

JPA 소개
: JPA와 모던 자바 데이터 저장 기술
현재 개발 트렌드 - 언어,DB
•
현재의 개발 언어 트렌드 → 객체 지향 언어(ex: [Java, Scala, Kotlin...] )
•
현재 데이터베이스 세계의 헤게모니 → 관계형 DB(ex: Oracle, MySQL, PostgreSQL...]
→ 객체를 관계형 DB에 관리한다는 것 이 문제 → 개발자가 객체로 데이터를 가공했지만 DB에 저장할 땐 결국 SQL → SQL 중심적인 개발이 되버린다.
 무엇이 문제인가?
무엇이 문제인가?
1.
기능하나 추가해서 테이블이 생성 될 때마다 CRUD SQL을 다 만들어줘야 한다.
→ JdbcTemplate, MyBatis가 Mapping에 도움을 주는 것은 있지만 그래도 한계가 있다.
•
Example:: 회원 객체를 만들고 DB에 CRUD를 하는 기능이 있는 상태
1.
기존 회원객체와 테이블 기능쿼리 구현
/*회원 객체*/
public class Member {
private String memberId;
private String name;
}
/*쿼리*/
INSERT INTO MEMBER(MEMBER_ID, NAME) VALUES ...
SELECT MEMBER_ID, NAME FROM MEMBER M
UPDATE MEMBER SET ...
Java
복사
2. 기획자가 전화번호 필드를 추가 해 달라고 한 상황
/*회원 객체*/
public class Member {
private String memberId;
private String name;
private String tel;
}
/*쿼리*/
INSERT INTO MEMBER(MEMBER_ID, NAME, TEL) VALUES ...
SELECT MEMBER_ID, NAME, TEL FROM MEMBER M
UPDATE MEMBER SET ...TEL = ?
Java
복사
◦
모든 CRUD 쿼리에 TEL을 하나하나 추가해줘야 한다.
