
목차
개요
재사용성(resusability) 이라는 키워드는 개발자에게 항상 고민을 하게 만드는 요소다.
우리가 만드는 여러 기능들 중에서 하나가아닌 여러 클라이언트가 사용한다는 이유로 xxxUtils라는 객체에서 범용적으로 제공되며 재사용성을 높힐 수도 있다. 하지만, 이렇게 되면 재사용성은 높아지지만 해당 객체가 책임져야 할 바운더리는 끔찍하게 넓어져서 결국엔 모든 객체의 책임을 져야 하는 상황이 올 수도 있다. 그 뿐아니라 너무 많이 얽혀서 변경할 수 없는 코드가 만들어질 확률도 있다.
그렇다면 재사용성은 나쁜것일까? 그렇진 않다. System.out.print 함수가 사라져서 매번 직접 구현해야 한다면 JNI를 통해 C를 이용해 OS와 통신하는 것까지 직접 구현해야 하고, 그외에 우리가 편하게 사용하는 Collection API, Stream API, Iterable, Iterator 프로토콜까지 모두 매번 다시 만들어줘야 할 것이다. 생각만 해도 끔찍하다.
그렇기에 재사용성은 정말 쉬워보이지만 또 어려운 키워드다.
이번 장에서는 이러한 재사용성에 대해 살펴보고, 올바른 재사용성을 구현하는 방법에 대해 알아보자.
19. knowledge를 반복해 사용하지 말라

프로젝트에서 이미 있던 코드를 복사해서 붙여 넣고 있다면, 무언가 잘못된 것이다.
knowledge가 무엇인지부터 알아보자.
프로그래밍에서 knowledge는 넓은 의미로 ‘의도적인 정보’를 뜻한다.
다음 코드를 보자. Child에서는 Parent를 상속하지만 methodA를 재정의 하진 않았다. 이를 통해 우리는 ‘해당 메서드가 슈퍼클래스(Parent)와 동일하게 동작하길 원한다’ 라는 정보를 제공한다는 것을 알 수 있다.
open class Parent() {
open fun methodA(){...}
}
class Child() : Parent {
...
}
Kotlin
복사
이와 같이 프로젝트를 진행하며 정의한 모든 것이 knowledge라 할 수 있다.
가독성이 좋다는 말은 곧 knowledge를 잘 나타낸다고 볼 수도 있다. 그럼 이러한 의도적인 정보(knowledge)는 우리 프로그램에서 뽑아보면 다음과 같다.
1.
Logic
: 프로그램이 어떠한 식으로 동작하는지와 프로그램이 어떻게 보이는지
2.
Common Algorithm
: 원하는 동작을 하기 위한 알고리즘
두 knowledge의 가장 큰 차이는 시간에 따른 변화다.
로직은 시간이 흐름에 따라 계속해서 변하지만, 공통 알고리즘은 한 번 정의된 이후 거의 변화하지 않는다. 내부적으로 알고리즘 최적화등의 리팩토링은 있을 수 있지만 동작은 크게 변하지 않는다.
로직은 결국 변화한다.
예전 코드숨이라는 교육과정에서 리뷰를 받았던 내용 중 하나가 다음 내용이였다.
변하지 않는 진리는 변한다는 것이다.
처음엔 무슨 소린가 했는데, 해당 아이템과 연관되어 생각해보면 비즈니스 로직은 결국 사용자(고객)의 니즈를 토대로 만들어지는 것이고, 니즈는 변할 수 밖에 없고, 그에 따라 로직도 변할 수 밖에 없다.
옛날 네이버 메인화면
최근 네이버 메인화면
이처럼 우리 프로젝트들의 knowledge도 계속해서 변화하고, 이런 변화의 이유는 사용자의 니즈를 포함해 다음과 같다.
•
회사가 사용자의 니즈나 습관등을 더 많이 알게 되었다.
•
디자인 표준이 바뀌었다.
•
플랫폼, 라이브러리, 도구 등이 변화되어 이에 대응해야 한다.
변화에 대응하기 위해서는?
그렇다면 이런 변화에 대응해서 우리는 로직도 변화해야 한다.
