상속관계 매핑
•
관계형 데이터베이스는 상속 관계가 없다.
•
슈퍼타입 서브타입 관계라는 모델링 기법이 객체 상속과 유사
•
상속관계 매핑: 객체의 상속과 구조와 DB의 슈퍼타입 서브타입 관계를 매핑

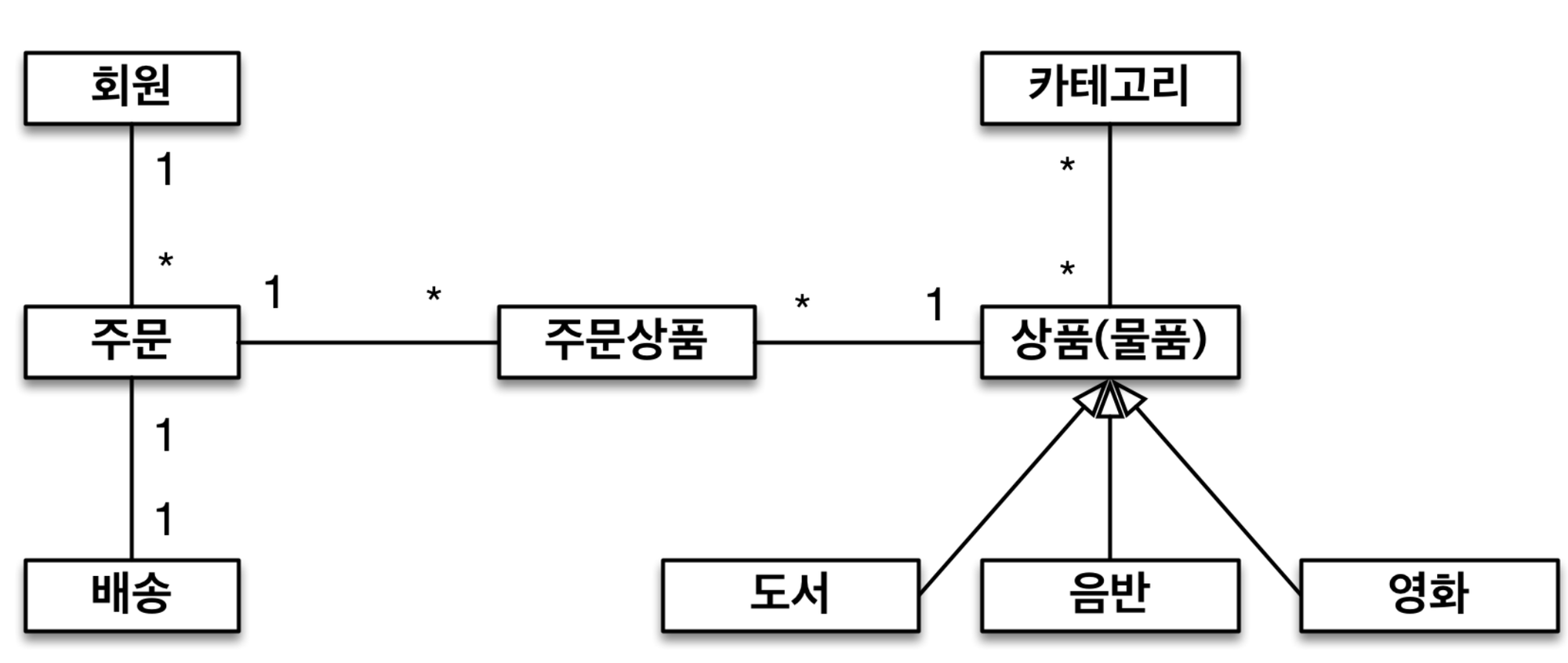
Album, Movie, Book은 모두id, name, price를 가지고 있다(공통 변수)
슈퍼타입 서브타입 논리 모델을 실제 물리 모델로 구현하는 방법
1. 조인전략
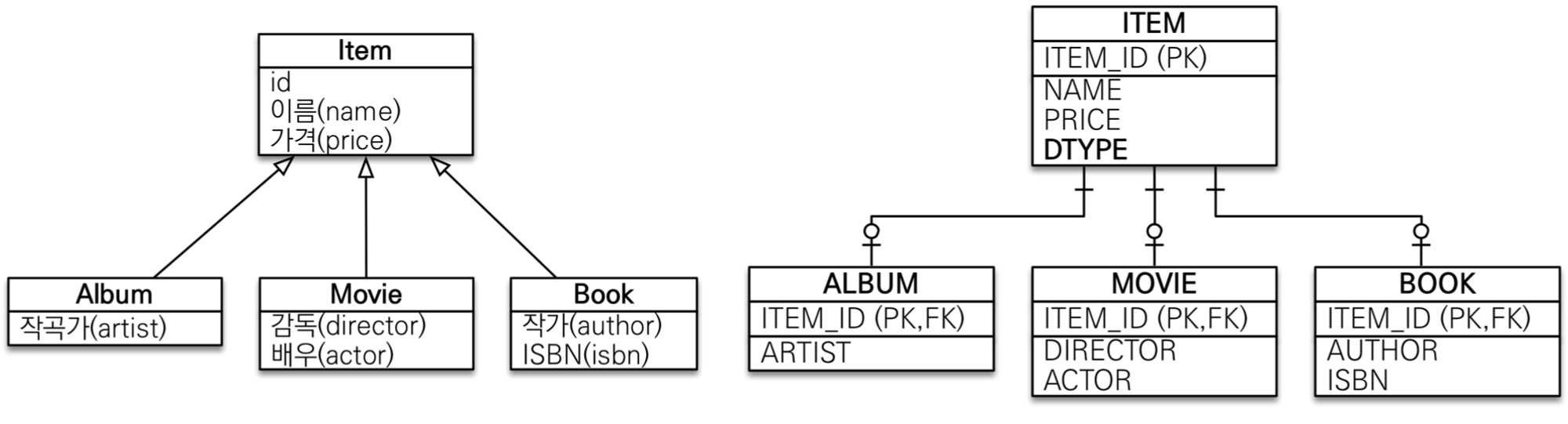
•
Item, Album에 pk,fk가 같아 각각의 테이블에 insert를 수행하고 Item내에 타입을 구분하는 컬럼을 만들어서 구해온다.
•
모든 자손 엔티티가 상위 엔티티의 아이디를 PK이자 FK로 지정해줘야 하는데, 컬럼명을 각각의 하위 클래스별로 다르게 만들고 싶다면 @PrimaryKeyJoinColumn 애노테이션을 활용하면 된다.
