

목차
왜 스프링 배치인가?

배치가 필요한 여러 상황들
1.
은행 월별 거래명세서
월별 거래 내역을 거래가 이뤄질 때마다 만들어서 제공하는게 효율적일까?
그보다는 월말까지 기다려서 월별 거래 내역을 인쇄하는게 낫다.
2.
주문 내역 배송 처리
사업적으로도 쇼핑몰에서 사용자가 구매버튼을 누르자마자 배송 트럭에 실어서 보내야 할까?
배송목록에 저장된 후 특정 시간에 집계하여 한 번에 배송작업을 진행하게 된다면, 구매자는 주문 취소까지의 시간을 줄 수 있고, 판매자는 일일히 처리를 하지 않아도 되기에 비용 절감을 할 수 있다.
3.
자원의 효율적 관리(feat. 비즈니스 인텔리전스)
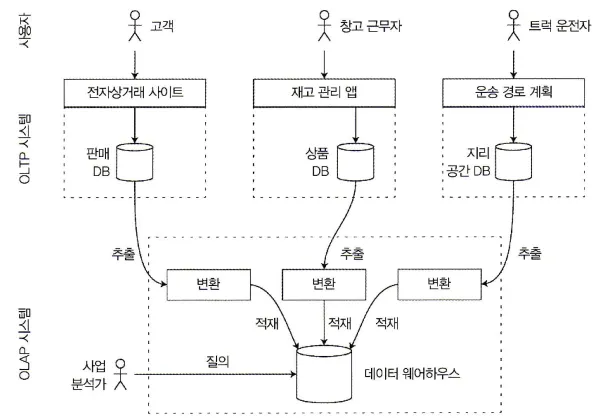
ETL의 간략한 개요
3시간이 걸리는 데이터 조회, 그룹핑, 필터 작업과 이 결과를 사용하는 1초짜리 작업이 있다고 할 때, 사용자가 원하는 시간은 1초다. 그렇기에 배치를 통해 스트리밍 시스템이 사용 할 데이터를 준비하기위한 첫 번째 작업을 배치 처리를 수행해 생성하고, 두 번째 단계는 스트리밍 시스템이 해당 결과를 실시간으로 사용하게 하는것이 합리적이다.
배치 처리가 무엇인가?
배치 처리가 무엇이길래 위와 같은 상황에서 사용되고 있다는 것인지 알 필요가 있다.
•
우리가 알고 있는 애플리케이션의 플로우
애플리케이션은 사용자와 상호작용한다.
배치 처리는
•
상호작용이나 중단 없이
•
특정 시간에 프로그램을 실행하고
•
대량의 데이터를 처리하며
•
일괄적으로 처리한다.
즉, 배치처리는 다음과 같은 상황에서 많이 사용된다.
•
대용량의 데이터를 복잡한 로직으로 처리해야 하는 경우
•
특정 시점에서 자동화된 작업이 필요한 경우
•
그 밖에 로깅/추적, 트랜잭션 관리, 작업 처리 통계, 작업 재시작, 건너뛰기, 리소스 관리와 같이 대용량 레코드 처리에 필수적인 기능이 필요한 경우
◦
배치 프로세스의 주기적인 커밋
◦
동시 다발적인 Job의 배치 처리 및 대용량 병렬 처리
◦
실패 후 수동 또는 스케줄링에 의한 재시작
◦
의존관계가 있는 Step들을 순차적으로 처리
◦
조건적 Flow 구성을 통한 체계적이고 유연한 배치 모델 구성
◦
반복, 재시도, 건너뛰기
왜 자바로 배치를 처리해야 할까?

배치의 장점, 사용 목적, 특징을 알아봤지만, 어째서 자바(혹은 스프링 배치)로 배치를 처리해야하는지에 대한 이해가 필요하다.

유지 보수성
: 배치 처리 코드는 다른 애플리케이션 코드보다 수명이 훨씬 길고, 사용자가 배치 코드를 볼 수 없다. 스프링 배치를 통해 스프링 생태계가 가진 장점들(testability, abstractions, DI, Spring Data JDBC, File I/O, Monitoring)을 누리는 것이 자바( 스프링 배치)가 제공하는 유지 보수성 측면의 장점이다.
