

웹의 동작을 알아야 하는 이유
•
문서인 웹페이지를 웹어플리케이션으로 만들기 위해
•
서버에 다양한 요청을 하고, 받은 응답 메세지를 해석하기 위해
•
네트워크에서 일어난 에러를 알고 문제를 해결하기 위해
1. 웹 서버와 웹 클라이언트
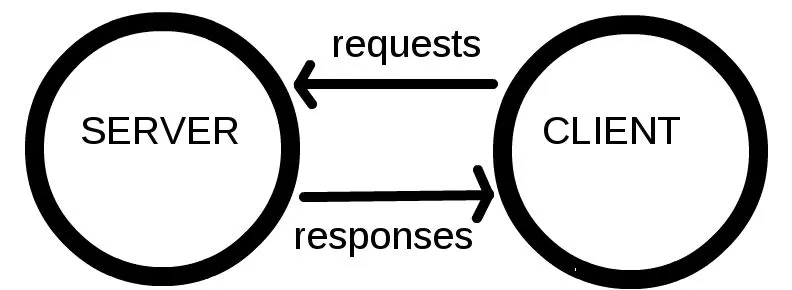
클라이언트와 서버의 상호작용 다이어그램
개요
우리는 컴퓨터,태블릿,핸드폰, TV 등등 다양한 기기에 포함되어 있는 브라우저(크롬,사파리,익스플로러,파이어폭스 등등)를 통해 웹을 경험합니다.
이 브라우저 이면에는 우리가 입력한 여러 행위(마우스 클릭, 드래그, 더블클릭, 엔터, 등등)들은 어떻게 요청을 보내고 화면에 출력 될까요? 현재의 컴퓨터 시스템에서는 클라이언트-서버 모델의 형태가 널리 사용되고 있습니다.
이는 클라이언트(Client)가 요청(Request)하면 서버(Server)가 응답(response)해주는 구조입니다.
웹 서버는 네트워크상에 공개하는 하이퍼텍스트(HTML 형식의 파일)를 쌓고, 웹 클라이언트가 요청하는 HTML파일을 건네주는 구조로 되어있습니다.
웹서버(Web Server)
: 하드웨어, 소프트웨어 혹은 두 가지 모두를 의미할 수 있습니다.
•
하드웨어 측면
⇒ website의 컴포넌트 파일들을 저장하는 곳. (ex: HTML문서, images, CSS stylesheets, JavaScript files) 그리고 이 파일들을 최종 소비자의 디바이스에 전달합니다. web server는 인터넷에 연결되어 있고, mozilla.org와 같은 domain name을 통해 접속될 수 있습니다.
•
소프트웨어 측면
⇒ 웹 사용자가 어떻게 호스트 파일들에 접근하는지를 관리합니다. 해당 포스팅에서 web server는 HTTP서버로 국한됩니다. HTTP는 URL(Web addresses)과 HTTP(브라우저가 웹페이지를 보여주기 위해 사용하는 프로토콜)의 소프트웨어 일부입니다.
웹 클라이언트(Web Client)
: 일반적인 웹 사용자의 인터넷이 연결된 장치들(ex: WI-FI 연결된 컴퓨터, 핸드폰의 모바일 네트워크)과 이런 장치들에서 이용가능한 웹에 접근하는 소프트웨어(ex: 파이어폭스, 크롬, 사파리 등)입니다.
왜 클라이언트와 서버로 나뉘는 것일까?
웹은 여러 콘텐츠를 불특정 다수에게 공개합니다. 그렇기에 콘텐츠를 적절히 정리하고 관리하는것이 중요합니다.
하지만, 이 컨텐츠들이 여러 곳에 분산되어 있으면 어떤 문제가 발생할까요? 웹에 존재하는 대부분의 콘텐츠들은 업데이트가 이뤄지는데, 이 콘텐츠들이 여러 곳에 분산되어 있으면 어디에 저장위치의 파악과 갱신에 비용이 많이 들뿐더러 어렵습니다. 그렇기에 웹 서버와 같이 컴퓨터 하나에 정보를 모아 두는 편이 관리가 수월합니다.
