으로 처리하고 외부 DB에 기록하는 등의 부수 효과를 피하기에 일괄 처리 작업은 좋은 성능과 유지보수성을 같이 가져간다.
•
어떤 문제로든 출력이 잘못된경우 코드를 이전 버전으로 돌리고 작업을 재수행 할 수 있다. 다른 디렉터리에 이전 출력을 기록했다면 출력의 위치만 바꿔 복구할 수도 있다.
이처럼 버그 있는 코드로부터 복원할 수 있을 때 인적 내결함성(human fault tolearance)을 가진다고 한다.
•
쉽게 되돌릴 수 있는 속성의 결과로 실수를 하면 손상을 되돌릴 수 없는 환경에서보다 빠르게 기능 개발을 할 수 있는다. 비가역성 최소화(minimizing irreversibility) 원리는 애자일 소프트웨어 개발에 이롭다.
•
맵이나 리듀스 태스크가 실패하면 맵리듀스 프레임워크는 해당 태스크를 자동으로 다시 스케줄링하고 동일한 입력을 사용해 재실행한다. 코드에 문제가 있어서 계속해서 실패한다면 몇 번의 재시도 이후 작업이 실패할 것이고, 일시적인 문제였다면 결국 성공할 것이다.
◦
이러한 재시도가 가능한 이유는 입력이 불변이고, 맵리듀스 프레임워크가 실패한 태스크의 출력을 폐기하기 때문이다.
•
다양한 작업에서 입력으로 동일한 파일 집합을 사용하곤 한다.
◦
모니터링 작업에서 성능 지표를 파악하기 쉽다.
•
유닉스 도구와 마찬가지로 연결 작업과 로직을 분리하기에 각각의 관심사를 따로 처리할 수 있고 코드의 재사용성도 높아진다.
하둡과 분산 데이터베이스 비교
맵리듀스는 사실 전혀 새로운 개념이 아니고, 위에서 설명했던 처리 알고리즘, 병렬 조인 알고리즘은 이전에 설명한 대규모 병렬 처리(massively parallel processing, MPP) DB에서 모두 구현됐다.
(6장 파티셔닝에서 간단하게 소개했었다.)
맵리듀스와 MPP의 차이점을 보면
•
MPP DB는 장비 클러스터에서 분석 SQL 질의를 병렬로 수행하는 것에 초점을 두지만
•
맵리듀스와 분산 파일 시스템의 조합은 아무 프로그램이나 실행할 수 있는 OS와 비슷한 속성을 제공한다.
저장소의 다양성
•
하둡
◦
파일 기반 저장소(HDFS)이기 때문에 모델에 상관없이 연속된 바이트이기 때문에 높은 유연성을 제공한다.
◦
제약없는 데이터 덤핑(data dumping)은 데이터 해석에 대한 책임을 이전한다.
▪
스키마 온 리드(schema-on-read)접근법
◦
맵리듀스 프로그래밍 모델을 사용한다.
◦
비정형 데이터 처리에 적합하다.
•
분산 데이터베이스
◦
DB는 모델에 따라(Ex: 관계형, 문서형) 데이터를 구조화해야 한다.
◦
MPP DB가 요구하는 세심한 스키마 설계는 중앙 집중식 데이터 수집을 느리게 만든다.
◦
sql을 사용한 데이터 처리를 한다.
◦
높은 쿼리 성능과 ACID 트랜잭션을 지원한다.
◦
실시간 쿼리 및 처리에 적합하다.
참고: 하이브리드 아키텍처를 고려하라
두 방식의 장점을 섞어서 사용할 수도 있다.
하둡을 사용해 대규모 데이터 처리 및 초기를 제공한 뒤, 분석된 데이터를 분산 DB로 이동해서 실시간 쿼리 및 처리를 수행할 수 있다. 두 시스템의 장점을 결합해 최적의 성능 및 안전성을 제공할 수 있다. 처리 모델의 다양성
•
하둡
◦
맵리듀스(MapReduce) 프로그래밍 모델을 사용한다.
◦
HDFS와 맵리듀스가 있으면 그 위에 SQL 질의 실행 엔진을 구축할수도 있다.
▪
HIVE 프로젝트가 이런 역할을 한다.
◦
맵리듀스로는 너무 제한적이고 어떤 형태 처리에선 성능도 나쁘기 떄문에 하둡 위에 다른다양한 처리 모델이 개발됐다.