•
장점
◦
정규화도 되어있고, 제약조건을 부모에 걸어 맞출 수 있다.
▪
ex: Order 테이블에서 특정 아이템(영화)의 가격을 볼때 ITEM 테이블만 봐도 된다.
◦
저장공간 효율화
•
단점
◦
조회시 조인이 많을 경우 성능 저하
◦
조회 쿼리가 복잡함.
◦
데이터 저장시 INSERT SQL 2번 호출(큰 문제는 아님)
•
조인이 많아도 조건이 잘 걸려있을 경우 성능 하락이 크지 않고 저장공간이 효율적으로 되기에 오히려 더 좋을 수 있다는 점을 고려해야 한다.
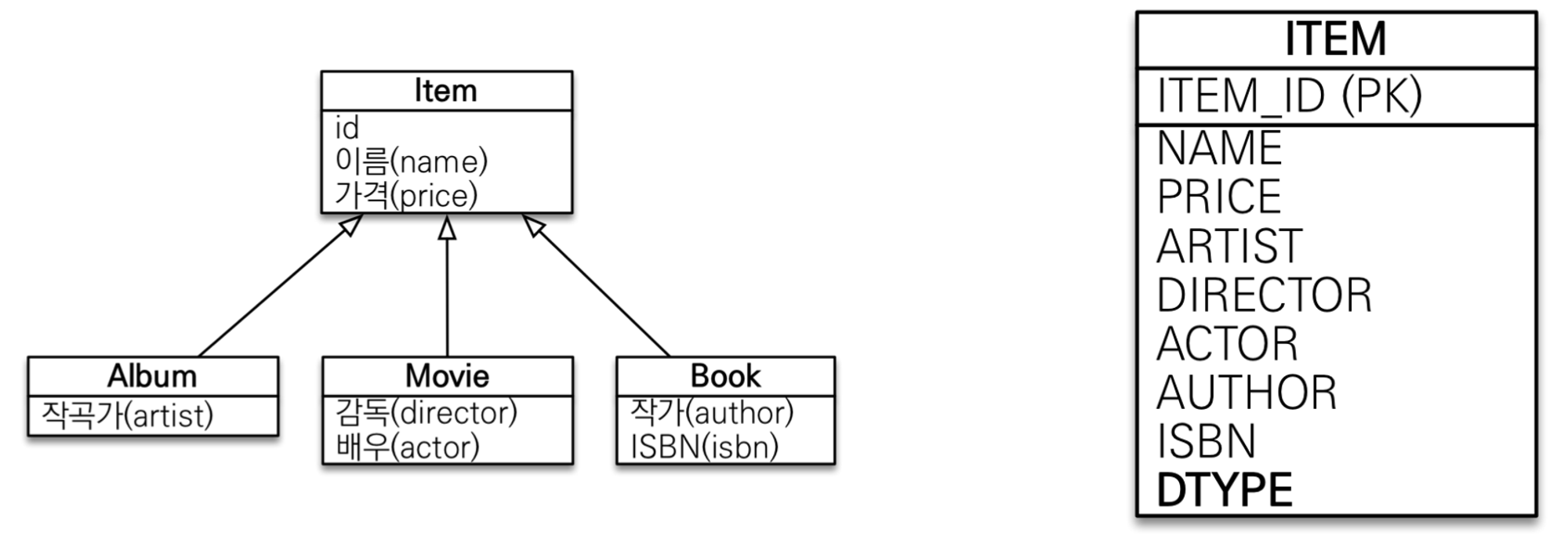
2. 단일 테이블 전략(default)
•
논리모델을 한 테이블로 합쳐버리는 방법.
•
한 테이블에 다 넣어 놓고 어떤 테이블인지 구분하는 컬럼(ex:DTYPE)을 통해 구분한다.
•
테이블은 ITEM 테이블 하나만 관리된다.