결론: SQL에 의존적인 개발을 할 수밖에 없다.
2. 패러다임의 불일치 - 객체 vs 관계형 데이터베이스
→ 관계형 데이터베이스와 객체지향은 서로 가지고있는 사상이 다르다.
•
객체지향개발 : 추상화, 캡슐화, 정보은닉, 상속, 다형성등 시스템의 복잡성을 제어하는 다양한 장치들 제공
•
관계형데이터베이스: 데이터를 잘 정규화해서 저장하는 것이 목표.
→ 객체를 영구 보관하는 다양한 저장소
•
Object
◦
RDB: 현 헤게모니
◦
NoSQL: 대안이 될 수 있을수는 있지만 main이 되기엔 아직 부족하다.
◦
File: 객체 100만건을 Serialize 저장하고, 또 반대로 100만건을 Deserialize해서 Object화 한 다음 검색하는건 불가능하다.
◦
OODB : 죽은지 오래
객체를 관계형 데이터베이스에 저장
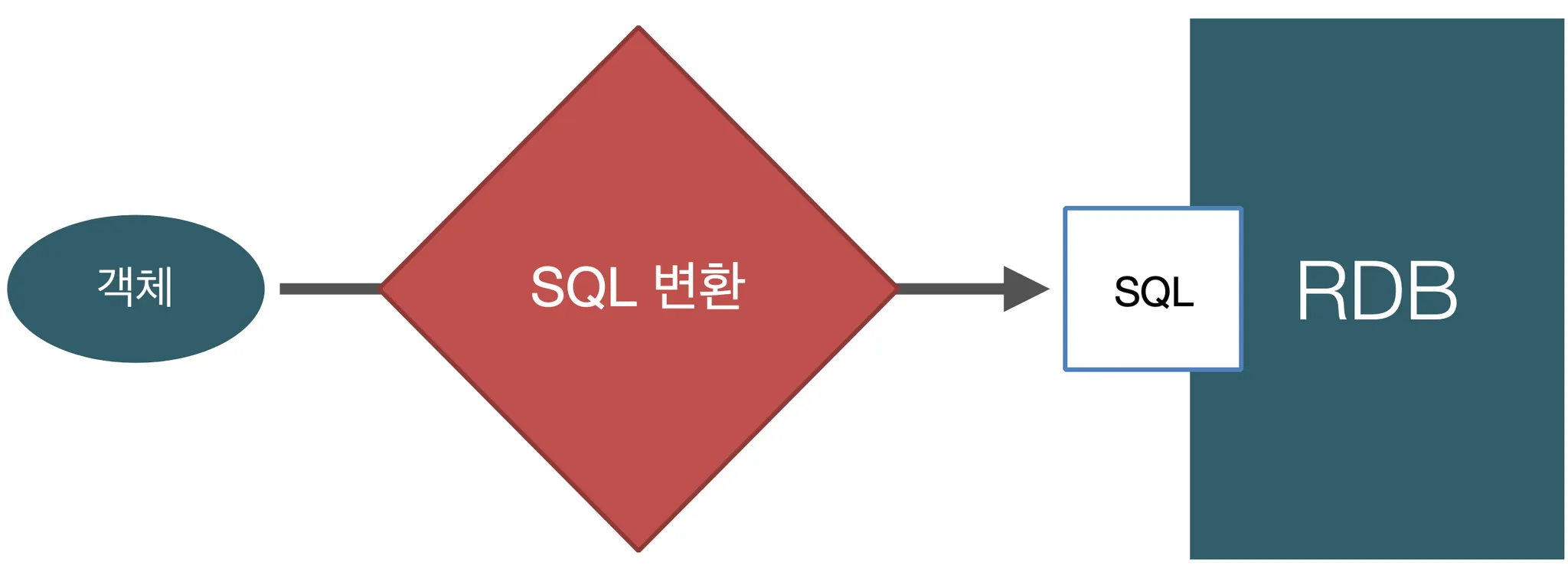
•
객체를 SQL로 변환해서 RDB에 저장하는 변환과정을 개발자가 해야 한다.
→ 노가다 시작
객체와 관계형 데이터베이스의 차이
1. 상속
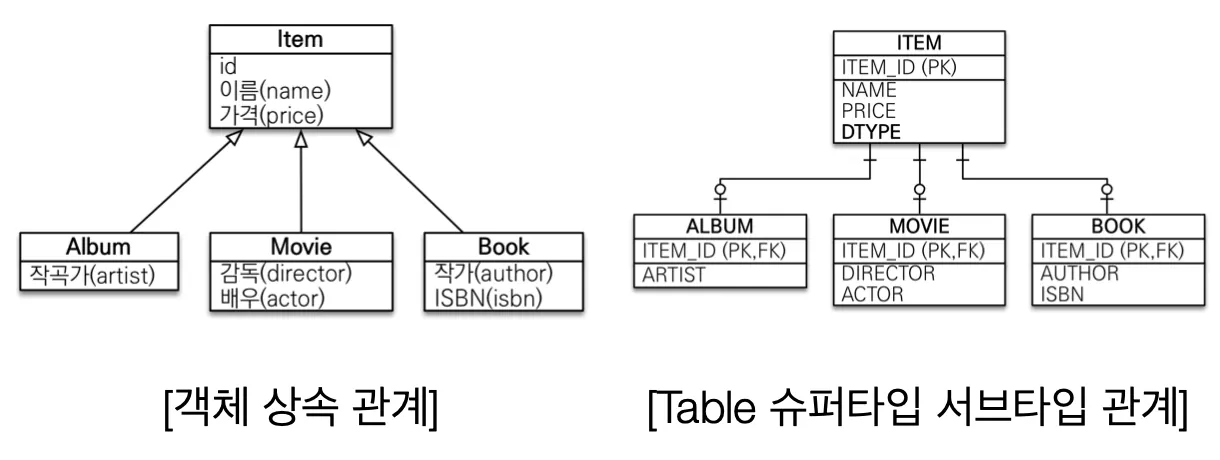
•
객체의 상속관계와 유사한 관계형 데이터베이스의 개념으로 Table 슈퍼타입, 서브타입 관계가 있다.
•
객체 상속 관계에서는 그저 extends나 implements 로 상속 관계를 맺고 캐스팅도 자유롭다.
•
하지만, 상속 받은 객체(Album, Movie, Book)을 데이터베이스에 저장하려면 어떻게 해야하는가?
1.
객체 분해: Album객체를 Item과 분리한다.
2.
Item Table에 하나, Album테이블에 하나 두개의 쿼리를 작성해서 저장한다.
•
Album 객체를 DB에서 조회하려면 어떻게 해야하는가?
→ ITEM과 ALBUM을 조인해서 가져온 다음 조회한 필드를 각각 맞는 객체(ITEM, ALBUM)에 매핑시켜서 가져와야 한다.
결론: DB에 저장할 객체는 상속관계를 쓰지 않는다.