•
분산 데이터베이스
◦
일체식(monolithic)구조로 디스크 저장소 레이아웃, 질의 계획, 스케줄링등이 긴밀하게 통합된다.
◦
SQL 질의 언어를 사용해 코드를 작성하지 않고도 다양한 질의를 할 수 있고 좋은 성능도 낼 수 있다.
◦
SQL 질의로 모든 처리를 표현할 순 없다.
▪
머신러닝이나 추천 시스템 혹은 이미지 분석을 할 경우 더 범용적인 데이터 처리 모델이 필요하다.
▪
이런 처리는 특정 애플리케이션에 한정되는 경우가 많아 단순한 질의 작성으로 대응할 수 없다.
SQL과 맵리듀스 두 가지 처리 모델로도 충분하지 않고, 더 많은 모델이 필요했는데, 하둡 플랫폼의 개방서으로 MPP DB에선 불가능했던 모든 범위의 접근법을 구현할수도 있었다.
결정적으로 이런 다양한 처리 모델은 모드 단일 공유 클러스터 장비에서 실행되고 분산 파일 시스템상에 존재하는 동일한 파일들에 접근이 가능하다.
다른 종류의 처리를 하기 위해 다른 시스템으로 데이터를 보낼 필요도 없기 때문에 데이터로부터 가치를 끌어내기도 쉽고 새로운 처리 모델을 사용한 실험도 훨씬 쉽다.
빈번히 발생하는 결함을 줄이는 설계
맵리듀스와 MPP DB는 설계 방식에서 큰 차이점 두 가지가 있다. 결함을 다루는 방식과 메모리 및 디스크를 사용하는 방식인데, 일괄 처리는 온라인 시스템에 비해 결함에 덜 민감하다.
•
하둡
◦
기본적으로 내결함성(fault-tolerance)을 가진다.
◦
HDFS는 데이터 블록을 여러 노드에 복제하여 저장, 노드 결함 시 다른 노드에서 데이터를 복구 가능하다
◦
개별 태스크 수준에서 작업을 재수행하기 때문에 전체로 볼 때 영향을 받지 않는다.
◦
맵리듀스 접근법은 대용량 작업에 더 적합하다.
▪
많은 데이터를 오랜 기간 처리하는 작업은 태스크 하나는 실패할 확률이 높은데, 맵리듀스 접근법에선 개별 태스크 수준에서 복구를 시도할 수 있어 적절하다.
•
분산 데이터베이스
◦
장비 하나만 죽어도 전체 질의가 중단되고, 사용자가 질의를 다시 제출하던가 자동 재실행이 되야한다. 일반적으로는 재시도 비용이 크지 않아서 수용 가능하다.
◦
데이터 복제 및 샤딩을 통해 내결함성을 제공한다.
◦
복제를 통해 여러 노드에 동일한 데이터를 저장하여 노드 결함 발생 시 데이터를 복구할 수 있다
◦
샤딩을 통해 데이터를 여러 노드에 분산 저장하여 부하 분산 및 병렬 처리를 통한 성능 향상 가능하다
◦
일부 분산 데이터베이스는 정족수(쿼럼(quorum)) 기반 접근 제어를 사용하여 데이터 일관성을 유지하면서도 결함 허용성을 제공한다
사실 하둡의 HDFS에서 가정하는 문제들은 사실 그렇게 자주 발생하진 않는다.
그런데도 내결함성을 확보하기 위해 상당한 오버헤드를 감당하는게 가치가 있을까?
이는 맵리듀스의 탄생배경을 알아볼 필요가 있는데, 맵리듀스의 탄생 배경에는 구글이 있고, 구글은 혼합 사용 데이터 센터를 소유하고 있다.
이 데이터센터는 온라인 프로덕션 서비스와 오프라인 일괄 처리 작업이 같은 방비에서 실행되는데 각 태스크는 컨테이너를 사용해 CPU 코어, RAM, 디스크 공간 등의 자원을 할당받는다.
모든 태스크는 우선순위가 있고, 이 우선순위에 따라 자원을 더 확보할 수 있고, 그러기 위해 우선순위가 낮은 태스크를 종료(선점)할 수도 있다.
구글에서 어떤 맵리듀스 태스크가 한 시간 정도 수행된다면 높은 우선순위의 프로세스를 위한 공간을 마련해주기 위해 태스크가 종료될 위험이 약 5%로 HW문제나 장비 재시작 등 다른 이유로 실패할 확률보다 상당히 높다. 작업이 5% 선점 확률로 10분간 수행하는 100개의 태스크를 가지고 있을 경우 작업 완료 전 태스크 하나가 종료될 가능성이 50%가 넘는다.