또한, 웹은 불특정 다수의 살마들이 콘텐츠를 자유롭게 열람할 수 있어야 하는데, 사용자가 콘텐츠를 열람하기 위해 그 콘텐츠를 보관하고 처리하는 웹 서버를 직접 조작하는 것은 비현실적입니다. 그렇기에 사용자앞에 있는 디바이스를 웹 클라이언트로, 콘텐츠 자원을 관리하고 처리하는 디바이스를 웹서버로 만들어 인터넷을 연결하는 것입니다.
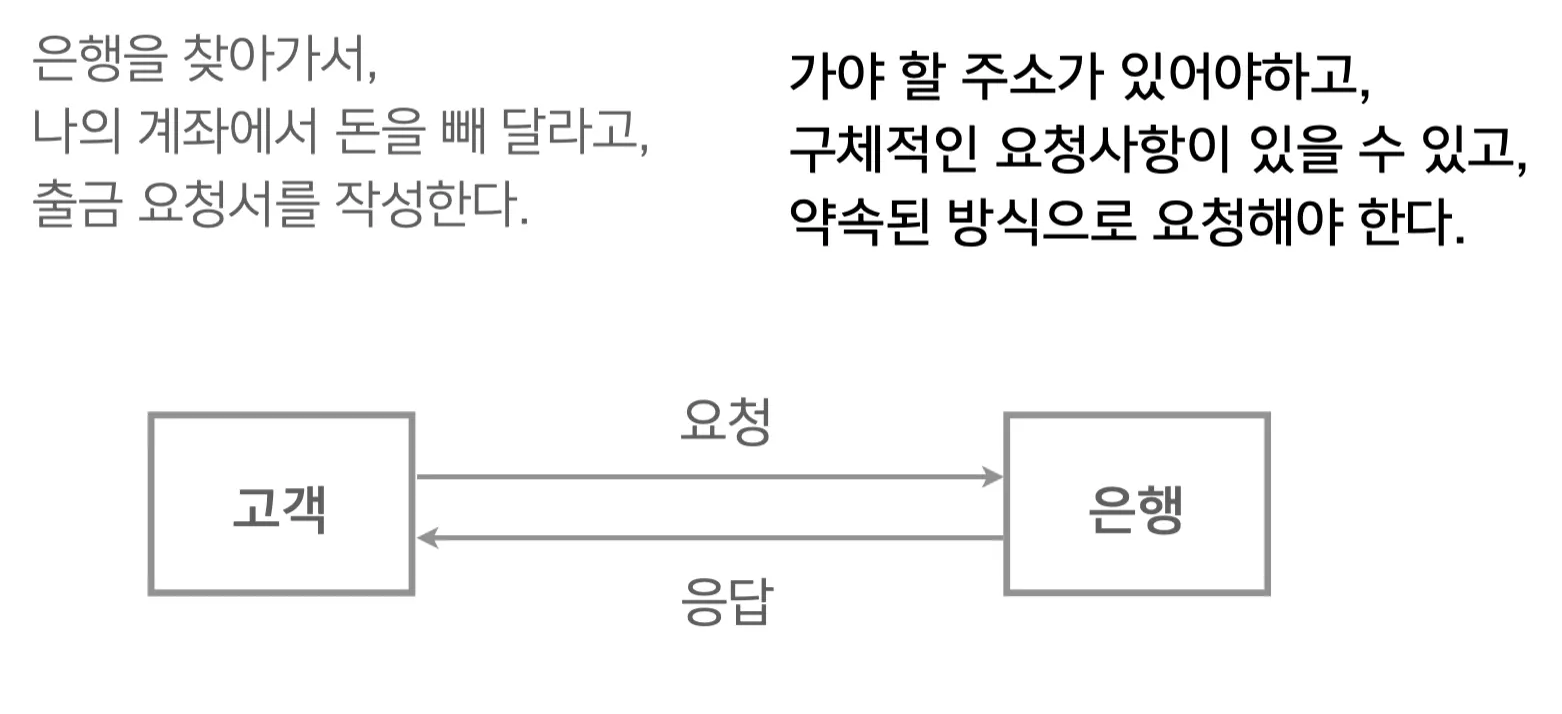