•
성능에서 우위를 가질 수 있다. (select or insert 가 한번에 수행으로 된다.)
•
@DiscriminatorColumn 이 필수로 들어간다(기입하지 않아도 자동으로 들어감)
•
장점
◦
조인이 필요 없기에 일반적으로 조회 성능이 빠름
◦
조회 쿼리가 단순함.
•
단점
◦
자식 엔티티가 매핑한 컬럼은 모두 nullable 해야 한다.
◦
단일 테이블에 모든 것을 저장하기에 테이블이 커질 수 있고 상황에 따라서
조회성능이 더 느려질 수 있다.
(임계점을 넘을 정도의 상황은 거의 오지 않는다.)
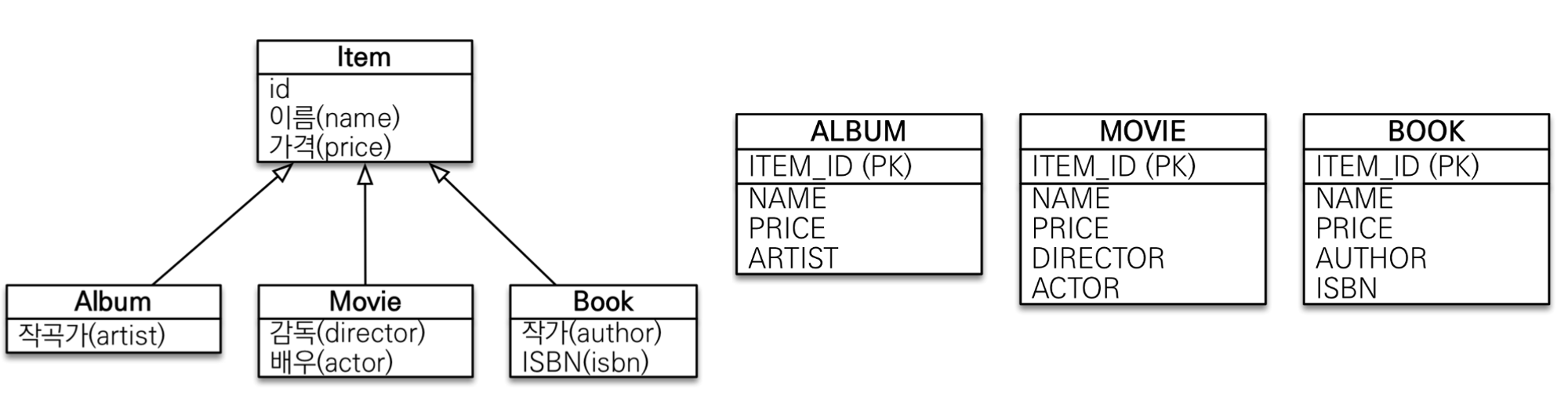
3. 구현 클래스마다 테이블 전략
•
각각의 테이블마다 별개로 만들어서 따로 관리
•
ITEM 테이블을 생성하지 않고 ALBUM, MOVIE, BOOK 테이블에서 각각 id, name, price필드를 가지고 있다.