이러한 이유로 맵리듀스는 태스크 종료가 예상치 못하게 자주 발생해도 견딜 수 있도록 설계됐다.
다만, 오픈소스 클러스터 스케줄러는 선점 방식을 많이 사용하지는 않는다.
일반적인 우선순위 선점 방식은YARN, Mesos, Kubernetes를 작성할 당시엔 지원하지 않았고, 사실 태스크가 자주 종료되지 않는 환경에서는 맵리듀스를 이런 식으로 설계할 필요가 없고, 그렇기 때문에 다른 방식으로 설계된 맵리듀스의 여러 대안도 존재한다.
맵리듀스를 넘어
맵리듀스는 2000년 후반 엄청난 인기를 끌었지만, 그로 인해 과대포장된 부분도 있다.
(필자 학부생 시절 하둡으로 대학교 강의도 생기고 엄청 핫했었다.)
맵리듀스는 분산 시스템에서 가능한 여러 프로그래밍 모델 중 하나일 뿐으로 데이터의 양, 자료 구조, 데이터 처리 방식에 따라 다른 도구가 더 적합할수도 있다.
그럼에도 맵리듀스는 상당히 단순 명료하게 추상화된 모델이기에 학습할 가치가 있다.
단순하다는 말은 사용이 쉽다는 의미가 아닌 무엇을 하고 있는지 이해하기 쉽다는 뜻이다.
하지만, 맵리듀스 실행 모델 자체도 문제는 존재하며 추상화로 해결되지 않는다.
그래서 이제 이러한 문제가 야기되는 특정 유형의 처리를 해결할 수 있는 대안을 살펴본다.
중간 상태 구체화
보통 한 작업의 출력은 같은 팀 내에서 유지보수하는 다른 특정 작업의 입력으로만 사용되는데, 이 경우 분산 파일 시스템 상에 있는 파일들은 데이터를 옮기는 수단, 즉 중간 상태(Intermediate state)다.
그리고 이런 중간 상태를 파일로 기록하는 과정을 구체화(materialization)라 한다.
반면, 유닉스 파이프는 중간 상태를 완전히 구체화하는 대신 작은 인메모리 버퍼만을 사용해 점진적으로 출력을 입력으로 스트리밍한다.
중간상태를 완전히 구체화하는 맵리듀스 접근법은 유닉스 파이프에 비해 여러 단점이 있다.
•
맵리듀스 작업은 입력을 생성하는 모든 선행 작업이 완료되었을 때만 시작 가능하지만, 유닉스 파이프로 연결된 프로세스들은 동시에 시작되고 출력은 생산되는 즉시 소비된다. 즉 많이 뒤처지는 태스크가 있을 경우 전체 워크 플로 수행 시간자체가 느려진다.
•
매퍼는 종종 중복되기도 하는데, 이 매퍼들은 리듀서에서 막 기록된 동일한 파일을 읽어 다음 단계인 파티셔닝과 정렬 단계를 준비한다. 대부분의 매퍼 코드는 이전 리듀서의 일부가 될 수 있다. 리듀서의 출력을 매퍼 출력과 같은 방식으로 파티셔닝하고 정렬한다면 매퍼 단계를 끼워넣지 않고 리듀서끼리 직접 연결할 수 있다.
•
분산 파일 시스템에서 중간 상태를 저장하는 것은 중간 상태 파일들이 여러 장비에 걸쳐 복제됐다는 의미로서 이런 임시데이터에겐 과잉조치다.
데이터플로 엔진
맵리듀스에 있는 위와 같은 문제를 해결하기 위해 분산 일괄 처리 연산을 수행하는 엔진이 몇 가지 새롭게 개발되었다.
•
Spark
•
Tez
•
Flink
위 엔진들은 설계 방식은 차이가 있지만, 전체 워크플로를 독립된 하위 작업으로 나누지 않고 작업 하나로서 다룬다는 공통점이 있다.
여러 처리 단계를 통해 데이터 흐름을 명시적으로 모델링 하기 때문에 데이터 플로 엔진(dataflow engine)이라고 부른다.