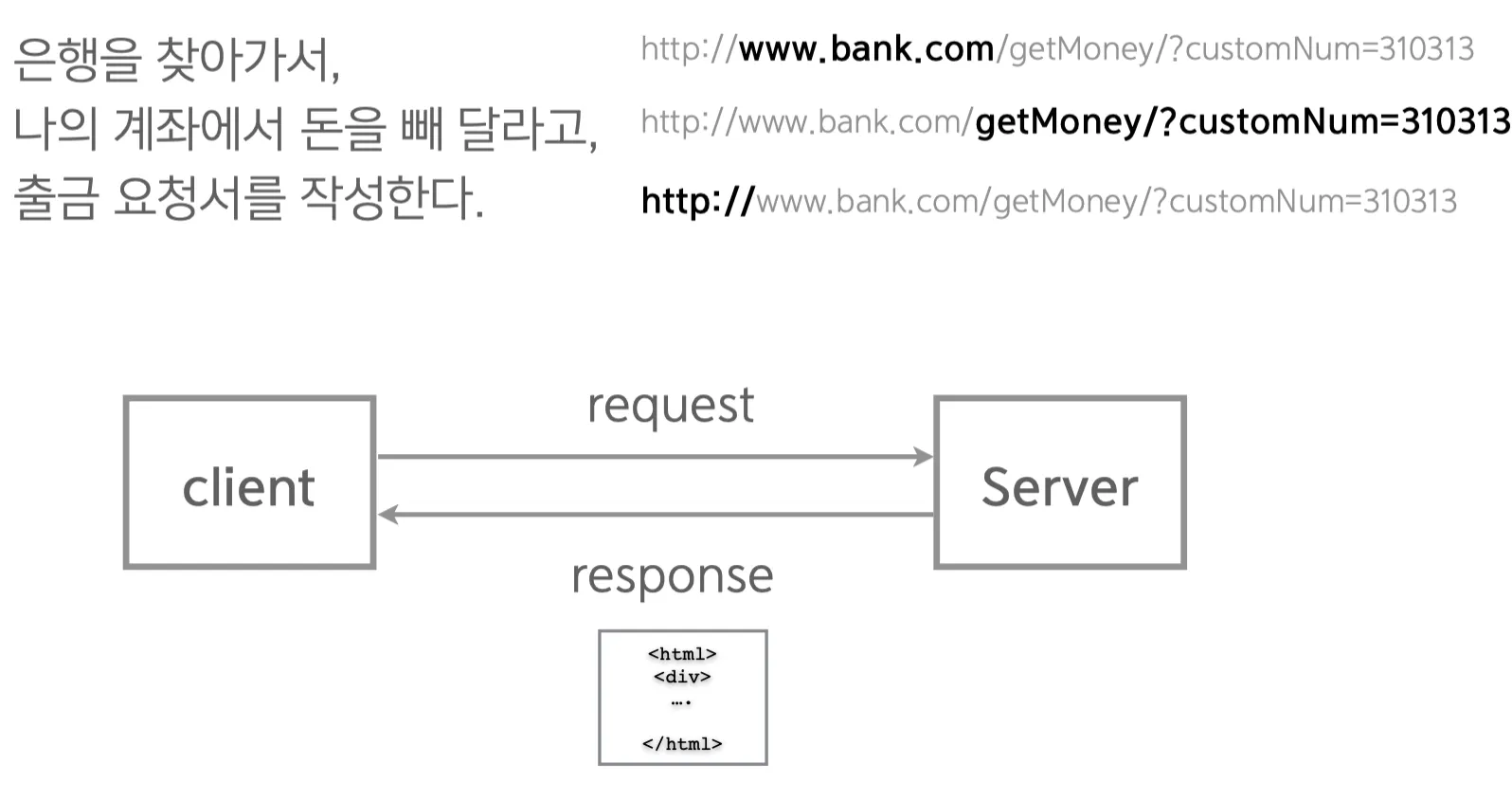
그 리소스(html 파일)어디서 찾아서 주는 것일까? - URL

URL(Uniform Resource Locator) : 인터넷상의 콘텐츠를 고유하게 지정하기 위한 구조
클라이언트는 "어디 어디에 있는 이 콘텐츠를 열람하고 싶다." 라고 지정할 방법으로 URL을 사용합니다.
즉, 유저가 웹 브라우저로 특정 사이트에 접속할 때 주소창에 입력하는 문자열이 바로 URL입니다.