2. 연관관계
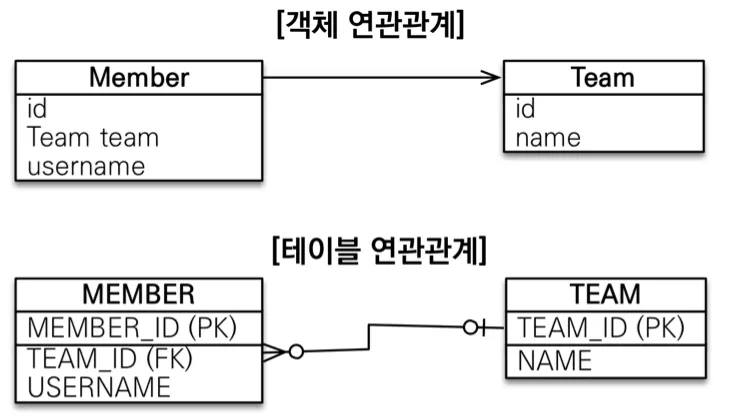
•
객체는 참조를 사용한다: member.getTeam();
•
테이블은 외래 키를 사용한다: JOIN ON M.TEAM_ID = T.TEAM_ID
Member와 Team간에 참조가 가능한가? •
객체: Member → Team 은 member.getTeam()을 통해 가능, Team → Member 는 참조할 객체가 없기 때문에 불가능하다.
•
테이블: 서로가 서로를 참조할 키(FK)가 있기 때문에 양측이 참조가 가능하다. Member Team
Team객체를 테이블에 맞춰 모델링하게 된다.class Member{
String id; //MEMBER_ID 컬럼 사용
Long teamId; //참조로 연관관계를 맺는다.
String username; // USERNAME 컬럼 사용
}
class Team{
Long id; //TEAM_ID 컬럼 사용
String name; //NAME 컬럼 사용
}
/*쿼리*/
INSERT INTO MEMBER(MEMBER_ID, TEAM_ID, USERNAME) VALUES ...
INSERT INTO TEAM(TEAM_ID, NAME) VALUES...
Java
복사
•
하지만, 위 코드는 객체지향적이지 못한 것 같다.
Why? : Member에서는 Team을 참조하는데 참조값을 가져야 하지 않을까?
Long teamId -> Team team;
Team getTeam(){
return team;
}
Java
복사
◦
이렇게 설계를 바꾼다면 외래키를 DB에 어떻게 저장하는가?
member.getTeam().getId();
Java
복사
◦
참조되는 Team객체에서 id를 가져와서 넣어줘서 저장한다.
◦
하지만, 조회할 때는 어떻게 하는가?
객체 모델링 조회
SELECT M.*, T.*
FROM MEMBER M
JOIN TEAM T ON M.TEAM_ID = T.TEAM_ID
public Member find(String memberId){
//SQL 실행
Member member = new Member();
//데이터터베이스에서 조회한 회원 관련 정보를 모두 입력
Team team = new Team();
//회원과 팀 관계 설정
member.setTeam(team);
return member;
}
Java
복사
•
객체 그래프 탐색
: 객체는 자유롭게 객체 그래프를 탐색할 수 있어야 한다( ex: member.getXXX())
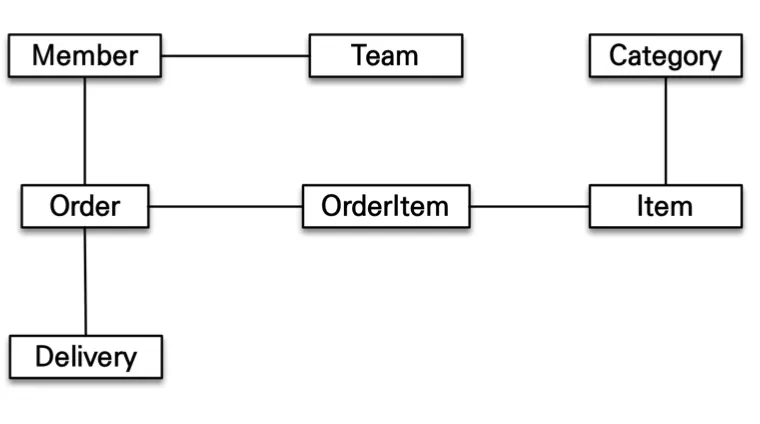
◦
Member 객체에서 엔티티 그래프를 통해 Category 까지도 접근이 가능해야 한다.