•
@DiscriminatorColumn을 사용할 수 없다.(구분 할 이유가 없다.)
•
ITEM을 조회하면 ALBUM, MOVIE, BOOK 세개의 테이블을 UNION ALL으로 전부 조회해서 가져온다.(단점)
•
추천하지 않는 전략(개발자,DBA 양측에서)
•
장점
◦
서브 타입을 명확하게 구분해서 처리할 때 효과적
◦
Not null 제약조건 가능
•
단점
◦
여러 자식 테이블을 함께 조회할 때 성능이 느림(UNION SQL)
◦
자식 테이블을 통합해서 쿼리하기 힘듬.
Default view
Search
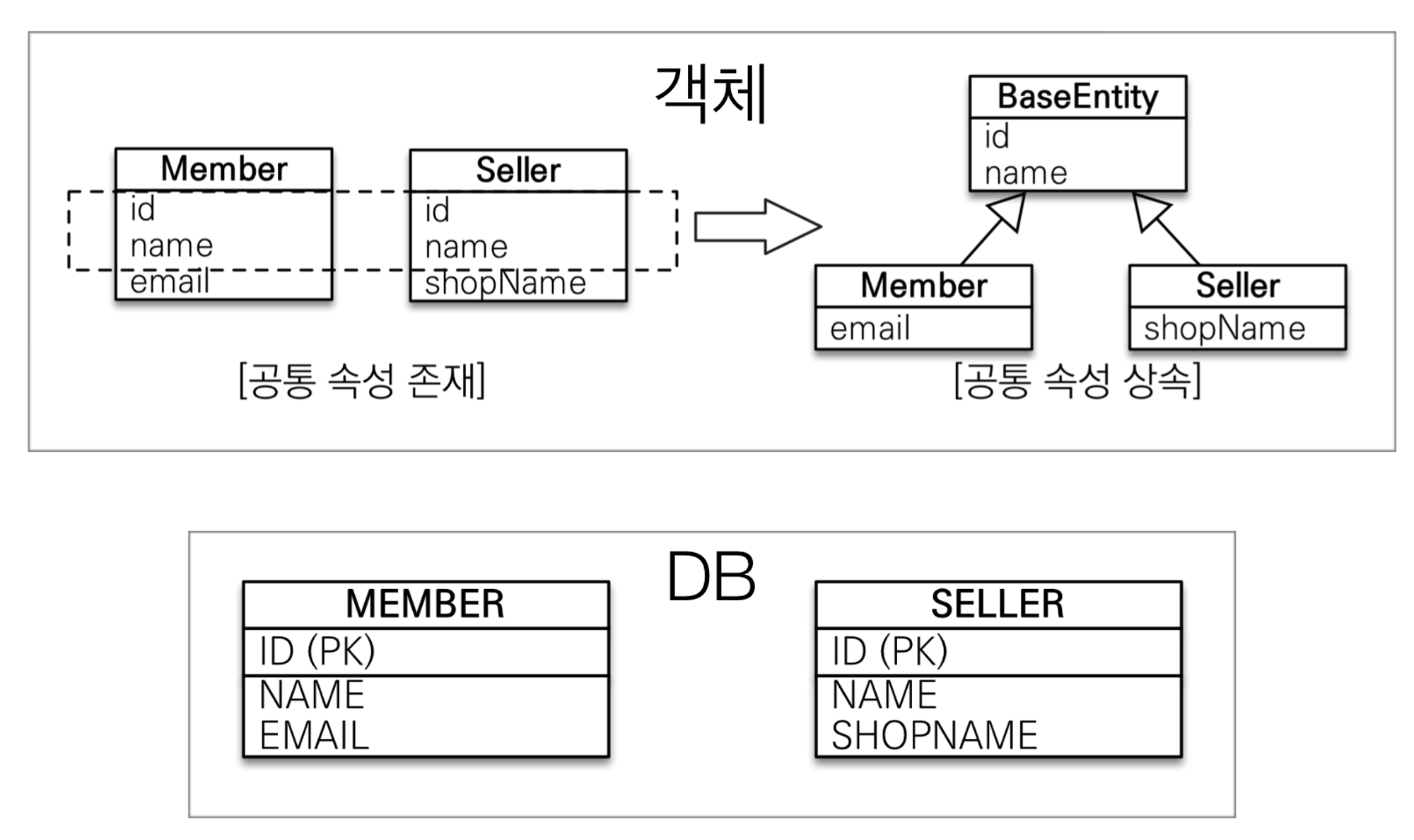
@MappedSuperclass
•
공통 매핑 정보가 필요할 때 사용(id, name)
◦
ex: 모든 테이블에 row 생성일, 수정일을 등록해야하는경우(createdAt, updatedAt)
•
상속관계 매핑이 아니다.