이 때 변화의 가장 큰 적은 knowledge가 반복되어 있는 곳들이다. 좀 더 쉽게 말하면 중복된 코드들이다.
어째서 위험할까? 중복된 코드가 N개 있다고 가정할 때 내가 아주 신경 써서 모두 업데이트 해준다고 해도 1개 이상 놓칠 가능성은 있고, 이 경우 문제가 된다. 또한 이런 작업들은 상당히 귀찮기도 하다.
그리고 힘들게 모두 변화했지만, 생각보다 큰 개선 효과가 없을 수도 있고, 놓쳤을 때 생기는 이슈가 크리티컬 할 수도 있다.
즉, knowledge의 반복은 프로젝트의 확장성(scalable)을 막고, 깨지기 쉬운 코드가 되도록 만든다.
그래서 우리는 다양한 추상화 도구들(Ex: ORM, DAO, Interface, …)을 이용해 반복을 줄여야 한다.
코드 반복이 허용되는 순간도 있다.
방금까지 knowledge 반복은 안좋다고 말하면서 바로 말을 뒤집는 것 같지만, 좀 더 얘기를 들어볼 필요가 있다. 진정하도록 하자.

진정하도록 하자.
코드 반복이 허용되는 순간은 반복 같지만 반복이 아닌 경우이다. 뭔 소리인가 싶겠지만, 말 그대로이다. 코드만 봐서는 반복된 코드인 것 같지만, 실제로는 다른 knowledge를 나타내는 경우이다.
fun validateSellingPrice(toy: CatToy): Boolean {
return toy.price > FEE_LIMIT_PRICE
}
fun validateWholesalePrice(toy: CatToy): Boolean {
return toy.price > FEE_LIMIT_PRICE
}
Kotlin
복사

위 코드를 보자. 하나는 소매가 하나는 도매가격의 유효성 검증로직이다.
둘 다 동일한 knowledge(FEE_LIMIT_PRICE보다 큰지)를 보여주고 있다. 같은 knowledge로 보이지만, 다르다.
도매가의 검증로직이 변하더라도 소매가의 검증로직이 같이 변해야 할 이유도 의무도 없다. 즉 두 로직을 중복으로 판단해 하나로 합칠 경우 문제가 될 수 있다.
즉, 같은 knowledge인지 판단하는 조건에는 함께 변경될 가능성이 높은지를 살펴보는 것으로도 어느정도 판단 할 수 있다.
그리고 또 다른 유용한 휴리스틱(결험과 직관을 기반으로 한 근사적인 문제 해결 방식)으로, 단일 책임 원칙(Single Responsiblity Principle, SRP)을 이용해 볼 수 있다.
클린 아키텍처의 SOLID 챕터에서는 SRP를 하나의 클래스는 하나의 액터(actor)에 대해서 책임져야 한다고 하는데, 이 말은 하나 이상의 액터가 같은 클래스를 변경하는 없어야 한다는 의미이기도 하다.
여기서 액터란 변화를 만들어 내는 존재(source of change)를 의미한다. 즉 정산 API 개발팀 개발자와 추천 상품 노출 API 개발팀 개발자가 같은 클래스를 바라봐서는 안된다는 것을 의미한다.
우리는 당연히 코드의 중복을 없애기 위해 (Don’t Repeat Yourself) 중복을 제거하려고 하고, 하나 이상의 액터가 하나의 클래스를 바라볼 경우, 중복을 제거한다는 미명하에 개발 당시엔 같은 기능으로 보이고 같은 로직으로 보이는 knowledge를 만들어 같이 사용하게 될 경우가 생기는데, 1년 2년 혹은 5년이상 지난 뒤 한 액터가 변경을 할 경우, 그리고 다른 액터측에선 변경을 할 필요가 없는 경우, 결국 knowledge를 변경해서 이슈가 생기거나 새로운 knowledge를 만드는 비용이 추가되게 될 것이다.
중복을 제거하는 것은 좋지만, 언제나 극단적인 방식은 문제를 일으킬 수 밖에 없고, 그렇기에 균형이 중요하다.