맵리듀스처럼 단일 스레드에서 사용자 정의 함수를 반복 호출해 레코드 한 개씩 처리하는데, 입력을 파티셔닝해 병렬화 하고, 한 함수의 출력을 다른 함수의 입력으로 사용하기 위해 네트워크를 통해 복사한다.
또한, 이러한 함수들을 유연하게 조합할 수 있는데 이러한 함수를 연산자(operator)라 부르고, 데이터플로 엔진은 이러한 연산자의 출력과 다른 연산자의 입력을 연결하는 선택지를 여럿 제공한다.
1.
레코드를 키로 재파티셔닝하고 정렬하기
•
맵리듀스와 같은 방식으로 정렬 병합 조인과 그룹화를 수행할 수 있다.
2.
여러 입력을 가져와 파티셔닝하면서 정렬은 건너뛰기
•
파티션 해시 조인에서 수행하는 일을 줄일 수 있다.
•
파티션 해시 조인에서 레코드 파티셔닝은 중요하지만 해시 테이블을 사용하면 순서는 무의미해진다.
3.
브로드캐스트 해시 조인을 사용하면 한 연산자의 출력을 조인 연산자의 모든 파티션으로 보낼 수 있다.
이러한 스타일의 처리 엔진은 Dryad, Nephele같은 연구용 시스템에 기초를 두고 있는데 다음과 같은 장점이 있다.
•
정렬과 같은 비싼 작업은 필요한 경우에만 수행한다.
◦
맵리듀스 모델은 모든 맵과 리듀스 사이에서 정렬 작업이 발생한다.
•
필요없는 맵 태스크는 없다. 매퍼가 수행한 작업은 종종 선행 리듀스 연산자로 통합될 수 있기 때문이다.(매퍼는 데이터셋의 파티셔닝을 변경하지 않기에 가능하다.)
•
워크플로에 모든 조인과 데이터 의존 관계를 명시적으로 선언하기 때문에 스케줄러가 어느 데이터가 어디에 필요한지에 대한 개요를 가져 지역성 최적화가 가능하다.
◦
데이터 소비 태스크를 생산 태스크와 동일한 장비에 배치해서, 네트워크가 아닌 공유 메모리 버퍼로 데이터를 교환할 수 있다.
•
연산자 간 중간 상태는 대개 메모리나 로컬 디스크에 기록하는 것으로 충분한데 HDFS에 중간 상태를 기록할 때보다 I/O가 훨씬 적게든다.
◦
HDFS는 데이터를 여러 장비에 복제하고 각 복제 서버에 있는 디스크에 기록해야 한다.
◦
데이터 플로 엔진은 이 아이디어를 모든 중간 상태로 일반화한다.
•
연산자들은 입력이 준비되는 즉시 실행을 시작할 수 있다.
•
새로운 연산자를 실행할 때 이미 존재하는 JVM을 재활용할 수 있다.
◦
맵리듀스는 태스크별로 JVM을 구동해야 한다.
데이터플로 엔진으로 맵리듀스 워크플로와 동일한 연산을 구현할 수 있는데 위에서 설명한 최적화로 수행속도가 훨씬 빠르다. 뿐만 아니라 연산자는 맵과 리듀스를 일반화 한 것이기에 Pig, HIVE, Cascading으로 구현된 워크플로를 코드 수정 없이 설정 변경만으로도 맵리듀스에서 tez, spark로 전환할 수 있다.
내결함성
다음과 같은 기능들로 내결함성을 보장한다.
1.
장애 복구를 위한 체크포인트 및 스냅샷
•
데이터플로 엔진은 정기적으로 처리 중인 데이터와 상태에 대한 체크포인트를 생성하고 스냅샷을 저장하는데, 노드 장애 발생 시 이러한 체크포인트와 스냅샷을 사용하여 작업을 중단된 지점에서 다시 시작할 수 있다.
2.
작업 재시작 및 이동
•
노드 장애가 발생하면 데이터플로 엔진은 다른 노드에서 작업을 자동으로 재시작하거나 이동시켜 작업이 계속 진행되며, 시스템의 전체 가용성을 높힌다.
3.
데이터 복제
•
데이터플로 엔진은 중요한 데이터를 여러 노드에 복제하여 저장할 수 있고, 이를 통해 노드 장애 발생했을 때 복제된 데이터를 사용하여 복구하고 작업을 계속 진행할 수 있다.
4.