유연성
JVM 의 유연성과 스프링 배치의 기능들을 이용할 수 있다.
즉, 자바의 특성인 한 번 작성해 어디서든 실행한다(Write Once, Run Anyware, WORA) 이다.
확장성
메인프레임에서는 확장성을 위한 용량 증설(스케일 업)이 제한된다.
하지만 스프링 배치를 이용해 높은 비용 작업(Ex: 청구 계산 작업)을 여러개로 나눠서 다른 노드로 밤새 완료시킬 수 있고, 매 달 특정한 날짜에 리소스 사용량이 급증할 때 클라우드 리소스 확장을 하는 것도 가능하다.
신뢰성
몇 가지 주요 원칙(설정)들만 잘 설정해두면 완전히 처리된 트랜잭션 커밋 건수와 롤백 건수를 얻을 수 있다.
개발 리소스
단순한 개발과 같은 기술적 이슈가 아닌 시스템 코딩 및 유지보수에 필요한 인력 수급 문제에서 배치 처리는 개발중인 웹 애플리케이션보다 수명이 길기에 관련 기술을 이해하는 사람을 찾는게 중요한데, 스프링 배치는 스프링 생태계이기에 러닝 커브도 낮은편이며, 인재풀을 구하기도 비교적 쉽다.
지원
혹은 생태계라고도 볼 수 있는데, 스프링 프레임워크 제품군은 깃허브(Github)나 스택오버플로(StackOverflow)에 커뮤니티가 상당히 방대하게 잘 갖춰져 있다.
그렇기에 이슈에 대한 해결방안도 더 손쉽게 찾을 수 있다.
스프링 배치 아키텍처
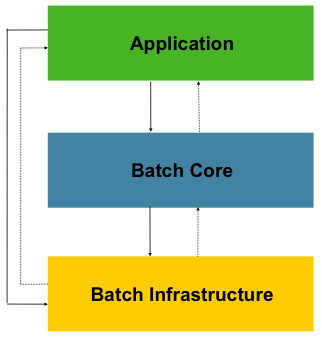
스프링 배치의 계층 구조는 각각의 계층이 자신의 영역에 집중할 수 있도록 설계되어 있어서 Application은 비즈니스 로직, Batch Core는 배치의 동작에만 신경쓰면 된다.
Application
: 스프링 배치 프레임워크를 통해 개발자가 만든 모든 배치 Job과 커스텀 코드를 포함하며, 개발자는 업무 로직에만 집중하고 그 외의 공통 부분에 대한 기술은 프레임워크가 담당하도록 할 수 있게 된다.
Batch Core
: 배치작업(Job)에 대한 관리(실행, 모니터링, 등)에 필요한 핵심 API를 가지고 있으며, JobLauncher, Job, Step, Flow등이 이에 속한다.
Batch Infrastructure
: Application과 Core 모두 공통 Infrastructure위에서 빌드한다.
Job실행의 흐름과 처리를 위한 틀을 제공하며 개발자와 애플리케이션이 사용하는 일반적인 Reader, Process Writer, Skip, Retry등이 속한다.
참고: 스프링 배치 아키텍처 좀 더 자세히
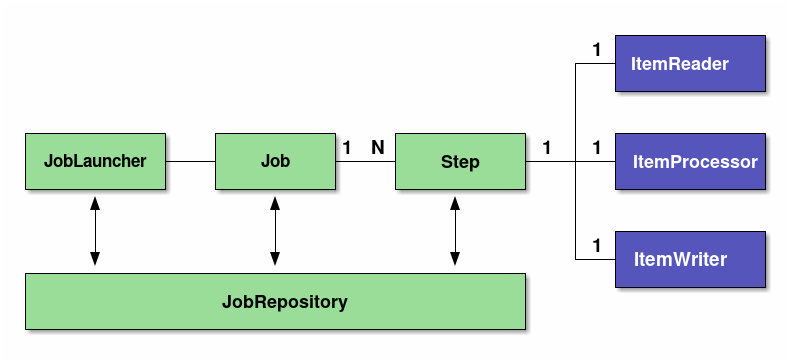
Components | Roles |
Job | 배치 처리 과정을 하나의 단위로 표현한 객체로 여러 Step을 포함하는 컨테이너이기도 한다.