그렇기에 우리는 정말 중복되는 knowledge와 그렇지 않은 knowledge를 구분해서 작업해야 하며, 하나의 개념에 매몰되어 위험성을 외면해서는 안된다.
20. 일반적인 알고리즘을 반복해서 구현하지 말라
바퀴를 다시 발명하지 마라(Don’t reinvent the wheel)
개발자들이라면 한 번쯤은 들어봤을만한 문구일 것이다.
개발자들은 여러 기능들을 개발하면서 여러 알고리즘들을 구현하게 되고 그 중 몇 알고리즘은 반복해서 구현이 필요할 수 있다. 예를 들어 1부터 n까지의 값들을 순회하며 더하거나, 특정 범위를 벗어난 값은 설정 해 놓은 기본 값을 반환하도록 하는 등의 알고리즘 말이다.
그럼 이러한 로직들을 매 번 다시 작성하는 것은 짧게는 한 줄에서 길게는 수십 줄 이상 시간이 소요될 수 있다. 그리고 개발자들은 내가 직접 만든 이 알고리즘에 자부심을 느낄 수도 있다.
하지만, 자기가 작성한 기능, 알고리즘, 코드에 애착심과 감정이입을 하지 않도록 해야 한다.
어째설까? 이입을 하는 순간 협업간의 코드 리뷰를 정확하게 받아들일 수 없게 되고, 그렇게 되면 코드리뷰 분위기가 경직될 뿐 아니라 내 코드가 더 발전할 수 있는 기회를 놓칠 수 있다.
이 뿐만이 아니다.
우리는 제한된 일정속에서 일정한 퀄리티의 기능을 만들어내야 하는데, 이미 안정적으로 많은 개발자들이 사용하는 라이브러리를 사용하는게 내가 직접 한 줄 한 줄 작성하는 것보다 높은 생산성과 안전성을 보장해줄 수 있다.
또한 시그니처를 잘 보여주는 함수의 네이밍은 그 자체로 의도와 결과를 유추할 수 있기에 가독성을 높힐 수 있고, 무엇보다 내가 직접 만들 경우 발생할 수 많은 실수들을 이미 다 해결한 라이브러리를 사용하는게 좋다.
여러 범용 라이브러리를 사용하는 것이 출근을 하거나, 결혼식을 가거나, 장례식을 갈 때마다 적절한 브랜드의 옷을 사서 입는 것에 비유한다면, 알고리즘을 직접 매 번 구현하는 것은 여러 행사나 모임에 갈 때마다 직접 재봉기를 사서 옷을 만들어서 입고 가는 것이라 할 수 있을 것이다.
우리는 옷의 원단, 옷의 박음질, 주머니의 갯수, 주머니의 크기등을 직접 모두 고려할 필요가 없다. 그런건 그냥 전문가가 직접 연구하고 테스트까지 마친 완성된 옷을 사서 입고, 좀 더 내게 중요한 핵심(위의 예를 이어서 생각하면 출근, 결혼식, 장례식)에 집중하는 게 낫지 않을까?
표준 라이브러리에 없는 알고리즘
하지만, 상황에 따라 내가 직접 알고리즘을 만들어서 사용해야 할 수도 있다.
fun Iterable<Int>.product() = fold(1) { acc, i -> acc * i }
Kotlin
복사
모든 숫자의 곱을 계산하는 product() 확장 함수
코틀린에서는 확장 함수를 제공하는데 이를 이용해 톱레벨 함수, 프로퍼티 위임, 클래스 등과 비교해서 다음과 같은 장점을 가진다.
•
함수는 무상태(stateless)이기에 행위를 나타내기 좋다.
•
톱레벨 함수와 비교해, 확장 함수는 구체적인 타입이 있는 객체에만 사용을 제한할 수 있다.
•
수정할 객체를 아규먼트로 전달받아 사용하는 것보다 확장 리시버로 사용하는게 가독성이 높다.
•
확장 함수는 객체에 정의한 함수보다 객체를 사용할 때, 자동 완성 기능으로 제안이 이뤄지기에 찾기 쉽다.