동적 리소스 할당
•
데이터플로 엔진은 클러스터 리소스를 동적으로 할당하여 작업의 요구 사항에 따라 리소스를 조절할 수 있다. 노드 장애 발생 시 다른 노드에 리소스를 재할당하여 작업이 계속 진행될 수 있도록 한다.
그런데, Spark, Flink, Tez는 HDFS의 중간 상태를 쓰지 않기에 내결함성 확보를 위해 다른 접근법을 사용한다. 만약 장비가 죽어 중간 상태까지 잃을 경우 아직 유효한 데이터로부터 계산을 다시 해서 복구한다.
그리고 이런 재계산을 하려면 프레임워크에서 주어진 데이터가 어떻게 연산되는지 추적해야 하는데, 어느 입력 파티션을 사용했는지와 어떤 연산자를 적용했는지도 추적해야하는데,
•
Spark는 데이터의 조상을 추적하기 위해 RDD(resilient distributed dataset)추상화를 사용한다.
•
Flink는 연산자 상태를 체크포인트로 남겨 작업 실행 중 실패한 연산자 수행을 재개할 수 있다.
그리고, 데이터 재연산을 할 때 해당 연산이 결정적인지 파악하는 것도 중요하다.
연산자를 재시작해서 재연산된 데이터가 잃어버린 원본 데이터와 다르다면 다운스트림 연산자는 이전 데이터와 새로운 데이터 간의 모순을 해결하기 힘들다.
연산자가 비결정적인 경우 해결책은 다운스트림 연산자도 죽이고 신규 데이터를 기준으로 다시 수행하는게 일반적이다. 그렇기 때문에 연산자를 결정적으로 만다는게 좋다.
구체화에 대한 논의
데이터플로 엔진은 유닉스 파이프와 매우 비슷하고, Flink는 파이프라인 실행 개념을 기초로 한다.
이말인즉슨, 연산자의 출력을 다른 연산자로 점진적으로 전달하고 입력을 처리하기 전에 입력이 완료될 때까지 기다리지 않는다.
정렬 연산자는 맨 마지막 입력이 가장 높은 우선순위를 가질수도 있기 때문에 전체 입력을 소비하고 출력을 생산해야 한다. 따라서 정렬이 필요한 연산자는 상태를 (일시적이라도) 누적할 필요가 있다.
작업을 완료한 다음에는 출력을 다른 사용자가 찾아 사용할 수 있게끔 지속성 있는 곳으로 보내야하는데, 대게 출력을 분산 파일시스템에 다시 기록한다.
따라서 데이터플로 엔진을 사용할 때 HDFS상에 구체화된 데이터셋은 보통 작업의 입력과 최종 출력이다. 맵리듀스와 비슷하지만 사용자가 직접 모든 중간 상태를 파일 시스템에 기록하는 수고를 덜어준다는 이점을 가진다.
그래프와 반복 처리
많은 그래프 알고리즘은 한 번에 하나의 간선을 수회하는 방식으로 표현되어 특정 정보를 전파하기 위해 정점 하나와 인접한 정점을 조인하며 특정 조건에 도달할 때까지 반복한다.
(특정 조건: 따라갈 간선이 없어지거나, 특정 지표 수렴)
다음은 어떤 지역이 어느 다른 지역 내에 속하는지 가리키는 간선을 반복적으로 따라가는 방식으로 DB에 포함된 북미 지역의 모든 위치 목록을 만드는 예제로 이런 알고리즘을 이형적 폐쇄(transitive closure)라 한다.
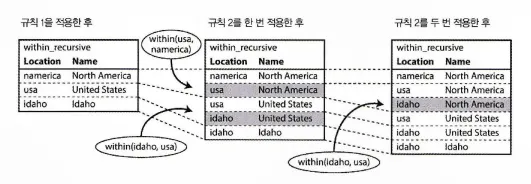
그래프는 분산 파일 시스템의 정점과 간선 목록이 포함된 파일의 형태로 저장할 수 있지만, 완료될 때까지 반복이라는 개념은 일반적인 맵리듀스로는 표현할 수 없다.
따라서, 이런 알고리즘은 대개 반복적 스타일로 구현된다.
1.
외부 스케줄러가 이 알고리즘의 한 단계를 연산하기 위해 일괄 처리를 수행한다.
2.
해당 일괄 처리가 완료되면 스케줄러는 종료 조건을 기반으로 완료 여부를 확인한다.
3.
완료 여부에 따라 스케줄러는 1단계로 돌아가서 일괄 처리를 수행하거나 종료한다.