반드시 하나 이상의 Step으로 구성해야 하고, Job이 실행될 경우 스프링 배치의 컴포넌트들은 탄력성을 위해 서로 상호작용을 한다. |
Step | Batch Job을 구성하는 독립적인 하나의 단계로 스프링 배치에서 가장 일반적인 상태 단위이다. 모든 Job은 하나 이상의 Step으로 구성되며, 배치 작업을 어떻게 구성하고 실행할 것인지 Job의 세부 작업을 Task 기반으로 설정하고 명세해놓은 객체이다. |
JobLauncher | 배치 Job을 실행시키는 역할을 하며, Job과 Job Parameter를 인자로 받으며 요청된 배치 작업 수행 후 최종 client에게 JobExecution을 반환한다. 그렇기에 Job의 재실행 가능 여부나 실행 방법, 파라미터 유효성 검증등도 같이 수행한다. 일반적으로 직접 다룰 필요가 없다. |
ItemReader
ItemProcessor
ItemWriter | 청크 모델을 구현하면서 데이터의 입력/처리/출력 3가지 프로세스로 분할하기 위한 인터페이스로 데이터 IO를 담당하는 ItemReader와 ItemWriter는 데이터 베이스와 파일을 Java객체 컨버팅을 제공하기에 Spring Batch를 사용하는 것으로 충분히 컨버팅이 가능하다. ItemProcessor는 입력 확인 및 비즈니스 로직을 구현한다. |
JobRepository | 배치 작업 중의 정보를 저장하는 저장소 역할을 한다.
저장 정보는 다양한 배치 수행과 관련된 수치 데이터와 잡의 상태이다. |
Basic Flow
@Configuration
@RequiredArgsConstructor
public class HelloJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Bean
public Job helloJob() {
return jobBuilderFactory.get("helloJob")
.start(helloStep())
.build();
}
@Bean
public Step helloStep() {
return stepBuilderFactory.get("helloStep")
.tasklet((contribution, chunkContext)->{
System.out.println("=========================");
System.out.println("Hello Spring Batch");
System.out.println("=========================");
return RepeatStatus.FINISHED;
}).build();
}
}
Java
복사

정상적으로 콘솔창에 Hello Spring Batch 를 출력하는걸 확인할 수 있다. 이제 이 코드의 흐름과 의미에 대해 살펴보자.
1.
@Configuration
: 하나의 배치 Job을 정의하고 빈 설정을 한다.
2.
JobBuilderFactory, StepBuilderFactory
: 각각 Job, Step을 생성하는 빌더 팩토리다.
3.
Job
: helloJob이라는 이름으로 Job을 생성한다.
4.
Step
: helloStep이라는 이름으로 Step을 생성한다.
5.
tasklet
: Step안에서 단일 태스크로 수행되는 로직을 수행한다.
Flow
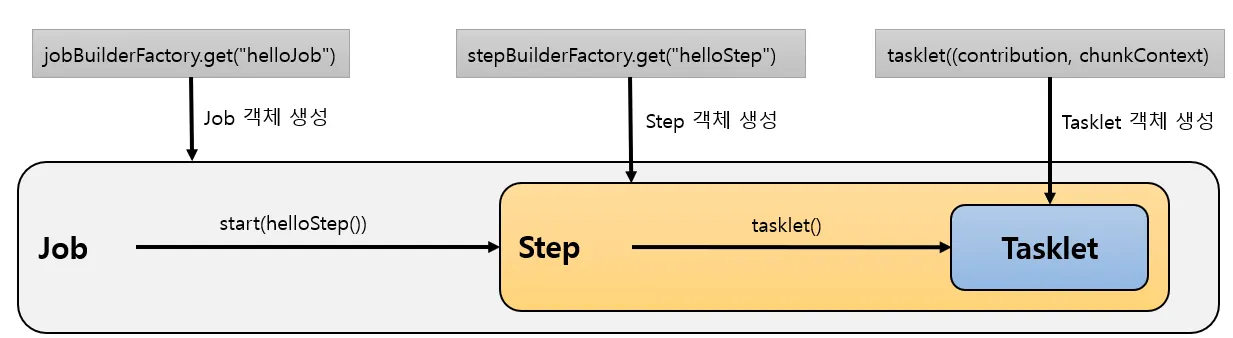
•
jobBuilderFactory.get(”helloJob”)으로 Job이 생성되면 start(helloStep)으로 Step을 실행하고,
•
stepBuilderFactory.get(”helloStep”)으로 생성된 Step이 Job에 의해 구동되면 tasklet()을 실행하고,
•
tasklet(contribution, chunkContext)→{…}) 으로 생성된 Tasklet 객체가 실행된다.