21. 일반적인 프로퍼티 패턴은 프로퍼티 위임으로 만들어라
코틀린에서는 코드 재사용과 관련해 프로퍼티 위임(property delegation)이라는 기능을 제공하는데, 이 개념을 이용해 여러 중복되는 행위들을 재사용 가능하게 만들 수 있다.
스프링에서 흔히 AOP(Aspect Oriented Programming) 이라는 관점 지향 프로그래밍 방법을 이용해 많은 코드의 중복들을 제거했다. 프로퍼티 위임도 이와 크게 다르지 않다.
예를 들어 초기화 시점을 프로퍼티 생성이 아닌 처음 사용하는 시점으로 미루고 싶을 경우 lazy 지연 프로퍼티를 이용해 할 수 있다.
val value by lazy { createValue() }
Kotlin
복사
value는 최초 호출 직전까지 createValue() 메서드는 호출되지 않는다. 즉, 지연되다가 실제로 사용하는 시점에 호출되어 비용을 절약하는 것이다.
이 뿐만이 아니라 ovservable 패턴도 프로퍼티 위임을 통해 쉽게 해결할 수 있다.
subject, observer 인터페이스를 만들고 구독/해지/발행 등의 행위들을 정의하고 구현할 필요가 없다.
var items: List<Item> by
Delegates.observable(listOf()) {_, _, _ -> notifyDataSetChanged() }
Kotlin
복사
이 밖에도
•
뷰
•
리소스 바인딩
•
의존성 주입
•
데이터 바인딩
같은 여러 동작에서도 자바에서는 애노테이션을 통해 제어해야 했던 것들을 프로퍼티 위임을 사용해 간단하고 type-safe하게 구현할 수 있게 되었다.
위에서 Spring AOP와 비슷하다고 했던 걸 기억 한다면, 그와 비슷하게 로깅 기능을 위임으로 추가해볼수도 있다.
var token: String? by LoggingProperty(null)
private class LoggingProperty<T>(var value: T) {
operator fun getValue(
thisRef: Any?,
prop: KProperty<*>
): T {
print("${prop.name} returned value $value")
return value
}
operator fun setValue(
thisRef: Any?,
prop: KProperty<*>,
newValue: T
) {
val name = prop.name
print("$name changed from $value to $newValue")
value = newValue
}
}
Kotlin
복사
getValue와 setValue는 단순하게 값만 바꾸고 반환하는게 아니라, 컨텍스트(this)와 프로퍼티 레퍼런스의 경계도 같이 사용하는 형태다. 그렇기에 getValue, setValue 메서드가 여러 개 있어도 컨텍스트 정보를 통해 구분할 수 있기에 상황에 따라 적절한 메서드가 선택될 수 있다.
범용적인 프로퍼티 델리게이터를 알아두면 유용하게 사용할 수 있으니 익혀두면 좋을 것 같다.
•
lazy
◦
위에서 설명했으니 생략
•
Delegates.observable
◦
값이 변경될 때마다 알림을 받는다.
var observedValue: Int by Delegates.observable(0) { prop, old, new ->
println("$old -> $new")
}
observedValue = 1 // 출력: 0 -> 1
observedValue = 2 // 출력: 1 -> 2
Kotlin
복사
•
Delegates.vetoable
◦
특정 조건을 충족하지 않으면 값 변경을 거부한다.
var vetoedValue: Int by Delegates.vetoable(0) { prop, old, new ->
new >= 0 // 음수는 허용되지 않습니다.
}
vetoedValue = 1 // OK
vetoedValue = -1 // 거부됨, 값이 변경되지 않습니다.
println(vetoedValue) // 출력: 1
Kotlin
복사
•
Delegates.notNull
◦
초기화 전 접근 시도시 예외를 던진다.
var notNullValue: String by Delegates.notNull()
// 아래 코드는 예외를 발생시킵니다.