처음 실행하는 SQL에 따라 탐색 범위가 결정된다.
SELECT M.*, T.*
FROM MEMBER M
JOIN TEAM T ON M.TEAM_ID = T.TEAM_ID
member.getTeam(); //OK
member.getOrder(); //null
Java
복사
엔티티 신뢰문제가 발생한다.
class MemberService{
...
public void process(){
Member member = memberDao.find(memberId);
member.getTeam(); //????
member.getOrder().getDelivery(); //????
}
}
Java
복사
•
정말 자유롭게 member안의 모든 참조를 자유롭게 참조할 수 있을까?
•
새로 투입된 개발자가 새로운 필드를 추가했는데 조회 로직에서 해당부분 매핑을 빼놨다면?
•
실제로 모든 코드와 쿼리를 분석해보기전까지는 엔티티 그래프 검색이 어디까지 되는지 확신할 수 없다.
그렇다고 모든 객체를 미리 로딩할 수는 없다.
•
상황에 따라 동일한 회원 조회 메서드를 여러벌 생성
memberDAO.getMember(); //Member만 조회
memberDAO.getMemberWithTeam(); //Member와 Team조회
memberDAO.getMemberWithOrderWithDelivery(); // Member, ORder, Delivery 조회
Java
복사
결론: 계층형 아키텍처
진정한 의미의 계층 분할이 어렵다.
동일한 식별자로 조회한 두 객체 비교결과는?
String memberId = "100";
Member member1 = memberDAO.getMember(memberId);
Member member2 = memberDAO.getMember(memberId);
member1 == member2; // false 다르다
class MemberDAO{
public Member getMember(String memberId){
String sql = "SELECT * FROM MEMBER WHERE MEMBER_ID = ?";
...
//JDBC API, SQL 실행
return new Member(...);
}
}
Java
복사
member를 조회할 때마다 new Member()를 통해 새로운 객체를 만들어서 조회 하기 때문에 두 인스턴스 비교는 내용물이 같더라도 다르다.
자바 컬렉션에서 조회한 객체를 비교
String memberId = "100";
Member member1 = list.get(memberId);
Member member2 = list.get(memberId);
member1 == member2; // true 같다.
Java
복사
참고: 동일성과 동등성(Identical & Equality)
자바에서 두 개의 오브젝트 혹은 값이 같은가 라는 말은 주의해서 사용해야 합니다.
(identical)동일한 오브젝트라는 말은 같은 레퍼런스를 바라보고 있는 객체라는 말로 실제론 하나의 오브젝트라는 의미이고,(Equivalent)동등한 오브젝트란는 말은 같은 내용을 담고 있는 객체라는 의미입니다.
결론: 객체지향적으로 모델링을 할 수록 매핑작업만 늘어나고 불일치가 늘어나서 사이드이펙트가 커지기만 한다.
그렇다면, 객체를 자바 컬렉션에 저장하듯이 DB에 저장할 수 없을까? 고민하다 나온 것이 JPA이다.
JPA 시작하기
프로젝트 생성
1.
DB 설치하기
⇒ 실습용으로는 간단하게 사용되고 웹상황에서 콘솔창도 볼 수 있는 H2를 사용한다. H2 설치 가이드는 링크 글을 참고한다.
2.
프로젝트 생성하기
•
자바 8 이상(8권장)
•
메이븐 or 그래들 프로젝트
◦
groupId: jpa-basic
◦
artifactId: ex1-hello-jpa
◦
version: 1.0.0
•
사용 라이브러리
◦
H2
◦
Spring Web
◦
Spring devtool
◦
JPA
◦
Lombok
•
프로젝트 설정
1.
Maven
<?xml version="1.0" encoding="UTF-8"?>
<persistence
version="2.2"
xmlns="http://xmlns.jcp.org/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd">
<persistence-unit
name="hello">
<properties>
<!-- 필수속성 -->
<property name="javax.persistence.jdbc.driver" value="org.H2.Driver"/>
<property name="javax.persistence.jdbc.user" value="sa"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.url" value="jdbc:h2:tcp://localhost/~/test"/>
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/>
<!-- 옵션 -->
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="hibernate.use_sql_comments"
value="true"/> <!--<property name="hibernate.hbm2ddl.auto" value="create" />-->
<property name="hibernate.jdbc.batch_size" value="10"/>
<property name="hibernate.hbm2ddl.auto" value="create"/>
</properties>
</persistence-unit>
</persistence>
XML
복사
2.