HTTP라는 약속
HTTP: HTML 문서와 같은 리소스들을 가져올 수 있도록 해주는 프로토콜(약속)
위에서 URL을 이용해 웹상의 공개된 다양한 콘텐츠를 열람할 수 있습니다.
하지만 하이퍼 텍스트를 통한 콘텐츠를 컴퓨터가 어떻게 송수신 할까요? 인터넷에는 다양한 종류의컴퓨터가 연결되어 있고, 그 중 웹 서버와 웹 클라이언트가 통신하기위해서는 어떻게 정보를 주고 받을지에 대한 약속이 필요합니다. 이 약속을 통신 프로토콜(communication protocol)이라고 합니다.
웹의 창시자인 버너스 리 박사는 HTML전송에 적합한 프로토콜을 새로 고안했는데, 이것이 현재도 널리 사용되고 있는 HTTP(HyperText Transfer Protocol)입니다.
HTTP 프로토콜
1. URL(Uniform Resource Location)

•
URI(Uniform Resource Identifier)라고도 합니다.
•
URI가 URL보다 상위 개념이지만 혼용해서 사용되고 있기에 같은 것으로 이해해도 상관 없습니다.
•
URL은 스킴(scheme), 호스트명, 경로명으로 구성됩니다.
◦
스킴(scheme)
⇒ 리소스를 획득하기 위한 방법을 나타냅니다. 웹 애플리케이션 대부분 HTTP프로토콜을 사용합니다.
▪
https: 암호화된 http통신을 나타내는 스킴
▪
mailto: 이메일의 수취인을 나타내는 스킴
▪
ftp: FTP 프로토콜을 통한 파일 획득을 나타내는 스킴
▪
file: 파일 시스템 속의 파일이나 디렉토리를 참조하기 위한 스킴
◦
호스트명
⇒ 리소스가 존재하는 호스트(컴퓨터)의 이름을 나타냅니다. 네트워크상에 등록되어 클라이언트의 요청을 받아 응답하는 컴퓨터를 호스트 컴퓨터라하는데, 호스트명은 호스트 컴퓨터의 이름을 가르킵니다.
◦
경로명
⇒ 호스트명에서 지정된 컴퓨터상의 리소스의 위치를 나타냅니다. 위 이미지에서 경로명은 wooteco.com이라는 호스트 컴퓨터의 webcontents안의 index.html파일을 나타냅니다.
2. HTTP Request Line
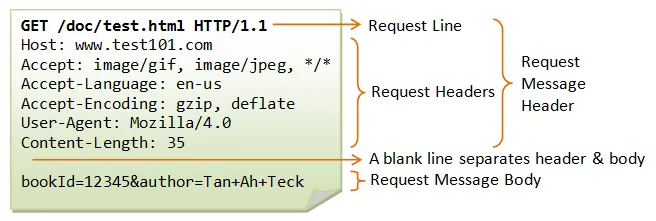
1.
메소드(scheme)
: 요청의 종류를 나타냅니다. 위 이미지에서는 GET이라는 메소드인데 'URI'에서 지정한 정보를 보내달라는 의미가 됩니다.
2.
URI(Uniform Resource Identifier)
: 무엇을 원하는가에 대해서 나타냅니다. URL과 URIL는 동일하게 취급해도 됩니다.
3.
HTTP버전
: 버전에 따라 이용할 수 있는 메서드의 종류와 요청 헤더의 종류가 달라지기에 어떤 버전에 따른 요청인지 저장합니다. 위 이미지의 Request Line 아래 Request Header부분은 메세지 헤더라고 하며, 요청의 부가적인 정보를 나타냅니다.
4.
Accept
: 웹 클라이언트가 받을 수 있는 데이터의 종류. 데이터의 종류는 Content-Type이라는 형식으로 표시되며, 클라이언트에서 받을 수 있는 Content-Type을 콤마로 구분해서 지정합니다. 이렇게 정보를 표현함으로써 Accept필드를 참조하면 웹 서버는 불필요한 정보를 송신하지 않아도 될 가능성이 있습니다.
5.
Accept-Language
: 웹 클라이언트가 받을 수 있는 자연 언어의 종류를 나타냅니다. 자연 언어는 사람이 사용하는 언어를 가르킵니다. ex(en-us, utf-8)
6.
User-Agent
: 이용중인 웹 브라우저의 종류와 버전을 나타냅니다.
7.