// println(notNullValue)
notNullValue = "Initialized"
println(notNullValue) // 출력: Initialized
Kotlin
복사
22. 일반적인 알고리즘을 구현할 때 제네릭을 사용하라
제네릭을 이용해 우리는 코드 블럭 내의 타입을 제한할 수 있고, 그로 인해 컴파일러는 더 안전하게 타입 추론을 할 수 있게 되고, 그 결과 우리는 좀 더 편하게 프로그래밍을 할 수 있게 된다.
제네릭은 컴퓨터의 성능같은 이득을 주지는 못한다. 어짜피 JVM 바이트 코드 제한으로 인해 컴파일 시점에 제네릭 정보들은 모두 사라진다. 오직 개발자의 프로그래밍에 이점을 준다.
하지만, 이 이점이 크다. 다음은 filter 함수이다.
inline fun <T> Iterable<T>.filter(predicate: (T) -> Boolean): List<T> {
val destination = ArrayList<T>()
for (elm in this) {
if(predicate(elm)) {
destination.add(elm)
}
}
return destination
}
Kotlin
복사
제네릭의 타입 아규먼트를 통해 우리는 필터 확장함수 내부에서 사용되는 값들이 컬렉션의 요소와 같은 타입이라는 것을 알 수 있다. 이를 통해 코드 자동 완성 기능은 더 적절한 제안을 해 줄 수도 있다.
또한 타입 제한을 통해 코드의 가독성을 높힐 수도 있다.
fun <T : Comparable<T>> Iterable<T>.sorted(): List<T> { ... }
fun <T, C : MutableCollection<in T>> Iterable<T>.toCollection(destination: C): C {...}
fun class ListAdapter<T: ItemAdapter>(...) {...}
Kotlin
복사
이렇게 타입 제한을 하면, 우리는 이 제약을 통해 해당 타입이 제공하는 기능들을 사용할 수 있다.
Comparable<T>로 제한하면, 해당 타입들을 비교할 수 있고(즉 정렬이 가능하고), MutableCollection<in T>로 제한하면 컬렉션이 T의 슈퍼타입인 변경 가능한 컬렉션이 반환된다는것을 알 수 있다.
이처럼 코틀린 자료형 시스템에서 제네릭을 이용해 코드의 가독성 뿐 아니라 타입 제한을 통해 기능을 유추할 수 있게 되고, 특정 자료형이 제공하는 기능을 사용할 수 있게 할 수도 있다.
23. 타입 파라미터의 섀도잉을 피하라
우선, 섀도잉(shadowing)이 뭔지부터 알아보자.
다음 코드를 보면 Food 클래스의 프로퍼티(name)과 addFood 함수의 아규먼트(name)이 동일하다.
class Food(val name: String) {
fun addFood(name: String) { ... }
}
Kotlin
복사
이 경우 addFood 함수 내에서 name을 호출할 경우 아규먼트가 외부 스코프에 있는 프로퍼티를 가리게 된다. 이런 상황을 섀도잉이라 부르는데, 생각보다 많은 상황에서 재연되며, 특히 제네릭에 대해 이해를 제대로 못했을 경우, 많이 발생한다.
다음 코드를 보자. 클래스와 함수의 타입 파라미터가 각기 독립적으로 작성되어 있다.
하지만, 자세히 보지 않으면 이 사실을 파악하기 힘들다.
interface Fruit
class Grape: Fruit
class Banana: Fruit
class FruitMarket<T: Fruit> {
fun <T: Fruit> addFruit(fruit: T) {
//...
}
}
val market = FruitMarket<Grape>() //과일 타입을 포도로 제한한 것 같은데...
market.addFruit(Grape())
market.addFruit(Banana()) // 왜 바나나도 추가가 되는걸까? 제네릭은 불공변인데..
Kotlin
복사
제네릭은 불공변이기에 바나나 추가는 안될 것 같지만, 잘 추가가 된다. 이는
함수의 타입 제한은 과일(Fruit)이기 때문이다. 클래스 레벨에서 작성한 포도 타입은 함수와는 무관하다는 것이다. 하지만, 이는 가독성 저하를 일으키고, 심각한 휴먼 에러를 유도할 수 밖에 없는 작성 방식이다. 차라리 addFruit 함수가 클래스 타입 파라미터를 사용하도록 하거나
class FruitMarket<T: Fruit> {
fun <T: Fruit> addFruit(fruit: T) {
//...