하지만, 이러한 알고리즘의 반복적 속성을 고려하지 않은 맵리듀스에선 동작은 하지만 비효율적이다.
프리글 처리 모델
보통 벌크 동기식 병렬(bulk synchronous parallel, BSP) 연산 모델을 사용해 일괄 처리 그래프를 최적화 한다. 이러한 BSP는 프리글(Pregel)모델로 불리는데, 프리글 모델은 구글의 프리글 논문에서 그래프 처리 방법론으로 소개되어 보급됐다.
프리글에서 한 정점은 다른 정점으로 메시지를 보낼 수 있으며 대게 간선을 따라 보내진다.
반복할 때마다 개별 정점에서 함수를 호출해 그 정점으로 보내진 모든 메시지를 전달하는데 리듀서를 호출하는 방식과 비슷하다.
하지만, 정점은 반복에서 사용한 메모리 상태를 기억하고 있다는 점에서 차이를 보인다. 그래서 정점은 새로 들어오는 메시지만 처리하면 된다.
내결함성
정점이 메시지 전달로 통신한다는 점은 메시지가 일괄처리가 가능해 통신 대기 시간이 발생하지 않 기 때문에 프리글 작업 성능 향상에 도움을 준다.
대기 시간은 반복과 다음 반복 사이에만 존재한다. 프리글 모델은 앞선 반복에서 보낸 모든 메시지는 다음 반복에 도착됨을 보장하기에 다음 반복을 시작하기 전 앞선 반복이 반드시 끝나야 하고 모든 메시지는 네트워크 상에서 복사돼야 한다.
만약, 네트워크의 문제로 메시지가 소실, 중복,지연되더라도 프리글 구현상 다음 반복에서 메시지는 정확히 한 번만 처리된다.
이런 내결함성은 반복이 끝나는 시점에 모든 정점의 상태를 주기적으로 체크포인트로 저장함으로써 보장된다. 즉 전체 상태를 지속성 있는 저장소에 기록한다.
병렬 실행
정점은 정점 ID를 통해 메시지를 다른 정점으로 보낸다.
그래프를 파티셔닝하는 일은 프리글 프레임워크가 담당하며 정점을 어떤 장비에서 실행하고 어떻게 라우팅할지 결정하는 것도 담당한다.
프로그래밍 모델에서 한 번에 하나의 정점을 다루기에 프리글 프레임워크는 임의의 방법으로 그래프를 파티셔닝할 수 있다. 통신이 잦은 정점끼리 같은 장비로 파티셔닝을 하는게 좋겠지만, 이 방법은 어렵기 때문에 단순히 임의로 부여된 정점 ID를 기준으로 단순하게 분할한다.
그래프 알고리즘은 장비 통신 간 오버헤드가 많이 발생하기 때문에 그래프가 단일 컴퓨터 메모리에 넣을 수 있는 크기라면 단일 장비 알고리즘이 분산 일괄 처리보다 성능이 좋을 가능성이 높다.
그래프가 단일 장비에 넣기에 너무 큰 경우에만 프리글 같은 분산 접근법을 사용하는게 좋다.
참고: 프리글 프레임워크는 어떤 임의의 방법으로 그래프를 파티셔닝하는가?
1. 벌크 동기적 병렬(BSP)
: 슈퍼스텝이라는 단계별로 처리가 수행되며 각 슈퍼스텝 동안 모든 노드는 병렬로 처리된다. 슈퍼스텝이 끝나면 처리가 동기화되고 다음 슈퍼스텝이 시작된다.
2. 그래프 파티셔닝
: 그래프를 여러 파티션으로 분할하는데, 각 파티션은 하나 또는 여러 머신에 할당되어 처리된다.
3. 메시지 전달
: 프리글은 각 슈퍼스텝 동안 노드 간 메시지를 전달하고 처리한다. 노드는 이웃 노드에게 메시지를 보내고, 다음 슈퍼스텝에서 이 메시지를 처리하며, 그래프 처리 작업이 완료될 때까지 반복한다.
고수준 API와 언어
맵리듀스가 나오고 몇년이 지나 생태계는 커졌고, hive, pig, cascading, crunch같은 고수준 언어나 API도 나와 인기를 끌고 있다. 그 밖에도 Tez, Spark, Flink등도 작업 코드를 새로 작성하지 않고도 맵리듀스 엔진에서 새로운 데이터 플로로 옮겨가거나 자체적으로 고수준 데이터플로 API를 가지고 있다.