•
엔티티도 아니고, 테이블과 매핑되지도 않는다.
•
부모 클래스를 상속받는 자식 클래스에 매핑 정보만 제공
•
부모타입으로 조회,검색 불가
•
직접 생성해서 사용할 일이 없으므로 추상클래스 추천
 @Entity클래스는 엔티티나 @MappedSuperclass로 지정한 클래스만 상속 가능
@Entity클래스는 엔티티나 @MappedSuperclass로 지정한 클래스만 상속 가능실전예제
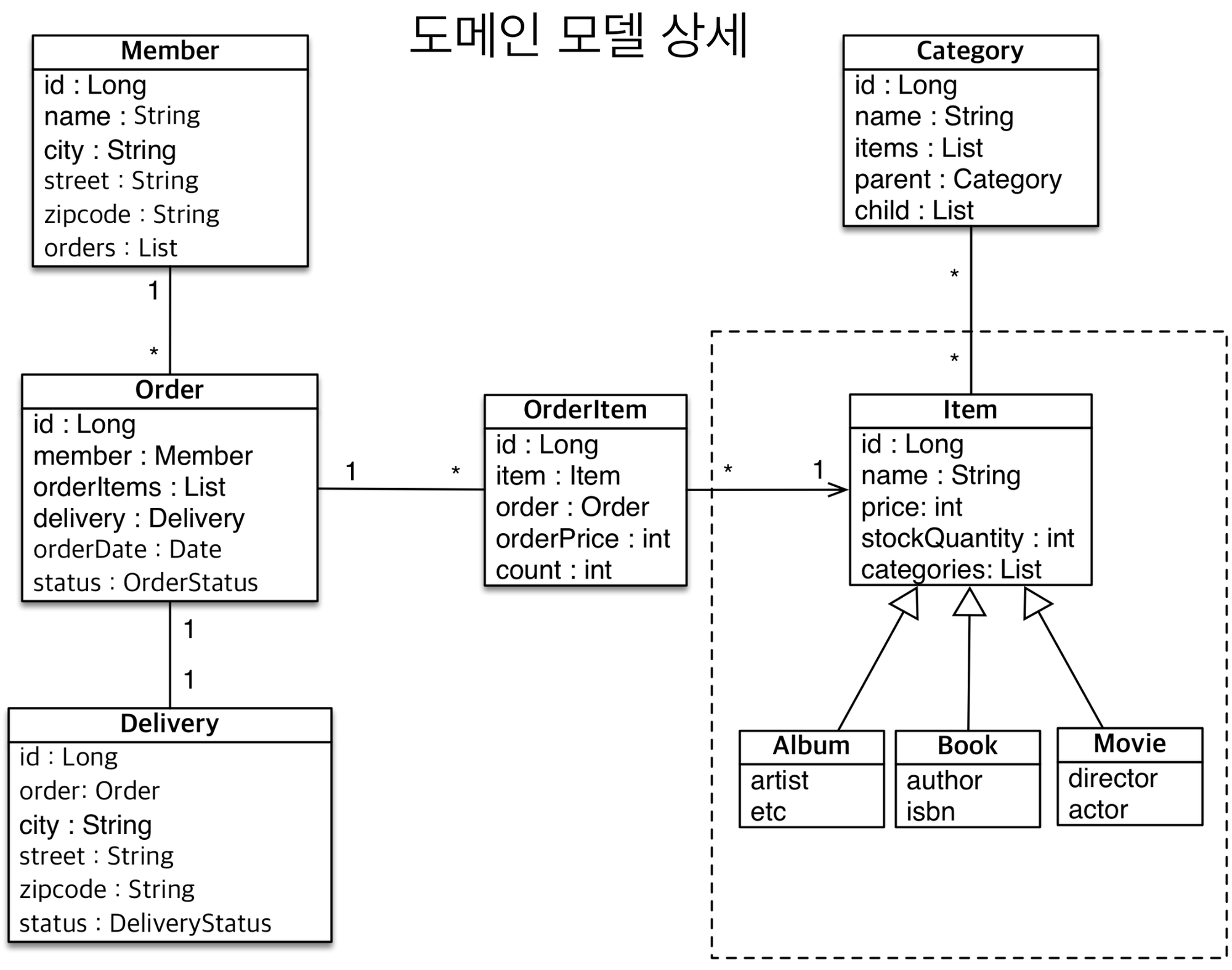
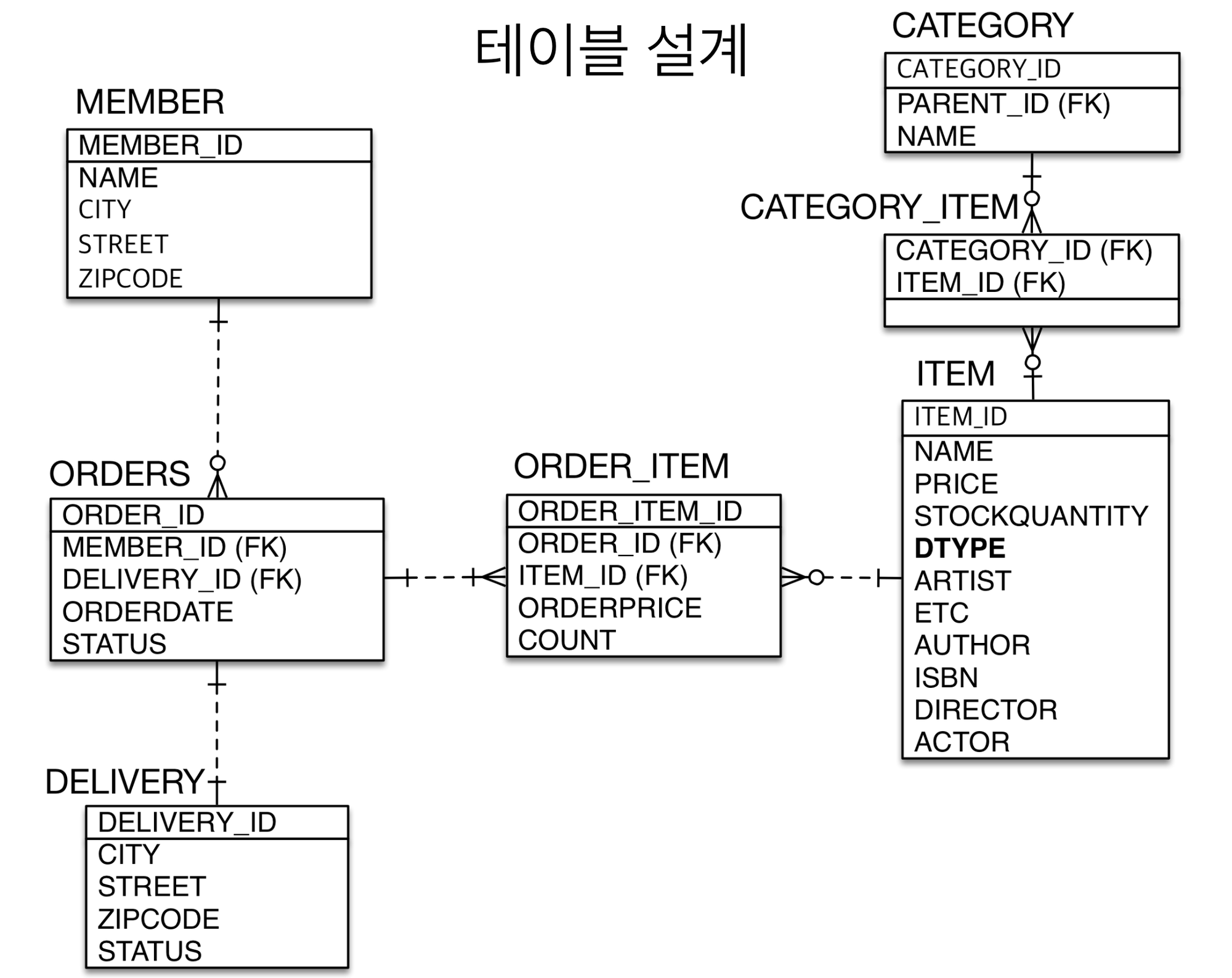
하단 도메인 모델을 참고하여 JPA를 이용하 예제를 만들어 보자.