Gradle - (properties) 코드 - 필자는 properties를 제거하고 yaml파일 사용
spring:
profiles:
active: local
datasource:
url: jdbc:h2:tcp://localhost/~/hellojpa
username: sa
password:
driver-class-name: org.h2.Driver
jpa:
hibernate:
ddl-auto: create
properties:
hibernate:
# show_sql:true
format_sql: true
thymeleaf:
prefix: classpath:/templates/
suffix: .html
logging:
level:
org.hibernate.SQL: debug
# org.hibernamte.type: trace
YAML
복사
JPA 구동 방식 - maven
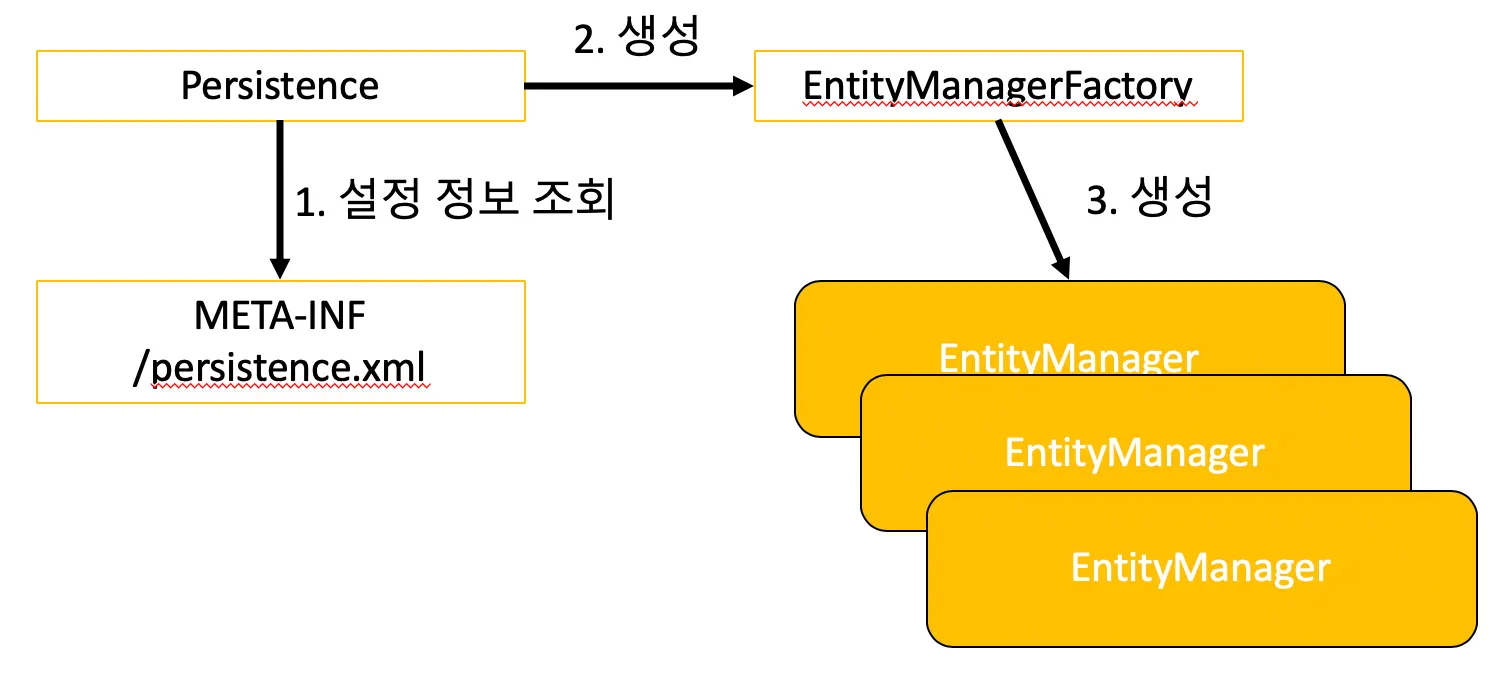
Example Source - Start
package hellojpa;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
import javax.persistence.Persistence;
public class JpaMain {
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
EntityManager em = emf.createEntityManager();
emf.close();
}
}
Java
복사
•
Persistence 클래스에서 persistence.xml의 persistenceUnitName을 인자 값으로 주면 해당 persistence Unit에 지정된 설정 정보들을 토대로
EntityManagerFactory를 만들어 준다.