이와 같은 고수준 인터페이스는 내가 직접 작성할 부분을 최소화해주기에 높은 생산성을 보장해준다.
선언형 질의 언어로 전환
hive, spark, flink는 비용 기반의 질의 최적화기를 내장하고 있다.
그래서 조인을 수행하는 질의를 요청하면 조인 입력의 속성을 분석해 자동으로 적절한 조인 알고리즘을 결정해준다.
어떤 조인 알고리즘을 선택하느냐에 따라 일괄 처리 작업의 성능이 크게 달라지는데, 선언적인 방법으로 조인을 지정하면, 알아서 질의 최적화기가 최적화된 방법을 결정한다.
하지만, 맵리듀스와 맵리듀스의 데이터플로 계승자들은 SQL의 완전한 선언형 질의모델과는 많이 다르다. 함수 콜백 개념으로 각 레코드나 레코드 그룹을 입력으로 사용자 정의 함수(매퍼 또는 리듀서)를 호출하는데, 이 함수에서 출력을 결정하는 코드를 임의로 작성할 수 있다.
코드를 임의로 실행할 수 있다는 점은 MPP DB와 맵리듀스를 계승하는 일괄 처리 시스템을 오랜 세월 동안 구별해준 특성이다.
DB는 사용자 정의 함수를 지원한다고 해도 사용하기 부담스럽고, 프로그램 언어에서 많이 사용되는 패키지 관리자나 의존성 관리 시스템(Maven, NPM, Rubygem)과의 통합이 어렵다.
하지만, 데이터플로 엔진도 조인 외에 좀 더 선언적인 기능을 통합하면 이점이 있다.
예를 들어 콜백 함수에 간단한 필터링 조건만 포함하거나 레코드의 특정 필드만 선택하는 경우 모든 레코드를 대상으로 해당 함수를 호출하기보단 간단한 필터링과 매핑 연산을 선언적 방법으로 표현해 질의 최적화기가 칼럼 기반 저장 레이아웃을 이용해 디스크에서 필요한 칼럼만 읽을 수 있도록 할 수 있다.
고수준 API에 선언적 측면을 포함하며 실행중에 이용할 수 있는 질의 최적화기를 가진다면 일괄 처리 프레임워크는 MPP 데이터베이스와 한층 비슷해진다.
동시에 일괄 처리 프레임워크는 임의의 코드를 실행하고 임의 형식의 데이터를 읽을 수 있는 확장성을 지녀 일괄 처리 프레임워크의 장점인 유연성도 그대로 유지한다.
참고: 데이터플로 엔진에서 선언적인 기능을 통합해보기
from pyspark.sql import SparkSession
# Spark 세션 생성
spark = SparkSession.builder
.appName("declarative_example")
.getOrCreate()
# 데이터셋 로드
data = spark.read.csv("data.csv", header=True, inferSchema=True)
# 데이터 처리 작업 정의
# 1. 'age' 컬럼 기준으로 그룹화
# 2. 각 그룹의 평균 'income' 계산
# 3. 결과를 'avg_income' 컬럼에 저장
result = data.groupBy("age")
.agg({"income": "mean"})
.withColumnRenamed("avg(income)", "avg_income")
# 결과 출력
result.show()
# 스파크 세션 종료
spark.stop()
Python
복사
다양한 분야를 지원하기 위한 전문화
표준화된 처리 패턴을 위해 재사용 가능한 공통 빌딩 블록을 구현하는건 가치있다.
통계학과 수치 알고리즘은
•
분류
•
추천 시스템
과 같은 머신러닝 애플리케이션을 구축하는데 필요하다.
떠오르는 재사용 가능한 구현의 예로는 머하웃(Mahout)이 있는데, 맵리듀스, 스파크, 플링크 상에서 실행되는 다양한 머신러닝용 알고리즘 구현을 가지고 있다.
반면 매드립(MADlib)은 관계형 MPP DB내부에 이와 유사한 기능 구현이 있다.
또한, K 최근접 이웃 알고리즘(k-nearest neighber)같은 공간 알고리즘도 유용하다. 이 알고리즘은 다차원 공간에 주어진 아이템과 근접한 아이템들을 찾는 일종의 유사도 검색 알고리즘이다.
일괄 처리 엔진과 MPP DB는 결국 둘 다 데이터를 저장하고 처리하는 시스템이기에 발전할수록 비슷해 보이기 시작했다.