DB 스키마 살펴보기
/org/springframework/batch/core/schema-*.sql
스프링 배치에선 실행 및 관리 목적으로 Job, Step, JobParameters등 여러 도메인들의 정보를 관리(CRUD)할 수 있는 스키마를 제공한다. inMemory가 아닌 DB와 연동할 겨우 메타 테이블이 생성되어야 하는데, 이러한 메타테이블에 대한 DB 스키마는 스프링 배치 라이브러리에 존재하며 DB유형별로 제공되니 사용하는 DB에는 적절한 sql을 확인하면 된다.
물론, 직접 sql 쿼리를 가져다가 수동으로 생성을 해도 되고, 자동으로 생성할 수도 있다.
수동 생성 - 쿼리 복사 후 직접 실행
자동 생성 - 프로퍼티 에 자동 생성 속성 지정
spring:
batch:
jdbc:
initialize-schema: always(or EMBEDDED, NEVER)
YAML
복사
여기서 속성은 ALWAYS, EMBEDDED, NEVER 세 가지를 선택할 수 있는데 각각 다음과 같은 속성을 가진다.
•
ALWAYS: 스크립트는 항상 실행되고 RDBMS설정이 되어 있을 경우 내장 DB보다 우선 실행한다.
•
EMBEDDED: 내장 DB일 때만 실행되며 스키마가 자동생성된다, (DEFAULT)
•
NVER: 스크립트 항상 실행안하고 내장 DB일 경우 스크립트 생성이 되지 않아 오류가 발생한다. 운영에서는 수동으로 스크립트 생성 후 설정하는 것이 권장된다.
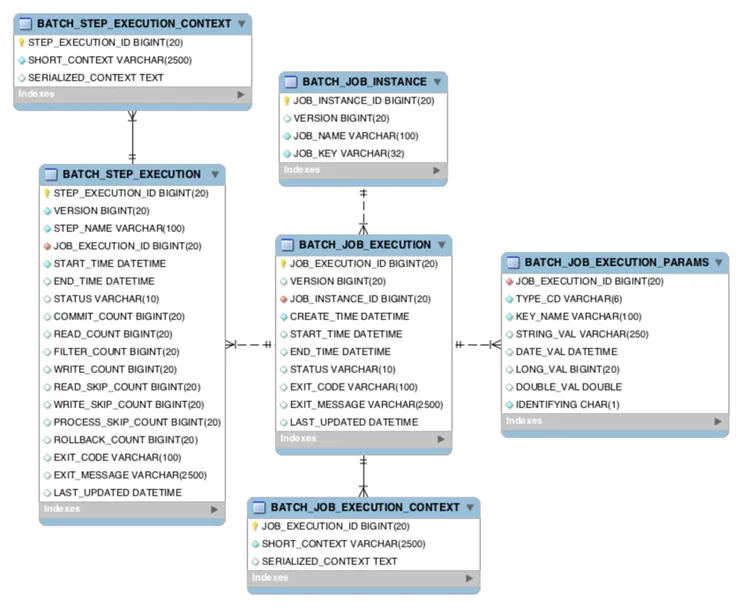
Job 관련 테이블
•
BATCH_JOB_INSTANCE
: Job이 실행될 때 JobInstnace 정보가 저장되며 Job_name과 job_key로 하여 하나의 데이터가 저장된다.
•
BATCH_JOB_EXECUTION
: Job의 실행정보가 저장되며 Job 생성, 시작, 종료 시간, 실행 상태, 메세지 등을 관리한다.
•
BATCH_JOB_EXECUTION_PARAMS
: Job과 함께 실행되는 JobParameter 정보를 저장한다.