•
EntityManagerFactory에서 EntityManager를 만들어 준다.
•
생성된 EntityManager로 DB에 SQL을 전달하며 데이터를 CRUD 한다.
Example Source - Entity
package hellojpa;
import javax.persistence.*;
import java.util.Date;
@Entity
public class Member {
@Id @GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
@Column(name = "USERNAME")
private String name;
@Column(name = "TEAM_ID")
private Long teamId;
//getter, setter
...
}
Java
복사
•
@Entity 어노테이션은 JPA에서 해당 객체를 관리하겠다는 어노테이션
•
@Id는 해당 필드가 식별자 역할을 한다는 어노테이션
•
@GeneratedValue 는 식별자 생성전략 어노테이션
•
@Column 은 해당 필드가 DB에서 쓰일 때 적용되는 속성들(
Example Source - Transaction
package hellojpa;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
import javax.persistence.Persistence;
public class JpaMain {
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
try{
Member member = new Member();
member.setId(2L);
member.setName("HelloA");
em.persist(member);
tx.commit();//member는 준영속 상태가 되어 name이 바뀐 것이 적용되지 않는다.
}catch(Exception error){
tx.rollback();
}finally {
em.close();
}
emf.close();
}
}
Java
복사
•
JPA는 모든 DB 로직은 Transaction 단위로 수행된다.
EntityManger의 기본적인 CRUD
•
저장 : persist()
•
조회: find()
•
삭제: remove()
•
변경: 변경은 따로 함수를 호출하기보다는 find를 해서 가져온 객체에서 setter 메서드를 통해 값을 변경하면 commit()호출시 적용되기 전 시스템에서 변경감지를 통해 기존 객체와 차이점을 찾아서 업데이트를 자동으로 해준다.
주의점
•
EntityManagerFactory는 시스템마다 1개만 생성되서 애플리케이션 전체에서 사용되며 공유된다.
•
EntityManager는 쓰레드간에 공유하는게 아니다(사용하고 버려야 한다.)
→ 데이터베이스의 커넥션을 공유하지 않는 것과 동일하다.
•
JPA의 모든 데이터 변경은 트랜잭션 안에서 실행되야 한다
JPQL 소개
→ 식별자를 통한 단순 조회가 아닌 추가 조건들을 통해 조회를 하고자 할 때 사용한다.
JPQL 간단한 예제
a.
회원 전체 조회
List<Member> result = em.createQuery("select m from Member as m", Member.class).getResultList();
Java
복사
•
일반 쿼리와는 다르게 From절의 Member는 테이블이아닌 엔티티(Member.class)를 대상으로 한다.
•
그렇다면 이게 무슨 장점이 있는가?
◦
여기서 페이징이 등장한다면?
List<Member> result = em.createQuery("select m from Member as m", Member.class)
.setFirstResult(5)
.setMaxResults(8)
.getResultList();
Java
복사
◦
limit 8 offset 5 를 메서드를 통해 손쉽게 처리할 수 있다.
◦
각 DB의 방언에따라 JPA가 자동으로 맞춰준다.
◦
ansi가 제공하는 표준 SQL 문법을 모두 제공한다.
JPQL
•
JPA를 사용하면 엔티티 객체를 중심으로 개발
•
문제는 검색 쿼리
→ JOIN, 집합통계 쿼리 등등...
•
검색을 할 때도 테이블이 아닌 엔티티 객체를 대상으로 검색
→ 테이블에서 가져오면 객체지향의 패러다임이 깨지기 때문에 엔티티 객체를 대상으로 검색
•
모든 DB데이터를 객체로 변환해서 검색하는 것은 불가능
•
애플리케이션이 필요한 데이터만 DB에서 불러오려면 결국 검색 조건이 포함된 SQL이 필요.
→ RDB에 직접 쿼리를 만들어 보내버리면 해당 쿼리는 특정 테이블에 종속적이 되버린다.
•
JPA는 SQL을 추상화한 JPQL이라는 객체 지향 쿼리 언어를 제공한다.
•
SQL과 문법 유사, SELECT, FROM, WHERE, GROUP BY, HAVING, JOIN 지원
•
JPQL은 엔티티 객체를 대상으로 쿼리한다.
→ DB를 바꾸더라도 방언을 교체 할 필요가 없다.
•
SQL은 데이터베이스 테이블을 대상으로 쿼리한다.