Host
: 요청을 보낸 곳의 호스트명과 포트번호를 지정합니다.
3. HTTP Response
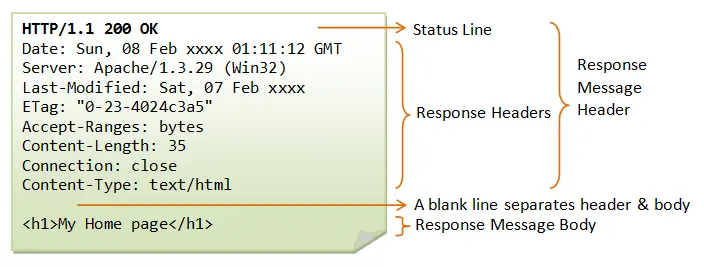
1.
상태라인(Status Line)
:HTTP요청과 마찬가지로 HTTP 응답에 대해서도 첫 번째 줄이 가장 중요하며, 이것을 상태라인(Status Line)이라 합니다. 구성은 HTTP버전과 상태 코드, 응답 구문으로 세 부분으로 나뉩니다.

•
HTTP/1.1 : 사용하는 포로토콜의 버전을 나타냅니다.
•
200 : 상태 코드로 요청이 성공했는지 실패했는지에 대한 값입니다.
◦
200 - OK
◦
201 - Created
◦
302 - Found(HTTP 1.0)
◦
304 - Not Modified
◦
401 - Unauthorized
◦
404 - Not Found
◦
500 - Internal Server Error
◦
503 - Service Unavailable
◦
status code 단위별 의미
▪
2XX: 성공, 클라이언트가 요청한 동작을 수신하여 이해했고, 승낙했으며 성공적으로 처리
▪
3XX: 리다이렉션 오나료. 클라이언트는 요청을 마치기 위해 추가 동작이 필요함.
▪
4XX: 요청 오류. 클라이언트에 오류가 있음
▪
5XX: 서버 오류. 서버가 유효한 요청을 명백하게 수행하지 못했음.
2.
메세지 헤더
: 상태라인에 이어서 나오는 메세지 헤더로 두 번째 줄부터 빈 줄까지입니다. HTTP요청의 메세지 헤더와 같은 형식으로, 응답에 관한 부가적인 정보가 들어있습니다.
3.
메세지 본문
: 웹 브라우저는 메세지 본문에 있는 HTML을 해석해 화면에 표시합니다. HTML은 텍스트 형식이므로 우리가 읽을 수 있는 형식으로 메세지 본문에 저장되어 있습니다.
4. HTTP method

일반적으로 개발을하며 자주 사용하는 메소드는 GET, POST가 있고 그외에 PUT, DELTE정도가 자주 쓰입니다. GET 메소드는 Select적인 성향을 가지고 있어서 서버에서 데이터를 받아 보여주거나 하는 용도로 사용되며 서버의 값이나 상태등을 바꾸지 않습니다. 주로 게시판의 글 목록 가져와서 보여주거나 프로필 상태를 보여주거나 하는 것들이 이에 해당합니다.
POST 메소드는 서버의 값이나 상태를 바꾸거나 등록하기위해 사용합니다. 글쓰기를 하면 내용이 디비에 저장되고 수정을 하면 디비값이 수정이 됩니다. 이럴 경우에는 POST를 사용합니다.
•
GET: 특정 리소스의 표시를 요청합니다. GET을 사용하는 요청은 오직 데이터를 받기만 합니다.
•
HEAD: GET메서드의 요청과 동일한 응답을 요구하지만, 응답 본문을 포함하지 않습니다.
•
POST: 특정 리소스에 엔티티를 제출할 때 쓰입니다. 이는 종종 서버의 상태의 변화나 부작용을 일으킵니다.
•
PUT: 목적 리소스 현재 표시를 요청 Payload로 바꿉니다.
•
DELETE: 특정 리소스를 삭제합니다.
•
CONNECT: 목적 리소스로 식별되는 서버로의 터널을 맺습니다.
•
OPTIONS: 목적 리소스의 통신을 설정하는데 쓰입니다.
•
TRACE: 목적 리소스의 경로를 따라 메세지 look-back 테스트를 합니다.
•
PATCH: 리소스의 부분만을 수정하는데 쓰입니다.