}
}
val market = FruitMarket<Grape>()
market.addFruit(Grape())
market.addFruit(Banana()) //ERROR, type mismatch
Kotlin
복사
타입 파라미터 이름을 구분지어서 작성해주는게 개발자가 오해할 여지를 줄여줄 수 있다.
class FruitMarket<T: Fruit> {
fun <ST: T> addFruit(fruit: ST) {
//...
}
}
Kotlin
복사
24. 제네릭 타입과 variance 한정자를 활용하라
코틀린의 제네릭타입과 variance 한정자는 자바와는 다르게 설계되었지만, 지키려는 가치는 유사하다. 코드의 유연성, 가독성과 안전성, 재사용성을 높히는 것 말이다.
유연성, 혹은 재사용성
제네릭 타입은 기본적으로 불공변이다.
즉, 다음과 같이 부모 자식 객체로 다형성이 성립된다 하더라도 상호 호환되지 않는다.
interface Fruit
class Grape: Fruit
class Banana: Fruit
val list: Market<Fruit> = Market<Grape>() // ERROR: Type mismatch
Kotlin
복사
이러한 제약을 해결하기 위해서 코틀린에서는 variance 한정자(out or in)를 이용해 해결해준다.
variance 한정자는 out과 in이 있는데 각각
•
out: 타입 파라미터를 covariant(공변성) 으로 만든다.
•
in: 타입 파라미터를 contravariant(반변성) 으로 만든다.
좀 더 쉽게 말하면 out 한정자를 사용할 경우 서브타입을 허용해주고, in 한정자를 사용할 경우 슈퍼타입을 허용해준다는 것이라고 볼 수 있다.
그럼 언제 out 한정자를, in 한정자를 사용해야 할까? 이펙티브 자바에서는 PECS 공식을 기억하라고 한다.
PECS: producer-extends, consumer-super
즉, 생산자는 extends(out)로 타입 유연성을 높히고 소비자는 super(in)으로 타입 유연성을 높히자는 말이다.
다르게 설명하면, 함수에서 파라미터 타입은 소비자이기에 super(in)이며 contravariant이고, 반환 타입은 생산자이기에 extends(out)이며 covariant이다.
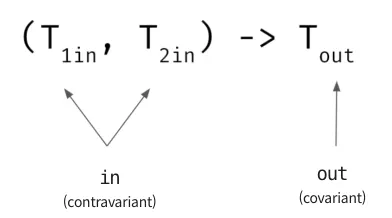
함수 타입을 사용할 땐 자동으로 위와 같이 variance 한정자가 사용된다.
가독성
variance 한정자를 통해 우리는 좀 더 쉽게 코드를 유추할 수 있다.
val list: MutableList<in Puppy> = mutableListOf()
val list2: List<out Dog> = listOf()
Kotlin
복사
위 코드를 보면 어떤가? list는 인덱스 제어가 가능하면서 Puppy의 슈퍼타입이라는 점을 바로 알 수 있고, list2는 불변 컬렉션이면서 Dog 의 하위타입을 요소로 가지고 있을 것이라고 유추할 수 있다.
이처럼 variance 한정자를 통해 요소의 정보를 좀 더 디테일하게 유추할 수 있게 되고 이는 더 높은 가독성을 제공하는 것이 된다.
안전성
variance 한정자를 이용해서 우리는 안전성을 가질 수 있다.
자바의 배열은 covariant 속성을 가지고 있어서 다음과 같이 힙 오염이 발생할 수 있다.
Integer[] nums = {1, 4, 2, 1};
Object[] objs = numbers;
objs[2] = "B"; // RuntimeException: ArrayStoreException
Kotlin
복사
코틀린에서는 Array(IntArray, CharArray, …)를 invariant로 만들어서 이런 문제들을 해결한다.