•
ATCH_JOB_EXECUTION_CONTEXT
: Job의 실행 동안 여러가지 상태정보나 공유 데이터를 JSON형태로 직렬화 해서저장한다.
(중요) Step간 서로 공유가 가능하다.
Step 관련 테이블
•
BATCH_STEP_EXECUTION
: Step의 실행정보가 저장되며 생성,시작,종료시간, 실행상태, 메시지 등을 관리한다.
•
BATCH_STEP_EXECUTION_CONTEXT
: Step의 실행동안 여러가지 상태정보와 공유 데이터를 JSON형태로 직렬화 하여 저장한다.
Step별로 저장되며 Step간에 서로 공유할 수 없다.
메타 테이블 더 자세히 살펴보기
mysql 을 기준으로 설명한다.
1. BATCH_JOB_INSTANCE
CREATE TABLE BATCH_JOB_INSTANCE (
JOB_INSTANCE_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT ,
JOB_NAME VARCHAR(100) NOT NULL,
JOB_KEY VARCHAR(32) NOT NULL,
constraint JOB_INST_UN unique (JOB_NAME, JOB_KEY)
) ENGINE=InnoDB;
SQL
복사
•
JOB_INSTANCE_ID : 고유하게 식별할 수 있는 기본 키
•
VERSION: 업데이트 될 때마다 1씩 증가하는 필드
•
JOB_NAME: Job을 구성할 때 부여하는 Job의 이름
•
JOB_KEY: job_name과 jobParameter를 합쳐 해싱한 해시코드를 저장하는 필드
2. BATCH_JOB_EXECUTION
CREATE TABLE BATCH_JOB_EXECUTION (
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT ,
JOB_INSTANCE_ID BIGINT NOT NULL,
CREATE_TIME DATETIME(6) NOT NULL,
START_TIME DATETIME(6) DEFAULT NULL ,
END_TIME DATETIME(6) DEFAULT NULL ,
STATUS VARCHAR(10) ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED DATETIME(6),
JOB_CONFIGURATION_LOCATION VARCHAR(2500) NULL,
constraint JOB_INST_EXEC_FK foreign key (JOB_INSTANCE_ID)
references BATCH_JOB_INSTANCE(JOB_INSTANCE_ID)
) ENGINE=InnoDB;
SQL
복사
•
JOB_EXECUTION_ID : jobExecution을 고유하게 식별할 수 있는 기본 키로 JOB_INSTANCE와 1:N
•
VERSION : 업데이트 될 때마다 1씩 증가하는 필드
•
JOB_INSTANCE_ID: JOB_INSTANCE의 키
•
CREATE_TIME: 실행(Execution)이 생성된 시점
•
START_TIME: 실행(Execution)이 시작된 시점
•
END_TIME : 실행(Execution)이 종료된 시점 ( job실행 도중 오류가 발생해 중단되면 값이 저장되지 않을 수도 있다.
•
STATUS: 실행 상태(BatchStatus)를 저장한다.(ex: COMPLETED, FAILED, STOPPED, STARTED, …)
•
EXIT_CODE: 실행 종료 코드(ExitStatus)를 저장한다.(ex. COMPLETED, FAILED, UNKNOWN, …)
•
EXIT_MESSAGE: Status가 실패일 경우 실패 원인을 저장한다.
•
LAST_UPDATED: 마지막 실행(Execution) 시점
3. BATCH_JOB_EXECUTION_PARAMS
CREATE TABLE BATCH_JOB_EXECUTION_PARAMS (
JOB_EXECUTION_ID BIGINT NOT NULL ,
TYPE_CD VARCHAR(6) NOT NULL ,
KEY_NAME VARCHAR(100) NOT NULL ,
STRING_VAL VARCHAR(250) ,
DATE_VAL DATETIME(6) DEFAULT NULL ,
LONG_VAL BIGINT ,
DOUBLE_VAL DOUBLE PRECISION ,
IDENTIFYING CHAR(1) NOT NULL ,
constraint JOB_EXEC_PARAMS_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
SQL
복사
•
JOB_EXECUTION_ID: JobExecution 식별 키로 JOB_EXECUTION과 1:N 관계
•
TYPE_CD: String, Long, Date, Double 타입 정보
•
KEY_NAME: 파라미터 키 값
•
STRING_VAL: 파라미터 문자 값
•
DATE_VAL: 파라미터 날짜 값
•
LONG_VAL: 파라미터 Long 값
•
DOUBLE_VAL: 파라미터 Double 값
•
IDENTIFYING: 식별 여부(true, false)
4. BATCH_JOB_EXECUTION_CONTEXT
CREATE TABLE BATCH_JOB_EXECUTION_CONTEXT (
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT ,
constraint JOB_EXEC_CTX_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
SQL
복사
•
JOB_EXECUTION_ID: JobExecution 식별키로 JOB_EXECUTION마다 각 생성된다.
•
SHORT_CONTEXT: JOB의 실행 상태 정보로 공유 데이터 등의 정보를 문자열로 저장한다.
•
SERIALIZED_CONTEXT: 직렬화(Serialized) 된 전체 컨텍스트를 저장한다.
5. BATCH_STEP_EXECUTION
CREATE TABLE BATCH_STEP_EXECUTION (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT NOT NULL,
STEP_NAME VARCHAR(100) NOT NULL,
JOB_EXECUTION_ID BIGINT NOT NULL,
START_TIME DATETIME(6) NOT NULL ,
END_TIME DATETIME(6) DEFAULT NULL ,
STATUS VARCHAR(10) ,
COMMIT_COUNT BIGINT ,
READ_COUNT BIGINT ,
FILTER_COUNT BIGINT ,
WRITE_COUNT BIGINT ,
READ_SKIP_COUNT BIGINT ,
WRITE_SKIP_COUNT BIGINT ,
PROCESS_SKIP_COUNT BIGINT ,
ROLLBACK_COUNT BIGINT ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED DATETIME(6),
constraint JOB_EXEC_STEP_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
SQL
복사
•
STEP_EXECUTION_ID: Step의 실행 정보 기본 키
•
VERSION: 업데이트 될 때마다 1씩 증가
•
STEP_NAME: Step을 구성할 때 부여하는 Step 이름
•
JOB_EXECUTION_ID: JobExecution 기본키로 JobExecution과 1:N관계
•
START_TIME: 실행(Execution)이 시작된 시점
•
END_TIME: 실행(Execution)이 종료된 시점으로 Job 실행 도중 오류로 인해 중단된 경우 값이 저장되지 않을 수 있다.
•
STATUS: 실행 상태(BatchStatus)를 저장한다.(ex: COMPLETED, FAILED, STOPPED, STARTED, …)
•
COMMIT_COUNT: 트랜잭션 당 커밋되는 수
•
READ_COUNT: 실행시점에 Read한 Item count
•
FILTER_COUNT: 실행도중 필터링 된 item수
•
WRITE_COUNT: 실행도중 저장되고 커밋된 Item 수
•
READ_SKIP_COUNT: 실행도중 Read가 건너뛰어진(Skip) Item 수
•
WRITE_SKIP_COUNT: 실행도중 Write가 건너뛰어진(Skip) Item 수
•
PROCESS_SKIP_COUNT: 실행도중 Process가 건너뛰어진(Skip)된 Item 수
•
ROLLBACK_COUNT: 실행도중 Rollback이 일어난 수
•
EXIT_CODE: 실행 종료 코드(ExitStatus)를 저장한다.
•
EXIT_MESSAGE: Status가 실패일 경우 실패 원인 내용을 저장한다.
•
LAST_UPDATED: 마지막 실행(Execution)시점
6. BATCH_STEP_EXECUTION
CREATE TABLE BATCH_STEP_EXECUTION_CONTEXT (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT ,
constraint STEP_EXEC_CTX_FK foreign key (STEP_EXECUTION_ID)
references BATCH_STEP_EXECUTION(STEP_EXECUTION_ID)
) ENGINE=InnoDB;
SQL
복사
•
STEP_EXECUTION_ID: StepExecution 식별 키, STEP_EXECUTION 마다 각 생성된다.
•
SHORT_CONTEXT: STEP의 실행 상태 정보, 공유 데이터 등의 정보를 문자열로 저장한다.
•
SERIALIZED_CONTEXT: 직렬화(Serialized)된 전체 컨텍스트