하지만, 그럼에도 다음과 같은 문제가 발생할 수 있다.
open class Dog
class Puppy: Dog()
fun takeDog(dog: Dog) {}
takeDog(Dog())
takeDog(Puppy())
Kotlin
복사
함수의 타입 매개변수는 소비자이기에 in 한정자 위치라고 할 수 있다. 하지만 Puppy는 covariant 타입(Dog의 서브 타입)이기에 covariant와 upcasting을 연결해 우리가 원하는 타입을 아무것이나 전달할 수 있게 되고, 이는 자바에서처럼 힙 오염이 발생하거나 런타임 예외가 던져질 가능성이 생긴다.
•
문제의 코드
class Box<out T> {
private var value: T? = null
//코틀린에서 실제론 에러가 발생하는 코드지만 일단 무시하자.
fun set(value: T) { this.value = value }
fun get(): T = value ?: error("Value not set")
}
val puppyBox = Box<Puppy>()
val dogBox: Box<Dog> = puppyBox
dogBox.set(Hound()) // 여기서 런타임 예외가 발생한다.
val dogHouse = Box<Dog>()
val box: Box<Any> = dogHouse
box.set("Some string") // 여기서 런타임 예외가 발생한다.
box.set(42) // 여기서 런타임 예외가 발생한다.
Kotlin
복사
캐스팅을 하더라도 실제 구현체가 바뀌는 것은 아니기에 문제가 된다.
그렇기에 각각 강아지 박스 객체들은 각각 Dog타입만을 받아들이고, public in 한정자 위치에 covariant 타입 파라미터(out 한정자)가 오는 것을 금지해 이런 상황을 막는다.
variance 한정자의 위치
variance 한정자는 크게 두 군데에 위치해서 사용할 수 있다.
1.
선언 부분
: 대부분 이 위치에서 사용하며 클래스와 인터페이스 선언에 한정자가 적용되며, 해당 클래스나 인터페이스가 사용되는 모든 곳에 영향을 준다.
class Box<out T>(val value: T)
Kotlin
복사
2.
클래스와 인터페이스를 활용하는 부분
: 특정한 변수에만 variance 한정자가 적용된다.
class Box<T>(val value: T)
val boxStr: Box<String> = Box("Str")
val boxAny: Box<out Any> = boxStr
Kotlin
복사
25. 공통 모듈을 추출해서 여러 플랫폼에서 재사용하라
코틀린 하나의 언어로 얼마나 많은 플랫폼에서 재사용이 가능할까?
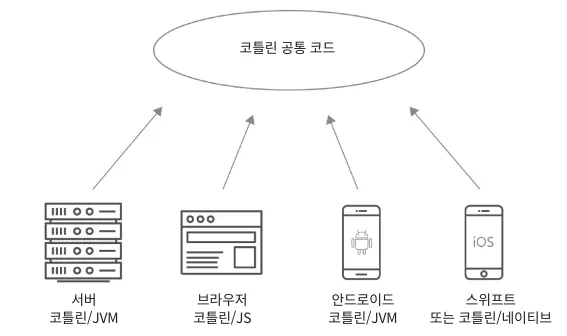
•
코틀린/JVM 을 사용한 백엔드 개발 - 스프링, Ktor, …
•
코틀린/JS를 사용한 웹사이트 개발 - 리액트 등
•
코틀린/JVM 을 사용한 안드로이드 개발 - 안드로이드 SDK등
•
코틀린/네이티브를 통해 Objective-C/스위프트로 IOS 프레임워크 개발
•
코틀린/JVM을 사용한 데스크톱 개발 TornadoFX등
•
코틀린/네이티브를 사용한 라즈베리파이, 리눅스, macOS 프로그램 개발
우리는 각각의 언어를 모두 공부하는게 아닌 코틀린 하나만 가지고도 여러 플랫폼을 개발 할 수 있게 되었다. 이런 공통 모듈을 이용해 코드의 재사용성을 높힐 수 있다.
하지만, 공통 개발이라는건 각 플랫폼에 맞춘 특화 기능들을 사용하는데 제약이 생기거나 분야에따라 생태계가 완성되지 않았기에 이슈에 대해 토론하거나 해결하기 더 높은 비용이 소비될 수 있기 때문에 잘 고려해서 사용해야 한다.

